
Abstract
The aim of the presented review is to summarize the literature data on the accuracy and clinical applicability of artificial intelligence (AI) models as a valuable alternative to the current guidelines in predicting cardiac resynchronization therapy (CRT) response and phenotyping of patients eligible for CRT implantation. This systematic review was performed according to the PRISMA guidelines. After a search of Scopus, PubMed, Cochrane Library, and Embase databases, 675 records were identified. Twenty supervised (prediction of CRT response) and 9 unsupervised (clustering and phenotyping) AI models were analyzed qualitatively (22 studies, 14,258 patients). Fifty-five percent of AI models were based on retrospective studies. Unsupervised AI models were able to identify clusters of patients with significantly different rates of primary outcome events (death, heart failure event). In comparison to the guideline-based CRT response prediction accuracy of 70%, supervised AI models trained on cohorts with > 100 patients achieved up to 85% accuracy and an AUC of 0.86 in their prediction of response to CRT for echocardiographic and clinical outcomes, respectively. AI models seem to be an accurate and clinically applicable tool in phenotyping of patients eligible for CRT implantation and predicting potential responders. In the future, AI may help to increase CRT response rates to over 80% and improve clinical decision-making and prognosis of the patients, including reduction of mortality rates. However, these findings must be validated in randomized controlled trials.
Similar content being viewed by others


Introduction
Cardiac resynchronization therapy (CRT) is one of the core treatment methods in chronic heart failure (HF) with reduced left ventricular ejection fraction (LVEF) and a wide QRS complex [1, 2]. According to the 2021 European Society of Cardiology (ESC) guidelines on HF, CRT-Pacemaker/CRT-Defibrillator should be considered for symptomatic patients with HF in sinus rhythm (SR) with a QRS duration (QRSd) ≥ 130 ms (ms) due to left bundle branch block (LBBB) or QRSd ≥ 150 ms if non-LBBB QRS morphology is present and with LVEF ≤ 35% despite optimal medical therapy (OMT) [2]. Clinical outcomes including death or HF hospitalization as well as improvements in the most important echocardiographic parameters, e.g., 6-month reduction in LVESV, have been proposed as outcomes relevant to CRT response [3, 4]. A reduction in morbidity and mortality as well as improvement in cardiac function with an enhancement of quality of life is observed after CRT implantation [1, 2].
Despite relatively clear guidelines, data from the literature report that about 30% of patients who meet eligibility criteria do not respond to CRT treatment [5,6,7,8,9,10,11] and identification of the phenotype of an “ideal” CRT responder remains a challenge [2, 12]. Thus, research on accurate prediction of CRT response continues. In addition to electrocardiographic and echocardiographic assessments, advanced computed tomography and magnetic resonance imaging studies are used to predict desired CRT outcomes [13]. Moreover, researchers try to combine several types of data to find new factors predicting positive CRT outcomes [14].
A novel advancement in clinical outcome prediction may result from the use of state-of-the-art statistical modeling, including artificial intelligence (AI) models [15, 16]. It was found that AI can be as good as, or sometimes even better than, health-care professionals in classifying diseases using medical imaging [17]. Moreover, AI can blend, analyze, and interpret a very sophisticated and broad range of different data types that are too complex for human-based analyses [18,19,20,21,22,23].
Therefore, training of complex AI algorithms seems to be a valuable solution to the task of accurate prediction of CRT response. In comparison with traditional statistics (descriptive statistics, statistical hypothesis testing with the use of p value), which describe trends and statistical significance based on the results for a group of patients, supervised AI models (S-AI model) can be used to predict CRT response for a single patient, providing a good basis for a personalized assessment of eligibility for CRT [24]. On the other hand, unsupervised AI models (U-AI model) can identify clusters of patients with homogenous clinical characteristics, including similar CRT outcome, which can reveal the phenotype of a CRT responder [25]. Recently, several studies that aim to utilize U-AI models in phenotyping of CRT respondents as well as S-AI models to predict the outcome of CRT have been published [4, 15, 16, 24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48]. Since this research area develops rapidly and AI has proven to be effective in various clinical settings [17], it is of value to summarize the body of evidence on CRT response prediction with the use of AI.
Aim
The aim of the presented review is to summarize the literature data regarding the accuracy and clinical applicability of AI models as a valuable alternative to the current guidelines in predicting CRT response and phenotyping of patients eligible for CRT implantation.
For U-AI models, the ability of accurate clustering of CRT (non-)respondents is evaluated. For S-AI models, the accuracy of the patient selection that will benefit from CRT in the future is assessed. Prospective primary outcome events are used as reference standards.
Methods
Evidence acquisition
Literature search
This systematic review was performed in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 statement [49]. Scopus, PubMed, Cochrane Library, and Embase databases were searched for relevant articles (Fig. 1).

Preferred Reporting Items for Systematic Reviews and Meta-Analyses flowchart. AI—artificial intelligence; PICO—patients, intervention, comparison, outcome
Two separate database searches by WN and KN were conducted to identify studies eligible for the systematic review. The last search was performed on 31st May 2023. The basic search query was as follows: “(cardiac resynchronisation therapy OR dyssynchrony) AND (ecg OR electrocardiography OR electrocardiogram OR echocardiography OR cardiac ultrasound OR echocardiogram OR computed tomography OR ct OR magnetic resonanse imaging OR mri OR Single-photon emission computed tomography OR spect) AND (machine learning OR ai OR artificial intelligence OR machine intelligence OR k-means OR random forest OR gradient boost OR support vector machines OR decision tree OR lstm OR long short term network OR encoder OR decoder OR tensorflow OR pytorch OR keras OR classification algorithm OR supervised learning OR unsupervised learning OR clustering OR deep learning OR deep neural network OR cnn OR convolutional neural network OR computer vision OR rnn OR recurrent neural network)”.
The following keywords were chosen as they describe the studied intervention (CRT, group 1), the diagnostic approaches used to qualify the patients for the intervention (electrocardiography and echocardiography, group 2), and the use of AI in the study (group 3). The keywords in the groups were connected with the operator “OR” and the groups of keywords were separated with the operator “AND” to find articles eligible for the review.
Full search strategy for each database is available in Supplementary Material S1.
The preliminary search returned a total of 675 articles. Duplicates were removed. After title and abstract screening, 93 studies were selected for full-text analysis. Articles were excluded due to the following reasons: article did not meet the PICO criteria (46), study description was not a full-text original article (19), and cohort < 100 patients (6). A total of 22 studies were thus included in the review.
Selection of AI models
In each study, a maximum of one binary clinical outcome and one binary echocardiographic endpoint of CRT response were identified. Further on, for each binary outcome, a maximum of one supervised and one unsupervised algorithm were identified. Only the best “AI model-primary outcome” pairs were incorporated in the review.
A S-AI model was represented by any machine learning algorithm that was used for supervised classification of patients who will and will not benefit from CRT implantation. An U-AI model was defined as any clustering algorithm that was used for unsupervised phenotyping of CRT responders. Moreover, according to the definition of “artificial intelligence,” the algorithm must have been able to analyze and draw inferences from patterns in data without direct instructions on how to perform it [50]. If an AI model was not described in the article, the study was not included in this review.
For S-AI models, the best AI model for the prediction of a given primary outcome was the AI model with the best overall accuracy score or the AI model chosen and recommended by the authors of the study. For U-AI models, the best AI model was the AI model with the best discrimination power to distinguish between the identified clusters of patients or the AI model chosen and recommended by the authors of the study.
A deep learning algorithm was defined as a prediction model that consists of multiple stacked layers and uses data to capture hierarchical levels of abstraction [51].
Data extraction
Only the best AI model-primary outcome analyses were taken into consideration.
The following information was extracted for each analyzed AI model: 1st author, date of publication, objective, study design, number of patients, mean age of patients, percentage of males, percentage of patients with LBBB, percentage of patients with ischemic cardiomyopathy (ICM), inclusion and exclusion criteria, definition of the primary outcome, rate of primary outcome events, type of the best performing algorithm, pre- and post-implantation data used to train the AI model (demographic, clinical, laboratory, medications, echocardiography, electrocardiography, computed tomography, magnetic resonance imaging, ergospirometry, text, genetic, post-lead position, post-intracardiac electrocardiography, post-electrocardiography), number of input features, other algorithms tested, and the method used to handle missing values.
Additionally, for S-AI models, measures of the performance of the best algorithm (accuracy, specificity, sensitivity etc.) and the most predictive variables were extracted. Furthermore, availability of the AI model online was checked. For U-AI models, additional information included the number of clusters identified by the AI model, the results of phenotyping, and the factors associated with CRT response.
If specific information was not obtainable in the original manuscript, it was described as Not Reported (NR). In some cases, the overall efficacy of prediction was reported as the area under the receiver operating characteristic curve (AUC), sometimes as accuracy, sometimes both metrics were available. All of them were always extracted, and each of them was used in an independent statistical analysis.
PICO question
A PICO-styled research question was formulated to identify studies eligible for the analysis. Respectively, for studies describing AI models based on supervised algorithms:
-
1.
Patients: patients who received CRT-D or CRT-P
-
2.
Intervention (index test): prediction of response to CRT with the use of AI model
-
3.
Comparison: response to CRT defined by the primary outcome (e.g., death, HF hospitalization, LVEF improvement)
-
4.
Outcome: accuracy/AUC of the CRT response prediction capabilities of the AI model
For studies describing AI models based on unsupervised algorithms (clustering and phenotyping of CRT patients), the following PICO was formed:
-
1.
Patients: patients who received CRT-D or CRT-P
-
2.
Intervention: a group of patients with the highest/lowest proportion of CRT responders
-
3.
Comparison: proportion of CRT responders in other group(s) revealed by the phenotyping
-
4.
Outcome: comparison of the proportion of CRT responders between the identified clusters of patients
Evidence synthesis
All studies meeting the eligibility criteria are summarized in Tables 1 and 2. Additional data are available in the Supplementary Tables S2 and S3. To analyze and compare findings across the studies, counts, percentages, median values, and range were used. Due to large differences in patient inclusion/exclusion criteria as well as various primary outcome definitions across the reviewed studies, a quantitative synthesis of the results (meta-analysis) was not possible.
Quality assessment
The risk of bias (ROB) of included studies was performed by the first author of the study (WN). It was assessed according to the Prediction model Risk Of Bias ASsessment Tool (PROBAST) [52].
ROB was assessed in the following 4 domains: participants, predictors, outcome, and analysis. A total of 20 signaling questions were used to facilitate a structured assessment of the ROB, which was defined as occurring when shortcomings in study design, conduct, or analysis lead to systematically distorted estimates of a given model’s predictive performance. The first three domains were also used for applicability assessment. Last but not least, an overall assessment of the ROB and applicability of the prediction model was completed. A “ + ” indicates low ROB/low concern regarding applicability; “ − ” indicates high ROB/high concern regarding applicability; and “?” indicates unclear ROB/unclear concern regarding applicability [52]. For each eligible study, a total of 9 analyses (+ / − /? assessments) were conducted. In this review, if any domain of ROB or applicability assessment was rated as high/unclear ROB, the “overall ROB”/ “overall applicability” domains were also rated as high or unclear ROB. Since S-AI models aim at the prediction of response to CRT, only these AI models were analyzed with the use of the PROBAST. A detailed table is available in the Supplementary Material S1.
Results
General characteristics
This review included a total of 22 studies, which reported 29 separate AI model-primary outcome analyses with a total of 14,258 patients (Fig. 1). There were 20 S-AI models and 9 U-AI models (N = 11,743 and N = 2917 patients, respectively). These were further divided into echocardiography outcome-based and clinical outcome-based U-AI models as well as into echocardiography outcome-based and clinical outcome-based S-AI models (Tables 1, 2, and 3, Supplementary Tables S2, S3, and S4). The majority of studies included in our analysis have been published during the last three years.
Most of the AI models were based on data collected in retrospective cohort studies (N = 16, 55%), followed by prospective cohort studies (N = 8, 28%), randomized controlled trials (RCTs, N = 5, 17%), and case–control studies (N = 1, 3%). Each AI model was trained and validated on a median number of 328 patients (range 117–1668) with a median age of 67 years (range 60–72). The median rate of primary outcome events was 47% (range 15–78%). The median percentage of male patients across the analyzed AI models was 68% (range 50–87%).
The most frequent inclusion criteria included QRSd ≥ 120 ms, NYHA class, and reduced LVEF ≤ 35%. The most frequently reported primary endpoints included death, a decrease in LV end-systolic volume (LVESV), a LVEF improvement, and an occurrence of an HF event. Thirty-three percent of the AI models were based on a composite outcome.
The majority of AI models were trained with a non-deep learning algorithm. The median number of types of input data the AI models were trained on was 5 (range 1–7), and input features, 20 (range 2–487). The most often used types of input features were pre-implantation features such as echocardiographic parameters, followed by clinical data, demographic characteristics, and electrocardiographic data. Most of the AI models did not have any post-implantation input data.
Unsupervised AI models
A total of 3 echocardiographic outcome-based unsupervised AI models (EU-AI models) and 6 clinical outcome-based unsupervised AI models (CU-AI models) were included in the review (771/2917 patients, respectively; Tables 1, and 3, Supplementary Tables S2 and S4). The median number of patients for EU-AI models was 250 (range 193–328) and 289 (range 193–1106) for CU-AI models. The median rate of primary outcome events was 68% (range 65–74%) and 22% (range 15–78%), respectively. The median number of clusters identified by EU-AI models was equal to 4 (range 2–5) and 3 (range 2–5) for CU-AI models. The most used input data for U-AI models were echocardiographic, clinical, laboratory, and demographic characteristics. Almost all U-AI models came from retrospective and prospective cohort studies. The median number of input features used to train an EU-AI model was equal to 55 (range 28–70) and 39 (range 3–70) to train a CU-AI model. The median number of input data types, 5, was the same for EU- and CU-AI models.
Most commonly, the patients were qualified for CRT implantation based on wide QRSd of ≥ 120 ms, NYHA class, and reduced LVEF of ≤ 35%. The most frequently reported primary outcome measures were death, HF event, and a decrease in LVESV. Forty-four percent of the AI models had a composite primary endpoint. The clustering of CRT patients was mostly based on k-means clustering or k-medoid algorithms. Independent of the primary outcome as well as the number of clusters identified by the U-AI models, statistically significant differences in the rate of primary outcome events across the observed clusters were observed in each study.
Various clinical, echocardiographic, and electrocardiographic variables were associated with more favorable outcomes (Fig. 2). However, in one study, LVEF and QRSd were not related to more positive outcomes.

Input variables predictive of CRT response. AI—artificial intelligence; CRT—cardiac resynchronization therapy; ESC—European Society of Cardiology; ECG—electrocardiography; HF—heart failure; LBBB—left bundle branch block; LV—left ventricle; non-ICM—non-ischemic cardiomyopathy; NT-proBNP—N-terminal pro–brain-type natriuretic peptide; PCI—percutaneous coronary intervention; peak VO2—maximal oxygen consumption; QRSd—QRS duration; RV—right ventricle
Supervised AI models
A total of 11 echocardiographic outcome-based supervised AI models (ES-AI models) and 9 clinical outcome-based supervised AI models (CS-AI models) were included in our review (6335/6413 patients, respectively; Tables 2, and 3, Supplementary Tables S3 and S4). The median number of patients for ES-AI models was 419 (range 130–1664) and 741 (range 117–1510) for CS-AI models. The median primary outcome reach was 51% (range 42–69%) and 32% (range 15–73%), respectively. In all described studies, always two groups of patients (responders/non-responders) were identified.
The median accuracy of ES-AI models and CS-AI models was equal to 78% (range 63–85%) and 75% (65–85%), respectively. The ES-AI models and CS-AI models achieved median AUCs of 0.76 (range 0.69–0.81) and 0.75 (range 0.69–0.86), respectively. Schmitz et al. created the best ES-AI model (85% accuracy, PART algorithm). In the group of CS-AI models, Bivona et al. proposed the best algorithm (AUC of 0.86, logistic regression algorithm). As many as 80% of all S-AI models achieved ≥ 70% accuracy/AUC ≥ 0.70 and 40% of S-AI models achieved ≥ 80% accuracy/AUC of ≥ 0.80.
Echocardiographic, clinical, demographic, and electrocardiographic characteristics made for the most commonly used input data for S-AI models. The majority of the S-AI models were based on data collected in retrospective cohort studies, followed by prospective cohort studies and RCTs. The median number of input features used to train an ES-AI model was equal to 16 (range 2–487) and 15 (range 3–45) to train a CS-AI model. The median number of input data types, 5, was the same for ES- and CS-AI models.
Inclusion criteria varied across the analyzed studies, but most of them qualified patients based on wide QRSd of ≥ 120 ms, NYHA class, and reduced LVEF of ≤ 35%. A decrease in LVESV and an absolute LVEF increase as well as death were the most frequently reported primary outcome measures, while 31% of the models had a composite outcome. Majority of algorithms used to create CRT prediction models were non-deep learning algorithms (85%), e.g., support vector machines or random forest algorithms.
Similar to the U-AI models, in S-AI models various clinical, echocardiographic, electrocardiographic, and laboratory characteristics were identified as the most predictive variables in the classification of CRT responders and non-responders (Fig. 2).
Almost all algorithms were validated internally, most commonly with the use of the tenfold or fivefold cross-validation protocol. Six studies (30%) were evaluated using an additional internal hold-out test dataset.
A total of 11 S-AI models are available online. The most accurate publicly available ES-AI model and CS-AI model were reported by Schmitz et al. (85% accuracy, > 100 patients) and Bivona et al. (AUC of 0.86, based on > 100 patients), respectively.
A total of 11 S-AI models (61%) had low overall ROB whereas 13 S-AI models (72%) had a low overall concern regarding applicability (Fig. 3). Unclear ROB in the domain “ROB participants” and “applicability participants” was allocated due to an unclear description of inclusion/exclusion criteria. Three S-AI models were rated as “unclear ROB” in the domain “ROB analysis” due to the absence of an explanation of how missing data were handled.

Risk of bias assessment with the use of the PROBAST. AI—artificial intelligence; ROB—risk of bias
Discussion
General characteristics
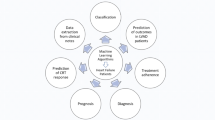
To the authors’ knowledge, this is the first comprehensive systematic review on the use of AI algorithms in CRT response prediction and phenotyping of patients qualified for CRT. Summarizing a total of 22 studies, involving 14,458 individuals, and describing 20 S-AI models as well as 9 U-AI models, this systematic review can provide a solid foundation for future research on the use of AI in CRT (Fig. 4).

Summary of key characteristics of analyzed artificial intelligence models. AI—artificial intelligence; AUC—area under the receiver operating characteristic curve; CRT—cardiac resynchronization therapy; QRSd—QRS duration; NYHA—New York Heart Association; HF—heart failure; LVEF—left ventricle ejection fraction; LVESV—left ventricle end-systolic volume
Most of the AI models described in this review included patients based on QRSd ≥ 120 ms, NYHA class, reduced LVEF ≤ 35%, and the condition of having an OMT prior to CRT implantation, which tends to be in line with the most recently published guidelines [1, 2]. The percentage of AI models based on retrospective and prospective studies was 55% and 45%, respectively. The populations included in this review were moderately homogenous, with the median age of 67 years old (range 60–72), the median proportion of male patients across the analyzed AI models of 68% (range 50–87%), and a wide variety of cohort sizes on which the AI models were trained (median number of patients = 328, range 117–1668). In addition, the use of a wide variety of echocardiographic and clinical outcomes that were based on different follow-up intervals resulted in a heterogenous rate of primary outcome events (median = 47%, range 15–78%).
Unsupervised AI models
Three EU-AI models and six CU-AI models met the eligibility criteria for this review. The patient inclusion criteria were homogenous (QRSd ≥ 120 ms, NYHA, reduced LVEF ≤ 35%, OMT), as most of the studies were based on the official guidelines [53]. Interestingly, even though a wide range of clusters of patients across the reviewed U-AI models was identified (median N of clusters = 4, range 2–5), which were based on various numbers of input features (median = 50, range 3–70), different numbers of patients were used to train the AI models (median = 250, range 193–1106) and a divergent rate of primary outcome events, especially for CU-AI models (median = 22%, range 15–78%), each of the U-AI models was able to separate clusters of patients with a significantly better prognosis than the rest of identified groups of patients. Therefore, it seems that nowadays available U-AI models can accurately extract phenotypes of patients with worse response to CRT independently of the input data.
Supervised AI models
Eighteen ES-AI models and nine CS-AI models were included in the review. Only about 80% of the analyzed studies included a direct description of the key guideline-recommended CRT inclusion criteria [1, 2, 53] (wide QRSd, NYHA class, reduced LVEF), increasing the potential ROB and rising applicability concerns. Similar to the U-AI models, even though the S-AI models were based on various types of input variables (median = 5, range 1–7), different numbers of input features (median = 16, range 2–487) and cohort sizes (median = 580, 130–1664) had a large discrepancy primary outcome event rate (median = 48%, range 15–73%), as many as 80% of them had ≥ 70% accuracy/AUC of ≥ 0.70, and 40% of them were able to achieve ≥ 80% accuracy/AUC of ≥ 0.80 in the prediction of response to CRT. Schmitz et al. [39] created the best ES-AI model (85% accuracy), while Bivona et al. [26] proposed the best CS-AI model (AUC of 0.86). Both algorithms are publicly available.
In two studies, a large number of input features (> 100) were used. Such a large number of input features were obtained by combining demographic, clinical, laboratory, medication, echocardiographic, and electrocardiographic data (487 features in total) [4]. On the other hand, Gallard et al. derived additional input data (311 features in total) with the use of advanced mathematical computations. However, in the end, only the 14 most important characteristics were selected to train the final model [16].
Clinical adoption of supervised AI models
To be clinically applicable, an S-AI model should require simple, routinely collected input data and have high performance. Moreover, the algorithm should be trained on a large, prospectively observed cohort and predict a valuable primary endpoint.
Schmitz et al. [39] and Bivona et al. [26] proposed AI models with the best performance (85% accuracy and 0.86 AUC, respectively). Increasing the CRT prediction accuracy from recommendation-based 70% to AI-based 85% would halve the number of potential non-responders and lead to a significantly higher clinical and economic effectiveness of CRT. However, these AI models are based on highly sophisticated mathematical computations and genetic analyses and require not routinely measured pre- and post-implantation data (e.g., peak VO2 before and 6 months after CRT implantation).
Relatively high-performing AI models trained on routinely collected data (demographic, clinical, echocardiographic, and electrocardiographic parameters) were proposed by Galli et al. [30] (AUC of 0.84 and 0.81), Tokodi et al. [41] (AUC of 0.80), and Howell et al. [31] (AUC of 0.76), but only the last two are publicly available. Moreover, presented S-AI models performed significantly better in CRT response classification than the official guidelines or many other previously created CRT response scores that were not based on AI algorithms [31, 35, 41, 43].
Cai et al. have proven that the increase in input data types improves the performance [4]. However, the relationships are not linear and hard to predict. For example, when guideline-based parameters are enriched with medication, echocardiographic, and demographic data, the AUC increases from 0.56 to 0.69, but further addition of laboratory parameters boosts the AUC to just 0.70 (+ 0.01). On the contrary, when clinical as well as experimental ECG parameters are added, the AUC increases from 0.70 to 0.73 and 0.76, respectively.
Interestingly, Wouters et al. propose a high-performance single-modality ECG-based model [43] (AUC 0.69, trained on 1306 patients). Performing better than the official guideline criteria and requiring just one modality of routinely collected data, it shows a promising perspective for a clinical implementation of models that are both time-effective in terms of data collection and accurate when it comes to CRT response prediction. The model is publicly available [43]. Moreover, when additional clinical data were added to the raw ECG model, the authors notice an increase in performance of only 4.3% (from 0.69 to 0.72). Therefore, this model sacrifices a small decrease in performance for a large boost in potential clinical applicability and proves the concept of “simple input and high-performance AI”.
The role of ECG in AI-based predictions
According to the most recent guidelines, wide QRSd is a primary characteristic associated with higher response rates after CRT implantation [1]. Pre- and post-implantation electrocardiographic data were used in 59% (n = 17) and 6% (n = 2) of AI models, respectively. So far, the most clinically applicable supervised AI model in CRT response prediction is the one proposed by Wouters et al. (AUC 0.69, publicly available) [43]. It utilizes raw 12-lead ECG signal processing with the use of deep learning. Interestingly, raw ECG signal can also be used in unsupervised phenotyping of patients and accurately classify groups of patients with significantly different survival probabilities [25]. Thus, AI is able to extract and process raw information without preprocessing.
Nevertheless, in the vast majority of cases, preprocessed data of proven clinical relevance (presence of LBBB, QRSd, QTc duration, etc.) were used as input data. They were used by the most accurate algorithms and were proved to be among the most relevant features in CRT response prediction (Tokodi et al. AUC 0.80 [41], Cai et al. AUC 0.76 [4]).
Challenging subgroups of CRT recipients
It is well known that one of the most challenging phenotypes of commonly qualified patients is a male with non-LBBB, ICM, and QRSd < 150 ms [1]. To date, there is no study that describes a supervised AI model (CRT response prediction) for the “challenging” subgroups. However, supervised algorithms revealed previously mentioned characteristics to be negatively correlated with CRT response [30, 41, 44]. Moreover, unsupervised algorithms demonstrated that groups of patients associated with this phenotype have significantly worse survival and/or CRT response rates [15, 30, 38]. A detailed description of features predictive for CRT outcome is available in the next section.
Features predictive for CRT outcome
According to the 2021 ESC guidelines, symptomatic patients with HF in SR, wide QRSd, and reduced LVEF ≤ 35% despite OMT are eligible for a CRT [1, 2]. Moreover, several additional factors including more extensive reverse remodeling of the myocardium, non-ischemic etiology of HF, absence of myocardial scar tissue, female sex, longer QRSd, presence of septal flash, and/or apical rocking in an echocardiographic study as well as lead placement outside of a scarred myocardium are predictive for a favorable CRT response [1, 2].
Based on the identified clusters of CRT patients, most commonly the presence of LBBB, longer QRSd, non-ischemic cardiomyopathy, and smaller dilatation as well as better LV and RV functions were associated with more favorable outcomes (Fig. 2). In addition to that, many clinical, demographic, electrocardiographic, and echocardiographic characteristics identified by the supervised AI models were predictive for CRT response. This emphasizes the need for the adoption of a holistic approach to the problem of a CRT responder selection, which should include an evaluation of a wide range of cardiovascular disease risk factors. Moreover, identification of the same predictors of (non-)response to CRT by the AI models that are endorsed by the most recent guidelines validates the robustness and credibility of the use of AI in this field (Fig. 2).
Future directions
Since many AI algorithms can predict CRT response with over 80% accuracy, while guideline-based CRT predictions report about 70% of overall accuracy, it would be beneficial to conduct an RCT to prove the potential superiority of AI algorithms over the official guidelines. Without robust, prospective validation in a real-world clinical setting, algorithm’s safety and readiness for implementation in patient care remain unknown [19]. A double-blind two-arm RCT is recommended (control group: patients are selected according the recent guidelines on CRT; experimental group: patients are selected according the classification outcome of the AI-model; primary endpoint: (non-)response to CRT defined by death/HF hospitalization/no improvement in LVEF) [54]. Such approach minimizes potential bias and rigorously examines cause-effect relationships between an intervention and outcome [54].
There is also some indication that AI models can achieve over 90% accuracy [27, 36], but the studies so far have been based on small groups of patients and the reliability of the proposed S-AI models must be validated on larger cohorts. In addition to that, only three AI models used deep learning for CRT response prediction while all the other AI models were based on non-deep learning AI algorithms. As deep learning has changed the landscape of many challenges in computer vision, e.g., image classification [55], it is possible that such methods could result in a boost in performance in the field of CRT response prediction, too. Moreover, many of the best-performing algorithms are based on highly sophisticated imaging techniques generating a lot of data that are not routinely performed and collected for each patient [26, 39].
In general, electrocardiography is considered weaker in terms of clinical relevance which influenced the class of this recommendation in the latest guidelines [1]. Interestingly, although raw electrocardiographic signal was rarely analyzed using machine learning, it shows considerable promise in CRT response prediction [25].
Research on highly accurate (≥ 90%) AI models trained on a large number of input data is highly desirable. This will lead to more robust models that will have higher chances of being generalizable to other cohorts. On the other hand, research on models requiring a small amount of routinely collected data (demographic, clinical, electrocardiographic, and echocardiographic) is also needed. It would be probably less accurate than the more advanced models based on, for example, genetic information [39], but it would be useful in preliminary screening for patients probably eligible for CRT and for qualification for additional diagnostic procedures required by more sophisticated AI models to make the final decision on CRT implantation. Moreover, just 11 out of 20 analyzed S-AI models were shared publicly and free of charge. Thus, the accessibility of AI models should be improved, too.
According to the current state of knowledge and data provided by the literature, the importance of many clinical characteristics (for example, post-implantation lead location, type of input data used) that could theoretically improve the accuracy of CRT response prediction remains unclear and requires future investigation. Apart from the AI algorithm training and validation, the algorithm’s clinical applicability and performance depend on many aspects like inclusion/exclusion criteria or cohort size. Thus, it remains a complex and yet unsolved matter.
Finally, due to the large variety of reviewed studies (various inclusion/exclusion criteria, outcome measures, size of cohorts, types of AI models used, etc.) as well as inconsistency in the reporting, it is not possible to provide any robust recommendations for future AI research in CRT response prediction. Reviewed studies lay the cornerstone for the high-performance, data-driven medicine of the future. We are looking forward to the synergy of machine-aided data analysis and human-driven interpretation of the outcomes.
Limitations
It is worth mentioning that information about the guideline-recommended inclusion criteria [1, 2] (wide QRSd, NYHA class II–IV, reduced LVEF, OMT) was not available for about 20 to 30% of analyzed AI models. For example, a few authors reported that patients eligible for the development of an AI model were qualified based just on “CRT implantation” [4, 24, 40, 41] or “CRT implantation and QRSd ≥ 120 ms” [35] which is a very broad term, encompassing not only patients with dyssynchrony but also other conditions such as sinus node dysfunction or atrioventricular blocks [1]. This issue reduced the quality of evidence synthesis, increased potential ROB, raised applicability concerns, and should be avoided in future manuscripts. In addition to that, some studies have been based on small groups of patients [27, 33, 36, 37]. Thus, although their reported accuracy may be high, such models tend to overfit data owing too small sample sizes which reduces its generalization capabilities and their potential applicability in clinical setting [19]. Almost all algorithms were evaluated using internal validation methods, most commonly with the use of the tenfold or fivefold cross-validation protocol. Only four studies used additional internal hold-out test dataset [4, 31, 32, 40]. In addition to that, only one AI algorithm was validated externally [42], which raises concerns about the potential validity of AI in real-world clinical environments [19].
Moreover, due to large variety of the studied cohorts (mean age, share of male sex, number of included patients), as well as due to the aforementioned incompleteness of information regarding the investigated cohorts, it was not possible to perform a robust meta-analysis of the reviewed studies. Furthermore, reporting of data on multiple outcomes with different measures and follow-up durations makes direct comparison of the studies problematic, creates opportunities for “cherry-picking” of the primary endpoints, and reduces applicability of the results in clinical practice [56].
In addition to that, sometimes only scarce data on the prediction quality were available (AUC or accuracy without corresponding sensitivity and specificity of the AI model). Thus, some studies were analyzed based on just one of the metrics and direct comparisons of the results were not possible. Moreover, accuracy and reliability of machine learning models are highly dependent on the quality as well as the completeness of both the training and validation data used [57]. To directly compare the performance of different AI models as well as to compare their performance with the accuracy of recommendation-based CRT response rates, one would need to train and evaluate them on exactly the same data.
Finally, many algorithms, especially the state-of-the-art deep learning models, are “black box algorithms” and the explainability of their prediction mechanisms remains unknown. As the determination of the output by the model is not transparent, it remains under debate if such algorithms should be implemented in the daily clinical practice [19].
Clinical implications
Unsupervised AI models were able to identify clusters of patients with significantly different rates of primary outcome events (death, heart failure event). In comparison to the guideline-based CRT response prediction accuracy of 70%, supervised AI models trained on cohorts with > 100 patients achieved up to 85% accuracy and AUC of 0.86 of CRT response prediction for echocardiographic and clinical outcomes, respectively. Thus, AI models seem to be a valuable tool in phenotyping of patients eligible for CRT implantation and predicting potential responders. However, these findings must be validated in RCTs. In addition to that, AI algorithms demonstrated that a holistic approach to the problem of CRT responder selection must be adopted, including evaluation of a wide range of cardiovascular disease risk factors. These findings must also be validated in RCTs. Moreover, forthcoming studies should be reported more thoroughly, to make it possible to perform more robust literature synthesis and meta-analysis.
Conclusion
AI models seem to be an accurate and clinically applicable tool in phenotyping of patients eligible for CRT implantation and predicting potential responders (Fig. 4). Synergy of machine-aided data analysis and human-driven interpretation of the results seems to be possible. In the future, AI may help to increase CRT response rates to over 80% and improve clinical decision-making and prognosis of the patients, including reduction of mortality rates. However, these hypotheses must be validated in randomized controlled trials.
References
Glikson M, Nielsen JC, Kronborg MB et al (2021) 2021 ESC guidelines on cardiac pacing and cardiac resynchronization therapy. Eur Heart J 42:3427–3520. https://doi.org/10.1093/eurheartj/ehab364
McDonagh TA, Metra M, Adamo M et al (2021) 2021 ESC guidelines for the diagnosis and treatment of acute and chronic heart failure. Eur Heart J 42:3599–3726. https://doi.org/10.1093/EURHEARTJ/EHAB368
Howell S, Stivland TM, Stein K et al (2021) Response to cardiac resynchronisation therapy in men and women: a secondary analysis of the SMART-AV randomised controlled trial. BMJ Open 11:3245–3279. https://doi.org/10.1136/BMJOPEN-2021-049017
Cai C, Tafti AP, Ngufor C et al (2021) Using ensemble of ensemble machine learning methods to predict outcomes of cardiac resynchronization. J Cardiovasc Electrophysiol 32:2504–2514. https://doi.org/10.1111/jce.15171
Zhu H, Zou T, Zhong Y et al (2020) Prevention of non-response to cardiac resynchronization therapy: points to remember. Heart Fail Rev 25:269. https://doi.org/10.1007/S10741-019-09834-W
Rao P, Faddis M (2017) Cardiac resynchronisation therapy: current indications, management and basic troubleshooting. Heart 103:2000–2007. https://doi.org/10.1136/HEARTJNL-2016-310656
Daubert C, Behar N, Martins RP et al (2017) Avoiding non-responders to cardiac resynchronization therapy: a practical guide. Eur Heart J 38:1463–1472. https://doi.org/10.1093/EURHEARTJ/EHW270
Morgan JM, Delgado V (2009) Lead positioning for cardiac resynchronization therapy: techniques and priorities. EP Europace 11(Suppl 5). https://doi.org/10.1093/EUROPACE/EUP306
Chen J, Bax JJ, Henneman MM et al (2008) Is nuclear imaging a viable alternative technique to assess dyssynchrony? EP Europace 10(Suppl 3). https://doi.org/10.1093/EUROPACE/EUN221
Pujol-López M, San Antonio R, Mont L et al (2019) Electrocardiographic optimization techniques in resynchronization therapy. EP Europace 21:1286–1296. https://doi.org/10.1093/EUROPACE/EUZ126
Varma N, Auricchio A, Connolly AT et al (2021) The cost of non-response to cardiac resynchronization therapy: characterizing heart failure events following cardiac resynchronization therapy. Europace 23:1586–1595. https://doi.org/10.1093/EUROPACE/EUAB123
Mullens W, Auricchio A, Martens P et al (2020) Optimized implementation of cardiac resynchronization therapy: a call for action for referral and optimization of care: a joint position statement from the Heart Failure Association (HFA), European Heart Rhythm Association (EHRA), and European Association of Cardiovascular Imaging (EACVI) of the European Society of Cardiology. Eur J Heart Fail 22:2349–2369. https://doi.org/10.1002/EJHF.2046
Rathi A, Kanee L, Limoges M et al (2022) Relationship between left ventricular strain assessment by cardiac magnetic resonance imaging and response to cardiac resynchronization therapy. J Thorac Imaging 37:W58–W59. https://doi.org/10.1097/RTI.0000000000000652
Maffessanti F, Jadczyk T, Wilczek J et al (2022) Electromechanical factors associated with favourable outcome in cardiac resynchronization therapy. EP Europace. https://doi.org/10.1093/EUROPACE/EUAC157
Cikes M, Sanchez-Martinez S, Claggett B et al (2019) Machine learning-based phenogrouping in heart failure to identify responders to cardiac resynchronization therapy. Eur J Heart Fail 21:74–85. https://doi.org/10.1002/ejhf.1333
Gallard A, Hubert A, Smiseth O et al (2020) Prediction of response to cardiac resynchronization therapy using a multi-feature learning method. Int J Cardiovasc Imaging 37:989–998. https://doi.org/10.1007/S10554-020-02083-1
Liu X, Faes L, Kale AU et al (2019) A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: a systematic review and meta-analysis. Lancet Digit Health 1:e271–e297. https://doi.org/10.1016/S2589-7500(19)30123-2/ATTACHMENT/49AB10F2-3AA4-4101-A155-11A5ED6772BC/MMC1.PDF
Ramesh AN, Kambhampati C, Monson JRT, Drew PJ (2004) Artificial intelligence in medicine. Ann R Coll Surg Engl 86:334–338. https://doi.org/10.1308/147870804290
Topol EJ (2019) High-performance medicine: the convergence of human and artificial intelligence. Nat Med 25:44–56. https://doi.org/10.1038/S41591-018-0300-7
Galmarini CM, Lucius M (2020) Artificial intelligence: a disruptive tool for a smarter medicine. Eur Rev Med Pharmacol Sci 24:7462–7474. https://doi.org/10.26355/EURREV_202007_21915
Lee S, Zhou J, Li K et al (2021) Brugada syndrome in Hong Kong: long term outcome prediction through machine learning. EP Europace 23. https://doi.org/10.1093/EUROPACE/EUAB116.494
Vamosi P, Tokodi M, Toth P et al (2022) A novel machine learning based algorithm to predict 1-year mortality after ventricular tachycardia ablation. EP Europace 24. https://doi.org/10.1093/EUROPACE/EUAC053.372
Barker J, Li X, Khavandi S et al (2022) Machine learning in sudden cardiac death risk prediction: a systematic review. EP Europace 24:1777–1787. https://doi.org/10.1093/EUROPACE/EUAC135
Feeny AK, Rickard J, Patel D et al (2019) Machine learning prediction of response to cardiac resynchronization therapy: improvement versus current guidelines. Circ Arrhythm Electrophysiol 12. https://doi.org/10.1161/CIRCEP.119.007316
Feeny AK, Rickard J, Trulock KM et al (2020) Machine learning of 12-lead QRS waveforms to identify cardiac resynchronization therapy patients with differential outcomes. Circ Arrhythm Electrophysiol 13:605–616. https://doi.org/10.1161/CIRCEP.119.008210
Bivona DJ, Tallavajhala S, Abdi M et al (2022) Machine learning for multidimensional response and survival after cardiac resynchronization therapy using features from cardiac magnetic resonance. Heart Rhythm O2. https://doi.org/10.1016/j.hroo.2022.06.005
Chao PK, Wang CL, Chan HL (2012) An intelligent classifier for prognosis of cardiac resynchronization therapy based on speckle-tracking echocardiograms. Artif Intell Med 54:181–188. https://doi.org/10.1016/j.artmed.2011.09.006
Field ME, Yu N, Wold N, Gold MR (2020) Comparison of measures of ventricular delay on cardiac resynchronization therapy response. Heart Rhythm 17:615–620. https://doi.org/10.1016/j.hrthm.2019.11.023
Gallard A, Bidaut A, Hubert A et al (2021) Characterization of responder profiles for cardiac resynchronization therapy through unsupervised clustering of clinical and strain data. J Am Soc Echocardiogr 34:483–493. https://doi.org/10.1016/j.echo.2021.01.019
Galli E, Le Rolle V, Smiseth OA et al (2021) Importance of systematic right ventricular assessment in cardiac resynchronization therapy candidates: a machine learning approach. J Am Soc Echocardiogr 34:494–502. https://doi.org/10.1016/j.echo.2020.12.025
Howell SJ, Stivland T, Stein K et al (2021) Using machine-learning for prediction of the response to cardiac resynchronization therapy: the SMART-AV study. JACC Clin Electrophysiol 7:1505–1515. https://doi.org/10.1016/j.jacep.2021.06.009
Kalscheur MM, Kipp RT, Tattersall MC et al (2018) Machine learning algorithm predicts cardiac resynchronization therapy outcomes: lessons from the COMPANION trial. Circ Arrhythm Electrophysiol 11. https://doi.org/10.1161/CIRCEP.117.005499
Khamzin S, Dokuchaev A, Bazhutina A et al (2021) Machine learning prediction of cardiac resynchronisation therapy response from combination of clinical and model-driven data. Front Physiol 12. https://doi.org/10.3389/fphys.2021.753282
Lei J, Wang YG, Bhatta L et al (2019) Ventricular geometry–regularized QRSd predicts cardiac resynchronization therapy response: machine learning from crosstalk between electrocardiography and echocardiography. Int J Cardiovasc Imaging 35:1221–1229. https://doi.org/10.1007/s10554-019-01545-5
Liang Y, Ding R, Wang J et al (2021) Prediction of response after cardiac resynchronization therapy with machine learning. Int J Cardiol 344:120–126. https://doi.org/10.1016/j.ijcard.2021.09.049
Peressutti D, Sinclair M, Bai W et al (2017) A framework for combining a motion atlas with non-motion information to learn clinically useful biomarkers: application to cardiac resynchronisation therapy response prediction. Med Image Anal 35:669–684. https://doi.org/10.1016/j.media.2016.10.002
Puyol-Antón E, Sidhu BS, Gould J et al (2022) A multimodal deep learning model for cardiac resynchronisation therapy response prediction. Med Image Anal 79. https://doi.org/10.1016/j.media.2022.102465
Riolet C, Menet A, Verdun S et al (2021) Clinical and prognostic implications of phenomapping in patients with heart failure receiving cardiac resynchronization therapy. Arch Cardiovasc Dis 114:197–210. https://doi.org/10.1016/j.acvd.2020.07.004
Schmitz B, De Maria R, Gatsios D et al (2014) Identification of genetic markers for treatment success in heart failure patients: insight from cardiac resynchronization therapy. Circ Cardiovasc Genet 7:760–770. https://doi.org/10.1161/CIRCGENETICS.113.000384
Hu SY, Santus E, Forsyth AW et al (2019) Can machine learning improve patient selection for cardiac resynchronization therapy? PLoS One 14. https://doi.org/10.1371/journal.pone.0222397
Tokodi M, Schwertner WR, Kovács A et al (2020) Machine learning-based mortality prediction of patients undergoing cardiac resynchronization therapy: the SEMMELWEIS-CRT score. Eur Heart J 41:1747–1756. https://doi.org/10.1093/eurheartj/ehz902
He Z, Zhang X, Zhao C et al (2023) A method using deep learning to discover new predictors from left-ventricular mechanical dyssynchrony for CRT response. J Nucl Cardiol 30:201–213. https://doi.org/10.1007/s12350-022-03067-5
Wouters PC, van de Leur RR, Vessies MB et al (2023) Electrocardiogram-based deep learning improves outcome prediction following cardiac resynchronization therapy. Eur Heart J 44:680–692. https://doi.org/10.1093/eurheartj/ehac617
de A. Fernandes F, Larsen K, He Z et al (2023) A machine learning method integrating ECG and gated SPECT for cardiac resynchronization therapy decision support. Eur J Nucl Med Mol Imaging. https://doi.org/10.1007/s00259-023-06259-4
Lalonde M, Wells RG, Birnie D et al (2014) Development and optimization of SPECT gated blood pool cluster analysis for the prediction of CRT outcome. Med Phys 41. https://doi.org/10.1118/1.4883881
Haque A, Stubbs D, Hubig NC et al (2022) Interpretable machine learning predicts cardiac resynchronization therapy responses from personalized biochemical and biomechanical features. BMC Med Inform Decis Mak 22. https://doi.org/10.1186/s12911-022-02015-0
Hong JA, Lee SE, Kim SO et al (2022) Determinants of left ventricular function improvement for cardiac resynchronization therapy candidates. ESC Heart Fail 9:283–292. https://doi.org/10.1002/ehf2.13765
Manohar A, Colvert GM, Yang J et al (2022) Prediction of cardiac resynchronization therapy response using a lead placement score derived from 4-dimensional computed tomography. Circ Cardiovasc Imaging 15:E014165. https://doi.org/10.1161/CIRCIMAGING.122.014165
Page MJ, McKenzie JE, Bossuyt PM et al (2021) The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ 372. https://doi.org/10.1136/BMJ.N71
Wagner MW, Namdar K, Biswas A et al (2021) Radiomics, machine learning, and artificial intelligence—what the neuroradiologist needs to know. Neuroradiology 63:1957. https://doi.org/10.1007/S00234-021-02813-9
Bizopoulos P, Koutsouris D (2019) Deep learning in cardiology. IEEE Rev Biomed Eng 12:168–193. https://doi.org/10.1109/RBME.2018.2885714
Wolff RF, Moons KGM, Riley RD et al (2019) PROBAST: a tool to assess the risk of bias and applicability of prediction model studies. Ann Intern Med 170:51–58. https://doi.org/10.7326/M18-1376
Brignole M, Auricchio A, Baron-Esquivias G et al (2013) 2013 ESC guidelines on cardiac pacing and cardiac resynchronization therapy. The Task Force on cardiac pacing and resynchronization therapy of the European Society of Cardiology (ESC). Developed in collaboration with the European Heart Rhythm Association (EHRA). Europace 15:1070–1118. https://doi.org/10.1093/EUROPACE/EUT206
Hariton E, Locascio JJ (2018) Randomised controlled trials—the gold standard for effectiveness research. BJOG 125:1716. https://doi.org/10.1111/1471-0528.15199
Krizhevsky A, Sutskever I, Hinton GE (2012) ImageNet classification with deep convolutional neural networks. In: Advances in neural information processing systems 25 (NIPS 2012), 1st ed. pp 1097–1105
Mayo-Wilson E, Fusco N, Li T et al (2017) Multiple outcomes and analyses in clinical trials create challenges for interpretation and research synthesis. J Clin Epidemiol 86:39–50. https://doi.org/10.1016/J.JCLINEPI.2017.05.007
Soriano-Valdez D, Pelaez-Ballestas I, Manrique De Lara A, Gastelum-Strozzi A (2021) The basics of data, big data, and machine learning in clinical practice. Clin Rheumatol 11–23. https://doi.org/10.1007/s10067-020-05196-z/Published
Author information
Authors and Affiliations
Contributions
Conceptualization: WN; methodology: WN, SS; formal analysis and investigation: WN, KN; writing—original draft preparation: WN, KN; writing—review and editing: SS, EW, DK, RB-D, LD-S; supervision: RB-D, LD-S.
Corresponding author
Ethics declarations
Ethical approval
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nazar, W., Szymanowicz, S., Nazar, K. et al. Artificial intelligence models in prediction of response to cardiac resynchronization therapy: a systematic review. Heart Fail Rev 29, 133–150 (2024). https://doi.org/10.1007/s10741-023-10357-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10741-023-10357-8