Deep extreme learning machine with knowledge augmentation for EEG seizure signal recognition
 Xiongtao Zhang
Xiongtao Zhang Shuai Dong1,2
Shuai Dong1,2  Qing Shen
Qing Shen Jie Zhou
Jie Zhou Jingjing Min
Jingjing Min- 1School of Information Engineering, Huzhou University, Huzhou, China
- 2Zhejiang Province Key Laboratory of Smart Management and Application of Modern Agricultural Resources, Huzhou University, Huzhou, China
- 3Department of Computer Science and Engineering, Shaoxing University, Shaoxing, China
- 4Department of Neurology, The First People's Hospital of Huzhou, First Affiliated Hospital of Huzhou University, Huzhou, China
Introduction: Intelligent recognition of electroencephalogram (EEG) signals can remarkably improve the accuracy of epileptic seizure prediction, which is essential for epileptic diagnosis. Extreme learning machine (ELM) has been applied to EEG signals recognition, however, the artifacts and noises in EEG signals have a serious effect on recognition efficiency. Deep learning is capable of noise resistance, contributing to removing the noise in raw EEG signals. But traditional deep networks suffer from time-consuming training and slow convergence.
Methods: Therefore, a novel deep learning based ELM (denoted as DELM) motivated by stacking generalization principle is proposed in this paper. Deep extreme learning machine (DELM) is a hierarchical network composed of several independent ELM modules. Augmented EEG knowledge is taken as complementary component, which will then be mapped into next module. This learning process is so simple and fast, meanwhile, it can excavate the implicit knowledge in raw data to a greater extent. Additionally, the proposed method is operated in a single-direction manner, so there is no need to perform parameters fine-tuning, which saves the expense of time.
Results: Extensive experiments are conducted on the public Bonn EEG dataset. The experimental results demonstrate that compared with the commonly-used seizure prediction methods, the proposed DELM wins the best average accuracies in 13 out of the 22 data and the best average F-measure scores in 10 out of the 22 data. And the running time of DELM is more than two times quickly than deep learning methods.
Discussion: Therefore, DELM is superior to traditional and some state-of-the-art machine learning methods. The proposed architecture demonstrates its feasibility and superiority in epileptic EEG signal recognition. The proposed less computationally intensive deep classifier enables faster seizure onset detection, which is showing great potential on the application of real-time EEG signal classification.
1. Introduction
Epilepsy is a common chronic neurological disease caused by sudden abnormal discharge of neurons in human brain (Sanei and Chambers, 2013). Most epileptic patients have no difference from common people when epileptic seizure does not appear, but epilepsy has a serious effect on quality of human life, or even causes fatal harm (Iasemidis et al., 2003). Rapid and accurate diagnosis of epilepsy is essential for the treatment of patients and the risk reduction of potential seizures, and its relevant technique is urgently expected in current society. Electroencephalogram (EEG) shows the electrical activity of human brain recorded by amplifying voltage differences between electrodes placed on the scalp or cerebral cortex. In traditional epilepsy detection by doctors, visual marking of long EEG recordings is a tedious and high-cost task with high misjudgment rate, especially taking into account the subjectiveness of experts (Wang et al., 2018).
EEG signal recognition plays an important role in the assessment and auxiliary diagnosis of epilepsy (Ghosh-Dastidar et al., 2007; Ahmadlou and Adeli, 2011; Ayman et al., 2023). Careful analysis of the electroencephalograph records can provide valuable insight and improved understanding of the mechanisms causing epileptic disorders. Machine learning methods, such as neural network (Subasi and Ercelebi, 2005; Kumar et al., 2010), fuzzy system (Güler and Übeyli, 2005), support vector machine (Panda et al., 2010; Nicolaou and Georgiou, 2012; Kumar et al., 2014), and extreme learning machine (Liang et al., 2006b; Yuan et al., 2011; Song and Zhang, 2013), have been extensively used in EEG signal recognition. But some of the existing intelligent methods perform poor in terms of classification accuracy, real-time prediction and so on. As a novel paradigm of learning method, ELM can not only learn rapidly with good generalization performance, but also effectively overcome the inherent drawbacks of some intelligent technologies. In recent years, ELM and its variants (Huang et al., 2004, 2006, 2011a,b; Liang et al., 2006a; Betthauser et al., 2017) have received increasing attention. However, its shallow structure is deficient in extracting the significant implicit information from the original data, which becomes the main bottleneck restricting its development. As a popular trend in machine learning, deep learning has confirmed that pattern recognition can remarkably benefit from the knowledge learned via hierarchical feature representation. Typical deep networks include deep belief network (Hinton and Salakhutdinov, 2006; Hinton et al., 2006; Plis et al., 2014), convolutional neural network (Khan et al., 2017; Acharya et al., 2018; Choi et al., 2019), stack autoencoder (Bengio et al., 2007; Vincent et al., 2010; Xu et al., 2015), etc. There are many artifacts and noises in EEG signals, which can seriously decrease recognition efficiency (Bengio, 2009; Zhou and Chan, 2016; Bhattacharyya and Pachori, 2017). Deep learning is exactly able to resist noise in recognition process and can remove noise from EEG data (Huang et al., 2013; Deng et al., 2016). However, conventional deep learning algorithm is time-consuming with complicated structure and can easily lead to overfitting in presence of limited available samples. In order to tackle the aforementioned problems, ELM is gradually combined with deep learning to generate a high-performance model (Tang et al., 2014, 2015; Yu et al., 2015; Zhu et al., 2015; Duan et al., 2016; McIntosh et al., 2020). However, most of the existing hierarchical ELM models can hardly effectively use the knowledge learned in previous layers.
ELM is popular for its high-speed response, real-time prediction ability, network conciseness, and excellent generalization performance. The thought of deep learning can be beneficial to excavate the invisible value of input to the greatest extent. To address the problem of lacking representational learning, deep extreme learning machine (DELM) is proposed to recognize EEG epileptic signals. The efficient deep classifier is based on stacked structure, which in essence consists of several modules whose hidden layer parameters are initialized randomly. The proposed method forms a hierarchical structure to aggregate some discrete and valuable information stepwisely into knowledge for hierarchical representation. The previous valuable information is fed into new input in the manner of available knowledge and then transmitted to current sub-model, which serves to implement the subsequent recognition task better. According to stacking generalization theory, the output of the next sub-model plus the knowledge of the previous sub-model in DELM can indeed open the manifold structure of the input space, which resulting an improved performance. DELM have accomplish fast epileptic recognition and show greater performance in EEG signal classification than traditional ELM and some of the state-of-the-art methods, which makes it possible to finish accurate epilepsy diagnosis in real time and with high precision. The main contributions of this work are as follows:
(1) DELM is a novel deep learning structure, which is the product of the fusion of ELM and deep learning. DELM is composed of original ELMs, accordingly, the new structure is inherently brief, flexible to implement, and demonstrates a superior learning performance. Additionally, the introduction of deep representation ensures that valuable knowledge is refined and not wasted. Learning rich representations efficiently is crucial for achieving better generalization performance and informative features can promote the accuracy. In our paper, the new framework can achieve classification accuracy comparable to that of existing deep network schemes in EEG recognition tasks, while DELM takes the leading position in training speed.
(2) Motivated by deep learning, the proposed DELM is used to capture useful information in multi-dimensional EEG variables. DELM is a hierarchical framework, which incorporates a stepwise knowledge augmentation strategy into original ELM. It learns knowledge in an incremental way and expands it in the manner of forward calculation. The current sub-model can exploit knowledge from all previous sub-models and the recognition results can be obtained in the last layer.
(3) DELM uses classic ELM as the basic building block, and each module is the same as the original ELM structure. Supervised learning performs throughout the whole learning process and each sample has a tendency to approach to its own class under the supervision.
The main differences of the proposed DELM and traditional and deep learning methods are summarized in Table 1. The rest of this paper is organized as follows. Section 2 presents the details of deep extreme learning machine proposed in our work and describes its learning process. Section 3 introduces the experiment conducted and compares the recognition performance of the proposed method with that of existing conventional methods on real EEG datasets. Finally, Section 4 concludes the findings of the study.
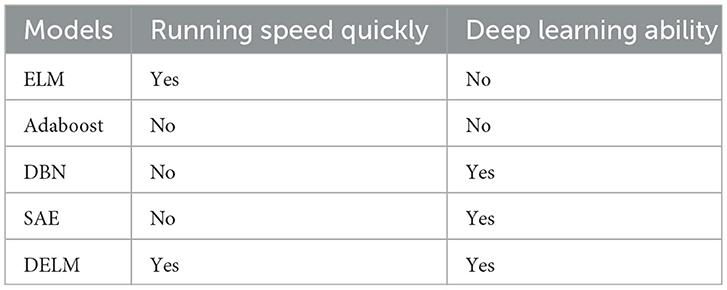
Table 1. Comparisons between the proposed DELM and traditional and deep learning methods.
2. The proposed classifier DELM
2.1. The proposed architecture based on deep representation
ELM with L hidden neural units and activation function g(.) can approximate these N samples with zero error, which is modeled as (Huang et al., 2004):
where , , βi is the weight vector connecting the ith hidden node and the output nodes, wi is the ith hidden node and the input nodes, and bi represents the bias of the ith hidden node. For the sake of convenience, the equation can be written in a compact form
with , and
where H is the hidden layer output matrix of neural network, the ith column of H is corresponding output of the ith hidden layer unit with respect to inputs.
The solution of Equation 2 is equivalent to the next optimization problem (Liang et al., 2006a):
In most cases of practical application, the hidden layer neurons is far less than the samples need be trained, L≪N. The output matrix of the hidden layer is not a square matrix, and the minimum norm least-squares solution of the above linear system can be calculated by Equation 4 (Huang et al., 2011a):
H+ denotes the Moore-Penrose generalized inverse of the output matrix H. The theory of ELM is aimed at reaching not only the smallest training error but also the smallest norm of output weights.
ELM is a shallow network composed of three layers (respectively input layer, hidden layer and output layer), whose representation capability is limited. Adequate representation of the input is routinely desired to acquire an excellent performance in the idea of deep learning. On account of the flexibility and efficiency of ELMs, ELM is extended to the learning of deep neural network (DNN) to shorten the learning time dramatically and reduce the computational complexity without deserting their original excellence. The proposed architecture constructed from ELM building block is a new ELM-based stacked structure that processes information layer by layer in order to utilize the learned knowledge. Figure 1 depicts the architecture of the proposed hierarchical method.
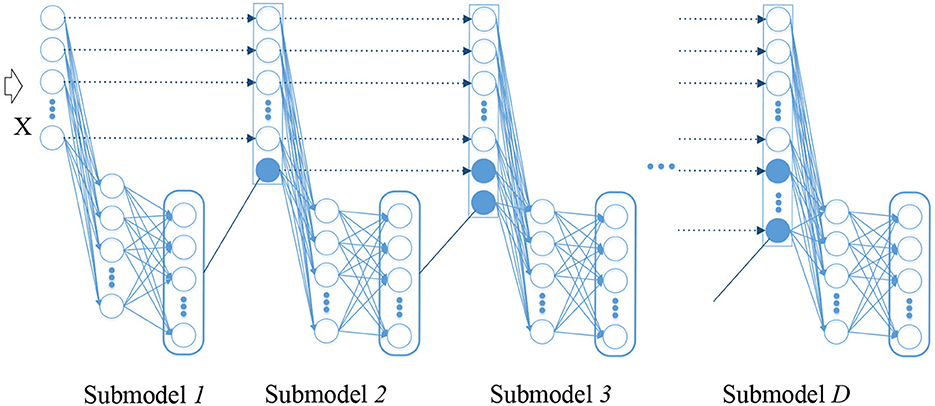
Figure 1. The proposed hierarchical architecture.
The proposed structure inherits the simplicity of the original ELM, and then digestion and absorption of knowledge is performed in multiple sub-model. In DELM, the initial EEG epileptic signal is learned step by step in a forward manner. The representation learned from the previous layer is regarded as new knowledge and will then be taught. Upon the arrival of given input, the corresponding linear system can be solved immediately in the first ELM.
In a singleton ELM module, the knowledge generation process is as follows. If HTH is nonsingular, the orthogonal projection method can be used to calculate the generalized inverse of a matrix (Huang et al., 2011b):
According to Equation 4 (Betthauser et al., 2017), we can get
For binary EEG classification applications, the decision function is:
g(.) maps the data from input space into the L-dimensional hidden-layer feature space (ELM feature space). By inserting Equations 6 into Equation 7, we can obtain
For multi-class EEG classification tasks, the corresponding predicted label of sample is the index number of the output node which has the highest output value for the given instance. fp denotes the output function of pth node, then we have the predicted class label of sample x:
Each sub-model in a higher layer takes information transformed from the decision output of the previous lower layers and appends them as supplementary knowledge, enabling more relevant representation to be handed over to the next generation. Deeper representation is captured to build a hierarchical network until the next additive ELM had no remarkable effect.
With deep representation in DELM, useful information is well-explored and transmitted from the initial layer to the last layer, bringing a more complete and precise expression of original input, improving the knowledge utilization rate greatly and strengthening the learning capability of ELM. Several ELMs are combined together by means of a serial link and the response can be reused in higher sub-model next to it. On the premise of meaningfulness of extended ELM, the purpose of the previous submodel is to convey the knowledge learned by previous layer. By updating the knowledge community, the original manifold can be separated apart in the end.
2.2. Knowledge augmentation based on DELM
A detailed introduction to knowledge transfer between multiple modules is provided in Figure 2. The input of n dimensional attributes provides data for the first level to construct a traditional ELM classifier. For N samples in a given dataset, xi is the data of the ith dimension attribute corresponding to different samples, and ti is the expected label, where , .
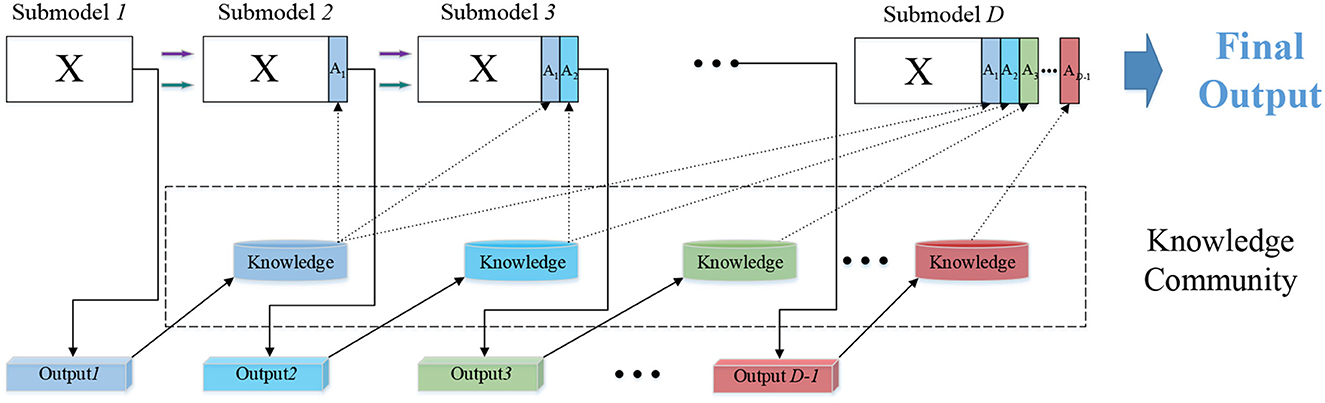
Figure 2. Stepwise knowledge learning in DELM.
The expected label is expressed in T while the actual output Yd calculated by the dth level model is expressed as:
m represents the number of categories of samples. The matrix form is as follows: . After finishing the task of the first ELM, the output produced by sub-model1 is . Resemble the process in classic ELM, the output matrix should perform a transformation here. The information acquired by current sub-model is integrated, and the fused knowledge community is stored for the next knowledge transmission. For the ith instance, take the maximum value in its each column as its class label, store the class label and merge it with the original input. The updated input is obtained in the second level Submodel2: . The label T remains the same as the original one. Similarly, calculate the actual output Y2. Y2 is transformed into knowledge again, and the significant information is stored in new input: . Then, the third sub-model leverages knowledge extracted from the output of sub-model_1 and sub-model_2 to complete the classification of the model. Establish three modules or more on both training and testing sets and that can yield favorable results. The input for these modules comprises original features and appended features from all previous recognition prediction. So the augmented input for each module can be formed as:
At each level, the predicted output of current sub-model is integrated into the input as learning experiences. In the next learning step, the new input after incorporation will be mapped into a new ELM feature space through random mapping in current sub-model to solve the least square problem. The new features, including A1, A2 and so on, contains discriminative information derived from lower modules, so it is helpful in forcing the manifold structure apart in original EEG input. In this course of knowledge augmentation, DELM is aimed at learning a more reasonable decision basis from raw data in classification tasks.
2.3. Specialty of DELM pattern classifier
We are motivated by the idea of deep learning and stacking generalization theory, and establish a hierarchical ELM-based stacked architecture. Each sub-model has the same supervised learning process as classic ELM and several ELMs are integrated into a deep network. ELM in each level is an elegant original model, which is respectively composed of input layer, hidden layer and output layer in our paper. Under the guidance of the corresponding expected labels, DELM can better pull each sample to its own class cluster, hence, samples have a tendency to approach their own field gradually after knowledge augmentation. In other words, it makes it easier for the samples belonging to some class to be identified as belonging to its true class by DELM pattern classifier. Accordingly, the output generated in previous submodel performs knowledge transformation first, and then it is regarded as a supplement to the input. DELM is targeted at achieving a richer form of representation from raw data, which enables the sequential propagation of knowledge in a forward way and provides a method to automatically discover valuable implied patterns. With the valuable information extracted from the instances, the whole model is directed to study the internal information of instances, and constantly approach the ideal output with stepwise learning.
Noise caused by electrode movement or others often appears in the practical EEG signal, resulting in poor recognition results. The proposed framework has the anti-noise capability of deep network in practice in contrast to the traditional ELM algorithm, which can stand against the noise to a certain extent. With stepwise transformation of input EEG epileptic information, the dimension of the input expands continuously, and the pollution in the original data is gradually reduced or eliminated. Stepwise knowledge is continuously strengthened, more reasonable features are generated, and the final classification accuracy of epileptic EEG signals is improved.
The entire network consists of several stacked independent ELM modules. The stacked approach is one of the most effective ensemble learning strategies. Our model trains several submodels in a serial way, and each submodel still preserve the output of the previous submodel for deep representation learning, which shares the same philosophy as stacked generalization (Wolpert, 1992; Wang et al., 2017; Hang et al., 2020).
Our model is aimed at reducing the loss of effective information in the original data and greatly economizing the time required for classification under the premise of ensuring certain accuracy. The information is extracted, grows in refinement and richness, and is accepted to be vital members of the knowledge community ultimately. The sub-model that organizes the higher layer has additional input features involving the classification output from all previous sub-models. DELM learns reasonable and effective features from a large number of complex raw data, and the newly generated features are absorbed by our deep network into its own knowledge, which can achieve satisfactory results in most cases when faced with practical application problems.
In the previous phase, multi submodels are adopted for knowledge augmentation and knowledge are automatically captured through feature expansion. In the latter phase, the original input and the generated knowledge in previous modules are used to accomplish the modeling and the classification tasks. The deep learning algorithm of the proposed DELM is summarized in Algorithm 1.

Algorithm 1. DELM
2.4. Time complexity analysis
In order to exhibit the time complexity of the proposed deep learning algorithm, we start with the classic ELM algorithm first. The time complexity of classic ELM algorithm mainly lies in the solution of Moore-Penrose generalized inverse of hidden output matrix. In terms of Equation 5, O(N2L) can be required to compute the HTH. It requires O(N3) to calculate the inverse. So the time complexity in ELM becomes O(N3 + N2L + NnL + 1). The proposed DELM introduces the concept of deep learning, which is composed of several building units. Obviously, the time complexity of the entire DELM can be indicated as , where D is the final value of depth, L is the number of hidden layer neural network units and N is the number of instances.
3. Experiment studies
In this section, we will demonstrate the effectiveness of our proposed hierarchical model DELM by reporting the experiment result from Bonn dataset. In our experimental study, DELM is sequentially compared with some machine learning algorithms and popular deep learning networks such as DBN, and so on. The final performance evaluation is performed according to the result. In our experiment, all adopted methods were implemented using MATLAB 2019a on a personal computer with Intel Core i5-9400 2.90 GHz CPU and 8.0G RAM.
3.1. Epileptic EEG dataset
The EEG signals used in the paper are derived from Department of Epileptology, Bonn University, Germany. The dataset has been described in detail by Andrzejak et al. (2001). The EEG signals were collected under various conditions with five healthy volunteers and five epileptic patients. The details information of five groups are summarized in Table 2, in which each group contains 2,300 samples.
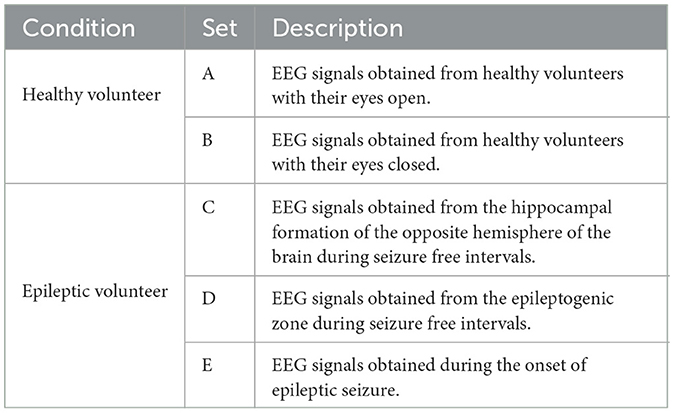
Table 2. A brief introduction to the EEG dataset.
The dataset consists of five groups of data (A, B, C, D, and E) where each containing 100 single-channel EEG segments. EEG data were recorded using the same 128-channel amplifier system with a sampling rate of 173.6 Hz and a 12-bit resolution. Each EEG segment contained 4,096 sampling points and lasted 23.6 s. The five samples in Figure 3 come from Set A, B, C, D and E respectively, as shown below.
Figure 3. Samples from five EEG sets (A–E).
In our experiment, three kinds of EEG signals are employed, namely normal (A and B), interictal (C and D), and ictal (E), to evaluate the proposed epilepsy detection framework.
3.2. Data preparation and normalization
Firstly, the EEG signals are segmented into 178 sampling points by means of moving windows, among which there is no overlapping of sampling windows. Therefore, 23 epochs can be obtained from each segment. The remaining points in each segment are dismissed. Different features extracted from the original EEG signals have different scales after data segmentation, so it is necessary to use normalization processing to normalize all attribute features.
3.3. Experiment setup
In our experimental organization, the processed dataset is firstly randomly divided into two parts: training and testing set. In each scenario, we randomly selected 80% of the data as the training data, and the remaining 20% as the testing data. The experiment is repeated 20 times in various scenarios and then the average experimental results of some other schemes are also collected as contrast. In our experiment, SVM, RBF and some ensemble algorithms such as Adaboost are used. Meanwhile, experimental results of well-known deep networks, such as DBN and SAE, are also adopted as comparison in our experiment in order to demonstrate the superiority of the proposed DELM.
To reasonably evaluate our method, the performance metrics adopted here are Accuracy and F−measure, which are defined as follows:
where TP (true positive) represents the number of segments detected as seizure correctly, FN (false negative) represents the number of segments detected as non-seizure incorrectly, TN (true negative) represents the number of segments detected as non-seizure correctly, and FP (false positive) is the number of segments detected as seizure incorrectly.
In terms of recognition accuracy, our DELM model can achieve great classification accuracy comparable to that of deep learning schemes. Running time is one of the key evaluation indexes which can perform excellent performance in DELM. The classic ELM is qualified for real-time recognition requirements and so does our hierarchical model. Extremely fast recognition ability can still be exhibited in DELM, meanwhile traditional deep networks are too far behind to catch with.
Among all the competing schemes, SVM, RBF, and ensemble algorithms were implemented by toolbox in MATLAB. And traditional deep learning algorithms are implemented by MATLAB which is encapsulated in the DeepLearning Toolbox. The parameters settings are summarized in Table 3.
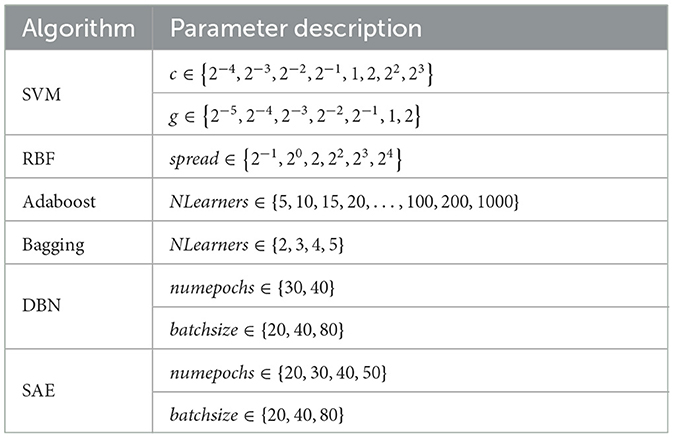
Table 3. The detailed parameters used in our experiment.
In each sub-model, all input weights and hidden biases are set to the pseudo random values drawn from the uniform distribution on the interval (−1, 1) and (0, 1). Such scheme is in accordance with the standard methodology of ELM, which simplifies the learning process. In each ELM, the hidden layer adopts the same number of hidden nodes and the same activation function. Sigmoid function is chosen as the activation function g(.) in each submodel. The number of hidden units is usually scenario-specific and determined by experience or by continuous attempts. We need to find a point as balanced as possible between the number of hidden units and time. As a result, DELM can acquire a relatively mature knowledge system, which can well meet the accuracy requirements of classification. The optimal amount of hidden units in all sub-models is uniformly set to a fixed value 500. Considering the difficulty of recognition in five class problem, the number of hidden units is set to 800. More ELMs can be cascaded to modules, if desired, for the purpose of adequate knowledge. So we dynamically determine the depth of network. The stacking process will be aborted if the difference between the current and upper level in the experiment is <0.1. It is clear that DELM simply involves a few parameters, which greatly reduces the cost of parameter adjustment. To evaluate DELM comprehensively and precisely, classification tasks in various scenarios are designed here.
3.4. Epileptic EEG signal recognition
3.4.1. Two class problem
Classification of four combinations between A and E, B and E, C and E, and D and E are considered to distinguish normal from seizure. Epileptic seizure segments E was selected to compare with one of the remaining EEG sets from the dataset for classification. Then select two or more sets in the database and conduct trials again. The combinations are as follows: AB and E, AC and E, AD and E, BC and E, BD and E, CD and E, ABC and E, ABD and E, ACD and E, BCD and E, and ABCD and E.
3.4.2. Three class problem
In three class problems, the selected combinations are: A, B, E and A, C, E and A, D, E and B, C, E and B, D, E and C, D, E.
3.4.3. Five class problem
In five class problem, each group is regarded as an independent class for testing.
3.5. Experimental results and statistical analysis
Table 4 shows us the accuracy in the sense of both the mean and standard deviation in DELM and deep networks. The results are also presented when the depth d of DELM is 3. But the result in the case is still a certain gap from the ideal, and more ELMs are required to assure higher accuracy. In terms of accuracy, DELM can compete with conventional intelligent methods. It can be noted in the results that the proposed method has certain advantages over traditional methods and is generally comparable to traditional deep networks. We attribute this advancement in recognition performance to the embedded knowledge. The accuracy is greatly improved by extending the vertical network layers and the model gradually acquires a better command of the implication of knowledge. Table 4 also report the accuracy of common machine learning algorithms on our datasets.
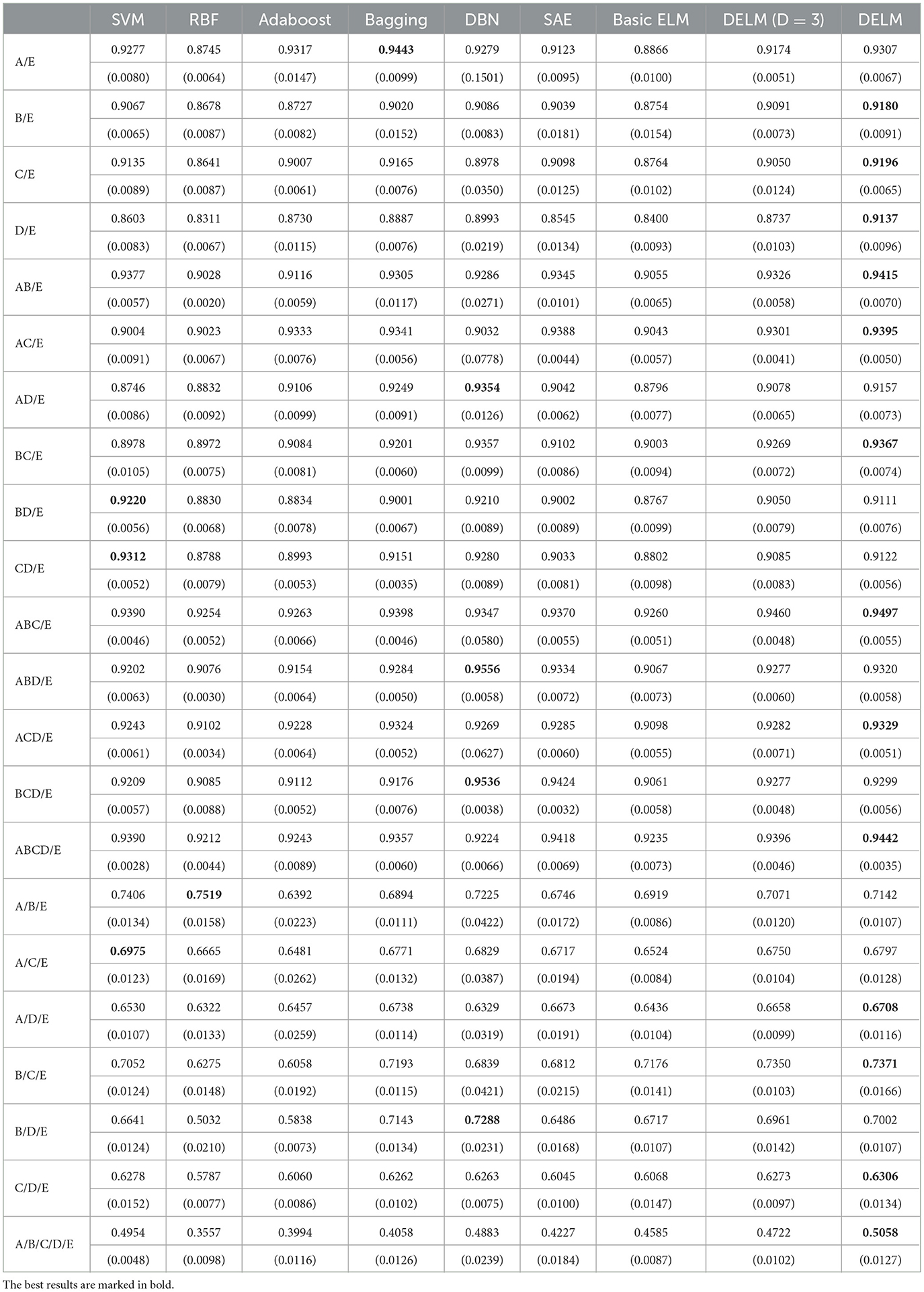
Table 4. Average testing accuracy in our experiment.
Since DELM can inherit advantages of ELM, extremely fast learning speed is one of its remarkable characteristics. In the aspect of computational efficiency, the slight increase of learning time (extremely short seconds) in DELM compared to the original ELM is inappreciable, especially when considering the added improvement in classification accuracy. DELM is about sacrificing a little time and tolerating a cascade of multi modules in exchange for final performance, so we just need to draw comparison between our ELM-based deep network and traditional deep network. The experimental results show that the time needed in DELM is much less than that of the traditional deep networks after the accuracy is guaranteed to meet the requirements. In some designed scenarios, the speed of DELM in training and testing is approximately a dozen times faster than traditional deep networks.
Figure 4 reports time efficiency during learning process, and the result is average learning time of models. As observed from both Table 4 and Figure 4, the accuracy performance is almost similar in DELM and traditional deep methods. However, the time consumed by the proposed classifier is the least. Taking into account both accuracy and computational effort simultaneously, the proposed DELM demonstrates tremendous potential in EEG classification and may be a competitive choice.
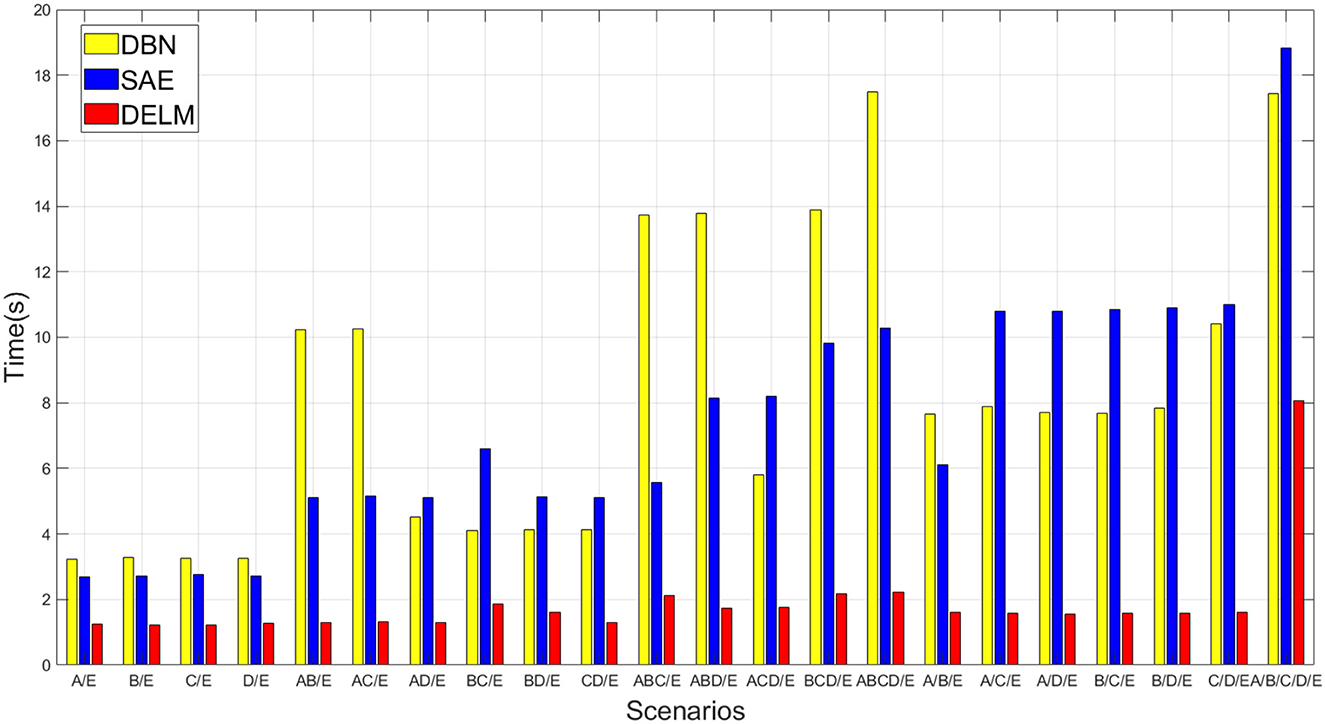
Figure 4. Average time consumed by deep networks in our experiment.
Figure 5 shows the changes in recognition accuracy along with current stacked depth of modules in different EEG classification scenarios. There is no doubt that the EEG classification accuracy increases with the addition of sub-models. The number of submodels we use is namely the depth of DELM. Depth is denoted by d, and the result shows the classification accuracy from d = 1 to d = 10. It is shown that the improvement in accuracy can be relatively evident in the first three levels. Modest improvement can still be obtained in the subsequent expansion of ELMs, but DELM will gradually lose competitiveness in real-time tasks. Without rapid classification performance, what we think of as our inherent excellence in our model, several serial ELM network modules in our model, would make no sense and our previous efforts would not worth it. By starting from d = 1, ordinary extreme learning machine, excellent features can be well-preserved and classification effect is gradually improved. Performance augmentation can be seen in these figures.
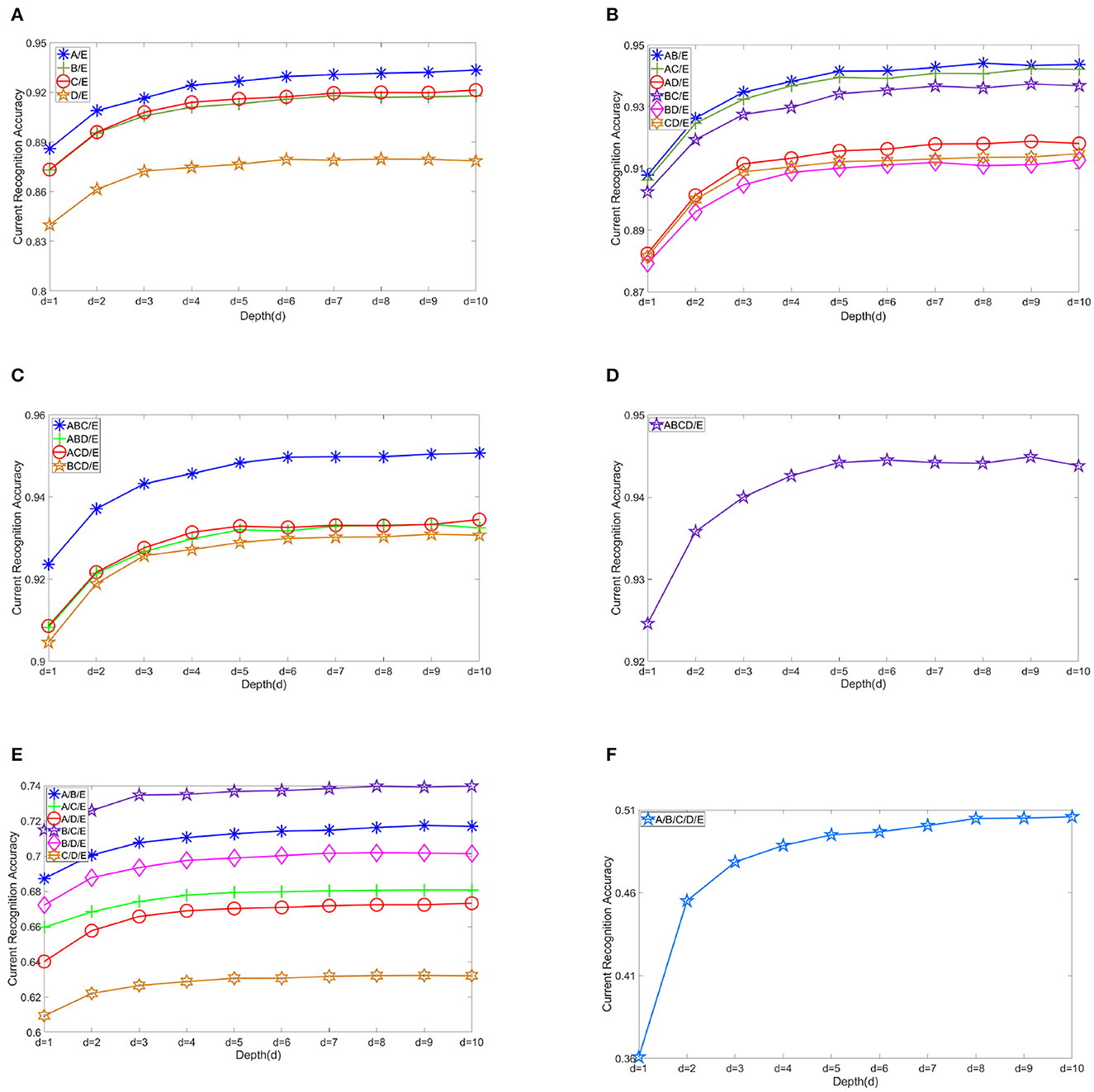
Figure 5. Changes in recognition accuracy along with stacked depth of modules in various scenarios. (A) Another individual group vs. ictal A/E, B/E, C/E, and D/E. (B) Two other groups vs. ictal AB/E, AC/E, AD/E, BC/E, BD/E, and CD/E. (C) Three other groups vs. ictal ABC/E, ABD/E, ACD/E, and BCD/E. (D) All other groups vs. ictal ABCD/E. (E) A/B/E, A/C/E, A/D/E, B/C/E, B/D/E, and C/D/E. (F) A/B/C/D/E.
The depth is the key aspect to knowledge augmentation in DELM. In our experimental organization, different depths are adopted in binary class problems, while D = 6 is uniformly adopted in three and five class problems in order to obtain better classification accuracy. Setting a threshold for DELM is because excessive accumulation of layers is not productive any more. The average depth of binary class problems is dAVG = 5.8. The selection of depth parameters are shown in Figure 6.
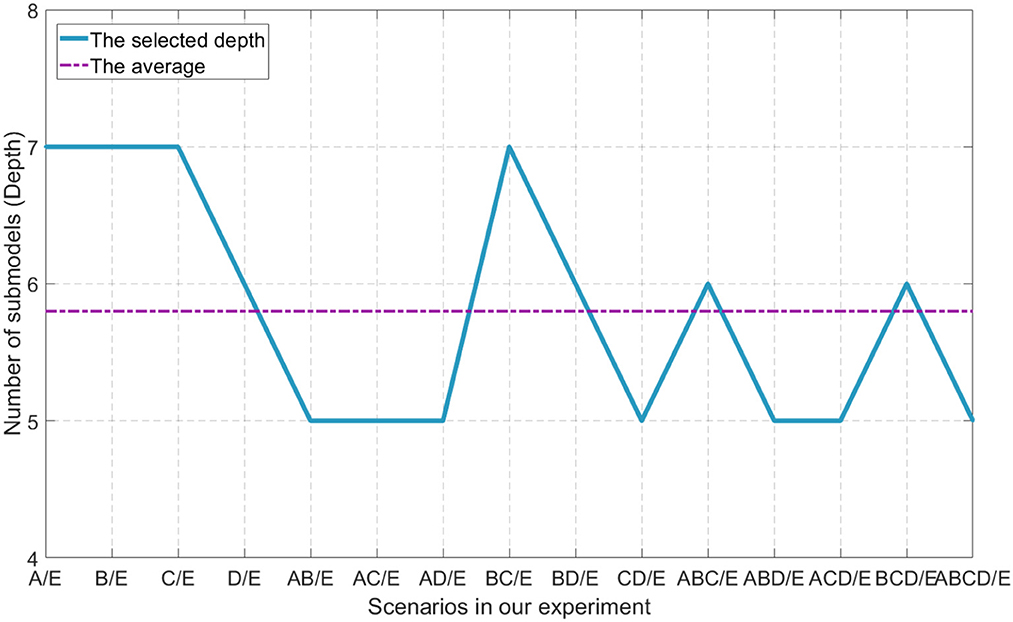
Figure 6. Different parameters of depth used in our experiment.
Table 5 presents F−measure scores obtained by traditional deep learning methods in different scenarios. From the perspective of F−measure scores, DELM outperforms several deep networks used for comparison. In other scenarios, DELM is slightly worse than deep networks, but it still performs well and is comparable to deep networks.
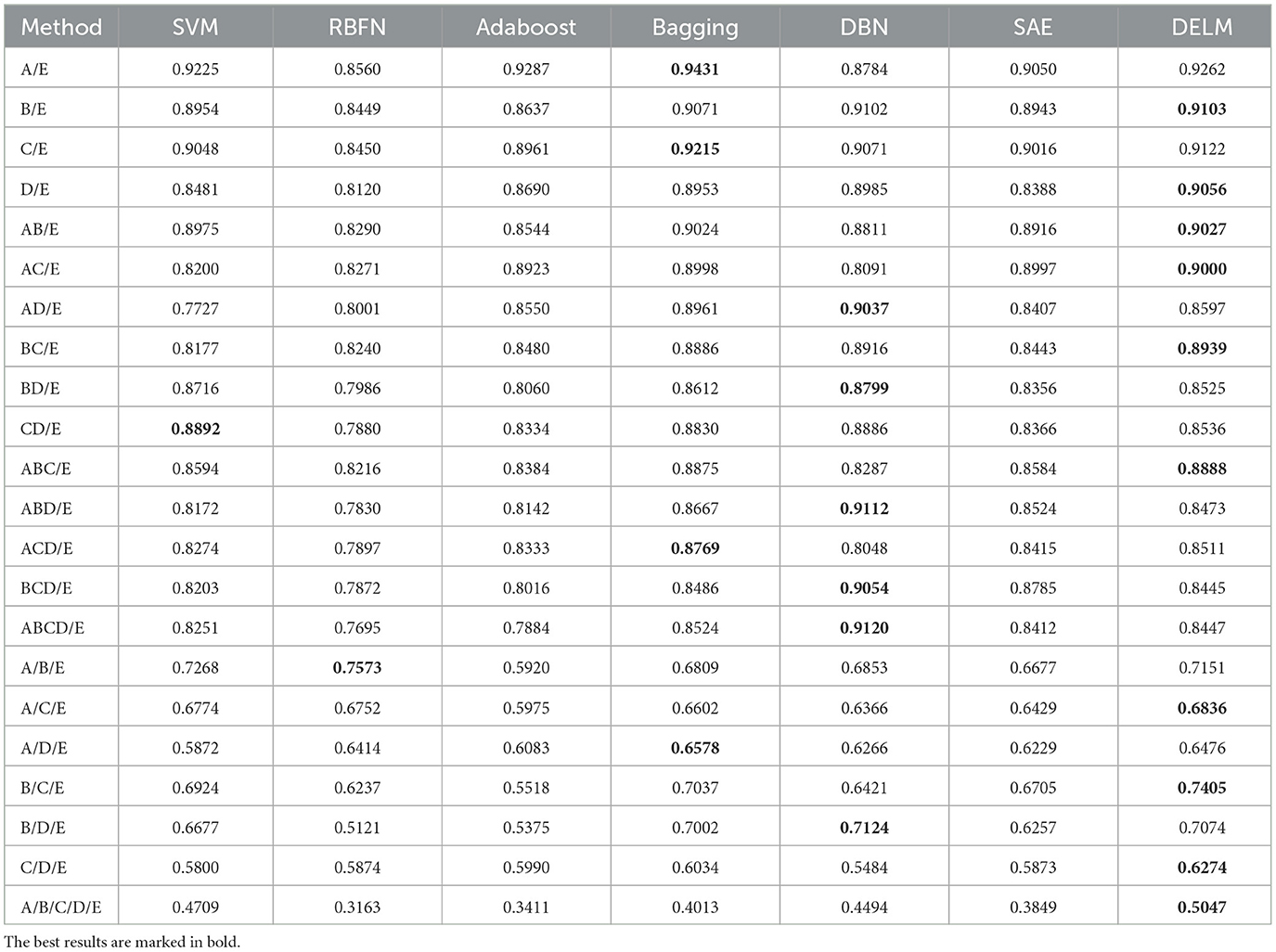
Table 5. F − measure scores of the comaparative methods.
DELM enjoys extremely fast speed of ELM while providing deeper representation of original signals. Experiments show that our algorithm consistently outperforms several existing state-of-art schemes in terms of accuracy and execution time.
4. Conclusion
A novel deep extreme learning machine DELM is proposed for the recognition of EEG epileptic signals in our paper. DELM stepwisely transmits the response to the next submodel through fusion of knowledge derived from previous sub-models. Such a process is beneficial to mine the valuable information of the original EEG data, so as to better accomplish the subsequent EEG recognition tasks. The proposed model operates in a forward way with an increment form to strive for an increasingly efficient performance and its computation speed is considerably fast. ELM is introduced as the basic building block, making the whole learning process flexible and effective. As available knowledge, the classification results of the previous multi-module can enhance the classification performance of the subsequent modules. Our experimental results demonstrate that the proposed method is a promising candidate for epileptic EEG-based recognition. Compared with traditional methods, the proposed DELM is motivated by deep learning and stack generalization theory, which can obtain excellent classification results and outperform the traditional methods. According to stacking generalization theory, the output of the next sub-model plus the knowledge of the previous sub-model in DELM can indeed open the manifold structure of the input space, which resulting an improved performance. Moreover, knowledge augmentation can effectively extract the implied knowledge in each sub-model and obtain increasing performance.
However, it is still not clear the reason for the improvement of knowledge augmentation throughout the training process. In the future work, we will spare no efforts to theoretically demonstrate how the prediction output in each ELM module can be helpful with EEG epileptic signal recognition.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found at: http://epileptologie-bonn.de/cms/upload/workgroup/lehnertz/eegdata.html.
Author contributions
XZ and JZ conceived and designed the theoretical framework of this paper. All authors participated the experimentation and analysis process and drafted the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Natural Science Foundation of China under Grant: 62101645, Zhejiang Provincial Natural Science Foundation of China under Grant: LQ22F020024, Zhejiang Medicine and Health Science and Technology Project: 2020RC118, and Huzhou Municipal Science and Technology Bureau Public Welfare Application Research Project: 2019GZ40.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Acharya, U. R., Oh, S. L., Hagiwara, Y., Tan, J. H., and Adeli, H. (2018). Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Comput. Biol. Med. 100, 270–278. doi: 10.1016/j.compbiomed.2017.09.017
Ahmadlou, M., and Adeli, H. (2011). Functional community analysis of brain: a new approach for EEG-based investigation of the brain pathology. Neuroimage 58, 401–408. doi: 10.1016/j.neuroimage.2011.04.070
Andrzejak, R. G., Lehnertz, K., Mormann, F., Rieke, C., David, P., and Elger, C. E. (2001). Indications of non-linear deterministic and finite-dimensional structures in time series of brain electrical activity: dependence on recording region and brain state. Phys. Rev. E 64, e061907. doi: 10.1103/PhysRevE.64.061907
Ayman, U., Zia, M. S., Okon, O. D., Rehman, N.-u., Meraj, T., Ragab, A. E., et al. (2023). Epileptic patient activity recognition system using extreme learning machine method. Biomedicines 11, 30816. doi: 10.3390/biomedicines11030816
Bengio, Y., Lamblin, P., Popovici, D., Larochelle, H., et al. (2007). Greedy layer-wise training of deep networks. Adv. Neural Inform. Process. Syst. 19, 153. doi: 10.7551/mitpress/7503.003.0024
Betthauser, J. L., Hunt, C. L., Osborn, L. E., Masters, M. R., Lévay, G., Kaliki, R. R., et al. (2017). Limb position tolerant pattern recognition for myoelectric prosthesis control with adaptive sparse representations from extreme learning. IEEE Trans. Biomed. Eng. 65, 770–778. doi: 10.1109/TBME.2017.2719400
Bhattacharyya, A., and Pachori, R. B. (2017). A multivariate approach for patient-specific EEG seizure detection using empirical wavelet transform. IEEE Trans. Biomed. Eng. 64, 2003–2015. doi: 10.1109/TBME.2017.2650259
Choi, G., Park, C., Kim, J., Cho, K., Kim, T.-J., Bae, H., et al. (2019). "A novel multi-scale 3D CNN with deep neural network for epileptic seizure detection," in 2019 IEEE International Conference on Consumer Electronics (ICCE) (Las Vegas, NV: IEEE), 1–2.
Deng, Y., Ren, Z., Kong, Y., Bao, F., and Dai, Q. (2016). A hierarchical fused fuzzy deep neural network for data classification. IEEE Trans. Fuzzy Syst. 25, 1006–1012. doi: 10.1109/TFUZZ.2016.2574915
Duan, L., Bao, M., Miao, J., Xu, Y., and Chen, J. (2016). Classification based on multilayer extreme learning machine for motor imagery task from EEG signals. Proc. Comput. Sci. 88, 176–184. doi: 10.1016/j.procs.2016.07.422
Ghosh-Dastidar, S., Adeli, H., and Dadmehr, N. (2007). Mixed-band wavelet-chaos-neural network methodology for epilepsy and epileptic seizure detection. IEEE Trans. Biomed. Eng. 54, 1545–1551. doi: 10.1109/TBME.2007.891945
Güler, I., and Übeyli, E. D. (2005). Adaptive neuro-fuzzy inference system for classification of EEG signals using wavelet coefficients. J. Neurosci. Methods 148, 113–121. doi: 10.1016/j.jneumeth.2005.04.013
Hang, W., Feng, W., Liang, S., Wang, Q., Liu, X., and Choi, K.-S. (2020). Deep stacked support matrix machine based representation learning for motor imagery EEG classification. Comput. Methods Progr. Biomed. 193, 105466. doi: 10.1016/j.cmpb.2020.105466
Hinton, G. E., Osindero, S., and Teh, Y.-W. (2006). A fast learning algorithm for deep belief nets. Neural Comput. 18, 1527–1554. doi: 10.1162/neco.2006.18.7.1527
Hinton, G. E., and Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science 313, 504–507. doi: 10.1126/science.1127647
Huang, G., Kasun, L., Zhou, H., and Vong, C. (2013). Representational learning with extreme learning machine for big data. IEEE Intell. Syst. 28, 31–34. doi: 10.1109/MIS.2013.140
Huang, G.-B., Wang, D. H., and Lan, Y. (2011a). Extreme learning machines: a survey. Int. J. Machine Learn. Cybernet. 2, 107–122. doi: 10.1007/s13042-011-0019-y
Huang, G.-B., Zhou, H., Ding, X., and Zhang, R. (2011b). Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybernet. B 42, 513–529. doi: 10.1109/TSMCB.2011.2168604
Huang, G.-B., Zhu, Q.-Y., and Siew, C.-K. (2004). "Extreme learning machine: a new learning scheme of feedforward neural networks," in 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Vol. 2 (Budapest: IEEE), 985–990.
Huang, G.-B., Zhu, Q.-Y., and Siew, C.-K. (2006). Extreme learning machine: theory and applications. Neurocomputing 70, 489–501. doi: 10.1016/j.neucom.2005.12.126
Iasemidis, L. D., Shiau, D.-S., Chaovalitwongse, W., Sackellares, J. C., Pardalos, P. M., Principe, J. C., et al. (2003). Adaptive epileptic seizure prediction system. IEEE Trans. Biomed. Eng. 50, 616–627. doi: 10.1109/TBME.2003.810689
Khan, H., Marcuse, L., Fields, M., Swann, K., and Yener, B. (2017). Focal onset seizure prediction using convolutional networks. IEEE Trans. Biomed. Eng. 65, 2109–2118. doi: 10.1109/TBME.2017.2785401
Kumar, S. P., Sriraam, N., Benakop, P., and Jinaga, B. (2010). Entropies based detection of epileptic seizures with artificial neural network classifiers. Expert Syst. Appl. 37, 3284–3291. doi: 10.1016/j.eswa.2009.09.051
Kumar, Y., Dewal, M., and Anand, R. (2014). Epileptic seizure detection using DWT based fuzzy approximate entropy and support vector machine. Neurocomputing 133, 271–279. doi: 10.1016/j.neucom.2013.11.009
Liang, N.-Y., Huang, G.-B., Saratchandran, P., and Sundararajan, N. (2006a). A fast and accurate online sequential learning algorithm for feedforward networks. IEEE Trans. Neural Netw. 17, 1411–1423. doi: 10.1109/TNN.2006.880583
Liang, N.-Y., Saratchandran, P., Huang, G.-B., and Sundararajan, N. (2006b). Classification of mental tasks from EEG signals using extreme learning machine. Int. J. Neural Syst. 16, 29–38. doi: 10.1142/S0129065706000482
McIntosh, J. R., Yao, J., Hong, L., Faller, J., and Sajda, P. (2020). Ballistocardiogram artifact reduction in simultaneous EEG-FMRI using deep learning. IEEE Trans. Biomed. Eng. 68, 78–89. doi: 10.1109/TBME.2020.3004548
Nicolaou, N., and Georgiou, J. (2012). Detection of epileptic electroencephalogram based on permutation entropy and support vector machines. Expert Syst. Appl. 39, 202–209. doi: 10.1016/j.eswa.2011.07.008
Panda, R., Khobragade, P., Jambhule, P., Jengthe, S., Pal, P., and Gandhi, T. (2010). "Classification of EEG signal using wavelet transform and support vector machine for epileptic seizure diction," in 2010 International Conference on Systems in Medicine and Biology (Kharagpur: IEEE), 405–408.
Plis, S. M., Hjelm, D. R., Salakhutdinov, R., Allen, E. A., Bockholt, H. J., Long, J. D., et al. (2014). Deep learning for neuroimaging: a validation study. Front. Neurosci. 8, 229. doi: 10.3389/fnins.2014.00229
Song, Y., and Zhang, J. (2013). Automatic recognition of epileptic EEG patterns via extreme learning machine and multiresolution feature extraction. Expert Syst. Appl. 40, 5477–5489. doi: 10.1016/j.eswa.2013.04.025
Subasi, A., and Ercelebi, E. (2005). Classification of EEG signals using neural network and logistic regression. Comput. Methods Progr. Biomed. 78, 87–99. doi: 10.1016/j.cmpb.2004.10.009
Tang, J., Deng, C., and Huang, G.-B. (2015). Extreme learning machine for multilayer perceptron. IEEE Trans. Neural Netw. Learn. Syst. 27, 809–821. doi: 10.1109/TNNLS.2015.2424995
Tang, J., Deng, C., Huang, G.-B., and Hou, J. (2014). "A fast learning algorithm for multi-layer extreme learning machine," in 2014 IEEE International Conference on Image Processing (ICIP) (Paris: IEEE), 175–178.
Vincent, P., Larochelle, H., Lajoie, I., Bengio, Y., Manzagol, P.-A., and Bottou, L. (2010). Stacked denoising autoencoders: learning useful representations in a deep network with a local denoising criterion. J. Machine Learn. Res. 11, 3371–3408. doi: 10.1016/j.mechatronics.2010.09.004
Wang, D., Ren, D., Li, K., Feng, Y., Ma, D., Yan, X., et al. (2018). Epileptic seizure detection in long-term EEG recordings by using wavelet-based directed transfer function. IEEE Trans. Biomed. Eng. 65, 2591–2599. doi: 10.1109/TBME.2018.2809798
Wang, G., Zhang, G., Choi, K.-S., and Lu, J. (2017). Deep additive least squares support vector machines for classification with model transfer. IEEE Trans. Syst. Man Cybernet. 49, 1527–1540. doi: 10.1109/TSMC.2017.2759090
Xu, J., Xiang, L., Liu, Q., Gilmore, H., Wu, J., Tang, J., et al. (2015). Stacked sparse autoencoder (SSAE) for nuclei detection on breast cancer histopathology images. IEEE Trans. Med. Imag. 35, 119–130. doi: 10.1109/TMI.2015.2458702
Yu, W., Zhuang, F., He, Q., and Shi, Z. (2015). Learning deep representations via extreme learning machines. Neurocomputing 149, 308–315. doi: 10.1016/j.neucom.2014.03.077
Yuan, Q., Zhou, W., Li, S., and Cai, D. (2011). Epileptic EEG classification based on extreme learning machine and nonlinear features. Epilepsy Res. 96, 29–38. doi: 10.1016/j.eplepsyres.2011.04.013
Zhou, P.-Y., and Chan, K. C. (2016). Fuzzy feature extraction for multichannel EEG classification. IEEE Trans. Cogn. Dev. Syst. 10, 267–279. doi: 10.1109/TCDS.2016.2632130
Keywords: multilayer extreme learning machine, deep network, knowledge utilization, EEG, seizure recognition
Citation: Zhang X, Dong S, Shen Q, Zhou J and Min J (2023) Deep extreme learning machine with knowledge augmentation for EEG seizure signal recognition. Front. Neuroinform. 17:1205529. doi: 10.3389/fninf.2023.1205529
Received: 14 April 2023; Accepted: 10 August 2023;
Published: 24 August 2023.
Edited by:
Peter A. Tass, Stanford University, United StatesReviewed by:
Alireza Valizadeh, Institute for Advanced Studies in Basic Sciences (IASBS), IranMd. Ariful Islam, University of Dhaka, Bangladesh
Copyright © 2023 Zhang, Dong, Shen, Zhou and Min. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jie Zhou, sxuj_zhou@163.com