
Abstract
Protein sequence comparison remains a challenging work for the researchers owing to the computational complexity due to the presence of 20 amino acids compared with only four nucleotides in Genome sequences. Further, protein sequences of different species are of different lengths; it throws additional changes to the researchers to develop methods, specially alignment-free methods, to compare protein sequences. In this work, an efficient technique to compare protein sequences is developed by a graphical representation. First, the classified grouping of 20 amino acids with a cardinality of 4 based on polar class is considered to narrow down the representational range from 20 to 4. Then a unit vector technique based on a two-quadrant Cartesian system is proposed to provide a new two-dimensional graphical representation of the protein sequence. Now, two approaches are proposed to cope with the varying lengths of protein sequences from various species: one uses Dynamic Time Warping (DTW), while the other one uses a two-dimensional Fast Fourier Transform (2D FFT). Next, the effectiveness of these two techniques is analyzed using two evaluation criteria—quantitative measures based on symmetric distance (SD) and computational speed. An analysis is performed on five data sets of 9 ND4, 9 ND5, 9 ND6, 12 Baculovirus, and 24 TF proteins under the two methods. It is found that the FFT-based method produces the same results as DTW but in less computational time. It is found that the result of the proposed method agrees with the known biological reference. Further, the present method produces better clustering than the existing ones.













Similar content being viewed by others

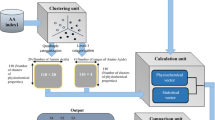
References
Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ (1990) Basic local alignment search tool. J Mol Biol 215(3):403–410. https://doi.org/10.1016/S0022-2836(05)80360-2
Thompson JD, Higgins DG, Gibson TJ (1994) CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice. Nucleic Acids Res 22(22):4673–4680. https://doi.org/10.1093/nar/22.22.4673
Zielezinski A, Vinga S, Almeida J, Karlowski WM (2017) Alignment-free sequence comparison: benefits, applications, and tools. Genome Biol 18:186. https://doi.org/10.1186/s13059-017-1319-7
Hamori E, Ruskin J (1983) H curves, a novel method of representation of nucleotide series especially suited for long DNA sequences. J Biol Chem 258(2):1318–1327. https://doi.org/10.1016/S0021-9258(18)33196-X
Gates MA (1986) A simple way to look at DNA. J Theor Biol 119(3):319–328
Jeffrey HJ (1990) Chaos game representation of gene structure. Nucleic Acids Res 18(8):2163–2170. https://doi.org/10.1093/nar/18.8.2163
Nandy A (1994) A new graphical representation and analysis of DNA sequence structure: I. Methodology and application to globin genes. Curr Sci 66:309–314
Leong PM, Morgenthaler S (1995) Random walk and gap plots of DNA sequences. Bioinformatics 11(5):503–507
Hoang T, Yin C, Yau S-T (2016) Numerical encoding of DNA sequences by chaos game representation with application in similarity comparison. Genomics 108(3–4):134–142. https://doi.org/10.1016/j.ygeno.2016.08.002
Jin X, Jiang Q, Chen Y et al (2017) Similarity/dissimilarity calculation methods of DNA sequences: a survey. J Mol Graph Model 76:342–355. https://doi.org/10.1016/j.jmgm.2017.07.019
Abd Elwahaab MA, Abo-Elkhier MM, Abo el Maaty MI (2019) A statistical similarity/dissimilarity analysis of protein sequences based on a novel group representative vector. Biomed Res Int 2019:1–9. https://doi.org/10.1155/2019/8702968
He P-A, Xu S, Dai, Q.i., Yao, Y. (2016) A generalization of CGR representation for analyzing and comparing protein sequences. Int J Quantum Chem 116(6):476–482. https://doi.org/10.1002/qua.25068
Hu H, Li Z, Dong H, Zhou T (2017) Graphical representation and similarity analysis of protein sequences based on fractal interpolation. IEEE/ACM Trans Comput Biol Bioinform 14(1):182–192. https://doi.org/10.1109/TCBB.2015.2511731
Li C, Li X, Lin YX (2016) Numerical characterization of protein sequences based on the generalized Chou’s pseudo amino acid composition. Appl Sci 6:406. https://doi.org/10.3390/app6120406
Ma T, Liu Y, Dai Q, Yao Y, He PA (2014) A graphical representation of protein based on a novel iterated function system. Physics A 403:21–28. https://doi.org/10.1016/j.physa.2014.01.067
Mervat MA, Marwa AA, Moheb IA, Jiangke Y (2019) Measuring similarity among protein sequences using a new descriptor. Biomed Res Int 22:2796971. https://doi.org/10.1155/2019/2796971
Mu Z, Yu T, Liu X, Zheng H, Wei L, Liu J (2021) FEGS: a novel feature extraction model for protein sequences and its applications. BMC Bioinform 22:1–5
Wu C, Gao R, De Marinis Y, Zhang Y (2018) A novel model for protein sequence similarity analysis based on spectral radius. J Theor Biol 446:61–70. https://doi.org/10.1016/j.jtbi.2018.03.001
Yao Y-H, Dai Q, Li C, He P-A, Nan X-Y, Zhang Y-Z (2008) Analysis of similarity/dissimilarity of protein sequences. Proteins 73(4):864–871. https://doi.org/10.1002/prot.22110
Yao YH, Yan S, Han J, Dai Q, He PA (2014) A novel descriptor of protein sequences and its application. J Theor Biol 347:109–117. https://doi.org/10.1016/j.jtbi.2014.01.001
Zhang Y, Ruan J, He PA (2013) Analyzes of the similarities of protein sequences based on the pseudo amino acid composition. Chem Phys Lett 590:239–244. https://doi.org/10.1016/j.cplett.2013.10.076
Lochel HF, Eger D, Sperlea T, Heider D (2020) Deep learning on chaos game representation for proteins. Bioinformatics 36:272–279. https://doi.org/10.1093/bioinformatics/btz493
Li C, Dai Q, He PA (2022) A time series representation of protein sequences for similarity comparison. J Theor Biol 538:111039. https://doi.org/10.1016/j.jtbi.2022.111039
Akbar S, Hayat M, Tahir M, Chong KT (2020) cACP-2LFS: classification of anticancer peptides using sequential discriminative model of KSAAP and two-level feature selection approach. IEEE Access 8:131939–131948
Akbar S, Hayat M, Iqbal M, Jan MA (2017) iACP-GAEnsC: evolutionary genetic algorithm based ensemble classification of anticancer peptides by utilizing hybrid feature space. Artif Intell Med 79:62–70
Ahmad A, Akbar S, Khan S, Hayat M, Ali F, Ahmed A, Tahir M (2021) Deep-AntiFP: prediction of antifungal peptides using distanct multi-informative features incorporating with deep neural networks. Chemom Intell Lab Syst 208:104214
Ahmad A, Akbar S, Tahir M, Hayat M, Ali F (2022) iAFPs-EnC-GA: identifying antifungal peptides using sequential and evolutionary descriptors based multi-information fusion and ensemble learning approach. Chemom Intell Lab Syst 222:104516
Akbar S, Ahmad A, Hayat M, Rehman AU, Khan S, Ali F (2021) iAtbP-Hyb-EnC: prediction of antitubercular peptides via heterogeneous feature representation and genetic algorithm based ensemble learning model. Comput Biol Med 137:104778
Sakoe H, Chiba S (1978) Dynamic-programming algorithm optimization for spoken word recognition. IEEE Trans Acoust Speech Signal Process 26:43–49
Gold O, Sharir M (2018) Dynamic time warping and geometric edit distance: breaking the quadratic barrier. ACM Trans Algorithms (TALG) 14(4):1–17
Zhang Y, Yu X (2010) Analysis of protein sequence similarity. In: 2010 IEEE fifth international conference on bio-inspired computing: theories and applications (BIC-TA), pp 1255–1258. IEEE.
Pal J, Ghosh S, Maji B, Bhattacharya DK (2022) Mathematical approach to protein sequence comparison based on physiochemical properties. ACS Omega 7(43):39446–39455
Pal J, Ghosh S, Maji B, Bhattacharya DK (2018) Protein sequence comparison under a new complex representation of amino acids based on their physio-chemical properties. Int J Eng Technol 7:181–184
Oppenheim AV, Buck JR, Schafer RW (2001) Discrete-time signal processing, vol 2. Prentice Hall, Upper Saddle River
Cooley JW, Tukey OW (1965) An algorithm for the machine calculation of complex Fourier series. Math Comput 19:297–301
Yu ZG, Anh V, Lau KS (2004) Chaos game representation of protein sequences based on the detailed HP model and their multifractal and correlation analyses. J Theor Biol 226(3):341–348
Yau SST, Wang J, Niknejad A, Lu C, Jin N, Ho YK (2003) DNA sequence representation without degeneracy. Nucleic Acids Res 31(12):3078–3080
Tamura K, Stecher G, Kumar S (2021) MEGA11: molecular evolutionary genetics analysis version 11. Mol Biol Evol 38(7):3022–3027
King BR, Aburdene M, Thompson A, Warres Z (2014) Application of discrete Fourier inter-coefficient difference for assessing genetic sequence similarity. EURASIP J Bioinform Syst Biol 2014(1):1–12
Aamir KM, Maud MA, Loan A (2005) On Cooley-Tukey FFT method for zero padded signals. In: Proceedings of the IEEE symposium on emerging technologies, 2005 (pp 41–45). IEEE.
Felsenstein J (2004) PHYLIP (phylogeny inference package) version 3.6. Distributed by the author. http://www.evolution.gs.washington.edu/phylip.Html.
Yao YH, Kong F, Dai Q, He PA (2013) A sequence-segmented method applied to the similarity analysis of long protein sequence. Commun Math Comput Chem 70(1):431–450
Yao Y, Yan S, Xu H, Han J, Nan X, He PA, Dai Q (2014) Similarity/dissimilarity analysis of protein sequences based on a new spectrum-like graphical representation. Evol Bioinform 10:EBO-S14713
Yu L, Zhang Y, Gutman I, Shi Y, Dehmer M (2017) Protein sequence comparison based on physicochemical properties and the position-feature energy matrix. Sci Rep 7(1):1–9
Funding
We wish to confirm that there has been no financial support for this work that could have influenced its outcome.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by JP, SG, BM. The first draft of the manuscript was written by DKB and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Consent to Participate
Not applicable.
Consent to Publish
Not applicable.
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Pal, J., Ghosh, S., Maji, B. et al. Use of 2D FFT and DTW in Protein Sequence Comparison. Protein J 43, 1–11 (2024). https://doi.org/10.1007/s10930-023-10160-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10930-023-10160-2