
Abstract
Lexicographically minimal string rotation (LMSR) is a problem to find the minimal one among all rotations of a string in the lexicographical order, which is widely used in equality checking of graphs, polygons, automata and chemical structures. In this paper, we propose an \(O(n^{3/4})\) quantum query algorithm for LMSR. In particular, the algorithm has average-case query complexity \(O(\sqrt{n} \log n)\), which is shown to be asymptotically optimal up to a polylogarithmic factor, compared to its \(\Omega \left( \sqrt{n/\log n}\right) \) lower bound. Furthermore, we show that our quantum algorithm outperforms any (classical) randomized algorithms in both worst and average cases. As an application, it is used in benzenoid identification and disjoint-cycle automata minimization.
Similar content being viewed by others


1 Introduction
1.1 Lexicographically Minimal String Rotation
Lexicographically Minimal String Rotation (LMSR) is the problem of finding the lexicographically smallest string among all possible cyclic rotations of a given input string [21]. It has been widely used in equality checking of graphs [25], polygons [47, 58], automata [64] (and their minimizations [10]) and chemical structures [68], and in generating de Bruijn sequences [34, 71] (see also [40, 74]). Booth [21] first proposed an algorithm in linear time for LMSR based on the Knuth-Morris-Pratt string-matching algorithm [54]. Shiloach [69] later improved Booth’s algorithm in terms of performance. A more efficient algorithm was developed by Duval [37] from a different point of view known as Lyndon Factorization. All these algorithms for LMSR are deterministic and have worst-case time complexity \(\Theta (n)\). After that, several parallel algorithms for LMSR were developed. Apostolico, Iliopoulos and Paige [3] found an \(O(\log n)\) time CRCW PRAM (Concurrent Read Concurrent Write Parallel Random-Access Machine) algorithm for LMSR using O(n) processors, which was then improved by Iliopoulos and Smyth [48] to use only \(O(n/\log n)\) processors.
The LMSR of a string s can also be computed by finding the lexicographically minimal suffix of \(ss\$ \), i.e. the concatenation of two occurrences of s and an end-marker \( \$ \), where \(\$ \) is considered as a character lexicographically larger than every character in s. The minimal suffix of a string can be found in linear time with the help of data structures known as suffix trees [2, 59, 76] and suffix arrays [38, 56, 60], and alternatively by some specific algorithms [32, 37, 67] based on Duval’s algorithm [37] or the KMP algorithm [54].
1.2 Quantum Algorithms for String Problems
Although a large number of new quantum algorithms have been found for various problems (e.g., [9, 23, 24, 39, 41, 62, 70]), only a few of them solve string problems.
Pattern matching is a fundamental problem in stringology, where we are tasked with determining whether a pattern P of length m occurs in a text T of length n. In classical computing, it is considered to be closely related to LMSR. The Knuth-Morris-Pratt algorithm [54] used in Booth’s algorithm [21] for LMSR mentioned above is one of the first few algorithms for pattern matching, with time complexity \(\Theta (n + m)\). Recently, several quantum algorithms have been developed for pattern matching; for example, Ramesh and Vinay [66] developed an \(O\left( \sqrt{n} \log (n/m) \log m + \sqrt{m}\log ^2 m\right) \) quantum pattern matching algorithm based on a useful technique for parallel pattern matching, namely deterministic sampling [73], and Montanaro [61] proposed an average-case \(O\left( (n/m)^d 2^{O\left( d^{3/2}\sqrt{\log m}\right) }\right) \) quantum algorithm for d-dimensional pattern matching. However, it seems that these quantum algorithms for pattern matching cannot be directly generalized to solve LMSR.
Additionally, quantum algorithms for reconstructing unknown strings with nonstandard queries have been proposed; for example, substring queries [29] and wildcard queries [6]. Recently, a quantum algorithm that approximates the edit distance within a constant factor was developed in [20]. Soon after, Le Gall and Seddighin [57] studied quantum algorithms for several other string problems: longest common substring, longest palindrome substring, and Ulam distance.
1.3 Main Contributions of This Paper
A naive quantum algorithm for LMSR (see Definition 2.1 for its formal definition) is to find the LMSR of the string within \(O(\sqrt{n})\) comparisons of rotations by quantum minimum finding [5, 33] among all rotations. However, each comparison of two rotations in the lexicographical order costs \(O(\sqrt{n})\) and is bounded-error. Combining the both, an \(\tilde{O}(n)\) quantum algorithm for LMSR is obtained, which has no advantages compared to classical algorithms.
In this paper, however, we find a more efficient quantum algorithm for LMSR. Formally, we have:
Theorem 1.1
(Quantum Algorithm for LMSR) There is a bounded-error quantum query algorithm for LMSR, for which the worst-case query complexity is \(O\left( n^{3/4}\right) \) and average-case query complexity is \(O\left( \sqrt{n} \log n\right) \).
In the top-level design of this algorithm, we are required to find the minimal value of a function, which is given by a bounded-error quantum oracle. To resolve this issue, we develop an efficient error reduction for nested quantum algorithms (see Section 1.4.1 for an outline). With this framework of nested quantum algorithms, we are able to solve problems in nested structures efficiently. The high level illustrations of the algorithm for the worst and average cases are given in Sections 1.4.2 and 1.4.3, respectively. A detailed description of the algorithm is presented in Section 5.
We assume access to a quantum-read/classical-write random access memory (QRAM) and define time complexity as the number of elementary two-qubit quantum gates, input queries and QRAM operations (see Section 2.2.2 for more details). Our quantum algorithm uses only \(O(\log ^2 n)\) classical bits in QRAM and \(O(\log n)\) “actual” qubits in the quantum computation. Thus, the time complexity of our quantum algorithms in this paper is just an \(O( \log n )\) factor bigger than their query complexity (in both worst and average cases).
In order to show a separation between classical and quantum algorithms for LMSR, we settle the classical and quantum lower bounds for LMSR in both the worst and average cases. Let \(R({\text {LMSR}})\) and \(R^ unif ({\text {LMSR}})\) be the worst-case and average-case (classical) randomized query complexities for LMSR, and let \(Q({\text {LMSR}})\) and \(Q^ unif ({\text {LMSR}})\) be their quantum counterparts. Then we have:
Theorem 1.2
(Classical and Quantum Lower Bounds for LMSR)
-
1.
For every bounded-error (classical) randomized algorithm for LMSR, it has worst-case query complexity \(\Omega (n)\) and average-case query complexity \(\Omega (n / \log n)\). That is, \(R({\text {LMSR}}) = \Omega (n)\) and \(R^{ unif }({\text {LMSR}}) = \Omega (n / \log n)\).
-
2.
For every bounded-error quantum algorithm for LMSR, it has worst-case query complexity \(\Omega \left( \sqrt{n}\right) \) and average-case query complexity \(\Omega \left( \sqrt{n / \log n}\right) \). That is, \(Q({\text {LMSR}}) = \Omega (\sqrt{n})\) and \(Q^{ unif }({\text {LMSR}}) = \Omega \left( \sqrt{n / \log n}\right) \).
Remark 1.1
It suffices to consider only bounded-error quantum algorithms for LMSR, as we can show that every exact (resp. zero-error) quantum algorithm for LMSR has worst-case query complexity \(\Omega (n)\). This is achieved by reducing the search problem to LMSR (see Appendix F), since the search problem is known to have worst-case query complexity \(\Omega (n)\) for exact and zero-error quantum algorithms [13].
Theorem 1.2 is proved in Section 6. Our main proof technique is to reduce a total Boolean function to LMSR and to find a lower bound of that Boolean function based on the notion of block sensitivity. The key observation is that the block sensitivity of that Boolean function is related to the string sensitivity of input (Lemma 6.3, and see Section 1.4.3 for more discussions).
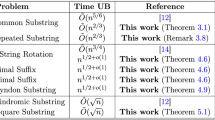
The results of Theorems 1.1 and 1.2 can be summarized as Table 1.
Note that
Therefore, our quantum algorithm is asymptotically optimal in the average case up to a logarithmic factor. Moreover, a quantum separation from (classical) randomized computation in both the worst-case and average-case query complexities is achieved:
-
1.
Worst case: \(Q({\text {LMSR}}) = O\left( n^{3/4} \right) \) but \(R({\text {LMSR}}) = \Omega (n)\); and
-
2.
Average case: \(Q^ unif ({\text {LMSR}}) = O\left( \sqrt{n} \log n\right) \) but \(R^ unif ({\text {LMSR}}) = \Omega (n / \log n)\).
In other words, our quantum algorithm is faster than any classical randomized algorithms both in the worst case and the average case.
As an application, we show that our algorithm can be used in identifying benzenoids [11] and minimizing disjoint-cycle automata [10] (see Section 7). The quantum speedups for these problems are illustrated in Table 2.
Recent Developments After the work described in this paper, the worst-case quantum query complexity of LMSR was further improved to \(n^{1/2+o(1)}\) in [4] by refining the exclusion rule of LMSR proposed in this paper (see Lemma 4.8 of [4]), and later a quasi-polylogarithmic improvement was achieved in [75]. A quantum algorithm for the decision version of LMSR with worst-case query complexity \(\tilde{O}( \sqrt{n} )\) was proposed in [30] under their quantum divide-and-conquer framework.
As an application, the near-optimal quantum algorithm for LMSR [4] was then used as a subroutine in finding the longest common substring of two input strings [52].
1.4 Overview of the Technical Ideas
Our results presented in the above subsection are achieved by introducing the following three new ideas:
1.4.1 Optimal Error Reduction for Nested Quantum Minimum Finding
Our main algorithm for LMSR is essentially a nest of quantum search and minimum finding. A major difficulty in its design is error reduction in nested quantum oracles, which has not been considered in the previous studies of nested quantum algorithms (e.g., nested quantum search analyzed by Cerf, Grover and Williams [26] and nested quantum walks introduced by Jeffery, Kothari and Magniez [51]).
A d-level nested classical algorithm needs \(O(\log ^{d-1} n)\) repetitions to ensure a constant error probability by majority voting. For a d-level quantum algorithm composed of quantum minimum finding, it is known that only a small factor \(O(\log n)\) of repetitions is required [27]. We show that this factor can be even better; that is, only O(1) of repetitions are required as if there were no errors in quantum oracles:
-
We extend quantum minimum finding algorithm [5, 33] to the situation where the input is given by a bounded-error oracle so that it has query complexity \(O(\sqrt{n})\) (see Lemma 3.4) rather than \(O(\sqrt{n} \log n)\) straightforwardly by majority voting.
-
We introduce a success probability amplification method for quantum minimum finding on bounded-error oracles, which requires \(O\left( \sqrt{n \log (1/\varepsilon )}\right) \) query complexity to obtain the minimum with error probability \(\le \varepsilon \) (see Lemma 3.5). In contrast, a straightforward solution by \(O(\log (1/\varepsilon ))\) repetitions of the \(O(\sqrt{n})\) algorithm (by Lemma 3.4) has query complexity \(O(\sqrt{n} \log (1/\varepsilon ))\).
These ideas are inspired by quantum searching on bounded-error oracles [43] and amplification of success of quantum search [16]. The above two algorithms will be used in the main algorithm for LMSR as a subroutine. Both of them are optimal because their simpler version (OR function) has lower bound \(\Omega (\sqrt{n})\) [12, 15, 79] for quantum bounded-error algorithm and \(\Omega (\sqrt{n \log (1/\varepsilon )})\) [16] for its error reduction. To be clearer, we compare the results about quantum searching and quantum minimum finding in the previous literature and ours in Table 3.
Based on the above results, we develop an \(O\left( \sqrt{n \log ^{3} n \log \log n}\right) \) quantum algorithm for deterministic sampling [73], and furthermore obtain an \(O\left( \sqrt{n \log m} +\right. \) \(\left. \sqrt{m \log ^{3} m \log \log m}\right) \) quantum algorithm for pattern matching, which is better than the best known result [66] of \(O(\sqrt{n} \log (n/m) \log m + \sqrt{m} \log ^2 m). \)
We also develop an optimal \(O\left( \sqrt{n^d}\right) \) quantum algorithm for evaluating d-level shallow MIN-MAX trees that matches the lower bound \(\Omega \left( \sqrt{n^d}\right) \) [7, 22] for AND-OR trees, and therefore it is optimal. The best known previous quantum query complexity of MIN-MAX trees is \(O\left( W_d(n) \log n\right) \) [27], where \(W_d(n)\) is the query complexity of d-level AND-OR trees and optimally \(O\left( \sqrt{n^d}\right) \) as known from [18, 43]. Our improvements on these problems are summarized in Table 4.
1.4.2 Exclusion Rule of LMSR
We find a useful property of LMSR, named exclusion rule (Lemma 5.1): for any two overlapped substrings which are prefixes of the canonical representation of a string, the LMSR of the string cannot be the latter one. This property enables us to reduce the worst-case query complexity by splitting the string into blocks of suitable sizes, and in each block the exclusion rule can apply so that there is at most one candidate for LMSR. This kind of trick has been used in parallel algorithms, e.g., Lemma 1.1 of [48] and the Ricochet Property of [73]. However, the exclusion rule of LMSR used here is not found in the literature (to the best of our knowledge).
We outline our algorithm as follows:
-
1.
Let \(B = \lfloor {\sqrt{n}}\rfloor \) and \(L = \lfloor {B/4}\rfloor \). We split s into \(\lceil n/L \rceil \) blocks of size L (except the last block).
-
2.
Find the prefix p of \({\text {SCR}}(s)\) of length B, where \({\text {SCR}}(s)\) is the canonical representation of s.
-
3.
In each block, find the leftmost index that matches p as the candidate. Only the leftmost index is required because of the exclusion rule of LMSR.
-
4.
Find the lexicographically minimal one among all candidates in blocks. In case of a tie, the minimal candidate is required.
A formal description and the analysis of this algorithm is given in Section 5.1. In order to find the leftmost index that matches p (Step 3 of this algorithm) efficiently, we adopt the deterministic sampling [73] trick. That is, we preprocess a deterministic sample of p, with which whether an index matches p can be checked within \(O(\log | p |)\) rather than \(O(| p |)\) comparisons. Especially, we allow p to be periodic, and therefore extend the definition of deterministic samples for periodic strings (see Definition 4.1) and propose a quantum algorithm for finding a deterministic sample of a string (either periodic or aperiodic) (see Algorithm 4).
1.4.3 String Sensitivity
We also observe the property of LMSR that almost all strings are of low string sensitivity (Lemma 5.3), which can be used to reduce the query complexity of our quantum algorithm significantly in the average case. Here, the string sensitivity of a string (see Definition 5.1) is a metric showing the difficulty to distinguish its substrings, and helpful to obtain lower bounds for LMSR (see Lemma 6.3).
We outline our improvements for better average-case query complexity as follows:
-
1.
Let \(s_1\) and \(s_2\) be the minimal and the second minimal substrings of s of length \(B = O(\log n)\), respectively.
-
2.
If \(s_1 < s_2\) lexicographically, then return the starting index of \(s_1\); otherwise, run the basic quantum algorithm given in Section 1.4.2.
Intuitively, in the average case, we only need to consider the first \(O(\log n)\) characters in order to compare two rotations. The correctness is straightforward but the average-case query complexity needs some analysis. See Section 5.2 for a formal description and the analysis of the improvements.
1.5 Organization of This Paper
We recall some basic definitions about strings and quantum query algorithms, and formally define the LMSR problem in Section 2. An efficient error reduction for nested quantum algorithms is developed in Section 3. An improved quantum algorithm for pattern matching based on the new error reduction technique (given in Section 3) is proposed in Section 4. The quantum algorithm for LMSR is proposed in Section 5. The classical and quantum lower bounds for LMSR are given in Section 6. The applications are discussed in Section 7.
2 Preliminaries
For convenience of the reader, in this section, we briefly review the lexicographically minimal string rotation (LMSR) problem, quantum query model and several notions of worst-case and average-case complexities used in the paper.
2.1 Lexicographically Minimal String Rotation
For any positive number n, let \([n] = \{0, 1, 2, \dots , n-1\}\). Let \(\Sigma \) be a finite alphabet with a total order <. A string \(s \in \Sigma ^n\) of length n is a function \(s: [n] \rightarrow \Sigma \). The empty string is denoted \(\epsilon \). We use s[i] to denote the i-th character of s. In case of \(i \notin \mathbb {Z} \setminus [n]\), we define \(s[i] \equiv s[i \bmod n]\). If \(l \le r\), \(s[l \dots r] = s[l] s[l+1] \dots s[r]\) stands for the substring consisting of the l-th to the r-th character of s, and if \(l > r\), we define \(s[l \dots r] = \epsilon \). A prefix of s is a string of the form \(s[0 \dots i]\) for \(i \in [n] \cup \{-1\}\). The period of a string \(s \in \Sigma ^n\) is the minimal positive integer d such that \(s[i] = s[i+d]\) for every \(0 \le i < n-d\). String s is called periodic if its period \(\le n/2\), and s is aperiodic if it is not periodic.
Let \(s \in \Sigma ^n\) and \(t \in \Sigma ^m\). The concatenation of s and t is string \(st = s[0] s[1] \dots s[n-1] t[0] t[1] \dots t[m-1]\). We write \(s = t\) if \(n = m\) and \(s[i] = t[i]\) for every \(i \in [n]\). We say that s is smaller than t in the lexicographical order, denoted \(s < t\), if either s is a prefix of t but \(s \ne t\), or there exists an index \(0 \le k < \min \{n, m\}\) such that \(s[i] = t[i]\) for \(i \in [k]\) and \(s[k] < t[k]\). For convenience, we write \(s \le t\) if \(s < t\) or \(s = t\).
Definition 2.1
(Lexicographically Minimal String Rotation) For any string \(s \in \Sigma ^n\) of length n, we call \(s^{(k)} = s[k \dots k+n-1]\) the rotation of s by offset k. The lexicographically minimal string rotation (LMSR) problem is to find an offset k such that \(s^{(k)}\) is the minimal string among \(s^{(0)}, s^{(1)}, \dots , s^{(n-1)}\) in the lexicographical order. The minimal \(s^{(k)}\) is called the string canonical representation (SCR) of s, denoted \({\text {SCR}}(s)\); that is,
In case of a tie; that is, there are multiple offsets such that each of their corresponding strings equals to \({\text {SCR}}(s)\), then the minimal offset is desired, and the goal is to find
The LMSR problem has been well-studied in the literature [21, 25, 28, 31, 37, 50, 69], and several linear time (classical) algorithms for LMSR are known, namely Booth’s, Shiloach’s and Duval’s Algorithms:
Theorem 2.1
([21, 37, 69]) There is an O(n) deterministic algorithm for LMSR.
2.2 Quantum Query Algorithms
Our computational model is the quantum query model [8, 19]. The goal is to compute an n-variable function \(f(x)=f(x_0, x_1, \dots , x_{n-1})\), where \(x_0, x_1, \dots , x_{n-1}\) are input variables. For example, the LMSR problem can be viewed as function \(f(x) = {\text {LMSR}}(x_0,x_1,\dots x_{n-1})\), where \(x_0x_1x_2\dots x_{n-1}\) denotes the string of element \(x_0, x_1, \dots , x_{n-1}\). The input variables \(x_i\) can be accessed by queries to a quantum oracle \(O_x\) (which is a quantum unitary operator) defined by \(O_x | i, j \rangle = | i, j \oplus x_i \rangle \), where \(\oplus \) is the bitwise exclusive-OR operation. A quantum algorithm A with T queries is described by a sequence of quantum unitary operators
The intermediate operators \(U_0, U_1, \dots , U_T\) can be arbitrary quantum unitary operators that are determined independent of \(O_x\). The computation is performed in a Hilbert space \(\mathcal {H} = \mathcal {H}_o \otimes \mathcal {H}_w\), where \(\mathcal {H}_o\) is the output space and \(\mathcal {H}_w\) is the work space. The computation starts from basis state \(| 0 \rangle _o | 0 \rangle _w\), and then we apply \(U_0, O_x, U_1, O_x, \dots , O_x, U_T\) on it in that order. The result state is
Measuring the output space, the outcome is then defined as the output A(x) of algorithm A on input x. More precisely, \(\Pr [A(x) = y] = \Vert M_y | \psi \rangle \Vert ^2\), where \(M_y = | y \rangle _o \langle y |\). Furthermore, A is said to be a bounded-error quantum algorithm that computes f, if \(\Pr [A(x) = f(x)] \ge 2/3\) for every x.
To deal with average-case complexity, following the setting used in [1], we assume that after each \(U_j\), a dedicated flag-qubit will be measured on the computational basis (and this measurement may change the quantum state). The measurement outcome indicates whether the algorithm is ready to halt and return its output. If the outcome is 1, then we measure the output space with the outcome as the output, and then stop the algorithm; otherwise, the algorithm continues with the next query \(O_x\) and \(U_{j+1}\). Let \(T_A(x)\) denote the expected number of queries that A uses on input x. Note that \(T_A(x)\) only depends on the algorithm A and its given input x (which is fixed rather than from some distribution).
2.2.1 Worst-Case and Average-Case Query Complexities
Let \(f: \{0, 1\}^n \rightarrow \{0, 1\}\) be a Boolean function. If A is a (either randomized or quantum) algorithm and \(y \in \{0, 1\}\), we use \(\Pr [A(x) = y]\) to denote the probability that A outputs y on input x. Let \(\mathcal {R}(f)\) and \(\mathcal {Q}(f)\) be the set of randomized and quantum bounded-error algorithms that compute f, respectively:
Then the worst-case query complexities of f are:
Let \(\mu : \{0, 1\}^n \rightarrow [0, 1]\) be a probability distribution. We usually use \( unif \equiv 2^{-n}\) to denote the uniform distribution. The average-case query complexity of an algorithm A with respect to \(\mu \) is
Thus, the randomized and quantum average-case query complexities of f with respect to \(\mu \) are:
Clearly, \(Q^\mu (f) \le R^\mu (f)\) for all f and \(\mu \).
2.2.2 Time and Space Efficiency
In order to talk about the “time” and “space” complexities of quantum algorithms, we assume access to a quantum-read/classical-write random access memory (QRAM), where it takes a single QRAM operation to either classically write a bit to the QRAM or make a quantum query to a bit stored in the QRAM. For simplicity, we assume the access to the QRAM is described by a quantum unitary operator \(U_{\text {QRAM}}\) that swaps the accumulator and a register indexed by another register:
where \(r_0, r_1, \dots , r_{M-1}\) are bit registers that are only accessible through this QRAM operator.
Let A be a quantum query algorithm, and \(t_A(x)\) denote the expected number of two-qubit quantum gates and QRAM operators \(U_\text {QRAM}\) composing intermediate operators, and the quantum input oracles \(O_x\) that A uses on input x. The space complexity of A measures the number of (qu)bits used in A. The worst-case and average-case time complexities of a Boolean function f are defined similarly to Section 2.2.1 by replacing \(T_A(x)\) with \(t_A(x)\).
3 Optimal Error Reduction for Nested Quantum Algorithms
Our quantum algorithm for LMSR (Theorem 1.1) is essentially a nested algorithm calling quantum search and quantum minimum finding. The error reduction is often crucial for nested quantum algorithms. Traditional probability amplification methods for randomized algorithms can obtain an \(O\left( \log ^d n\right) \) slowdown for d-level nested quantum algorithms by repeating the algorithm \(O(\log n)\) times in each level. In this section, we introduce an efficient error reduction for nested quantum algorithms composed of quantum search and quantum minimum finding, which only costs a factor of O(1). This improvement is obtained by finding an \(O\left( \sqrt{n}\right) \) quantum algorithm for minimum finding when the comparison oracle can have bounded errors (see Algorithm 1). Moreover, we also show how to amplify the success probability of quantum minimum finding with both exact and bounded-error oracles. In particular, we obtain an \(O\left( \sqrt{n \log {(1/\varepsilon )}}\right) \) quantum algorithm for minimum finding with success probability \(\ge 1 - \varepsilon \) (see Algorithm 2). These two algorithms allow us to control the error produced by nested quantum oracles better than traditional (classical) methods. Both of them are optimal because their simpler version (OR function) has lower bound \(\Omega (\sqrt{n})\) [12, 15, 79] for quantum bounded-error algorithm and \(\Omega (\sqrt{n \log (1/\varepsilon )})\) [16] for its error reduction. As an application, we develop a useful tool to find the first solution in the search problem.
3.1 Quantum Search
Let us start from an \(O\left( \sqrt{n}\right) \) quantum algorithm to search on bounded-error inputs [43]. The search problem is described by a function \(f(x_0, x_1, \dots , x_{n-1})\) that finds an index \(j \in [n]\) (if exists) such that \(x_j = 1\), where \(x_i \in \{0, 1\}\) for all \(i \in [n]\). It was first shown by Grover [39] that the search problem can be solved by an \(O\left( \sqrt{n}\right) \) quantum algorithm, which was found after the discovery of the \(\Omega ( \sqrt{n} )\) lower bound [12] (see also [15, 79]).
3.1.1 Quantum Search on Bounded-Error Oracles
A more robust approach for the search problem on bounded-error oracles was proposed by Høyer, Mosca and de Wolf [43]. Rather than an exact quantum oracle \(U_x | i, 0 \rangle = | i, x_i \rangle \), they consider a bounded-error one introducing extra workspace \(| 0 \rangle _w\):
where \(p_i \ge 2/3\) for every \(i \in [n]\), \(\bar{u}\) denotes the negation of u, and \(| \psi _{i} \rangle _w\) and \(| \phi _{i} \rangle _w\) are ignorable work qubits. This kind of bounded-error oracles is general in the sense that every bounded-error quantum algorithm and (classical) randomized algorithm can be described by it. A naive way to solve the search problem on bounded-error oracles is to repeat \(k = O(\log n)\) times and choose the majority value among the k outputs. This gives an \(O\left( \sqrt{n} \log n\right) \) quantum algorithm. Surprisingly, it can be made better to \(O\left( \sqrt{n}\right) \) as shown in the following:
Theorem 3.1
(Quantum Search on Bounded-Error Oracles, [43]) There is an \(O\left( \sqrt{n}\right) \) bounded-error quantum algorithm for the search problem on bounded-error oracles. Moreover, if there are \(t \ge 1\) solutions, the algorithm finds a solution in expected \(O\left( \sqrt{n/t}\right) \) queries (even if t is unknown).
For convenience, we use \({\textbf {Search}}(U_x)\) to denote the algorithm of Theorem 3.1 which, with probability \(\ge 2/3\), returns an index \(j \in [n]\) such that \(x_j = 1\) or reports that no such j exists (we require the algorithm to return \(-1\) in this case).
3.1.2 Amplification of the Success of Quantum Search
Usually, we need to amplify the success probability of a quantum or (classical) randomized algorithm to make it sufficiently large. A common trick used in randomized algorithms is to repeat the bounded-error algorithm \(O(\log (1/\varepsilon ))\) times and choose the majority value among all outputs to ensure success probability \(\ge 1 - \varepsilon \). Buhrman, Cleve, de Wolf and Zalka [16] showed that we can do better for quantum searching.
Theorem 3.2
(Amplification of the success of quantum search, [16]) For every \(\varepsilon > 0\), there is an \(O\left( \sqrt{n \log (1/\varepsilon )}\right) \) bounded-error quantum algorithm for the search problem with success probability \(\ge 1-\varepsilon \). Moreover, if there is a promise of \(t \ge 1\) solutions, the algorithm finds a solution in \(O\left( \sqrt{n} \left( \sqrt{t+\log (1/\varepsilon )} - \sqrt{t}\right) \right) \) queries.
Theorem 3.2 also holds for bounded-error oracles. For convenience, we use \({\textbf {Search}}(U_x, \varepsilon )\) to denote the algorithm of Theorem 3.2, which succeeds with probability \(\ge 1-\varepsilon \). Note that Theorem 3.2 does not cover the case that there can be \(t \ge 2\) solutions without promise. In this case, we can obtain an \(O\left( \sqrt{n/t} \log (1/\varepsilon )\right) \) bounded-error quantum algorithm with error probability \(\le \varepsilon \) by straightforward majority voting.
3.2 Quantum Minimum Finding
We now turn to consider the minimum-finding problem. Given \(x_0, x_1, \dots , x_{n-1}\), the problem is to find an index \(j \in [n]\) such that \(x_j\) is the minimal element. Let \(\text {cmp}(i, j)\) be the comparator to determine whether \(x_i < x_j\):
The comparison oracle \(U_\text {cmp}\) simulating \(\text {cmp}\) is defined by
We measure the query complexity by counting the number of queries to this oracle \(U_\text {cmp}\). A quantum algorithm was proposed by Dürr and Høyer [33] and Ahuja and Kapoor [5] for finding the minimum:
Theorem 3.3
(Minimum finding, [5, 33]) There is an \(O\left( \sqrt{n}\right) \) bounded-error quantum algorithm for the minimum-finding problem.
We also note that a generalized minimum-finding was developed in [72], which only needs to prepare a superposition over the search space (rather than make queries to individual elements of the search space).
3.2.1 Optimal Quantum Minimum Finding on Bounded-Error Oracles
For the purpose of this paper, we need to generalize the above algorithm to one with a bounded-error version of \(U_\text {cmp}\). For simplicity, we abuse a little bit of notation and define:
where \(p_{ij} \ge 2/3\) for all \(i, j \in [n]\), and \(| \psi _{ij} \rangle _w\) and \(| \phi _{ij} \rangle _w\) are ignorable work qubits. Moreover, for every index \(j \in [n]\), we can obtain a bounded-error oracle \(U_\text {cmp}^j\):
with only one query to \(U_\text {cmp}\). Then we can provide a quantum algorithm for minimum finding on bounded-error oracles as Algorithm 1.

\({\textbf {Minimum}}(U_\text {cmp})\): An algorithm for minimum finding on bounded-error oracles.
The constant \(C > 0\) in Algorithm 1 is given so that \({\textbf {Search}}(U_x)\) in Theorem 3.1 takes at most \(C \sqrt{n/\max \{t, 1\}}\) queries to \(U_x\) if there are t solutions.
Lemma 3.4
Algorithm 1 is a bounded-error quantum algorithm for minimum finding on bounded-error oracles in \(O\left( \sqrt{n} \right) \) queries.
Proof
The query complexity is trivially \(O(\sqrt{n})\) due to the guard (Line 7) of Algorithm 1.
The correctness is proved as follows. Let \(m = \lceil 12 \ln n \rceil \) and \(q = \lceil 36 \ln m \rceil \). We assume that \(n \ge 3\) and therefore \(m \ge 12\). In each of the m iterations, Line 11-14 of Algorithm 1 calls \(U_\text {cmp}\) for q times and b gets the value \(( i \ne -1 ) \wedge ( x_i < x_j )\) with probability \(\ge 1-1/m^2\) (This is a straightforward majority voting. For completeness, its analysis is provided in Appendix A). Here, i is an index such that \(x_i < x_j\) (with high probability) and \(i = -1\) if no such i exists; thus \(b = 1\) means that there exists smaller element \(x_i\) than \(x_j\).
We only consider the case that the values of b in all iterations are as desired. This case happens with probability \(\ge (1 - 1/m^2)^m \ge 1 - 1/m \ge 11/12\). In each iteration, i finds a candidate index with probability \(\ge 2/3\) such that \(x_i < x_j\) if exists (and if there are many, any of them is obtained with equal probability). It is shown in [33, Lemma 2] that: if i finds a candidate index with certainty, then the expected number of queries before j holds the index of the minimal is \(\le \frac{5}{2} C\sqrt{n}\); moreover, the expected number of iterations is \(\le \ln n\). In our case, i finds a candidate index in expected 3/2 iterations. Therefore, the expected number of queries to \(U_\text {cmp}\) is \(\le \frac{15}{4} C\sqrt{n}\) and that of iterations is \(\le \frac{3}{2} \ln n\). When Algorithm 1 makes queries to the oracle \(\ge 30C\sqrt{n}\) times (except those negligible queries in Line 11-14) or iterations \(\ge m\) times (that is, more than 8 times their expectations), the error probability is \(\le 1/8 + 1/8 = 1/4\) by Markov’s inequality. Therefore, the overall success probability is \(\ge \frac{11}{12} \cdot \frac{3}{4} \ge 2/3\). \(\square \)
3.2.2 Amplifying the Success Probability of Quantum Minimum Finding
We can amplify the success probability for quantum minimum finding better than a naive method, as shown in Algorithm 2.

\({\textbf {Minimum}}(U_\text {cmp}, \varepsilon )\): Amplification of the success of minimum finding.
Lemma 3.5
Algorithm 2 runs in expected \(O\left( \sqrt{n \log {(1/\varepsilon )}}\right) \) queries with error probability \(\le \varepsilon \).
Proof
Algorithm 2 terminates with a guard by \({\textbf {Search}}(U_\text {cmp}^j, \varepsilon )\). Here, \({\textbf {Search}}(U_\text {cmp}^j, \!\varepsilon )\) \(\ne -1\) means that with probability \(\ge 1-\varepsilon \), there is no index i such that \(\text {cmp}( i, j ) = 1\) and thus j is the desired answer. Therefore, it has error probability \(\le \varepsilon \) as the guard. Let \(p \ge 2/3\) be the probability that j holds the index of the minimal element with a single query to \({\textbf {Minimum}}(U_\text {cmp})\) by Lemma 3.4. Let q be the probability that Algorithm 2 breaks the “while” loop at each iteration. Then
which is greater than a constant. So, the expected number of iterations is O(1). In a single iteration, \({\textbf {Minimum}}(U_\text {cmp})\) takes \(O\left( \sqrt{n}\right) \) queries (by Lemma 3.4) and \({\textbf {Search}}(U_\text {cmp}^j, \varepsilon )\) takes \(O\left( \sqrt{n \log (1/\varepsilon )}\right) \) queries (by Theorem 3.2). Therefore, the expected query complexity of Algorithm 2 is \(O( 1 ) \cdot ( * ){ O( \sqrt{n} )+O\left( \sqrt{n \log {(1/\varepsilon )}}\right) } = O\left( \sqrt{n \log {(1/\varepsilon )}}\right) \). \(\square \)
3.3 An Application: Searching for the First Solution
In this subsection, we develop a tool needed in our quantum algorithm for LMSR as an application of the above two subsections. It solves the problem of finding the first solution (i.e. leftmost solution, or solution with the minimal index rather than an arbitrary solution) and thus can be seen as a generalization of quantum searching, but the solution is based on quantum minimum finding.
Formally, the query oracle \(U_x\) of \(x_0, x_1, \dots , x_{n-1}\) is given. The searching-first problem is to find the minimal index \(j \in [n]\) such that \(x_j = 1\) or report that no solution exists. This problem can be solved by minimum-finding with the comparator
which immediately yields an \(O(\sqrt{n})\) solution if the query oracle \(U_x\) is exact.
In the case that the query oracle \(U_x\) is bounded-error, a bounded-error comparison oracle \(U_\text {cmp}\) corresponding to \(\text {cmp}\) can be implemented with a constant number of queries to \(U_x\). Therefore, the results in Lemmas 3.4 and 3.5 also hold for the searching-first problem. For convenience in the following discussions, we write \({\textbf {SearchFirst}}(U_x)\) and \({\textbf {SearchFirst}}(U_x, \varepsilon )\) to denote the algorithm for the searching-first problem based on the two algorithm \({\textbf {Minimum}}(U_\text {cmp})\) and \({\textbf {Minimum}}(U_\text {cmp}, \varepsilon )\), respectively. Symmetrically, we have \({\textbf {SearchLast}}(U_x)\) and \({\textbf {SearchLast}}(U_x, \varepsilon )\) for searching the last solution.
Recently, an \(O(\sqrt{n})\) quantum algorithm for searching the first was proposed in [53]. Their approach is quite different from our presented above. It is specifically designed for this particular problem, but our approach is based on a more general framework of quantum minimum finding.
We believe that the techniques presented in this section can be applied in solving other problems. For this reason, we present a description of them in a general framework of nested quantum algorithm in Appendix B.
4 Quantum Deterministic Sampling
In this section, we prepare another tool to be used in our quantum algorithm for LMSR, namely an efficient quantum algorithm for deterministic sampling. It is based on our nested quantum algorithm composed of quantum search and quantum minimum finding given in the last section. Deterministic sampling is also a useful trick in parallel pattern matching [73]. We provide a simple quantum lexicographical comparator in Section 4.1, and a quantum algorithm for deterministic sampling in Section 4.2. As an application, we obtain quantum algorithms for string periodicity and pattern matching in Section 4.3.
4.1 Lexicographical Comparator
Suppose there are two strings \(s, t \in \Sigma ^n\) of length n over a finite alphabet \(\Sigma = [\alpha ]\). Let \(U_s\) and \(U_t\) be their query oracles, respectively. That is,
In order to compare the two strings in the lexicographical order, we need to find the leftmost index \(k \in [n]\) that \(s[k] \ne t[k]\). If no such k exists, then \(s = t\). To this end, we construct the oracle
using 1 query to each of \(U_s\) and \(U_t\). A straightforward algorithm for lexicographical comparison based on the searching-first problem is described in Algorithm 3.

\({\textbf {LexicographicalComparator}}(U_s, U_t)\): Lexicographical Comparator.
Lemma 4.1
Algorithm 3 is an \(O\left( \sqrt{n}\right) \) bounded-error quantum algorithm that compares two strings by their oracles in the lexicographical order.
Remark 4.1
We usually need to compare two strings in the lexicographical order as a subroutine nested as low-level quantum oracles in string algorithms. However, the lexicographical comparator (Algorithm 3) brings errors. Therefore, the error reduction trick for nested quantum oracles proposed in Section 3 is required here.
4.2 Deterministic Sampling
Deterministic sampling [73] is a useful technique for pattern matching in pattern analysis. In this subsection, we provide a quantum solution to deterministic sampling in the form of a nested quantum algorithm.
For our purpose, we extend the definition of deterministic samples to the periodic case. The following is a generalised definition of deterministic samples.
Definition 4.1
(Deterministic samples) Let \(s \in \Sigma ^n\) and d be its period. A deterministic sample of s consists of an offset \(0 \le \delta < \lfloor n/2 \rfloor \) and a sequence of indices \(i_0, i_1, \dots , i_{l-1}\) (called checkpoints) such that
-
1.
\(i_k-\delta \in [n]\) for \(k \in [l]\);
-
2.
For every \(0 \le j < \lfloor n/2 \rfloor \) with \(j \not \equiv \delta \pmod d\), there exists \(k \in [l]\) such that \(i_k-j \in [n]\) and \(s[i_k - j] \ne s[i_k - \delta ]\). We denote \(c_k = s[i_k - \delta ]\) when the exact values of \(i_k\) and \(\delta \) are ignorable.
If s is aperiodic (i.e. \(d > n/2\)), the second condition degenerates into “for every \(0 \le j < \lfloor n/2 \rfloor \) with \(j \ne \delta \)”, which is consistent with the definition for aperiodic strings in [73].
The Use of Deterministic Sampling Suppose that T is a text and P is a pattern. If we have a deterministic sample \((\delta ; i_0, i_1, \dots , i_{l-1})\) of P with a small l, then we can test if an index of T can be a starting position that matches P using only l comparisons according to the deterministic sample. It is worth noting that one can disqualify two possible starting positions (that pass the above testing of deterministic sampling) by the Ricochet property proposed in [73] (see Lemma D.1).
The following theorem shows that the size of the deterministic sample can be every small.
Theorem 4.2
(Deterministic sampling [73]) Let \(s \in \Sigma ^n\). There is a deterministic sample \((\delta ; i_0, i_1, \dots , i_{l-1})\) of s with \(l \le \lfloor \log _2 n \rfloor \).
Proof
For the case that s is aperiodic, a simple procedure for constructing a valid deterministic sample was given in [73]. We describe it as follows.
-
1.
Initially, let \(A_0 = [ \lfloor n/2 \rfloor ]\) be the set of candidates of \(\delta \), and \(S_0 = \emptyset \) be the set of checkpoints.
-
2.
At step \(k \ge 0\), let \(\delta _k^{\min } = \min A_k\) and \(\delta _k^{\max } = \max A_k\).
-
2.1.
If \(\delta _k^{\min } = \delta _k^{\max }\), then set \(\delta = \delta _k^{\min }\) and return the current set \(S_k\) of checkpoints.
-
2.2.
Otherwise, there must be an index \(i_k\) such that \(s[ i_k-\delta _k^{\min } ] \ne s[ i_k-\delta _k^{\max } ]\) (or s is periodic). Let \(\sigma _k\) be the symbol with least occurrences (but at least once) among \(s[ i_k - \gamma ]\) for \(\gamma \in A_k\) (and choose any of them if there are multiple possible symbols). Let \(S_{k+1} = S_k \cup \{ i_k \}\) and \(A_{k+1} = \left\{ \, \gamma \in A_k :s[ i_k-\gamma ] = \sigma _k \,\right\} \), then go to the next step for \(k+1\).
-
2.1.
It can be seen that the above procedure always stops as the set \(A_k\) halves after each step, i.e., \(| A_{k+1} | \le | A_k |/2\). It can be verified that the returned \(\delta \) and checkpoints together form a valid deterministic sample. The procedure will have at most \(\lfloor \log _2 n \rfloor \) steps and each step will add one checkpoint, which implies that there exist a deterministic sample with at most \(\lfloor \log _2 n \rfloor \) checkpoints.
For the case that s is periodic, the above procedure will still work if we set the initial set of candidates to be \(A_0 = [ d ]\). Intuitively, since s is periodic, most symbols are redundant and thus we only have to consider the first d offsets. After this modification, the analysis of the modified procedure is almost identical to the original one. Here, we note that if \(i_k\) does not exist during the execution of the modified procedure, then s has a smaller period than d. Finally, the procedure will return at most \(\lfloor \log _2 d \rfloor \le \lfloor \log _2 n \rfloor \) checkpoints. \(\square \)
Now let us consider how a quantum algorithm can do deterministic sampling. We start from the case where \(s \in \Sigma ^n\) is aperiodic. Let \(U_s\) be the query oracle of s, that is, \(U| i, j \rangle = | i, j \oplus s[i] \rangle \). Suppose at step l, the sequence of indices \(i_0, i_1, \dots , i_{l-1}\) is known as well as \(c_k = s[i_k-\delta ]\) for \(k \in [l]\) (we need not know \(\delta \) explicitly). For \(0 \le j < \lfloor n/2 \rfloor \), let \(x_j\) denote whether candidate j agrees with \(\delta \) at all checkpoints, that is,
Based on the search problem, there is a bounded-error oracle \(U_x\) for computing \(x_j\) with \(O\left( \sqrt{l}\right) = O\left( \sqrt{\log n}\right) \) queries to \(U_s\).
A quantum algorithm for deterministic sampling is described in Algorithm 4. Initially, all offsets \(0 \le \xi < \lfloor n/2 \rfloor \) are candidates of \(\delta \). The idea of the algorithm is to repeatedly find two remaining candidates p and q that differ at an index j (if there is only one remaining candidate, the algorithm has already found a deterministic sample and terminates), randomly choose a character c being \(s[j-p]\) or \(s[j-q]\), and delete either p or q according to c. It is sufficient to select p and q to be the first and the last solution of \(x_j\) defined in (3). To explicitly describe how to find an index j where p and q differ, we note that \(q \le j < p+n\) and j must exist because of the aperiodicity of s, and let
It is trivial that there is an exact oracle \(U_y\) for computing \(y_j\) with O(1) queries to \(U_s\).
For the case of periodic \(s \in \Sigma ^n\), the algorithm requires some careful modifications. We need a variable Q to denote the upper bound of current available candidates. Initially, \(Q = \lfloor n/2 \rfloor - 1\). We modify the definition of \(x_j\) in (3) to make sure \(0 \le j \le Q\) by
For an aperiodic string s, there is at least one \(y_j\) such that \(y_j = 1\), so the algorithm will reach Line 17-25 during its execution with small probability \(\le 1/m\), where \(m = O(\log n)\). But for periodic string s, let d be its period, if \(q-p\) is divisible by d, then \(y_j = 0\) for all \(y_j\) and thus the algorithm once reaches Line 17-25 with high probability \(\ge 1-1/6m^2\). In this case, there does not exist \(q \le j < p+n\) such that \(y_j = 1\). We set \(Q = q-1\) to eliminate all candidates \(\ge q\). In fact, even for a periodic string s, the algorithm is intended to reach Line 17-25 only once (with high probability). If the algorithm reaches Line 17-25 the second (or more) time, it is clear that current \((\delta ; i_0, i_1, \dots , i_{l-1})\) is a deterministic sample of s (with high probability \(\ge 1-1/m\)), and therefore consequent computation does not influence the correctness and can be ignored.

\({\textbf {DeterministicSampling}}(U_s)\): Deterministic Sampling.
Lemma 4.3
Algorithm 4 is an \(O\left( \sqrt{n \log ^3 n \log \log n}\right) \) bounded-error quantum algorithm for deterministic sampling.
Proof
Assume \(n \ge 2\) and let \(m = \lceil 8 \log _2 n \rceil \) and \(\varepsilon = 1/6m^2\). There are m iterations in Algorithm 4. In each iteration, there are less than 6 calls to \({\textbf {Search}}\), \({\textbf {SearchFirst}}\) or \({\textbf {SearchLast}}\), which may bring errors. It is clear that each call to \({\textbf {Search}}\), \({\textbf {SearchFirst}}\) or \({\textbf {SearchLast}}\) has error probability \(\le \varepsilon \). Therefore, Algorithm 4 runs with no errors from \({\textbf {Search}}\), \({\textbf {SearchFirst}}\) or \({\textbf {SearchLast}}\) with probability \(\ge (1-\varepsilon )^{6m} \ge 1-1/m\).
Now suppose Algorithm 4 runs with no errors from \({\textbf {Search}}\), \({\textbf {SearchFirst}}\) or \({\textbf {SearchLast}}\). To prove the correctness of Algorithm 4, we consider the following two cases:
-
1.
Case 1. s is aperiodic. In this case, Algorithm 4 will never reach Line 17-25. In each iteration, the leftmost and the rightmost remaining candidates p and q are found. If \(p = q\), then only one candidate remains, and thus a deterministic sample is found. If \(p \ne q\), then there exists an index \(q \le j < p+n\) such that \(s[j-p]\) and \(s[j-q]\) differ. We set \(i_l = j\) and set \(c_l\) randomly from \(s[j-p]\) and \(s[j-q]\) with equal probability. Then with probability 1/2, half of the remaining candidates are eliminated. In other words, it is expected to find a deterministic sample in \(2 \log _2 n\) iterations. The iteration limit to \(m \ge 8 \log _2 n\) will make error probability \(\le 1/4\). That is, a deterministic sample is found with probability \(\ge 3/4\).
-
2.
Case 2. s is periodic and the period of s is \(d \le n/2\). In each iteration, the same argument for aperiodic s holds if Algorithm 4 does not reach Line 17-25. If Line 17-25 is reached for the first time, it means candidates between \(q + 1\) and \(\lfloor n/2 \rfloor -1\) are eliminated and \(q - p\) is divisible by d. If Line 17-25 is reached for the second time, all candidates \(p \not \equiv q \pmod d\) are eliminated, and therefore a deterministic sample is found.
Combining the above two cases, a deterministic sample is found with probability \(\ge 3/4 (1 - 1/m) \ge 2/3\).
On the other hand, we note that a single call to \({\textbf {SearchFirst}}\) and \({\textbf {SearchLast}}\) in Algorithm 4 has \(O\left( \sqrt{n \log (1/\varepsilon )}\right) = O\left( \sqrt{n \log \log n}\right) \) queries to \(U_x\) (by Lemma 3.5), and \({\textbf {Seach}}\) has query complexity \(O\left( \sqrt{n \log (1/\varepsilon )}\right) = O\left( \sqrt{n \log \log n}\right) \) (by Theorem 3.2). Hence, a single iteration has query complexity \(O\left( \sqrt{nl\log \log n}\right) = O\left( \sqrt{n \log n \log \log n}\right) \), and the total query complexity (m iterations) is \(O\left( m\right. \) \(\left. \sqrt{n \log n \log \log n}\right) = O\left( \sqrt{n \log ^3 n \log \log n}\right) \). \(\square \)
Algorithm 4 is a 2-level nested quantum algorithm (see Appendix C for a more detailed discussion), and is a better solution for deterministic sampling in \(O\left( \sqrt{n \log ^3 n \log \log n}\right) \) queries than the known \(O\left( \sqrt{n} \log ^2 n\right) \) solution in [66].
Remark 4.2
In order to make our quantum algorithm for deterministic sampling time and space efficient, we need to store and modify the current deterministic sample \((\delta ; i_0, i_1, \dots , i_{l-1})\) during the execution in the QRAM, which needs \(O(l \log n) = O(\log ^2 n)\) bits of memory. Moreover, only \(O(\log n)\) qubits are needed in the computation (for search and minimum finding). In this way, the time complexity of the quantum algorithm is \(O( * ){\sqrt{n \log ^5 n \log \log n}}\), which is just an \(O( \log n )\) factor bigger than its query complexity.
4.3 Applications
Based on our quantum algorithm for deterministic sampling, we provide applications for string periodicity and pattern matching.
4.3.1 String Periodicity
We can check whether a string is periodic (and if yes, find its period) with its deterministic sample. Formally, let \((\delta ; i_0, i_1, \dots , i_{l-1})\) be a deterministic sample of s, and \(x_j\) defined in (3). Let \(j_1\) denote the smallest index j such that \(x_j = 1\), which can be computed by \({\textbf {SearchFirst}}\) on \(x_j\). After \(j_1\) is obtained, define
Let \(j_2\) denote the smallest index j such that \(x_j' = 1\) (if not found then \(j_2 = -1\)), which can be computed by \({\textbf {SearchFirst}}\) on \(x_j'\). If \(j_2 = -1\), then s is aperiodic; otherwise, s is periodic with period \(d = j_2-j_1\). This algorithm for checking periodicity is \(O\left( \sqrt{n \log n}\right) \). (See Appendix D for more details.)
4.3.2 Pattern Matching
As an application of deterministic sampling, we have a quantum algorithm for pattern matching with query complexity \(O\left( \sqrt{n \log m} + \sqrt{m \log ^{3} m \log \log m}\right) \), better than the best known solution in [66] with query complexity \(O\left( \sqrt{n} \log (n/m) \log m + \sqrt{m}\right. \) \(\left. \log ^2 m\right) \).
For readability, these algorithms are postponed to Appendix D.
5 The Quantum Algorithm for LMSR
Now we are ready to present our quantum algorithm for LMSR and thus prove Theorem 1.1. This algorithm is designed in two steps:
-
1.
Design a quantum algorithm with worst-case query complexity \(O\left( n^{3/4} \right) \) in Section 5.1; and
-
2.
Improve the algorithm to average-case query complexity \(O\left( \sqrt{n} \log n\right) \) in Section 5.2.
5.1 The Basic Algorithm
For convenience, we assume that the alphabet \(\Sigma = [\alpha ]\) for some \(\alpha \ge 2\), where \([n] = \{ 0, 1, 2, \dots , n-1 \}\) and the total order of \(\Sigma \) follows that of natural numbers. Suppose the input string \(s \in \Sigma ^n\) is given by an oracle \(U_{\text {in}}\):
The overall idea of our algorithm is to split s into blocks of length B, and then in each block find a candidate with the help of the prefix of \({\text {SCR}}(s)\) of length B. These candidates are eliminated between blocks by the exclusion rule for LMSR (see Lemma 5.1). We describe it in detail in the next three subsections.
5.1.1 Find a Prefix of SCR
Our first goal is to find the prefix \(p = s[{\text {LMSR}}(s) \dots {\text {LMSR}}(s)+B-1]\) of \({\text {SCR}}(s)\) of length B by finding an index \(i^* \in [n]\) such that \(s[i^* \dots i^*+B-1]\) matches p, where \(B = \lfloor \sqrt{n} \rfloor \) is chosen optimally (see later discussions). To achieve this, we need to compare two substrings of s of length B with the comparator \(\text {cmp}_B\):
According to Algorithm 3, we can obtain a bounded-error comparison oracle \(U_{\text {cmp}_B}\) corresponding to \(\text {cmp}_B\) with \(O\left( \sqrt{B}\right) \) queries to \(U_{\text {in}}\). After that, let \(i^* \in [n]\) be any index such that \(s[i^* \dots i^* + B - 1] = p\) by calling \({\textbf {Minimum}}(U_{\text {cmp}_B})\), which needs \(O\left( \sqrt{n} \right) \) queries to \(U_{\text {cmp}_B}\) (by Lemma 3.4) and succeeds with a constant probability. In the following discussion, we use \(i^*\) to find possible candidates of \({\text {LMSR}}(s)\) and then find the solution among all candidates.
5.1.2 Candidate in Each Block
Being able to access contents of p by \(i^*\), we can obtain a deterministic sample of p by Algorithm 4 in \(O\left( \sqrt{B \log ^{3} B \log \log B}\right) {= \tilde{O}( \sqrt{B} )}\) queries with a constant probability. Suppose a deterministic sample of p is known to be \((\delta ; i_0, i_1, \dots , i_{l-1})\). We split s into blocks of length \(L = \lfloor B/4 \rfloor \). In the i-th block (0-indexed, \(0 \le i < \lceil n/L \rceil \)), with the index ranging from iL to \(\min \{(i+1)L, n\} - 1\), a candidate \(h_i\) is computed by
where the minimum is taken over all indices j in the i-th block such that \(s[j \dots j+B-1] = p\), and \(\min \emptyset = \infty \). Intuitively, for each \(0 \le i < \lceil n/L \rceil \), \(h_i\) defined by (6) denotes the leftmost possible candidate for \({\text {LMSR}}(s)\) such that \(s[h_i \dots h_i+B-1] = p\) in the i-th block. On the other hand, \(h_i\) denotes the first occurrence of p with starting index in the i-th block of s, and thus can be computed by a procedure in quantum pattern matching (see Appendix D for more details), which needs \(O\left( \sqrt{B \log B} \right) = {\tilde{O}( \sqrt{B} )}\) queries to \(U_\text {in}\) with the help of the deterministic sample of p. We write \(U_h\) for the bounded-error oracle of \(h_i\). Note that \(U_h\) is a 2-level nested quantum oracle.
5.1.3 Candidate Elimination Between Blocks
If we know the values of \(h_i\) for \(0 \le i < \lceil n/L \rceil \), with either \(h_i\) being a candidate or \(\infty \) (indicating non-existence), then we can find \({\text {LMSR}}(s)\) among all \(h_i\)’s with the comparator
where \(\text {cmp}_n\) is defined by (5), and \(\infty \) can be regarded as n explicitly in the computation. Then we can obtain the bounded-error comparison oracle \(U_\text {cmp}\) corresponding to \(\text {cmp}\) with constant number of queries to \(U_{\text {cmp}_n}\) and \(U_h\), with \(O\left( \sqrt{B \log B} + \sqrt{n}\right) \) queries to \(U_\text {in}\). Here, \(U_\text {cmp}\) is a 2-level nested quantum oracle. At the end of the algorithm, the value of \({\text {LMSR}}(s)\) is chosen to be the minimal element among \(h_i\) by comparison oracle \(U_\text {cmp}\) according to comparator \(\text {cmp}\). It can be seen that the algorithm is a 3-level nested quantum algorithm.
5.1.4 The Algorithm
We summarize the above design ideas in Algorithm 5. There are four main steps (Line 5, Line 6, Line 7 and Line 8) in the algorithm. Especially, Line 7 of Algorithm 5 involves a 3-level nested quantum algorithm. For convenience, we assume that each of these steps succeeds with a high enough constant probability, say \(\ge 0.99\). To achieve this, each step just needs a constant number of repetitions to amplify the success probability from 2/3 up to 0.99.

\({\textbf {BasicLMSR}}(U_\text {in})\): Quantum algorithm for LMSR.
5.1.5 Complexity
The query complexity of Algorithm 5 comes from the following four parts:
-
1.
One call to \({\textbf {Minimum}}(U_{\text {cmp}_B})\), which needs \(O\left( \sqrt{n} \right) \) queries to \(U_{\text {cmp}_B}\) (by Lemma 3.4), i.e. \(O\left( \sqrt{nB}\right) \) queries to \(U_\text {in}\).
-
2.
One call to \({\textbf {DeterministicSampling}}(U_{s[i^* \dots i^*+B-1]})\), which needs O\(\left( \sqrt{B \log ^{3} B \log \log B }\right) \) queries to \(U_\text {in}\) (by Lemma 4.3).
-
3.
One call to \({\textbf {Minimum}}(U_\text {cmp})\), which needs \(O\left( \sqrt{n/L} \right) \) queries to \(U_\text {cmp}\) (by Lemma 3.4), i.e.
$$ O\left( \sqrt{n/L} \left( \sqrt{B \log B} + \sqrt{n}\right) \right) = O\left( n/\sqrt{B} \right) $$queries to \(U_\text {in}\).
-
4.
Compute \(h_i\), i.e. one query to \(U_h\), which needs \(O\left( \sqrt{B \log B} \right) \) queries to \(U_\text {in}\).
Therefore, the total query complexity is
by selecting \(B = \Theta \left( \sqrt{n}\right) \).
5.1.6 Correctness
The correctness of Algorithm 5 is not obvious due to the fact that we only deal with one candidate in each block, but there can be several candidates that matches p in a single block. This issue is resolved by the following exclusion rule:
-
For every two equal substrings \(s[i \dots i+B-1]\) and \(s[j \dots j+B-1]\) of s that overlap each other with \(0 \le i< j < n\) and \(1 \le B \le n/2\), if both of them are prefixes of \({\text {SCR}}(s)\), then \({\text {LMSR}}(s)\) cannot be the larger index j.
More precisely, this exclusion rule can be stated as the following:
Lemma 5.1
[Exclusion Rule for LMSR] Suppose \(s \in \Sigma ^n\) is a string of length n. Let \({2} \le B \le n/2\), and two indices \(i, j \in [n]\) with \(i< j < i+B\). If \(s[i \dots i+B-1] = s[j \dots j+B-1] = s[{\text {LMSR}}(s) \dots {\text {LMSR}}(s)+B-1]\), then \({\text {LMSR}}(s) \ne j\).
Proof
See Appendix E. \(\square \)
Indeed, the above exclusion rule can be viewed as the Ricochet Property of LMSR. Here, the Ricochet Property means that if two candidates are in the same block, then at most one of them can survive. This kind of Ricochet property was found to be useful in string matching, e.g., [73]. If there are two candidates in the same block, since each block is of length \(L = \lfloor B/4 \rfloor < B\), then the two candidates must overlap each other. By this rule, the smaller candidate remains. Consequently, the correctness of Algorithm 5 is guaranteed because \(h_i\) defined by (6) always chooses the smallest candidate in each block.
After the above discussions, we obtain:
Theorem 5.2
Algorithm 5 is an \(O\left( n^{3/4} \right) \) bounded-error quantum query algorithm for LMSR.
The quantum algorithm given by Theorem 5.2 uses quantum deterministic sampling (Lemma 4.3) as a subroutine. It can be also made time-efficient in the same way as discussed in Remark 4.2.
5.2 An Improvement for Better Average-Case Query Complexity
In the previous subsection, we propose an efficient quantum algorithm for LMSR in terms of its worst-case query complexity. It is easy to see that its average-case query complexity remains the same as its worst-case query complexity. In this subsection, we give an improved algorithm with better average-case query complexity which also retains the worst-case query complexity.
The basic idea is to individually deal with several special cases, which cover almost all of the possibilities on average. Let \(B = \lceil 3 \log _\alpha n \rceil \). Our strategy is to just consider substrings of length B. Let
denote the index of the minimal substring among all substrings of length B, and then let
denote the index of the second minimal substring among all substrings of length B. If \(s[k \dots k+B-1] \ne s[k' \dots k'+B-1]\), then it immediately holds that \({\text {LMSR}}(s) = k\). To find the second minimal substring, the index k of the minimal substring should be excluded. For this, we need comparator \(\text {cmp}_{B \setminus k}\):
The bounded-error quantum comparison oracle \(U_{\text {cmp}_{B \setminus k}}\) corresponding to \(\text {cmp}_{B \setminus k}(i, j)\) can be defined with at most one query to \(U_{\text {cmp}_B}\).
5.3 The Algorithm
Our improved algorithm is presented as Algorithm 6. It has three main steps (Line 5, Line 6 and Line 10). For the same reason as in Algorithm 5, we assume that the third step (Line 10) succeeds with a high enough constant probability, say \(\ge 0.99\).

\({\textbf {ImprovedLMSR}}(U_\text {in})\): Improved quantum algorithm for LMSR.
5.4 Correctness
The correctness of Algorithm 6 is trivial. We only consider the case where \(n \ge 4\), and all of the three main steps succeed with probability
If \(\text {cmp}_{B}(k, k') = 1\), then \(s[k \dots k+B-1]\) is the minimal substring of length B, and it immediately holds that \({\text {LMSR}}(s) = k\). Otherwise, the correctness is based on that of \({\textbf {BasicLMSR}}(U_\text {in})\), which is guaranteed by Theorem 5.2.
5.5 Complexity
The worst-case query complexity of Algorithm 6 is \(O\left( n^{3/4} \right) \), obtained directly by Theorem 5.2. But settling the average-case query complexity of Algorithm 6 is a bit more subtle, which requires a better understanding of some properties of LMSR. To this end, we first introduce the notion of string sensitivity.
Definition 5.1
(String Sensitivity) Let \(s \in \Sigma ^n\) be a string of length n over a finite alphabet \(\Sigma \). The string sensitivity of s, denoted C(s), is the smallest positive number l such that \(s[i \dots i+l-1] \ne s[j \dots j+l-1]\) for all \(0 \le i< j < n\). In case that no such l exists, define \(C(s) = \infty \).
The string sensitivity of a string is a metric indicating the difficulty to distinguish its rotations by their prefixes. If we know the string sensitivity C(s) of a string s, we can compute \({\text {LMSR}}(s)\) by finding the minimal string among all substrings of s of length C(s), that is, \(s[i \dots i+C(s)-1]\) for all \(i \in [n]\).
The following lemma shows that almost all strings have a low string sensitivity.
Lemma 5.3
(String Sensitivity Distribution) Let s be a uniformly random string over \(\Sigma ^n\) and \(1 \le B \le n/2\). Then
where \(\alpha = | \Sigma |\). In particular,
Proof
Let \(s \in \Sigma ^n\) and \(0 \le i< j < n\). We claim that
This can be seen as follows. Let d be the number of members that appear in both sequences \(\{ i \bmod n, (i+1) \bmod n, \dots , (i+B-1) \bmod n \}\) and \(\{ j \bmod n, (j+1) \bmod n, \dots , (j+B-1) \bmod n \}\). It is clear that \(0 \le d < B\). We note that \(s[i \dots i+B-1] = s[j \dots j+B-1]\) implies the following system of B equations:
On the other hand, these B equations involve \(2B-d\) (random) characters. Therefore, there must be \((2B-d) - B = B-d\) independent characters, and the probability that the B equations hold is
Consequently, we have:
In particular, in the case of \(B = \lceil 3 \log _\alpha n \rceil \), it holds that \(\alpha ^B \ge n^3\) and we obtain:
\(\square \)
With the above preparation, we now can analyze the average-case query complexity of Algorithm 6. Let \(s \in \Sigma ^n\) be a uniformly random string over \(\Sigma ^n\) and \(B = \lceil 3\log _\alpha n \rceil \). Let k and \(k'\) denote the indices of the minimal and the second minimal substrings of length B of s. To compute k and \(k'\), by Lemma 3.5, Algorithm 6 needs to make \(O\left( \sqrt{n \log n}\right) \) queries to \(U_{\text {cmp}_B}\), which is equivalent to \(O\left( \sqrt{n \log n} \sqrt{B}\right) = O\left( \sqrt{n} \log n\right) \) queries to \(U_\text {in}\). On the other hand, it requires \(O(B) = O(\log n)\) queries to \(U_\text {in}\) in order to check whether \(\text {cmp}_{B}(k, k') = 1\), which is ignorable compared to other large complexities. Based on the result of \(\text {cmp}_{B}(k, k')\), we only need to further consider the following two cases:
Case 1. \(\text {cmp}_{B}(k, k') = 1\). Note that this case happens with probability
In this case, Algorithm 6 returns k immediately.
Case 2. \(\text {cmp}_{B}(k, k') \ne 1\). According to (9), this case happens with probability \(\le 1/n\). In this case, Algorithm 6 makes one query to \({\textbf {BasicLMSR}}(U_\text {in})\), which needs \(O\left( n^{3/4}\right) \) queries to \(U_\text {in}\) (by Theorem 5.2).
Combining the above two cases yields the average-case query complexity of Algorithm 6:
After the above discussions, we obtain:
Theorem 5.4
Algorithm 6 is an \(O\left( n^{3/4} \right) \) bounded-error quantum query algorithm for LMSR, whose average-case query complexity is \(O\left( \sqrt{n}\log n\right) \).
Algorithm 6 for Theorem 5.4 can be made time-efficient by an argument similar to that given in Section 5.1 for time and space efficiency.
6 Lower Bounds of LMSR
In this section, we establish average-case and worst-case lower bounds of both classical and quantum algorithms for the LMSR problem and thus prove Theorem 1.2.
The notion of block sensitivity is the key tool we use to obtain lower bounds. Let \(f: \{0, 1\}^n \rightarrow \{0, 1\}\) be a Boolean function. If \(x \in \{0, 1\}^n\) is a binary string and \(S \subseteq [n]\), we use \(x^S\) to denote the binary string obtained by flipping the values of \(x_i\) for \(i \in S\), where \(x_i\) is the i-th character of x:
where \(\bar{u}\) denotes the negation of u, i.e. \(\bar{0} = 1\) and \(\bar{1} = 0\). The block sensitivity of f on input x, denoted \( bs _x(f)\), is the maximal number m such that there are m disjoint sets \(S_1, S_2, \dots , S_m \subseteq [n]\) for which \(f(x) \ne f(x^{S_i})\) for \(1 \le i \le m\).
6.1 Average-case Lower Bounds
For settling the average-case lower bound, we need the following useful result about block sensitivities given in [1].
Theorem 6.1
(General bounds for average-case complexity, [1, Theorem 6.3]) For every function \(f: \{0, 1\}^n \rightarrow \{0, 1\}\) and probability distribution \(\mu : \{0, 1\}^n \rightarrow [0, 1]\), we have \(R^\mu (f) = \Omega \left( \mathbb {E}_{x \sim \mu }[ bs _x(f)]\right) \) and \(Q^\mu (f) = \Omega \left( \mathbb {E}_{x \sim \mu }\left[ \sqrt{ bs _x(f)}\right] \right) \).
In order to give a lower bound for LMSR by using Theorem 6.1, we need a binary function that can be reduced \({\text {LMSR}}(x)\) to but is simpler than it. Here, we choose \({\text {LMSR}}_0(x) = {\text {LMSR}}(x) \bmod 2\). Obviously, we can compute \({\text {LMSR}}(x)\), then \({\text {LMSR}}_0(x)\) is immediately obtained. Moreover, \({\text {LMSR}}_0\) enjoys the following basic property:
Lemma 6.2
Let \(x \in \{0, 1\}^n\) and \(0 \le r < n\). Then \( bs _x({\text {LMSR}}_0) = bs _{x^{(r)}}({\text {LMSR}}_0)\).
Proof
Let \(m = bs _x({\text {LMSR}}_0)\) and \(S_1, S_2, \dots , S_m\) be the m disjoint sets for which \({\text {LMSR}}_0(x) \ne {\text {LMSR}}_0\left( x^{S_i}\right) \) for \(1 \le i \le m\). We define \(S_i' = \{ (a+r) \bmod n: a \in S_i \}\) for \(1 \le i \le m\). Then it can be verified that \({\text {LMSR}}_0\left( x^{(r)}\right) \ne {\text {LMSR}}_0\left( \left( x^{(r)}\right) ^{S_i}\right) \) for \(1 \le i \le m\). Hence, \( bs _{x^{(r)}}({\text {LMSR}}_0) \ge m = bs _x({\text {LMSR}}_0)\).
The same argument yields that \( bs _{x}({\text {LMSR}}_0) \ge bs _{x^{(r)}}({\text {LMSR}}_0)\). Therefore, \( bs _x({\text {LMSR}}_0) = bs _{x^{(r)}}({\text {LMSR}}_0)\). \(\square \)
Next, we establish a lower bound for \( bs _x({\text {LMSR}}_0)\).
Lemma 6.3
Let \(x \in \{0, 1\}^n\). Then
where C(x) is the string sensitivity of x.
Proof
We first note that inequality (10) is trivially true when \(C(x) > n/5\) because the right hand side is equal to 0. For the case of \(C(x) \le n/5\), our proof is carried out in two steps:
Step 1. Let us start from the special case of \({\text {LMSR}}(x) = 0\). Note that \({\text {LMSR}}_0(x) = 0\). Let \(B = C(x)\). We split x into \((k + 1)\) substrings \(x = y_1 y_2 \dots y_k y_{k+1}\), where \(| y_i | = B\) for \(1 \le i \le k\), \(| y_{k+1} | = n \bmod B\), and \(k = \lfloor n/B \rfloor \). By the assumption that \(C(x) = B\), we have \(y_1 < \min \{y_2, y_3, \dots , y_k\}\). It holds that \(y_1y_2 > 0^{2B}\); otherwise, \(y_1 = y_2 = 0^B\), and then a contradiction \(C(x) > B\) arises.
Let \(m = \lfloor (k-1)/4 \rfloor \). We select some of \(y_i\)s and divide them into m groups (and the others are ignored). For every \(1 \le i \le m\), the i-th group is \(z_i = y_{4i-2} y_{4i-1} y_{4i} y_{4i+1}\). Let \(L_i\) be the number of characters in front of \(z_i\). Then \(L_i = (4i-3)B\). We claim that \( bs _x({\text {LMSR}}_0) \ge m\) by explicitly constructing m disjoint sets \(S_1, S_2, \dots , S_m \subseteq [n]\) such that \({\text {LMSR}}_0(x) \ne {\text {LMSR}}_0\left( x^{S_i}\right) \) for \(1 \le i \le m\):
-
1.
If \(L_i\) is even, then we define:
$$ S_i = \{ L_i \le j \le L_i+2B: x_j \ne \delta _{j, L_i} \}, $$where \(\delta _{x, y}\) is the Kronecker delta, that is, \(\delta _{x, y}=1\) if \(x = y\) and 0 otherwise.
-
2.
If \(L_i\) is odd, then we define:
$$ S_i = \{ L_i+1 \le j \le L_i+2B+1: x_j \ne \delta _{j, L_i+1} \}. $$
Note that \(S_i \ne \emptyset \), and \(0^{2B}\) is indeed the substring of \(x^{S_i}\) that starts at the index \(L_i+1\) if \(L_i\) is even and at \(L_i+2\) if \(L_i\) is odd. That is,
Then we conclude that \({\text {LMSR}}_0\left( x^{S_i}\right) = 1\) for \(1 \le i \le m\). Consequently,
Step 2. Now we remove the condition that \({\text {LMSR}}(x) = 0\) in Step 1. Let \(r = {\text {LMSR}}_0(x)\) and we consider the binary string \(x^{(r)}\). Note that \({\text {LMSR}}\left( x^{(r)}\right) = 0\). By Lemma 6.2, we have:
Therefore, inequality (10) holds for all \(x \in \{0, 1\}^n\) with \(C(x) \le n/5\). \(\square \)
We remark that inequality (10) can be slightly improved:
by splitting x more carefully. However, Lemma 6.3 is sufficient for our purpose. With it, we obtain a lower bound of the expected value of \( bs _x({\text {LMSR}}_0)\) when x is uniformly distributed:
Lemma 6.4
Let \( unif : \{0, 1\}^n \rightarrow [0, 1]\) be the uniform distribution that \( unif (x) = 2^{-n}\) for every \(x \in \{0, 1\}^n\). Then
Proof
By Lemmas 5.3 and 6.3, we have:
A similar argument yields that \(\mathbb {E}_{x \sim unif }\left[ \sqrt{ bs _x({\text {LMSR}}_0)}\right] = \Omega \left( \sqrt{n/\log n}\right) \). \(\square \)
By combining the above lemma with Theorem 6.1, we obtain lower bounds for randomized and quantum average-case bounded-error algorithms for LMSR:
6.2 Worst-case Lower Bounds
Now we turn to consider the worst-case lower bounds. The idea is similar to the average case. First, the following result similar to Theorem 6.1 was also proved in [1].
Theorem 6.5
([1]) Let A be a bounded-error algorithm for some function \(f: \{0, 1\}^n \rightarrow \{0, 1\}\).
-
1.
If A is classical, then \(T_A(x) = \Omega \left( bs _x(f)\right) \); and
-
2.
If A is quantum, then \(T_A(x) = \Omega \left( \sqrt{ bs _x(f)}\right) \).
We still consider the function \({\text {LMSR}}_0\) in this subsection. The following lemma shows that its block sensitivity can be linear in the worst case.
Lemma 6.6
There is a string \(x \in \{0, 1\}^n\) such that \( bs _x({\text {LMSR}}_0) \ge \lfloor n/2 \rfloor \).
Proof
Let \(x = 1^n\). Then \({\text {LMSR}}(x) = 0\) and \({\text {LMSR}}_0(x) = 0\). We can choose \(m = \lfloor n/2 \rfloor \) disjoint sets \(S_1, S_2, \dots , S_m\) with \(S_i = \{ 2i-1 \}\). It may be easily verified that \({\text {LMSR}}_0\left( x^{S_i}\right) = 1\) for every \(1 \le i \le m\). Thus, by the definition of block sensitivity, we have \( bs _x({\text {LMSR}}_0) \ge \lfloor n/2 \rfloor \). \(\square \)
Combining the above lemma with Theorem 6.5, we conclude that \(R({\text {LMSR}}_0) = \Omega (n)\) and \(Q({\text {LMSR}}_0) = \Omega \left( \sqrt{n}\right) \), which give a lower bound for randomized and one for quantum worst-case bounded-error algorithms for LMSR, respectively. We have another more intuitive proof for the worst-case lower bound for quantum bounded-error algorithms and postpone into Appendix F.
7 Applications
In this section, we present some practical applications of our quantum algorithm for LMSR.
7.1 Benzenoid Identification
The first application of our algorithm is a quantum solution to a problem about chemical graphs. Benzenoid hydrocarbons are a very important class of compounds [35, 36] and also popular as mimics of graphene (see [63, 77, 78]). Several algorithmic solutions to the identification problem of benzenoids have been proposed in the previous literature; for example, Bašić [11] identifies benzenoids by boundary-edges code [42] (see also [55]).
Formally, the boundary-edges code (BEC) of a benzenoid is a finite string over a finite alphabet \(\Sigma _6 = \{ 1, 2, 3, 4, 5, 6 \}\). The canonical BEC of a benzenoid is essentially the lexicographically maximal string among all rotations of any of its BECs and their reverses. Our quantum algorithm for LMSR can be used to find the canonical BEC of a benzenoid in \(O\left( n^{3/4}\right) \) queries, where n is the length of its BEC.
More precisely, it is equivalent to find the lexicographically minimal one if we assume that the lexicographical order is \(6< 5< 4< 3< 2 < 1\). Suppose a benzenoid has a BEC s. Our quantum algorithm is described as follows:
-
1.
Let \(i = {\text {LMSR}}(s)\) and \(i^R = {\text {LMSR}}(s^R)\), where \(s^R\) denotes the reverse of s. This is achieved by Algorithm 5 in \(O(n^{3/4})\) query complexity.
-
2.
Return the smaller one between \(s[i \dots i+n-1]\) and \(s^R[i^R \dots i^R+n-1]\). This is achieved by Algorithm 3 in \(O(\sqrt{n})\) query complexity.
It is straightforward to see that the overall query complexity is \(O(n^{3/4})\).
7.2 Disjoint-cycle Automata Minimization
Another application of our algorithm is a quantum solution to minimization of a special class of automata. Automata minimization is an important problem in automata theory [14, 44] and has many applications in various areas of computer science. The best known algorithm for minimizing deterministic automata is \(O(n \log n)\) [46], where n is the number of states. A few linear algorithms for minimizing some special automata are proposed in [10, 65], which are important in practice, e.g., dictionaries in natural language processing.
We consider the minimization problem of disjoint-cycle automata discussed by Almeida and Zeitoun in [10]. The key to this problem is a decision problem that checks whether there are two cycles that are equal to each other under rotations. Formally, suppose there are m cycles, which are described by strings \(s_1, s_2, \dots , s_m\) over a finite alphabet \(\Sigma \). It is asked whether there are two strings \(s_i\) and \(s_j\) (\(i \ne j\)) such that \({\text {SCR}}(s_i) = {\text {SCR}}(s_j)\). For convenience, we assume that all strings are of equal length n, i.e. \(| s_1 | = | s_2 | = \dots = | s_m | = n\).
A classical algorithm solving the above decision problem was developed in [10] with time complexity O(mn). With the help of our quantum algorithm for LMSR, this problem can be solved more efficiently. We employ a quantum comparison oracle \(U_\text {cmp}\) that compares strings by their canonical representations in the lexicographical order, where the corresponding classical comparator is:
and can be computed by finding \(r_i = {\text {LMSR}}(s_i)\) and \(r_j = {\text {LMSR}}(s_j)\). In particular, it can be done by our quantum algorithm for LMSR in \(O\left( n^{3/4}\right) \) queries. Then the lexicographical comparator in Algorithm 3 can be use to compare \(s_i[r_i \dots r_i + n - 1]\) and \(s_j[r_j \dots r_j + n - 1]\) in query complexity \(O\left( n^{3/4}\right) \). Furthermore, the problem of checking whether there are two strings that are equal to each other under rotations among the m strings may be viewed as the element distinctness problem with quantum comparison oracle \(U_\text {cmp}\), and thus can be solved by Ambainis’s quantum algorithm [9] with \(\tilde{O}\left( m^{2/3}\right) \) queries to \(U_\text {cmp}\). In conclusion, the decision problem can be solved in quantum time complexity \(\tilde{O}\left( m^{2/3}n^{3/4}\right) \), which is better than the best known classical O(mn) time.
References
Ambainis, A., de Wolf, R.: Average-case quantum query complexity. J. Phys. A Gen. Phys. 34(35), 6741–6754 (1999)
Aho, A.V., Hopcroft, J.E., Ullman, J.D.: The Design and Analysis of Computer Algorithms. Addison-Wesley (1974)
Apostolico, A., Iliopoulos, C.S., Paige, R.: An \(O(n \log n)\) cost parallel algorithm for the one function partitioning problem. In: Proceedings of the International Workshop on Parallel Algorithms and Architectures, pp. 70–76 (1987)
Akmal, S., Jin, C.: Near-optimal quantum algorithms for string problems. In: Proceedings of the 2022 Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 2791–2832 (2022)
Ahuja, A., Kapoor, S.: A quantum algorithm for finding the maximum. (1999). arXiv:quant-ph/9911082
Ambainis, A., Montanaro, A.: Quantum algorithms for search with wildcards and combinatorial group testing. Quantum. Inf. Comput. 14(5–6), 439–453 (2014)
Ambainis, A.: Quantum lower bounds by quantum arguments. In: Proceedings of the Thirty-Second Annual ACM Symposium on Theory of Computing, pp. 636–643 (2000)
Ambainis, A.: Quantum query algorithms and lower bounds. In: Classical and New Paradigms of Computation and their Complexity Hierarchies, pp. 15–32 (2004)
Ambainis, A.: Quantum walk algorithm for element distinctness. SIAM J. Comput. 37(1), 210–239 (2007)
Almeida, J., Zeitoun, M.: Description and analysis of a bottom-up DFA minimization algorithm. Inf. Process. Lett. 107(2), 52–59 (2008)
Bašić, N.: PhD thesis, Faculty of Mathematics and Physics. In: Algebraic approach to several families of chemical graphs. University of Ljubljana (2016)
Bennett, C.H., Bernstein, E., Brassard, G., Vazirani, U.: Strengths and weaknesses of quantum computing. SIAM J. Comput. 26(5), 1524–1540 (1997)
Beals, R., Buhrman, H., Cleve, R., Mosca, M., de Wolf, R.: Quantum lower bounds by polynomials. J. ACM 48(4), 778–797 (2001)
Berstel, J., Boasson, L., Carton, O., Fagnot, I.: Minimization of automata. (2010). arXiv:1010.5318
Boyer, M., Brassard, G., Hoeyer, P., Tapp, A.: Tight bounds on quantum searching. Fortschr. der Physik. 46(4–5), 493–505 (1998)
Buhrman, H., Cleve, R., de Wolf, R., Zalka, C.: Bounds for small-error and zero-error quantum algorithms. In: Proceedings of the Fortieth IEEE Annual Symposium on Foundations of Computer Science, pp. 358–368 (1999)
Bassino, F., Clément, J., Nicaud, C.: The standard factorization of Lyndon words: an average point of view. Discret. Math. 280(1), 1–25 (2005)
Buhrman, H., Cleve, R., Wigderson, A.: Quantum vs. classical communication and computation. In: Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, pp. 63–68 (1998)
Buhrman, H., de Wolf, R.: Complexity measures and decision tree complexity: A survey. Theor. Comput. Sci. 288(1), 21–43 (2002)
Boroujeni, M., Ehsani, S., Ghodsi, M., HajiAghayi, M., Seddighin, S.: Approximating edit distance in truly subquadratic time: Quantum and mapreduce. In: Proceedings of the 29th Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 1170–1189 (2018)
Booth, K.S.: Lexicographically least circular substrings. Inf. Process. Lett. 10(4–5), 240–242 (1980)
Barnum, H., Saks, M.: A lower bound on the quantum query complexity of read-once functions. J. Comput. Syst. Sci. 69(2), 244–258 (2004)
Buhrman, H., Špalek, R.: Quantum verification of matrix products. In: Proceedings of the 17th Annual ACM-SIAM Symposium on Discrete Algorithm, pp. 880–889 (2006)
Brandao, F.G.S.L., Svore, K.M.: Quantum speed-ups for solving semidefinite programs. In: Proceedings of the 58th Annual Symposium on Foundations of Computer Science, pp. 415–426 (2017)
Colbourn, C.J., Booth, K.S.: Linear time automorphism algorithms for trees, interval graphs, and planar graphs. SIAM J. Comput. 10(1), 203–225 (1980)
Cerf, N.J., Grover, L.K., Williams, C.P.: Nested quantum search and structured problems. Phys. Rev. A 61(3), 032303 (2000)
Cleve, R., Gavinsky, D., Yonge-Mallo, D.L.: Quantum algorithms for evaluating MIN-MAX trees. In: Theory of Quantum Computation, Communication, and Cryptography: Third Workshop, TQC 2008, pp. 11–15, (2008)
Crochemore, M., Hancart, C., Lecroq, T.: Algorithms on Strings. Cambridge University Press (2007)
Cleve, R., Iwama, K., Le Gall, F., Nishimura, H., Tani, S., Teruyama, J., Yamashita, S.: Reconstructing strings from substrings with quantum queries. In Proceedings of the 13th Scandinavian Symposium and Workshops on Algorithm Theory, pp. 388–397 (2012)
Childs, A.M., Kothari, R., Kovacs-Deak, M., Sundaram, A., Wang, D.: Quantum divide and conquer. (2022) arXiv:2210.06419
Crochemore, M., Rytter, W.: Text Algorithms. Oxford University Press (1994)
Crochemore, M.: String-matching on ordered alphabets. Theor. Comput. Sci. 92(1), 33–47 (1992)
Dürr, C., Høyer, P.: A quantum algorithm for finding the minimum. (1996). arXiv:quant-ph/9607014
Dragon, P.B., Hernandez, O.I., Sawada, J., Williams, A., Wong, D.: Constructing de Bruijn sequences with co-lexicographic order: The k-ary Grandmama sequence. Eur. J. Comb. 72, 1–11 (2018)
Dias, J.R.: Handbook of Polycyclic Hydrocarbons: Part A. Elsevier, Benzenoid Hydrocarbons. Physical Sciences Data (1987)
Dias, J.R.: Handbook of Polycyclic Hydrocarbons: Part B. Elsevier, Polycyclic Isomers and Heteroatom Analogs of Benzenoid Hydrocarbons. Physical Sciences Data (1988)
Duval, J.P.: Factorizing words over an ordered alphabet. J. Algoritm. 8(8), 363–381 (1983)
Gonnet, G.H., Baeza-Yates, R.A., Snider, T.: New indices for text: PAT trees and PAT arrays. In: Information Retrieval: Data Structures and Algorithms, pp. 66–82 (1992)
Grover, L.K.: A fast quantum mechanical algorithm for database search. In: Proceedings of the Twenty-eighth Annual ACM Symposium onTheory of Computing, pp. 212–219, (1996)
Gross, J.L., Yellen, J.: Handbook of Graph Theory. CRC Press (2003)
Harrow, A.W., Hassidim, A., Lloyd, S.: Quantum algorithm for linear systems of equations. Phys. Rev. Lett. 103(15), 150502 (2009)
Hansen, P., Lebatteux, C., Zheng, M.: The boundary-edges code for polyhexes. J. Mol. Struct: THEOCHEM 363(2), 237–247 (1996)
Høyer, P., Mosca, M., de Wolf, R.: Quantum search on bounded-error inputs. In: International Colloquium on Automata, Languages, and Programming, pp. 291–299 (2003)
Hopcroft, J.E., Motwani, R., Ullman, J.D.: Introduction to Automata Theory, Languages, and Computation, 2nd edn. Addison-Wesley (2000)
Hoeffding, W.: Probability inequalities for sums of bounded random variables. J. Am. Stat. Assoc. 58(301), 13–30 (1963)
Hopcroft, J.E.: An \(n \log n\) algorithm for minimizing states in a finite automaton. In: Proceedings of an International Symposium on the Theory of Machines and Computations, pp. 189–196 (1971)
Iliopoulos, C.S., Smyth, W.F.: PRAM algorithms for identifying polygon similarity. In: Proceedings of the International Symposium on Optimal Algorithms, pp. 25–32 (1989)
Iliopoulos, C.S., Smyth, W.F.: Optimal algorithms for computing the canonical form of a circular string. Theor. Comput. Sci. 92(1), 87–105 (1992)
Iliopoulos, C.S., Smyth, W.F.: A fast average case algorithm for Lyndon decomposition. Int. J. Comput. Math. 57(1–2), 15–31 (1994)
Jeuring, J.T.: Theories for algorithm calculation. Utrecht University (1993)
Jeffery, S., Kothari, R., Magniez, F.: Nested quantum walks with quantum data structures. In: Proceedings of the Twenty-Fourth Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 1474–1485 (2013)
Jin, C., Nogler, J.: Quantum speed-ups for string synchronizing sets, longest common substring, and \(k\)-mismatch matching. In: Proceedings of the 2023 Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 5090–5121 (2023)
Kapralov, R., Khadiev, K., Mokut, J., Shen, Y., Yagafarov, M.: Fast classical and quantum algorithms for online \(k\)-server problem on trees. (2020) arXiv:2008.00270
Knuth, D., Morris, J.H., Pratt, V.: Fast pattern matching in strings. SIAM J. Comput. 6(2), 323–350 (1977)
Kovič, J., Pisanski, T., Balaban, A.T., Fowler, P.W.: On symmetries of benzenoid systems. MATCH Commun. Math. Comput. Chem. 72(1), 3–26 (2014)
Kärkkäinen, J., Sanders, P., Burkhardt, S.: Linear work suffix array construction. J. ACM 53(6), 918–9360 (2006)
Le Gall, F., Seddighin, S.: Quantum meets fine-grained complexity: Sublinear time quantum algorithms for string problems. In: Proceedings of the 13th Innovations in Theoretical Computer Science Conference, pp. 97:1–97:23 (2022)
Maes, M.: Polygonal shape recognition using string-matching techniques. Pattern Match. 24(5), 433–440 (1991)
McCreight, E.M.: A space-economical suffix tree construction algorithm. J. ACM 23(2), 262–272 (1976)
Manber, U., Myers, G.: Suffix arrays: a new method for on-line string searches. In: Proceedings of the First Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 319–327 (1990)
Montanaro, A.: Quantum pattern matching fast on average. Algorithmica 77, 16–39 (2017)
Magniez, F., Santha, M., Szegedy, M.: Quantum algorithms for the triangle problem. SIAM J. Comput. 37(2), 413–424 (2007)
Papadakis, R., Li, H., Bergman, J., Lundstedt, A., Jorner, K., Ayub, R., Haldar, S., Jahn, B.O., Denisova, A., Zietz, B., Lindh, R., Sanyal, B., Grennberg, H., Leifer, K., Ottosson, H.: Metal-free photochemical silylations and transfer hydrogenations of benzenoid hydrocarbons and graphene. Nat Commun. 7, 12962 (2016)
Puppis, G.: Automata for Branching and Layered Temporal Structures: An Investigation into Regularities of Infinite Transition Systems. Springer Science & Business Media (2010)
Revuz, D.: Minimisation of acyclic deterministic automata in linear time. Theor. Comput. Sci. 92(1), 181–189 (1992)
Ramesh, H., Vinay, V.: String matching in \(\tilde{O}(\sqrt{n} + \sqrt{m})\) quantum time. J. Discret. Algoritm. 1(1), 103–110 (2003)
Rytter, W.: On maximal suffixes and constant-space linear-time versions of KMP algorithm. Theor. Comput. Sci. 299(1–3), 763–774 (2003)
Shiloach, Y.: A fast equivalence-checking algorithm for circular lists. Inf. Process. Lett. 8(5), 236–238 (1979)
Shiloach, Y.: Fast canonization of circular strings. J. Algoritm. 2(2), 107–121 (1981)
Shor, P.W.: Algorithms for quantum computation: discrete logarithms and factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, pp. 124–134 (1994)
Sawada, J., Williams, A., Wong, D.: A surprisingly simple de Bruijn sequence construction. Discret. Math. 339(1), 127–131 (2016)
van Apeldoorn, J., Gilyén, A., Gribling, S., de Wolf, R.: Quantum SDP-solvers: better upper and lower bounds. In: Proceedings of the Fifty-eighth Annual Symposium on Foundations of Computer Science, pp 403–414 (2017)
Vishkin, U.: Deterministic sampling - a new technique for fast pattern matching. In: Proceedings of the Twenty-Second Annual ACM Symposium on Theory of Computing, pp. 170–180 (1990)
van Lint, J.H., Wilson, R.W., Wilson, R.M.: A Course in Combinatorics. Cambridge University Press (2001)
Wang, Q.: A note on quantum divide and conquer for minimal string rotation. (2022). arXiv:2210.09149
Weiner, P.: Linear pattern matching algorithms. In: Proceedings of the Fourteenth Annual Symposium on Switching and Automata Theory, pp. 1–11 (1973)
Wang, W.L., Meng, S., Kaxiras, E.: Graphene NanoFlakes with large spin. Nano Lett. 8(1), 241–245 (2008)
Wassmann, T., Seitsonen, A.P., Saitta, A.M., Lazzeri, M., Mauri, F.: Structure, stability, edge states, and aromaticity of graphene ribbons. Phys. Rev. Lett. 101(9), 096402 (2008)
Zalka, C.: Grover’s quantum searching algorithm is optimal. Phys. Rev. A 60(4), 2746–2751 (1999)
Acknowledgements
We would like to thank the anonymous referees for their valuable comments and suggestions, which helped to improve this paper. Qisheng Wang would like to thank François Le Gall for helpful discussions in an earlier version of this paper.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 61832015. Qisheng Wang was also supported in part by the MEXT Quantum Leap Flagship Program (MEXT Q-LEAP) grants No. JPMXS0120319794.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Probability Analysis of Majority Voting
For convenience of the reader, let us first recall the Hoeffding’s inequality [45].
Theorem A.1
(The Hoeffding’s inequality, [45]) Let \(X_1, X_2, \dots , X_n\) be independent random variables with \(0 \le X_i \le 1\) for every \(1 \le i \le n\). We define the empirical mean of these variables by
Then for every \(\varepsilon > 0\), we have:
We only consider the case where b is true. In this case, we have \(q = \lceil 36 \ln m \rceil \) independent random variables \(X_1, X_2, \dots , X_q\), where for \(1 \le i \le q\), \(X_i = 0\) with probability \(\le 1/3\) and \(X_i = 1\) with probability \(\ge 2/3\) (Here, \(X_i = 1\) means the i-th query is true and 0 otherwise). It holds that \(\mathbb {E}[\bar{X}] \ge 2/3\). By Theorem A.1 and letting \(\varepsilon = 1/6\), we have:
By choosing \(\hat{b}\) to be true if \(\bar{X} > 1/2\) and false otherwise, we obtain \(\Pr \left[ \hat{b} = b\right] = 1 - \Pr \left[ \bar{X} \le 1/2\right] \ge 1-1/m^2\) as required in Algorithm 1.
Appendix B: A Framework of Nested Quantum Algorithms
In this appendix, we provide a general framework to explain how the improvement given in Section 3 can be achieved on nested quantum algorithms composed of quantum search and quantum minimum finding.
This framework generalizes multi-level AND-OR trees. In an ordinary AND-OR tree, a Boolean value is given at each of its leaves, and each non-leaf node is associated with an AND or OR operation which alternates in each level. A query-optimal quantum algorithm for evaluation of constant-depth AND-OR trees was proposed in [43]. Our framework can be seen as a generalization of fault tolerant quantum search studied in [43], which deals with the extended MIN-MAX-AND-OR trees which allow four basic operations and work for non-Boolean cases. Moreover, combining the error reduction idea in [16], we also provide an error reduction for nested quantum algorithms. Our results will be formally stated later in Lemma B.1.
Suppose there is a d-level nested quantum algorithm composed of d bounded-error quantum algorithms \(A_1, A_2, \dots , A_d\) on a d-dimensional input \(x(\theta _{d-1}, \dots , \theta _{2}, \theta _{1}, \theta _{0})\) given by an (exact) quantum oracle \(U_0\):
where \(\theta _k \in [n_k]\) for \(k \in [d]\) and \(d \ge 2\). For \(1 \le k \le d\), \(A_k\) is a bounded-error quantum algorithm given parameters \(\theta _{d-1}, \dots , \theta _{k}\) that computes the function \(f_k(\theta _{d-1}, \dots , \theta _k)\). In particular, \(f_0 \equiv x\), and \(A_d\) computes a single value \(f_d\), which is considered to be the output of the nested quantum algorithm \(A_1, A_2, \dots , A_d\).
Let \(t_k \in \{s, m\}\) denote the type of \(A_k\), where s indicates the search problem and m indicates the minimum finding problem. Let \(S_m = \{ 1 \le k \le d: t_k = m \}\) denote the set of indices of the minimum finding algorithms. The behavior of algorithm \(A_k\) is defined as follows:
-
1.
Case 1. \(t_k = s\). Then \(A_k\) is associated with a checker \(p_k(\theta _{d-1}, \dots , \theta _k, \xi )\) that determines whether \(\xi \) is a solution (which returns 1 for “yes” and 0 for “no”). \(A_k\) is to find a solution \(i \in [n_{k-1}]\) such that
$$ p_k(\theta _{d-1}, \dots , \theta _k, f_{k-1}(\theta _{d-1}, \dots , \theta _k, i)) = 1 $$(which returns \(-1\) if no solution exists). Here, computing \(p_k(\theta _{d-1}, \dots , \theta _k, f_{k-1}\) \((\theta _{d-1}, \dots , \theta _k, i))\) requires the value of \(f_{k-1}(\theta _{d-1}, \dots , \theta _k, i)\), which in turn requires a constant number of queries to \(A_{k-1}\) with parameters \(\theta _{d-1}, \dots , \theta _k, i\).
-
2.
Case 2. \(t_k = m\). Then \(A_k\) is associated with a comparator \(c_k(\theta _{d-1}, \dots , \theta _k, \alpha , \beta )\) that compares \(\alpha \) and \(\beta \). \(A_k\) is to find the index \(i \in [n_{k-1}]\) of the minimal element such that
$$ c_k(\theta _{d-1}, \dots , \theta _k, f_{k-1}(\theta _{d-1}, \dots , \theta _{k}, j), f_{k-1}(\theta _{d-1}, \dots , \theta _{k}, i)) = 0 $$for all \(j \ne i\). Here, computing \(c_k(\theta _{d-1}, \dots , \theta _k, f_{k-1}(\theta _{d-1}, \dots , \theta _{k}, j), f_{k-1}\) \((\theta _{d-1}, \dots , \theta _{k}, i))\) requires the value of \(f_{k-1}(\theta _{d-1}, \dots , \theta _{k}, j)\) and \(f_{k-1}(\theta _{d-1}, \dots ,\) \(\theta _{k}, i)\), which requires a constant number of queries to \(A_{k-1}\) with parameters \(\theta _{d-1}, \dots , \theta _k, j\) and \(\theta _{d-1}, \dots , \theta _k, i\), respectively.

Quantum pattern matching algorithm for aperiodic strings
The following lemma settles the query complexity of nested quantum algorithms, which shows that nested algorithms can do much better than naively expected.
Lemma B.1
(Nested quantum algorithms) Given a d-level nested quantum algorithm \(A_1, A_2, \dots , A_d\), where \(d \ge 2\), and \(n_0, n_1, \dots , n_{d-1}\), \(S_m, f_d\) are defined as above. Then:
-
1.
There is a bounded-error quantum algorithm that computes \(f_d\) with query complexity
$$ O\left( \sqrt{\prod _{k=0}^{d-1} n_k} \right) . $$ -
2.
There is a quantum algorithm that computes \(f_d\) with error probability \(\le \varepsilon \) with query complexity
$$ O\left( \sqrt{\prod _{k=0}^{d-1} n_k \log \frac{1}{\varepsilon }} \right) . $$
Proof
Immediately yields by Theorems 3.1, 3.2, Lemmas 3.4 and 3.5. \(\square \)
Remark B.1
Lemma B.1 can be seen as a combination of Theorems 3.1, 3.2, Lemmas 3.4 and 3.5. For convenience, we assume \(n_0 = n_1 = \dots = n_{d-1} = n\) in the following discussions. Note that traditional probability amplification methods for randomized algorithms usually introduce an \(O\left( \log ^{d-1} n\right) \) slowdown for d-level nested quantum algorithms by repeating the algorithm \(O(\log n)\) times in each level. However, our method obtains an extremely better O(1) factor as if there were no errors in oracles at all.
Remark B.2
Lemma B.1 only covers a special case of nested quantum algorithms. A more general form of nested quantum algorithms can be described as a tree rather than a sequence, which allows intermediate quantum algorithms to compute their results by queries to several low-level quantum algorithms. We call them adaptively nested quantum algorithms, and an example of this kind algorithm is presented in Appendix D for pattern matching (see Fig. 1).
Appendix C: Remarks for Quantum Deterministic Sampling
Algorithm 4 uses several nested quantum algorithms as subroutines, but they are not described as nested quantum algorithms explicitly. Here, we provide an explicit description for Line 10 in Algorithm 4 as an example. Let \(\theta _0 \in [l]\) and \(\theta _1 \in [n]\). Then:
-
The 0-level function is
$$ f_0(\theta _1, \theta _0) = {\left\{ \begin{array}{ll} 1 &{} \theta _1 \le i_{\theta _0} < \theta _1 + n \wedge s[i_{\theta _0} - \theta _1] \ne s[i_{\theta _0} - \delta ], \\ 0 &{} \text {otherwise}, \end{array}\right. } $$which checks whether candidate \(\theta _1\) does not match the current deterministic sample at the \(\theta _0\)-th checkpoint.
-
The 1-level function is
$$ f_1(\theta _1) = {\left\{ \begin{array}{ll} 0 &{} \theta _1 > Q \vee \exists i, f_0(\theta _1, i) = 1, \\ 1 &{} \text {otherwise}, \end{array}\right. } $$which checks candidate \(\theta _1\) matches the current deterministic sample at all checkpoints.
-
The 2-level function is
$$ f_2 = \min \left\{ i: f_1(i) = 1 \right\} , $$which finds the first candidate of \(\delta \).
By Lemma B.1, \(f_2\) can be computed with error probability \(\le \varepsilon = 1/6m^2\) in
Appendix D: Quantum Algorithm for Pattern Matching
In this appendix, we give a detailed description of our quantum algorithm for pattern matching.
1.1 D.1 Quantum Algorithm for String Periodicity
The algorithm will be presented in the form of a nested quantum algorithm. Suppose a string \(s \in \Sigma ^n\) is given by a quantum oracle \(U_s\) that \(U_s| i, j \rangle = | i, j\oplus s[i] \rangle \). We are asked to check whether s is periodic, and if yes, find its period.
Let \((\delta ; i_0, i_1, \dots , i_{l-1})\) be a deterministic sample of s. We need a 2-level nested quantum algorithm. Let \(\theta _0 \in [l]\) and \(\theta _1 \in [n]\). Then:
-
The 0-level function is
$$ f_0(\theta _1, \theta _0) = {\left\{ \begin{array}{ll} 1 &{} \theta _1 \le i_{\theta _0} < \theta _1+n \wedge s[i_{\theta _0}-\theta _1] = s[i_{\theta _0}-\delta ], \\ 0 &{} \text {otherwise}, \end{array}\right. } $$which checks whether offset \(\theta _1\) matches the deterministic sample at the \(\theta _0\)-th checkpoint. There is obviously an exact quantum oracle that computes \(f_0(\theta _1, \theta _0)\) with a constant number of queries to \(U_s\).
-
The 1-level function is
$$ f_1(\theta _1) = {\left\{ \begin{array}{ll} 0 &{} \exists i \in [l], f_0(\theta _1, i) = 1, \\ 1 &{} \text {otherwise}, \end{array}\right. } $$where \(f_1(\theta _1)\) means offset \(\theta _1\) matches the deterministic sample of s. The 2-level function is
$$ f_2 = \min \{ i \in [n]: f_1(i) = 1 \}, $$which finds the minimal offset that matches the deterministic sample.
By Lemma B.1, we obtain an \(O(\sqrt{nl})\) bounded-error quantum algorithm that finds the smallest possible offset \(\delta _1\) of the deterministic sample of s. According to \(\delta _1\), we define another 2-level function
which finds the second minimal offset that matches the deterministic sample of s, where \(\min \emptyset = \infty \). Similarly, we can find the second smallest offset \(\delta _2\) of the deterministic sample of s in query complexity \(O\left( \sqrt{nl} \right) \) with bounded-error. If \(\delta _2 = \infty \), then s is aperiodic; otherwise, s is periodic with period \(d = \delta _2 - \delta _1\). Therefore, we obtain an \(O\left( \sqrt{n \log n}\right) \) bounded-error quantum algorithm that checks whether a string is periodic and, if yes, finds its period.
1.2 D.2 Quantum Algorithm for Pattern Matching
Suppose text \(t \in \Sigma ^n\) and pattern \(p \in \Sigma ^m\), and a deterministic sample of p is \((\delta ; i_0, i_1, \dots , i_{l-1})\). The idea for pattern matching is to split the text t into blocks of length \(L = \lfloor m/4 \rfloor \), the i-th (0-indexed) of which consists of indices ranged from iL to \(\min \{(i+1)L, n\} - 1\). Our algorithm applies to the case of \(m \ge 4\), but does not to the case \(1 \le m \le 3\), where a straightforward quantum search is required (we omit it here).
The key step for pattern matching is to find a candidate \(h_i\) for \(0 \le i < \lceil n/L \rceil \), indicating the first occurrence in the i-th block with starting index \(iL \le j < \min \{(i+1)L, n\}\), where \(j+m \le n\) and \(t[j \dots j+m-1] = p\). Formally,
where \(\min \emptyset = \infty \). Note that (6) is similar to (11) but without the condition of \(j + m \le n\), which can easily removed from our algorithm given in the following discussion. In the previous subsection, we presented an efficient quantum algorithm that checks whether the string is periodic or not. Then we are able to design an quantum algorithm for pattern matching. Let us consider the cases of aperiodic patterns and periodic patterns, separately:
1.2.1 D.2.1 Aperiodic Patterns
The Algorithm For an aperiodic pattern p, \(h_i\) can be computed in the following two steps:
-
1.
Search j from \(iL \le j < \min \{(i+1)L, n\}\) such that \(t[i_k - \delta + j] = p[i_k - \delta ]\) for every \(k \in [l]\) (we call such j a candidate of matching). For every j, there is an \(O(\sqrt{l})\) bounded-error quantum algorithm to check whether \(t[i_k - \delta + j] = p[i_k - \delta ]\) for every \(k \in [l]\). Therefore, finding any j requires \(O\left( \sqrt{Ll}\right) = O\left( \sqrt{m \log m}\right) \) queries (by Theorem 3.1).
-
2.
Check whether the index j found in the previous step satisfies \(j+m \le n\) and \(t[j \dots j+m-1] = p\). This can be computed by quantum search in \(O\left( \sqrt{m}\right) \) queries. If the found index j does not satisfy this condition, then \(h_i = \infty \); otherwise, \(h_i = j\).
It is clear that \(h_i\) can be computed with bounded-error in \(O\left( \sqrt{m \log m}\right) \) queries according to the above discussion. Recall that p appears in t at least once, if and only if there is at least a \(0 \le i < \lceil n/L \rceil \) such that \(h_i = 1\). By Theorem 3.1, this can be checked in \(O\left( \sqrt{n/L} \sqrt{m \log m}\right) = O\left( \sqrt{n \log m}\right) \) queries.
Correctness Note that in the i-th block, if there is no such j or there are more than two values of j such that \(t[i_k - \delta + j] = p[i_k - \delta ]\) for every \(k \in [l]\), then there is no matching in the i-th block. More precisely, we have:
Lemma D.1
(The Ricochet Property [73]) Let \(p \in \Sigma ^m\) be aperiodic, \((\delta ; i_0, i_1\!, \dots , \!i_{l\!-\!1})\) be a deterministic sample, and \(t \in \Sigma ^n\) be a string of length \(n \ge m\), and let \(j \in [n-m+1]\). If \(t[i_k+j-\delta ] = p[i_k-\delta ]\) for every \(k \in [l]\), then \(t[j' \dots j'+m-1] \ne p\) for every \(j' \in [n-m+1]\) with \(j-\delta \le j' < j-\delta +\lfloor m/2 \rfloor \).
Proof
Assume that \(t[j' \dots j'+m-1] = p\) for some \(j-\delta \le j' < j-\delta +\lfloor m/2 \rfloor \). Let \(x = \delta -j+j'\). Note that \(0 \le x < \lfloor m/2 \rfloor \). We further assume that \(x \ne \delta \). Then by the definition of a deterministic sample, there exists \(k \in [l]\) such that \(x \le i_k < x+m\) and \(p[i_k-x] \ne p[i_k - \delta ]\). On the other hand, \(p[i_k-x] = t[j'+i_k-x] = t[i_k+j-\delta ] = p[i_k-\delta ]\). A contradiction arises, which implies \(x = \delta \) and therefore \(j = j'\). \(\square \)
We can see that if there are two different indices \(j_1, j_2\) in the i-th block such that \(t[i_k - \delta + j_r] = p[i_k - \delta ]\) for every \(k \in [l]\) and \(r \in \{1, 2\}\), it must hold that \(| j_1-j_2 | \le m/4\), since each block has length \(L = \lfloor m/4 \rfloor \). If we apply Lemma D.1 on \(j_1\), then \(t[j_2 \dots j_2+m-1] \ne p\); and if we apply it on \(j_2\), then \(t[j_1 \dots j_1+m-1] \ne p\). Thus, we conclude that neither \(j_1\) nor \(j_2\) can be a starting index of occurrence p in t. As a result, there is at most one candidate of matching in each block.
A Description in the Form of a Nested Quantum Algorithm. The above algorithm can be more clearly described as a 3-level nested quantum algorithm.
-
The level-0 function is defined by
$$ f_0(\theta _2, \theta _1, \theta _0) = {\left\{ \begin{array}{ll} 1 &{} i_{\theta _0} - \delta + \theta _2L + \theta _1 \in [n] \wedge t[i_{\theta _0} - \delta + \theta _2L + \theta _1] = p[i_{\theta _0} - \delta ] \\ 0 &{} \text {otherwise} \end{array}\right. }, $$which checks whether t matches p at the \(\theta _0\)-th checkpoint at the \(\theta _1\)-th index in the \(\theta _2\)-th block, where \(\theta _0 \in [l]\), \(\theta _1 \in [L]\) and \(\theta _2 \in \left[ \lceil n/L \rceil \right] \).
-
The level-1 function is defined by
$$ f_1(\theta _2, \theta _1) = {\left\{ \begin{array}{ll} 0 &{} \exists i \in [l], f_0(\theta _2, \theta _1, i) = 0, \\ 1 &{} \text {otherwise}, \end{array}\right. } $$which checks whether t matches the deterministic sample at the \(\theta _1\)-th index in the \(\theta _2\)-th block.
-
The level-2 function \(f_2(\theta _2)\) finds a solution \(i \in [L]\) such that \(f_1(\theta _2, i) = 1\), which indicates the (only) candidate in the \(\theta _2\)-th block.
-
The level-3 function \(f_3\) finds a matching among \(f_2(i)\) over all \(i \in [\lceil n/L \rceil ]\) by checking whether \(iL + f_2(i) + m \le n\) and \(t[iL + f_2(i) \dots iL + f_2(i) + m - 1] = p\), where the latter condition can be checked by a quantum searching algorithm, which can be formulated as a 1-level nested quantum algorithm:
-
The level-0 function
$$ g_0(\xi _2, \xi _1, \xi _0) = {\left\{ \begin{array}{ll} 1 &{} t[\xi _2L + \xi _1 + \xi _0] = p[\xi _0], \\ 0 &{} \text {otherwise}, \end{array}\right. } $$which checks whether the \(\xi _0\)-th character of substring of t starting at offset \(\xi _1\) in the \(\xi _2\)-th block matches the \(\xi _0\)-th character of p, where \(\xi _0 \in [m]\), \(\xi _1 \in [L]\) and \(\xi _0 \in \left[ \lceil n/L \rceil \right] \).
-
The 1-level function
$$ g_1(\xi _2, \xi _1) = {\left\{ \begin{array}{ll} 0 &{} \exists i \in [m], g_0(\xi _2, \xi _1, i) = 0,\\ 1 &{} \text {otherwise}, \end{array}\right. } $$which checks whether the substring of t starting at offset \(\xi _1\) in the \(\xi _2\)-th block matches p. Finally, we have that \(f_3\) finds a solution \(i \in \left[ \lceil n/L \rceil \right] \) such that \(iL + f_2(i) + m \le n\) and \(g_1(i, f_2(i)) = 1\).
-
The structure of our algorithm can be visualized as the tree in Fig. 1. It is worth noting that \(f_3\) calls both \(f_2\) and \(g_1\).
By a careful analysis, we see that the query complexity of the above algorithm is \(O\left( \sqrt{n \log m}\right) \).
1.2.2 D.2.2 Periodic Patterns
For a periodic pattern p, a similar result can be achieved with some minor modifications to the algorithm for an aperiodic pattern. First, we have:
Lemma D.2
(The Ricochet Property for periodic strings) Let \(p \in \Sigma ^m\) be periodic with period \(d \le m/2\), \((\delta ; i_0, i_1, \dots , i_{l-1})\) be a deterministic sample, and \(t \in \Sigma ^n\) be a string of length \(n \ge m\), and let \(j \in [n-m+1]\). If \(t[i_k+j-\delta ] = p[i_k-\delta ]\) for every \(k \in [l]\), then \(t[j' \dots j'+m-1] \ne p\) for every \(j' \in [n-m+1]\) with \(j-\delta \le j' < j-\delta +\lfloor m/2 \rfloor \) and \(j' \not \equiv j \pmod d\).
Proof
Similar to proof of Lemma D.1. \(\square \)
Now in order deal with periodic pattern p, the algorithm for an aperiodic pattern can be modified as follows. For the i-th block, in order to compute \(h_i\), we need to find (by minimum finding) the leftmost and the rightmost candidates \(j_l\) and \(j_r\), which requires \(O\left( \sqrt{Ll} \right) = O\left( \sqrt{m \log m} \right) \) queries (by Algorithm 1). Let us consider two possible cases:
-
1.
If \(j_l \not \equiv j_r \pmod d\), then by Lemma D.2, there is no matching in the i-th block and thus \(h_i = \infty \);
-
2.
If \(j_l \equiv j_r \pmod d\), find the smallest \(j_l \le q \le R_i\) such that \(t[q \dots R_i] = p[q-j_l \dots q-j_l+R_i-q]\), where \(R_i = \min \{(i+1)L, n\} - 1\) denotes the right endpoints of the i-th block, by minimum finding in \(O\left( \sqrt{L} \right) = O\left( \sqrt{m} \right) \) queries (by Algorithm 1). Then the leftmost candidate will be
$$ j = j_l + \lceil * \rceil {\frac{q-j_l}{d}} d. $$If \(j \le \min \left\{ n - m, j_r \right\} \) and \(t[j \dots j+m-1] = p\) (which can be checked by quantum search in \(O(\sqrt{m})\) queries), then \(h_i = j\); otherwise, \(h_i = \infty \).
Correctness It is not straightforward to see that the leftmost occurrence in the i-th block is found in the case \(j_l \equiv j_r \pmod d\) if there does exist an occurrence in that block. By Lemma D.2, if there exists an occurrence starting at index \(j_l \le j \le j_r\) in the i-th block, then \(j_l \equiv j \equiv j_r \pmod d\). Let the leftmost and the rightmost occurrences of p in the i-th block be \(j_l'\) and \(j_r'\), respectively. Then \(j_l \le j_l' \le j_r' \le j_r\) and \(j_l \equiv j_l' \equiv j_r' \equiv j_r \pmod d\). By the minimality of q with \(j_l \le q \le R_i\) and \(t[q \dots R_i] = p[q-j_l \dots q-j_l+R_i-q]\), we have \(q \le j_l'\), and therefore the candidate determined by q is
On the other hand, if \(j_q \ne j_l'\), the existence of \(j_l'\) leads immediately to that \(t[j_q \dots j_q + m - 1]\) matches p, i.e. \(j_q < j_l'\) is also an occurrence, which contradicts with the minimality of \(j_l'\). As a result, we have \(j_q = j_l'\). That is, our algorithm finds the leftmost occurrence in the block, if exists.
Complexity According to the above discussion, it is clear that \(h_i\) can be computed with bounded-error in \(O\left( \sqrt{m \log m} \right) \) queries. Thus, the entire problem can be solved by searching on bounded-error oracles (by Theorem 3.1) and the query complexity is
Combining the above two cases, we conclude that there is a bounded-error quantum algorithm for pattern matching in \(O\left( \sqrt{n \log m} + \sqrt{m \log ^{3} m \log \log m}\right) \) queries.
Appendix E: Proof of Exclusion Rule for LMSR
In this appendix, we present a proof of Lemma 5.1. To this end, we first observe:
Proposition E.1
Suppose \(s \in \Sigma ^n\) and \(s[{\text {LMSR}}(s) \dots {\text {LMSR}}(s)+B-1] = aba\), where \(| a | \ge 1\), \(| b | \ge 0\), and \(B = 2| a |+| b | \le n/2\). For every \(m > 0\) and \(i \in [n]\), if \(s[i \dots i+| b |+| a |-1] = ba\), then
Proof
We prove it by induction on m.
Basis. For every \(i \in [n]\) with \(s[i \dots i+| b |+| a |-1] = ba\), we note that \(s[i+| b | \dots i+| b |+B-1] = a s[i+| b |+| a | \dots i+| b | {+} B-1]\). On the other hand, by the definition of LMSR, we have
Therefore, it holds that \(s[i+| b |+| a | \dots i+| b |-B-1] \ge ba = s[i \dots i+| b |+| a |-1]\). Immediately, we see that the proposition holds for \(1 \le m \le | b |+| a |\).
Induction Assume that the proposition holds for \(m' = k(| b |+| a |)\) and \(k \ge 1\), and we are going to prove it for the case \(m' < m \le (k+1)(| b |+| a |)\). According to the induction hypothesis, we have
for every \(0 \le i < n\). Let us consider the following two cases:
-
1.
\(s[i \dots i+m'-1] < s[i+| b |+| a | \dots i+| b |+| a |+m'-1]\). In this case, it is trivial that \(s[i \dots i+m-1] < s[i+| b |+| a | \dots i+| b |+| a |+m-1]\) for every \(m > m'\).
-
2.
\(s[i \dots i+m'-1] = s[i+| b |+| a | \dots i+| b |+| a |+m'-1]\). In this case, we have \(s[i \dots i+(k+1)(| b |+| a |)-1] = (ba)^{k+1}\), and
$$ s[i\!+\!| b |\!+\!| a | \dots i\!+\!(k\!+\!2)(| b |\!+\!| a |)-1] \!=\! (ba)^k s[i+(k+1)(| b |+| a |) \dots i+(k+2)(| b |+| a |)-1]. $$According to the induction hypothesis for \(i' = i+m' = i+k(| b |+| a |)\) (this can be derived from the index \(i'' = i' \bmod n \in [n]\)), we have:
$$ s[i+k(| b |+| a |) \dots i+(k+1)(| b |+| a |)-1] \le s[i+(k+1)(| b |+| a |) \dots i+(k+2)(| b |+| a |)-1]. $$Therefore, we obtain \(s[i \dots i+(k+1)(| b |+| a |)-1] \le s[i+| b |+| a | \dots i+(k+2)(| b |+| a |)-1]\), which means the proposition holds for \(m = m' + | b | + | a |\). Immediately, we see that the proposition also holds for \(m' < m \le (k+1)(| b |+| a |)\).
\(\square \)
Now we are ready to prove Lemma 5.1. Let \(\delta = j-i\), then we have \(1 \le \delta \le B-1\). We consider the following two cases:
-
Case 1. \(\delta > B/2\). In this case, \(s[{\text {LMSR}}(s) \dots {\text {LMSR}}(s)+B-1] = aba\) for some strings a and b, where \(| a | = B-\delta \) and \(| b | = 2\delta -B\). In order to prove that \({\text {LMSR}}(s) \ne j\), it is sufficient to show that \(s[i \dots i+n-1] \le s[j \dots j+n-1]\). Note that
$$\begin{aligned} s[i \dots i+n-1]&= ababa s[j+B \dots j+n-\delta -1], \\ s[j \dots j+n-1]&= aba s[j+B \dots j+n-1]. \end{aligned}$$We only need to show that \(ba s[j+B \dots j+n-\delta -1] \le s[j+B \dots j+n-1]\), that is, \(s[i+B \dots i+n-1] \le s[i+B+\delta \dots i+\delta +n-1]\), which can be immediately obtained from Proposition E.1 by letting \(m \equiv n-B\) and \(i \equiv i+B\).
-
Case 2. \(\delta \le B/2\). Let \(t = s[{\text {LMSR}}(s) \dots {\text {LMSR}}(s)+B-1]\). Note that \(t[i+\delta ] = t[i]\) for every \(i \in [B]\). We immediately see that t has period \(d = \gcd (B, \delta )\), that is, \(t = a^k\), where \(| a | = d\) and \(B = kd\) with \(k \ge 2\). For convenience, we denote \(\delta = ld\) for some \(1 \le l \le k-1\). In order to prove that \({\text {LMSR}}(s) \ne j\), it is sufficient to show that \(s[i \dots i+n-1] \le s[j \dots j+n-1]\). Note that
$$\begin{aligned} s[i \dots i+n-1]&= a^{k+m} s[j+B \dots j+n-\delta -1], \\ s[j \dots j+n-1]&= a^k s[j+B \dots j+n-1]. \end{aligned}$$We only need to show that \(a^m s[j+B \dots j+n-\delta -1] \le s[j+B \dots j+n-1]\), i.e. \(s[i+B \dots i+n-1] \le s[i+B+\delta \dots i+\delta +n-1]\), which can be immediately obtained from Proposition E.1 by noting that \(s[{\text {LMSR}}(s) \dots {\text {LMSR}}(s)+B-1] = a^l a^{k-2l} a^l\).
Appendix F: Worst-Case Quantum Lower Bound
The worst-case quantum lower bound can be examined in a way different from that in Section 6.2. Let us consider a special case where all strings are binary, that is, the alphabet is \(\Sigma = \{0, 1\}\). A solution to the LMSR problem implies the existence of a 0 character. That is, \(s[i] = 0\) for some \(i \in [n]\) if and only if \(s[{\text {LMSR}}(s)] = 0\). Therefore, the search problem can be reduced to LMSR. It is known that the search problem has a worst-case query complexity lower bound \(\Omega \left( \sqrt{n}\right) \) for bounded-error quantum algorithms [12, 15, 79], and \(\Omega (n)\) for exact and zero-error quantum algorithms [13]. Consequently, we assert that the LMSR problem also has a worst-case quantum query complexity lower bound \(\Omega \left( \sqrt{n}\right) \) for bounded-error quantum algorithms, and \(\Omega (n)\) for exact and zero-error quantum algorithms.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Q., Ying, M. Quantum Algorithm for Lexicographically Minimal String Rotation. Theory Comput Syst 68, 29–74 (2024). https://doi.org/10.1007/s00224-023-10146-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00224-023-10146-8