
Abstract
In contemporary cities, road collapse is one of the most common disasters. This study proposed a framework for assessing the risk of urban road collapse. The framework first established a risk indicator system that combined environmental and anthropogenic factors, such as soil type, pipeline, and construction, as well as other indicators. Second, an oversampling technique was used to create the dataset. The framework then constructed and trained a convolutional neural network (CNN)-based model for risk assessment. The experimental results show that the CNN model (accuracy: 0.97, average recall: 0.91) outperformed other models. The indicator contribution analysis revealed that the distance between the road and the construction site (contribution: 0.132) and the size of the construction (contribution: 0.144) are the most significant factors contributing to road collapse. According to the natural breaks, a road collapse risk map of Foshan City, Guangdong Province, was created, and the risk level was divided into five categories. Nearly 3% of the roads in the study area are at very high risk, and 6% are at high risk levels, with the high risk roads concentrated in the east and southeast. The risk map produced by this study can be utilized by local authorities and policymakers to help maintain road safety.
Similar content being viewed by others

1 Introduction
China’s road network is expanding rapidly. According to the data published by the Ministry of Transport, in 2020, China’s road length is 5,198,100 km, a 29.6% increase over the previous decade (Ministry of Transport of the People’s Republic of China 2021). With the increase in road network, urban road collapse has been a constant occurrence. Frequent urban road collapse accidents have caused severe damage (Wang and Xu 2022). On 7 February 2018, an urban road collapse accident occurred in Chancheng District, Foshan City, Guangdong Province, resulting in 11 fatalities and eight injuries. The direct economic loss was about RMB 53.238 million yuanFootnote 1 (Department of Emergency Management of Guangdong 2019). On 1 December 2019, an urban road collapse accident occurred near Shahe Station of Guangzhou Metro Line 11, resulting in three fatalities and causing a direct economic loss of approximately RMB 20.047 million yuan (Department of Emergency Management of Guangzhou 2020). Conducting urban road collapse risk assessment to realize risk warnings and effective prevention has become crucial for maintaining urban safety (Wang et al. 2022).
The establishment of an assessment model is a crucial step in the urban road collapse risk assessment implementation process. In the field of ground collapse risk assessment, traditional assessment models have been widely utilized, such as the use of the analytic hierarchy process (Wei et al. 2021), the fuzzy comprehension evaluation method (Yan et al. 2012), and the weighted arithmetic mean (Kuliczkowska 2016) to assess the probability of collapse based on lithology, pipelines, and other causal factors. These traditional assessment methods achieve the objective of risk assessment by dividing the assessment units in the area and establishing different weighting systems for each assessment unit. However, the spatial distribution of collapse events and impact factors tends to be discontinuous (Wang et al. 2022), and it is challenging to balance both accuracy and scope when assessing cities with traditional assessment methods (Li, Fan et al. 2020). It is also difficult for traditional assessment methods to achieve quantitative validation of assessment results based on accident cases. Due to the need for quantitative validation of assessment results, machine learning models are beginning to be incorporated into disaster risk assessment (Li, Sheng et al. 2020) in order to achieve the goal of large-scale and accurate assessment. Machine learning models are considered to have stronger predictive performance due to their nonlinear fitting ability and feature extraction (Huang et al. 2017) and have been widely used in disaster risk assessment. For example, convolutional neural network (CNN) models have been used to assess the likelihood of earthquakes (Jena et al. 2021), and integrated models have been used to assess the probability of floods (Li and Hong 2023). Artificial neural networks (ANN) (Yilmaz et al. 2013), support vector machines (Li, Sheng et al. 2020), and random forests (Li, Fan et al. 2020) with logistic regression (Papadopoulou-Vrynioti et al. 2013) have also begun to be used in the field of ground collapse risk assessment. However, the current urban road collapse risk assessment continues to rely heavily on conventional assessment methods.
A further crucial step in achieving urban road collapse risk assessment is to establish a system of assessment indicators. The mechanism of ground collapse is complex, and many factors can contribute to its occurrence. Cui et al. (2017) concluded that fracture zones could regulate the formation of subsurface cavities and create conditions for collapse breeding. Rainfall can diminish the bearing capacity and stability of soils, creating favorable conditions for their collapse (Wang and Xu 2022). Changes in the water level of rivers and groundwater can have a direct impact on the soil, leading to ground subsidence or even collapse (Cui et al. 2017). Factors such as lithology and soil type (Papadopoulou-Vrynioti et al. 2013; Li, Sheng, et al. 2020) can determine the geological structure of the area and the stability of the soil, which are crucial factors influencing the occurrence of collapse. Existing collapse assessment studies rely on geological type and environmental indicators, such as lithology, rainfall, and fracture zones (Yan et al. 2012; Liu et al. 2021). But the occurrence of urban road collapse is the result of a combination of human and natural factors (Wang and Xu 2022). The road collapse that occurred in Chancheng District, Foshan City, in 2018 was caused by lithology, construction, and pipelines (Zhang et al. 2021). Existing urban road collapse risk assessment studies are limited to a few specific factors in the selection of indicators and do not consider the simultaneous inclusion of multiple risk factors in the indicator system, such as assessing the likelihood of road collapse occurrence based solely on pipelines (Kuliczkowska 2016), lithology and rainfall (Xiao and Tian 2019), and construction factors (Liu et al. 2021).
To address the above research gap in urban road collapse risk assessment, we developed a risk assessment framework for urban road collapse. In this framework, a CNN-based risk assessment model is designed to assess risk with data-driven extraction of incident features, and an assessment indicator system that couples human and environmental factors is constructed to support the assessment model. In addition, validation experiments are conducted based on urban roads in Foshan to demonstrate the viability of the framework. The two main contributions of this work are:
-
(1)
A CNN-based risk assessment model is constructed to realize collapse risk assessment under different urban road scenarios.
-
(2)
The problem of significantly extracting collapse sample data in the case of limited collapse accidents is resolved using the data augmentation method.
Section 2 describes the study area and data sources, the methodology used in this study is presented in Sect. 3, and Sect. 4 presents the results and discussion.
2 Data
Foshan is a city in Guangdong Province, located in coastal southeast China, at 113°06’ E, 23°02’ N. The resident population of Foshan is approximately 9.5 million (2020 census), with an area of 3,798 km2. As of 2020, the length of roads (grade 4 and higher) was 5462 km (Foshan Bureau of Transportation 2021). The geological structure of Foshan is typical of the Pearl River Delta, with a wide distribution of soluble rocks that promotes ground collapse (Zhao et al. 2018). From 2014 to 2018, there were 43 serious ground collapse accidents, the majority of which occurred in the east and southeast.
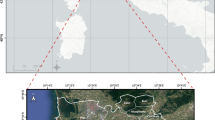
By investigating accident reports and field surveys, 19 collapse cases that occurred on urban roads were selected as accident samples from the 43 ground collapse accidents, and their distribution is shown in Fig. 1.

The Foshan City study area in Guangdong Province, China, and the spatial distribution of the 19 selected ground collapse accidents that occurred on urban roads
A total of 1000 points were randomly selected as negative samples from the entire road network in Foshan. The original dataset is comprised of positive and negative samples, and the dataset is subdivided into training and test sets, as detailed in Table 1.
According to previous research, environmental and anthropogenic factors have a significant impact on the occurrence of urban road collapse (Kuliczkowska 2016; Cui et al. 2017; Wang and Xu 2022). In this study, the indicator system was refined based on the previous research, and the environmental factors were categorized as geological and geoenvironmental, while the anthropogenic factors were categorized as construction, pipeline, and anthropogenic environmental influences.
The geological factors include fracture zone, soil type (ST), lithology, and historical geohazard conditions. The fracture zone variable consists of the distance to fracture zone (DTFZ) and fracture zone length (FZL). Lithology is rock type (RT). Historical geohazard consists of historical ground disaster situation (HGDS) and distance to historic ground hazard sites (DTHS). Geoenvironmental factors include monthly rainfall (MR), river, flood-prone roads, and low-lying areas. The river variable refers to distance to river (DTR). Flood-prone roads is distance to flood-prone areas (DTFA) and low-lying areas is distance to low-lying areas (DTLA). Construction factors include distance to construction site (DTCS) and construction size (CS). Pipelines factors consist of pipeline material (PM), pipeline type (PT), and distance to pipeline (DTP). Anthropogenic environmental influences include metro and road network density (RND). The metro variable is distance to metro line (DTML). The distribution of all variables is shown in Fig. 2; information on the data sources, scale, and collection years of the variables is shown in Table 2.

Influencing factors of road collapse occurrence in Foshan City, Guangdong Province, China: a Fracture zone, b Soil type, c Lithology, d Historical geohazard sites, e Monthly Rainfall, f Rivers, g Pipeline detection point data, h Construction site, i Flood-prone roads, j Low-lying areas, k Metro station, l Road network density.
Considering the difference in indicator value range, z-score normalization was implemented as Eq. 1:
where \({x}_{i}\) is the original value of the \(i\)-th variable; \(x\in R(1, 17)\); \(\mu \,\mathrm{and }\,\sigma\) are the mean value and variance of the variable; and \({y}_{i}\) is the standardized value. Pearson’s coefficient was used to test the correlation between the indicators and was calculated as Eq. 2:
where \(cov(X,Y)\) represents the covariance of the two variables X and Y; and \(Var\left[X\right]\mathrm{ and }Var[Y]\) are the variances of X and Y, respectively.
3 Method
This study presented a CNN-based framework for urban road collapse risk assessment. The three procedures that comprise the proposed framework are depicted in Fig. 3: (1) data collection and processing, (2) data augmentation and model training, and (3) model evaluation and risk mapping. In the data collection and processing section, Foshan’s road collapse data and the indicators needed for the assessment were collected and manually verified, and the original dataset was created. In the data augmentation section, positive samples from the original data were fed into the synthetic minority over-sampling technique (SMOTE) model to generate augmented positive sample data. For model training and testing, the augmented positive sample data were combined with the original data and divided into the training set and test set. The entire original dataset was then also used for model testing to test whether the data augmentation technique used could reduce the impact of small samples on the assessment model. Finally, the urban road collapse risk map for Foshan was created based on the model with the highest performance.

The proposed urban road collapse risk assessment framework for Foshan City, Guangdong Province, China. Note: SMOTE = Synthetic minority over-sampling technique; CNN = Convolutional neural network; ANN = Artificial neutral network.
3.1 Data Augmentation
A characteristic of deep learning models is that they require a large number of samples for training (Dong et al. 2020), and training a model with small samples reduces its ability to recognize the samples, resulting in poor generalization (Kiani et al. 2019). Data augmentation is a common technique for addressing the limited amount of data in small-sample learning (Zhang et al. 2022). Oversampling can achieve data augmentation by increasing the number of minority class samples for efficient model training (Shi et al. 2019). The synthetic minority oversampling technique is one of the most popular algorithms in oversampling (Zhai et al. 2021) and has been widely used in the field of risk assessment, including vehicle crash assessment (Katrakazas et al. 2019), seismic risk assessment (Kourehpaz and Hutt 2022), and wildfire risk assessment (Jiang et al. 2021). The synthetic minority oversampling technique works by first selecting a central sample (containing label and indicator information) in the sample space using k nearest neighbors and then selecting the closest sample with a similar label. To generate a new sample, the distance formula is applied to the central sample and its similar labeled sample, and the distance formula is defined as shown in Eq. 3:
where t is a random number between 0 and 1; \(x\in R(1, 17)\) is the indicator of the central sample; and \(y\in R(1, 17)\) is the indicator of the nearest similar label sample. After applying SMOTE to the positive samples, the generated positive samples are referred to as augmented data. The augmented data are then merged with the original data set and partitioned, as detailed in Table 3. The imbalance rate (IR) is the ratio of negative samples to positive samples and can quantify the degree of imbalance in a data set. Training with a high-IR dataset leads to a poor generalization of the model; 50 was the IR of the original training data, while 1.03 was the IR of the reconstructed training data. Reducing the IR can improve the performance of the model training (Gao, Lu et al. 2021).
3.2 Network Structure
In this study, a CNN-based risk assessment model was constructed to assess the risk of road collapse. Convolutional neural network is one of the most popular deep learning algorithms (Krizhevsky et al. 2017) and was first proposed by LeCun et al. (1989). It performs exceptionally well in disaster risk assessment, including earthquake (Jena et al. 2020), flood (Chen et al. 2021), and landslide risk assessment (Gao, Chen et al. 2021; Hong et al. 2021; Lv et al. 2022).
Figure 4 depicts the network architecture of the CNN constructed for this study. The input data had a dimension of 1 by 17, which correspond to the standard values of the risk indicators. The model’s core network consisted of four convolutional layers and three fully connected layers with respective dimensions of 512, 256, and 32. There were 16, 32, 64, and 64 convolutional kernels utilized. The output layer had a dimension of 2, a binary label, and the binary values represented the probability that the output was a positive or negative sample.

Convolutional neural network (CNN) structure constructed for this study
In the \(l\)-th convolutional layer, the forward tensor propagation calculation is as shown in Eq. 4:
where \({x}_{I,j}^{l}\) is the output of the \(l\)-th convolutional layer; \(f\left({x}_{i,j}^{l}\right)=\mathrm{max}(0,{x}_{i,j}^{l})\) is the activation function; \({W}_{m,n}^{l}\) and \({b}^{l}\) are the weight parameters and bias parameters of the l layer, respectively; \({K}_{1}^{l}\) and \({k}_{2}^{l}\) are the size of the convolutional kernel, and \(H\) and \(W\) represent the size of the output tensor from the upper layer. The mean squared error (MSE) loss function is utilized to compute the degree of disparity between the network predicted values and the actual sample values, as defined by Eq. 5:
where \(N\) is the batch size, \(a\) is the predicted value of the model output; \(y\) is the value of the real sample; \(t\in R(1, N)\). Based on the value derived from the loss function, the weight gradient of the l-th convolutional layer can be calculated by the chain rule, as defined in Eq. 6:
where \(\frac{\partial L}{{\partial x}_{i,j}^{l}}\) denotes the partial derivative of the loss function on the l-layer’s output; and \(\frac{{\partial x}_{i,j}^{l}}{{\partial w}_{m,n}^{l}}\) is the partial derivative of the l-layer’s output to the weights. Eventually, the model parameters are continuously optimized through training. In addition, the artificial neutral network (ANN) (Yao 1999) was evaluated and contrasted with the CNN.
3.3 Network Configurations
The CNN model utilized in this study was implemented in the Pytorch machine learning framework, with all the network training and testing performed on a server with 32 GB RAM and a GTX1080 GPU. Throughout the training period, the initial learning rate was 1×10-4, the batch size was 32, and L2 regularization was implemented. The network uses the MSE loss function to calculate the network loss. The MSE loss of the network on the training data set stopped decreasing after 1.5×10 iterations, and the final MSE loss converged to 1.07×10-3.
3.4 Model Evaluation
Several evaluation metrics, such as accuracy, average recall, AUC, and specificity, were used to evaluate the performance of the models when they were developed and implemented. These metrics are calculated as follows:
where TP (true positive) and FP (false positive) represent the amount of data rightly labeled and mislabeled as collapse, TN (true negative) and FN (false negative) are the amount of data rightly labeled and mislabeled as non-collapse, P represents all collapse data, N represents all non-collapse data, k represents the number of sample categories, \({x}_{i}\) represents a particular indicator to be computed, \(j\in R(1, 17)\), \(shuffle({x}_{i})\) means that all samples are shuffled, and their i-th indicator value is randomly swapped, \(L(shuffle\left({x}_{j}\right))\) is the loss value of the shuffled samples fed into the network after it has been trained.
4 Results and Discussion
This section presents the experimental results of the model, a model-based risk map, the impact of the indicators on the model, and a discussion of an actual case.
4.1 Model Results
The correlation test of the indicators is performed before the model training and validation phase, and this step is mainly to reduce the influence of highly correlated indicator factors on the model. Spearman correlation coefficients were calculated for 17 indicator factors; DTML and MR had the highest correlation, with a correlation coefficient of − 0.7. If the correlation coefficient does not exceed 0.7 or − 0.7, each indicator factor can be considered independent of the other, as shown in Fig. 5.

Pearson’s correlation coefficients for the indicators Note: DTFZ = Distance to fracture zone; FZL = Fault zone length; MR = Monthly rainfall; DTR = Distance to river; DTCS = Distance to construction site; CS = Construction size; DTFA = Distance to flood-prone areas; DTLA = Distance to low-lying areas; DTHS = Distance to historic ground hazard sites; DTML = Distance to metro line; DTP = Distance to pipeline; ST = Soil type; RT = Rock type; HGDS = Historical ground disaster situation; PM = Pipeline material; PT = Pipeline type; RND = Road network density.
Table 4 displays the accuracy of the models on the training set data, with the ANN* model achieving the highest accuracy of 0.9974, followed by CNN* (0.9955), ANN (0.9865), and CNN (0.9865). The average recall and specificity share similar attributes.
Table 5 depicts the model on the test set data, where CNN has the highest accuracy with 0.9950, followed by CNN* (0.9949), and the average recall of the ANN model trained on the original data decreases significantly from 0.9012 to 0.8308.
As shown in Table 6, the original dataset is also used to evaluate the model’s accuracy to determine whether our proposed data augmentation strategy is effective at enhancing model performance; CNN* continues to have the highest accuracy at 0.9695, followed by CNN (0.9911), ANN* (0.9558), and ANN (0.9509). However, the average recall values of ANN, CNN, and ANN* have decreased to 0.7183, 0.7631, and 0.7967, respectively, while CNN*’s average recall remains at 0.8812. The ROC curves of the models based on the original data are plotted in Fig. 6, which shows that the AUC values of all the models are greater than 0.9, but CNN* has the highest AUC value of all the models at 0.957.

ROC curves on the original dataset
4.2 Risk Map
The road risk map of Foshan was created based on the CNN* model. According to the natural breaks, the risk level was divided into five categories: very low, low, moderate, high, and very high. From low to high, the risk levels of Foshan’s roads are 55%, 25%, 11%, 6%, and 3%, respectively. Figure 7 depicts the proportion of high-risk roads in each district. The proportion of high risk roads in Nanhai and Shunde is 6% and 10%, respectively, which is greater than the city average; and 8% of the roads in Shunde pose a very high risk of collapse, a much higher proportion than in other districts.

Percentage of roads with different risk levels in each district of Foshan City, Guangdong Province, China
Figure 8 presents the risk map of each region based on CNN. In the east and south, high risk roads show a block distribution, while the southeast and parts of the north show a scattered distribution. There are fewer high-risk roads in Sanshui, and even fewer in the city’s central areas. The majority of moderate and high risk roads in Chancheng are located in the east. There are fewer high risk roads in Sanshui, and only a few exist in the central areas. The majority of Gaoming’s moderate and high risk roads are located in the southeast and southwest. The moderate and high risk roads in Nanhai are dispersed in the north, center, and south. The majority of Shunde’s high and very high risk roads are located in the north and southeast, with a few high risk roads in the south.

Road collapse risk map: a Foshan City, b Chancheng District, c Gaoming District, d Nanhai District, e Sanshui District, and f Shunde District.
4.3 Risk Indicator Analysis
As shown in Fig. 9, the contribution index was used to determine the relative importance of the influencing factors to the model. Due to the complex relationship between the factors and the model, the contribution of each factor to the model varies. The results indicate that urban road collapse is primarily caused by construction, with DTCS (contribution 0.144) and CS (contribution 0.132) ranking as the top two contributors to the CNN* model, followed by environmental factors such as DTLA (contribution 0.120), DTR (contribution 0.094), MR (contribution 0.093), and DTFA (contribution 0.092).

Contribution of the influencing factors to road collapse in Foshan City, Guangdong Province, China. Note: DTCS = Distance to construction site; CS = Construction size; DTLA = Distance to low-lying areas; DTR = Distance to river; MR = Monthly rainfall; DTFA = Distance to flood-prone areas; DTHS = Distance to historic ground hazard sites; FZL = Fault zone length; DTP = Distance to pipeline; ST = Soil type; DTML = Distance to metro line; PM = Pipeline material; PT = Pipeline type; HGDS = Historical ground disaster situation; RND = Road network density; RT = Rock type; DTFZ = Distance to fracture zone.
The intersection of the three regions of Gaoming District, Chancheng District, and Shunde District is where the city’s moderate and high risk roads are most concentrated on the risk map. There are numerous construction sites and extensive earth excavations in the area (see Fig. 2h), which greatly increases the risk of road collapse. There are a number of minor rivers in the region (see Fig. 2f), and the impact of rivers on the soil increases the possibility of collapse. The area serves as one of the Foshan Metro’s transportation hubs, and the dense subway lines (see Fig. 2k) may cause disturbance to the soil along the line. This area also has the highest road network density (see Fig. 2l) in Foshan. Dense road networks are accompanied by high road loads, increasing the risk of road collapse.
Figure 10 depicts the variation in the average recall of the CNN* model for the top three contributors as each indicator’s value changes. The results indicate that the average recall of the model decreases as the value of the DTCS variable increases, indicating that the probability of collapse increases as the road approaches the construction site. Second, in the CS variable, it was discovered that the risk of road collapse increases as the size of the construction site increases; however, at a certain point, the risk of collapse decreases, which may be because large sites pay more attention to the safety feasibility assessment before construction. Increased precipitation and the distance, or proximity, to low-lying areas (DTLA) increases the risk of road collapse, but this increase is limited.

Effect of variable changes on CNN* models. a Distance to construction site (DTCS), b Size of construction (CS), and c Distance to low-lying areas (DTLA).
4.4 Accident Case Discussion
On 28 November 2022 at 19:00, an urban road collapse accident occurred at the intersection of Lingnan Avenue and Kuiqi Road in Chancheng District. The collapsed area is about 800 m2, the depth is approximately 0.5 m, and the water depth in the pit is about 0.5 m. The location of the accident is shown in Fig. 11. There were three construction sites within 500 m of the collapsed road, as well as two cast-iron water supply pipes with a diameter of 600 mm that existed beneath the road. The collapsed road is 440 m from the closest Metro line and 1.97 km from the nearby river. In November, affected by Typhoon Nalgae (China Meteorological Administration 2022), the accident road was severely flooded and washed away by rain. Figure 11 shows the collapsed road and the surrounding conditions. The possible causes of the collapse were: (1) The types of nearby buildings under construction are high-rise structures with deep excavations and soil disturbance; (2) The collapsed road is near the Metro, where road collapse had occurred several times, and this area belongs to the collapse-prone area; (3) The collapsed road had been waterlogged due to the heavy rainfall caused by Typhoon Nalgae in November; (4) The nearby river banks are constantly eroded by the long-term action of the river, and there had been several collapses along the banks; (5) The regional temperature changed dramatically around 28 November (National Weather Science Data Center 2022), and the water supply pipes were not buried deep enough to meet the insulation requirements. The cast iron material has poor tensile properties, and the pipeline ruptures under temperature stress. The water flow hollowed out the ground, and a collapse accident occurred. Our proposed indicator system and risk assessment results are reflected in this case.

Factors near the collapsed road and site conditions in Chancheng District, Foshan City, in November 2022
5 Conclusion
This study proposed a new framework for multifactorial urban road collapse risk assessment. Using a combination of environmental and anthropogenic factors, this framework developed an indicator system for risk assessment. Then, SMOTE was utilized to implement data augmentation on the collected accident samples in order to create a dataset of urban road collapse accidents that was used to train the CNN model. The experimental results demonstrate that the CNN model trained with the augmented data significantly outperformed the other models on the original data (accuracy of 0.97, average recall of 0.91, and specificity of 0.97). By training the network with augmented data, the proposed framework effectively improved the precision of the risk assessment for urban road collapse. The road collapse risk map of Foshan was created using this model. Through indicator contribution analysis, it was determined that the distance between the road and the construction site, as well as the size of the construction, were the most influential factors in road collapse. A recent accident case confirmed the results of the indicator system and model evaluation concluded in this study. Local governments and policymakers can use the urban road collapse risk map generated by this study to maintain the safety of road collapse-prone areas.
Notes
USD 1 = RMB 7.04.
References
Chen, J.L., G.R. Huang, and W.J. Chen. 2021. Towards better flood risk management: Assessing flood risk and investigating the potential mechanism based on machine learning models. Journal of Environmental Management 293: 12810.
China Meteorological Administration. 2022. Guangdong: Pursue advantages and avoid disadvantages to deal with typhoon "Nige". http://www.cma.gov.cn/2011xwzx/2011xgzdt/202211/t20221107_5166943.html. Accessed 15 May 2023 (in Chinese).
Cui, L., J. Huang, X. Wu, J. Chen, G. Jiang, and S. Xu. 2017. The control of the formation of karst collapse through the ancient Yellow River Fault zone in Xuzhou China. Carbonates and Evaporites 34(1): 1–10.
Department of Emergency Management of Guangdong. 2019. Investigation report on the major accident of the collapse of rail transit line 2 in Foshan City, Guangdong Province, 2018. http://yjgl.gd.gov.cn/gk/zdlyxxgk/sgdcbg/content/post_2511537.html. Accessed 15 May 2023 (in Chinese).
Department of Emergency Management of Guangzhou. 2020. Guangzhou Tianhe District under construction rail transit collapse accident investigation report. http://yjglj.gz.gov.cn/zwgk/zdlyxxgk/scaqsgdcbgxx/content/post_5832879.html. Accessed 15 May 2023 (in Chinese).
Dong, Z.H., R.X. Zhang, X.L. Shao, and Z.S. Kuang. 2020. Learning sparse features with lightweight ScatterNet for small sample training. Knowledge-Based Systems 205: 106315.
Foshan Bureau of Transportation. 2021. 2019 traffic statistics. http://jtys.foshan.gov.cn/zwgk/tjsj/content/post_4868689.html. Accessed 15 May 2023 (in Chinese).
Gao, L., P. Lu, and Y.H. Ren. 2021. A deep learning approach for imbalanced crash data in predicting highway-rail grade crossings accidents. Reliability Engineering & System Safety 216: Article 108019.
Gao, X., T. Chen, R.Q. Niu, and A. Plaza. 2021. Recognition and mapping of landslide using a fully convolutional DenseNet and influencing factors. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 14: 7881–7894.
Hong, D.F., L.R. Gao, N. Yokoya, J. Yao, J. Chanussot, Q. Du, and B. Zhang. 2021. More diverse means better: Multimodal deep learning meets remote-sensing imagery classification. IEEE Transactions on Geoscience and Remote Sensing 59(5): 4340–4354.
Huang, F.M., J.S. Huang, S.H. Jiang, and C.B. Zhou. 2017. Landslide displacement prediction based on multivariate chaotic model and extreme learning machine. Engineering Geology 218: 173–186.
Jena, R., B. Pradhan, G. Beydoun, A.M. Alamri, Nizamuddin Ardiansyah, and H. Sofyan. 2020. Earthquake hazard and risk assessment using machine learning approaches at Palu Indonesia. Science of the Total Environment 749: Article 141582.
Jena, R., B. Pradhan, S.P. Naik, and A.M. Alamri. 2021. Earthquake risk assessment in NE India using deep learning and geospatial analysis. Geoscience Frontiers 12(3): 101110.
Jiang, T., S.K. Bendre, H. Lyu, and J. Luo. 2021. From static to dynamic prediction: Wildfire risk assessment based on multiple environmental factors. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), 15–18 December 2021, Orlando, FL, USA, 4877–4886.
Katrakazas, C., M. Quddus, and W.H. Chen. 2019. A new integrated collision risk assessment methodology for autonomous vehicles. Accident Analysis and Prevention 127: 61–79.
Kiani, J., C. Camp, and S. Pezeshk. 2019. On the application of machine learning techniques to derive seismic fragility curves. Computers & Structures 218: 108–122.
Kourehpaz, P., and C.M. Hutt. 2022. Machine learning for enhanced regional seismic risk assessments. Journal of Structural Engineering. https://doi.org/10.1061/(asce)st.1943-541x.0003421.
Krizhevsky, A., I. Sutskever, and G.E. Hinton. 2017. ImageNet classification with deep convolutional neural networks. Communications of the ACM 60(6): 84–90.
Kuliczkowska, E. 2016. The interaction between road traffic safety and the condition of sewers laid under roads. Transportation Research Part D: Transport and Environment 48: 203–213.
LeCun, Y., B. Boser, J.S. Denker, D. Henderson, R.E. Howard, W. Hubbard, and L.D. Jackel. 1989. Backpropagation applied to handwritten zip code recognition. Neural Computation 1(4): 541–551.
Li, Y.T., and H.Y. Hong. 2023. Modelling flood susceptibility based on deep learning coupling with ensemble learning models. Journal of Environmental Management 325: 116450.
Li, Y.Y., Y.F. Sheng, B. Chai, W. Zhang, T.L. Zhang, and J.J. Wang. 2020. Collapse susceptibility assessment using a support vector machine compared with back-propagation and radial basis function neural networks. Geomatics Natural Hazards & Risk 11(1): 510–534.
Li, W.B., X.M. Fan, F.M. Huang, W. Chen, H.Y. Hong, J.S. Huang, and Z.Z. Guo. 2020. Uncertainties analysis of collapse susceptibility prediction based on remote sensing and GIS: Influences of different data-based models and connections between collapses and environmental factors. Remote Sensing 12(24): 4134.
Liu, Y., F. Tan, Y. Jiao, J. Wang, and W. Wang. 2021. Risk assessment of ground collapse based on finite interval cloud model. Safety and Environmental Engineering 28(4): 115–120.
Lv, L., T. Chen, J. Dou, and A. Plaza. 2022. A hybrid ensemble-based deep-learning framework for landslide susceptibility mapping. International Journal of Applied Earth Observation and Geoinformation 108: Article 102713.
Ministry of Transport of the People's Republic of China. 2021. 2020 national highway statistics bulletin. https://xxgk.mot.gov.cn/2020/jigou/glj/202110/t20211027_3623195.html. Accessed 15 May 2023 (in Chinese).
National Weather Science Data Center. 2022. Hourly observation data of surface meteorological stations in China. https://data.cma.cn/data/cdcdetail/dataCode/A.0012.0001.html. Accessed 15 May 2023 (in Chinese).
Papadopoulou-Vrynioti, K., G.D. Bathrellos, H.D. Skilodimou, G. Kaviris, and K. Makropoulos. 2013. Karst collapse susceptibility mapping considering peak ground acceleration in a rapidly growing urban area. Engineering Geology 158: 77–88.
Shi, H., Y. Chen, and X. Chen. 2019. Summary of research on SMOTE oversampling and its improved algorithms. CAAI Transactions on Intelligent Systems 14: 1073–1083.
Wang, X., and Y. Xu. 2022. Investigation on the phenomena and influence factors of urban ground collapse in China. Natural Hazards 113(1): 1–33.
Wang, K., J.W. Zhang, G.Q. Gao, J.L. Qiu, Y.J. Zhong, C.X. Guo, W.C. Zhao, K.J. Tang, and X.L. Su. 2022. Causes, risk analysis, and countermeasures of urban road collapse in China from 2019 to 2020. Journal of Performance of Constructed Facilities. https://doi.org/10.1061/(asce)cf.1943-5509.0001765.
Wei, A.H., D. Li, Y.H. Zhou, Q. Deng, and L.D. Yan. 2021. A novel combination approach for karst collapse susceptibility assessment using the analytic hierarchy process, catastrophe, and entropy model. Natural Hazards 105(1): 405–430.
Xiao, W., and W.P. Tian. 2019. Hazard assessment and zoning of collapse along highways in China based on backward cloud algorithm. Geomatics Natural Hazards & Risk 10(1): 1227–1241.
Yan, J., Y. Cheng, A. Zhang, and Y. Zhao. 2012. The evaluation of highway collapse hazard based on the fuzzy comprehensive evaluation method. In Proceedings of the 2nd International Conference on Civil Engineering and Transportation (ICCET 2012), 27–28 October 2013, Guilin, China, 1593–1597.
Yao, X. 1999. Evolving artificial neural networks. Proceedings of the IEEE 87(9): 1423–1447. https://doi.org/10.1109/5.784219.
Yilmaz, I., M. Marschalko, and M. Bednarik. 2013. An assessment on the use of bivariate, multivariate and soft computing techniques for collapse susceptibility in GIS environ. Journal of Earth System Science 122(2): 371–388.
Zhai, J., J. Qi, and S. Zhang. 2021. Imbalanced data classification based on diverse sample generation and classifier fusion. International Journal of Machine Learning and Cybernetics 13(3): 735–750.
Zhang, Y., W. Zhu, C. Zhao, and B. Han. 2021. Moniting and inversion of Foshan metro collapse with multi-temporal Insar and field investigation. Journal of Engineering Geology 29(4): 1167–1177.
Zhang, A., H. Yu, Z. Huan, X. Yang, S. Zheng, and S. Gao. 2022. SMOTE-RkNN: A hybrid re-sampling method based on SMOTE and reverse k-nearest neighbors. Information Sciences 595: 70–88.
Zhao, W., F.P. Gan, Y. Meng, Z.J. Zheng, and X.M. Liu. 2018. Application of seismic velocity tomography in investigation of karst collapse hazards, Guangzhou. China. Environmental Earth Sciences. https://doi.org/10.1007/s12665-018-7419-1.
Acknowledgments
This research was supported by the Guangdong Provincial Key Laboratory of New Construction Technology for Urban Rail Transit Engineering (2017B030302009).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jiang, J., Wang, F., Wang, Y. et al. An Urban Road Risk Assessment Framework Based on Convolutional Neural Networks. Int J Disaster Risk Sci 14, 475–487 (2023). https://doi.org/10.1007/s13753-023-00498-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13753-023-00498-7