
Abstract
There is an expectation that health professions schools respond to priority societal health needs. This expectation is largely based on the underlying assumption that schools are aware of the priority needs in their communities. This paper demonstrates how open-access, pan-national health data can be used to create a reliable health index to assist schools in identifying societal needs and advance social accountability in health professions education. Using open-access data, a psychometric evaluation was conducted to examine the reliability and validity of the Canadian Health Indicators Framework (CHIF) conceptual model. A non-linear confirmatory factor analysis (CFA) on 67 health indicators, at the health-region level (n = 97) was used to assess the model fit of the hypothesized 10-factor model. Reliability analysis using McDonald’s Omega were conducted, followed by Pearson’s correlation coefficients. Findings from the non-linear CFA rejected the original conceptual model structure of the CHIF. Exploratory post hoc analyses were conducted using modification indices and parameter constraints to improve model fit. A final 5-factor multidimensional model demonstrated superior fit, reducing the number of indicators from 67 to 32. The 5-factors included: Health Conditions (8-indicators); Health Functions (6-indicators); Deaths (5-indicators); Non-Medical Health Determinants (7-indicators); and Community & Health System Characteristics (6-indicators). All factor loadings were statistically significant (p < 0.001) and demonstrated excellent internal consistency (\(\upomega\) >0.95). Many schools struggle to identify and measure socially accountable outcomes. The process highlighted in this paper and the indices developed serve as starting points to allow schools to leverage open-access data as an initial step in identifying societal needs.
Similar content being viewed by others


Introduction
Health professions education aims to produce competent graduates equipped to meet societal needs. This goal represents one of the core principles of social accountability in medical education, which emphasizes the need for schools to direct their education, research, and service activities towards priority health needs of the communities they serve (Boelen & Heck, 1995; Global Consensus for Social Accountability of Medical Schools, 2010). However, there remains a misalignment between health professions education and societal needs (Ross and Cameron, 2021). While many schools have explicit institutional mandates to serve a specific geographic area or region (Barber et al., 2022), schools often remain unaware of the local health needs in their communities (Global Consensus and for Social Accountability of Medical Schools, 2010). One approach to address this gap is for schools to leverage open access, secondary population health data to better identify priority health needs. Despite repeated calls to utilize publicly available data to improve medical training (Triola et al., 2018; Chahine et al., 2018; Dauphinee, 2012), this data has yet to be fully utilized to identify societal needs. This paper demonstrates how open access pan-national population health data can be used to better identify relevant health needs and advance the social accountability mandate of health professions education.
Social accountability in medical education
Social accountability in health professions education is the obligation of medical schools to actively address the priority health needs of to their local communities (Boelen & Heck, 1995; Global Consensus and for Social Accountability of Medical Schools, 2010). This includes ensuring education, research, and service activities are aligned with societal needs. Social accountability represents a measurable activity (Global Consensus and for Social Accountability of Medical Schools, 2010), rooted in the identification of priority health needs and evaluated based on how well those needs are met (Dauphinee, 2012; Barber et al., 2020; Ventres et al., 2018; Boelen et al., 2019; Palsdottir et al., 2008; Larkins et al., 2013; Ross et al., 2014; Strasser et al., 2015; Preston et al., 2016). One strategy for schools to better identify priority health needs is to leverage open-access, secondary population health data.
Population health data and education
Pan-national population health data are collected iteratively by governments or non-profit agencies in most countries worldwide for research, public policy, evaluation, and accountability purposes. This data is used extensively in public health, epidemiology, as well as social, health and clinical sciences. However, despite repeated calls to better utilize publicly available data to improve medical training (Triola et al., 2018; Chahine et al., 2018; Dauphinee, 2012), this data has yet to be leveraged to better inform educational, research and service activities.
Health indicators, derived from population health data, are often represented as summary statistics or proxy measures of health and factors that influence health (Idler & Benyamini 1997; Ashraf et al., 2019). They are often used to evaluate population health outcomes and health systems performances through advocacy, accountability, quality improvement, and research (Etches et al., 2006; Murray & Frenk 2000). Health indicators provide insights into health risks, patterns, and trends and determine the extent to which performance expectations are met (Declich & Carter, 1994). These indicators are often used for accountability purposes by governments, health professionals, voluntary agencies, and the public. Additionally, health indicators are also used to improve public health education and professional training (Murray et al., 2002; Porter, 1993). Health indicator frameworks capture relevant health outcomes, often comprised of numerous health and non-health related measures, to assess and monitor population health outcomes, inequities, and health care utilization (Ashraf et al., 2019; Etches et al., 2006; Kindig & Stoddart, 2003; Braithwaite et al., 2017). However, many health indicator frameworks lack validity evidence as they are often developed using conceptual models (Ashraf et al., 2019; Etches et al. 2006). Despite their usefulness in explaining causal connections and interrelationships across specific domains, these frameworks must be empirical evaluated to ensure reliability and determine their effectiveness in serving their intended purposes (Etches et al., 2006; Krieger, 2001).
Our review of the health professions education literature provides some key examples and methods of how population health data can be used to set educational priorities (MacDonald et al., 1989), inform curricular content (Arthur & Baumann 1996), and evaluate institutional practices (Coutinho et al., 2017). For instance, MacDonald et al., (1989) utilized secondary population health data to inform curricular content and establish educational priorities across the health professions training continuum. While this article was published more than 30 years ago, the authors identified prevalent health conditions in a population or geographic area to better inform curricular planning and set educational priorities. Their goal was to better equip medical graduates to address priority health needs of the community they serve. Similarly, Arthur & Baumann (1996) described a planning framework to identify essential curricular context using a mixed methods approach. The authors utilized secondary population health data to identify community health needs relevant to nursing education. This data was triangulated using an expert panel and review of the literature to help inform core curricular content surrounding priority health issues. Lastly, Coutinho et al., (2017) examined the relationship between primary care medical graduates and indicators of population need using demographic data obtained from the United States Census Bureau. Findings from this study suggest little correlation between primary care residency training and population need. Moreover, the strategic initiative of expanding primary care residency training was not correlated to state needs in terms of the number of primary care physicians per population (Coutinho et al., 2017).
This paper adds to the literature by leveraging open-access, pan-national population health data and validates its viability to assist schools identify relevant health needs for social accountability purposes. This work is imperative in advancing the social accountability agenda of health professions education and can be used to identify regional health needs, inform educational priorities, and perhaps serve as an initial step towards monitoring educational outcomes on population health.
Methods
The goal of this study was to put forward an evidenced-based model that can be used by others to support social accountability. In this paper, we used open-source pan-national data from Statistics Canada’s Canadian Community Health Survey (CCHS) Public Use Microdata File (PUMF) (Statistics Canada, 2021) and online mortality and vital statistics (Statistics Canada, 2018) to examine the factor structure and reliability of a national conceptual health indicator model in Canada. Using an iterative approach, a non-linear factor analysis was used to validate the viability of the Canadian Health Indicator Framework (CHIF) (Canadian Institute and for Health Information, 2013).
Study setting
Canada was the first country to adopt a national social accountability mandate for medical education globally (Health Canada, 2001). The Canadian healthcare system is publicly funded and provides universal coverage for medically necessary hospital and physician services to all Canadian citizens and permanent residents. The system is primarily funded through taxpayers and managed by individual provinces or territories (Government of Canada, 2023). Canada also provides open access to high-quality and easily accessible pan-national data on the economy, society, and environment (Statistics Canada, 2020a). Currently, 187 countries worldwide have national statistical systems that collect, process, and disseminate official statistics on behalf of their respective national governments (Open Data Watch, 2020). These systems aim to provide relevant, comprehensive, accurate, and objective statistical information on a country’s society, economy, and environment (Statistics Canada 2016a).
Canada is widely recognized for having some of the most comprehensive health data in the world (Lucyk et al. 2015). However, unlike other countries, Canada has yet to widely adapted a reliable national health indicator framework (Office of the Auditor General of Canada, 2008).
Organizational framework
The CHIF (Canadian Institute and for Health Information, 2013) was selected as the organizational framework for grouping variables available from Statistics Canada’s 2017–18 CCHS PUMF (Statistics Canada, 2021) and online mortality and vital statistics.
The CHIF is a conceptual model developed by Statistics Canada and Canadian Institute for Health Information (CIHI) through national consensus with provincial and regional health authorities (Canadian Institute and for Health Information, 2013). Statistics Canada is Canada’s national statistical agency responsible for collecting statistical data on the country’s population, economy, society, and culture (Statistics Canada, 2020b). CIHI is an independent, not-for-profit organization that works closely with Statistics Canada and provincial and territorial governments to collect and share data on Canada’s health system and population health (Canadian Institute and for Health Information, 2021).
This framework provides reliable and comparable data on the health of Canadians, health care systems, and health determinants (Canadian Institute and for Health Information, 2021). It consists of over 80 indicators, measured across 4 domains and several factors, including health status (4 factors), non-medical determinants of health (3 factors), health system performance (1 factor), and community health system characteristics (2 factors) (depicted in Table 1) (Canadian Institute and for Health Information, 2021). A more detailed description of the CHIF is provided on Statistics Canada and CIHI’s website (Canadian Institute and for Health Information, 2013). These indicators serve as both measures of health and factors which influence health, used to inform health policy and manage the health care system (Statistics Canada, 2021). The CHIF has been widely used in guiding previous health indicator development (Statistics Canada, 2015a). However, it has not been empirically validated.
The importance of developing a population health profile has been well-established in the literature (Boelen & Heck, 1995; Global Consensus and for Social Accountability of Medical Schools, 2010; Ventres et al., 2018). From a social accountability perspective, the local community serves as the main stakeholder of all health professions schools, and it is essential for schools to identify and respond to the priority health needs in the communities they serve (Boelen & Heck, 1995). This includes identifying and understanding the cultural context, social determinants of health, and health disparities in the communities they are expected to serve.
The CHIF serves as a comprehensive set of health indicators that are specifically designed to measure and monitor the health of Canadians. This framework may be used as a valuable tool for schools to their advance their social accountability mandate by identifying relevant population health needs in their respective geographic areas or region.
Data
This study utilized two open-source data sources were, the CCHS PUMF and publicly available mortality and vital statistics data obtained online from Statistics Canada website.
The CCHS is a voluntary, cross-sectional nationally representative survey offered in both English and French and is distributed annual to individuals >12 years of age living in Canada (Statistics Canada, 2021). Excluded from the sampling frame are individuals living on Indigenous reserves or other settlements, full-time members of the Canadian Forces, institutionalized populations, children aged 12–17 living in foster care, and those living in remote health regions in Quebec (Statistics Canada, 2021). The survey employs a stratified multistage sampling strategy to provide reliable estimates at the health region level every two years (Statistics Canada, 2021).
The CCHS is comprised of two years of data and includes responses surveyed over the reference period. The CCHS cycle is comprised of common content (asked of all respondents), optional content (selected by each province/territory), and rapid response content (Statistics Canada, 2021). The common content collected during the first year of the survey cycle consists of questions asked of all respondents. The optional content, collected from a smaller sample during the second year of the survey cycle, comprises of questions selected by each province/territory on specific health topics (Statistics Canada, 2021).
The CCHS PUMF is an open access dataset representing 3% of the Canadian population, inclusive of approximately 1,050 variables related to Canadians' health-status, health care utilization, and health determinants, including socio-demographic data, health conditions and diseases, lifestyle, social conditions, as well as mental health and well-being. A more detailed description of the CCHS PUMF survey design, sampling methodology, and validation has been described elsewhere (Statistics Canada, 2021).
To ensure comprehensive representation of all factors associated with the CHIF, publicly available mortality, vital statistics, and community indicators data were obtained online from Statistics Canada’s website (Canadian Institute and for Health Information, 2013; Statistics Canada, 2016b).
Ethics approval was obtained from Maastricht University’s Ethics Review Committee Health, Medicine and Life Sciences (FHML-REC).
Analysis
Level of analysis
Due to missing data observed at the individual level due to the CCHS sampling design and data disclosures controls, the level of analysis was aggregated to the health region level (n = 97). The CCHS employs a stratified multistage sampling cycle and imposes several data disclosure controls to protect respondent anonymity and confidentiality. These controls include the use of subsampling and data suppression techniques, such as the removal of sensitive variables (e.g., outliers) or indirect identifiers (i.e., socio-demographic characteristics, geographic metrics), to minimize the risk of disclosing personal information due to small population sizes. These methods minimize the potential for identifying individual respondents while preserving the analytical value of the data (Statistics Canada, 2021).
To overcome missing data issues observed at the individual level, place-level data aggregation was imposed at the health region level. Health regions are administrative areas defined by provincial ministries of health responsible for delivering public health care services (Statistics Canada, 2018). Aggregating the CCHS PUMF at the health region level yielded a total analytical sample of 97 health regions, which are listed in ‘Appendix I’.
Measures
The selection of health indicators was guided by the CHIF conceptual model and based on data availability from the 2017–18 CCHS PUMF, and mortality and vital statistics, and community indicators obtained online from Statistics Canada website (Canadian Institute and for Health Information, 2013; Statistics Canada, 2016b). A total of 67 variables were identified and selected to measure the CHIF conceptual model across four domains and several factors and indicators: (1) health status (4 factors, 40 indicators), (2) non-medical determinants of health (3 factors, 17 indicators), (3) health system performance (2 factors, 2 indicators), and (4) community health system characteristics (2 factors, 8 indicators) (shown in Table 2).
Nominal and ordinal scale indicators were recoded dichotomously. For instance, non-favourable health outcomes such as fair or poor perceived health, presence of disease (e.g., arthritis, cancer, diabetes, high blood pressure, etc.), and personal behaviours and risk factors (e.g., under/overweight, or obese body mass index (BMI), smoking, heavy drinking, etc.) were coded as ‘1’. On the other hand, favourable health outcomes such as good, very good, or excellent perceived health, normal BMI, absence of disease (e.g., no cancer in lifetime, normal blood pressure), and positive personal behaviours (e.g., non-smoker or non-drinker, etc.) were coded as ‘0’. These indicators were aggregated to the health region level and calculated as proportions derived from discrete counts at the aggregated health region. Ratio-scale variables such as income (i.e., low-income rates, medium share of income, government transfer income) and employment rates (unemployment rate, long-term unemployment rate) were not dichotomized to preserve their continuous scale and were aggregated to the health region level. The analytical dataset comprised of compositional data derived from discrete count-based proportions or percentages aggregated to the health region level (Aitchison, 1982).
Analytical approach
To assess the factor structure of the CHIF at the health region level, a non-linear confirmatory factor analysis (CFA) was used due to the non-normality of the data (McDonald, 1967; Bauer & Hussong, 2009).
Validity frameworks often consist of four components, including content validity, response process validity, internal structure validity, and criterion validity (Smirnova et al., 2022; Cook et al., 2015). The rigorous design and development process of the CHIF involved three validity components: content validity, response process validity, and criterion validity. These validity components were established through a comprehensive review of existing literature and expert consultation, the use of clear operational definitions and standardized data collection methods, and comparison with other established measures of health status (Canadian Institute and for Health Information, 2013). This paper specifically assesses the internal structure validity of the CHIF using CFA. Factor analyses are often utilized to provide construct validity evidence (Henson & Roberts, 2006; American Education Research Association et al., 1999; Thompson & Daniel, 1996) to evaluate the underlying structure of the observed measures by examining inter-item correlation.
Using an iterative process, maximum likelihood with robust standard errors (MLR) and accelerated expectation maximization (EMA) estimators were used to estimate the factors. The expectation maximization (EM) algorithm (Byrne, 2005) was used to optimize the complete data loglikelihood, while EMA, an accelerated EM procedure, utilized Quasi-Newton and Fisher Scoring optimization (Schreiber et al., 2006). To improve model fit through modifications indices and identify potential misspecified parameters, post hoc model fit was conducted in an exploratory manner (Dempster et al., 1977). This approach aimed to create a multi-dimensional respecified model while ensuring that the hypothesized model fit well with the observed data and aligned theory and epistemology (Muthén & Muthén, 2007). CFA analyses were conducted in Mplus (Version 8.7, Muthén & Muthén, Los Angeles, CA).
Model specification
The CHIF conceptual model was used to initially specify the factor structure of the model. Criteria for retaining items in the model included a statistically significant path coefficient (p < 0.05) between the item and its predicted subscales on the CHIF. Post-hoc modification indices were used to modify the model for improved model fit indices. To set a metric for each factor, unit loading identification constraints were imposed by fixing the unstandardized coefficient of one item per latent variable equal to one (Kline, 2015).
The respecification process included examining modification indices, residuals, parameter estimates, and explained variance. Based on these sources of the model information, the Well-Being factor and several indicators within the five remaining hypothesized factors were deleted due to weak relationships and excessive redundancy of items (Wang & Staver, 2001). The use of modification indices resulted in the identification of additional statistically significant paths, leading to a better model fit. All factor loadings were statistically significant (p < 0.001), and residuals remained close to zero.
Several conditions needed to be satisfied for an item to be retained in the generated model. The path coefficient between an item and its predicted subscale on the CHIF needed to be statistically significant (p < 0.05). Post-hoc modification indices generated from the structural parameters were used to modify the model to achieve better model fit indices. To set a metric for each factor, unit loading identification constraints were imposed (Kline, 2015); the unstandardized coefficient of one item per latent variable was fixed equal to ‘1’.
Respecification of the structural model included the examination of the following: (1) modification indices, (2) residuals, (3) parameter estimates, and (4) explained variance. Taken together, sources of model information suggested the deletion of the Well-Being factor as well as several indicators within the five remaining hypothesized factors. Item deletion was deemed appropriate due to weak relationships and evidence of excessive redundancy of items (Hoyle, 1995). Additionally, modification indices generated from the structural parameters were used to identify additional statistically significant paths, resulting in a better model fit. All factor loadings were statistically significant (p < 0.001), and residuals remained close to zero.
Model fit
The quality of the model was assessed by examining several fit indices, including Chi-square (χ2), Comparative Fit Index (CFI), Tucker-Lewis Index (TLI), Root Mean Square Error of Approximation (RMSEA), and Standardized Root-Mean-Square Residuals (SRME). Model fit was evaluated using a combination of these indices (Hoyle, 1995; Thompson, 2004). The following thresholds were selected based on previous literature: CFI and TLI values ≥ 0.95 were considered favourable and indicative of good model fit (Hu & Bentler 1998), RMSEA values between 0.05 and 0.08 indicated reasonable error of approximation (Browne & Cudeck, 1992), and SRMR values ≤ 0.08 were considered reasonable (Browne & Cudeck, 1992).
Reliability
Internal consistency of scales resulting from the final CFA model was assessed using McDonalds Omega \(\upomega\) coefficient. The coefficient was obtained in JAMOVI (Version 1.2; The jamovi project, Sydney, Australia). McDonald’s Omega coefficient was preferred over Cronbach’s Alpha as it has been suggested to have superior psychometric properties and provide more accurate estimates of a scale’s internal structure (Crutzen & Peters, 2017; Peters, 2014; Revelle & Zinbarg, 2009).
Results
In total, 67 indicators aggregated to the health region level (n = 97) from the 2017–18 CCHS PUMF and online mortality and vital and community indicators were analyzed using non-linear CFA. Table 3 provides the mean, standard deviation, distribution (skewness & kurtosis), and range of possible scores for the variables included in analysis. Overall, the number of health regions per indicator remained relatively stable. However, the range of possible scores, means, and standard deviation for each indicator varied. The skewness and kurtosis measures confirm non-normality of all indicators, except for the Government Share Income indicator.
Social health index
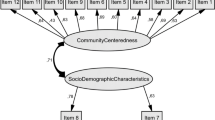
The initial model involved 67 measured indicators and 10 hypothesized factors (shown in Table 2). However, the initial 10-factor model was rejected due to poor model fit. Post hoc analyses were conducted in an exploratory manner to identify which parameters in the model were misspecified (Aitchison, 1982). Using an iterative process, modification indices and parameter constraints were imposed to improve model fit. The final 5-factor CFA (depicted in Fig. 1) included: (1) Health Conditions (8 indicators), (2) Health Functions (6 indicators), (3) Deaths (5 indicators), (4) Non-Medical Health Determinants (7 indicators), and (5) Community & Health System Characteristics (6 indicators).

Final model with standardized loadings for 32 health indicators aggregated to the health region level from the 2017–18 CCHS PUMF. Observed variables are represented as rectangles, circles represent the unobserved variables, and the arrows going to the rectangles represent the measurement error associated with each observed variable. The arrows between unobserved and observed variable represents a regression path and the standardised regression weight. The double-headed arrows represent the correlation between two unobserved variables (factor covariances) in the model
Overall, 35 indicators were removed, resulting in the reduction of the number of indicators in the initial model from 67 to 32. Additionally, seven correlated error terms were allowed between two indicators on four of the five factors: Health Conditions, Health Functions, Non-Medical Health Determinants, and Community & Health System Characteristics. The 5-factor model demonstrated good model fit according to the recommended criteria (Kline, 2015) (shown in Table 4).
Internal consistency reliability was conducted for the five scales at the health region level, based on the items retained in the final model, and assessed using McDonald’s ω coefficient (Table 4). The coefficients for all subscales were excellent, ranging from 0.945 to 0.984 (Lucke, 2005).
Pearson’s correlation coefficients were used to investigate the inter-relationships between the CFA factors. As shown in Table 4, all correlation coefficients were significant and positively correlated with one another. Based on the magnitude of the coefficients (ranging from strong to very strong), the strength of the association was highest for Health Function and Health Conditions (0.986), and lowest for Non-Medical Health Determinants and Deaths (0.733).
Discussion
This study developed and evaluated a multi-dimensional health index to be used by health professions programs for social accountability purposes. Utilizing open access, pan-national health data, this paper assessed the psychometric properties and internal factor structure of an existing national conceptual health indicator framework in Canada. This study represents, to our knowledge, the first examination of the underlying factor structure and reliability assessment of the CHIF at the health region level. This effort extends previous research that examined the correlations between CHIF health and healthcare performance indicators at the provincial and territorial level (Arah & Westert, 2005).
Results from our non-linear CFA rejected the original 10-factor conceptual model structure of the CHIF. Exploratory post hoc analyses resulted in a 5-factor multi-dimensional model, demonstrating excellent model fit on various fit indices. Our findings, generally corroborate the structural validity of the CHIF. However, several modifications were imposed to improve model fit, reducing the number of constructs and indicators in the final model from 67 to 32, creating a more parsimonious set of indicators. Additionally, outcomes from our analysis did not psychometrically support the inclusion of the well-being construct at health region level due to poor model fit. However, this finding does not suggest that well-being is not an important health indicator. These reductions improved the feasibility and utility of the indices. The reliability of each subscale supported by McDonald’s \(\upomega\) coefficient exceeded the recommended standards of > 0.80 (Lucke, 2005), indicating high internal consistency.
The findings from our 5-factor non-linear CFA demonstrated a multidimensional model of health, supportive of the multifaceted nature of the concept of health. The concept of health is both influenced and produced by biological and social factors, culture referents, as well as social interactions and networks (WHO, 1986; Olafsdottir, 2013; Conrad & Baker, 2010). These 5-factors may be used as parcels in examining health at the construct level (Matsunaga, 2008). These findings are consistent with the public health literature which favour multi-dimensional models of health, over a single health composite score (Braithwaite et al., 2017; Smith Papanicolas, 2013). The use of a single health composite measure was initially thought to provide a holistic overview of health and the healthcare system (Braithwaite et al., 2017; Smith Papanicolas, 2013). However, it has been found to be challenging to interpret and fails to account for heterogenous system differences (Braithwaite et al., 2017; Smith Papanicolas, 2013).
The process highlighted in this paper and the indices developed serve as starting points to allow schools to leverage open access population health data to better identify relevant priority health needs. This initial step in identifying community needs is imperative to advancing the social accountability agenda of health professions schools and may begin to close the gap between education and society. There are a number of ways in which this study might be used in the selection and teaching of medical students. From a programmatic standpoint these indices may be used by schools to better identify societal health needs, create community profiles, inform educational priorities and modify curricular activities and/or practices (Kolak et al., 2020) to ensure better alignment between education and societal needs (Ross & Cameron, 2021; Kaprielian et al., 2013). While priority health concerns are to be identified collaboratively alongside key stakeholders (Boelen & Heck, 1995), these indices may be used to establish more impactful collaborations with local health stakeholders (Kolak et al., 2020). Furthermore, schools may elect to use these indices during the admissions process by creating more targeted application components and/or interview questions asking potential applicants about their perceptions of community health needs. Lastly, schools may also decide to use these indices in combination with other internal data to assist in identifying community-based learning opportunities and areas of need (Kolak et al., 2020).
The aim of developing the indices was to provide guidance to advance social accountability in health professions education. The consequential validity of the index lies in its ability to provide insight into the health needs of a respective region. This information may be used by schools to help inform educational practices and perhaps provide the initial steps in being able to generate actionable recommendations to improve population health outcomes. Leveraging open access population health data in a systematic approach serves as a valuable tool for identifying relevant societal needs. This approach could lead to the development of regionally sensitive health profiles, increased agreement of relevant community health needs, more purposeful conversations with community stakeholders, as well as more targeted resource allocation (Kolak et al., 2020). The use of data to support educational improvements has been shown to be effective in improving medical training (Triola et al., 2018; Chahine et al., 2018). Despite calls in the literature to better utilize open access data collected by governments to improve medical training, schools struggle to make these links (Triola et al., 2018; Chahine et al., 2018; Dauphinee, 2012). Few seminal population-based outcome studies have examined the relationship between health professions training and health outcomes (Tamblyn, 2011; Wenghofer et al., 2009; Kawasumi et al., 2011; Cadieux et al., 2007; Norcini et al., 2000; Norcini et al., 2014; Asch et al., 2009; Asch et al., 2014; Epstein et al., 2013, 2016; Teodorczuk et al., 2017). However, this paper provides an example of how schools can begin to utilize open access, secondary data to create a reliable health indices as a means to empirically identify regional population health needs.
Findings of this study utilized open access data to identify priority health needs. Although open access data remains readily available, cost-effective, and generalizable, there are a number of limitations to consider. Despite continual global government invest in the quality and accessibility of publicly available data, the system remains imperfect (Health Canada, 2004). Open access datasets are designed to be representative of the larger population there are often several data control methods and restrictions imposed for confidentiality and anonymity, limiting access to information and variables at smaller levels of geography. Although access to neighbourhood-level data would allow for greater specificity and comparisons across smaller geographical areas, this study identified universal health needs from open access data, accessible to all schools. Further research could include replicating these analyses using restricted data available through affiliated academic research data centres (e.g., Statistics Canada’s Research Data Centres (RDC) or Federal Statistical Research Data Centers (FSRDC) in the United States). Additionally, the speed at which up-to-date data is available is often delayed, which could impact the reliability of the indices over time. While this study utilized the most up-to-date available data at the time of analysis, more timely access to current data should be made more readily available to researchers. These indices should be updated and modified with the release of new CCHS cycle data (approximately every 4 years) to reflect accurate and timely population health needs. This timeline aligns to previous research stating that the half-life of most health professions curricula is 5 years, at which time necessitates the need to examine and revise content (Arthur & Baumann, 1996). However, caution should be used when combining CCHS cycles across years as modules and question response categories often change (Statistics Canada, 2015b).
The indicators included in this study were selected based on their alignment to the CIHF conceptual model. However, the selection of indicators was limited by data availability and may not necessarily reflect a comprehensive list of all possible health indicators. Due to missing data issues, analyses were aggregated to the health region level, reflecting population means, reducing the analytical sample. However, health region level aggregation was deemed appropriate from a theoretical and epistemological perspective. This paper presents a reliable, nationally relevant, regionally sensitive health index measured at administrative regions responsible for administering and delivering health care in Canada. Additionally, there are also several potential other important factors that may be necessary to validate the use of a regional health profile to advance social accountability in medical education, including stakeholder engagement (Boelen & Heck, 1995) (e.g., community members, healthcare providers, and policy makers, etc.), contextual factors (Boelen et al., 2012) (e.g., broader social, economic, and geo-political contexts), longitudinal data (e.g., track changes in health outcomes over time), interprofessional collaboration (Fleet et al., 2008) (e.g., promotion of collaboration among various health professions teams and disciplines), and resource allocation (Global Consensus and for Social Accountability of Medical Schools, 2010) (e.g., financial and human resources). Lastly, the CCHS is representative of self-reported data, and the presence of chronic health conditions cannot be confirmed and may be under/over reported. However, self-reported health metrics are often used as general proxies for health status as they are inexpensive, readily available (Muggah et al. 2013; Miilunpalo et al. 1997; Skinner et al. 2005) and associated with lifestyle-related diseases, lifestyle habits as well as mortality (Li et al., 2020; Yamada et al., 2012; Gallagher et al., 2016; Cislaghi & Cislaghi, 2019).
Conclusion
The development of a health index is imperative to initiate quality processes to empirically identify societal needs, and serves as a starting point to establish stronger relationships between education and society (Triola et al., 2018). Despite the importance of secondary population health and demographic databases in other fields, health professions education has largely overlooked their use. This study demonstrates how open access, secondary data can be utilized to create reliable health indices that identify population health needs. These indices can be used to align resources, services, and research activities, and inform admissions criteria and curricular design.
Future research should focus on how health professions schools can better utilize secondary data to better inform and understand priority health needs as well as the socio-demographic composition of the populations they serve. This information may be used to better inform health workforce need, admission processes, underservice areas, future health care needs, and curricular design to ensure social determinants of health are integrated throughout the curriculum. Schools must utilize their resources in a more purposeful way and ensure that graduates acquire the competencies most relevant to societal needs (Boelen et al., 2019). Additionally, future work could also focus on how schools can better identify their mandated geographic service areas using preidentified government regions or administrative areas such as health regions, census divisions or subdivisions.
This study provides an example of a systematic and iterative approach to developing a socially accountable health index using pan-national open access secondary data. The indices created in this study serve as a proxy for societal health needs and perhaps may provide a starting point for establishing stronger relationships between education and society. It is important for schools to utilize their resources more purposefully and ensure that graduates are equipped with the competencies needed to address societal needs (Boelen & Woollard, 2009). Closing the gap between education and society has the potential to improve health outcomes (Triola et al., 2018), and promote a more socially accountable health professions education system.
References
Aitchison, J. (1982). The statistical analysis of compositional data. Journal of the Royal Statistical Society: Series B (Methodological), 44(2), 139–177.
Arah, O. A., & Westert, G. P. (2005). Correlates of health and healthcare performance: Applying the Canadian health indicators framework at the provincial-territorial level. BMC Health Service Research, 5(76), 1–13.
Arthur, H., & Baumann, A. (1996). Nursing curriculum content: An innovative decision-making process to define priorities. Nursing Education Today, 16, 63–68.
Asch, D. A., Nicholson, S., Srinivas, S., Herrin, J., & Epstein, A. J. (2009). Evaluating obstetrical residency programs using patient outcomes. JAMA, 302(12), 1277–1283.
Asch, D. A., Nicholson, S., Srinivas, S. K., Herrin, J., & Epstein, A. J. (2014). How do you deliver a good obstetrician? Outcome-based evaluation of medical education. Academic Medicine, 89(1), 24–26.
Ashraf, K., Ng, J. C., Teo, C. H., & Goh, K. L. (2019). Population indices measuring health outcomes: A scoping review. Journal of Global Health., 9(1), 1–14.
American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (1999). Standards for educational and psychological testing. Washington, DC: American Educational Research Association.
Barber, C., Chahine, S., Leppink, J., & van der Vleuten, C. (2022). Global perceptions on social accountability and outcomes: A survey of medical schools. Teaching and Learning in Medicine. https://doi.org/10.1080/10401334.2022.2103815
Barber, C., van der Vleuten, L. J., & Chahine, S. (2020). Social accountability frameworks and their implications for medical education and program evaluation: A narrative review. Acad Med, 95(12), 1945–1954.
Bauer, D. J., & Hussong, A. M. (2009). Psychometric approaches for developing commensurate measures across independent studies: Traditional and new models. Psychological Methods., 14, 101–125.
Boelen C, Heck JE. Defining and measuring the social accountability of medical schools. Geneva, Switzerland: World Health Organization; 1995. http://whqlibdoc.who.int/hq/1995/WHO_HRH_95.7.pdf. Accessed July 5, 2021.
Boelen, C., Blouin, D., Gibbs, T., & Woollard, R. (2019). Accrediting excellence for a medical school’s impact on population health. Educ for Health., 32(1), 41–48.
Boelen, C., Shafik, D., & Gibbs, T. (2012). The social accountability of medical schools and its indicators. Educ for Health., 25(3), 180–194.
Boelen, C., & Woollard, B. (2009). Social accountability and accreditation: A new frontier for educational institutions. Medical Education, 43, 887–894.
Braithwaite, J., Hibbert, P., Blackely, B., Plumb, J., et al. (2017). Health system frameworks and performance indicators in eight countries: A comparative international analysis. Sage Open Medicine, 5, 1–10.
Browne, M. W., & Cudeck, R. (1992). Alternative ways of assessing model fit. Sociol Methods Res., 21(2), 230–258.
Byrne, B. M. (2005). Factor analytic models: Viewing the structure of an assessment instrument from three perspectives. Journal of Personality Assessment., 85(1), 17–32.
Cadieux, G., Tamblyn, R., Dauphinee, D., & Libman, M. (2007). Predictors of inappropriate antibiotic prescribing among primary care physicians. CMAJ, 177(8), 887–883.
Health Canada. Social Accountability: A Vision for Canadian Medical Schools. Ottawa, ON, Canada: Health Canada; 2001. https://www.afmc.ca/future-of-medicaleducation-in-canada/medical-doctorproject/pdf/sa_vision_canadian_medical_schools_en.pdf. Accessed July 15, 2020.
Health Canada. (2004). Healthy Canadians A federal report on comparable health indicators 2004. Her Majesty the Queen in Right of Canada.
Government of Canada. Canada’s health care system. 2023. Available from: https://www.canada.ca/en/health-canada/services/canada-health-care-system.html.
Chahine, S., Kulasegaram, K. M., Wright, S., et al. (2018). A call to investigate the relationship between education and health outcomes using big data. Academic Medicine, 93, 829–832.
Cislaghi, B., & Cislaghi, C. (2019). Self-rated health as a valid indicator for health-equity analyses: Evidence from the Italian health interview survey. BMC Public Health, 19(1), 533.
Conrad, P., & Baker, K. K. (2010). The social construction of illness: Key insights and policy implications. J Health Soc Behav, 51(S), S67–S79.
Global Consensus for Social Accountability of Medical Schools. (2021). Global consensus for social accountability of medical schools. http://healthsocialaccountability.org. Published December 2010. Accessed July 5.
Cook, D. A., Brydges, R., Ginsburg, S., & Hatala, R. (2015). A contemporary approach to validity arguments: A practical guide to Kane’s framework. Medical Education, 49, 560–575.
Coutinho, A. J., Klink, K., Wingrove, P., Petterson, S., Phillips, R. L., & Bazemore, A. (2017). Changes in primary care graduate medical education are not correlated with indicators of need: are states missing an opportunity to strengthen their primary care workforce? Academic Medicine, 92(9), 1280–1286.
Crutzen, R., & Peters, G. J. Y. (2017). Scale quality: Alpha is an inadequate estimate and factor-analytic evidence is needed first of all. Health Psychology Review., 11(3), 242–247.
Dauphinee, W. D. (2012). Educators must consider patient outcomes when assessing the impact of clinical training. Med Ed., 46, 13–20.
Declich, S., & Carter, A. O. (1994). Public health surveillance: Historical origins, methods and evaluation. Bulletin of the World Health Organization, 72(2), 285–304.
Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. J R Stat Soc Series B Stat Methodol., 39(1), 1–22.
Epstein, A. J., Nicholson, S., & Asch, D. A. (2016). The Production of and market for new physicians’ skill. AM J Health Econ., 2(1), 41–65.
Epstein, A. J., Srinivas, S. K., Nicholson, S., Herrin, J., & Asch, D. A. (2013). Association between physicians’ experience after training and maternal obstetrical outcomes: cohort study. BMJ, 346(mar284), f1596.
Etches, V., Frank, J., Di Ruggiero, E. D., & Manuel, D. (2006). Measuring population health: A review of indicators. Annual Review of Public Health, 27, 29–55.
Fleet, L. J., Kirby, F., Cutler, S., Dunikowski, L., Nasmith, L., & Shaughnessy, R. (2008). Continuing professional development and social accountability: A review of the literature. Journal of Interprofessional Care, 22(1), 15–29.
Gallagher, J. E., Wilkie, A. A., Cordner, A., et al. (2016). Factors associated with self-reported health: implications for screening level community-based health and environmental studies. BMC Public Health, 16, 640.
Henson, R. K., & Roberts, J. K. (2006). Use of exploratory factor analysis in published research. Educational and Psychological Measurement, 66, 393–416.
Hoyle, R. H. (Ed.). (1995). Structural equation modeling: Concepts, issues and applications. Sage.
Hu, L. T., & Bentler, P. M. (1998). Fit indices in covariance structure modeling: Sensitivity to underparameterized model misspecification. Psychological Methods., 3, 424–453.
Idler, E. L., & Benyamini, Y. (1997). Self-rated health and mortality: A review of twenty-seven community studies. JHSB., 38(1), 21–37.
Canadian Institute for Health Information. Health indicators. 2013. Available from: https://secure.cihi.ca/free_products/HI2013_Jan30_EN.pdf.
Canadian Institute for health Information (CIHI). Health indicators 2013. 2014. Available from: https://www.cihi.ca/sites/default/files/document/health-indicators-2013-en.pdf.
Canadian Institute for Health Information (CIHI). About us. 2021. Available from: https://www.cihi.ca/en/about-cihi.
Kaprielian, V. S., Silberberg, M., McDonald, M. A., et al. (2013). Teaching population health: A competency map approach to education. Academic Medicine, 88(5), 626–637.
Kawasumi, Y., Ernst, P., Abrahamowicz, M., & Tamblyn, R. (2011). Association between physician competence at licensure and the quality of asthma management among patients with out-of-control asthma. Archives of Internal Medicine, 171(14), 1292–1294.
Kindig, D., & Stoddart, G. (2003). What is population health? American Journal of Public Health, 93(3), 380–383.
Kline, R. B. (2015). Principles and practice of structural equation modeling (4th ed.). Guilford Press.
Kolak, M., Bhatt, J., Park, Y. H., Padron, N. A., & Molefe, A. (2020). Quantification of neighborhood-level social determinants of health in the continental United States. JAMA Network Open, 3(1), e1919928.
Krieger, N. (2001). Theories for social epidemiology in the 21st century: An ecosocial perspective. International Journal of Epidemiology, 30(4), 668–677.
Larkins, S. L., Reston, R., Marre, M. C., et al. (2013). Measuring social accountability in health professional education: Development and international pilot testing of an evaluation framework. Medical Teacher, 35, 32–45.
Li, Y., Schoufour, J., Wang, D. D., Dhana, K., Pan, A., Liu, X., et al. (2020). Healthy lifestyle and life expectancy free of cancer, cardiovascular disease, and type 2 diabetes: Prospective cohort study. BMJ, 368, l6669.
Lucke, J. F. (2005). The α and the ω of congeneric test theory: An extension of reliability and internal consistency to heterogeneous tests. Applied Psychological Measurement., 29(1), 65–81.
Lucyk, K., Lu, M., Sajobi, T., et al. (2015). Administrative health data in Canada: Lessons from history. BMC Med Inform Decis Mak, 15(1), 1–6.
MacDonald, P. J., Chong, J. P., Pet, C., et al. (1989). Setting educational priorities for leaning the concepts of population health. Medical Education, 23, 429–439.
Matsunaga, M. (2008). Item parceling in structural equation modeling: A primer. Communication Methods and Measures, 2(4), 260–293.
McDonald RP. (1967). Nonlinear factor analysis (Psychometric Monograph No. 15). Richmond, VA: Psychometric Corporation.
Miilunpalo, S., Vuori, I., Oja, P., Pasanen, M., & Urponen, H. (1997). Self-rated health status as a health measure: The predictive value of self-reported health status on the use of physician services and on mortality in the working-age population. Journal of Clinical Epidemiology, 50(5), 517–528.
Muggah, E., Graves, E., Bennett, C., & Manuel, D. G. (2013). Ascertainment of chronic diseases using population health data: A comparison of health administrative data and patient self-report. BMC Public Health, 13, 16.
Murray, C. J. L., & Frenk, J. A. (2000). A framework for assessing the performance of health systems. Bulletin of the World Health Organization., 78(6), 717–731.
Murray, C. J. L., Salomon, J. A., & Mathers, C. D. (2002). A critical examination of summary measures of population health. In C. J. L. Murray, J. A. Salomon, C. D. Mathers, & A. D. Lopez (Eds.), Summary measures of population health: Concepts, ethics, measurement and applications (pp. 13–40). WHO.
Muthén, L.K. and Muthén, B.O. (1998–2007). Mplus User’s Guide. Fifth Edition. Los Angeles, CA: Muthén & Muthén.
Norcini, J. J., Boulet, J. R., Opalek, A., & Dauphinee, W. D. (2014). The relationship between licensing examination performance and the outcomes of care by international medical school graduates. Academic Medicine, 89(8), 1157–1162.
Norcini, J., Kimball, H., & Lipner, R. (2000). Certification and specialisation: Do they matter in the outcome of acute myocardial infarction? Academic Medicine, 75, 1193–1198.
Office of the Auditor General of Canada. (2008) Report of the Auditor General of Canada to the House of Commons. Chapter 8: Reporting on health indicators – Health Canada.
Olafsdottir, S. (2013). Social construction and health. In W. C. Cockerham (Ed.), Medical sociology on the move. Springer.
Open Data Watch. Open Data Inventory 2020/21. (ODIN). Annual Report. 2021. Available from: https://odin.opendatawatch.com/Report/annualReport2020.
Palsdottir, B., Neusy, A. J., & Reed, G. (2008). Building the evidence base: Networking innovative socially accountable medical education programs. Education for Health (Abingdon, England), 21, 177.
Peters, G. J. Y. (2014). The alpha and the omega of scale reliability and validity: Why and how to abandon Cronbach’s alpha and the route towards more comprehensive assessment of scale quality. The European Health Psychologist., 16(2), 56–69.
Porter, D. (1993). Public health. In W. F. Bynum & R. Porter (Eds.), Companion encyclopedia of the history of medicine (Vol. 2, pp. 1231–1261). Routledge.
Preston, R., Larkins, S., Taylor, J., & Judd, J. (2016). Building blocks for social accountability: A conceptual framework to guide medical schools. BMC Medical Education, 16, 227.
Revelle, W., & Zinbarg, R. E. (2009). Coefficients alpha, beta, omega, and the GLB: Comments on Sijtsma. Psychometrika, 74, 145–154.
Ross, B. M., & Cameron, E. (2021). Socially accountable medical education: Our story might not be yours. Higher Education Studies, 11(1), 114–120.
Ross, S. J., Preston, R., Lindemann, I. C., et al. (2014). The training for health equity network evaluation framework: A pilot study at five health professional schools. Education for Health (abingdon, England), 27, 116–126.
Schreiber, J. B., Stage, F. K., King, J., Am, N., & Barlow, E. A. (2006). Reporting structural equation modeling and confirmatory factor analysis results: A review. The Journal of Educational Research., 99(6), 323–337.
Skinner, K. M., Miller, D. R., Lincoln, E., Lee, A., & Kazis, L. E. (2005). Concordance between respondent self-reports and medical records for chronic conditions: Experience from the Veterans Health Study. The Journal of ambulatory care management, 28, 102–110.
Smirnova, A., Chahine, S., Milani, C., et al. (2022). Using Resident-Sensitive Quality Measures Derived from Electronic Health Record Data to Assess Residents’ Performance in Pediatric Emergency Medicine. Academic Medicine.
Smith P, Papanicolas, I, (Eds). (2013). Health system performance comparison: an agenda for policy, information and research. Policy summary, 4. Open University Press, Maidenhead, UK. ISBN 9780335247264.
Statistics Canada. Combining cycles of the Canadian Community Health Survey: Findings. 2015b. Available from: https://www150.statcan.gc.ca/n1/pub/82-003-x/2009001/article/10795/findings-resultats-eng.htm.
Statistics Canada. Health indictors consensus conference report: Report from the third consensus conference on health indicators. 2015a. Available from: https://www150.statcan.gc.ca/n1/pub/82-230-x/82-230-x2009001-eng.htm#a1
Statistics Canada. Health Region: Boundaries and correspondence with census geography. Health Regions and peer groups. 2018. Available from: https://www150.statcan.gc.ca/n1/pub/82-402-x/2018001/hrpg-rsgh-eng.htm
Statistics Canada. Census indicator profile, based on the 2016b Census long-form questionnaire, Canada, provinces and territorities, and health regions (2017 boundaries). 2018. Available from: https://www150.statcan.gc.ca/t1/tbl1/en/tv.action?pid=1710012301.
Statistics Canada. (2016). Chapter 1.1: Leadership and coordination of the national statistical system. Available from: https://www150.statcan.gc.ca/n1/pub/11-634-x/2016001/section1/chap1-eng.htm.
Statistics Canada. Statistics Canada data strategy. 2020a. Available from: https://www.statcan.gc.ca/en/about/datastrategy.
Statistics Canada. About us. 2020b. Available from: https://www.statcan.gc.ca/en/about/about?MM=as.
Statistics Canada. Canadian Community Health Survey – Annual Component (CCHS). 2021. Available from: https://www23.statcan.gc.ca/imdb/p2SV.pl?Function=getSurvey&SDDS=3226.
Statistics Canada. Health regions: Boundaries and correspondence with census geography. Geographic files and documentations: 82–402-X. Available from: https://www150.statcan.gc.ca/n1/en/catalogue/82-402-X.
Strasser, R., Worley, P., Cristobal, F., et al. (2015). Putting communities in the driver’s seat: The realities of community-engaged medical education. Academic Medicine, 90, 1466–1470.
Tamblyn, R. (2011). Protecting the public: Is it time for a paradigm shift in expected practice standards? Journal of General Internal Medicine, 26(5), 460–461.
Tamblyn, R., Abrahamowicz, M., Brailovsky, C., et al. (1998). Association between licensing examination scores and resource use and quality of care in primary care practice. JAMA, 280(11), 989–996.
Tamblyn, R., Abrahamowicz, M., Dauphinee, W. D., et al. (2002). Association between licensure examination scores and practice in primary care. JAMA, 288(23), 3019–3026.
Teodorczuk, A., Yardley, S., Patel, R., Rogers, G. D., Billett, S., Worley, P., et al. (2017). Medical education research should extend further into clinical practice. Medical Education, 51(11), 1098–1100.
Thompson, B. E. (2004). Confirmatory factor analysis: Understanding concepts and applications. American Psychological Association.
Thompson, B., & Daniel, L. G. (1996). Factor analytic evidence for the construct validity of scores: A historical overview and some guidelines. Educational and Psychological Measurement., 56(2), 197–208.
Triola, M. M., Hawkins, R. E., & Skochelak, S. E. (2018). The time is now: Using graduates’ practice data to drive medical education reform. Academic Medicine, 93, 826–828.
Ventres, W., Boelen, C., & Haq, C. (2018). Time for action: Key considerations for implementing social accountability in the education of health professionals. Advances in Health Sciences Education: Theory and Practice, 23, 853–862.
Wang, J., & Staver, J. R. (2001). Examining relationships between factors of science education and student career aspiration. Journal of Education Research, 94, 312–319.
Wenghofer, E., Klass, D., Abrahamowicz, M., et al. (2009). Doctor scores on national qualifying examinations predict quality of care in future practice. Med Ed., 43, 1166–1173.
Ottawa Charter for Health Promotion. WHO/HPR/HEP/95.1. WHO, Geneva, 1986.
Yamada, C., Moriyama, K., & Takahashi, E. (2012). Self-rated health as a comprehensive indicator of lifestyle-related health status. Environmental Health and Preventive Medicine, 17(6), 457–462.
Acknowledgements
The authors would like to thank Jimmie Leppink, PhD for his continued support and encouragement throughout this project.
Funding
This research is supported in part by funding from the Social Sciences and Humanities Research Council (SSHRC) Doctoral Fellowship Award.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflict of interests related to the data, research methodologies, funding agencies or any other factor that could be deemed a conflict.
Ethical approval
Ethical approval for this study was obtained from Maastricht University’s Ethics Review Committee Health, Medicine and Life Sciences (FHML-REC).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Canadian Provinces and Territories and Affiliated Health Regions included in the Canadian Community Health Survey (CCHS) 2017–18 Public Use Micro-Data File (PUMF) (n = 97).
Province or Territorya | Health regionsb |
|---|---|
Newfoundland & Labrador | Eastern Regional |
Central Regional | |
Western Regional Health Authority & Labrador-Grenfell Regional Health | |
Prince Edward Island | Prince Edward Island |
Nova Scotia | Zone 1–Western |
Zone 2–Northern | |
Zone 3–Eastern | |
Zone 4–Central | |
New Brunswick | Zone 1 (Moncton area) |
Zone 2 (Saint John area) | |
Zone 3 (Fredericton area) | |
Zone 4 (Edmundston area) & Zone 5 (Campbellton area) | |
Zone 6 (Bathurust area) & Zone 7 (Miramichi area) | |
Quebec | Bas-Saint-Laurent |
Capitale-Nationale | |
Chaudière-Appalaches | |
Région de Laval | |
Région de Lanaudière | |
Région des Laurentides | |
Saguenay-Lac-Saint-Jean | |
L'Estrie | |
Gaspésie-Îles-de-la-Madeleine | |
Mauricie et du Centre-du-Québec | |
Région de Montréal | |
Montérégie | |
L'Outaouais | |
L'Abitibi-Témiscamingue | |
Côte-Nord | |
Ontario | Brant county health unit |
City of hamilton health unit | |
Niagara Regional area health unit | |
Waterloo health unit | |
North Bay parry sound & timiskaming | |
Northwestern health unit | |
Porcupine health unit | |
Renfrew county and district health unit | |
Sudbury and district health unit | |
The District of algoma health unit | |
Thunder Bay District health unit | |
City of Ottawa health unit | |
Eastern Ontario health unit | |
Haliburton, Kawartha, Pine Ridge district health unit | |
Leeds, Grenville and Lanark district health unit | |
Hastings and Prince Edward counties health unit | |
Kingston, Frontenac and Lennox and Addington health unit | |
City of Toronto health unit | |
Durham Regional health unit | |
Halton Regional health unit | |
Peel Regional Health Unit | |
Peterborough County-City health unit | |
Simcoe Muskoka District health unit | |
Wellington-Dufferin-Guelph health unit | |
York Regional health unit | |
Chatham-Kent health unit | |
Elgin-St Thomas health unit | |
Grey Bruce health unit | |
Haldimand-Norfolk health unit | |
Huron & Perth | |
Lambton health unit | |
Middlesex-London health unit | |
Oxford County Health Unit | |
Windsor-Essex County health unit | |
Manitoba | Winnipeg RHA |
Prairie Mountain health | |
Interlake-Eastern regional health | |
Northern Regional health area | |
Southern health | |
Saskatchewan | Sun Country Regional health authority & Five Hills regional health authority & Cypress regional health authority |
Regina Qu’Appelle RHA | |
Sunrise Regional health authority & Kelsey Trail Regional health authority | |
Saskatoon RHA | |
Heartland Regional Health Authority & Prairie North regional health authority | |
Prince Albert Parkland regional health authority | |
Alberta | South zone |
Calgary zone | |
Central zone | |
Edmonton zone | |
North Zone | |
British Columbia | East Kootenay HSDA |
Kootenay-Boundary HSDA | |
Okanagan HSDA | |
Thompson/Cariboo HSDA | |
Fraser east HSDA | |
Fraser north HSDA | |
Fraser south HSDA | |
Richmond HSDA | |
Vancouver HSDA | |
North Shore/Coast Garibaldi HSDA | |
South Vancouver Island HSDA | |
Central Vancouver Island HSDA | |
North Vancouver Island HSDA | |
Northwest HSDA | |
Northern interior HSDA | |
Northeast HSDA | |
Yukon | Yukon |
Northwest Territories | Northwest Territories |
Nunavut | Nunavut |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Barber, C., van der Vleuten, C. & Chahine, S. Validity evidence and psychometric evaluation of a socially accountable health index for health professions schools. Adv in Health Sci Educ 29, 147–172 (2024). https://doi.org/10.1007/s10459-023-10248-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10459-023-10248-5