
Abstract
The safe-consensus task was introduced by Afek, Gafni and Lieber (DISC’ 09) as a weakening of the classic consensus. When there is concurrency, the consensus output can be arbitrary, not even the input of any process. They showed that safe-consensus is equivalent to consensus, in a wait-free system. We study the solvability of consensus in three shared memory iterated models extended with the power of safe-consensus black boxes. In the first iterated model, for the i-th iteration, the processes write to memory, then they snapshot it and finally they invoke safe-consensus boxes. We prove that in this model, consensus cannot be implemented. In a second iterated model, processes first invoke safe-consensus, then they write to memory and finally they snapshot it. We show that this model is equivalent to the previous model and thus consensus cannot be implemented. In the last iterated model, processes write to the memory, invoke safe-consensus boxes and finally they snapshot the memory. We show that in this model, any wait-free implementation of consensus requires \(\Omega (n^{2})\) safe-consensus black-boxes and this bound is tight.
Similar content being viewed by others


1 Introduction
The ability to agree on a common decision is key to distributed computing. The most widely studied agreement abstraction is consensus. In the consensus task each process proposes a value, and all correct processes have to decide the same value. In addition, validity requires that the decided value is a proposed value.
Herlihy’s seminal paper [1] examined the power of different synchronization primitives for wait-free computation, e.g., when computation completes in a finite number of steps by a process, regardless of how fast or slow other processes run, and even if some of them halt permanently. He showed that consensus is a universal primitive, in the sense that a solution to consensus (with read/write registers) can be used to implement any synchronization primitive in a wait-free manner. Also, consensus cannot be wait-free implemented from read/write registers alone [2, 3]; indeed, all modern shared-memory multiprocessors provide some form of universal primitive.
Afek, Gafni and Lieber [4] introduced safe-consensus, which seemed to be a synchronization primitive much weaker than consensus. The validity requirement becomes: if the first process to invoke the task returns before any other process invokes it, then it outputs its input; otherwise, when there is concurrency, the consensus output can be arbitrary, not even the input of any process. In any case, all processes must agree on the same output value. Trivially, consensus implements safe-consensus. Surprisingly, they proved that the converse is also true, by presenting a wait-free implementation of consensus using safe-consensus black-boxes and read/write registers. Why is it then, that safe-consensus seems a much weaker synchronization primitive?
Our Results. We show that while consensus and safe-consensus are wait-free equivalent, any wait-free implementation of consensus for n processes in an iterated model (with the appropriate order of snapshot and safe-consensus operations) requires \({n \atopwithdelims ()2}\) safe-consensus black-boxes, and this bound is tight.
Our main result is the lower bound. It uses connectivity arguments based on subgraphs of Johnson graphs, and an intricate combinatorial and bivalency argument, that yields a detailed bound on how many safe-consensus objects of each type (i.e., which processes and how many processes invoke a safe-consensus object) are used by the implementation protocol. For the upper bound, we present a simple protocol, based on the new g-2coalitions-consensus task, which may be of independent interestFootnote 1.
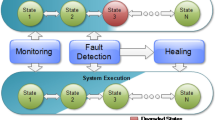
We develop our results in an iterated model of computation [6], where the processes repeatedly: write their information to a (fresh) shared array, invoke (fresh) safe-consensus boxes and snapshot the contents of the shared array.
Also, we study the solvability of consensus in two alternate iterated models extended with safe-consensus. In the first model, the processes write to memory, then they snapshot it and finally they invoke safe-consensus boxes. We prove that in this model, consensus cannot be implemented from safe-consensus. In the second model, processes first invoke safe-consensus, then they write to shared memory and finally they snapshot the contents of the memory. We show that this model is equivalent to the previous model and thus consensus cannot be solved in this model.
Related Work. Distributed computing theory has been concerned from early on with understanding the relative power of synchronization primitives. The wait-free context is the basis to study other failure models e.g. [7], and there is a characterization of the wait-free, read/write solvable tasks [8]. For instance, the weakening of consensus, set agreement, where n processes may agree on at most \(n-1\) different input values, is still not wait-free solvable [8,9,10] with read/write registers only. The renaming task where n processes have to agree on at most \(2n-1\) names has also been studied in detail e.g. [11,12,13,14,15].
Iterated models e.g. [6, 16,17,18,19,20] facilitate impossibility results, and (although more restrictive) facilitate the analysis of protocols [21]. We follow in this paper the approach of [22] that used an iterated model to prove the separation result that set agreement can implement renaming but not vice-versa, and expect our result can be extended to a general model using simulations, as was done in [23] for that separation result. For an overview of the use of topology to study computability, including the use of iterated models and simulations see [24].
Afek, Gafni and Lieber [4] presented a wait-free protocol that implements consensus using \({n \atopwithdelims ()2}\) safe-consensus black-boxes (and read/write registers). Since our implementation uses the iterated form of shared-memory, it is easier to prove correct. Safe-consensus was used in [4] to show that the g-tight-group-renaming taskFootnote 2 [25] is as powerful as g-consensus.
The idea of the classical consensus impossibility result [2, 3] is (roughly speaking) that the executions of a protocol in such a system can be represented by a graph which is always connected. The connectivity invariance has been proved in many papers using the critical state argument introduced in [2], or sometimes using a layered analysis as in [26]. Connectivity can be used also to prove time lower bounds e.g. [26,27,28]. We extend here the layered analysis to prove the lower bound result on the number of safe-consensus objects needed to implement consensus. Also, our results show that when the basic shared memory iterated model is used with objects stronger than read/write memory, care has be taken in the way they are added to the model, as the resulting power of the model to solve tasks can vary.
In a previous work [29] we had already studied an iterated model extended with the power of safe-consensus. However, that model had the restriction that in each iteration, all processes invoke the same safe-consensus object. We showed that set agreement can be implemented, but not consensus. The impossibility proof uses much simpler connectivity arguments than those of this paper.
Organization. The paper is organized as follows. Section 2 describes the basic concepts and previous results of the models of computation. This section can be skipped by readers familiar with standard distributed computing notions. Section 3 defines the three iterated models of computation that we investigate and also we present the main results for each model. Section 4 is dedicated to our first iterated model with safe-consensus. In this model, the processes first write to memory, then they snapshot the contents of the memory and after that, they invoke safe-consensus objects. We prove that in this model, consensus cannot be implemented. In Section 4.2, we develop our second iterated model extended with safe-consensus. In this model, the processes first invoke safe-consensus objects, then they write to the memory and finally, they snapshot the shared memory. We prove that this model is equivalent to the previous model (for task solvability), thus the consensus task cannot be implemented in this model. Section 5 is devoted to develop all the results obtained for our last iterated model, in it the processes write to memory, invoke the safe-consensus objects and then they snapshot the shared memory. For this model, our results are the following:
-
We construct a protocol that solves n-process consensus using \({n \atopwithdelims ()2}\) safe-consensus boxes (Section 5.2). We give our consensus protocol using the new 2coalitions-consensus task, which is described in full detail in Section 5.1.
-
We describe and prove the main result for this iterated model, which is also the main result of this paper, it is a lower bound on the number of safe-consensus objects needed to solve consensus in this iterated model (Section 5.3).
In Section 6 we give our final conclusions and some open problems.
2 Basic Definitions
In this section, we introduce the model of computation and present many basic concepts used in this paper. We follow the usual definitions and extend some concepts from [30, 31].
2.1 Distributed Systems
Our formal model is an extension of the standard iterated version [16] of the usual read/write shared memory model e.g. [31]. A process is a deterministic state machine, which has a (possible infinite) set of local states, including a subset called the initial states and a subset called the output states.
A shared object \(\textsf{O}\) has a domain D of input values, and a domain \(D^\prime \) of output values. \(\textsf{O}\) provides a unique operation, \(\textsf{O}.exec(d)\), that receives an input value \(d\in D\) and returns an output value \(d^\prime \in D^\prime \).
A one-shot snapshot object A is a shared memory array \(A\left[ 1,\ldots ,n\right] \) with one entry per process. That array is initialized to \(\left[ \bot ,\ldots ,\bot \right] \), where \(\bot \) is a default value that cannot be written by a process. The snapshot object A provides two atomic operations that can be used by a process at most once:
-
\(A.\textsf {update}(v)\): when called by process \(p_j\), it writes the value v to the register \(A\left[ j\right] \).
-
\(A.\textsf {scan} ()\): returns a copy of the whole shared memory array A.
It is also customary to make no assumptions about the size of the registers of the shared memory, and therefore we may assume that each process \(p_i\) can write its entire local state in a single register. Notice that the snapshot operation can be implemented in read/write shared memory, according to [32, 33].
A system consists of the following data:
-
A set of \(n \geqslant 1\) processes \(\Pi = \{ p_1, \ldots , p_n \}\);
-
a shared memory \(SM\left[ i \right] \) (\(i \geqslant 0\)) structured as an infinite sequence of one-snapshot objects;
-
an infinite sequence \(\textsf{S} \left[ j \right] \) (\(j \geqslant 0\)) of shared objects.
A global state of a system is a vector P of the form
where \(s_i\) is the local state of process \(p_i\in \Pi \) and SM is the shared memory of the system. An initial state is a state in which every local state is an initial local state and all registers in the shared memory are set to \(\bot \). A decision state is a state in which all local states are output states. When referring to a global state P, we usually omit the word global and simply refer to P as a state.
2.2 Events and Round Schedules
An event in the system is performed by a single process \(p_i\in \Pi \), which applies only one of the following actions: a write (update) operation, denoted by W or a read (scan) operation, denoted by R, on the shared memory or an invocation to a shared object (S). Any of these operations may be preceded/followed by some local computation, formally a change of the process to its next local state. We will need to consider events performed concurrently by the processes. If E is any event and \(p_{i_1},\ldots , p_{i_k}\in \Pi \) are processes, then we denote the fact that \(p_{i_1},\ldots , p_{i_k}\) execute concurrently the event E by \(\textsf {E}(X)\), where \(X=\{i_1,\ldots , i_k\}\).
We fix once and for all some notation. Let \(\overline{n}=\{1,\ldots ,n\}\), when convenient, we will denote \(\textsf {E}(X)\) by \(\textsf {E}(i_1, \ldots , i_k)\) and if \(i\in \overline{n}\) is a process id, then \(\textsf {E}(\overline{n}-\{ i\})\) is written simply as \(\textsf {E}(\overline{n}-i)\).
A round schedule \(\pi \) is a finite sequence of events of the form
that encodes the way in which the processes with ids in the set \(\bigcup _{j=1}^r X_j\) perform the events \(\textsf {E}_1,\ldots ,\textsf {E}_r\). For example, the round schedule given by
means that processes \(p_1,p_3\) perform the write and read events concurrently; after that, \(p_2\) executes solo its read and write events and finally all three processes invoke the shared objects concurrently. Similarly, the round schedule \(\textsf {W}(1,2,3),\textsf {R}(1,2,3),\) \(\textsf {S}(1,2,3)\) says that \(p_1,p_2\) and \(p_3\) execute concurrently the write and read events in the shared memory and then they invoke the shared objects concurrently.
2.3 Protocols and Executions
The state machine of each process \(p_i\in \Pi \) is called a local protocol \(\mathcal {A}_i\), that determines the steps taken by \(p_i\). We assume that all local protocols are identical; i.e. Processes have the same state machine. A protocol is a collection \(\mathcal {A}\) of local protocols \(\mathcal {A}_1,\ldots ,\mathcal {A}_n\).
For the sake of simplicity, we will give protocols specifications using pseudocode and we establish the following conventions: A lowercase variable denotes a local variable, with a subindex that indicates to which process it belongs; the shared memory (which is visible to all processes) is denoted with uppercase letters. Intuitively, the local state \(s_i\) of process \(p_i\) is composed of the contents of all the local variables of \(p_i\). Also, we identify two special components of each process’ states: an input and an output. It is assumed that initial states differ only in the value of the input component; moreover, the input component never changes. The protocol cannot overwrite the output, it is initially \(\bot \); once a non-\(\bot \) value is written to the output component of the state, it never changes; when this occurs, we say that the process decides. The output states are those with non-\(\bot \) output values.
Let \(\mathcal {A}\) be a protocol. An execution of \(\mathcal {A}\) is a finite or infinite alternating sequence of states and round schedules
where \(S_0\) is an initial state and for each \(k\geqslant 1\), \(S_k\) is the resulting state of applying the sequence of events performed by the processes in the way described by the round schedule \(\pi _{k}\). An r-round partial execution of \(\mathcal {A}\) is a finite execution of \(\mathcal {A}\) of the form \(S_0,\pi _1,\ldots ,S_{r-1},\pi _r,S_r\).
If P is a state, P is said to be reachable in \(\mathcal {A}\) if there exists an r-round partial execution of \(\mathcal {A}\) \((r\geqslant 0)\) that ends in the state P and when there is no confusion about which protocol we refer to, we just say that P is reachable.
Given the protocol \(\mathcal {A}\) and two states S, R, we say that R is a successor of S in \(\mathcal {A}\), if there exists an execution \(\alpha \) of \(\mathcal {A}\) such that
i.e., starting from S, we can run the protocol \(\mathcal {A}\) k rounds (for some \(k\geqslant 0\)) such that the system enters state R. If \(\pi \) is any round schedule and S is a state, the successor of S in \(\mathcal {A}\) obtained by running the protocol (starting in the state S) one round with the round schedule \(\pi \) is denoted by \(S\cdot \pi \).
2.4 Decision Tasks
In distributed computing, a decision task is a problem that must be solved in a distributed system. Each process starts with a private input value, communicates with the others, and halts with a private output value. Formally, a decision task \(\Delta \) is a relation that has a domain \(\mathcal {I}\) of input values and a domain \(\mathcal {O}\) of output values; \(\Delta \) specifies for each assignment of the inputs to processes on which outputs processes can decide. A bounded decision task is a task whose number of input values is finite.
We also refer to decision task simply as tasks. Examples of tasks includes consensus [2], renaming [25, 33] and the set agreement task [34].
A protocol \(\mathcal {A}\) solves a decision task \(\Delta \) if any finite execution \(\alpha \) of \(\mathcal {A}\) can be extended to an execution \(\alpha ^\prime \) in which all processes decide on values which are allowable (according to \(\Delta \)) for the inputs in \(\alpha \). Because the outputs cannot be overwritten, if a process has decided on a value in \(\alpha \), it must have the same output in \(\alpha ^\prime \). This means that outputs already written by the processes can be completed to outputs for all processes that are permissible for the inputs in \(\alpha \).
A protocol \(\mathcal {A}\) is wait-free if in any execution of \(\mathcal {A}\), a process either has a finite number of events or decides. This implies that if a process has an infinite number of events, it must decide after a finite number of events. Roughly speaking, \(\mathcal {A}\) is wait-free if any process that continues to run will halt with an output value in a fixed number of steps, regardless of delays or failures by other processes. However, in our formal model, we do not require the processes to halt; they solve the decision task and decide by writing to the output component; processes can continue to participate. We typically consider the behaviour of a process until it decides, and therefore, the above distinction does not matter.
The study of wait-free shared memory protocols has been fundamental in distributed computing, some of the most powerful results have been constructed on top of wait-free protocols [6, 8,9,10]. Also, other variants of distributed systems can be reduced to the wait-free case [7, 9, 35].
2.4.1 Definition of Consensus and Safe-Consensus Tasks
The tasks of interest in this paper are the consensus and safe-consensus [4] tasks.
Consensus Every process starts with some initial input value taken from a set I and must output a value such that:
-
Termination: Each process must eventually output some value.
-
Agreement: All processes output the same value.
-
Validity: If some process outputs v, then v is the initial input of some process.
Safe-consensus Every process starts with some initial input value taken from a set I and must output a value such that Termination and Agreement are satisfied, and:
-
Safe-Validity: If a process \(p_i\) starts executing the task and outputs before any other process starts executing the task, then its decision is its own proposed input value. Otherwise, if two or more processes access the safe-consensus task concurrently, then any decision value is valid.
The safe-consensus task was proposed first in [4] as a result of weakening the validity condition of consensus.
3 Iterated Models Extended with Safe-Consensus and Results
Intuitively, a model of distributed computing describes a set of protocols that share some common properties and restrictions in the way the processes can access the shared objects and these conditions affect the way in which the protocols can be specified. In this paper, we are interested in protocols which can be written in a simple and structured way, such that the behaviour of the system in the ith-iteration, can be described by using the behaviour of the \((i - 1)\)th-iteration, in an inductive way.
In this section, we introduce an extension of the basic iterated model of [16], adding the power of safe-consensus shared objects. We also present all the results of this paper.
3.1 The Iterated Model with Shared Objects
In the iterated model extended with shared objects, the processes can use two kinds of communication media. The first is the shared memory SM structured as an infinite array of snapshot objects; the second medium is the infinite array \(\textsf{S}\) of shared objects (SM and \(\textsf{S}\) are described in Section 2.1). The processes communicate between them through the snapshot objects and the shared objects of \(\textsf{S}\), in an asynchronous and round-based pattern. In all the iterated models that we investigate, we make the assumption that the shared memory is composed of one-shot snapshot objects and the array \(\textsf{S}\) contains one-shot shared objets. Specifically, we assume that:
-
The operations \(\textsf {update}\) and \(\textsf {scan}\) of the snapshot objects in SM can be used by a process at most once.
-
The exec operation of each shared object in \(\textsf{S}\) can be used at most once by each process that invokes it.
When we want to add the power of shared objects to the standard iterated model [16], we must consider two important questions. The first question is: In which order should we place the three basic operations (write, read and invoke a shared object)? We have three possibilities:
-
Write, read from the shared memory and invoke a shared object;
-
invoke a shared object, write and read the shared memory;
-
write to memory, invoke a shared object and read the contents of the shared memory.
The second question, which is very closely related to the previous one is: Does the order of the main operations affect the computational power of the new model (for task solvability)? In this paper, we address these two questions and show the differences of the models of distributed computing that we obtain when the shared objects invoked by the processes are safe-consensus objects.
A safe-consensus object is a shared object that can be invoked by any number of processes. The object receives an input value from each process that invokes it, and returns to all the processes an output value that satisfies the Agreement and Validity condition of the safe-consensus task. In other words, a safe-consensus object is like a “black box” that the processes can use to solve instances of the safe-consensus task. The method of using distributed tasks as black boxes inside protocols is a standard way to study the relative computational power of distributed tasks (i.e. if one task is weaker than another, see [4, 22, 36]). Notice that safe-consensus shared objects combined with shared memory registers, can implement consensus [4].
From now on, we work exclusively in iterated models, where the shared objects invoked by the processes are safe-consensus objects.
3.2 The WRO Iterated Model
We now define the first iterated model that we investigate; in it, processes write to shared memory, then they snapshot it and finally they invoke the safe-consensus objects. We say that a protocol is in the WRO (Write, Read and invoke Object) iterated model if it can be written in the form given in Fig. 1.

The WRO iterated model
An explanation of the pseudocode in Fig. 1 follows. All the variables r, sm, val, input and dec are local to process \(p_i\) and only when we analyse a protocol, we add a subindex i to a variable to specify it is local to \(p_i\). The symbol “id” contains the id if the executing process. Initially, r is zero and sm is assigned the contents of the read-only variable input, which contains the input value for process \(p_i\); all other variables are initialized to \(\bot \). In each round, \(p_i\) increments by one the loop counter r, accesses the current shared memory array \(SM\left[ r \right] \), writing all the information it has stored in sm and val (full information) and taking a snapshot of the shared memory array and after these operations, \(p_i\) decides which shared object it is going to invoke by executing a deterministic function h that returns an index l, which \(p_i\) uses to invoke the shared object \(\textsf{S}\left[ l\right] \) with some value v. Finally, \(p_i\) checks if dec is equal to \(\bot \), if so, it executes a deterministic function \(\delta \) to determine if it may decide a valid output value or \(\bot \). Notice that in each round of a protocol, each process invokes at most one safe-consensus object of the array \(\textsf{S}\).
In Section 4, we argue that the consensus task cannot be implemented in the WRO iterated model using safe-consensus objects (Theorem 1), this is the main result for this iterated model.
3.3 The OWR Iterated Model
The second iterated model that we study is the OWR (invoke Object, Write and Read) iterated model. In this model, processes first invoke safe-consensus shared objects and then they write and snapshot the shared memory. We say that a protocol \(\mathcal {A}\) is in the OWR iterated model if \(\mathcal {A}\) can be written in the form specified in Fig. 2.

The OWR iterated model
This pseudocode is explained in a similar way to that used for the code in Fig. 1, the only thing that changes is the place where we put the invocations to the safe-consensus shared objects, before the execution of the snapshot operations.
In Section 4.2, we argue that for task solvability, there is no real difference between the WRO and the OWR iterated models. Any protocol in the WRO iterated model can be simulated by a protocol in the OWR iterated model and the converse is also true, this is stated formally in Theorem 2. Combining this result with Theorem 1, we can conclude that it is impossible to solve consensus in the OWR iterated model (Corollary 1).
3.4 The WOR Iterated Model
The last iterated model that we introduce is constructed by placing the safe-consensus objects between the update and snapshot operations. A protocol \(\mathcal {A}\) is in the WOR (Write, invoke Object and Read) iterated model if it can be written as specified in Fig. 3.

The WOR iterated model
It turns out that the WOR iterated model is quite different from the two previous iterated models. This is true because of the following facts:
-
The consensus task for n processes can be solved in the WOR iterated model using only \({n \atopwithdelims ()2}\) safe-consensus black boxes (Theorem 3).
-
Any protocol in the WOR iterated model which implements consensus using safe-consensus objects must use at least \({n \atopwithdelims ()2}\) safe-consensus objects.
The second fact, which is a consequence of Theorem 4, is the main result of this paper. It describes a matching lower bound on the number of safe-consensus objects needed to solve consensus by any protocol in the WOR iterated model which implements consensus. In Section 5, we give the detailed description of the WOR iterated protocol which implements consensus using safe-consensus objects, we prove its correctness and finally, we give the proof of the lower bound on the number of safe-consensus objects needed to solve consensus in the WOR iterated model. Our lower bound proof is based in the fact that, if for a protocol \(\mathcal {A}\) there exists \(m_0 \in \{2, \ldots , n\}\) such that there are not enough groups (of size \(m_0\)) of processes that can invoke safe-consensus shared objects, then \(\mathcal {A}\) will fail to solve consensus. Specifically, \(\mathcal {A}\) cannot solve consensus if the total number of groups of size \(m_0\) is no more than \(n - m_0\). See Theorem 4 in Section 5.3 for the full details.
3.5 Shared Objects Represented as Combinatorial Sets
We now introduce some combinatorial definitions which will help us represent shared objects and the specific way in which the processes can invoke these shared objects. These definitions are useful in Sections 4 and 5.
For any \(n\geqslant 1\) and \(m \in \overline{n}\), let \(V_{n,m} = \{ c \subseteq \overline{n} \mid |c |= m \}\). Given a protocol \(\mathcal {A}\), we define for each \(m\leqslant n\) the set \(\Gamma _\mathcal {A}(n,m)\subseteq V_{n,m}\) as follows: \(b = \{ i_1,\ldots , i_m \} \in \Gamma _\mathcal {A}(n,m)\) if and only if in some execution of \(\mathcal {A}\), only the processes \(p_{i_1}, \ldots , p_{i_m}\) invoke a safe-consensus object of the array \(\textsf{S}\) (see Figs. 1, 2 and 3). Roughly speaking, each \(c\in \Gamma _\mathcal {A}(n,m)\) represents a set of processes which together can invoke safe-consensus shared objects in \(\mathcal {A}\).
For example, if \(m = 3\) and \(c=\{ i,j,k \}\in \Gamma _\mathcal {A}(n,3)\), then in at least one round of \(\mathcal {A}\), processes \(p_i,p_j\) and \(p_k\) invoke a safe-consensus object and if in another round or perhaps another execution of \(\mathcal {A}\), these processes invoke another safe-consensus object in the same way, then these two invocations are represented by the same set \(c\in \Gamma _\mathcal {A}(n,3)\), that is, shared objects invoked by the same processes are considered as the same element of \(\Gamma _\mathcal {A}(n,3)\) (repetitions do not count). On the other hand, if \(d=\{ i,j,l \} \notin \Gamma _\mathcal {A}(n,3)\), then there does not exist an execution of \(\mathcal {A}\) in which only the three processes \(p_i,p_j\) and \(p_l\) invoke a safe-consensus shared object.
A set \(b\in \Gamma _\mathcal {A}(n,m)\) is called a m-box or simply a box. An element \(d \in \Gamma _\mathcal {A}(n,1)\) is called a trivial box, it represents a safe-consensus object invoked only by one process, we consider such objects as useless, because they do not give any additional information to the process. We model a process that does not invoke a safe-consensus object as a process that invokes a safe-consensus object and no other process invokes that object, i.e., this safe-consensus object is represented by a trivial box. A process \(p_i\) participates in the box b if \(i\in b\). Let the set \(\Gamma _\mathcal {A}(n)\) and the quantities \(\nu _\mathcal {A}(n,m)\) and \(\nu _\mathcal {A}(n)\) be defined as follows:
-
\(\Gamma _\mathcal {A}(n)=\bigcup _{m=2}^n \Gamma _\mathcal {A}(n,m)\);
-
\(\nu _\mathcal {A}(n,m)=|\Gamma _\mathcal {A}(n,m) |\);
-
\(\nu _\mathcal {A}(n)=\sum _{m=2}^n \nu _\mathcal {A}(n,m)\).
From now on, for all our protocols, we consider global states only at the end of some iteration. Suppose that P is a reachable state in the protocol \(\mathcal {A}\). The set of shared objects \(o_1,\ldots ,o_q\) invoked by the processes to enter state P is represented by a set of boxes \(\textbf{Inv}(P)=\{ b_1,\ldots , b_q \}\) which is called the global invocation specification of P. We assume without loss of generality that in all rounds, each process invokes some shared object, that is, the set \(\textbf{Inv}(P)\) satisfies
(a process that does not invoke a safe-consensus object can be seen as a process that invokes a safe-consensus object and no other process invokes that object). Notice that since each process invokes only one safe-consensus object in each round, \(\textbf{Inv}(P)\) is a partition of \(\overline{n}\).
If \(b = \{ l_1, \ldots , l_s \} \in \textbf{Inv}(P)\) is a box representing a safe-consensus shared object invoked by the processes \(p_{l_1},\ldots ,p_{l_s}\), we define the safe-consensus value of b in P, denoted by \(\textsf{scval}(b,P)\) as the unique output value of the safe-consensus shared object represented by b.
3.6 Additional Definitions on Global States
We now introduce the notions of connectivity and paths between global states. These are well known concepts [2, 8] and have become a fundamental tool to study distributed systems.
3.6.1 Paths of Global States
Two states S, P are said to be adjacent if there exists a non-empty subset \(X\subseteq \overline{n}\) such that all processes with ids in X have the same local state in both S and P. That is, for each \(i\in X\), \(p_i\) cannot distinguish between S and P. We denote this by \(S\overset{X}{\sim }\ P\). States S and P are connected, if we can find a sequence of states (called a path)
such that for all j with \(1\leqslant j \leqslant r-1\), \(P_j\) and \(P_{j+1}\) are adjacent.
Connectivity of global states are a key concept for many beautiful results in distributed systems, namely, impossibility proofs. The indistinguishability of states between processes is the building block to construct topological structures based on the executions of a given protocol and is fundamental in many papers [3, 8,9,10, 29]. In addition to the classic definitions of connectivity and paths, we also introduce the following concepts. Let \(\mathfrak {q}:Q_1 {\sim } \cdots {\sim } Q_l\) be a path of connected states, define the set of states \(\textsf{States}(\mathfrak {q})\); the set of indistinguishability sets \(\textsf{iSets}(\mathfrak {q})\); and the degree of indistinguishability \(\deg \mathfrak {q}\), of \(\mathfrak {q}\) as follows:
-
\(\textsf{States}(\mathfrak {q})=\{ Q_1, \ldots , Q_l \}\);
-
\(\textsf{iSets}(\mathfrak {q})=\{ X\subseteq \overline{n} \mid (\exists Q_i,Q_j \in \textsf{States}(\mathfrak {q}))(Q_i \overset{X}{\sim }\ Q_j) \}\);
-
\(\deg \mathfrak {q} = \min \{ |X |\mid X \in \textsf{iSets}(\mathfrak {q}) \}\).
The degree of indistinguishability of the path \(\mathfrak {q}\) guarantees that we can find for any pair of states \(Q_i,Q_j \in \textsf{States}(\mathfrak {q})\) with \(Q_i {\sim } Q_j\), a set of processes \(P\subset \Pi \) that cannot distinguish between \(Q_i\) and \(Q_j\) such that \(|P| \geqslant \deg \mathfrak {q}\). The degree of indistinguishability of a path is usually of non-importance in the standard and well known bivalency proofs of the impossibility of consensus in various systems [2, 3], but in the impossibility proof of Section 4 and also the lower bound proof of Section 5, measuring the degree of indistinguishability will be a recurring action in all the proofs.
A path \(\mathfrak {p}\) of connected states of \(\mathcal {A}\) is said to be C-regular if and only if \(\textbf{Inv}(S) = \textbf{Inv}(Q)\) for all \(S,Q\in \textsf{States}(\mathfrak {p})\), that is, \(\mathfrak {p}\) is C-regular when all the states in the set \(\textsf{States}(\mathfrak {p})\) have the same global invocation specification.
Lemma 1
Let \(\mathcal {A}\) be an iterated protocol for n processes, \(A \subseteq \overline{n}\) a non-empty set and S, Q two reachable states of \(\mathcal {A}\) in round r, such that for all \(j\in A\), \(p_j\) cannot distinguish between S and Q. Then all processes with ids in A participate in the same boxes in S and Q.
Proof (Sketch)
Intuitively, for each \(j \in A\), \(p_j\) has the same content in all its local variables, thus it inputs the same values for the function h that outputs the index of the shared object (box) \(p_j\) is going to invoke in S and Q respectively. Therefore h outputs the same index in both states, gather that, \(p_j\) invokes the same shared object in S and Q. \(\square \)
3.7 Consensus Protocols
We need some extra definitions regarding consensus protocols: If v is a valid input value of consensus for processes and S is a state, we say that S is v-valent if in any possible execution starting from S, there exists a process that outputs v. S is univalent if in every execution starting from S, processes always output the same value. If S is not univalent, then S is bivalentFootnote 3.
Lemma 2
Any two initial states of a protocol for consensus are connected.
Proof
Let S, P be two initial states. If S and P differ only in the initial value \(input_i\) of a single process \(p_i\), then S and P are adjacent (Only \(p_i\) can distinguish between the two states, the rest of the processes have the same initial values). In the case S and P differ in more that one initial value, they can be connected by a sequence of initial states \(S=S_1 {\sim } \cdots {\sim } S_q=P\) such that \(S_j,S_{j+1}\) differ only in the initial value of some process (we obtain \(S_{j+1}\) from \(S_j\) by changing the input value of some process \(p_i\), the result is a valid input of the consensus problem), hence they are adjacent. In summary, S and P are connected. \(\square \)
We need one last result about consensus protocols, we omit its easy proof.
Lemma 3
Suppose that \(\mathcal {A}\) is a protocol that solves the consensus task and that I, J are connected initial states of \(\mathcal {A}\), such that for all rounds \(r \geqslant 1\), \(I_r, J_r\) are connected successor states of I and J respectively. Also, assume that I is a v-valent state. Then J is v-valent.
Proof
Suppose that I is v-valent and J is \(v^\prime \)-valent (\(v\ne v^\prime \)). By hypothesis, for all rounds \(r\geqslant 1\), \(I_r\) and \(J_r\) are connected successor states of I and J respectively. Thus, for any \(r \geqslant 0\), we can find r-round partial executions
such that \(I_r\) and \(J_r\) are connected states for all \(r\geqslant 0\). Given that \(\mathcal {A}\) solves consensus, there must exists \(k\geqslant 1\) such that \(I_u\) and \(J_u\) are decision states for all \(u \geqslant k\). Let \(\mathfrak {p}_u\) be a path connecting \(I_u\) and \(J_u\). For the rest of the proof, assume that \(\textsf{States}(\mathfrak {p}_u) =\{ I_u, J_u\}\) (i.e., \(I_u {\sim } J_u\)), as the general case will follow easily from this case and induction on \(|\textsf{States}(\mathfrak {p}_u)|\).
Since \(I_u\) is a successor state of I, which is a v-valent state, all processes decide v in \(I_u\); similarly, as \(J_u\) is a successor state of J (a \(v^\prime \)-valent state), processes decide \(v^\prime \) in \(J_u\). Let p be a process that cannot distinguish between \(I_u\) and \(J_u\). Then the local state of p in \(I_u\) and \(J_u\) must be the same and this includes its output component. But this is a contradiction, because in \(I_u\), p decides v while in \(J_u\), p decides \(v^\prime \). We conclude that J must be v-valent, such as I. \(\square \)
4 Impossibility of Consensus in the WRO and OWR Iterated Models
In this section, we prove that the consensus task cannot be implemented in the WRO iterated model with safe-consensus objects and we extend this result to the OWR iterated model, by showing that the WRO and OWR iterated models are equivalent models in their computational power to solve tasks. Given that there exists a protocol in the standard model that solves consensus with registers and safe-consensus objects [4], it is a consequence of the results presented in this section that the WRO and OWR iterated models are not equivalent to the standard model extended with safe-consensus objects.
4.1 The Impossibility of Consensus in the WRO Iterated Model
We give a negative result concerning protocols in the WRO iterated model. Although there exist wait-free shared memory protocols that can solve consensus using safe-consensus objects [4], in this paper we show that there is no protocol in the WRO iterated model that solves consensus using safe-consensus objects. We first introduce some extra definitions and results that we will be using and after that, we prove that there is no protocol in the WRO iterated model which can solve the consensus task. For simplicity, we will refer to a protocol in the WRO iterated model simply as a WRO protocol.
Lemma 4
Let \(\mathcal {A}\) be a WRO protocol for n processes, \(A_i=\overline{n} - i\) for some \(i\in \overline{n}\). Assume there exist S, Q two reachable states of \(\mathcal {A}\) in round r, such that for all \(j\in A_i\), \(p_j\) does not distinguish between S and Q. Then \(\textbf{Inv}(S)=\textbf{Inv}(Q)\).
Proof
Let \(\mathcal {A}\) be a WRO protocol, \(A_i=\overline{n} - i\) and S, Q such that every process \(p_j\) with \(j\in A_i\) cannot distinguish between S and Q. By Lemma 1, if \(b\in \textbf{Inv}(S)\) is a box such that \(i\notin b\), then \(b\in \textbf{Inv}(Q)\). For the box \(c\in \textbf{Inv}(S)\) that contains the id i, we argue by cases:
-
Case I. \(|c |= 1\). All processes with ids in \(A_i\) participate in the same boxes in both states S and Q and \(p_i\) does not participate in those boxes, thus \(c = \{ i \} \in \textbf{Inv}(Q)\).
-
Case II. \(|c |> 1\). There exists a process \(p_j\) with \(j\in c\) and \(j\ne i\). Then \(j\in A_i\), so that by Lemma 1, \(c\in \textbf{Inv}(Q)\).
We have prove that \(\textbf{Inv}(S)\subseteq \textbf{Inv}(Q)\). To show that the other inclusion holds, the argument is symmetric. Therefore \(\textbf{Inv}(S) = \textbf{Inv}(Q)\). \(\square \)
In order to prove the impossibility of consensus in the WRO iterated model (Theorem 1), we need various results that describe the structure of protocols in the WRO iterated model. These results tell us that for any given WRO protocol, the degree of indistinguishability of paths of connected states is high, even with the added power of safe-consensus objects, because we can make the safe-consensus values returned by the shared objects the same in all these reachable states, so that they cannot help the processes distinguish between these states. This is the main reason (of) why consensus cannot be implemented with safe-consensus in the WRO iterated model.
The following construction will be useful for the rest of this section. If \(A_1,\ldots ,\) \(A_q\subset \overline{n}\) \((q\geqslant 1)\) is a collection of disjoin subsets of \(\overline{n}\), define the round schedule
for \(\mathcal {A}\) as:
where \(Y=\overline{n} - (\bigcup _{i=1}^q A_i)\). Sometimes, we omit the set Y and just write \(\eta (A_1,\ldots ,A_q)\). The key point of the round schedule \(\eta (A_1,\ldots ,A_q,Y)\) is that in a given one-round execution of a WRO protocol, it will allow us to choose the safe-consensus values of the safe-consensus shared objects invoked by at least two processes (using the Safe-Validity property of the safe-consensus task).
Our next Lemma is the first step to prove Theorem 1. Roughly speaking, it tells us that if a WRO protocol has entered any reachable state S, then we can find two one-round successor states of S, such that we can connect these states with a small path of very high indistinguishability degree. These two successor states of S are obtained when the processes execute the WRO protocol in such a way that only one process is delayed in the update and snapshot operations, but all processes execute the safe-consensus shared objects concurrently in every state of the resulting path, thus we can keep the safe-consensus values of every safe-consensus shared object the same in every state.
Lemma 5
Let \(n\geqslant 2\), \(\mathcal {A}\) a WRO protocol and \(i,j\in \overline{n}\). If S is a reachable state of \(\mathcal {A}\) in round \(r\geqslant 0\) and the states \(Q_i=S\cdot \eta (\overline{n} - i)\) and \(Q_j=S\cdot \eta (\overline{n} - j)\) satisfy the conditions
-
A.
\(\textbf{Inv}(Q_i) = \textbf{Inv}(Q_j)\);
-
B.
\((\forall b\in \textbf{Inv}(Q_i)) (\textsf{scval}(b,Q_i)=\textsf{scval}(b,Q_j))\).
Then \(Q_i\) and \(Q_j\) are connected in round \(r+1\) of \(\mathcal {A}\) with a C-regular path \(\mathfrak {q}\) with \(\deg \mathfrak {q} \geqslant n - 1\).
Proof
If \(i=j\), the result is immediate. Suppose that \(i\ne j\) and \(\overline{n} - i = \{ l_1,\ldots ,l_{n - 1} \}\) with \(l_{n-1}=j\). We show that \(Q_i\) and \(Q_j\) can be connected with a C-regular sequence with indistinguishability degree \(n - 1\) by building three subsequences \(\mathfrak {q}_1,\mathfrak {q}_2\) and \(\mathfrak {q}_3\).
We proceed to build the sequence \(\mathfrak {q}_1\). We claim that there exists a state Q of the form \(Q=S\cdot \eta (l_1, \overline{n} - \{ i, l_1\},i)\) such that
-
\(\textbf{Inv}(Q_i) = \textbf{Inv}(Q)\);
-
\(\textsf{scval}(b,Q_i)=\textsf{scval}(b,Q)\) for all \(b\in \textbf{Inv}(Q)\).
The first property holds because in any state of the form \(S\cdot \eta (l_1, \overline{n} - \{ i, l_1\},i)\), only process \(l_1\) can distinguish between \(Q_i\) and Q, thus by Lemma 4 we obtain that \(\textbf{Inv}(Q_i) \) \(= \textbf{Inv}(Q)\). Now, in both \(Q_i\) and Q, all processes execute the safe-consensus shared objects concurrently and we can use the Safe-Validity property of the safe-consensus task to find a state of \(\mathcal {A}\) in round \(r+1\) such that \(Q=S\cdot \eta (l_1, \overline{n} - \{ i, l_1\},i)\) in which \(\textsf{scval}(b,Q_i)=\textsf{scval}(b,Q)\) for each \(b\in \textbf{Inv}(Q)=\textbf{Inv}(Q_i)\). This proves the second property. Therefore, we have that
and this sequence is a C-regular path. Repeating the same argument, we can connect Q with a state of the form \(P=S\cdot \eta (l_1,l_2,\overline{n} - \{ i, l_1,l_2\},i)\) and obtain the three state C-regular path \(Q_i \overset{\overline{n} - l_1}{\sim } Q \overset{\overline{n} - l_2}{\sim } P\). Continuing in this way, we can show that the path \(\mathfrak {q}_1\) is given by
which is clearly a C-regular path by repeated use of the previous argument. In the same way, we construct the sequence \(\mathfrak {q}_2\) as
and finally, in a very similar way, we build \(\mathfrak {q}_3\) as follows,
Both \(\mathfrak {q}_2\) and \(\mathfrak {q}_3\) are C-regular paths and for \(k=1,2,3\), \(\deg \mathfrak {q}_k = n - 1\). Notice that the processes execute the safe-consensus objects in the same way in all the states of the previous sequences, and by construction, all the states have the same invocation specification. As \(j=l_{n - 1}\), \(S\cdot \eta (\overline{n} - l_{n - 1},l_{n - 1}) = S\cdot \eta (\overline{n} - j,j)=Q_j\), thus we can join \(\mathfrak {q}_1,\mathfrak {q}_2\) and \(\mathfrak {q}_3\) to obtain a C-regular path \(\mathfrak {q} :Q_i {\sim } \cdots {\sim } Q_j\) such that \(\deg \mathfrak {q} = n - 1\). This finishes the proof. \(\square \)
Lemma 6 is the next step towards proving Theorem 1. Basically, it says that for any WRO protocol, if we already have a path of connected states with high indistinguishability degree for some round, then we can use this path to build a new sequence of connected states in the next round with a high degree of indistinguishability. Again, using the round schedules where the processes execute the safe-consensus shared objects concurrently, we can render useless the safe-consensus values, so that the number of processes that cannot distinguish between a pair of states of the path is as high as possible.
Lemma 6
Let \(\mathcal {A}\) be a WRO protocol and S, P be two reachable states of some round \(r\geqslant 0\) such that S and P are connected with a sequence \(\mathfrak {s}\) such that \(\deg \mathfrak {s} \geqslant n - 1\); suppose also that the number of participating processes is \(n\geqslant 2\). Then there exist successor states \(S^{\prime },P^{\prime }\) of S and P respectively, in round \(r+1\) of \(\mathcal {A}\), such that \(S^{\prime }\) and \(P^{\prime }\) are connected with a C-regular path \(\mathfrak {q}\) with \(\deg \mathfrak {q} \geqslant n - 1\).
Proof
Suppose that S and P are connected with a sequence \(\mathfrak {s} :S=S_1 {\sim } \cdots {\sim } S_m=P\) such that for all j \((1\leqslant j \leqslant m-1)\), \(S_j\overset{X}{\sim }\ S_{j+1}\), where \(|X |\geqslant n - 1\). Let \(p_1,\ldots ,p_n\) be the set of participating processes. We now construct a sequence of connected states
in such a way that each \(Q_i\) is a successor state to some state \(S_j\) and \(\deg \mathfrak {q} \geqslant n - 1\). We use induction on m; for the basis, consider the adjacent states \(S_1,S_2\) and suppose that all processes with ids in the set \(X_1\) \((|X_1 |\geqslant n - 1)\) cannot distinguish between \(S_1\) and \(S_2\). By the Safe-Validity property of the safe-consensus task and Lemma 4, we can find states \(Q_1,Q_2\) such that
-
\(Q_1=S_1\cdot \eta (X_1)\) and \(Q_2=S_2\cdot \eta (X_1)\);
-
\(Q_1\) and \(Q_2\) are indistinguishable for all processes with ids in \(X_{1}\);
-
\(\textbf{Inv}(Q_1)=\textbf{Inv}(Q_2)\).
Combining these facts, we can see that the small sequence \(Q_1\overset{X_1}{\sim }\ Q_2\) is C-regular and has indistinguishability degree at least \(n - 1\). Assume now that we have build the sequence
of connected successor states for \(S_1{\sim } \cdots {\sim } S_q\) \((1\leqslant q < m)\) such that \(\mathfrak {q}^\prime \) is C-regular , \(\deg \mathfrak {q}^\prime \geqslant n - 1\) and \(Q_{s^\prime }=S_q \cdot \eta (X)\) with \(|X |\geqslant n -1\). Let \(X_q\) with \(|X_q |\geqslant n - 1\) be a set of processes’ ids that cannot distinguish between \(S_q\) and \(S_{q+1}\). To connect \(Q_{s^\prime }\) with a successor state for \(S_{q+1}\), we first use Lemma 5 to connect \(Q_{s^\prime }\) and \(Q=S_q \cdot \eta (X_q)\) by means of a C-regular sequence \(\mathfrak {p}\) such that \(\deg \mathfrak {p} \geqslant n - 1\). Second, notice that we have the small C-regular path \(\mathfrak {s}:Q \overset{X_q}{\sim } S_{q+1} \cdot \eta (X_q)=Q_{s^\prime +1}\). In the end, we use \(\mathfrak {q}^\prime ,\mathfrak {p}\) and \(\mathfrak {s}\) to get a C-regular sequence
which fulfils the inequality \(\deg \mathfrak {q} \geqslant n - 1\). By induction, the result follows. \(\square \)
Using Lemmas 5 and 6 and previous results regarding bivalency arguments, we can finally prove the impossibility of consensus in the WRO iterated model.
Theorem 1
There is no protocol for consensus in the WRO iterated model using safe-consensus objects.
Proof
Suppose \(\mathcal {A}\) is a WRO protocol that solves consensus with safe-consensus objects and without loss, assume that 0,1 are two valid input values. Let O, U be the initial states in which all processes have as initial values only 0 and 1 respectively. By Lemma 2, O and U are connected and it is easy to see that the sequence joining O and U, build in the proof on Lemma 2 has degree of indistinguishability \(n -1\). So that applying an easy induction, we can use Lemma 6 to show that there exist connected successor states \(O_r,U_r\) of O and U respectively in each round \(r\geqslant 1\) of the protocol \(\mathcal {A}\). Clearly, O is a 0-valent state and by Lemma 3, U is 0-valent. But this is a contradiction, because U is a 1-valent state. Therefore no such protocol \(\mathcal {A}\) can exists. \(\square \)
At this moment we remark that the key fact that allows us to prove this impossibility of consensus in the WRO model, is that in all our proofs, we are able to “neutralize” the safe-consensus objects by making all processes invoke their respective shared objects concurrently, this is the entry point for the Safe-Validity property of consensus to allow us to find the states of the executing protocol with the same safe-consensus values, so that the processes can only distinguish different states by their local view of the shared memory. In contrast to the protocols in the WOR model, it is not possible to apply this technique and neutralize the safe-consensus objects, because the shared objects operations are located between the update and snapshot operations, so that when the processes take the snapshot, they have already invoked the safe-consensus shared objects.
4.2 The Equivalence of the WRO and OWR Iterated Models
In this section, we prove Theorem 2, which tells us that the WRO and the OWR iterated models have the same computational power. We show that given any protocol in the WRO iterated model, there is an OWR protocol that can simulate its behaviour and the converse is also true. To check the meaning of some definition or previous result, the reader may consult Sections 2, 3.2 and 3.3. For the sake of simplicity, we will refer to a protocol in the OWR iterated model, simply as an OWR protocol.

General WRO-simulation protocol in the OWR iterated model
4.2.1 Transforming a WRO Protocol into an OWR Protocol
The algorithm of Fig. 4 is a generic OWR protocol to simulate protocols in the WRO iterated model. Suppose that \(\mathcal {A}\) is a WRO protocol that solves a task \(\Delta \) and assume that \(h_\mathcal {A}\) is the deterministic function to select safe-consensus objects in \(\mathcal {A}\) and \(\delta _\mathcal {A}\) is the decision map used in the protocol \(\mathcal {A}\). To obtain an OWR protocol \(\mathcal {B}\) that simulates the behaviour of \(\mathcal {A}\), we use the generic protocol of Fig. 4, replacing the functions \(h_{\_}\) and \(\delta _{\_}\) with \(h_\mathcal {A}\) and \(\delta _\mathcal {A}\) respectively. If the processes execute \(\mathcal {B}\) with valid input values from \(\Delta \), then in the first round, the participating processes discard the output value of the safe-consensus object that they invoke, because the test at line (6) is successful and after that, each process goes on to execute the write-snapshot operations, with the same values that they would use to perform the same operations in round one of \(\mathcal {A}\). Later, at lines (13)-(15), they do some local computing to try to decide an output value. It is clear from the code of the generic protocol that none of the executing processes will write a non-\(\bot \) value to the local variables dec, thus no process makes a decision in the first round and they finish the current round, only with two simulated operations from \(\mathcal {A}\): write and snapshot. In the second round, the processes invoke one or more safe-consensus objects at line (5), accordingly to the return values of the function \(h_\mathcal {A}\), which is invoked with the values obtained from the snapshot operation of the previous round (from the round one write-read simulation of \(\mathcal {A}\)) and notice that instead of using the current value of the round counter r, the processes call \(h_\mathcal {A}\) with the parameter \(r - 1\). Since \(r = 2\), the processes invoke \(h_\mathcal {A}\) as if they were still executing the first round of the simulated protocol \(\mathcal {A}\). Finally, after using the safe-consensus objects, processes do local computations in lines (8)-(10), using the decision map \(\delta _\mathcal {A}\) to simulate the decision phase of \(\mathcal {A}\), if for some process \(p_j\), it is time to take a decision in \(\mathcal {A}\), it stores the output value in the local variable \(dec_j^\prime \), which is used at the end of the round to write the output value in \(dec_j\) and then \(p_j\) has decided. If the map \(\delta _\mathcal {A}\) returns \(\bot \), then \(p_j\) goes on to do the next write-read operations (simulating the beginning of round two of \(\mathcal {A}\)) and proceeds to round three of \(\mathcal {B}\). The described behaviour is going to repeat in all subsequent rounds.
4.2.2 Correspondence Between Executions of the Protocols
Let \(\pi \) be a round schedule. Denote by \(\pi \left[ \textsf {W},\textsf {R} \right] \) the sequence of write and read events of \(\pi \), these events appear in \(\pi \left[ \textsf {W},\textsf {R} \right] \) just in the same order they are specified in \(\pi \). The symbol \(\pi \left[ \textsf {S} \right] \) is defined for the event S in a similar way. For example, given the round schedule
then \(\pi \left[ \textsf {W},\textsf {R} \right] =\textsf {W}(1, 3), \textsf {R}(1,3), \textsf {W}(2), \textsf {R}(2)\) and \(\pi \left[ \textsf {S} \right] =\textsf {S}(1,2,3)\). For another example, suppose that the round schedule \(\pi ^\prime \) is given by
In this case, we have that \(\pi ^\prime \left[ \textsf {W},\textsf {R} \right] =\textsf {W}(1,2,3), \textsf {R}(1,2,3)\) and \(\pi ^\prime \left[ \textsf {S} \right] =\textsf {S}(1),\textsf {S}(3),\) \(\textsf {S}(2)\).
Let \(\mathcal {A}\) be a WRO protocol as given in Fig. 1, \(h_\mathcal {A}\) the deterministic function to select safe-consensus objects and \(\delta _\mathcal {A}\) the decision map used in the protocol \(\mathcal {A}\). An OWR protocol \(\mathcal {B}\) that simulates the behaviour of \(\mathcal {A}\) is obtained by using the generic protocol \(\mathcal {G}\) of Fig. 4. To construct \(\mathcal {B}\), we only replace the functions \(h_{\_}\) and \(\delta _{\_}\) of \(\mathcal {G}\) with \(h_\mathcal {A}\) and \(\delta _\mathcal {A}\) respectively.
In order to show that \(\mathcal {B}\) simulates \(\mathcal {A}\), we first notice that there is a correspondence between executions of \(\mathcal {A}\) and \(\mathcal {B}\). For, if \(\alpha \) is an execution of \(\mathcal {A}\) such that
Then there exists an execution \(\alpha _\mathcal {B}\) of \(\mathcal {B}\)
such that
where \(\bigcup _{j=1}^s X_j=\overline{n}\) is an arbitrary partition of \(\overline{n}\). Conversely, for any execution \(\beta =R_0,\eta _1,R_1,\ldots \) \(\eta _k,R_k,\) \(\eta _{k+1},\ldots \) of the protocol \(\mathcal {B}\), we can find an execution
of \(\mathcal {A}\) such that
Lemma 7
Suppose that \(\beta \) is an execution of the protocol \(\mathcal {B}\) and process \(p_i\) is executing the protocol (accordingly to \(\beta \)) in round \(r > 0\) at line 11. Then the local variables \(sm_i,dec^\prime _i\) and \(val_i\) of \(\mathcal {B}\) have the same values of the respectively local variables \(sm_i,dec_i\) and \(val_i\) of the protocol \(\mathcal {A}\), when \(p_i\) finishes executing round \(r - 1\) of \(\mathcal {A}\), in the way specified by the execution \(\beta _\mathcal {A}\).
Proof
The proof is based on induction on the round number r, the base case and the inductive case are obtained by an easy analysis of the programs given in Figs. 1 and 4. \(\square \)
The converse of the previous lemma is also true.
Lemma 8
Suppose that \(\alpha \) is an execution of the protocol \(\mathcal {A}\) and process \(p_i\) is executing the protocol (accordingly to \(\alpha \)) in round \(r > 0\) at line 4. Then the local variables \(sm_i,dec_i\) and \(val_i\) of \(\mathcal {A}\) have the same values of the respective local variables \(sm_i,dec^\prime _i\) and \(val_i\) of the protocol \(\mathcal {B}\), when \(p_i\) finishes executing round \(r + 1\) of \(\mathcal {B}\), in the way specified by the execution \(\alpha _\mathcal {B}\).
The final result that we need to prove that \(\mathcal {B}\) simulates \(\mathcal {A}\) for task solvability is an immediate consequence of Lemma 7.
Lemma 9
Suppose that \(\Delta \) is a decision task solved by the protocol \(\mathcal {A}\) and let \(p_i\in \Pi \). Then \(p_i\) decides an output value v in round \(r > 0\) of an execution \(\alpha \) of \(\mathcal {A}\) if and only if \(p_i\) decides the output value v in round \(r+1\) of \(\mathcal {B}\), in the execution \(\alpha _\mathcal {B}\).
This shows that the protocol \(\mathcal {B}\) simulates the behaviour of \(\mathcal {A}\) for task solvability and therefore proves the first part of Theorem 2.
4.2.3 Transforming an OWR Protocol into a WRO Protocol
Now we show that any OWR protocol can be simulated with a WRO protocol. We follow the same technique that we used in the previous section, we use the generic protocol of Fig. 5. The intuitive argument of how it works is very much the same as in the WRO case, thus we omit the details.

General OWR-simulation protocol in the WRO iterated model
Theorem 2
Let \(\mathcal {A}\) be a protocol in the WRO iterated model which solves a task \(\Delta \). Then \(\mathcal {A}\) can be simulated with a protocol \(\mathcal {B}\) in the OWR iterated model. Conversely, for every protocol \(\mathcal {B}^\prime \) in the OWR iterated model that solves a task \(\Delta ^\prime \), there is a protocol \(\mathcal {A}^\prime \) in the WRO iterated model, which simulates \(\mathcal {B}^\prime \).
The equivalence of the WRO iterated model with the OWR iterated model can be combined with Theorem 1 to obtain the following
Corollary 1
There is no protocol in the OWR iterated model for consensus using safe-consensus objects.
The results of this section about the WRO and OWR iterated models combined with the consensus protocol using safe-consensus objects of [4], allow us to conclude that the standard model enriched with safe-consensus shared objects is more powerful that the WRO and OWR iterated models. But there are still some unanswered questions regarding these two iterated models, see our conclusions at Section 6.
5 Solving Consensus in the WOR Iterated Model
In this section, We investigate the solvability of consensus in the WOR iterated model. We show that there exists a protocol in the WOR iterated model for consensus with \({n \atopwithdelims ()2}\) safe-consensus objects. Although the formal specification of this protocol is a bit complicated (see Section 5.2), the intuitive idea behind it is quite simple and this idea can be depicted in a graphical way. This is a nice property of our consensus protocol and it is a consequence of working in an (extended) iterated model of computation. As a byproduct of the design of the consensus protocol, we discovered the new g-2coalitions-consensus task, which is a new kind of “consensus task”. More details can be found in Section 5.1. In Section 5.3, we present the main result of this paper, the lower bound on the number of safe-consensus objects needed by any protocol in the WOR iterated model which implements consensus. The lower bound proof is a result of combining a careful study of the connectivity of protocols in the WOR iterated model and the effects of invoking safe-consensus shared objects on the indistinguishability degree of paths connecting reachable states of the protocols. These effects are described in part combinatorially by a new application of Johnson graphs in distributed computing. We use terminology and results from Sections 2 and 3. For simplicity, we refer to any protocol in the WOR iterated model as a WOR protocol.
5.1 The Coalitions-Consensus Task
In order to present the complete specification of the consensus protocol, we define the 2coalition-consensus task, which will be useful to give a simpler description of the consensus protocol of Fig. 8 and prove its correctness in Theorem 3, but before that, we show that the 2coalitions-consensus task can be solved in the WOR iterated model in one round with one snapshot object and one safe-consensus object.
Intuitively, in the g-2coalitions-consensus task, g processes try to decide a consensus value from two proposed input values, there are exactly \(g - 2\) processes which know the two input values, while each of the two remaining processes know only one input value and it is this last fact that makes the 2coalitions-consensus task dificult to solve. We now give the formal definition of this new task. First, we need to define the set of all valid input values for this new task.
Let I be a non-empty set of names such that \(\bot \notin I\) and \(\mathcal {N} = I \cup \{ \bot \}\). If \(x=\langle v_1, v_2 \rangle \in \mathcal {N} \times \mathcal {N}\), x.left denotes the value \(v_1\) and x.right is the value \(v_2\). If \(g\in \mathbb {N}\), then an ordered g-tuple \(C= (x_1,\ldots ,x_g)\in (\mathcal {N} \times \mathcal {N})^g\) is a g-coalitions tuple if and only if
-
(a)
For all \(x_i\) in C, \(x_i.left \ne \bot \) or \(x_i.right \ne \bot \).
-
(b)
If \(x_i,x_j\) are members of C such that \(x_i.left \ne \bot \) and \(x_j.left \ne \bot \), then \(x_i.left = x_j.left\). A similar rule must hold if \(x_i.right \ne \bot \) and \(x_j.right \ne \bot \).
Let \(l(C)=\{ i\in \overline{g} \mid x_i.left \ne \bot \}\) and \(r(C)=\{ j\in \overline{g} \mid x_j.right \ne \bot \}\). Then we also require that
-
(c)
\(|l(C) - r(C) |= 1\) and \(r(C) - l(C) = \{ g \}\).
Notice that property (a) implies that \(l(C)\cup r(C)=\overline{g}\). The set of all g-coalitions tuples is denoted by \(\mathcal {C}_g\). Some examples can help us understand better the concept of a coalition tuple. Let \(\mathcal {N}=\{ 0,1, \bot \}\). The following tuples are examples of elements of the set \(\mathcal {C}_4\),
-
\(C_1=(\langle 1, \bot \rangle , \langle 1, 0 \rangle , \langle 1, 0 \rangle , \langle \bot , 0 \rangle )\);
-
\(C_2=(\langle 1, 0 \rangle , \langle 1, 0 \rangle , \langle 1, \bot \rangle , \langle \bot , 0 \rangle )\).
Clearly, \(C_1,C_2\in \mathcal {C}_4\) and also we have that \(l(C_1)=\{ 1,2,3 \}\) and \(r(C_1)=\{ 2,3,4 \}\). Notice that \(l(C_1) \cup r(C_1)=\overline{4}\) and also \(l(C_1) \cap r(C_1) = \{ 2,3 \}\). For \(C_2\), it is true that \(l(C_2) - r(C_2) = \{ 1,2,3 \} - \{ 1,2,4 \}=\{ 3 \}\), \(r(C_2) - l(C_2) = \{ 1,2,4 \} - \{ 1,2,3 \}=\{ 4 \}\) and \(l(C_2) \cap r(C_2) = \{ 1,2 \}\). The following tuples are not elements of any coalitions tuples set:
-
\(C_3=(\langle \bot , \bot \rangle , \langle 1, 0 \rangle , \langle 1, 0 \rangle , \langle 1, 0 \rangle )\);
-
\(C_4=(\langle 1, \bot \rangle , \langle 1, 0 \rangle , \langle \bot , 1 \rangle , \langle \bot , 0 \rangle )\).
For \(C_3\), properties (a) and (c) are not satisfied and for \(C_4\), condition (b) is not fulfilled. Thus we conclude that \(C_3,C_4 \notin \mathcal {C}_4\). We can now define a new distributed task.
The g-2coalitions-consensus task We have g processes \(p_1,\ldots ,p_{g}\) and each process \(p_i\) starts with a private input value of the form \(x_i \in \mathcal {N} \times \mathcal {N}\) such that \(C=(x_1,\ldots ,x_g)\in \mathcal {C}_g\), and C is called a global input. In any execution, the following properties must be true:
-
Termination: Each process must eventually output some value.
-
Agreement: All processes output the same value.
-
2coalitions-Validity: If some process outputs c, then there must exists a process \(p_j\) with input \(x_j\) such that \(x_j = \langle c, v \rangle \) or \(x_j = \langle v, c \rangle \) (\(c\in I, v\in \mathcal {N}\)).
Notice that the sets \(\mathcal {C}_g\) (\(g\geqslant 2\)) encapsulate the intuitive ideas given at the beginning of this section about the coalition-consensus task that we need: With an input \(C\in \mathcal {C}_g\), there are two processes that know exactly one of the input values, while the rest of the processes do know the two input values. These processes could easily reach a consensus, but they still need the other two processes with unique input values to agree on the same value, and this is the difficult part of the g-2coalitions-consensus task.
The protocol of Fig. 6 implements g-2coalitions-consensus. Each process \(p_i\) receives as input a tuple with values satisfying the properties of the 2coalitions-consensus task and then in lines 3-5, \(p_i\) writes its input tuple in shared memory using the snapshot object SM; invokes the safe-consensus object with its id as input, storing the unique output value u of the shared object in the local variable val and finally, \(p_i\) takes a snapshot of the memory. Later, what happens in Lines 6-10 depends on the output value u of the safe-consensus object. If \(u=g\), then by the Safe-Validity property, either \(p_g\) invoked the object or at least two processes invoked the safe-consensus object concurrently and as there is only one process with input tuple \(\langle v, \bot \rangle \), \(p_i\) will find an index j with \(sm\left[ j \right] .right \ne \bot \) in line 7, assign this value to dec and in line 11 \(p_i\) decides. On the other hand, if \(u\ne g\), then again by the Safe-Validity condition of the safe-consensus task, either process \(p_u\) is running and invoked the safe-consensus object or two or more processes invoked concurrently the shared object and because all processes with id not equal to g have input tuple \(\langle z, y \rangle \) with \(z\ne \bot \), it is guaranteed that \(p_i\) can find an index j with \(sm\left[ j \right] .left \ne \bot \) and assign this value to dec to finally execute line 11 to decide its output value. All processes decide the same value because of the properties of the input tuples of the 2coalitions-consensus task and the Agreement property of the safe-consensus task.

A g-2coalitions-consensus protocol with one safe-consensus object
We now prove that this g-2coalitions-consensus protocol is correct.
Lemma 10
The protocol of Fig. 6 solves the g-2coalitions-consensus task using one snapshot object and one safe-consensus object.
Proof
Let \(p_i\in \{p_1,\ldots ,p_g\}\); after \(p_i\) writes the tuple \(\langle v_1,\) \(v_2 \rangle \) to the snapshot object SM, it invokes the safe-consensus object and takes a snapshot of the shared memory, \(p_i\) enters into the if/else block at lines 6-10. Suppose that the test in line 6 is successful, this says that the safe-consensus object returned the value g to process \(p_i\). By the Safe-Validity condition of the safe-consensus task, either process \(p_g\) invoked the shared object or at least two processes \(p_j,p_k\) invoked the safe-consensus object concurrently (and it could happen that \(j,k\ne g\)). In any case, the participating processes wrote their input tuples to the snapshot object SM before accessing the safe-consensus object, so that \(p_i\) can see these values in its local variable \(sm_i\), and remember that the coalitions tuple C consisting of all the input values of processes \(p_1,\ldots ,p_g\) satisfies the properties
Thus, the equation \(\left| l(C) - r(C) \right| = 1\) tells us that only one process has input tuple \(\langle x, \bot \rangle \) \((x\ne \bot )\), then when \(p_i\) executes line 7, it will find a local register in \(sm_i\) such that \(sm_i\left[ j \right] .right \ne \bot \) and this value is assigned to \(dec_i\). Finally, \(p_i\) executes line 11, where it decides the value stored in \(dec_i\) and this variable contains a valid input value proposed by some process.
If the test at line 6 fails, the argument to show that \(dec_i\) contains a valid proposed input value is very similar to the previous one. This proves that the protocol satisfies the 2coalitions-Validity condition of the g-2coalitions-consensus task.
The Agreement condition is satisfied because by the Agreement condition of the safe-consensus task, all participating processes receive the same output value from the shared object and therefore all processes have the same value in the local variables \(val_i\) \((1\leqslant i \leqslant g)\), which means that all participating processes execute line 7 or all of them execute line 9. Then, for every process \(p_r\), \(dec_r\) contains the value \(sm_r\left[ j_r \right] .right\) or the value \(sm_r\left[ j^\prime _r \right] .left\) where \(j_r\) (\(j_r^\prime \)) depends on \(p_r\). But because the input pairs of the processes constitute a coalitions tuple C, they satisfy property (b) of the definition of coalitions tuple, which implies that \(sm_r\left[ j_r \right] .right = sm_r\left[ j_q \right] .right\) whenever \(sm_r\left[ j_r \right] .right\) and \(sm_r\left[ j_q \right] .right\) are non-\(\bot \) (a similar statement holds for the left sides). We conclude that all processes assign to the variables \(dec_i\) \((1\leqslant i \leqslant g)\) the same value and thus all of them decide the same output value, that is, the Agreement property of the g-2coalitions-consensus tasks is fulfilled. The Termination property is clearly satisfied. \(\square \)
5.2 The WOR Protocol for Consensus
We first give an intuitive description of the WOR protocol for consensus, using 2coalitions-consensus shared objects and then we introduce the formal specification and prove its correctness.
5.2.1 Intuitive Description
A simple way to describe the protocol that solves consensus is by seeing it as a protocol in which the processes use a set of \({n \atopwithdelims ()2}\) shared objects which implement our new g-2coalitions-consensus task. In this way, the protocol in Fig. 8 can be described graphically as shown in Fig. 7, for the case of \(n=4\). In each round of the protocol, some processes invoke a 2coalitions-consensus object, represented by the symbol \(\textsf {2CC}_i\). In round one, \(p_1\) and \(p_2\) invoke the object \(\textsf {2CC}_1\) with input values \(\langle v_1, \bot \rangle \) and \(\langle \bot , v_2 \rangle \) respectively, (where \(v_i\) is the initial input value of process \(p_i\)) and the consensus output \(u_1\) of \(\textsf {2CC}_1\) is stored by \(p_1\) and \(p_2\) in some local variables. In round two, \(p_2\) and \(p_3\) invoke the \(\textsf {2CC}_2\) object with inputs \(\langle v_2, \bot \rangle \) and \(\langle \bot , v_3 \rangle \) respectively and they keep the output value \(u_2\) in local variables. Round three is executed by \(p_3\) and \(p_4\) in a similar way, to obtain the consensus value \(u_3\) from the 2coalition-consensus object \(\textsf {2CC}_3\). At the beginning of round four, \(p_1,p_2\) and \(p_3\) gather the values \(u_1,u_2\) obtained from the objects \(\textsf {2CC}_1\) and \(\textsf {2CC}_2\) to invoke the \(\textsf {2CC}_4\) 2coalition-consensus object with the input values \(\langle u_1, \bot \rangle , \langle u_1, u_2 \rangle \) and \(\langle \bot , u_2 \rangle \) respectively (Notice that \(p_2\) uses a tuple with both values \(u_1\) and \(u_2\)) and they obtain a consensus value \(u_4\). Similar actions are taken by the processes \(p_2,p_3\) and \(p_4\) in round five with the shared object \(\textsf {2CC}_5\) and the values \(u_2,u_3\) to compute an unique value \(u_5\). Finally, in round six, all processes invoke the last shared object \(\textsf {2CC}_6\), with the respective input tuples
and the shared object returns to all processes an unique output value u, which is the decided output value of all processes, thus this is the final consensus of the processes.

The structure of the 4-consensus protocol using 2coalitions-consensus tasks
5.2.2 Formal Specification
The formal specification of the iterated consensus protocol with safe-consensus objects is given in Fig. 8. This is a protocol that implements consensus using only \({n \atopwithdelims ()2}\) 2coalitions-consensus tasks. If we suppose that the protocol is correct, then we can use the g-2coalitions-consensus protocol presented in Section 5.1 (Fig. 6) to replace the call to the 2coalitions-consensus objects in Fig. 8 to obtain a full iterated protocol that solves the consensus task using \({n \atopwithdelims ()2}\) safe-consensus objects.

An iterated consensus protocol using g-2coalitions-consensus objects
We now give a short description of how the protocol works. There are precisely \({n \atopwithdelims ()2}\) rounds executed by the processes and in each round, some subset of processes try to agree in a new consensus value among two given input values. The local variables step, firstid and lastid are used by the processes to store information that tell them which is the current set of processes that must try to reach a new agreement in the current round, using a 2coalitions-consensus object (the symbol ”id“ contains the id of the process which is executing the code). The local array agreements contains enough local registers used by the processes to store the agreements made in each round of the protocol and two distinct processes can have different agreements in agreements. Each consensus value v stored in a register of agreements is associated with two integers \(i_1,i_r \in \overline{n}\) (\(r\geqslant 1\)), which represent a set of processes \(p_{i_1},\ldots ,p_{i_r}\) (with \(i_1< \cdots < i_r\)) that have invoked a 2coalitions-consensus object to agree on the value v, thus we can say that v is an agreement made by the coalition of processes represented by the pair \((i_1,i_r)\). To be able to store v in the array agreements, the processes use a deterministic function \({\textbf {tup }} :\mathbb {N} \times \mathbb {N} \rightarrow \mathbb {N}\), which maps bijectively \(\mathbb {N} \times \mathbb {N}\) onto \(\mathbb {N}\). This map can be easily constructed, for example, here is a simple definition for \({\textbf {tup }}\)
Using all the elements described above, the processes can use the protocol of Fig. 8 to implement consensus using \({n \atopwithdelims ()2}\) 2coalitions-consensus objects, building in the process the structure depicted in Fig. 7. From the first round and up to round \(n - 1\), all the processes use their proposed input values to make new agreements in pairs, in round one, \(p_1,p_2\) invoke a 2coalitions-consensus shared object to agree on a common value, based on their input values; in round 2, \(p_2\) and \(p_3\) do the same with another 2coalitions-consensus object and their own input values; later, the turn comes to \(p_3\) and \(p_4\) to do the same with another shared object and their input values and so on until the round number \(n - 1\), where \(p_{n-1}\) and \(p_n\) agree on a common value in the way that we have already described. All the agreements obtained in these \(n - 1\) rounds are stored on the local registers
In this way, the processes build the first part of the structure shown in Fig. 7. At the end of round \(n - 1\), in lines 14-15, each process updates the values of the local variables step and firstid and proceeds to round n. What happens in the next \(n - 2\) rounds, is very similar to the case of the previous \(n - 1\) rounds, but instead of making agreements in pairs, the processes reach new agreements in groups of three processes (see Fig. 7) invoking new 2coalitions-consensus shared objects and the consensus values obtained in the first \(n - 1\) rounds and when each process reaches round \(n - 1 + n - 2= 2n - 3\), it updates the values of its local variables step and firstid and then the processes proceed to round \(2n - 2\).
In general, when the processes are about to begin executing round \((\sum ^{m}_{j=1} n - j) + 1\) (\(m < n\)), they will try to make \(n - (m + 1)\) new agreements in groups of size \(m+2\), with the aid of the 2coalitions-consensus objects and the agreements they obtained from the previous \(n - m\) rounds and store the new consensus values in their local arrays agreements, using the \({\textbf {tup }}\) function. When a process finishes round \((\sum ^{m+1}_{j=1} n - j)\), the values of step and firstid are updated to repeat the described behaviour for the next \(n - (m + 2)\) rounds, until the \({n \atopwithdelims ()2}\) round, where the last agreement is made and this value is the output value of all the processes.
Now we are ready to give the full proof of Theorem 3. We need a series of Lemmas.
Lemma 11
The protocol in Fig. 8 solves the consensus task using \({n \atopwithdelims ()2}\) g-2coalitions-consensus objects.
Proof
The protocol clearly satisfies the Termination condition of the consensus task (the only loop is finite). We prove that it fulfils the Agreement and Validity conditions; to do this, we need some definitions and some intermediate results.
With respect to the protocol of Fig. 8, let \(F=\{ i_1, \ldots , i_r \}\subseteq \overline{n}\) be elements such that \(i_1< \cdots < i_r\). The set F will be called a coalition and will be denoted by \(F=\left[ i_1,\ldots ,i_r \right] \). Let \(p_i\) a process such that \(i\in F\). We say that \(p_i\) belongs to the coalition F if and only if the following condition is fulfilled:
-
(1)
\(agreements_{i}\left[ {\textbf {tup }}(i_1, i_r) \right] = v\), where \(v\ne \bot \) is a valid input value proposed by some participating process.
We ask the following agreement property to be satisfied by F:
-
(2)
if \(p_i,p_j\) are processes which belong to F and \(v,v^\prime \) are the values which satisfy (1) for \(p_i\) and \(p_j\) respectively, then \(v = v^\prime \).
The value v of the first condition is called the name of the coalition. The second condition says that all processes that belong to the same coalition must agree on the coalition’s name. For \(n>m\geqslant 0\), let \(\gamma (n,m)\) be defined by
Notice that \(\gamma (n,m)=\sum _{i=1}^{m} n -i\) for \(m>0\) and \(\gamma (n, n - 1)= {n \atopwithdelims ()2}\). \(\square \)
Lemma 12
Let \(1\leqslant m \leqslant n - 1\) and \(1\leqslant c \leqslant n - m\). If \(p_i\) is executing the protocol at the beginning of round number \(r=\gamma (n, m - 1) + c\) (before line 11) then \(step_i = m\) and \(firstid_i= c\).
Proof
We prove this by induction on m. An easy analysis of the code in Fig. 8 shows that the base case holds (when \(m=1\), in the first \(n -1\) rounds). Assume that for \(m< n - 1\), the lemma is true. We first prove the following claim: When \(p_i\) starts executing round \(\gamma (n,m) + 1\), \(step_i = m+1\) and \(firstid_i=1\). By the induction hypothesis, when process \(p_i\) executed the protocol at round \(r^\prime = \gamma (n,m) = \gamma (n, m - 1) + c= \gamma (n, m - 1) + (n - m)\) before line 11, the local variables \(step_i\) and \(firstid_i\) had the values of m and \(n-m\) respectively. When \(p_i\) reached line 11, it executed the test of the if statement, but before that, \(p_i\) executed line 4 of the protocol, gather that, \(lastid_i = firstid_i + step_i = (n - m) + m = n\); thus the test in line 11 failed and \(p_i\) executed lines 14-15 of the else statement (\(firstid_i> 1\) because \(m < n - 1\)) and then \(step_i\) was incremented by one and \(firstid_i\) was set to 1 at the end of round \(r^\prime \). Therefore, when \(p_i\) starts executing round \(\gamma (n,m) + 1\), \(step_i = m+1\) and \(firstid_i=1\).
Now suppose that \(p_i\) executes the protocol at the beginning of round number \(r = \gamma (n,m) + c\) where \(1\leqslant c \leqslant n - (m + 1)\). If \(c = 1\) then by the preceding argument, \(step_i= m + 1\) and \(firstid_i = 1 = c\). Using this as a basis for an inductive argument, we can prove that for \(c\in \{ 1, \ldots , n - (m + 1)\}\), \(c=firstid_i\) and \(step_i = m + 1\). \(\square \)
Lemma 13
Let \(0\leqslant m \leqslant n - 2\). Suppose that process \(p_i\) is about to begin executing the protocol at round \(r=\gamma (n,m) + c\) \((1 \leqslant c \leqslant n - (m + 1))\). If \(c\leqslant i \leqslant c+m+1\) and \(p_i\) belongs to the coalition \(P= \left[ c,\ldots ,c + m \right] \) or it belongs to the coalition \(Q= \left[ c+1,\ldots ,c + m+ 1 \right] \), then at the end of round r, \(p_i\) belongs to the coalition \(\left[ c,\ldots ,c + m+ 1 \right] \).
Proof
Let \(p_i\) be any process that begins executing round r. By Lemma 12, we know that \(step_i = m + 1\) and \(firstid_i = c\), which implies that \(lastid_i=c + m + 1\). If \(i\in \{c, \ldots , c+ m+1 \}\), the if’s test at line 5 is successful and after that what happens in lines 6, 7 depends on i. If \(c\leqslant i \leqslant c + m\), then \(p_i\) is in the coalition P and if \(c+ 1\leqslant i \leqslant c + m+ 1\), \(p_i\) is in the coalition Q, gather that, a valid input value is assigned to at least one of the variables \(C_i\) or \(D_i\), so \(p_i\) invokes in line 8 the \((m+2)\)-2coalitions-consensus object with the input \(x_i = \langle C_i,D_i\rangle \). We now pause for a moment to argue that the tuple \(J=(x_c,\ldots ,x_{c+m+1})\) built with the inputs of processes \(p_c,\ldots ,p_{c+m+1}\) is a valid global input for the \((m+2)\)-2coalitions-consensus task. Indeed, from the hypothesis, it is easy to see that J satisfies the requirements (a)-(c) of the definition of coalition tuple and notice that \(r(J) - l(J) = \{ c + m+1 \}\) and \(l(J) - r(J) = \{ c \}\).
Now back to the execution of process \(p_i\). After \(p_i\) invokes the \((m+2)\)-2coalitions-consensus task, the return value of the shared object, say v, is assigned to the local variable \(newagreement_i\). Finally, \(p_i\) stores the contents of \(newagreement_i\) in the local array \(agreements_i\) at position \({\textbf {tup }}(firstid_i, lastid_i)\), where \(firstid_i=c\) and \(lastid_i=c+m+1\). Because of the Agreement condition of the 2coalitions-consensus task, every process with id in the set \(\{ c,\ldots , c+ m+ 1\}\) obtained the same value v as return value from the shared object and by the 2coalitions-Validity, this is a valid input value proposed by some process. Therefore process \(p_i\) belongs to the coalition \(\left[ c,\ldots ,c + m+ 1 \right] \) at the end of round r.
On the other hand, if \(i\notin \{ c, \ldots , c+ m+1 \}\), \(p_i\) does not execute the body of the if statement (lines 6 to 9) and it goes on to execute the if/else block at lines 11-16 and then round r ends for \(p_i\), thus it does not try to make a new coalition with other processes. \(\square \)
Lemma 14
Let \(m\in \{0,\ldots ,n - 2\}\) be fixed. Suppose that process \(p_j\) has executed the protocol for \(\gamma (n, m)\) rounds and that there exists \(i\in \{ 1, \ldots , n - (m + 1) \}\) such that \(p_j\) belongs to the coalition \(\left[ i,\ldots , i + m\right] \) or it belongs to the coalition \(\left[ i + 1, \ldots , i + m +1\right] \). Then after \(p_j\) has executed the protocol for \(n - (m+1)\) more rounds, \(p_j\) belongs to the coalition \(\left[ i,\ldots , i + m + 1\right] \).
Proof
We apply Lemma 13 in each round \(\gamma (n, m) + c\), where \(c\in \{ 1, \ldots ,n - (m+1)\}\). \(\square \)
Now we can complete the proof of Lemma 11. Let \(p_j\) be any process that executes the protocol. Just at the beginning of the first round (line 2), process \(p_j\) belongs to the coalition \(\left[ j \right] \) (because of the assignments made to the local array \(agreements_j\) in line 1, so that if \(p_j\) executes the protocol for \(\gamma (n,1)=n-1\) rounds, we can conclude using Lemma 14, that process \(p_j\) belongs to some of the coalitions \(\left[ i, i+1 \right] \) \((1\leqslant i \leqslant n - 1)\). Starting from this fact and using induction on m, we can prove that for all \(m=1,\ldots ,n - 1\); at the end of round \(\gamma (n,m)\), \(p_j\) belongs to some of the coalitions \(\left[ i,\ldots , i + m \right] \) \((1\leqslant i \leqslant n - m)\). In the last round (when \(m=n -1\)), after executing the main for block, process \(p_j\) belongs to the coalition \(T=\left[ 1,\ldots ,n\right] \), thus when \(p_j\) executes line 18, it will assign to the local variable \(dec_i\) a valid proposed input value and this is the value decided by \(p_j\) at line 19. All processes decide the same value because all of them are in the coalition T. Therefore the protocol satisfies the Agreement and Validity conditions of the consensus task.
The final result of this section is obtained by combining Lemmas 10 and 11.
Theorem 3
There exists a WOR protocol that solves the consensus task for n processes using \({n \atopwithdelims ()2}\) safe-consensus objects.
5.3 The Lower Bound
The main result of this paper is a matching lower bound on the number of safe-consensus objects needed to solve consensus using safe-consensus. Our lower bound proof is based partly on standard bivalency arguments [2], but in order to be able to apply them, a careful combinatorial work is necessary.
5.3.1 The Connectivity of Iterated Protocols with Safe-Consensus
Roughly speaking, a typical consensus impossibility proof shows that a protocol \(\mathcal {A}\) cannot solve consensus because there exists one execution of \(\mathcal {A}\) in which processes decide a consensus value v and a second execution of \(\mathcal {A}\) where the consensus output of the processes is \(v^\prime \), with \(v\ne v^\prime \), such that the global states of these executions can be connected with paths of connected states. The existence of such paths will imply that in some execution of \(\mathcal {A}\), some processes decide distinct output values [2, 3, 8, 29], violating the Agreement requirement of consensus. Any protocol that solves consensus, must be able to destroy these paths of connected states.
Remember from Section 3.5 that the set \(\Gamma _\mathcal {A}(n,m)\) encodes all the valid subsets of processes of size m that can invoke safe-consensus objects in \(\mathcal {A}\). The cardinality of \(\Gamma _\mathcal {A}(n,m)\) is denoted by \(\nu _\mathcal {A}(n ,m)\) and
For the case of our lower bound proof, the main property that will prevent \(\mathcal {A}\) from solving consensus (i.e., from destroying paths of connected states) is that for some \(m_0\in \{ 2,\ldots ,n \}\), it is true that
i.e., at most \(n - m_0\) subsets of processes of size \(m_0\) can invoke safe-consensus shared objects in the protocol \(\mathcal {A}\). We are ready to present our main result, it is the following
Theorem 4
If \(\mathcal {A}\) is a WOR protocol for n-consensus using safe-consensus objects, then for every \(m\in \{ 2,\ldots , n \}\), \(\nu _\mathcal {A}(n,m) > n - m\).
Theorem 4 describes the minimum number of different process groups, each of size m, that must invoke safe-consensus shared objects, in order to be able to solve the consensus task, for each \(m = 2,\ldots , n\). The lower bound on the total number of safe-consensus objects necessary to implement consensus, is an easy consequence of Theorem 4 and the definition of \(\nu _\mathcal {A}(n)\).
To understand better the implications of Theorem 4 on the minimum number of safe-consensus shared objects needed to implement n-consensus, here is an example: Let \(n = 5\) and suppose \(\mathcal {A}\) is a WOR protocol that solves 5-consensus. By Theorem 4, for each \(m= 2,3,4,5\), \(\mathcal {A}\) satisfies the following inequalities:
-
\(\nu _\mathcal {A}(5,2) > 5 - 2 = 3\),
-
\(\nu _\mathcal {A}(5,3) > 5 - 3 = 2\),
-
\(\nu _\mathcal {A}(5,4) > 5 - 4 = 1\),
-
\(\nu _\mathcal {A}(5,5) > 5 - 5 = 0\).
In words, There must be at least 4 groups of 2 processes that invoke safe-consensus objects, 3 groups of 3 processes that invoke safe-consensus objects, 2 groups of 4 processes and finally, a group of 5 processes (e.g., all the processes) that must invoke a safe-consensus object. Thus the minimum total number of safe-consensus shared objects that the processes must invoke in \(\mathcal {A}\) to implement consensus is
Generalizing this example for arbitrary n, we obtain the inequality \(\nu _{\mathcal {A}}(n) \geqslant {n \atopwithdelims ()2}\). Notice that we are not counting trivial boxes (safe-consensus objects invoked by one process) in the lower bound.
Theorem 4 will be proven by contradiction, that is, we will assume that for some \(m_0\), Equation (3) holds. There are two structural results about WOR protocols that will be needed: Lemmas 20 and 23. Basically, these two results tell us how to find paths of connected reachable states in every round of an executing WOR protocol, whenever Equation (3) is satisfied. The proof of each lemma relies on the development of various results about the connectivity of states of WOR protocols with safe-consensus shared objects and additionally, these results give us information about the combinatorial interactions that exists between the sets of processes which cannot distinguish between the states of a path and the boxes that represent safe-consensus objects invoked by the processes. This extra information is provided by two results about the connectivity of subgraphs of Johnson graphs, Lemma 21 and Theorem 6. Since the theory and prior results needed to prove these two results are purely combinatorial, we defer their formal proofs to Appendix A.
5.3.2 Further Model Terminology
We will be using definitions and terminology given in Sections 2 and 3. Before giving the formal proof of our results, we need some technical definitions and lemmas. First, we define a set of round schedules that will be very useful for the rest of the paper. Given \(q\geqslant 1\) disjoint sets \(A_1,\ldots ,A_q\subset \overline{n}\), define the round schedule \(\xi (A_1,\ldots ,A_q)\) for \(\mathcal {A}\) as:
where \(Y=\overline{n} - (\bigcup _{i=1}^q A_i)\). For any state S and \(u\geqslant 0\), define
I.e. \(S\cdot \xi ^{u}(A_1,\ldots ,A_q)\) is the state that we obtain after we run the protocol \(\mathcal {A}\) (starting from S) u rounds with the round schedule \(\xi (A_1,\ldots ,A_q)\) each iteration.
Let \(\mathcal {A}\) be a WOR protocol for n-processes, \(X\subseteq \overline{n}\), R a state of some round \(r > 0\) and \(b\in \textbf{Inv}(R)\). We say that R is a ladder state for X with step b, if \(R= S\cdot \xi (C_1,\ldots ,C_u, B)\) \((u \geqslant 0)\), where S is a reachable state in \(\mathcal {A}\) and
-
\(X=(\bigcup _j^u C_j) \cup B\);
-
for \(j=1,\ldots ,u\), \(0 \leqslant |C_j |\leqslant 2\);
-
\((\bigcup _j^u C_j) \cap b=\varnothing \);
-
\(B = b \cap X\).
The following definition is given for convenience. For each box \(b_i\) and \(W \subseteq \overline{n}\), let the set \(W_{(i)}\) be defined as
Lemma 15
Let \(\mathcal {A}\) be a WOR protocol for \(n\geqslant 2\) processes with safe-consensus objects and S a reachable state in \(\mathcal {A}\). Then for any two round schedules \(\pi _1,\pi _2\), \(\textbf{Inv}(S\cdot \pi _1) = \textbf{Inv}(S\cdot \pi _2)\).
Proof
In Fig. 3, notice that process \(p_i\) executes the deterministic function h with the local state it has from the previous round (except from the round counter r), so that if r is the round number of S and \(p_i\) starts executing the protocol \(\mathcal {A}\) in round \(r+1\) with the local state it had in S, the input to the function h is given by the tuple \((r+1, i, sm_S, val_S)\), where \(sm_S,val_S\) depend only on S. Thus in both successor states \(S\cdot \pi _1\) and \(S\cdot \pi _2\), \(p_i\) feeds the same input to h, gather that
and the lemma is true. \(\square \)
5.4 The Local Structure of WOR Protocols with Safe-Consensus Objects
In this section, we present results that will be needed to prove Lemma 20. The goal here is to show Theorem 5, which give us a way to connect two states of the form \(S\cdot \xi (X)\) and \(S\cdot \xi (Y)\) for \(X,Y\subseteq \overline{n}\) and any reachable state S of a WOR protocol. Put it another way, with Theorem 5 we can connect for a given WOR protocol, a state that is obtained if the processes with ids in X first update the memory, invoke safe-consensus objects and finally they snapshot the shared memory and after that, processes with ids in \(\overline{n} - X\) perform the same actions, with a state that is obtained when processes with ids in Y and ids in \(\overline{n} - Y\) perform the same action in the same way. All this is done with a careful handling of the safe-consensus values returned by the shared objects to the processes, in order to keep the degree of indistinguishability of the path as high as possible. The ladder states defined previously play an important role in the construction of the path given by Theorem 5.
Lemma 16
Let \(n\geqslant 2\), \(\varnothing \ne X\subseteq \overline{n}\), \(\mathcal {A}\) a WOR protocol with safe-consensus objects, S a state that is reachable in \(\mathcal {A}\) in some round \(r\geqslant 0\) and \(b\in \textbf{Inv}(S_X)\), where \(S_X=S\cdot \xi (X)\). Then there exists a state L, such that L is a ladder state for X with step b, such that \(S_X\) and L are connected in round \(r+1\) with a path of states \(\mathfrak {p}\) with \(\deg \mathfrak {p} \geqslant n -2\).
Proof
Let \(\textbf{Inv}(S_X)= \{ b_1,\ldots , b_q \}\) \((q\geqslant 1)\). By Lemma 15, for any one-round successor state Q of S, \(\textbf{Inv}(Q)=\textbf{Inv}(S_X)\) and we can write \(\textbf{Inv}_{S}\) instead of \(\textbf{Inv}(S_X)\). Without loss of generality, assume that \(b_1=b\). If \(q=1\), then \(b_1=\overline{n}\) and the result is immediate, because \(S_X\) is a ladder state for X with step \(\overline{n}\). Suppose that \(q > 1\). Partition X as \(X=X_{(1)} \cup \cdots \cup X_{(q)}\) and build the following sequence of connected states
where \(X_{(2)}=\bigcup _{i=1}^{\alpha _2} \Lambda _{2}(i)\) is a partition of \(X_{(2)}\) such that \(|\Lambda _{2}(j) |=1\) for \(j=2,\ldots ,\alpha _2\). The set \(\Lambda _{2}(1)\) has cardinality given by
(notice that the \(\Lambda _{2}(j)\)’s and \(\alpha _2\) depend on \(b_2\) and \(X_{(2)}\)), and we choose the safe-consensus value of every box in the set \(\textbf{Inv}_{S}\) to be the same in each state of the previous sequence. This can be done because of the way we partition \(X_{(2)}\), the election of the elements of the set \(\Lambda _{2}(1)\) and the properties of the safe-consensus task (Safe-Validity). We execute similar steps with box \(b_3\), so that we obtain the path
where the \(\Lambda _{3}(i)\)’s and \(\alpha _3\) depend on \(b_3\) and \(X_{(3)}\), just in the same way the \(\Lambda _{2}(j)\)’s and \(\alpha _2\) depend on \(b_2\) and \(X_{(2)}\) and each box has safe-consensus value equal to the value it has in the sequence of (6). We can repeat the very same steps for \(b_4,\ldots ,b_q\) to obtain the sequence
It is easy to prove that \(L=S \cdot \xi (\Lambda _{2}(1),\ldots ,\Lambda _{q}(\alpha _q), X_{(1)})\) is a ladder state for X with step \(b_1\) and that each of the sequences of equations (6), (7) and (8) has indistinguishability degree no less that \(n -2\). Combining all these sequences, we obtain a new path
with \(\deg \mathfrak {p} \geqslant n - 2\). \(\square \)
Lemma 17
Let \(n\geqslant 2,X,Y \subseteq \overline{n}\), \(\mathcal {A}\) a WOR protocol with safe-consensus objects and S a state that is reachable in \(\mathcal {A}\) in some round \(r\geqslant 0\). Assume also that \(b_j\) is a box representing a safe-consensus object invoked by some processes such that \(b_j\in \textbf{Inv}(L_1) = \textbf{Inv}(L_2)\), where \(L_1 = S\cdot \xi (C_1,\ldots ,C_u,X_{(j)})\) is a ladder state for X with step \(b_j\) and \(L_2 = S\cdot \xi (C_1,\ldots ,C_u, Y_{(j)})\) is a ladder state for \((X - X_{(j)}) \cup Y_{(j)}\) with step \(b_j\). Finally, suppose that if \(b_j=\overline{n}\), \(\textsf{scval}(b_j,L_1)=\textsf{scval}(b_j,L_2)\). Then \(L_1\) and \(L_2\) are connected in round \(r+1\) with a C-regular path of states \(\mathfrak {p}\) that satisfies the following properties:
-
i)
If \(\textsf{scval}(b_j,L_1)=\textsf{scval}(b_j,L_2)\) then \(\deg \mathfrak {p} \geqslant n - 2\).
-
ii)
If \(\textsf{scval}(b_j,L_1) \ne \textsf{scval}(b_j,L_2)\) then \(\deg \mathfrak {p} \geqslant n - |b_j |\) and \(\overline{n} - b_j \in \textsf{iSets}(\mathfrak {p})\).
Proof
Partition \(\overline{n}\) as the disjoint union \(\overline{n}=X^- \cup (X \cap Y) \cup Y^- \cup W\), where
-
\(X^-=X - Y\);
-
\(Y^- = Y - X\);
-
\(W =\overline{n} - (X^- \cup (X \cap Y) \cup Y^-)\).
What we need to do to go from \(L_1\) to \(L_2\) is to “interchange” \(X_{(j)}\) with \(Y_{(j)}\). We first construct a sequence of connected states \(\mathfrak {p}_1\) given by
where the following properties hold:
-
\(X_{(j)}=\bigcup _{i=1}^{\alpha _j} \Lambda _{j}(i)\) is a partition of \(X_{(j)}\) such that \(|\Lambda _{j}(l) |=1\) for \(l=2,\ldots ,\alpha _j\);
-
\(|\Lambda _{j}(1) |= 2\) if \(|X_{(j)} |> 1\) and \(|\Lambda _{j}(1) |= |X_{(j)} |\) otherwise;
-
\(\mathfrak {p}_1\) is a C-regular sequence (Lemma 15) with \(\deg \mathfrak {p}_1 \geqslant n - 2\);
-
the safe-consensus value of every box \(b_i\) is the same in each state of \(\mathfrak {p}_1\). This can be achieved by a proper selection of elements of the set \(\Lambda _{j}(1)\) and the Safe-Validity property of the safe-consensus task.
Now, since the following equalities hold:
we can write the state \(S \cdot \xi (C_1,\ldots ,C_u,X_{(j)} \cup Y^- \cup W)\) as
We need to build a second path \(\mathfrak {p}_2\) as follows:
Let \(L_2\) be the last state of the previous sequence. The next assertions are true for the path \(\mathfrak {p}_2\):
-
The sets \(\Omega _{j}(i)\) and \(\epsilon _j\) are defined for \(Y_{(j)}\) and \(b_j\) in the same way as the \(\Lambda _{j}(i)\) and \(\alpha _j\) are defined for \(X_{(j)}\) and \(b_j\);
-
The sequence \(\mathfrak {p}_2\) is C-regular (Lemma 15);
-
The safe-consensus value of every box \(c\ne b_j\) is the same in every element of \(\textsf{States}(\mathfrak {p}_2)\);
-
\(\textsf{scval}(b_j,Q)=\textsf{scval}(b_j,P)\) for all \(Q,P\in \textsf{States}(\mathfrak {p}_2) - \{ R \}\), where R is such that
$$\begin{aligned} R=S \cdot \xi (C_1,\ldots ,C_u,Y_{(j)} \cup X^-_{(j)} \cup (Y^- - Y^-_{(j)})\cup W); \end{aligned}$$ -
the set U is defined by
$$\begin{aligned} U= \left\{ \begin{array}{ll} b_j &{} \text {if } \textsf{scval}(b_j,L_1) \ne \textsf{scval}(b_j,L_2) \\ \Omega _{j}(1) &{} \text {otherwise;} \end{array}\right. \end{aligned}$$(10)
Notice that by the last assertion, we can deduce that \(\deg \mathfrak {p}_2 \geqslant n - |b_j |\text { and } \overline{n} - b_j \in \textsf{iSets}(\mathfrak {p}_2)\) if \(\textsf{scval}(b_j,L_1) \) \(\ne \textsf{scval}(b_j,L_2)\) and \(\deg \mathfrak {p}_2 \geqslant n - 2\) when \(\textsf{scval}(b_j,L_1) = \textsf{scval}(b_j,L_2)\). Thus we can use \(\mathfrak {p}_1\) and \(\mathfrak {p}_2\) to obtain a C-regular sequence \(\mathfrak {p}\) which fulfils properties i)-ii) of the lemma and that concludes the proof. \(\square \)
Lemma 18
Let \(n\geqslant 2\), \(X,Y \subseteq \overline{n}\), \(\mathcal {A}\) a WOR protocol with safe-consensus objects, S a state that is reachable in \(\mathcal {A}\) in some round \(r\geqslant 0\) and \(b_j\) a box representing a safe-consensus object invoked by some processes in round \(r+1\) such that \(b_j\in \textbf{Inv}(Q_1) = \textbf{Inv}(Q_2)\), where \(Q_1 = S\cdot \xi (X)\) and \(Q_2 = S\cdot \xi (Y_{(j)} \cup (X - X_{(j)}))\). Assume also that if \(b_j=\overline{n}\), \(\textsf{scval}(b_j,Q_1) = \textsf{scval}(b_j,Q_2)\). Then the states \(Q_1\) and \(Q_2\) are connected in round \(r+1\) with a C-regular path of states \(\mathfrak {p}\) that satisfies the following properties:
-
a)
If \(\textsf{scval}(b_j,Q_1) = \textsf{scval}(b_j,Q_2)\) then \(\deg \mathfrak {p} \geqslant n - 2\).
-
b)
If \(\textsf{scval}(b_j,Q_1) \ne \textsf{scval}(b_j,Q_2)\) then \(\deg \mathfrak {p} \geqslant n - |b_j |\) and \(\overline{n} - b_j \in \textsf{iSets}(\mathfrak {p})\).
Proof
By Lemma 16, the state \(Q_1\) can be connected with a state of the form \(Q_{X_{(j)}}=S\cdot \xi (B_{1},\ldots ,B_{s},X_{(j)})\) with a C-regular path \(\mathfrak {q}_1\) such that \(\deg \mathfrak {q}_1 \geqslant n - 2\). Using Lemma 17, \(Q_{X_{(j)}}\) can be connected with \(Q_{Y_{(j)}}=S\cdot \xi (B_{1},\ldots ,B_{s},Y_{(j)})\) by means of a C-regular sequence \(\mathfrak {q}_2:Q_{X_{(j)}}{\sim } \cdots {\sim } Q_{Y_{(j)}}\) such that \(\mathfrak {q}_2\) satisfies properties i) and ii) of that Lemma. And we can apply Lemma 16 to connect \(Q_{Y_{(j)}}\) with \(Q_2\) with the C-regular path \(\mathfrak {q}_3\) which has indistinguishability degree no less that \(n - 2\). Therefore the sequence of connected states built by first gluing together the sequences \(\mathfrak {q}_1\) and \(\mathfrak {q}_2\), followed by \(\mathfrak {q}_3\), is a C-regular sequence \(\mathfrak {q}\) such that the requirements a)-b) are satisfied. \(\square \)
With the three previous lemmas at hand, we are almost ready to state and prove Theorem 5, only one more definition is necessary. Let \(Q_1,Q_2\) be two reachable states in round r of an iterated protocol \(\mathcal {A}\) for n processes with safe-consensus objects. The set \(\mathfrak {D}_\mathcal {A}^r(Q_1,Q_2)\) is defined as
In words, \(\mathfrak {D}_\mathcal {A}^r(Q_1,Q_2)\) represents the safe-consensus shared objects that the same subset of processes invoked in both states \(Q_1\) and \(Q_2\), such that the shared objects returned different output values in each state. If there is no confusion about which round number and protocol we refer to, we will write \(\mathfrak {D}_\mathcal {A}^r(Q_1,Q_2)\) as \(\mathfrak {D}(Q_1,Q_2)\).
Theorem 5
Let \(n\geqslant 2\) and \(X,Y \subseteq \overline{n}\), \(\mathcal {A}\) a WOR protocol with safe-consensus objects, S a reachable state of \(\mathcal {A}\) in some round \(r\geqslant 0\) and let \(Q_1=S\cdot \xi (X)\) and \(Q_2=S\cdot \xi (Y)\) be such that \(\overline{n} \notin \mathfrak {D}(Q_1,Q_2)\). Then \(Q_1\) and \(Q_2\) are connected in round \(r+1\) with a C-regular path of states \(\mathfrak {p}\) such that
-
(A)
If \(\mathfrak {D}(Q_1,Q_2)=\varnothing \), then \(\deg \mathfrak {p} \geqslant n - 2\).
-
(B)
If the set \(\mathfrak {D}(Q_1,Q_2)\) is not empty, then
-
1.
\(\deg \mathfrak {p} \geqslant \min \{ n -|b |\}_{b\in \mathfrak {D}(Q_1,Q_2)}\);
-
2.
for every \(Z\in \textsf{iSets}(\mathfrak {p})\) with \(|Z |< n - 2\), there exists \(b\in \mathfrak {D}(Q_1,\) \(Q_2)\) such that \(Z=\overline{n}- b\).
-
1.
Proof
By Lemma 15, we have the following equation,
where \(P_l\) is a one-round successor state of S and \(\textbf{Inv}_{S}=\textbf{Inv}(P_l)\), \(l=1,2\). Let \(\textbf{Inv}_{S}=\{ b_1, \ldots , b_q \}\). By Lemma 18, we can connect the state \(Q_1\) with \(R_1=S\cdot \xi (Y_{(1)} \cup (X - X_{(1)}))\) using a C-regular path \(\mathfrak {p}_1:Q_1 {\sim } \cdots {\sim } R_1\) such that
-
\((A_1)\) If \(b_1\notin \mathfrak {D}(Q_1,R_1)\), then \(\deg \mathfrak {p}_1 \geqslant n - 2\).
-
\((B_1)\) If \(b_1\in \mathfrak {D}(Q_1,R_1)\), then \(\deg \mathfrak {p}_1 \geqslant n - |b_1 |\) and \(\overline{n} - b_1 \in \textsf{iSets}(\mathfrak {p}_1)\).
Assume there is a set \(Z\in \textsf{iSets}(\mathfrak {p}_1)\) with size strictly less that \(n - 2\). Then it must be true that \(b_1\in \mathfrak {D}(Q_1,R_1)\), because if \(b_1\notin \mathfrak {D}(Q_1,R_1)\), by \((A_1)\), \(|Z |\geqslant n - 2\) and this is impossible. Thus the conclusion of property \((B_1)\) holds for \(\mathfrak {p}_1\), which means that \(\overline{n} - b_1 \in \textsf{iSets}(\mathfrak {p}_1)\). Examining the proofFootnote 4 of Lemma 18 we can convince ourselves that every \(W\in \textsf{iSets}(\mathfrak {p}_1)\) such that \(W\ne \overline{n} - b_1\) has cardinality at least \(n - 2\), therefore, \(Z=\overline{n} - b_1\).
Now, considering thatFootnote 5\(Y_{(2)} \cup ((Y_{(1)} \cup (X - X_{(1)})) - X_{(2)}) = Y_{(2)} \cup ((Y_{(1)} - X_{(2)}) \cup ((X - X_{(1)})- X_{(2)})) = Y_{(1)} \cup Y_{(2)} \cup (X - (X_{(1)} \cup X_{(2)}))\), we can apply Lemma 18 to the states \(R_1\) and \(R_2=S\cdot \xi (Y_{(1)} \cup Y_{(2)} \cup (X - (X_{(1)} \cup X_{(2)})))\) to find a C-regular sequence \(\mathfrak {p}_2 :R_1 {\sim } \cdots {\sim } R_2\) such that \(\mathfrak {p}_2\) and \(b_2\) enjoy the same properties that \(\mathfrak {p}_1\) and \(b_1\) have. We can combine the paths \(\mathfrak {p}_1\) and \(\mathfrak {p}_2\) to obtain a C-regular sequence \(\mathfrak {p}_{12}:Q_1 {\sim } \cdots {\sim } R_2\) from \(Q_1\) to \(R_2\) satisfying the properties
-
\((A_2)\) If \(\{ b_1, b_2 \} \cap \mathfrak {D}(Q_1,R_2) = \varnothing \), then \(\deg \mathfrak {p}_{12} \geqslant n - 2\).
-
\((B_2)\) If \(\{ b_1, b_2 \} \cap \mathfrak {D}(Q_1,R_2)\) is not empty, then
-
1.
\(\deg \mathfrak {p}_{12} \geqslant \min \{ n -|b |\}_{b\in \{ b_1, b_2 \} \cap \mathfrak {D}(Q_1,R_2)}\);
-
2.
for every \(Z\in \textsf{iSets}(\mathfrak {p}_{12})\) with \(|Z |< n - 2\), there exists an unique \(b\in \{ b_1, b_2 \} \cap \mathfrak {D}(Q_1,R_2)\) such that \(Z=\overline{n}-b\).
-
1.
We can repeat this process for all \(s\in \{1, \ldots , q \}\). In general, if \(R_s=S \cdot \xi ((\bigcup _{i}^s Y_{(i)}) \cup (X - (\bigcup _i^s X_{(i)})) )\), we can construct a C-regular path
with the properties
-
\((A_s)\) If \(\{ b_1, \ldots , b_s \} \cap \mathfrak {D}(Q_1,R_s) = \varnothing \), then \(\deg \mathfrak {p}_{1s} \geqslant n - 2\).
-
\((B_s)\) If \(\{ b_1, \ldots , b_s \} \cap \mathfrak {D}(Q_1,R_s)\) is not empty, then
-
1.
\(\deg \mathfrak {p}_{1s} \geqslant \min \{ n -|b |\}_{b\in \{ b_1, \ldots , b_s \} \cap \mathfrak {D}(Q_1,R_s)}\);
-
2.
for every \(Z\in \textsf{iSets}(\mathfrak {p}_{1s})\) with \(|Z |< n - 2\), there exists an unique \(b\in \{ b_1,\ldots ,\) \(b_s \} \cap \mathfrak {D}(Q_1,R_s)\) such that \(Z=\overline{n}- b\).
-
1.
As \(R_q=S \cdot \xi ((\bigcup _{i}^q Y_{(i)}) \cup (X - (\bigcup _i^q X_{(i)})) )=S\cdot \xi (Y)=Q_2\), the sequence \(\mathfrak {p}_{1q}\) is the desired C-regular path from \(Q_1\) to \(Q_2\), fulfilling conditions (A) and (B) (because \(\{ b_1, \ldots , b_q \} \cap \mathfrak {D}(Q_1,R_q) = \textbf{Inv}_{S} \cap \mathfrak {D}(Q_1,Q_2) = \mathfrak {D}(Q_1,Q_2)\)). The result follows. \(\square \)
5.5 The Main Structural Results
In this section, we prove Lemma 20. To do this, we need one more structural result, Lemma 19 and our main result about Johnson graphs: Theorem 6. We first introduce some combinatorial definitions before stating this theorem. Remember from Section 3.5 that for \(1\leqslant m \leqslant n\), \(V_{n,m}=\{ c\subseteq \overline{n} \mid \left| c \right| = m \}\) and let \(U\subseteq V_{n,m}\). We define the set \(\zeta (U)\) as
Notice that each \(f\in \zeta (U)\) has size \(m+1\), thus \(\zeta (U)\subseteq V_{n,m+1}\). For any \(v=0,\ldots ,n-m\), the iterated \(\zeta \)-operator \(\zeta ^v\) is given by
Since \(U\subseteq V_{n,m}\), we can check that \(\zeta ^v(U)\subseteq V_{n,m+v}\).
The intuitive interpretation of \(U,\zeta \) and the iterated \(\zeta \)-operator from the point of view of WOR consensus protocols is the following: U represents a set of possible intermediate agreements between some subsets of processes of size m and \(\zeta \) is some kind of method the processes use to extend the partial agreements specified by U to new agreements between sets of processes of size \(m+1\), but these new agreements can be made only if the required agreements of m processes exist inside U. The iterated \(\zeta \)-operator is just a way to extend \(\zeta \) to produce larger agreements, starting from agreements between sets of processes of size m. We are ready to state the combinatorial result needed to prove Lemma 20.
Theorem 6
Let \(U\subset V_{n,m}\) such that \(|U |\leqslant n - m\). Then \(\zeta ^{n - m}(U) = \varnothing \).
Notice that \(\zeta ^{n - m}(U)\subseteq V_{n,m+(n-m)}=V_{n,n}=\{ \overline{n} \}\). Thus, the intuitive meaning of Theorem 6 (again, from the point of view of WOR consensus protocols) is that if there are not enough agreements \((\leqslant n - m)\) of subsets of processes of size m, it is impossible to reach consensus among n processes, represented by the set \(\overline{n}\). See Appendix A for more details and the full proof of Theorem 6.
With respect to the proofs of Lemmas 19 and 20, we need one more definition regarding paths of connected states of a WOR protocol and the boxes representing safe-consensus shared objects. For a given path \(\mathfrak {s}\) of connected states of an iterated protocol \(\mathcal {A}\), consider the set
and if \(m\in \overline{n}\), let \(\beta _\mathcal {A}(\mathfrak {s}; m)=\beta _\mathcal {A}(\mathfrak {s}) \cap \Gamma _\mathcal {A}(n,m)\). Roughly speaking, the set \(\beta _\mathcal {A}(\mathfrak {s})\) captures the safe-consensus shared objects the processes can invoke to decrease the degree of indistinguishability of paths composed of states which are succesor states of the elements of \(\textsf{States}(\mathfrak {s})\). In other words, if the path \(\mathfrak {s}\) is composed of reachable states in \(\mathcal {A}\) in round r, then the boxes (safe-consensus objects) in \(\beta _\mathcal {A}(\mathfrak {s})\) can help the processes diminish the degree of indistinguishability of any posible path \(\mathfrak {q}\) such that each state in \(\textsf{States}(\mathfrak {q})\) is a successor state of some member of \(\textsf{States}(\mathfrak {s})\). If there is no confusion about which protocol we refer to, we write \(\beta (\mathfrak {s})\) and \(\beta (\mathfrak {s}; m)\) instead of \(\beta _\mathcal {A}(\mathfrak {s})\) and \(\beta _\mathcal {A}(\mathfrak {s}; m)\) respectively.
Lemma 19
Let \(n\geqslant 3\) and \(1 \leqslant v \leqslant s \leqslant n - 2\) be fixed. Suppose that \(\mathcal {A}\) is a WOR protocol with safe-consensus objects and that there exists a sequence
of connected states of round \(r\geqslant 0\) such that
- \(\Lambda _1\):
-
\(\deg \mathfrak {s} \geqslant v\).
- \(\Lambda _2\):
-
For every \(X_i\) with \(v \leqslant |X_i |< s\), there exists \(b_i\in \Gamma _\mathcal {A}(n,n - |X_i |)\) such that \(X_i=\overline{n} - b_i\)
- \(\Lambda _3\):
-
\(\overline{n} \notin \beta (\mathfrak {s})\).
Then in round \(r+1\) there exists a sequence
of connected successor states of all the \(S_j\), such that the following statements hold:
- \(\Psi _1\):
-
If \(\beta (\mathfrak {s}; n - v + 1)=\varnothing \), then \(\deg \mathfrak {q} \geqslant v\).
- \(\Psi _2\):
-
If \(\beta (\mathfrak {s}; n - v + 1) \ne \varnothing \), then \(\deg \mathfrak {q} \geqslant v - 1\).
- \(\Psi _3\):
-
For every \(Z\in \textsf{iSets}(\mathfrak {q})\) with \(|Z |= v - 1\), there exist \(X,X^\prime \in \textsf{iSets}(\mathfrak {s})\) and \(b\in \beta (\mathfrak {s}; n - v + 1)\) such that \(Z=\overline{n} - b=X \cap X^\prime \) and \(b=c_{1}\cup c_{2}\), \(c_{k}\in \Gamma _\mathcal {A}(n,n - v)\).
- \(\Psi _4\):
-
For every \(Z\in \textsf{iSets}(\mathfrak {q})\) with \(v \leqslant |Z |< s\), there exists \(b\in \Gamma _\mathcal {A}(n,n - |Z |)\) such that \(Z=\overline{n} - b\).
- \(\Psi _5\):
-
\(\beta (\mathfrak {q}; n - l + 1)\subseteq \zeta (\beta (\mathfrak {s}; n - l))\) for \(v \leqslant l < s\).
Proof
In order to find the path \(\mathfrak {q}\) that has the properties \(\Psi _1\)-\(\Psi _5\), first we need to define a set of states of round \(r+1\), called \(\Phi (\mathfrak {s})\), which we will use to construct the path \(\mathfrak {q}\). The key ingredient of \(\Phi (\mathfrak {s})\) is the safe-consensus values of the boxes used in each member of \(\Phi (\mathfrak {s})\). Define the set of states \(\Phi (\mathfrak {s})\) as
Each element of \(\Phi (\mathfrak {s})\) is a state in round \(r+1\) which is obtained when all the processes with ids in some set \(X\in \textsf{iSets}(\mathfrak {s})\) execute concurrently the operations of \(\mathcal {A}\), followed by all processes with ids in \(\overline{n} - X\). The safe-consensus values of each box for the states of \(\Phi (\mathfrak {s})\) in round \(r+1\) are defined by using the following rules: Let b be any box such that \(b\notin \beta (\mathfrak {s})\).
-
If \(|X \cap b|\ne 1\) for every \(X\in \textsf{iSets}(\mathfrak {s})\), then we choose any value j such that j is the safe-consensus value of b in every state \(R\in \Phi (\mathfrak {s})\) with \(b\in \textbf{Inv}(R)\).
-
If there exists exactly one set \(X\in \textsf{iSets}(\mathfrak {s})\) such that \(X \cap b = \{ x \}\), then b has \(j_x\) as its safe-consensus value in every state \(Q\in \Phi (\mathfrak {s})\) with \(b\in \textbf{Inv}(Q)\), where \(j_x\) is the value proposed by process \(p_x\) when invoking the safe-consensus object represented by b.
Now we establish rules to define the safe-consensus values of every element of the set \(\beta (\mathfrak {s})\), using the order on the set \(\textsf{iSets}(\mathfrak {s})\) induced by the path \(\mathfrak {s}\), when we traverse \(\mathfrak {s}\) from \(S_0\) to \(S_q\). That is, \(\textsf{iSets}(\mathfrak {s})\) is ordered as
For each \(b\in \beta (\mathfrak {s})\), let that \(X_i,X_{i+ z_1}, \ldots ,X_{i+ z_k}\), (\(1 \leqslant i< i+z_1< i+z_2<\cdots < i+z_{k} \leqslant q; z_j > 0\) and \(k \geqslant 1\)) be the (ordered) subset of \(\textsf{iSets}(\mathfrak {s})\) of all \(X\in \textsf{iSets}(\mathfrak {s})\) with the property \(|X \cap b |= 1\). Take the set \(X_i\). If \(x_i\in X_i \cap b\), then we make the value proposed by process \(p_{x_i}\) (when invoking the shared object represented by b) the safe-consensus value of b for all the elements of \(\Phi (\mathfrak {s})\) of the form
where \(b\in \textbf{Inv}(P_j)\). Next, in all states \(R_u\in \Phi (\mathfrak {s})\) such that \(R_u=S\cdot \xi (X_u)\) with \(b\in \textbf{Inv}(R_u)\) and \(i + z_1 \leqslant u \leqslant i + z_2 - 1\), b has safe-consensus value equal to the input value of the process with id \(x_{i+z_1}\in X_{i+z_1}\cap b\) when invoking the safe-consensus object represented by b. In general, in all states \(T_v\in \Phi (\mathfrak {s})\) of the form
where \(b\in \textbf{Inv}(T_v)\), b has safe-consensus value equal to the input value of the process with id \(x_{i+z_{l}}\in X_{i+z_l}\cap b\) feed to the safe-consensus object represented by b. Finally, in each state \(L_w=S\cdot \xi (X_w) \in \Phi (\mathfrak {s})\) with \(b\in \textbf{Inv}(L_w)\) and \(i+z_{k} \leqslant w \leqslant q\), b has safe-consensus value equal to the input value that the process with id \(x_{i+z_{k}}\in X_{i+z_k}\cap b\) inputs to the safe-consensus shared object represented by b.
Using the Safe-Validity property of the safe-consensus task, it is an easy routine task to show that we can find states of \(\mathcal {A}\) in round \(r+1\) which have the form of the states given in \(\Phi (\mathfrak {s})\) and with the desired safe-consensus values for every box.
We are ready to build the sequence \(\mathfrak {q}\) of the LemmaFootnote 6. We use induction on \(q\geqslant 1\). For the base case when \(q=1\), we have that \(\mathfrak {s} :S_0\overset{X_1}{\sim } S_1\), with \(|X_1 |\geqslant v\). Here we easily build the sequence \(S_0 \cdot \xi (X_1) \overset{X_1}{\sim }\ S_1 \cdot \xi (X_1)\) which clearly satisfies properties \(\Psi _1\)-\(\Psi _5\). Assume that for \(1\leqslant w < q\) we have a path
Satisfying conditions \(\Psi _1\)-\(\Psi _5\) and such that \(Q_0=S_0\cdot \xi (X_1),Q_l=S_w \cdot \xi (X_w)\). We now connect the state \(Q_l\) with \(Q=S_{w+1} \cdot \xi (X_{w+1})\). By Theorem 5, there is a C-regular sequence
such that \(Q^\prime =S_w \cdot \xi (X_{w+1})\) and \(\mathfrak {v},Q_l\) and \(Q^\prime \) satisfy conditions (A)-(B) of that theorem. Clearly \(\mathfrak {D}(Q_l,\) \(Q^\prime )\subseteq \beta (\mathfrak {s})\), because the only boxes used by \(\mathcal {A}\) in the states \(Q_l\) and \(Q^\prime \) with different safe-consensus value, are the boxes which intersect two different sets \(X,X^\prime \in \textsf{iSets}(\mathfrak {s})\) in one element. Joining the sequence \(\mathfrak {q}^\prime \) with \(\mathfrak {v}\), followed by the small path \(\mathfrak {t} :Q^\prime \overset{X_{w+1}}{\sim } Q\) (such that \(\deg \mathfrak {t} \geqslant v\)), we obtain a new sequence \(\mathfrak {q} :Q_0 {\sim } \cdots {\sim } Q\). We now need to show that \(\mathfrak {q}\) satisfies properties \(\Psi _1\)-\(\Psi _5\).
- \(\Psi _1\):
-
Notice that every box in \(\beta (\mathfrak {s})\) has size no bigger that \(n - v + 1\). Suppose that \(\beta (\mathfrak {s}; n - v + 1)=\varnothing \). In particular, this implies that \(\mathfrak {D}(Q_l,Q^\prime ) \cap \Gamma _\mathcal {A}(n, n - v + 1)=\varnothing \). If it happens that \(\mathfrak {D}(Q_l,Q^\prime )\) is void, then as condition (A) of Theorem 5 holds for \(\mathfrak {v}\), \(\deg \mathfrak {v} \geqslant v\). But if \(\mathfrak {D}(Q_l,Q^\prime )\ne \varnothing \) we have that \(|b |\leqslant n - v\) for all \(b\in \mathfrak {D}(Q_l,Q^\prime )\), thus by part 1. of property (B) of Theorem 5,
$$\begin{aligned} \deg \mathfrak {v} \geqslant \min \{ n -|b |\}_{b\in \mathfrak {D}(Q_l,Q^\prime )} \geqslant v. \end{aligned}$$By the induction, hypothesis \(\deg \mathfrak {q}^\prime \geqslant v\). It is also true that \(\deg \mathfrak {t} \geqslant v\), therefore \(\deg \mathfrak {q} \geqslant v\).
- \(\Psi _2\):
-
If \(\beta (\mathfrak {s}; n - v + 1)\ne \varnothing \), then either \(\deg \mathfrak {q}^\prime \geqslant v - 1\) (by the induction hypothesis) or \(\deg \mathfrak {v} \geqslant v - 1\). This last assertion is true, because by (B) of Theorem 5, we have that \(\deg \mathfrak {v} \geqslant \min \{ n -|b |\}_{b\in \mathfrak {D}(Q_l,Q^\prime )} \geqslant v - 1\). Thus, \(\deg \mathfrak {q} \geqslant v - 1\).
- \(\Psi _3\):
-
We remark first that \(\textsf{iSets}(\mathfrak {q})= \textsf{iSets}(\mathfrak {q}^\prime ) \cup \textsf{iSets}(\mathfrak {v}) \cup \textsf{iSets}(\mathfrak {t})\). If we are given \(Z\in \textsf{iSets}(\mathfrak {q})\) such that \(|Z |= v - 1\), then \(Z\in \textsf{iSets}(\mathfrak {q}^\prime )\) or \(Z\in \textsf{iSets}(\mathfrak {v})\). When \(Z\in \textsf{iSets}(\mathfrak {q}^\prime )\), we use our induction hypothesis to show that \(Z=Y \cap Y^\prime =\overline{n} - d\) for some \(Y,Y^\prime \in \textsf{iSets}(\mathfrak {s})\) and \(d\in \beta (\mathfrak {s}; n - v + 1)\) such that \(d=d^\prime \cup d^{\prime \prime }\), \(d^{\prime },d^{\prime \prime } \in \Gamma _\mathcal {A}(n, n - v)\). On the other hand, if \(Z\in \textsf{iSets}(\mathfrak {v})\), it must be true that \(\mathfrak {D}(Q_l,Q^\prime )\ne \varnothing \) (if not, then \(\deg \mathfrak {v} \geqslant n - 2\) by property (A) of Theorem 5 for \(\mathfrak {v}\) and this contradicts the size of Z). As \(v - 1 < n - 2\), we can apply part 2 of condition (B) of Theorem 5 to deduce that \(Z=\overline{n} - b\) for a unique \(b\in \mathfrak {D}(Q_l,Q^\prime )\). Because \(|Z |= v - 1\), it is true that \(|b |= n - v + 1\). Now, \(b\in \mathfrak {D}(Q_l,Q^\prime )\subseteq \beta (\mathfrak {s})\), thus there exist \(X,X^\prime \in \textsf{iSets}(\mathfrak {s})\) such that
$$\begin{aligned} |X \cap b |= 1 \text { and } |X^\prime \cap b |= 1 \end{aligned}$$(12)Combining Equation (12) with the fact that the size of b is \(n - v + 1\), we can check that \(|X |= |X^\prime |= v\) and \(\overline{n} - b = X \cap X^\prime \), that is,
$$\begin{aligned} Z=\overline{n} - b=X \cap X^\prime , \end{aligned}$$and finally, we apply \(\Lambda _2\) of the sequence \(\mathfrak {s}\) to \(X,X^\prime \) to find two unique boxes \(c,c^\prime \in \Gamma _\mathcal {A}(n,n - v)\) with \(X=\overline{n} - c \text { and } X^\prime =\overline{n} - c^\prime \), so that
$$\begin{aligned} \overline{n} - b=X \cap X^\prime = (\overline{n} - c) \cap (\overline{n} - c^\prime ) = \overline{n} - (c \cup c^\prime ), \end{aligned}$$then \(b=c \cup c^\prime \) and condition \(\Psi _3\) is satisfied by \(\mathfrak {q}\).
- \(\Psi _4\):
-
The sequence \(\mathfrak {q}\) fulfils this property because of the induction hypothesis on \(\mathfrak {q}^\prime \), condition \(\Lambda _2\) for \(\mathfrak {s}\) and (B) of Theorem 5 for \(\mathfrak {v}\).
- \(\Psi _5\):
-
Let \(l\in \{ v,\ldots ,s - 1\}\). This property is satisfied by \(\mathfrak {q}\) if \(\beta (\mathfrak {q}; n - l + 1)=\varnothing \). Suppose that \(c\in \beta (\mathfrak {q}; n - l + 1)\), there exist \(X,Y\in \textsf{iSets}(\mathfrak {q})\) such that \(|X \cap c |= |Y \cap c |= 1\). Then \(|X |= |Y |= l\), so that we use property \(\Psi _3\) (or \(\Psi _4\)) on X, Y to find two boxes \(b_X,b_Y\in \beta (\mathfrak {s}; n - l)\) such that \(X = \overline{n} - b_X \text { and } Y = \overline{n} - b_Y\). Also, \(X \cap Y = \overline{n} - c\), thus \(\overline{n} - c = X \cap Y = (\overline{n} - b_X) \cap (\overline{n} - b_Y) = \overline{n} - (b_X \cup b_Y)\). Therefore \(c = b_X \cup b_Y\) and this says that \(c\in \zeta (\beta (\mathfrak {s}; n - l))\). Condition \(\Psi _5\) is fulfilled by \(\mathfrak {q}\).
We have shown by induction that we can build the path \(\mathfrak {q}\) from the sequence \(\mathfrak {s}\), no matter how many states \(\mathfrak {s}\) has. This proves the Lemma. \(\square \)
The following corollary is a weaker version of Lemma 19, and it can be proven as a consequence of that result.
Corollary 2
Let \(n\geqslant 3\) and \(1 \leqslant s \leqslant n -2\) be fixed. Suppose that \(\mathcal {A}\) is a WOR protocol with safe-consensus objects and there exists a sequence
of connected states of round \(r\geqslant 0\) such that \(\deg \mathfrak {s} \geqslant s\) and \(\overline{n}\notin \beta (\mathfrak {s})\). Then in round \(r+1\) there exists a sequence
such that the following statements hold:
- \(\Psi _1\):
-
If \(\beta (\mathfrak {s}; n - s + 1)=\varnothing \), then \(\deg \mathfrak {q} \geqslant s\).
- \(\Psi _2\):
-
If \(\beta (\mathfrak {s}; n - s + 1)\) is not empty, then \(\deg \mathfrak {q} \geqslant s - 1\).
- \(\Psi _3\):
-
For every \(Z\in \textsf{iSets}(\mathfrak {q})\) with \(|Z |= s - 1\), there exist \(X,X^\prime \in \textsf{iSets}(\mathfrak {s})\) and a unique \(b\in \beta (\mathfrak {s}; n - s + 1)\) such that \(Z=\overline{n} - b=X \cap X^\prime \).
- \(\Psi _5\):
-
\(\beta (\mathfrak {q}; n - s + 2)\subseteq \zeta (\beta (\mathfrak {s}; n - s + 1))\).
We have gathered all the required elements to prove one of the key ingredient of the full proof of Theorem 4. Lemma 20 expresses formally the fact that if in a WOR consensus protocol, the processes cannot make enough agreements of size m (\(\nu _\mathcal {A}(n, m)\leqslant n-m\)) then they won’t be able to decrease the degree of indistinguishability of paths of connected states of reachable states in every round \(r\geqslant 1\) of the protocol.
Lemma 20
Assume that \(3 \leqslant m \leqslant n\). Suppose that \(\mathcal {A}\) is a WOR protocol with safe-consensus objects such that \(\nu _\mathcal {A}(n, m)\leqslant n-m\). If \(S^r,Q^r\) are two reachable states in \(\mathcal {A}\) for some round \(r\geqslant 0\), connected with a sequence \(\mathfrak {q} :S^r{\sim } \cdots {\sim } Q^r\) of connected states such that \(\deg \mathfrak {q} \geqslant n - m+1\). Then for all \(u\geqslant 0\), there exist successor states \(S^{r+u},Q^{r+u}\) of \(S^r\) and \(Q^r\) respectively, in round \(r+u\) of \(\mathcal {A}\), such that \(S^{r+u}\) and \(Q^{r+u}\) are connected.
Proof
Let \(\mathcal {A}\) be a protocol with the given hypothesis, set \(\mathfrak {q}_0=\mathfrak {q}\) and \(m=n - s + 1\). Because \(3\leqslant m \leqslant n\), \(s \in \{1,\ldots , n - 2 \}\). Using the sequence \(\mathfrak {q}_0\) and applying Corollary 2, we build a path \(\mathfrak {q}_1:S^{r+1}{\sim } \cdots {\sim } Q^{r+1}\), connecting the successor states \(S^{r+1},Q^{r+1}\) of \(S^r\) and \(Q^r\) respectively, such that
- \(\Psi _{1,1}\):
-
If \(\beta (\mathfrak {q}_0; n - s + 1)=\varnothing \), then \(\deg \mathfrak {q}_1 > s - 1\).
- \(\Psi _{1,2}\):
-
If \(\beta (\mathfrak {q}_0; n - s + 1)\) is not empty, then \(\deg \mathfrak {q}_1 \geqslant s - 1\).
- \(\Psi _{1,3}\):
-
For every \(Z\in \textsf{iSets}(\mathfrak {q}_1)\) with \(|Z |= s - 1\), there exist \(X,X^\prime \in \textsf{iSets}(\mathfrak {q}_0)\) and a unique \(b\in \beta (\mathfrak {q}_0; n - s + 1)\) such that \(Z=\overline{n} - b=X \cap X^\prime \).
- \(\Psi _{1,5}\):
-
\(\beta (\mathfrak {q}_1; n - s + 2)\subseteq \zeta (\beta (\mathfrak {q}_0; n - s + 1))\).
Starting from \(\mathfrak {q}_1\) and using induction together with Lemma 19, we can prove that for each \(u\in \{1,\ldots , s - 1 \}\), there exist successor states \(S^{r+u},Q^{r+u}\) of the states \(S^{r}\) and \(Q^{r}\) respectively, and a sequence
satisfying the properties:
-
\(\Psi _{u,1}\) If \(\beta (\mathfrak {q}_{u - 1}; n - s + u)=\varnothing \), then \(\deg \mathfrak {q}_u > s - u\).
-
\(\Psi _{u,2}\) If \(\beta (\mathfrak {q}_{u - 1}; n - s + u)\) is not empty, then \(\deg \mathfrak {q}_u \geqslant s - u\).
-
\(\Psi _{u,3}\) For each \(Z\in \textsf{iSets}(\mathfrak {q}_u)\) with \(|Z |= s - 1\), there exist \(X,X^\prime \in \textsf{iSets}(\mathfrak {q}_{u - 1})\) and a unique \(b\in \beta (\mathfrak {q}_{u - 1}; \) \(n - s + 1)\) such that \(Z=\overline{n} - b=X \cap X^\prime \).
-
\(\Psi _{u,4}\) For each \(Z\in \textsf{iSets}(\mathfrak {q}_u)\) with \(s - u \leqslant |Z |< s - 1\), there exist \(X,X^\prime \in \textsf{iSets}(\mathfrak {q}_{u - 1})\) and a unique \(b\in \beta (\mathfrak {q}_{u - 1};n - |Z |)\) such that \(Z=\overline{n} - b=X \cap X^\prime \) and \(b=c_{1}\cup c_{2}\), \(c_{k}\in \beta (\mathfrak {q}_{u - 1};n - |Z |- 1)\).
-
\(\Psi _{u,5}\) \(\beta (\mathfrak {q}_u; n - l + 1)\subseteq \zeta (\beta (\mathfrak {q}_{u - 1}; n - l))\) for \(s - u \leqslant l < s\).
When \(u=s - 1\), we obtain a sequence \(\mathfrak {q}_{s - 1} :S^{r+ s - 1} {\sim } \cdots {\sim } Q^{r+s - 1}\) that connects the states \(S^{r+ s - 1}\) and \(Q^{r+ s - 1}\), such that
-
\(\Psi _{s-1,1}\) If \(\beta (\mathfrak {q}_{s - 2}; n - 1)=\varnothing \), then \(\deg \mathfrak {q}_{s - 1} > 1\).
-
\(\Psi _{s-1,2}\) If \(\beta (\mathfrak {q}_{s - 2}; n - 1)\) is not empty, then \(\deg \mathfrak {q}_{s - 1} \geqslant 1\).
-
\(\Psi _{s-1,3}\) For each \(Z\in \textsf{iSets}(\mathfrak {q}_{s - 1})\) with \(|Z |= s - 1\), there exist \(X,X^\prime \in \textsf{iSets}(\mathfrak {q}_{s - 2})\) and a unique \(b\in \beta (\mathfrak {q}_{s - 2}; n - s + 1)\) such that \(Z=\overline{n} - b=X \cap X^\prime \).
-
\(\Psi _{s-1,4}\) For any \(Z\in \textsf{iSets}(\mathfrak {q}_{s - 1})\) with \(1 \leqslant |Z |< s - 1\), there exist \(X,X^\prime \in \textsf{iSets}(\mathfrak {q}_{s - 2})\) and a unique \(b\in \beta (\mathfrak {q}_{s - 2};n - |Z |)\) such that \(Z=\overline{n} - b=X \cap X^\prime \) and \(b=c_{1}\cup c_{2}\), \(c_{k}\in \beta (\mathfrak {q}_{s - 2};n - |Z |- 1)\).
-
\(\Psi _{s-1,5}\) \(\beta (\mathfrak {q}_{s - 1}; n - l + 1)\subseteq \zeta (\beta (\mathfrak {q}_{s - 2}; n - l))\) for \(1\leqslant l < s\).
Our final goal is to show that for all \(v \geqslant s - 1\), we can connect in each round \(r+v\) of \(\mathcal {A}\), successor states of \(S^r\) and \(Q^r\). We first claim that for any \(w=0,\ldots ,s - 1\) and \(z\geqslant 0\),
(this is true because \(\zeta \) preserves \(\subseteq \)) and combining this fact with the properties \(\Psi _{u,5}\) and induction, we can show that for \(1 \leqslant l < s\)
And because \(|\Gamma _\mathcal {A}(n, n - s + 1) |= \nu _\mathcal {A}(n, n - s + 1) \leqslant s - 1\) and \(m=n - s + 1\), we use Theorem 6 to check that \(\zeta ^{s - 1}(\Gamma _\mathcal {A}(n, n - s + 1))=\varnothing \), implying that
With all this data, Lemma 19 and an easy inductive argument (starting at the base case \(v=s - 1\)), we can find for all \(v\geqslant s - 1\), states \(S^{r+v},Q^{r+v}\) of round \(r+v\) of \(\mathcal {A}\), which are successor states of \(S^r\) and \(Q^r\) respectively and connected with a sequence \(\mathfrak {q}_v\) such that
- \(\Psi ^\prime _{v,1}\):
-
\(\deg \mathfrak {q}_{v} \geqslant 1\).
- \(\Psi ^\prime _{v,2}\):
-
For every \(Z\in \textsf{iSets}(\mathfrak {q}_{v})\) with \(|Z |= s - 1\), there exist \(X,X^\prime \in \textsf{iSets}(\mathfrak {q}_{v - 1})\) and a unique \(b\in \beta (\mathfrak {q}_{v - 1}; n - s + 1)\) such that \(Z=\overline{n} - b=X \cap X^\prime \).
- \(\Psi ^\prime _{v,3}\):
-
For every \(Z\in \textsf{iSets}(\mathfrak {q}_{v})\) with \(1 \leqslant |Z |< s - 1\), there exist \(X,X^\prime \in \textsf{iSets}(\mathfrak {q}_{v - 1})\) and a unique \(b\in \beta (\mathfrak {q}_{v - 1};n - |Z |)\) such that \(Z=\overline{n} - b=X \cap X^\prime \) and \(b=c_{1}\cup c_{2}\), \(c_{k}\in \beta (\mathfrak {q}_{v - 1};n - |Z |- 1)\).
- \(\Psi ^\prime _{v,4}\):
-
\(\beta (\mathfrak {q}_{v}; n - l + 1) \subseteq \zeta ^{s - l}(\Gamma _\mathcal {A}(n, n - s + 1))\) for \(1 \leqslant l < s\).
It is precisely these four properties of the path \(\mathfrak {q}_{v}\) which allow us to find the path \(\mathfrak {q}_{v+1}\), applying Lemma 19, such that \(\mathfrak {q}_{v+1}\) enjoys the same properties. Therefore, starting from round r, we can connect in all rounds of \(\mathcal {A}\), successor states of \(S^r\) and \(Q^r\). The Lemma is proven. \(\square \)
5.6 The Case \(\nu _\mathcal {A}(n,2) \leqslant n - 2\)
In Section 5.5, we proved Lemma 20, a key result to prove Theorem 4, but that lemma does not cover the case \(\nu _\mathcal {A}(n,2) \leqslant n - 2\). In this section we prove Lemma 23, which covers the case \(\nu _\mathcal {A}(n,2) \leqslant n - 2\) and it is the last ingredient that we need to prove Theorem 4. This can be done easily using Lemma 22, a structural result concerning paths of connected states and the following combinatorial result.
Lemma 21
Let \(U\subset V_{n,2}\) such that \(|U |\leqslant n - 2\). Then there exists a partition \(\overline{n}=A \cup B\) such that
The proof of Lemma 21 can be found in Section A.3 of the Appendix. Lemma 21 describes the combinatorics of Lemma 23 for the case \(m=2\), just in the same way Theorem 6 does the same thing for Lemma 20. Intuitively, when \(|U |\leqslant n - 2\), there are not enough agreements between pairs of processes and this allow us to partition the set of processes \(\Pi \) into two sets
and this partition can be used to build sequences of connected states in every round of an executing WOR protocol (Lemmas 22 and 23). We now proceed to prove the required results.
Lemma 22
Let \(\mathcal {A}\) be a WOR protocol with safe-consensus objects. Suppose there exists a partition \(\overline{n}=A \cup B\) and a sequence
of connected states in round \(r\geqslant 0\) of \(\mathcal {A}\), with the following properties
-
I)
\(\textsf{iSets}(\mathfrak {p})=\{ A,B \}\);
-
II)
\((\forall b\in \Gamma _\mathcal {A}(n, 2)) (b\subseteq A \text { or } b \subseteq B)\).
Then in round \(r+1\) of \(\mathcal {A}\) there exists a path
of connected states and the following properties hold:
-
a)
Each state \(Q_k\) is of the form \(Q_k=S_j \cdot \xi (X)\), where \(X=A \text { or } X=B\);
-
b)
\(\textsf{iSets}(\mathfrak {q})=\{ A,B \}\).
Proof
The techniques needed to prove this result are similar to those used in the proof of Lemma 19. We first define the safe-consensus value of every box \(b\in \Gamma _\mathcal {A}(n, 2)\), using property II) and the safe-Validity property of safe-consensus. After doing that, we apply induction on l to build the path \(\mathfrak {q}\) (of succesor states of elements from \(\textsf{iSets}(\mathfrak {p})\)) satisfying a)-b). We omit the details. \(\square \)
Lemma 23
Let \(n\geqslant 2\). If \(\mathcal {A}\) is a WOR protocol for n processes using safe-consensus objects with \(\nu _\mathcal {A}(n,2)\) \(\leqslant n - 2\) and S is a reachable state in \(\mathcal {A}\) for some round \(r\geqslant 0\), then there exists a partition of the set \(\overline{n}=A\cup B\) such that for all \(u\geqslant 0\), the states \(S \cdot \xi ^{u}(A)\) and \(S\cdot \xi ^{u}(B)\) are connected.
Proof
This proof is analogous to the proof of Lemma 20. We use Lemma 21 to find the partition of \(\overline{n}\) and then we apply inductively Lemma 22. We omit the details. \(\square \)
5.7 The Proof of Theorem 4
Here we give the proof of Theorem 4 for any \(n \geqslant 2\), thus completing all the necessary proofs of the paper.
Proof of Theorem 4 Assume that there exists a protocol \(\mathcal {A}\) for consensus such that there is some m with \(2\leqslant m \leqslant n\) with \(\nu _\mathcal {A}(n,m) \leqslant n - m\). Let O, U be the initial states in which all processes have as input values 0s and 1s respectively. We now find successor states of O and U in each round \(r\geqslant 0\), which are connected. There are two cases:
-
Case \(m=2\). By Lemma 23, there exists a partition of \(\overline{n}=A\cup B\) such that for any state S and any \(r\geqslant 0\), \(S \cdot \xi ^{r}(A)\) and \(S\cdot \xi ^{r}(B)\) are connected. Let OU be the initial state in which all processes with ids in A have as input value 0s and all processes with ids in B have as input values 1s. Then for all \(r\geqslant 0\) we have that
$$\begin{aligned} O\cdot \xi ^{r}(A)\overset{A}{\sim }\ OU\cdot \xi ^{r}(A)\quad \text {and} \quad OU\cdot \xi ^{r}(B)\overset{B}{\sim }\ U\cdot \xi ^{r}(B) \end{aligned}$$and by Lemma 23, the states \(OU\cdot \xi ^{r}(A)\) and \(OU\cdot \xi ^{r}(B)\) are connected. Thus, for any r-round partial execution of \(\mathcal {A}\), we can connect the states \(O^r=O \cdot \xi ^{r}(A)\) and \(U^r=U\cdot \xi ^{r}(B)\).
-
Case \(3\leqslant m \leqslant n\). By Lemma 2, we know that any two initial states for consensus are connected, so that we can connect O and U with a sequence \(\mathfrak {q}\) of initial states of \(\mathcal {A}\) and it is not hard to check that \(\deg \mathfrak {q} \geqslant n - 1 \geqslant n - m + 1\). By Lemma 20, for each round \(r\geqslant 0\) of \(\mathcal {A}\), there exist successor states \(O^r,U^r\) of O and U respectively, such that \(O^r\) and \(U^r\) are connected.
In this way, we have connected successor states of O and U in each round of the protocol \(\mathcal {A}\). Now, O is a 0-valent, initial state, which is connected to the initial state U, so that we can apply Lemma 3 to conclude that U is 0-valent. But this contradicts the fact that U is a 1-valent state, so we have reached a contradiction. Therefore \(\nu _\mathcal {A}(n,m) > n - m\). \(\square \)
6 Conclusion
In this paper, we have introduced three extensions to the basic iterated model of distributed computing [16], using the safe-consensus task proposed by Yehuda, Gafni and Lieber in [4] and studied some of their properties and the solvability of the consensus task in each model. These extensions are very natural, in the sense that, for the set of new shared objects used by the processes (besides the snapshot objects), the protocols follow the conventions of the standard iterated model for the snapshot objects and the new shared objects: Each set of objects is arranged as an array and each object is used only once by each processes and each process can access at most one shared object. This gives the protocols of the extended models a well behaved structure and allows for an easier analysis of their executions, because of their inductive nature, even with the use of the new shared objects. We believe that iterated models extended with shared objects will play an important role in the development of the theory of models of distributed computing systems with shared objects, just in the same way the basic iterated model has played a fundamental role in the development of the theory of standard shared memory systems.
In the first iterated model that we investigated, the WRO iterated model, the processes first write to memory, then they snapshot it and after that, they invoke safe-consensus objects. We proved that in this model, the consensus task cannot be implemented. The impossibility proof uses simpler connectivity arguments that those used in the lower bound proof of the WOR iterated model. For the second iterated model, the OWR iterated model, processes first invoke safe-consensus objects, then they write to memory and then they snapshot the contents of the shared memory. We proved that this model is equivalent to the WRO iterated model for task solvability using simulations, thus we obtained as a corollary that consensus cannot be implemented in the OWR iterated model.
Finally, in the third model, the WOR iterated model, processes write to memory, invoke safe-consensus objects and they snapshot the shared memory. We first constructed a WOR protocol which can solve n-consensus with \({n \atopwithdelims ()2}\) safe-consensus objects. To make this protocol more readable and simplify its analysis, we introduced a new group consensus task: The g-2coalitions-consensus task, which captures the difficulties of solving g processes consensus, even when almost all the processes know the proposed input values, except for two processes that only know one input value. This new task may be of independent interest in future research. We also proved that our WOR consensus protocol is sharp, by giving a \({n \atopwithdelims ()2}\) lower bound on the number of safe-consensus objects necessary to implement n-consensus in the WOR iterated model with safe-consensus. This lower bound is the main result of this paper. To obtain this lower bound, we combined structural results about WOR protocols and combinatorial results applied to all the different subsets of processes that can invoke safe-consensus objects. At the very end, it is bivalency [2], but in order to be able to use bivalency, an intricate connectivity argument must be developed, in which we relate the way that the processes use the safe-consensus shared objects to solve consensus with subgraphs of the Johnson graphs. More specifically, our results suggest that for a given WOR protocol which solves n-consensus, the ability of the processes to make incremental partial agreements using safe-consensus objects to reach consensus, is encoded in the number of vertices and the connectivity of specific subgraphs of \(J_{n,m}\) for \(2\leqslant m \leqslant n\). It is somehow surprising that Johnson graphs played such an important role in the proof of Theorem 4, these graphs and their properties are known to have applications in coding theory, specifically, Johnson graphs are closely related to Johnson schemes [37]. It is the first time that they appear in the scene of distributed systems. Our results might suggest some kind of connection between distributed systems and coding theory.
Also, in all our structural results of iterated protocols with safe-consensus, we see that connectivity of graphs appear again in the scene for the consensus task, this suggests that topology will play an important role to understand better the behaviour of protocols that use shared objects more powerful that read/write shared memory registers. The proofs developed to obtain the lower bound say that the connectivity of the topological structures given by the shared objects used by the processes, can affect the connectivity of the topology of the protocol complex [24].
With respect to the relationship between the iterated models introduced in this paper and the standard model of distributed computing [1, 38] extended with safe-consensus objects used in [4] to implement consensus using safe-consensus objects, we can conclude the following. Our results for the WRO and the OWR iterated models say that these two models are not equivalent to the standard model with safe-consensus (for task solvability), as consensus can be implement in the latter model [4], but consensus cannot be implemented in the WRO and OWR iterated models. Still, an open problem related to these two iterated models remains unsolved: The characterization of their exact computational power. Another closely related problem is: Are these two models more powerful than the standard shared memory model of distributed computing?
On the other hand, the relationship between the standard model extended with safe-consensus and the WOR iterated model remains unknown. Are these two models equivalent? We conjecture that the answer is yes.
Notes
These results appeared for the first time in the Proceedings of the 21st International Colloquium on Structural Information and Communication Complexity [5].
In a tight group renaming task with group size g, n processes with ids from a large domain \(\{ 1, 2,\ldots ,N \}\) are partitioned into m groups with ids from a large domain \(\{1, 2,\ldots , M \}\), with at most g processes per group. A tight group renaming task renames groups from the domain \(1\ldots M\) to \(1\ldots l\) for \(l \ll M\) , where all processors with the same initial group ID are renamed to the same new group ID, and no two different initial group ids are renamed to the same new group ID.
This definition of valency is based on [2].
In the proof of Lemma 18, \(\mathfrak {p}_1\) is build using three subpaths \(\mathfrak {q}_1,\mathfrak {q}_2\) y \(\mathfrak {q}_3\). The paths \(\mathfrak {q}_1\) and \(\mathfrak {q}_3\) have indistinguishability degree at least \(n - 2\) (Lemma 16). The path \(\mathfrak {q}_2\) is build using Lemma 17 and we can check that every set \(X \in \textsf{States}(\mathfrak {q}_2)\) satisfies \(| X| \geqslant n - 2\), except at most, the set \(\overline{n} - U\) in Equation (9), since U satisfies Equation (10).
Remember that \(Y_{(1)} - X_{(2)}=(Y \cap b_1) - (X \cap b_2)= Y \cap b_1= Y_{(1)}\), since \(b_1 \cap b_2 = \varnothing \).
Notice that the order given to \(\Phi (\mathfrak {s})\) in equation 11 is the precise order in which the states of this set will appear in the path \(\mathfrak {q}\).
References
Herlihy, M.: Wait-free synchronization. ACM Trans. Program. Lang. Syst. 13(1), 124–149 (1991)
Fischer, M.J., Lynch, N.A., Paterson, M.S.: Impossibility of distributed consensus with one faulty process. J. ACM. 32(2), 374–382 (1985)
Loui, M.C., Abu-Amara, H.H.: Memory requirements for agreement among unreliable asynchronous processes. Parallel Distrib. Comput. Adv. Comput. Res. F. P. Preparata ed. JAI Press Greenwich CT. 4, 163–183 (1987)
Afek, Y., Gafni, E., Lieber, O.: Tight group renaming on groups of size g is equivalent to g-consensus. In: Proceedings of the 23rd international conference on Distributed computing (DISC’09), vol. 5805 of LNCS, pp. 111–126. Springer-Verlag, Berlin, Heidelberg (2009)
Conde, R., Rajsbaum, S.: The complexity gap between consensus and safe-consensus. In: Halldórsson, M.M. (ed.) Structural Information and Communication Complexity, vol. 8576 of Lecture Notes in Computer Science, pp. 68–82. Springer International Publishing (2014)
Rajsbaum, S.: Iterated shared memory models. In: López-Ortiz, A. (ed.) LATIN 2010: Theoretical Informatics, vol. 6034 of Lecture Notes in Computer Science, pp. 407–416. Springer, Berlin, Heidelberg (2010)
Borowsky, E., Gafni, E., Lynch, N., Rajsbaum, S.: The BG distributed simulation algorithm. Distrib. Comput. 14(3), 127–146 (2001)
Herlihy, M., Shavit, N.: The topological structure of asynchronous computability. J. ACM. 46(6), 858–923 (1999)
Borowsky, E., Gafni, E.: Generalized FLP impossibility result for t-resilient asynchronous computations. In: STOC ’93: Proceedings of the twenty-fifth annual ACM symposium on Theory of computing, pp. 91–100. ACM, New York (1993)
Saks, M., Zaharoglou, F.: Wait-free k-set agreement is impossible: The topology of public knowledge. SIAM J. Comput. 29(5), 1449–1483 (2000)
Attiya, H., Bar-Noy, A., Dolev, D., Peleg, D., Reischuk, R.: Renaming in an Asynchronous Environment. J. ACM. (1990)
Castañeda, A., Herlihy, M., Rajsbaum, S.: An equivariance theorem with applications to renaming. In: Proceedings of the 10th Latin American International Conference on Theoretical Informatics, LATIN’12, pp. 133–144. Springer-Verlag, Berlin, Heidelberg (2012)
Castañeda, A., Rajsbaum, S.: New combinatorial topology upper and lower bounds for renaming. In: Proceedings of the Twenty-seventh ACM Symposium on Principles of Distributed Computing, PODC ’08, pp. 295–304. ACM, New York (2008)
Castañeda, A., Rajsbaum, S.: New combinatorial topology bounds for renaming: The upper bound. J. ACM. 59(1), 3:1–3:49 (2012)
Castañeda, A., Rajsbaum, S., Raynal, M.: The renaming problem in shared memory systems: An introduction. Comput. Sci. Rev. 5(3), 229–251 (2011)
Borowsky, E., Gafni, E.: A simple algorithmically reasoned characterization of wait-free computation (extended abstract). In: PODC ’97: Proceedings of the sixteenth annual ACM symposium on Principles of distributed computing, pp. 189–198. ACM, New York (1997)
Herlihy, M., Rajsbaum, S.: The topology of shared-memory adversaries. In: PODC ’10: Proceeding of the 29th ACM symposium on Principles of distributed computing, pp. 105–113. ACM, New York (2010)
Herlihy, M., Rajsbaum, S.: The topology of distributed adversaries. Distrib. Comput. 26(3), 173–192 (2013)
Rajsbaum, S., Raynal, M., Travers, C.: An impossibility about failure detectors in the iterated immediate snapshot model. Inf. Process. Lett. 108(3), 160–164 (2008)
Rajsbaum, S., Raynal, M., Travers, C.: The iterated restricted immediate snapshot model. In: COCOON ’08: Proceedings of the 14th annual international conference on Computing and Combinatorics, pp. 487–497. Springer-Verlag, Berlin, Heidelberg (2008)
Gafni, E., Rajsbaum, S.: Recursion in distributed computing. In: Dolev, S., Cobb, J., Fischer, M., Yung, M. (eds.) Stabilization, Safety, and Security of Distributed Systems. Lecture Notes in Computer Science, vol. 6366, pp. 362–376. Springer, Berlin, Heidelberg (2010)
Gafni, E., Rajsbaum, S., Herlihy, M.: Subconsensus tasks: Renaming is weaker than set agreement. In: Proceedings of the 20th international conference on Distributed computing (DISC’06), vol. 4167 of LNCS, pp. 329–338. Springer-Verlag, Berlin, Heidelberg (2006)
Gafni, E., Rajsbaum, S.: Distributed programming with tasks. In: Lu, C., Masuzawa, T., Mosbah, M. (eds) Principles of Distributed Systems, vol. 6490 of Lecture Notes in Computer Science, pp. 205–218. Springer, Berlin, Heidelberg (2010)
Herlihy, M., Kozlov, D., Rajsbaum, S.: Distributed Computing Through Combinatorial Topology. Morgan Kaufmann (2013)
Afek, Y., Gamzu, I., Levy, I., Merritt, M., Taubenfeld, G.: Group renaming. In: OPODIS ’08: Proceedings of the 12th International Conference on Principles of Distributed Systems, vol. 5401 of LNCS, pp. 58–72. Springer-Verlag, Berlin, Heidelberg (2008)
Moses, Y., Rajsbaum, S.: A layered analysis of consensus. SIAM J. Comput. 31(4), 989–1021 (2002)
Attiya, H., Dwork, C., Lynch, N., Stockmeyer, L.: Bounds on the time to reach agreement in the presence of timing uncertainty. J. ACM. 41, 122–152 (1994)
Dwork, C., Moses, Y.: Knowledge and common knowledge in a byzantine environment: Crash failures. Inf. Comput. 88(2), 156–186 (1990)
Conde, R., Rajsbaum, S.: An introduction to the topological theory of distributed computing with safe-consensus. Electron. Notes Theor. Comput. Sci. 283(0), 29–51 (2012). Proceedings of the workshop on Geometric and Topological Methods in Computer Science (GETCO)
Attiya, H., Rajsbaum, S.: The combinatorial structure of wait-free solvable tasks. SIAM J. Comput. 31(4), 1286–1313 (2002)
Attiya, H., Welch, J.: Distributed Computing: Fundamentals, Simulations and Advanced Topics. Wiley, (2004)
Afek, Y., Attiya, H., Dolev, D., Gafni, E., Merritt, M., Shavit, N.: Atomic snapshots of shared memory. J. ACM. 40(4), 873–890 (1993)
Borowsky, E., Gafni, E.: Immediate atomic snapshots and fast renaming. In: PODC ’93: Proceedings of the twelfth annual ACM symposium on Principles of distributed computing, pp. 41–51. ACM, New York (1993)
Chaudhuri, S.: More choices allow more faults: set consensus problems in totally asynchronous systems. Inf. Comput. 105, 132–158 (1993)
Gafni, E.: The extended BG-simulation and the characterization of t-resiliency. In: STOC ’09: Proceedings of the 41st annual ACM symposium on Theory of computing, pp. 85–92. ACM, New York (ACM)
Castañeda, A., Imbs, D., Rajsbaum, S., Raynal, M.: Renaming is weaker than set agreement but for perfect renaming: A map of sub-consensus tasks. In: Proceedings of the 10th Latin American International Conference on Theoretical Informatics, LATIN’12, pp. 145–156. Springer-Verlag, Berlin, Heidelberg (2012)
Delsarte, P., Levenshtein, V.I.: Association schemes and coding theory. IEEE Trans. Inf. Theory. 44(6), 2477–2504 (1998)
Herlihy, M.P., Wing, J.M.: Linearizability: a correctness condition for concurrent objects. ACM Trans. Program. Lang. Syst. 12(3), 463–492 (1990)
Bollobás, B.: Modern Graph Theory: Béla Bollobás. Graduate Texts in Mathematics Series. Springer (1998)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A Preliminary version of these results appeared in SIROCCO 2014.
Appendix: Results on subgraphs of Johnson graphs
Appendix: Results on subgraphs of Johnson graphs
In this appendix, we prove Theorem 6 and Lemma 21, two results about subgraphs of Johnson graphs used to build the full proof of Theorem 4. The main result here is Theorem 6, which provides a new and interesting connection between Johnson graphs and iterated consensus protocols. We will be using some combinatorial facts of graph theory and finite sets.
1.1 Subgraphs of Johnson Graphs
Our graph terminology is standard, see for example [39], all the graphs that we use are simple graphs. For any set A and \(E\subseteq 2^{A}\), we denote the union of all the elements of every set in E as \(\bigcup E\). For \(1\leqslant m \leqslant n\), the Johnson graph \(J_{n,m}\) has as vertex set all subsets of \(\overline{n}\) of cardinality m, two vertices \(b_1,b_2\) are adjacent if and only if \(|b_1 \cap b_2 |= m - 1\). Let \(V_{n,m}=V(J_{n,m})\) and \(U\subseteq V_{n,m}\), define the set \(\zeta (U)\) as
Notice that each \(f\in \zeta (U)\) has size \(m+1\) because, if \(f= c\cup d\) for \(c,d \in U\), then \(|c |= |d |= m\) and it is known that \(|c \cap d |= m - 1 \Leftrightarrow |c \cup d |= m + 1\). Thus \(\zeta (U)\subseteq V_{n,m+1}\). For any \(v=0,\ldots ,n-m\), the iterated \(\zeta \)-operator \(\zeta ^v\) is given by
As \(U\subseteq V_{n,m}\), we can check that \(\zeta ^v(U)\subseteq V_{n,m+v}\). A simple, but useful property of the \(\zeta \)-operator is that
1.2 Preliminaries
We are ready to prove all the combinatorial results that we need.
Lemma 24
Let \(U \subseteq V_{n,m}\) and \(G=G\left[ U \right] \). The following properties are satisfied.
-
(i)
If G is connected, then \(\bigl | \bigcup U \bigr | \leqslant m - 1 + |U |\).
-
(ii)
If \(U_1,\ldots ,U_r\) are connected components of G, then \(\zeta (\bigcup _{i=1}^r U_i)=\bigcup _{i=1}^r \zeta (U_i)\).
Proof
(i) can be proven easily using induction on \(|U |\) and (ii) is an easy consequence of the definitions, thus we omit the proof. \(\square \)
Lemma 25
Let \(U\subseteq V_{n,m}\) with \(|U |\leqslant n - m\). If \(G\left[ U\right] \) is connected then \(\bigcup U \ne \overline{n}\).
Proof
Suppose that with the given hypothesis \(\bigcup U = \overline{n}\). As \(G\left[ U \right] \) is connected, we can use part (i) of Lemma 24 to obtain the inequality \(n\leqslant m + |U |-1\). But this implies that \(|U |\geqslant n - m + 1\) and this is a contradiction. Therefore \(\bigcup U \ne \overline{n}\). \(\square \)
Lemma 26
Let \(U\subset V_{n,m}\) with \(|U |> 1\) and \(G=G\left[ U \right] \) a connected subgraph of \(J_{n,m}\). Then the graph \(G^\prime =G\left[ \zeta (U) \right] \) is connected and \(\bigcup \zeta (U) = \bigcup U\).
Proof
We show that \(G^\prime \) is connected. If G contains only two vertices, then \(G^\prime \) contains only one vertex and the result is immediate. So assume that \(|U |> 2\) and take \(b,c\in \zeta (U)\). We need to show that there is a path from b to c. We know that \(b=b_1 \cup b_2\) and \(c=c_1 \cup c_2\) with \(b_i,c_i\in U\) for \(i=1,2\). As G is connected, there is a path
and we use it to build the following path in \(G^\prime \),
thus b and c are connected in \(G^\prime \), so that it is a connected graph.
Now we prove that \(\bigcup \zeta (U) = \bigcup U\). By Equation (16), \(\bigcup \zeta (U) \subseteq \bigcup U\), so it only remains to prove the other inclusion. Let \(x\in \bigcup U\), there is a vertex \(b\in U\) such that \(x\in b\) and as \(|U |> 1\) and G is connected, there exists another vertex \(c\in U\) such that b and c are adjacent in G. Then \(b\cup c\in \zeta (U)\), thus
gather that, \(\bigcup U \subseteq \bigcup \zeta (U)\) and the equality holds. This concludes the proof. \(\square \)
Lemma 27
Let \(U\subseteq V_{n,m}\), \(G=G\left[ U \right] , G^\prime =G\left[ \zeta (U) \right] \) and \(\mathcal {U}\) be the set of connected components of the graph G. Then the following conditions hold:
-
1.
For any connected component V of \(G^\prime \), there exists a set \(\mathcal {O}\subseteq \mathcal {U}\) such that \(V=\zeta (\bigcup \mathcal {O})=\bigcup _{Z\in \mathcal {O}} \zeta (Z)\).
-
2.
If \(V,V^\prime \) are two different connected components of \(G^\prime \) and \(\mathcal {O},\mathcal {O}^\prime \subseteq \mathcal {U}\) are the sets which fulfil property 1 for V and \(V^\prime \) respectively, then \(\mathcal {O} \cap \mathcal {O}^\prime = \varnothing \).
Proof
Part 2 is clearly true, so we only need to prove part 1. Define the graph \(\mathcal {H}=(V(\mathcal {H}), E(\mathcal {H}))\) as follows:
-
\(V(\mathcal {H})=\mathcal {U}\);
-
Two vertices \(Z, Z^\prime \) form an edge in \(E(\mathcal {H})\) if and only if there exist \(b,c\in Z\) and \(d,e \in Z^\prime \) such that
-
\(|b \cap c |= m - 1 \text { and } |d \cap e |= m - 1\)
-
\(\bigl | (b \cup c) \cap (d \cup e) \bigr | \geqslant m\).
-
Roughly speaking, \(\mathcal {H}\) describes for two connected components \(Z,Z^\prime \) of G, whether \(\zeta (Z),\zeta (Z^\prime )\) lie in the same connected component of \(G^\prime \) or not. Let V be a connected component of \(G^\prime \), if \(b \in V\), then \(b=b_1 \cup b_2\), where \(b_1,b_2\) are in some connected component \(Z_b\subseteq U\) of G. In \(\mathcal {H}\), there exists a component \(\mathcal {O}\) such that \(Z_b\in \mathcal {O}\). By Lemma 26, \(G\left[ \zeta (Z_b) \right] \) is connected and \(b\in \zeta (Z_b) \cap V\), so it is clear that \(\zeta (Z_b) \subseteq V\). Suppose that \(Z^\prime \in \mathcal {O}\) with \(Z^\prime \ne Z_b\) and these components form an edge in \(\mathcal {H}\). This means that \(G\left[ \zeta (Z_b) \right] \) and \(G\left[ \zeta (Z^\prime ) \right] \) are joined by at least one edge in \(G^\prime \), thus every vertex of \(\zeta (Z^\prime )\) is connected with every vertex of \(\zeta (Z_b)\), and as \(\zeta (Z_b)\subseteq V\), \(\zeta (Z_b) \cup \zeta (Z^\prime )\subseteq V\). We can continue this process with every element of the set \(\mathcal {O} - \{ Z_b, Z^\prime \}\) to show that
(The first equality comes from part (ii) of Lemma 24). We prove the other inclusion, if \(V = \{ b \}\), we are done. Otherwise, let \(c\in V - \{ b \}\), if \(c\in \zeta (Z_b)\), then \(c\in \zeta \bigl ( \bigcup \mathcal {O}\bigr )\). In case that \(c\notin \zeta (Z_b)\), there must exists some connected component \(Z_c\) of G such that \(c\in \zeta (Z_c)\) and \(Z_c\ne Z_b\). In \(G^\prime \), we can find a path \(b=v_1,\ldots ,v_q=c\) where \(v_i\in V\) for \(i=1,\ldots ,q\). The set \(\mathcal {Q} \subset \mathcal {U}\) defined as
can be seen to have the property that every pair of vertices \(X,X^\prime \in \mathcal {Q}\) are connected by a path in \(\mathcal {H}\). Since \(Z_b,Z_c\in \mathcal {Q}\), they are connected in \(\mathcal {H}\) and as \(Z_b \in \mathcal {O}\), then \(Z_c\in \mathcal {O}\), gather that, \(c\in \zeta (\bigcup \mathcal {O})\). Therefore \(V\subseteq \zeta (\bigcup \mathcal {O})\) and the equality \(V=\bigcup _{Z\in \mathcal {O}} \zeta (Z)\) holds. This proves part 1 and finishes the proof. \(\square \)
Lemma 28
Let \(U\subseteq V_{n,m}\) and \(\mathcal {U}\) be the set of connected components of \(G\left[ U \right] \). Then for all \(s\in \{ 0,\ldots , n - m \}\) and \(G^s=G\left[ \zeta ^s(U) \right] \), the following conditions are satisfied.
-
H1 For every connected component V of the graph \(G^s\), there exists a set \(\mathcal {O} \subseteq \mathcal {U}\) such that
$$\begin{aligned} \bigl | \bigcup V \bigr | \leqslant m - 1 + \sum _{Z\in \mathcal {O}} \bigl | Z \bigr |. \end{aligned}$$(17) -
H2 If \(V,V^\prime \) are two different connected components of \(G^s\) and \(\mathcal {O},\mathcal {O}^\prime \subseteq \mathcal {U}\) are the sets which make true the inequality given in (17) for V and \(V^\prime \) respectively, then \(\mathcal {O} \cap \mathcal {O}^\prime = \varnothing \).
Proof
We prove the lemma by using induction on s. For the base case \(s=0\), \(G^0=G\left[ U \right] \), we use Lemma 24 and we are done. Suppose that for \(0 \leqslant s < n - m\), H1 and H2 are true. We prove the case \(s+1\), let W be a connected component of the graph \(G^{s+1}\). By part 1 of Lemma 27, we know that there is a unique set \(\mathcal {Q}\) of connected components of \(G^{s}\) such that
and because \(\zeta (Q) \ne \varnothing \), \(|Q |> 1\), so that by Lemma 26, \(\bigcup \zeta (Q) = \bigcup Q\) for all \(Q\in \mathcal {Q}\), thus it is true that
By the induction hypothesis, \(|\bigcup Q |\leqslant m - 1 + \sum _{Z\in \mathcal {O}_Q} |Z |\), where \(\mathcal {O}_Q\subseteq \mathcal {U}\) for all \(Q\in \mathcal {Q}\) and when \(Q \ne R\), \(\mathcal {O}_Q \cap \mathcal {O}_R=\varnothing \). With a simple induction on \(|\mathcal {Q} |\), it is rather forward to show that
where \(\mathcal {O}=\bigcup _{Q\in \mathcal {Q}} \mathcal {O}_Q\), gather that, property H1 is fulfilled. We now show that condition H2 holds. If \(W^\prime \) is another connected component of \(G^{s+1}\), then applying the above procedure to \(W^\prime \) yields \(W^\prime =\bigcup _{S \in \mathcal {S}} \zeta (S)\), \(\bigcup W^\prime = \bigcup _{S\in \mathcal {S}} \bigl (\bigcup S \bigr )\) and \(\bigl | \bigcup W^\prime \bigr | \leqslant m - 1 + \sum _{X \in \mathcal {O}^\prime } \bigl | X \bigr |\), with \(\mathcal {O}^\prime =\bigcup _{S\in \mathcal {S}} \mathcal {O}_S\). By 2 of Lemma 27, \(\mathcal {Q} \cap \mathcal {S} = \varnothing \), so that if \(Q\in \mathcal {Q}\) and \(S\in \mathcal {S}\), then \(Q\ne S\) and the induction hypothesis tells us that \(\mathcal {O}_Q \cap \mathcal {O}_S=\varnothing \), thus
and property H2 is satisfied, so that by induction we obtain the result. \(\square \)
1.3 Proofs of Theorem 6 and Lemma 21
Using all the results that we have developed in this appendix, we can now prove Theorem 6, (the main result of the combinatorial part of the proof of Theorem 4) and Lemma 21, which is used to prove Lemma 23.
Proof of Theorem 6. For a contradiction, suppose that \(\zeta ^{n - m}(U) \ne \varnothing \), then \(G\left[ \zeta ^{n - m}(U) \right] \) is the graph \(J_{n,n}\) and contains the unique connected component \(C=\{ \overline{n} \}\), thus by Lemma 28, for some set \(\mathcal {O}\) of connected components of \(G\left[ U \right] \),
and we conclude that \(|U |\geqslant n - m + 1\), a contradiction. So that \(\zeta ^{n - m}(U) \ne \varnothing \) is impossible. Therefore \(\zeta ^{n - m}(U)\) has no elements.
The proof of Lemma 21 uses properties of subgraphs of \(J_{n,2}\) and it is far easier to obain than the proof of Theorem 6.
Proof of Lemma 21. If \(\bigcup U \ne \overline{n}\), then setting \(A=\overline{n} - \{ i \}\) and \(B=\{ i \}\) where \(i\notin \bigcup U\) we are done. Otherwise, by Lemma 25, the induced subgraph \(G=G\left[ U \right] \) of \(J_{n,2}\) is disconnected. There exists a partition \(V_1,V_2\) of \(V(G)=U\) with the property that there is no edge of G from any vertex of \(V_1\) to any vertex of \(V_2\). Let
It is easy to show that \(\overline{n}=A\cup B\) is the partition of \(\overline{n}\) that we need.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Conde, R., Rajsbaum, S. The Solvability of Consensus in Iterated Models Extended with Safe-Consensus. Theory Comput Syst 67, 901–955 (2023). https://doi.org/10.1007/s00224-023-10125-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00224-023-10125-z