


1. Introduction
When conducting phonetic investigations of a lesser-studied language, researchers will often encounter resource challenges when it comes to segmentation. Even for Swedish, a language not typically considered lesser-studied, very few technological tools circulate for phoneticians. This paper seeks to address this gap by incorporating a simple and straight-forward Swedish-language adaptation of FAVE-Align (Rosenfelder et al. Reference Rosenfelder, Fruehwald, Evanini and Yuan2011) that resembles approaches used in the past for endangered languages (DiCanio et al. Reference DiCanio, Nam, Whalen, Bunnell, Amith and García2013; Coto-Solano & Solórzano Reference Coto-Solano and Sofía2017; Coto-Solano et al. Reference Coto-Solano, Nicholas and Wray2018; Strunk et al. Reference Strunk, Schiel, Seifart, Nicoletta, Khalid, Thierry, Hrafn, Bente, Joseph, Asuncion, Jan and Stelios2014). The novel contributions of this paper are that (1) this is the first published adaptation for any Nordic language, (2) this adaptation meets most of the accuracy benchmarks established by the literature, (3) a step-by-step guideline is offered in the Appendix for those who wish to duplicate the adaptation for another Nordic language.
In cases where a language has not yet been modeled for forced alignment – or it has been modeled but not disseminated publicly Footnote 1 – phoneticians must invest in training a new aligner. Not only does this demand time and expertise, researchers may not have access to sufficient transcribed material in that language, which is a key prerequisite for model training. But even if this material were to be available, such a task is always a potential ‘rabbit hole’ if the end product does not end up being sufficiently accurate. In other words, vetting the software before investing time in learning, training and validating is simply not possible, because a good track record for one language does not guarantee a similar track record for another (see, e.g., the various languages in Strunk et al. Reference Strunk, Schiel, Seifart, Nicoletta, Khalid, Thierry, Hrafn, Bente, Joseph, Asuncion, Jan and Stelios2014). In the case of researchers and students working with small datasets where the material is insufficiently large for training, the frustrating reality is that manual alignment is often the only option.
This paper proposes an alternative; namely, adapting the English-language FAVE-Align to the Nordic languages while using its existing hidden Markov models. Whereas using such ‘untrained’ models has rendered unreliable results for endangered languages typologically distant from the original language(s) used for training (DiCanio et al. Reference DiCanio, Nam, Whalen, Bunnell, Amith and García2013; Coto-Solano & Solórzano Reference Coto-Solano and Sofía2017; Coto-Solano et al. Reference Coto-Solano, Nicholas and Wray2018; Strunk et al. Reference Strunk, Schiel, Seifart, Nicoletta, Khalid, Thierry, Hrafn, Bente, Joseph, Asuncion, Jan and Stelios2014), we show it to be robust and reliable for spontaneous and read-aloud Stockholm Swedish – likely because the variety is more typologically similar to English. In crudely and quickly adapting FAVE-Align to Stockholm Swedish, we were able to reduce total manual segmentation time to approximately 78 hours per recorded hour. For spontaneous speech, 37% of the boundaries fell within 10 ms and 65% of the boundaries fell within 20 ms of the manual-alignment benchmark. For read-aloud speech, these figures were 50% and 73%, respectively. Successful alignment of spontaneous speech requires of course access to a comprehensive pronunciation dictionary, and this is not always available for lesser-studied languages. However, aligning read-aloud speech requires just a short list of pronunciations, so we believe that our latter results will have the widest reach.
Given the long absence of publicly-disseminated forced aligners for any of the Nordic languages, Footnote 2 and the fact that untested Swedish aligners have only recently been released (see Section 2.2 for a review), this paper can serve both as a methodological template for adapting FAVE-Align to other Nordic varieties (see Appendix) and as a base reference for benchmarking the performance of future aligners. Such peer-reviewed benchmarks are needed as linguists pollinate technological movement in the field, and they are vital for seeking out prospective grants and funds to finance the training of designated Nordic-language aligners.
2. Background
2.1 Forced alignment and its advancement of phonetic research
With the help of readily-available forced-alignment programs, phonetic investigations of English have advanced further than those of any other language. Meanwhile, phonetic investigations of the Nordic languages, including Swedish, have lagged. To offer an example, we examined and coded – according to language researched – the 782 articles published between 2001 and 2020 in the Journal of Phonetics. The top three researched languages were English, German and French with 336, 71, and 65 articles, respectively. Swedish, the most-commonly researched Nordic language, had a mere 12 articles, followed by Norwegian with eight, Danish with four, and Icelandic with one. Proportionate to number of speakers, these languages are somewhat underrepresented. Finnish, a language with approximately 5 million speakers, had 19 articles; Arrernte, a language with approximately 4,000 speakers, had six articles. As an additional example, before the onset of the project to which this development is tied (Young Reference Young2019), only three variationist investigations had ever been conducted on Swedish (Gross et al. Reference Gross, Boyd, Leinonen and Walker2016; Kotsinas Reference Kotsinas, Johan, Ulf, Michael, Hillevi and Bo1994; Nordberg Reference Nordberg and Karl-Hampus1975). Among these three, only the first-listed study was acoustic-phonetic, relying on manual segmentation (personal conversation with Johan Gross, 2020). The latter two were based on data that was never phonetically segmented; rather, variants were perceptually coded and counted.
We believe a circular dynamic is at play. The low number of contemporary phoneticians engaged with research on Nordic languages Footnote 3 has translated into few investments in forced alignment. In turn, this lack of investment has perhaps discouraged growth of the field. For English, the same feedback cycle may also be operating, albeit in the opposite direction. The early dominance of research on English has motivated the development of a high number of forced aligners, which has allowed the anglo-linguistic enterprise to be more prolific than ever.
The four main forced-alignment suites that circulate today were all trained on the English language. They are Forced Alignment and Vowel Extraction (FAVE-Align; Rosenfelder et al. Reference Rosenfelder, Fruehwald, Evanini and Yuan2011; Yuan et al. Reference Yuan, Ryant, Liberman, Stolcke, Mitra and Wang2013), ProsodyLab Aligner (Gorman et al. Reference Gorman, Howell and Wagner2011), LaBB-CAT Transcriber (Fromont & Hay Reference Fromont, Jennifer, Paul and Scott2012), and the Montreal Forced Aligner (McAuliffe et al. Reference McAuliffe, Socolof, Mihuc, Wagner and Sonderegger2017). FAVE-Align (formerly known as the Penn Forced Aligner, Yuan & Liberman Reference Yuan and Mark2008), ProsodyLab Aligner, and the Montreal Forced Aligner are modeled on American English. LaBB-CAT is modeled on New Zealand English.
As a very recent addition (and after the onset of the present study), the Montreal Forced Aligner began offering pre-trained acoustic models for Bulgarian, Croatian, Czech, French, German, Hausa, Korean, Mandarin, Polish, Portuguese, Russian, Spanish, Swahili, Swedish, Thai, Turkish, Ukrainian, and Vietnamese. These newer models are trained on read-aloud speech and require the use of the GlobalPhone dictionary (Schultz & Schlippe Reference Schultz, Tim, Nicoletta, Khalid, Thierry, Hrafn, Bente, Joseph, Asuncion, Jan and Stelios2014), which is proprietary and costs 600 euros to obtain (alternative pronunciation dictionaries cannot be used because phone coding within the models is opaque). Performance metrics have not yet been released for any of these newer models (see Section 2.4).
Other options are EasyAlign for Praat (Goldman Reference Goldman2011) and the BAS Speech Science Web Services (Kisler et al. Reference Kisler, Reichel, Schiel, Draxler, Jackl and Pörner2016). EasyAlign offers automatic transcription for French, Spanish, and Taiwan Min, and works only on Windows machines. It appears that a singular adaptation had been made for Swedish in 2007, but this adaptation has not been made available to the public, and performance metrics were not ever disclosed (Lindh Reference Lindh2007). BAS Speech Science Web Services has offered for quite some time a web-accessible interface called WebMAUS Basic for automatic transcription of Basque, Catalan, Dutch, English, Estonian, Finnish, Georgian, German, Japanese, Hungarian, Italian, Maltese, Polish, Russian, and Spanish. Recently and also after the onset of this project, Swedish was also added, but performance metrics have not been released on this either.
As has been discussed in the Introduction, the present study is not the first time that FAVE-Align has been adapted as an ‘untrained’ prototype for lesser-studied languages. DiCanio et al. (Reference DiCanio, Nam, Whalen, Bunnell, Amith and García2013) built an adaptation for Yoloxóchitl Mixtec, and Coto-Solano Solórzano (Reference Coto-Solano and Sofía2017) built a similar prototype for the endangered lan- guage Bribri and, later, Cook Islands Maori (Coto-Solano et al. Reference Coto-Solano, Nicholas and Wray2018). Strunk et al. (Reference Strunk, Schiel, Seifart, Nicoletta, Khalid, Thierry, Hrafn, Bente, Joseph, Asuncion, Jan and Stelios2014) built a language-general model and used it to align read-aloud and spontaneous Baura, Bora, Even, and Sri Lankan Malay. These aligners produced between poor and fair accuracy levels, likely due to the typological difference between them and the language(s) their respective aligners were trained on (mostly Indo-European). The present adaptation stands out from this group in that its accuracy performance is competitive with custom-trained aligners.
What this review aims to demonstrate is that the development of forced alignment programs has been solidly anglocentric and that the expansion to other languages has excluded Nordic languages until very recently. This curious exclusion motivated the present study and has likely motivated the recent addition of Swedish to MFA and WebMAUS Basic. The ensuing performance analysis will serve as a handy baseline benchmark for the eventual testing of these other Swedish adaptations, and the step-by-step instructions we provide will allow others to duplicate our adaptation for other Nordic languages.
2.2 How forced alignment works
ProsodyLab, FAVE-Align, LaBB-CAT, BAS, and EasyAlign rely on the proprietary Hidden Markov toolkit (Young et al. Reference Young, Woodland and Byrne1993), and the Montreal Forced Aligner (MFA) relies on the open-source Kaldi (Povey et al. Reference Povey, Ghoshal, Boulianne, Burget, Glembek, Goel, Hannemann, Motlček, Qian, Schwarz, Silovský, Stemmer and Veselý2011), which is a type of neural network. Regardless of program, the inputs are always (1) an orthographic transcription, (2) a sound file, and (3) a pronunciation dictionary. The output is a phonetically-segmented file for use in Praat (Boersma & Weenink Reference Boersma and Weenink2017). The orthographic transcription is often a tab-delimited file outputted by ELAN (Sloetjes & Wittenburg Reference Sloetjes, Peter, Nicoletta, Khalid, Bente, Joseph, Jan, Stelios and Daniel2008) that has start and end times for each phrase/breath group (see Figure 1). The pronunciation dictionary is a text file that has pronunciation entries for every word in the language, which often can be as high as 30 or 40 possibilities for long compound words. This can be seen in Figure 2 where cirkusartist ‘circus performer’ has a canonical pronunciation option like [²ˈsɪr.kɵs.₂aˌʈɪst] on line 21, but a series of elided options such as [²ˈsɪr.kʂ̩.₂ˌʈɪs] on line 14. Footnote 4 The final output, exemplified in Figure 3, is a Textgrid file for use with Boersma & Weenink’s (Reference Boersma and Weenink2017) Praat that, as we discuss in the following sections, can vary in accuracy depending on the aligner at hand.

Figure 1. INPUTS 1 and 2: Five-column tab-delimited transcription input for FAVE-Align, produced with ELAN, and sound file.

Figure 2. INPUT 3: Pronunciation dictionary with all possible pronunciations using ASCII characters for IPA.
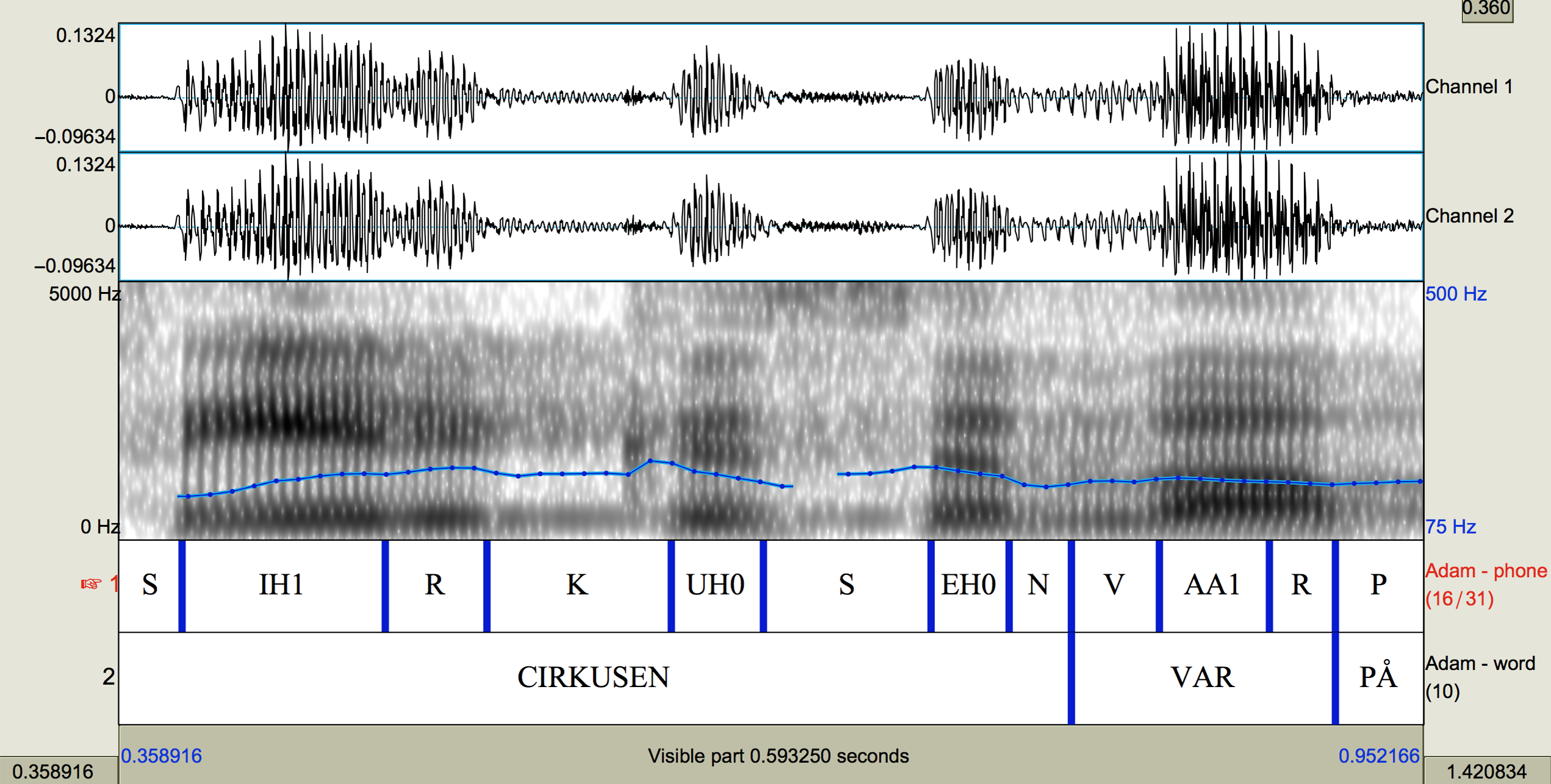
Figure 3. OUTPUT: Phonetically segmented file that is readable in Praat.
Most of the programs are free of cost (with the exception of the GlobalPhone extension of the MFA), and they provide various amounts of source code to the public along with varying degrees of written instructions for customizing the software to new languages. FAVE-Align stands out because it was specifically designed for sociolinguistic purposes and because it has shown the highest accuracy rates for the alignment of spontaneous vernacular speech (Yuan et al. Reference Yuan, Ryant, Liberman, Stolcke, Mitra and Wang2013). ProsodyLab and the MFA stand out because they provide the most robust assistance for training new languages. Additionally, the MFA is wrapped, which means it can be used out of the box with no subsidiary installations (e.g. Python).
FAVE-Align and the MFA are also noteworthy because they can process large sound files. They break files into chunks, align them, and concatenate them back together – all behind the scenes. This is very useful for any large-scale sociolinguistic project, but obviously less important for small projects. The remaining other programs require the user to manually break sound and transcription files down into one file per breath group. MFA is additionally noteworthy because it is relatively user-friendly and has an out-of-the-box trainer for new languages (should one have sufficient transcribed material handy).
We have offered a review of the various aligners on the market because this paper is, after all, about forced alignment. We would like, however, to point out that in the case of the Nordic languages, the comparative merits of each aligner do not matter much. In the case of Swedish, we had neither sufficient material to train an aligner like the MFA, nor were there pre-trained models available (and even today, the MFA model for Swedish sits behind a paywall). The picture is the same for Danish, Estonian Swedish, Faroese, Fenno-Swedish, Icelandic, the Northern and Western Norwegian dialects, and Övdalian. Absent of a large corpus of transcribed material, researchers will not be able to use MFA’s out-of-the-box trainer. The only reasonable alternative is the one we propose here.
2.3 Teasing apart the benefits of forced alignment
The purpose of this paper is to share a resource – a FAVE ‘hack’, if you will – to help phoneticians save time. Therefore, we will first devote this section to unpacking where exactly the most time is spent in the segmentation process. In doing so, we hope to demonstrate convincingly that there is a limit to the additional amount of time one can save after a certain accuracy threshold.
There is indeed a consistent positive relationship between alignment accuracy and time saved – if one wishes to extract data from uncorrected files, which is often the practice for variationist projects that take formant measurements from the nucleus of, for example, 25,000-plus vowels within a corpus (Dodsworth & Benton Reference Dodsworth and Benton2017:377). However, for analyses of rhythm (Torgersen & Szakay Reference Torgersen and Anita2012; Thomas & Carter Reference Thomas and Carter2006; Young Reference Young2019), manual corrections are obligatory. Laboratory Phonetics studies, typically using smaller datasets, also mandate manually-aligned datasets (Chodroff & Wilson Reference Chodroff and Wilson2017:33; Cole et al. Reference Cole, Hualde, Smith, Eager, Mahrt and Napoleão de Souza2019:120). In such instances, the time needed to manually move an incorrect boundary is roughly the same for 5 ms off-mark as it is for 40 ms off-mark. What saves time is fewer inaccurate boundary placements, with the degree of accuracy being more or less unimportant once the boundary error crosses a pre-established threshold.
Importantly, those time savings are marginal when compared to the time needed to manually build boundaries and populate the resulting cells with the appropriate phonetic orthography. To illustrate what we mean, take the following example. The recording that contains the first breath group from Figure 1 (Cirkusen var på väg! Deras plakat) lasts 2.37 seconds. Footnote 5 We set a timer while the first author conducted the following tasks in Praat:
-
1. Building tiers, then boundaries between words; populating the resulting cells: 2m 26s
-
2. Building boundaries between phonemes; populating the resulting cells: 4m 24s
-
3. Proofing boundaries; making final edits: 2m 19s
It takes 9 minutes 9 seconds (549 seconds) to manually align a 2.37-second transcription, which makes our segmentation-to-recording ratio 232:1. Footnote 6 Observe, however, that more than 75% of that time is spent building the boundary architecture and populating cells. Any program that can automatically do that has the potential to save a lot of time, regardless of how accurate boundary placement is. A program that can accurately place the boundaries is also a boon, but that is in many respects a secondary benefit.
It is this fact that motivated our choice to build a prototype from FAVE-Align rather than training an entirely new model for Swedish. Since we had no guarantee for future alignment accuracy, we felt that the rapid adaptation of a pre-existing aligner was the more prudent investment to make, since it would eliminate steps 1 and 2 no matter what. This is also the viewpoint taken by the researchers who paved the way for this study and used untrained aligners for typologically-rare endangered languages (DiCanio et al. Reference DiCanio, Nam, Whalen, Bunnell, Amith and García2013; Coto-Solano & Solórzano Reference Coto-Solano and Sofía2017; Coto-Solano et al. Reference Coto-Solano, Nicholas and Wray2018; Strunk et al. Reference Strunk, Schiel, Seifart, Nicoletta, Khalid, Thierry, Hrafn, Bente, Joseph, Asuncion, Jan and Stelios2014). Although the accuracy levels were poor, they nonetheless saved the authors considerable time in their alignment endeavors.
2.4 Identifying acceptable accuracy benchmarks
If one accepts the review presented in the preceding section, then nearly any level of accuracy is acceptable as a starting point from which to manually correct boundaries. Of course, the literature on forced alignment is not as permissive. It has established a consistent range of performance metrics that are reviewed below. We will later apply these same metrics as a way to assess the quality of our Swedish-language adaptation.
Many metrics circulate, and this can often make cross-comparability within the literature challenging. This paper will therefore limit itself to the four most common metrics: (1) median onset difference from manual alignments, (2) mean onset difference from manual alignments, (3) the percentage of boundaries that fall within 10 ms of the manual alignment, and (4) the percentage of boundaries that fall within 20 ms of the manual alignment.
As regards the median and mean differences, some studies have calculated these solely for vowels (Evanini Reference Evanini2009:56) or have calculated them from log-transformed absolute values (Wilbanks Reference Wilbanks2015; Gorman et al. Reference Gorman, Howell and Wagner2011). Here, we calculate them for all phonemes. Some studies have also used standard deviations (Labov et al. Reference Labov, Rosenfelder and Fruehwald2013) or the percentage of boundaries that fall within 5, 25, 30, 40, 50, and 100 milliseconds of the manual benchmark (Cosi et al. Reference Cosi, Falavigna and Omologo1991:695; McAuliffe et al. Reference McAuliffe, Socolof, Mihuc, Wagner and Sonderegger2017:500). We chose not to include these metrics because their adoption is not sufficiently widespread. The below review will first cover automatic alignment benchmarks followed by manual alignment benchmarks. In select cases where visual figures are provided with no actual number, we have estimated the number by lining a straight edge between the plot and the axes (Evanini Reference Evanini2009; Yuan & Liberman Reference Yuan and Mark2008; Cosi et al. Reference Cosi, Falavigna and Omologo1991). While different papers have rounded to different decimal levels, we round to the nearest whole percentage or millisecond.
2.4.1 Benchmarks for automatic alignment
Table 1 contains a schedule of the benchmarks laid out in the literature for forced alignment that we will discuss in the ensuing prose.
Table 1. Schedule of the benchmarks set in the literature according to the four most popular measurements. (Abbreviations: AE American English; BE British English; S spontaneous speech; R read-aloud speech; ms milliseconds; pct percentage.)
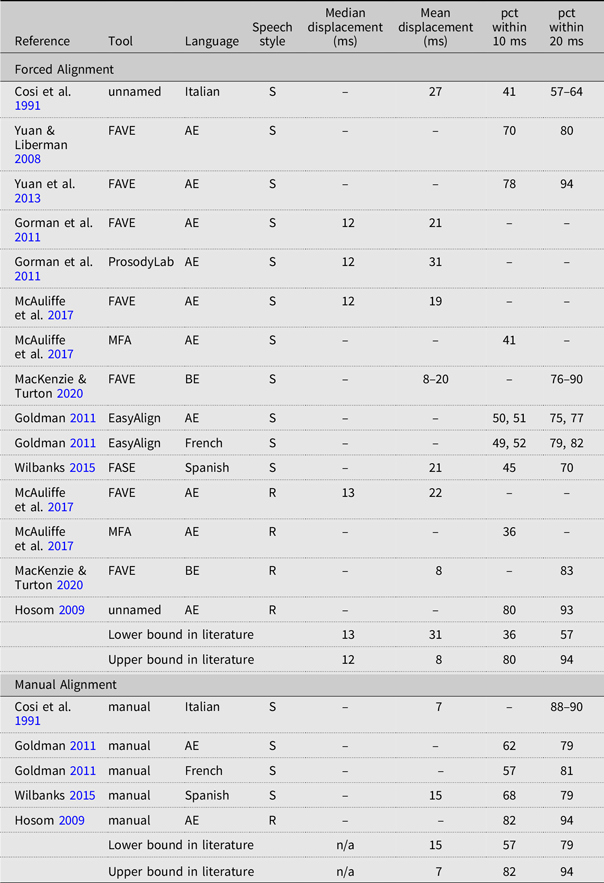
Cosi et al. (Reference Cosi, Falavigna and Omologo1991) is the earliest paper on phonetic forced alignment that we are aware of. They built an aligner for spontaneous Italian speech that had a mean error of 27 ms when compared to manually-aligned boundaries. For the 10-millisecond and 20-millisecond benchmarks, they were able to achieve circa 41% for the former and between 57% and 64% for the latter (Cosi et al. Reference Cosi, Falavigna and Omologo1991:695).
Yuan & Liberman (Reference Yuan and Mark2008), the most commonly-cited study for FAVE-Align, reported that approximately 70% of the boundaries fell within 10 ms of the manual standard and that approximately 80% of the boundaries fell within 20 ms of the manual standard (Yuan & Liberman Reference Yuan and Mark2008:4). These measurements were calculated on the original US Supreme Court Justice corpus upon which FAVE-Align was also modeled. In later work, Yuan et al. (Reference Yuan, Ryant, Liberman, Stolcke, Mitra and Wang2013:2308) proposed explicit phone boundary models within the Hidden Markov Model framework that improved the accuracy to 78% and 94% for the 10- and 20-millisecond error ranges, respectively.
Gorman et al. (Reference Gorman, Howell and Wagner2011) compared the performance of FAVE-Align with their newly-developed ProsodyLab Aligner on spontaneous American English taken from a television media corpus. They found FAVE-Align to have a median boundary error of 12 ms and a mean boundary error of 21 ms. For ProsodyLab, this was 12 ms and 31 ms, respectively. Ten- and 20-millisecond benchmarks were not calculated.
McAuliffe et al. (Reference McAuliffe, Socolof, Mihuc, Wagner and Sonderegger2017) assessed FAVE-Align and their newly-proposed Montreal Forced Aligner on read-aloud and spontaneous American English. For spontaneous speech run through FAVE-Align, the mean error was 19 ms, and the median error was 12 ms (McAuliffe et al. Reference McAuliffe, Socolof, Mihuc, Wagner and Sonderegger2017:501). For read-aloud speech run through FAVE-Align, the mean error was 22 ms, and the median error was 13 ms. Boundary-threshold percentages were not reported for FAVE-Align; they were, however, reported for the Montreal Forced Aligner. These were 41% within 10 ms for spontaneous speech and 36% within 10 ms for read-aloud speech (McAuliffe et al. Reference McAuliffe, Socolof, Mihuc, Wagner and Sonderegger2017:500). Twenty-millisecond thresholds were not calculated. What is particularly interesting about these results is that read-aloud speech aligned less accurately than spontaneous speech.
MacKenzie & Turton (Reference MacKenzie and Danielle2020) later tested FAVE-Align on read-aloud and spontaneous British English and found 83% of read-aloud phones to fall within 20 ms of the manual benchmark with a mean displacement of 8 ms. They found between 76% and 90% of spontaneous boundaries to fall within 20 ms of the manual benchmark with a mean displacement ranging between 8 ms and 20 ms (MacKenzie & Turton Reference MacKenzie and Danielle2020:9). Neither median errors nor 10-millisecond performance metrics were calculated.
Goldman (Reference Goldman2011), in his development of EasyAlign for Praat, tested its accuracy on two fifteen-minute excerpts of spontaneous English and French speech. He compared performance against the alignments of two manual transcribers. For English, 50% and 51% of automatic alignments fell within 10 ms of the standards set by human aligners 1 and 2, respectively; 77% and 75% fell within 20 ms. For French, 49% and 52% of automatic alignments fell within 10 ms of the standards set by human aligners 1 and 2, respectively; 79% and 82% fell within 20 ms.
Wilbanks (Reference Wilbanks2015) built a forced aligner for Spanish (FASE) that attained a 45% agreement rate for the 10-millisecond range and 70% for the 20-millisecond range. The mean difference between FASE and human alignment was 21 ms.
Lastly, Hosom (Reference Hosom2009) developed his own aligner for read-aloud English that is the sole aligner to come close to the standards set by FAVE-Align; namely, 80within 10 ms and 93% within 20 ms of his manual alignments (Hosom Reference Hosom2009:364). Important, however, is that the standards set by FAVE-Align are based on sponta- neous speech whereas Hosom’s (Reference Hosom2009) metrics are from read-aloud speech within the TIMIT corpus.
The trend between read-aloud speech and spontaneous speech is not at all as consistent as one would have thought; in other words, the popular aligners have not always fared better on read-aloud speech. Therefore, we have decided to consolidate both speech registers for the ensuing synopsis on benchmarks: The lower bounds in the literature on automatic alignment for (1) median onset difference from manual alignments, (2) mean onset difference from manual alignments, (3) the percentage of boundaries that fall within 10 ms of the manual alignment, and (4) the percentage of boundaries that fall within 20 ms of the manual alignment are 13 ms, 31 ms, 36%, and 57%, respectively. The upper bounds in the literature are 12 ms, 8 ms, 80%, and 94%, respectively.
2.4.2 Benchmarks for manual alignment
Focusing on the accuracy of automatic aligners can lead one to forget that human alignment can have its share of errors as well. Table 1 contains a schedule of the benchmarks set by the literature on manual alignment. Cosi et al. (Reference Cosi, Falavigna and Omologo1991) compared three manual alignments of spontaneous speech against a fourth ‘gold-standard’ reference. They found mean variation to be 7 ms and that the poorest agreement rate was 88% and the highest agreement rate was 90% when the tolerance range was 20 ms (Cosi et al. Reference Cosi, Falavigna and Omologo1991:694). Hosom (Reference Hosom2009), who tested his own alignments against the TIMIT corpus alignment, had an agreement rate of 82% for a tolerance of 10 ms and 94% for a tolerance of 20 ms. Goldman (Reference Goldman2011) found human-to-human agreement for North American English to be 62% within the 10-millisecond range and 79% within the 20-millisecond range. For French, it was 57% and 81%, respectively. For Spanish, Wilbanks (Reference Wilbanks2015) found human-to-human agreement to be 68% and 79% for the 10- and 20-millisecond thresholds, respectively. The mean difference in boundary placement between the two human aligners was 15 ms.
In summary, the lower bounds in the literature on manual alignment for (1) median onset difference from manual alignments, (2) mean onset difference from manual alignments, (3) the percentage of boundaries that fall within 10 ms of the manual alignment, and (4) the percentage of boundaries that fall within 20 ms of the manual alignment are n/a, 15 ms, 57%, and 79%, respectively. The upper bounds in the literature are n/a, 7 ms, 82%, and 94%, respectively.
Evident here is that the lower bounds certainly exceed those offered by forced-alignment software but that the upper bounds are nearly identical. This is to say that the current technology is relatively mature, which implies that a lot can be gained by expanding it to lesser-studied languages. In the subsequent sections, the procedure for building the aligner will be discussed, and its performance will be assessed according to the minimal and maximal standards established the literature. The minimal standards will be taken from the lower bounds set by the literature on forced alignment (13 ms, 31 ms, 36%, 57%). The maximal standards will be taken from the upper bounds set by the literature on both manual alignments and forced alignment, whichever of the metrics is superior (7 ms, 8 ms, 82%, 94%).
3. The current study
The present study adapted FAVE-Align to Swedish (henceforeth SweFA, the acronym for Forced Alignment of Swedish) and tested SweFA on the speech of nine adult male speakers of Stockholm Swedish. First, the acoustic models in FAVE-Align were relabeled according to their closest corresponding Swedish phoneme. Second, a Swedish pronunciation dictionary was procured and configured to the requirements set by the FAVE-Align and HTK architecture. Third, performance was tested on spontaneous and read-aloud speech from the aforementioned nine speakers. The following three sections outline the procedure in detail.
3.1 Adapting FAVE-Align to Swedish
FAVE-Align has transparent architecture and ample documentation, which makes it particularly handy for adaptation. Although is has been adapted before DiCanio et al. Reference DiCanio, Nam, Whalen, Bunnell, Amith and García2013; Coto-Solano & Solórzano Reference Coto-Solano and Sofía2017; Coto-Solano et al. Reference Coto-Solano, Nicholas and Wray2018), detailed instructions for doing so have never been shared, which has resulted in an unfortunate stream of duplicated and uncoordinated efforts. The first author, who has expertise in Swedish phonetics, therefore scoured the code and identified change spots that would allow the use of the English HTK models for the closest corresponding Swedish phoneme. The second author, a seasoned programmer, proofed these change spots and made the hardcoded changes more pythonic. The original English monophones in FAVE-Align are done in ARPAbet, which is an ASCII-compatible system created by the Advanced Research Projects Agency’s (ARPA) Speech Understanding Project. We created a similar system for Swedish that we refer to here as SweFAbet.
Table 2 provides a list of the Swedish phoneme inventory. The first column contains the SweFAbet monophone, the second column the corresponding IPA symbol, the third column the most common corresponding grapheme, the fourth column a Swedish lexical example (some are loanwords; e.g. cok), the fifth column the closest English phoneme, and the sixth column the ARPAbet monophone for that closest English phoneme.
Table 2. SweFAbet, corresponding IPA, grapheme, Swedish lexical example,Footnote 8 and closest English phoneme with ARPAbet
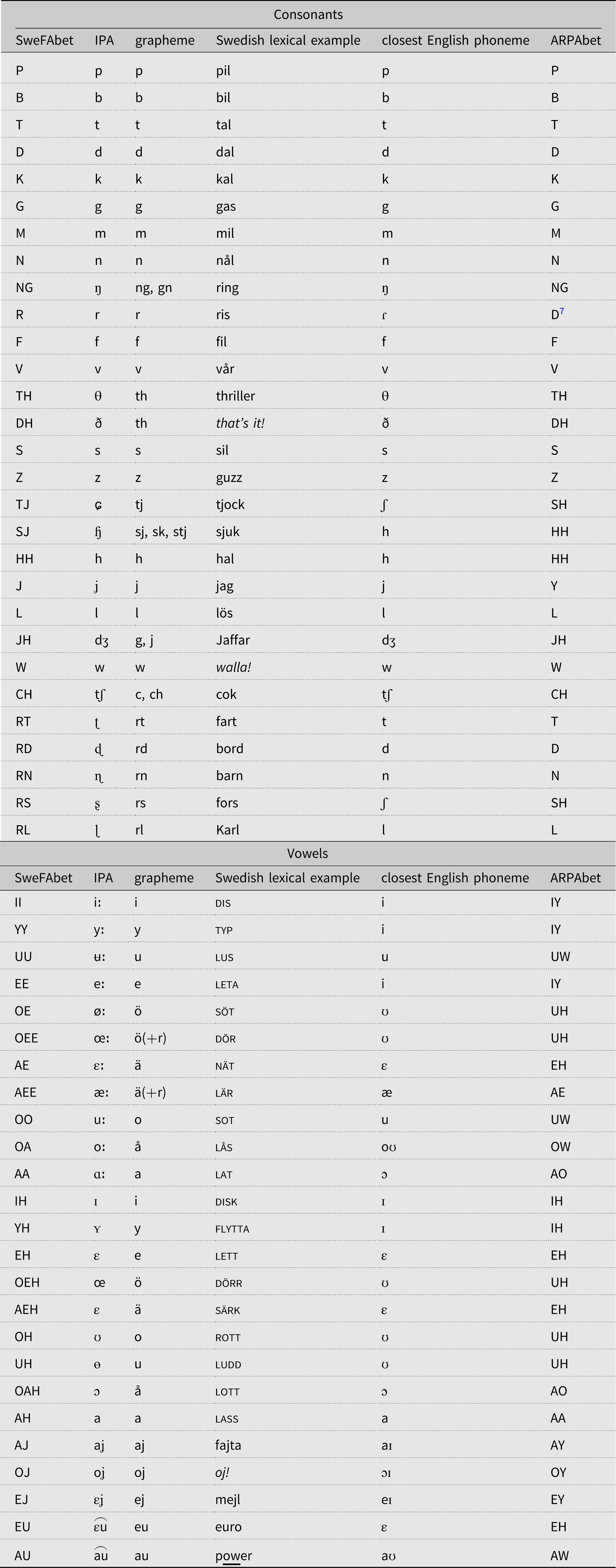
The closest phoneme match was subjectively determined by the first author, and no testing was conducted to assess which phoneme would be more suitable. For example, Central Swedish nät falls between American English trap and dress, so we decided arbitrarily on dress (Arpabet EH). For Central Swedish /ɧ/, there are strong arguments for both selecting American /h/ and /ʃ/, so we decided arbitrarily on /h/. It is because of this process that we have referred to our adaptation as ‘crude’ and ‘rapid’. Testing and optimizing phoneme matches would contradict the original aim of rapid prototype adaptation.
These adaptations are made in just six different locations within the FAVE-Align code. Since one aim of this paper is to be a resource for other researchers who wish to build a similar rapid prototype, detailed instructions on how we did this are provided in the Appendix.
After we programmed these substitutions in, we subsequently also built a prototype for Danish (not discussed in this paper), and the second author built a Unicode-8 converter, an IPA converter, and a language-general shell to host the Danish, English, and Swedish aligners within one program (LG-FAVE; Young & McGarrah Reference Young and Michael2017). The program is free and accessible at https://github.com/mcgarrah/LG-FAVE.
3.2 Procuring and adapting a pronunciation dictionary
The larger project for which this Swedish adaptation was built required a comprehensive dictionary (Young Reference Young2019), and two resources were particularly suitable for adaptation to the FAVE-Align format: Folkets Lexikon and the NTS pronunciation dictionary. These would not have been necessary for an experimental project that used, for example, a limited number of read-aloud sentences (e.g. Chodroff & Wilson Reference Chodroff and Wilson2017). Nonetheless, we have decided to dedicate some space here to the procurement of our dictionary because, as argued in Section 2.3, 75% of the time saved in automatic transcription comes from having a pronunciation dictionary that is both comprehensive and accurate. Furthermore, the NTS pronunciation dictionary is also publicly available for Danish and Eastern Norwegian (‘bokmål’), so our adaptation can serve as a guideline for those who wish to duplicate SweFA for these varieties.
3.2.1 Folkets Lexikon
Many proprietary dictionaries of Swedish are actually interface improvements to Folkets Lexikon (‘The People’s Lexicon’; Kann Reference Kann2010; Kann & Hollman Reference Kann and Joachim2011), a state-funded project that sought to offer the first web-accessible Swedish dictionary. It was first published in 2009 and has undergone successive improvements through 2014.
The first author of this paper wrote a series of regular expressions to transform its XDXF format into the FAVE-compatible format. Although Folkets Lexikon has 200,000 total entries, it only has 18,928 pronunciation entries, which made it insufficient for spontaneous speech recordings.
3.2.2 NTS pronunciation dictionary for Swedish
In 2003, Nordic Language Technology Holdings, Inc. (NTS) filed for bankruptcy, and the Norwegian National Library procured its intellectual property for public dissemination. At the time, NTS was working on Automatic Speech Recognition (ASR) for Danish, Eastern Norwegian (bokmål), and Central Swedish. All three of the NTS pronunciation dictionaries have been released to the public, but their accuracy could not be guaranteed. Whereas Folkets Lexikon is widely accepted as a credible source and has a chain of provenance in terms of its development, NTS is simply a file the first author ‘stumbled across’. We therefore reconciled the NTS entries with Folkets Lexikon. The NTS entries matched all but 609 of the 18,928 Folkets Lexikon entries.
We therefore decided to use the NTS dictionary, converting its original IBM format into the FAVE-compatible format. The resulting product was a pronunciation dictionary with 927,167 entries. We also added approximately 3,000 slang words and programmed in a series of alternate elided pronunciations. Such alternate pronunciations are showcased in Figure 2 with the entry for cirkusartist ‘circus performer’. The final version of the dictionary has just over 16 million pronunciation entries.
3.3 Testing SweFA’s performance
SweFA was tested on the speech of nine adult male speakers of Stockholm Swedish. Three of them speak the received Stockholmian variety, which is closest to what Riad (Reference Riad2014) refers to as Central Swedish (centralsvenska); three speak the traditional working-class variety, sometimes referred to as Södersnack or Ekensnack (Kotsinas Reference Kotsinas and Gertrud1988b); three speak Stockholm’s multiethnolect, sometimes referred to as Rinkeby Swedish or Suburban Swedish (förortssvenska) (Kotsinas Reference Kotsinas, Per, Viveka, Torbjörn and Pettersson1988a; Young Reference Young2018).
The geographic origin of the speakers is plotted on the map in Figure 4. The map includes Stockholm’s metro system because this is the spatial framework to which the city’s residents typically associate its social dialects (Bijvoet & Fraurud Reference Bijvoet and Fraurud2012). One might hear the comment ‘he sounds very blue line’ as a reference to Stockholm’s multiethnolect. Likewise, one might hear ‘that’s so green line’ in reference to the habitus of the white working class. In this study, speakers of the received variety hail from the City Center and affluent suburbs. Speakers of working-class Stockholmian hail from the traditional white working-class strongholds in the Southeast. Speakers of Stockholm’s multiethnolect hail from the multiethnic suburbs in the Northwest and Southwest.
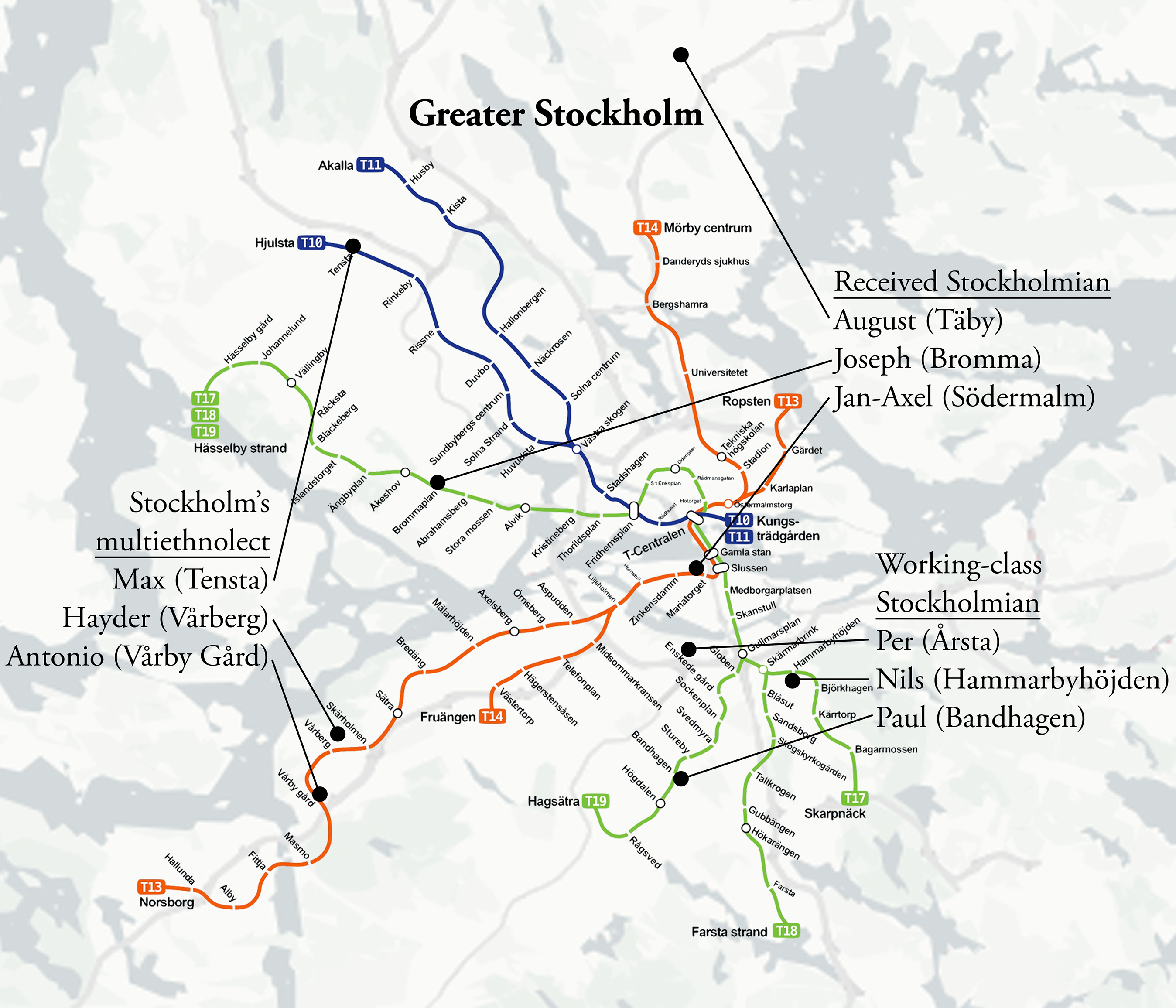
Figure 4. Map of greater Stockholm and its metro. Home neighborhoods of the nine speakers are plotted, and speakers are itemized according to their respective social dialects.
Two speech styles were recorded for each of the nine speakers: spontaneous and reading. Both styles were taken from sociolinguistic interviews conducted by the first author. Criteria for treatment as ‘spontaneous’ were the presence of swearing, channel cues (Labov Reference Labov1972:113) and/or a topic that was engaging for the speaker such as danger of death or supernatural occurrences (Labov Reference Labov1972). The reading task occurred at the end of the interview whereby the participant was asked to read an adaptation of Cirkusen, a speech-pathology diagnostic passage that contains multiple exemplars of every Swedish phoneme and tone accent (Morris Zetterman Reference Morris and Helena2011).
Recordings were made on individual Zoom H1 recorders with self-powered Audio-Technica lavalier microphones in a quiet setting with minimal background noise. They were recorded in wav format, mono, with a sample rate of 16,000 Hz. The speech material was orthographically transcribed by native-language transcribers, financed by a grant from the Sven och Dagmar Salén Foundation. The transcriptions were then checked by the first author and subsequently phonetically time-aligned using SweFA. The first author then manually corrected the segmentations in accordance with standard segmentation protocol and the guidelines provided in Engstrand et al. (Reference Engstrand, Bruce, Elert, Eriksson and Strangert2000). Manual correction of the alignments took an average of 68 seconds per recorded second (something that we discuss in Section 4). Segmental metrics were extracted using a customized adaptation of Brato’s (Reference Brato2015) script for Praat (Boersma & Weenink Reference Boersma and Weenink2017).
For the spontaneous samples, pauses and hesitation markers were removed, and the first 1000 boundaries were measured. For the reading samples, the entire recording was measured after pauses and hesitation markers were removed, resulting in a range between 954 and 1040 boundaries.
4. Results
Table 3 organizes the nine speakers and two speech styles according to the four selected metrics. It also offers the minimal standards taken from the literature on forced alignment and the maximal standards derived from the literature on both forced alignment and manual alignment (reviewed in Section 2.4). The results that exceed the minimal standards are highlighted in light gray. The results that exceed the maximum standards are highlighted in dark gray.
Table 3. (top) Upper and lower performance standards from the literature. (bottom) Performance of SweFA for three male speakers of Stockholm’s three main sociolects each in two speech styles according to four metrics. Results highlighted in light gray exceed the lowest standards in the literature; results highlighted in dark gray exceed the highest standards in the literature
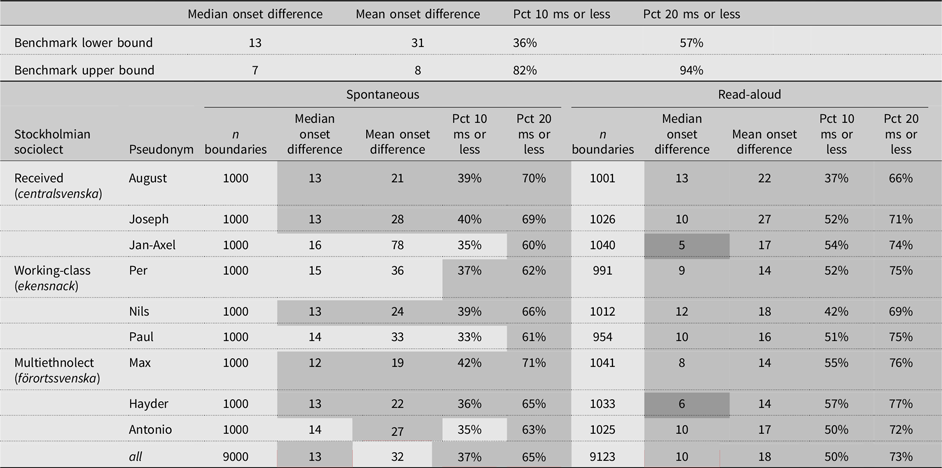
For read-aloud speech, SweFA exceeds the minimal standard across all four metrics for every speaker and variety. It also exceeds the maximal standards for two speakers on the parameters of median onset difference: 5 ms for Jan-Axel and 6 ms for Hayder. For all of the spontaneous speech excerpts, SweFA satisfies at least one minimal benchmark. For five of the eight spontaneous speech excerpts, all minimal benchmarks are satisfied (August, Joseph, Nils, Hayder, Max).
When all speakers were consolidated and assessed as a whole – shown in the bottom row of Table 3 – spontaneous speech exceeded three of the four minimal benchmarks, and read-aloud speech exceeded all four of the minimal benchmarks. For read-aloud speech, median and mean variation from the manual standard was 10 ms and 18 ms, respectively. For the 10- and 20-millisecond tolerance range, 50% and 73% of alignments fell within range, respectively. While spontaneous speech performed less well, it still showed an accuracy level that is competitive with other aligners reported in the literature. Median and mean variation from the manual standard were 13 ms and 32 ms, respectively. For the 10- and 20-millisecond tolerance range, 37% and 65% of alignments fell within range, respectively.
As disclosed in Section 3.3, manual correction of the alignments took us an average of 68 seconds per recorded second. The original orthographic transcriptions had an approximate ratio of 10:1, which meant that the final productivity ratio for human correction was 78:1.
As discussed in the closing of Section 2.2, the present study follows a series of other untrained prototypes for lesser-studied languages, including read-aloud Yoloxóchitl Mixtec (Coto-Solano & Solórzano Reference Coto-Solano and Sofía2017), Cook Islands Maori (Coto-Solano et al. Reference Coto-Solano, Nicholas and Wray2018), and read-aloud and spontaneous Baura, Bora, Even, and Sri Lankan Malay (Strunk et al. Reference Strunk, Schiel, Seifart, Nicoletta, Khalid, Thierry, Hrafn, Bente, Joseph, Asuncion, Jan and Stelios2014). It is not possible to compare the accuracy of SweFA with the adaptations to Bribri and Maori because they used different metrics. DiCanio et al. (Reference DiCanio, Nam, Whalen, Bunnell, Amith and García2013:2239), however, reported 32.3% and 52.3% of their (read-aloud) alignments falling within 10 ms and 20 ms of the manual benchmarks, respectively, in contrast to the 50% and 73% reported here. Strunk et al. (Reference Strunk, Schiel, Seifart, Nicoletta, Khalid, Thierry, Hrafn, Bente, Joseph, Asuncion, Jan and Stelios2014:3944) reported a median variation from the manual standard that ranged between 30 ms (read-aloud Bora) and 160 ms (spontaneous Bora) in contrast to the 10–13 ms reported here. Mean variation from the manual standard fell between 148 ms (read-aloud Bora) and 290 ms (spontaneous Bora) in contrast to the 18–32 ms reported here.
During the peer-review process it was pointed out that it is difficult to decide whether to attribute the success of the aligner to an excellent dictionary or to the typological similarity between Swedish and English. Recall that we reported in Section 3.2.2 that we added a high number of elided pronunciation options, bringing the entry number up from 1 million to 16 million entries (exemplified in Figure 2). To separate these two factors, we conducted a pilot analysis in which we ran the aligner using the ‘unexpanded’ dictionary on the spontaneous speech of August, Paul and Max. We found only marginal differences. Referring back to Table 3, August showed 13 ms, 21 ms, 39% and 70% for median onset difference, mean onset difference, percentage of onsets that fell within 10 ms of the manual benchmark, and percentage of onsets that fell within 20 ms of the manual benchmark, respectively, with the expanded dictionary. With the ‘unexpanded’ dictionary, these figures were 13 ms, 22 ms, 37%, and 68%, respectively. For Paul, the ‘expanded’ metrics in Table 3 were 14 ms, 33 ms, 33%, and 61%, and the ‘unexpanded’ metrics were 16 ms, 35 ms, 32% and 59%, respectively. For Max, the ‘expanded’ metrics in Table 3 were 12 ms, 19 ms, 42%, 71%, and the ‘unexpanded’ metrics were 12 ms, 20 ms, 43%, and 71%. We did not conduct this comparison for all 18 speech samples, but we believe this post hoc analysis buttresses the conclusion that the aligner’s success is mostly due to the typological similarity between English and Swedish.
5. Conclusion
SweFA, our Swedish adaptation of FAVE-Align, aligns the three main varieties of Stockholm Swedish at a competitive level of accuracy according to the minimal benchmarks set by the literature. This is of course important for Swedish phonetics research, but the broader implication is that researchers of other Nordic languages can rapidly adapt a prototype from FAVE-Align and expect a rewarding return on the endeavor. This is especially the case for read-aloud speech, where all nine test samples met all four benchmarks separately and as a whole.
As it pertains to the aligner working better on a particular Stockholmian variety, no significant trend emerged; rather, the variation appears to be idiolectal. For example, the spontaneous speech of Jan-Axel, Paul and Antonio performed similarly according to the 10 ms and 20 ms metrics. While their respective varieties are quite different, all three speakers mumble and have substantial vocal fry in their speech, which may be the reason behind SweFA’s hindered effectiveness.
For researchers who have little interest in chancing their analyses on pure automatic alignment, manually correcting the alignments from an automatic prototype like SweFA can cut time spent by a half. This is to say that even if a study required manual alignments, using our proposed prototype as a starting point would still result in considerable time savings. As we disclosed in Section 2.3, our own manual capacity was 232:1, which meant that manually aligning the current 1,899-second dataset would have taken approximately 122 hours (
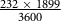 $${{232 \times 1899} \over {3600}}$$
). With SweFA, our manual corrections took 41 hours (
$${{232 \times 1899} \over {3600}}$$
). With SweFA, our manual corrections took 41 hours (
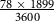 $${{78 \times 1899} \over {3600}}$$
). The actual adaptation of FAVE-Align took about 4 hours, and the base adaptation of the NTS dictionary took another 8 hours. This translates into a time savings of 69 hours for this project.
$${{78 \times 1899} \over {3600}}$$
). The actual adaptation of FAVE-Align took about 4 hours, and the base adaptation of the NTS dictionary took another 8 hours. This translates into a time savings of 69 hours for this project.
A serious hurdle for aligning a lesser-studied language is procuring a sufficiently comprehensive pronunciation dictionary. While such dictionaries also exist for Danish and Eastern Norwegian by means of the NTS archives, they are lacking for other Nordic languages. For those remaining languages, the adaptation proposed here is particularly valuable for laboratory investigations that require a finite number of read-aloud sentences to be aligned (as opposed to open-ended spontaneous speech).
We conclude by proposing that phonetic investigations of the Nordic languages could benefit from ‘untrained’ aligners such as SweFA. Whereas prior untrained models have usually rendered poor results, SweFA’s alignment of Swedish is as accurate as many custom-trained aligners of English. The implication here is of course that FAVE-Align is more easily adaptable to a language typologically closer to English than, for example, Finnish or Sami. Footnote 9 As we indicated earlier in the paper, Swedish has become somewhat underrepresented in the contemporary Phonetics literature. This is similarly the case for Danish and Eastern Norwegian, and of course the many other understudied Nordic varieties like Estonian Swedish, Faroese, Fenno-Swedish, Icelandic, the Northern and Western Norwegian dialects, and Övdalian. Our hope is that phoneticians can use our template to reduce the resource intensity of their future research endeavors.
Appendix. Detailed instructions for Adapting FAVE-Align to Swedish
The most recent version of FAVE-Align is downloadable from https://github.com/JoFrhwld/FAVE. Similarly, instructions on how to use it and how/where to download HTK and SoX are at https://github.com/JoFrhwld/FAVE/wiki/FAVE-align.
FAVE-Align was built using Python. Before any of the below steps are initiated, be sure that you have installed FAVE-Align properly and that you have executed it successfully for English. That way, if you encounter any problems in the below steps, you know it is because of your changes and not because of some other pre-existing bug.
Before adapting the software, the monophones that your language will use need to be defined and coded with ASCII characters. The ASCII requirement cannot be changed in FAVE-Align because the limitations are set by HTK, which is proprietary and encrypted. The closest corresponding American-English sound should be mapped to it as is shown for SweFAbet in Table 2. This mapping should be done subjectively and to the best of your knowledge about the language of study. (Fortunately, FAVE is quite forgiving.) Your pronunciation dictionary must use these same monophones.
In order to repurpose the English acoustic models over to the SweFAbet inventory, six files within the Folder entitled FAVE-align must be altered:
-
1. /FAVE-align/FAAValign.py
-
2. /FAVE-align/model/monophones
-
3. /FAVE-align/model/16000/hmmdefs
-
4. /FAVE-align/model/8000/hmmdefs
-
5. /FAVE-align/model/11025/hmmdefs
-
6. /FAVE-align/model/dict
Step 1: Adapt /FAVE-align/FAAValign.py
Figure A1 shows the English monophones on lines 97 and 98 of the original FAAValign.py script.

Figure A1. Section of FAVE’s Python code that defines monophones.
The English monophones on lines 97 and 98 need to be replaced with the monophones of the new language. The new monophones must be ASCII-compatible. Most of the monophones are phonemes, but some are allophones and diphthongs (like AJ or OJ). The new SweFAbet monophones are entered into lines 97 and 98 in Figure A2.

Figure A2. Section of SweFA’s Python code that defines monophones.
FAVE-Align measures stress on the vowel of each syllable, and this is coded with a 1 for primary stress, a 0 for no stress, and a 2 for secondary stress. Swedish, however, is a pitch-accent language (see Riad Reference Riad2014), so Accent 1 is denoted with a 1 on the vowel, Accent 2 is denoted with a 3 on the vowel, secondary stress is denoted with a 2 on the vowel, and lack of stress is denoted with a 0 on the vowel.
Line 468 should be changed such that it can accommodate monophones longer than three ASCII characters as well as the additional stress codings 0, 1, 2, and 3. This is shown in Figure A3. Line 500 needs a small change as well, shown in Figure A4.

Figure A3. Section of SweFA’s Python code that defines monophone string length and stress numbering.

Figure A4. Additional section of SweFA’s Python code that defines monophone string length.
Even though FAVE-Align is restricted to ASCII, its script has a number of sophisticated protections built to keep things running even if there are non-ASCII characters in the transcription that would otherwise upset the program. These ‘fixes’, so to speak, begin on line 510, shown in the upper half of Figure A5. As line 513 indicates, this only works for transcriptions in Unicode 8 (UTF-8). The regular expressions from lines 517 to 520 turn the four most common rich-text single quotes into an ASCII single quote. The regular expressions from lines 521 to 524 turn the four most common rich-text double quotes into an ASCII double quote.
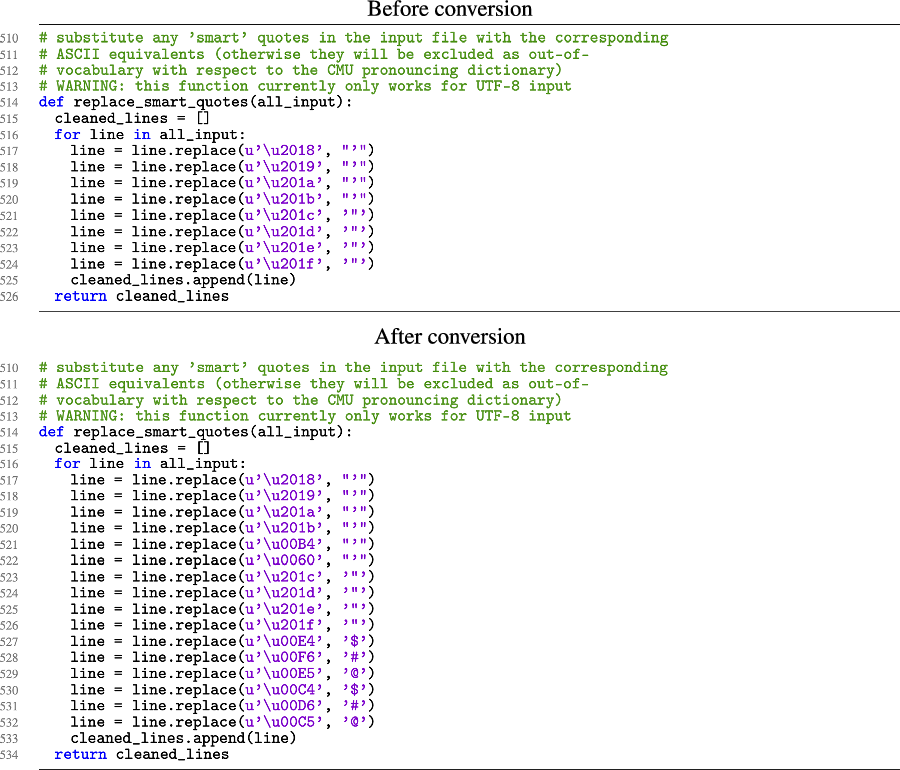
Figure A5. Section of FAVE’s Python code that converts potential UTF-8 characters in the transcription into ASCII.
Since the Swedish keyboard has two other types of double quotes, these were added to lines 525 and 526, shown in the lower half of Figure A5. Since the Swedish characters Ä, ä, Ö, ö, Å, å are not ASCII-compatible, we selected $, $, #, #, @, and @, respectively, as shown on lines 527 to 532. Crucially, these were then also substituted into the pronunciation dictionary.
Step 2: Adapt /FAVE-align/model/monophones
This file contains a simple list of all of the monophones. Note, however, that the vowels must be listed with all possible numerical stress markings. In the case of the SweFA adaptation, this means 0 through 3.
Step 3: Adapt /FAVE-align/model/16000/hmmdefs
The hidden Markov vectors for each monophone-including-stress is defined in the hmmdefs files. Figure A6 shows a snapshot of the vectors for the monophone UH0 for a 16,000 Hz sound file (/FAVE-align/model/16000/hmmdefs). The monophone is defined in the quotes that follow h. The Swedish monophones were substituted in for the closest-sounding English monophone, as shown in Figure A7. Since there are more Swedish monophones than English ones, many of the vectors were duplicated. For example, since only three vectors exist for UH (UH0, UH1, and UH2), UH1 was duplicated and then one duplicate was changed to OEH1 and the other to OEH3. UH0 became OEH0, and UH2 became OEH2.
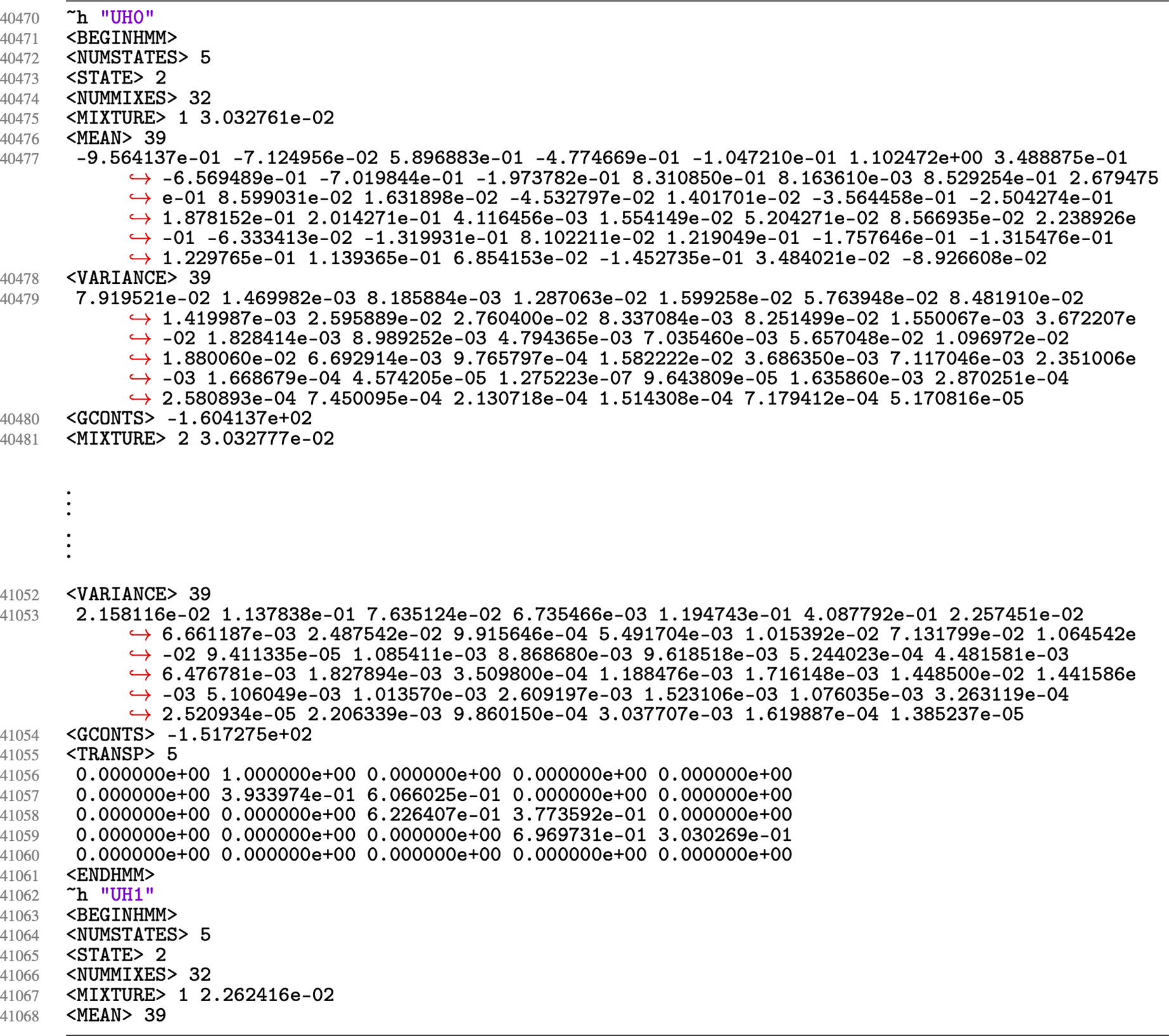
Figure A6. Excerpt from lines 40470 to 41068 of the hidden Markov model vectors for the monophone UH in unstressed position (indicated by ~h “UH0”).

Figure A7. Converting the FAVE-Align vectors for UH to SweFA’s OEH. First UH1 and UH2 are duplicated, then the names are changed.
Steps 4 and 5: Adapt /FAVE-align/model/8000/hmmdefs and /FAVE-align/model/11025/hmmdefs
These are done exactly the same way as Step 3.
Step 6: Adapt /FAVE-align/model/dict
This file is the pronunciation dictionary. All entries must be in ASCII and sit on a separate line. In the case of Swedish, this meant substituting $, $, #, #, @, @ for Ä, ä, Ö, ö, Å, and å, respectively. A space should separate the entry from its pronunciation, and a space must separate every monophone in the pronunciation entry. Figure A8 shows an example.

Figure A8. Dictionary format for /FAVE-align/model/dict. Every entry requires its own line, the entry must be in ASCII, and the entry is separated from its pronunciation by a single space. Subsequent spaces separate monophones.















 Open access
Open access