
Abstract
To identify potential mediating effects, researchers applying partial least squares structural equation modeling (PLS-SEM) typically contrast specific indirect and direct effects in a sequence of steps. Extending this standard procedure, we conceive mediation analysis as a type of model comparison, which facilitates quantifying the degree of the model effects’ uncertainty induced by the introduction of the mediator. By introducing a new dimension of quality assessment, the procedure offers a new means for deciding whether or not to introduce a mediator in a PLS path model, and improves the replicability of research results.
Similar content being viewed by others
Introduction
Researchers applying partial least squares (PLS), a composite-based approach to structural equation modeling (SEM), frequently consider mediating effects in their model design and estimation (e.g., Ghasemy et al. 2020; Guenther et al. 2023; Magno et al. 2022). Mediating effects assume a sequence of relationships in which an antecedent construct impacts a mediating construct which, in turn, influences a dependent construct. Examining such sequences of relationships enables substantiating the mechanisms that underlie the assumed cause-effect relationships in the path model (Nitzl et al. 2016). As a recent example, Menidjel et al. (2023) analyze the impact of costumers’ variety-seeking behavior on their service switching intention, finding that the positive effect is mediated by customer engagement.
To analyze mediating effects, researchers using PLS-SEM typically rely on Zhao et al.’s (2010) procedure, which involves contrasting indirect and direct effects in a sequence of steps to identify the existence and, if applicable, the type of the mediating effect. Several tutorial articles (e.g., Cheah et al. 2021; Nitzl et al. 2016; Sarstedt et al. 2020) and textbooks (e.g., Hair et al. 2022; Ramayah et al. 2018) document this procedure, which has become a standard in the field.
While Zhao et al.’s (2010) procedure proves useful for identifying and characterizing mediating effects, it does not offer any evidence whether the inclusion of the mediator improves the model’s quality in the first place. To answer this question, researchers in other fields have conceived mediation analysis as a type of model comparison (e.g., Ariyo et al. 2022; Crouse et al. 2022; Wiedermann & von Eye 2015) in which they compare one or more configurations of the mediation model with the more parsimonious baseline model that excludes the mediator. To do so, researchers revert to a rich array of information-theoretic model selection criteria (Lin et al. 2017) such as Akaike’s Information Criterion (AIC; Akaike 1973), which have become standard metrics in multivariate statistics. However, prior studies have pointed out that the decision for a specific model on the grounds of such criteria may yield false confidence in the results as models in the candidate set can at best be considered approximations of the data-generating process (e.g., Wagenmakers & Farrell 2004). Any model selection task comes with ambiguities in the design of the candidate set and the selection process, giving rise to model selection uncertainty (Preacher & Merkle 2012).
Addressing this concern, Rigdon et al. (2023) recently introduced a procedure to quantify this model selection uncertainty. Drawing on Akaike weights—metrics that normalize the information-theoretic model selection criteria’s values to approximate a model's posterior probability given the data (Burnham & Anderson 2002, 2004)—their procedure combines model-specific bootstrap samples to derive confidence intervals for model parameters that not only reflect sampling variance, but also the uncertainty induced by the model selection process. Researchers can draw on this approach to ascertain whether the consideration of different model configurations has the potential to decrease or bears the risk of increasing uncertainty in model estimates. Rigdon et al. (2023) evaluate and showcase their approach in standard model comparison settings where researchers explicitly hypothesize different model configurations. However, the approach’s relevance extends beyond such standard model comparisons—which researchers rarely document in their published research anyway—to much more visible modeling practices such as mediation. In addition, while Rigdon et al. (2023) introduced their approach in the context of factor-based SEM, the model selection procedure used as basis for quantifying uncertainty generalizes to composite-based methods such as PLS-SEM (e.g., Danks et al. 2020; Sharma et al. 2019, 2021).
Based on this notion and extending on Rigdon et al. (2023), this study uses a combination of Akaike weights and bootstrapping to quantify the uncertainty in parameter estimates induced by the inclusion of a mediator. The uncertainty perspective adds a new and important dimension to the evaluation of mediation models in that it offers support for the effects’ generalizability—or evidence against it (Rigdon et al. 2020, 2022). As such, the procedure may guide the decision whether or not to include a mediator in a PLS path model in situations where theory offers conflicting evidence in this regard. We document the procedure by extending a well-known model on the effects of corporate reputation (Eberl 2010), test different mediating relationships via a newly-introduced construct, and assess the effects on the uncertainty of model estimates.
Our results suggest that the inclusion of the mediator leads to a substantial decrease in the uncertainty in the corporate reputation model estimates, thereby increasing confidence in the effects. As such, our paper makes two important contributions to the literature. First, by showing how to quantify the uncertainty in applications of mediation analysis, we give PLS-SEM researchers a new tool at hand to improve the rigor of their analyses. Rather than restricting their mediation analyses to the comparison of direct and indirect effects, researchers can now draw on an uncertainty-centric approach to offer support for their inclusion of a mediator—or evidence that speaks against this step. Second, by analyzing an extended version of Eberl’s (2010) corporate reputation model, we address previous calls to consider additional mediators to clarify the mechanism through which reputation’s affective dimension impacts customer satisfaction and loyalty.
Uncertainty in comparisons of mediation models
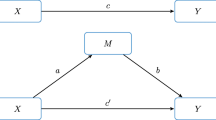
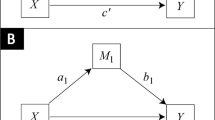
When estimating mediating effects in PLS path models, researchers typically draw on Zhao et al. (2010). Introduced as a response to conceptual concerns regarding Barron and Kenny’s (1986) approach, Zhao et al.’s (2010) procedure involves first assessing whether the indirect effect via a mediator is significant, followed by the assessment of the direct effect between the antecedent and target constructs (Nitzl et al. 2016). Depending on whether only the indirect or also the direct effect is significant, the authors distinguish between full mediation and partial mediation, the latter of which can be further differentiated into complementary and competitive mediation. A partial mediation indicates that the mediator does not account for the entire effect of the antecedent on the target construct, suggesting that other mediators may be missing in the model. Finally, if the indirect effect is not significant, there is no mediation.
While the contrasting of direct and indirect effects proves useful for identifying whether mediation is present and, if applicable, classifying the mediation type, the application of Zhao et al.’s (2010) procedure rests on the implicit assumption that the parameter estimates’ variance can be entirely attributed to random sampling variance—provided that the mediation model is correct in the population (Cohen et al. 2003). While this assumption may be tenable in a stand-alone analysis of a mediation model, this is not the case when conceiving the mediation analysis as a model selection task where researchers compare models with and without the mediator or different types of mediating effects (e.g., simple mediation vs. serial mediation)—see, for example, Ariyo et al. (2022), Crouse et al. (2022), and Wiedermann and von Eye (2015). In this case, the models may at best be nested, but they cannot be strictly correct at the same time. Rigdon et al. (2023) argue that the violation of this assumption introduces biases in model evaluation metrics such as standard errors in that they do not fully reflect the uncertainty that comes with the model selection task.
To measure the variance in parameter estimates that can be attributed to the uncertainty of the model selection process (Preacher & Merkle 2012), Rigdon et al. (2023) suggest a four-step procedure that draws on information-theoretic model selection criteria and bootstrapping to compute uncertainty-adjusted confidence intervals of model parameters across the candidate models. Information-theoretic model selection criteria seek to strike a balance between model fit and complexity in that they identify a model that generalizes beyond the particular sample. One of the first information-theoretic model selection criteria to be proposed was the AIC (Akaike 1973), which seeks to quantify the distance between a candidate model and the (unknown) true model. One of the most prominent alternatives to the AIC is Schwarz’s (1978) Bayesian Information Criterion (BIC), which provides an estimate of the posterior probability of a model being correct. Researchers have proposed a variety of model selection criteria designed for different data constellations (small sample sizes; Hurvich and Tsai 1989) and analysis tasks (e.g., mixture regression models; Naik et al. 2007). Sharma et al. (2019, 2021) have compared the relative efficacy of various criteria in the context of PLS-SEM on the grounds of large-scale simulation studies and found that the BIC is superior in that it selects the model with (1) the highest fit among a set of candidate models that (2) also performs well in terms of out-of-sample prediction. Researchers wanting to compare different PLS path models would compute model-specific BIC values for a specific key target construct and select the model that minimizes the metric’s value.
While the BIC enables researchers to rank their models, the criterion does not actually measure the relative weights of evidence in favor of each candidate model. This drawback is especially important when BIC values differ only marginally for competing models—as it is typically the case in empirical applications (Preacher & Merkle 2012). To address this issue, researchers can compute Akaike weights (Akaike 1983) using the BIC values for each candidate model as input. Akaike weights reflect each model’s relative strength of evidence as compared to the other competing models. Considering different values BICi for m candidate models (i = 1 to m), Akaike weights can be computed as follows (Danks et al. 2020):
-
(1)
compute Δi = BICi – min(BIC);
-
(2)
compute the relative likelihood of each candidate: L(mi) = exp (−1/2·Δi);
-
(3)
transform the relative likelihoods into weights: wi = L(mi) / Σi L(mi).
Rigdon et al. (2023) use these Akaike weights to initialize the bootstrapping procedure, as commonly used for inference testing in applications of PLS-SEM (Sarstedt et al. 2022). Bootstrapping involves drawing a large number of samples from the original dataset with replacement, and generating an empirical distribution for the parameter estimates, thus enabling researchers to calculate the variance that incorporates both, random sampling variance and model selection uncertainty. To capture the uncertainty associated with estimating a given parameter across several competing models, Rigdon et al. (2023) propose the following procedure:
-
(1)
Calculate Akaike weight wi for each candidate model mi using the BICi values as input (Sharma et al. 2019, 2021).
-
(2)
Settle on a total number of bootstrap samples R and, for each candidate model mi: (a) draw Ri = R· wi bootstrap samples; (b) estimate the parameter for each bootstrap sample; (c) calculate the 95% confidence interval using the percentile method (Aguirre-Urreta & Rönkkö, 2018). The model estimation should consider at least R=10,000 bootstrap samples (Streukens & Leroi-Werelds 2016).Footnote 1
-
(3)
Combine the Ri estimates of the parameter from each model mi into a single set of R estimates, and calculate an overall 95% uncertainty interval for the parameter estimate across all candidate models.
-
(4)
Compare the overall uncertainty interval with the confidence intervals from each model mi.
The uncertainty interval computed following this procedure captures both model selection uncertainty and random sampling variance. A wider confidence interval as compared to the individual models’ intervals indicates uncertainty associated with the model selection.
Drawing on this procedure, researchers can establish different models with and without the mediator (potentially considering different types of mediations), compute BIC-based Akaike weights for each model, and contrast the effects’ confidence intervals in individual models with the uncertainty interval derived for the overall candidate model set. In doing so, researchers should focus on the total and direct effects of the antecedent construct on the target construct via the mediator. A wider uncertainty interval would indicate that the introduction of the mediator introduces additional uncertainty, suggesting that the mediating effect is more difficult to replicate (Rigdon et al. 2023). On the contrary, a smaller uncertainty interval suggests that the inclusion of the mediator reduced the uncertainty, which increases confidence in the effects’ stability in future investigations (e.g., Rigdon et al. 2020).
Illustrative example
Our illustration of the approach draws on an extended version of Eberl’s (2010) model on the antecedents and consequences of corporate reputation. The model has frequently been used to showcase extensions of the PLS-SEM method, for example in the context of higher-order modeling (Sarstedt et al. 2019), necessary condition analysis (Hair et al. 2024; Chapter 4), and latent class analysis (Matthews et al. 2016). The original model considers the effects of corporate reputation—operationalized by a cognitive dimension (competence) and an affective dimension (likeability)—on customer satisfaction and loyalty (Fig. 1). Albeit of secondary concern for our study, the model also considers four drivers of corporate reputation: attractiveness, corporate social responsibility, performance, and quality. Hair et al. (2022; Chapter 7) use this model to explore the mediating role of customer satisfaction, showing that this construct partially mediates the effect of likeability on customer loyalty. This result suggests that there may be a missing mediator in this relationship that the direct effect of likeability on loyalty absorbs (Fig. 1).

Corporate reputation model
Sarstedt et al. (2023) recently presented a data article, which considers trust as one potential mediator in the relationships between likeability, satisfaction, and customer loyalty. Following this notion, we test different configurations of the extended reputation model with (1) trust as a potential mediator in the relationship between likeability and customer satisfaction, (2) trust as a potential mediator in the relationship between likeability and customer loyalty, and (3) trust as a serial mediator in the relationship between likeability and customer loyalty via customer satisfaction (Fig. 2). Our analysis draws on Sarstedt et al.’s (2023) dataset of n = 308 responses from German consumers. We use the SmartPLS 4 software (Ringle et al. 2022) to estimate the models.

Alternative models
Before comparing the models, we assess the measurement models following standard procedures (e.g., Hair et al. 2019, 2020, 2022). In the following, we focus our results reporting on Model #1.Footnote 2 We find that all measures are reliable, as evidenced by, for example, RhoA values well above 0.7. Similarly, all indicator loadings are high, yielding average variance extracted values larger than 0.5, thereby providing support for the measures’ convergent validity. Computing the 90% bootstrap-based confidence intervals (percentile method, 10,0000 subsamples) shows that all HTMT values (Henseler et al. 2015) are significantly lower than 0.85, which supports discriminant validity (Franke & Sarstedt 2019) (Table 1).Footnote 3
Having established the measures’ reliability and validity, we run a mediation analysis, following the procedure outlined in Zhao et al. (2010)—see also Nitzl et al. (2016). The results from bootstrapping show that all direct and serial mediating effects in Models 1—3 via trust are significant (p < 0.05). Since the direct effects of likeability on customer satisfaction and loyalty are also significant, the mediations are partial in nature.
In the next step, we focus on the model comparison on the ground of the BIC values of the models’ target construct customer loyalty. We find that Model 2 produces the lowest BIC value (−288.034), closely followed by Model 3 (−288), and Model 1 (−286.211). Compared to the original model (−286.138), all three mediation models have lower BIC values, thereby supporting the consideration of trust as a mediator (Table 2).
While the absolute differences in BIC values for the candidate models are not pronounced, using these values as input for computing Akaike weights produces more nuanced differences. Models 2 and 3 have similar weights of w2 = 0.419 and w3 = 0.412, respectively, Model 1 has a much lower weight of w1 = 0.169 (Table 2).
Next, we run bootstrapping for each model with the number of samples (10,000) weighted by wi and use the combined bootstrap samples to construct combined confidence intervals. More precisely, we combined the 1685 parameter estimates resulting from bootstrapping Model #1 with the 4193 and 4122 parameter estimates from bootstrapping Models #2 and #3. Using the combined 10,000 parameter estimates, we computed 95% percentile confidence intervals for all effects related to the likeability construct. Table 3 shows the estimates for the original model, the three candidate models, and the combined effects, resulting from the consolidation of the model-specific bootstrap estimates.Footnote 4
Focusing on the total effect of likeability on customer loyalty, we find that the widths of the confidence intervals in the three candidate models are highly stable, varying between 0.190 (Model 3) and 0.192 (Models 1 and 2). These values compare well with the original model where the width of the total effect’s confidence interval is 0.195. On the contrary, the combined confidence interval, expressing the uncertainty induced by the model selection task, is much narrower (0.167), which is 12.72% less than the average interval produced by Models 1–3 and 14.36% less than the original model’s interval.
The very same holds for the direct effect of likeability on customer loyalty. The widths of the confidence intervals of the three candidate models vary around 0.2, which compares well with the original model (0.196). On the contrary, the combined interval that also considers uncertainty is much narrower (0.179).
These results suggest that the different specifications of the mediator models led to a substantial decrease in uncertainty in the total and direct effects of likeability on customer loyalty. Hence, researchers can expect this effect to be more stable in future applications of the model. The additional insights generated by the uncertainty analysis speaks in favor of the inclusion of trust as a mediator—despite the marginal differences in BIC values compared to the original model without the mediator.
Discussion
Every step along the research process has the potential to contribute to the findings’ uncertainty. Researchers make countless decisions when working with theoretical frameworks, designing models, selecting measures, and collecting data—to name a few. The uncertainty introduced by such decisions may increase the variability of results, which goes well beyond mere sampling variance. Rigdon et al. (2020) argue that researchers’ disregard of uncertainty is to blame for much of the replication crisis that occupies behavioral research today. While Open Science initiatives like preregistrations, open data, and checklists (e.g., Simmons et al. 2021) may help to control for components of uncertainty, researchers need to proactively quantify uncertainty in order to successfully channel it (Rigdon & Sarstedt 2022).
This study makes one step into this direction by showcasing how to quantify uncertainty in PLS-SEM-based mediation analyses. In line with prior research (e.g., Ariyo et al. 2022; Crouse et al. 2022; Wiedermann & von Eye 2015), we conceive mediation analyses as a form of model selection, which makes them amendable to uncertainty analyses, as documented by Rigdon et al. (2023). Applying the procedure to an extended version of Eberl’s (2010) well-known corporate reputation model shows that the consideration of an additional mediator leads to a substantial decrease in uncertainty in the associated total and direct effects. These results thereby offer support for the inclusion of the mediator.
The procedure extends standard mediation analyses, which are restricted to the contrasting of direct and indirect effects, with little support whether the inclusion of the mediator adds to the model’s quality in the first place. Comparing the various models offers a basis for deriving an uncertainty interval for the mediating effects, which can readily be compared with the confidence intervals derived in each of the candidate models. This uncertainty perspective explicitly acknowledges the approximative character of model comparison tasks—models should be seen as approximations of the data-generating process, rather than strictly “correct” or “wrong” (Burnham & Anderson 2002; Sweeten 2020). Or as Cudeck and Henly (1991, p. 512) note: “Yet no model is completely faithful to the behavior under study. Models usually are formalizations of processes that are extremely complex. It is a mistake to ignore either their limitations or their artificiality. The best one can hope for is that some aspect of a model may be useful for description, prediction, or synthesis. The extent to which this is ultimately successful, more often than one might wish, is a matter of judgment.” The procedure seeks to grasp and quantify this fuzziness in the context of mediation analyses. In doing so, the procedure is very versatile in that it (1) allows for the inclusion of different types of mediating relationships (e.g., simple and serial mediations) and multiple mediators, and (2) is not restricted to PLS, but extends to other composite-based SEM methods like generalized structured component analysis (Hwang & Takane 2004) and its extensions (Hwang et al. 2021; see also Hwang et al. 2023).
Our empirical application showcases the usefulness of our approach in the context of Eberl’s (2010) widely-known corporate reputation model. The fact that the trust mediator reduces uncertainty in the likeability-related model estimates informs researchers and practitioners about its relevance for the model, thereby offering support for the construct’s inclusion. The results thereby suggest that efforts to improve corporate reputation’s likeability dimension—being the primary driver of customer satisfaction and loyalty—should also consider the trust-inducing effects of corresponding marketing activities. As such, our approach motivates a more holistic thinking and interpretation of the cause-effect relationships in nomological networks such as the corporate reputation model.
Our analysis considered the BIC as the primary information-theoretic model selection criterion in PLS-SEM that achieves a sound tradeoff between model fit and predictive power (Sharma et al. 2019, 2021). Researchers could, however, also focus on the mediator’s predictive contribution to decide whether or not to include it in the model (Danks 2021). Following this logic, researchers would focus on the increase in the model’s predictive accuracy due to the addition of the mediator as a decision rule rather than BIC values. Future research should therefore identify means to substitute Akaike weights in a purely prediction-oriented mediation framework (e.g., Chin et al. 2020; Hair & Sarstedt 2021; Sharma et al. 2022). Further research should also seek ways to quantify the change in uncertainty in all relationships involved in the mediation simultaneously, for example, by bootstrapping model fit measures such as the SRMR (Schuberth et al. 2022). Such improvements would further increase the rigor of mediation analyses, model comparisons, and model evaluation per se in a PLS-SEM framework.
Data availability
The dataset is available open access via Sarstedt et al.'s (2023) data article at: https://www.sciencedirect.com/science/article/pii/S235234092300197X.
Notes
See Chapter 5 in Hair et al. (2022) for further details on the algorithm settings and discussions of methods for constructing confidence intervals.
The measurement model evaluations of Models #2 and #3 produce results which differ only marginally for the corresponding construct measures.
Our analysis draws on the extended HTMT criterion (i.e., HTMT + ; Ringle et al. 2023).
Standard PLS-SEM software programs such as SmartPLS 4 (Ringle et al. 2022) allow for exporting the bootstrapping estimates. Hence, users can combine the bootstrapping estimates and compute confidence intervals using widely available software such as Microsoft Office Excel.
References
Aguirre-Urreta, M.I., and M. Rönkkö. 2018. Statistical inference with PLSc using bootstrap confidence intervals. MIS Quarterly 42 (3): 1001–1020. https://doi.org/10.25300/MISQ/2018/13587.
Akaike, H. 1973. Information theory and an extension of the maximum likelihood principle. In Selected Papers of Hirotugu Akaike, ed. B.N. Petrov and F.C.S. Ki, 199–213. New York: Springer.
Akaike, H. 1983. Information measures and model selection. International Statistical Institute 44: 277–291.
Ariyo, O., E. Lesaffre, G. Verbeke, M. Huisman, M. Heymans, and J. Twisk. 2022. Bayesian model selection for multilevel mediation models. Statistica Neerlandica 76 (2): 219–235. https://doi.org/10.1111/stan.12256.
Baron, R.M., and D.A. Kenny. 1986. The moderator-mediator variable distinction in social psychological research: Conceptual, strategic and statistical considerations. Journal of Personality and Social Psychology 51 (6): 1173–1182. https://doi.org/10.1037//0022-3514.51.6.1173.
Burnham, K.P., and D.R. Anderson. 2002. Model Selection and Multimodel Inference, 2nd ed. New York: Springer-Verlag.
Burnham, K.P., and D.R. Anderson. 2004. Multimodel inference: Understanding AIC and BIC in model selection. Sociological Research Methods 33 (2): 261–304. https://doi.org/10.1177/0049124104268644.
Cheah, J.H., C. Nitzl, J.L. Roldan, G. Cepeda-Carrion, and S.P. Gudergan. 2021. A primer on the conditional mediation analysis in PLS-SEM. ACM SIGMIS Database: the DATABASE for Advances in Information Systems 52 (SI): 43–100. https://doi.org/10.1145/3505639.3505645.
Chin, W., J.H. Cheah, Y. Liu, H. Ting, X.J. Lim, and T.H. Cham. 2020. Demystifying the role of causal-predictive modeling using partial least squares structural equation modeling in information systems research. Industrial Management & Data Systems 120 (12): 2161–2209. https://doi.org/10.1108/IMDS-10-2019-0529.
Cohen, J., P. Cohen, S.G. West, and L.S. Aiken. 2003. Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences, 3rd ed. Mahwah: LEA.
Crouse, W.L., G.R. Keele, M.S. Gastonguay, G.A. Churchill, and W. Valdar. 2022. A Bayesian model selection approach to mediation analysis. PLoS Genetics 18 (5): e1010184. https://doi.org/10.1371/journal.pgen.1010184.
Cudeck, R., and S.J. Henly. 1991. Model selection in covariance structures analysis and the ‘problem’ of sample size: A clarification. Psychological Bulletin 109 (3): 512–519. https://doi.org/10.1037/0033-2909.109.3.512.
Danks, N.P. 2021. The piggy in the middle: The role of mediators in PLS-SEM-based prediction: A research note. ACM SIGMIS Database: the DATABASE for Advances in Information Systems 52 (SI): 24–42. https://doi.org/10.1145/3505639.3505644.
Danks, N.P., P.N. Sharma, and M. Sarstedt. 2020. Model selection uncertainty and multimodel inference in partial least squares structural equation modeling (PLS-SEM). Journal of Business Research 113: 13–24. https://doi.org/10.1016/j.jbusres.2020.03.019.
Eberl, M. 2010. An application of PLS in multi-group analysis: The need for differentiated corporate-level marketing in the mobile communications industry. In Handbook of Partial Least Squares: Concepts, Methods and Applications in Marketing and Related Fields, vol. II, ed. V. Esposito Vinzi, W.W. Chin, J. Henseler, and H. Wang, 487–514. Berlin: Springer.
Franke, G., and M. Sarstedt. 2019. Heuristics versus statistics in discriminant validity testing: A comparison of four procedures. Internet Research. 29 (3): 430–447. https://doi.org/10.1108/IntR-12-2017-0515.
Ghasemy, M., V. Teeroovengadum, J.M. Becker, and C.M. Ringle. 2020. This fast car can move faster: A review of PLS-SEM application in higher education research. Higher Education 80 (6): 1121–1152. https://doi.org/10.1007/s10734-020-00534-1.
Guenther, P., M. Guenther, C.M. Ringle, G. Zaefarian, and S. Cartwright. 2023. Improving PLS-SEM use for business marketing research. Industrial Marketing Management 111 (May): 127–142. https://doi.org/10.1016/j.indmarman.2023.03.010.
Hair, J.F., and M. Sarstedt. 2021. Explanation plus prediction—The logical focus of project management research. Project Management Journal 52 (4): 319–322. https://doi.org/10.1177/8756972821999945.
Hair, J.F., J.J. Risher, M. Sarstedt, and C.M. Ringle. 2019. When to use and how to report the results of PLS-SEM. European Business Review 31 (1): 2–24. https://doi.org/10.1108/EBR-11-2018-0203.
Hair, J.F., M.C. Howard, and C. Nitzl. 2020. Assessing measurement model quality in PLS-SEM using confirmatory composite analysis. Journal of Business Research 109: 101–110. https://doi.org/10.1016/j.jbusres.2019.11.069.
Hair, J.F., T. Hult, C.M. Ringle, and M. Sarstedt. 2022. A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM), 3rd ed. Thousand Oaks: Sage.
Hair, J.F., M. Sarstedt, C.M. Ringle, and S.P. Gudergan. 2024. Advanced Issues in Partial Least Squares Structural Equation Modeling (PLS-SEM), 2nd ed. Thousand Oaks: Sage.
Henseler, J., C.M. Ringle, and M. Sarstedt. 2015. A new criterion for assessing discriminant validity in variance-based structural equation modeling. Journal of the Academy of Marketing Science 43 (1): 115–135. https://doi.org/10.1007/s11747-014-0403-8.
Hurvich, C.M., and C.L. Tsai. 1989. Regression and time series model selection in small samples. Biometrika 76 (2): 297–307. https://doi.org/10.1093/biomet/76.2.297.
Hwang, H., G. Cho, K. Jung, C.F. Falk, J.K. Flake, M.J. Jin, and S.H. Lee. 2021. An approach to structural equation modeling with both factors and components: Integrated generalized structured component analysis. Psychological Methods 26 (3): 273–294. https://doi.org/10.1037/met0000336.
Hwang, H., M. Sarstedt, G. Cho, H. Choo, and C.M. Ringle. 2023. A primer on integrated generalized structured component analysis. European Business Review 35 (3): 261–284. https://doi.org/10.1108/EBR-11-2022-0224.
Hwang, H., and Y. Takane. 2004. Generalized structured component analysis. Psychometrika 69 (1): 81–99. https://doi.org/10.1007/BF02295841.
Lin, L.C., P.H. Huang, and L.J. Weng. 2017. Selecting path models in SEM: A comparison of model selection criteria. Structural Equation Modeling: A Multidisciplinary Journal 24 (6): 855–869. https://doi.org/10.1080/10705511.2017.1363652.
Magno, F., F. Cassia, and C.M. Ringle. 2022. A brief review of partial least squares structural equation modeling (PLS-SEM) use in quality management studies. The TQM Journal. https://doi.org/10.1108/TQM-06-2022-0197.
Matthews, L., M. Sarstedt, J.F. Hair, and C.M. Ringle. 2016. Identifying and treating unobserved heterogeneity with FIMIX-PLS: Part II—A case study. European Business Review 28 (2): 208–224. https://doi.org/10.1108/EBR-09-2015-0095.
Menidjel, C., L.D. Hollebeek, S. Urbonavicius, and V. Sigurdsson. 2023. Why switch? The role of customer variety-seeking and engagement in driving service switching intention. Journal of Services Marketing. https://doi.org/10.1108/JSM-04-2022-0122.
Naik, P.A., P. Shi, and C.L. Tsai. 2007. Extending the Akaike information criterion to mixture regression models. Journal of the American Statistical Association 102 (477): 244–254. https://doi.org/10.1198/016214506000000861.
Nitzl, C., J.L. Roldan, and G. Cepeda. 2016. Mediation analysis in partial least squares path modeling: Helping researchers discuss more sophisticated models. Industrial Management & Data Systems 116 (9): 1849–1864. https://doi.org/10.1108/IMDS-07-2015-0302.
Preacher, K.J., and E.C. Merkle. 2012. The problem of model selection uncertainty in structural equation modeling. Psychological Methods 17 (1): 1–14. https://doi.org/10.1037/a0026804.
Ramayah, T., J. Cheah, F. Chuah, H. Ting, and M.A. Memon. 2018. Partial Least Squares Structural Equation Modeling (PLS-SEM) Using SmartPLS 3.0: An Updated Guide and Practical Guide to Statistical Analysis, 2nd ed. Kuala Lumpur: Pearson.
Rigdon, E.E., and M. Sarstedt. 2022. Accounting for uncertainty in the measurement of unobservable marketing phenomena. In Measurement in Marketing (Review of Marketing Research), vol. 19, ed. H. Baumgartner and B. Weijters, 53–73. Bingley: Emerald.
Rigdon, E.E., M. Sarstedt, and J.-M. Becker. 2020. Quantify uncertainty in behavioral research. Nature Human Behaviour 4: 329–331. https://doi.org/10.1038/s41562-019-0806-0.
Rigdon, E.E., M. Sarstedt, and O.I. Moisescu. 2023. Quantifying model selection uncertainty via bootstrapping and Akaike weights. International Journal of Consumer Studies. https://doi.org/10.1111/ijcs.12906.
Ringle, C.M., M. Sarstedt, N. Sinkovics, and R.R. Sinkovics. 2023. A perspective on using partial least squares structural equation modelling in data articles. Data in Brief 48: 109074. https://doi.org/10.1016/j.dib.2023.109074.
Ringle, C. M., Wende, S. and Becker, J.-M. 2022. SmartPLS 4 [Computer software]. http://www.smartpls.com.
Sarstedt, M., J.F. Hair, J.-H. Cheah, J.-M. Becker, and C.M. Ringle. 2019. How to specify, estimate, and validate higher-order models. Australasian Marketing Journal 27 (3): 197–211. https://doi.org/10.1016/j.ausmj.2019.05.003.
Sarstedt, M., J.F. Hair Jr., C. Nitzl, C.M. Ringle, and M.C. Howard. 2020. Beyond a tandem analysis of SEM and PROCESS: Use of PLS-SEM for mediation analyses! International Journal of Market Research 62 (3): 288–299. https://doi.org/10.1177/1470785320915686.
Sarstedt, M., J.F. Hair, M. Pick, B.D. Liengaard, L. Radomir, and C.M. Ringle. 2022. Progress in partial least squares structural equation modeling use in marketing in the last decade. Psychology & Marketing 39 (5): 1035–1064. https://doi.org/10.1002/mar.21640.
Sarstedt, M., C.M. Ringle, and D. Iuklanov. 2023. Antecedents and consequences of corporate reputation: A dataset. Data in Brief 48: 109079. https://doi.org/10.1016/j.dib.2023.109079.
Schuberth, F., M.E. Rademaker, and J. Henseler. 2022. Assessing the overall fit of composite models estimated by partial least squares path modeling. European Journal of Marketing. https://doi.org/10.1108/EJM-08-2020-0586.
Schwarz, G. 1978. Estimating the dimension of a model. The Annals of Statistics 6 (2): 461–464. https://doi.org/10.1214/aos/1176344136.
Sharma, P.N., B.D. Liengaard, J.F. Hair, M. Sarstedt, and C.M. Ringle. 2022. Predictive model assessment and selection in composite-based modeling using PLS-SEM: Extensions and guidelines for using CVPAT. European Journal of Marketing. https://doi.org/10.1108/EJM-08-2020-0636.
Sharma, P.N., M. Sarstedt, G. Shmueli, K.H. Kim, and K.O. Thiele. 2019. PLS-based model selection: The role of alternative explanations in information systems research. Journal of the Association for Information Systems 20 (4): 346–397. https://doi.org/10.17705/1jais.00538.
Sharma, P.N., G. Shmueli, M. Sarstedt, N. Danks, and S. Ray. 2021. Prediction-oriented model selection in partial least squares path modeling. Decision Sciences 52 (3): 567–607. https://doi.org/10.1111/deci.12329.
Simmons, J.P., L. Nelson, and U. Simonsohn. 2021. Pre-registration: Why and how. Journal of Consumer Psychology 31 (1): 151–162. https://doi.org/10.1002/jcpy.1208.
Streukens, S., and S. Leroi-Werelds. 2016. Bootstrapping and PLS-SEM: A step-by-step guide to get more out of your bootstrapping results. European Management Journal 34 (6): 618–632. https://doi.org/10.1016/j.emj.2016.06.003.
Sweeten, G. 2020. Standard errors in quantitative criminology: Taking stock and looking forward. Journal of Quantitative Criminology 36: 263–272. https://doi.org/10.1007/s10940-020-09463-9.
Wagenmakers, E.J., and S. Farrell. 2004. AIC model selection using Akaike weights. Psychonomic Bulletin & Review 11 (1): 192–196. https://doi.org/10.3758/BF03206482.
Wiedermann, W., and A. von Eye. 2015. Direction of effects in mediation analysis. Psychological Methods 20 (2): 221–244. https://doi.org/10.1037/met0000027.
Zhao, X., J.G. Lynch, and Q. Chen. 2010. Reconsidering Baron and Kenny: Myths and truths about mediation analysis. Journal of Consumer Research 37 (2): 197–206. https://doi.org/10.1086/651257.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Article was managed and handled by Maria Petrescu as editor.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sarstedt, M., Moisescu, OI. Quantifying uncertainty in PLS-SEM-based mediation analyses. J Market Anal 12, 87–96 (2024). https://doi.org/10.1057/s41270-023-00231-9
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1057/s41270-023-00231-9