
Detecting Fraudulent Transactions Using Stacked Autoencoder Kernel ELM Optimized by the Dandelion Algorithm

 , , and
, , and
Abstract
:1. Introduction
- Employing the stacked autoencoder kernel ELM makes the number of hidden nodes in each layer unimportant. It eliminates the subjective and time-consuming process of selecting the appropriate number of hidden nodes, making the model more efficient and reducing the danger of overfitting or underfitting.
- The best values of the AE-KELM parameters were adjusted using an optimization technique based on the dandelion algorithm, which was more optimal than that established using particle swarm optimization and the bat algorithm.
- Our proposed method unifies all transformation matrices into only two matrices. This unification simplifies the model’s structure and reduces storage requirements. It can also shorten the model’s execution time by minimizing computational complexity.
- According to the simulation results, the S-AEKELM-DA can achieve good testing accuracy results, including learning large amounts of data and detecting problems without causing memory problems.
2. Background and Related Work
3. Methods and Materials
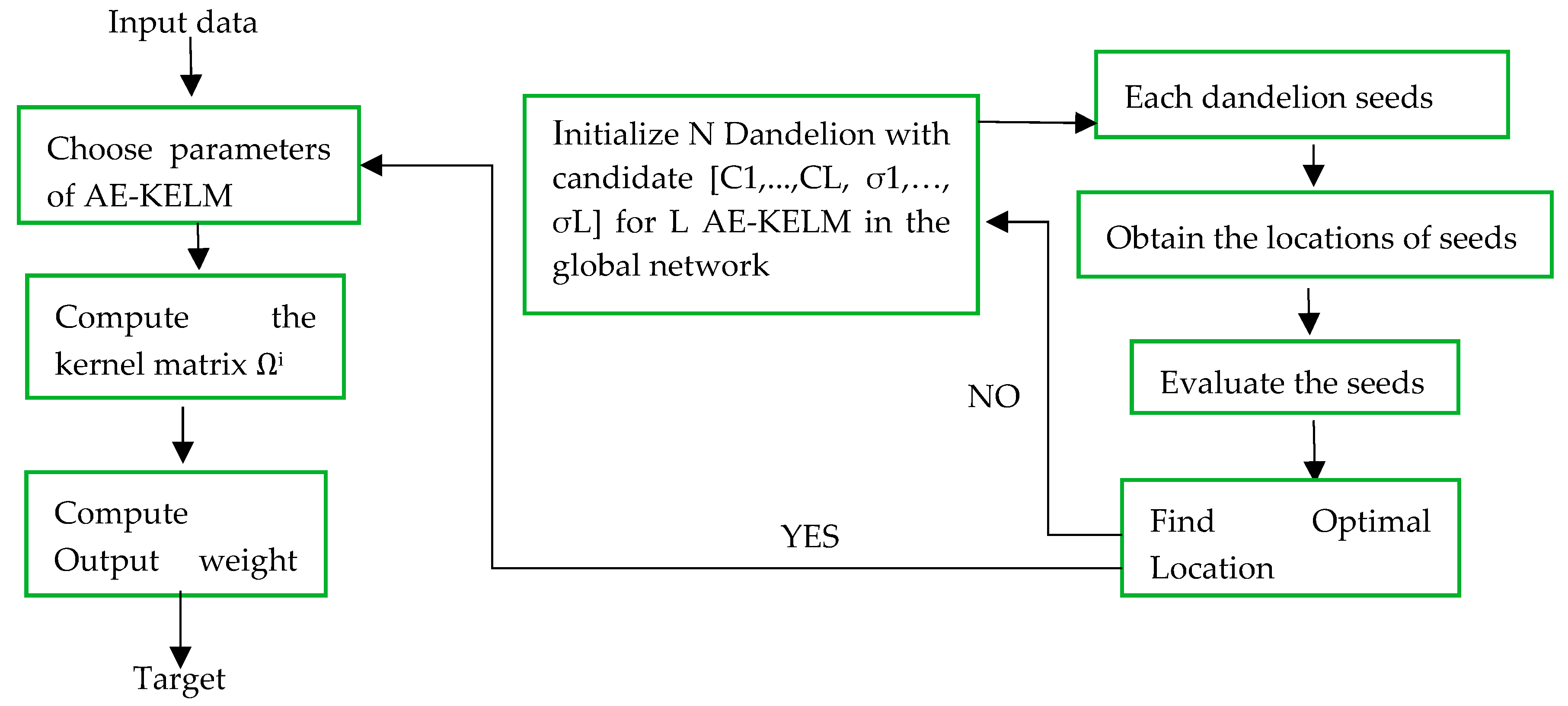
3.1. Dandelion Optimizer Algorithm
| Algorithm 1 Dandelion Optimizer |
| Input: popsize, pop sizeim is the dimension of the variable, maximum number of iterations T, and calculate the population fitness values. Output: The best dandelion seed (Dbest) and its fitness value (best) a. Randomly initialize a population pop. b. Determine each dandelion seed’s fitness value f. c. According to fitness values, choose the best dandelion seed Delite. d. While (t < T) do Rise stage. e. if randn () < 1.25 do f. Use Equation (7) to produce adaptive parameters. g. Use Equation (4) to update dandelion seeds. h. else if do i. Use Equations (10) and (11) to generate adaptive parameters. j. Use Equation (9) to update dandelion seeds. k. end if Decline stage. l. Use Equation (13) to update dandelion seeds. Land stage m. Use Equation (15) to update dandelion seeds. n. Sort dandelion seeds according to fitness values, from good to bad. o. Update Delite p. if f(Delite) < f(Dbest) q. Dbest = Delite, fbest = f(Delite) r. end if s. end While t. return Dbest and fbest |
3.2. Kernel Extreme Learning Machine
- (1)
- Initialize randomly input weight P and hidden biases where the input nodes to the hidden layer neuron i are connected by the vector Pi = [Pi1, Pi2, …, Pin].
- (2)
- Calculate matrix H of output hidden layer
- (3)
- Compute output matrix weight with
3.3. Multilayer Extreme Learning Machines
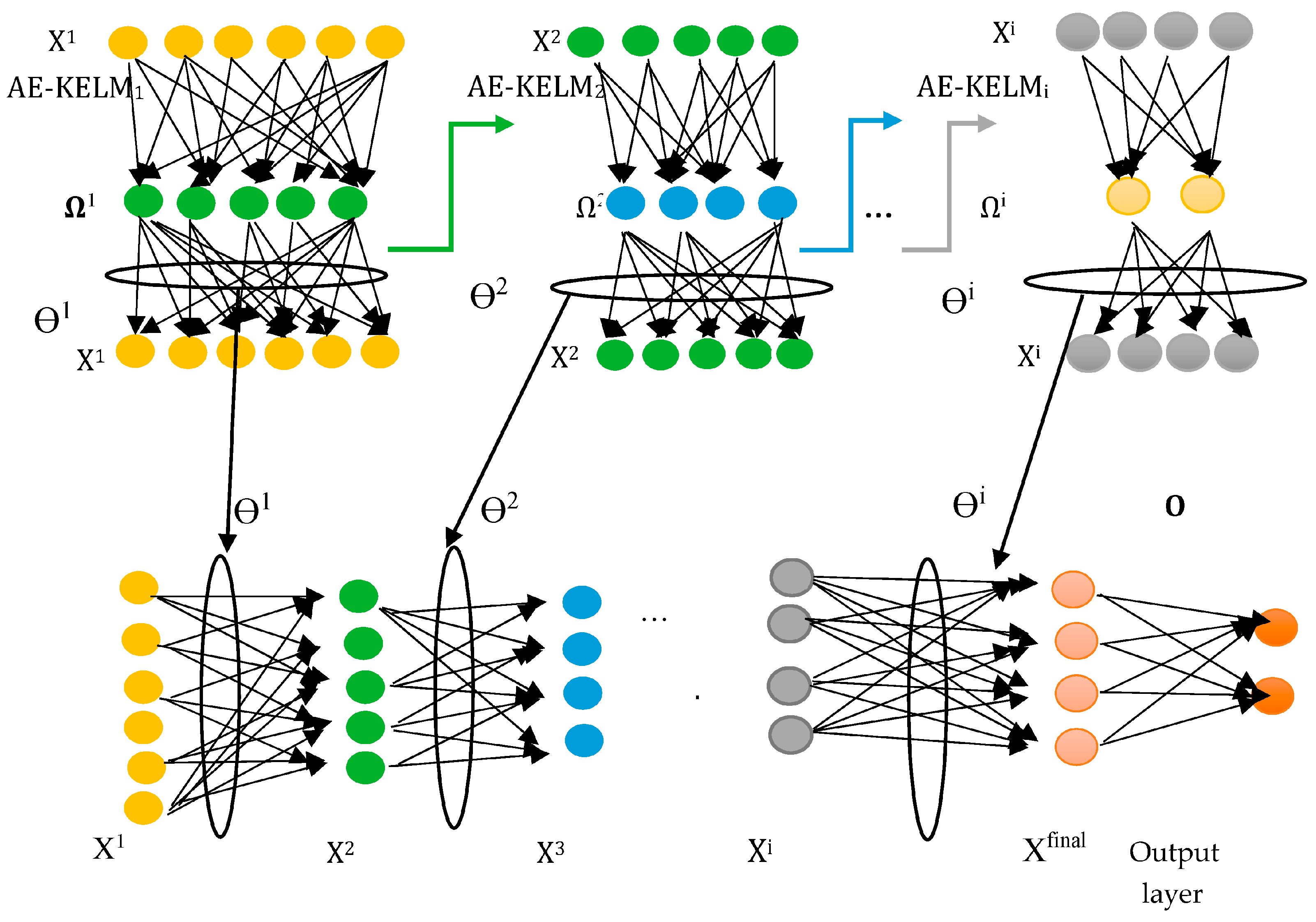
3.4. S-AEKELM-DA
| Algorithm 2 AE-KELM |
| Input: input matrix Xi−1, regularization Ci−1, kernel parameters of σi−1, and activation f’i−1 Output: Xi, Ωi, ϴi Method: a. Xi = f’i−1(Xi−1(ϴi−1)T) b. Ωi = k(xj,xk,σi−1) c. ϴi =Xi−1 |
| Algorithm 3 Stacked AE-KELM |
| Input: input matrix X1, output matrix T, regularization Ci, kernel parameters of σi, the number of layers NLayer, and activation f’i Output: Hfinal matrix, two transformation matrices ϴ and ϴunified, and output weight O Method: a. Compute the first kernel matrix Ω1(i,k) = k(xj,xk,σ1) for j, k = 1 to N b. Calculate ϴ1 =X1 c. Calculate new data representation X2 = f’1(X1(ϴ1)T) d. Compute the second kernel matrix Ω2(i,k) = k(xj,xk,σ2) e. Calculate ϴ2 =X2 f. ϴunified = ϴ2 g. for i = 3: NLayer-1 do h. Xi, Ωi, ϴi = AE-KELM (Xi−1, Ωi−1, ϴ−1i) i. Update ϴunified = ϴiϴunified j. Xfinal = XN k. Calculate the Nth kernel matrix ΩN(i,k) = k(xj,xk,σN) l. Calculate the output weight O = |
3.5. Other Optimization Algorithms
4. Experiments and Comparative Results
4.1. Evaluation Metrics
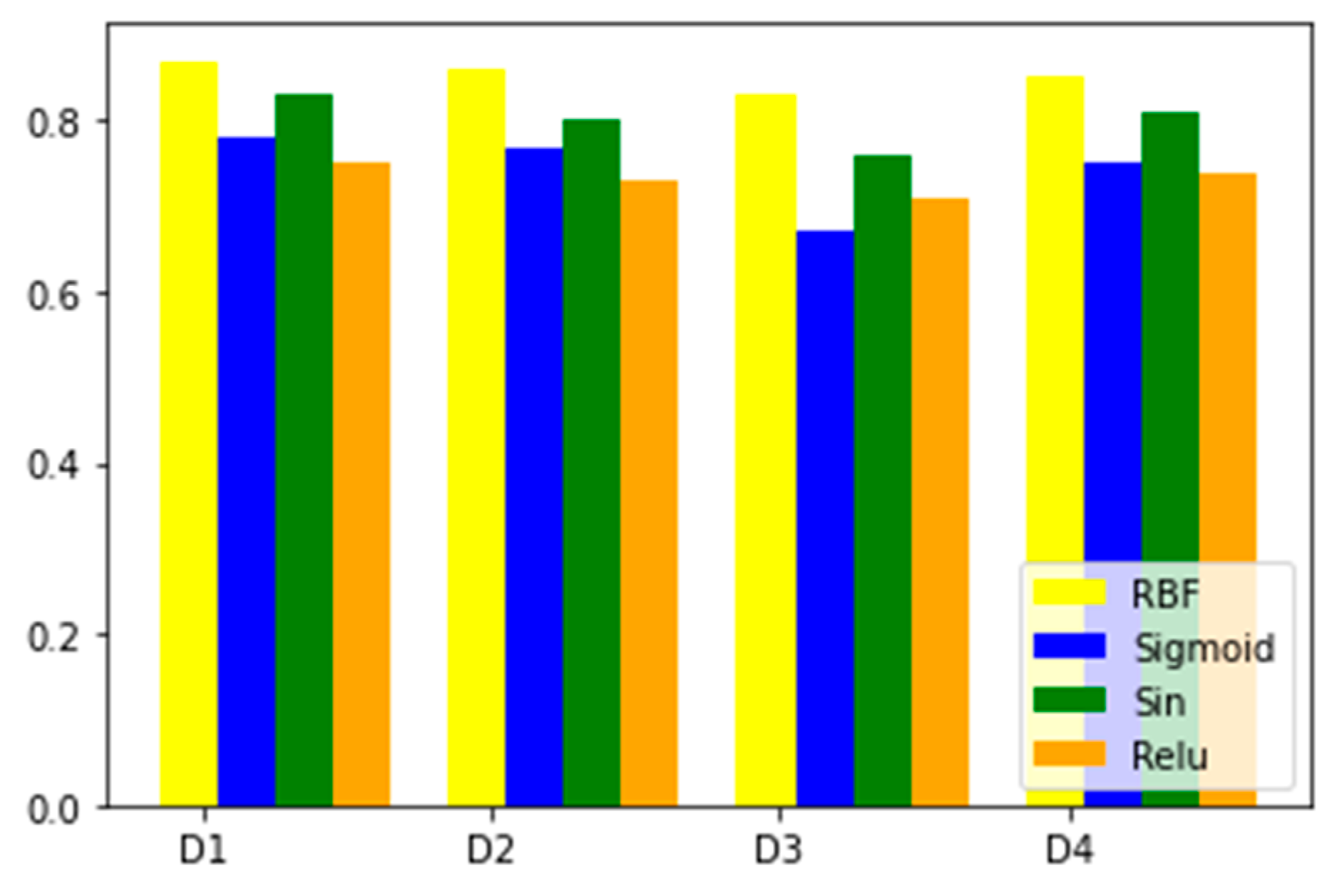
4.2. Dataset
- N is the population size in Table 5, and the parameters are introduced as follows:
- PSO: w stands for the inertia weight, and c1 and c2 are acceleration factors.
- BA: R is the pulse emission rate, A is loudness, and α and ξ are constants.
- DA: max is the number of seeds, and X is the number of the best dandelions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameters |
|---|---|
| PSO | N = 50, c1 = 1.5, c2 = 1.5, w = 0.7311 |
| BA | N = 50, A = 1, R = 1, α = γ = 0.9 |
| DA | N = 50, X = 20, max = 100 |
5. Conclusions and Future Work
- Extend the experimental evaluation of our proposed approach to a broader range of datasets with varying levels of class imbalance. It will help assess its robustness and generalizability across domains and dataset characteristics.
- Compare our approach with other state-of-the-art methods for imbalanced datasets, such as resampling techniques (e.g., SMOTE), cost-sensitive learning, or ensemble methods. It will provide insights into the relative performance and strengths of different approaches and further validate the superiority of our proposed method.
- Investigate advanced techniques for optimizing hyperparameters, such as using Bayesian optimization or evolutionary algorithms, to automatically search for optimal values of the regularization parameters C and σ. It can further enhance the performance and generalization of the model.
- Explore methods to enhance the interpretability of the model. Stacked autoencoders can sometimes be considered black-box models. Investigate techniques to extract meaningful insights from the learned representations and explain the model’s decisions.
- Apply our proposed approach to real-world applications with imbalanced datasets, such as fraud detection, medical diagnosis, or anomaly detection, to assess its practical effectiveness and impact in domains where imbalanced data is prevalent.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Forough, J.; Momtazi, S. Ensemble of deep sequential models for credit card fraud detection. Appl. Soft Comput. 2021, 99, 106883. [Google Scholar] [CrossRef]
- Shen, A.; Tong, R.; Deng, Y. Application of Classification Models on Credit Card Fraud Detection. In Proceedings of the 2007 International Conference on Service Systems and Service Management, Chengdu, China, 9–11 June 2007. [Google Scholar] [CrossRef]
- Almuteer, A.H.; Aloufi, A.A.; Alrashidi, W.O.; Alshobaili, J.F.; Ibrahim, D.M. Detecting Credit Card Fraud using Machine Learning. Int. J. Interact. Mob. Technol. 2021, 15, 108–122. [Google Scholar] [CrossRef]
- Murli, D.; Jami, S.; Jog, D.; Nath, S. Credit Card Fraud Detection Using Neural Network. Int. J. Soft Comput. Eng. 2014, 2, 84–88. [Google Scholar]
- El Hlouli, F.Z.; Riffi, J.; Mahraz, M.A.; El Yahyaouy, A.; Tairi, H. Credit Card Fraud Detection Based on Multilayer Perceptron and Extreme Learning Machine Architectures. In Proceedings of the 2020 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 9–11 June 2020. [Google Scholar] [CrossRef]
- Ma, R.; Karimzadeh, M.; Ghabussi, A.; Zandi, Y.; Baharom, S.; Selmi, A.; Maureira-Carsalade, N. Assessment of composite beam performance using GWO–ELM metaheuristic algorithm. Eng. Comput. 2022, 38, 2083–2099. [Google Scholar] [CrossRef]
- Cao, F.; Liu, B.; Sun, D. Neurocomputing Image classification based on effective extreme learning machine. Neurocomputing 2013, 102, 90–97. [Google Scholar] [CrossRef]
- Neethu, K.S.; Jyothis, T.S.; Dev, J. Text Classification Using KM-ELM Classifier. In Proceedings of the2016 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Nagercoil, India, 18–19 March 2016. [Google Scholar]
- Wang, Z.; Yu, G.; Kang, Y.; Zhao, Y.; Qu, Q. Neurocomputing Breast tumor detection in digital mammography based on extreme learning machine. Neurocomputing 2014, 128, 175–184. [Google Scholar] [CrossRef]
- Tripathi, D.; Reddy, D.; Kuppili, V.; Bablani, A. Engineering Applications of Artificial Intelligence Evolutionary Extreme Learning Machine with novel activation function for credit scoring. Eng. Appl. Artif. Intell. 2020, 96, 103980. [Google Scholar] [CrossRef]
- Shariati, M.; Mafipour, M.S.; Ghahremani, B.; Azarhomayun, F.; Ahmadi, M.; Trung, N.T.; Shariati, A. A novel hybrid extreme learning machine–grey wolf optimizer (ELM-GWO) model to predict compressive strength of concrete with partial replacements for cement. Eng. Comput. 2022, 38, 757–779. [Google Scholar] [CrossRef]
- Li, X.; Han, S.; Zhao, L.; Gong, C.; Liu, X. New Dandelion Algorithm Optimizes Extreme Learning Machine for Biomedical Classification Problems. Comput. Intell. Neurosci. 2017, 2017, 4523754. [Google Scholar] [CrossRef]
- Huang, G.; Siew, C.K. Extreme Learning Machine with Randomly Assigned RBF Kernels. Int. J. Inf. Technol. 2014, 11, 16–24. [Google Scholar]
- Lin, S.Y.; Chiang, C.C.; Li, J.-B.; Hung, Z.S.; Chao, K.M. Dynamic fine-tuning stacked auto-encoder neural network for weather forecast. Future Gener. Comput. Syst. 2018, 89, 446–454. [Google Scholar] [CrossRef]
- Gong, C.; Han, S.; Li, X.; Zhao, L.; Liu, X. A new dandelion algorithm and optimization for extreme learning machine. J. Exp. Theor. Artif. Intell. 2018, 30, 39–52. [Google Scholar] [CrossRef]
- Zhu, H.; Liu, G.; Zhou, M.; Xie, Y.; Abusorrah, A. Neurocomputing Optimizing Weighted Extreme Learning Machines for imbalanced classification and application to credit card fraud detection. Neurocomputing 2020, 407, 50–62. [Google Scholar] [CrossRef]
- Kwaku, J.; Tawiah, K.; Adoma, W.; Addai-henne, S.; Achiaa, H.; Odame, E.; Amening, S.; Eshun, J. A supervised machine learning algorithm for detecting and predicting fraud in credit card transactions. Decis. Anal. J. 2023, 6, 100163. [Google Scholar] [CrossRef]
- Roseline, J.F.; Naidu, G.; Pandi, V.S.; Alamelu, S.; Mageswari, N. Autonomous credit card fraud detection using machine learning approach☆. Comput. Electr. Eng. 2022, 102, 108132. [Google Scholar] [CrossRef]
- Bin, R.; Vitaly, S.; Paul, S. Review of Machine Learning Approach on Credit Card Fraud Detection. Hum. Centric Intell. Syst. 2022, 2, 55–68. [Google Scholar] [CrossRef]
- Carcillo, F.; Le Borgne, Y.A.; Caelen, O.; Bontempi, G. Streaming active learning strategies for real-life credit card fraud detection: Assessment and visualization. Int. J. Data Sci. Anal. 2018, 5, 285–300. [Google Scholar] [CrossRef]
- Carcillo, F.; Le Borgne, Y.A.; Caelen, O.; Kessaci, Y.; Oblé, F.; Bontempi, G. Combining unsupervised and supervised learning in credit card fraud detection. Inf. Sci. 2021, 557, 317–331. [Google Scholar] [CrossRef]
- Saia, R.; Carta, S. Evaluating credit card transactions in the frequency domain for a proactive fraud detection approach. In Proceedings of the 14th International Joint Conference on E-Business and Telecommunications (ICETE 2017), Madrid, Spain, 24–26 July 2017; Volume 4, pp. 335–342. [Google Scholar]
- Saia, R. Unbalanced data classification in fraud detection by introducing a multidimensional space analysis. In Proceedings of the 3rd International Conference on Internet of Things, Big Data and Security IoTBDS, Funchal, Portugal, 19–21 March 2018; pp. 29–40. [Google Scholar] [CrossRef]
- Cherif, A.; Badhib, A.; Ammar, H.; Alshehri, S.; Kalkatawi, M.; Imine, A. Credit card fraud detection in the era of disruptive technologies: A systematic review. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 145–174. [Google Scholar] [CrossRef]
- Fanai, H.; Abbasimehr, H. A novel combined approach based on deep Autoencoder and deep classifiers for credit card fraud detection. Expert Syst. Appl. 2023, 217, 119562. [Google Scholar] [CrossRef]
- Van Belle, R.; Baesens, B.; De Weerdt, J. CATCHM: A novel network-based credit card fraud detection method using node representation learning. Decis. Support Syst. 2023, 164, 113866. [Google Scholar] [CrossRef]
- Tanouz, D.; Subramanian, R.R.; Eswar, D.; Reddy, G.V.P.; Kumar, A.R.; Praneeth, C.H.V.N.M. Credit card fraud detection using machine learning. In Proceedings of the 2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 6–8 May 2021; pp. 967–972. [Google Scholar] [CrossRef]
- Abualigah, L. Group search optimizer: A nature-inspired meta-heuristic optimization algorithm with its results, variants, and applications. Neural Comput. Appl. 2021, 33, 2949–2972. [Google Scholar] [CrossRef]
- Ramzan, M.; Ahmed, M. Credit Card Fraud Detection Using State-of-the-Art Machine Learning and Deep Learning Algorithms. IEEE Access 2022, 10, 39700–39715. [Google Scholar] [CrossRef]
- Yu, X.; Li, X.; Dong, Y.; Zheng, R. A Deep Neural Network Algorithm for Detecting Credit Card Fraud. In Proceedings of the 2020 International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Fuzhou, China, 12–14 June 2020; pp. 181–183. [Google Scholar] [CrossRef]
- Huang, G.; Huang, G.-B.; Song, S.; You, K. Trends in extreme learning machines: A review. IEEE Access 2019, 7, 108070–108089. [Google Scholar] [CrossRef]
- Li, C.; Zhou, J.; Tao, M.; Du, K.; Wang, S.; Jahed Armaghani, D.; Tonnizam Mohamad, E. Developing hybrid ELM-ALO, ELM-LSO and ELM-SOA models for predicting advance rate of TBM. Transp. Geotech. 2022, 36, 100819. [Google Scholar] [CrossRef]
- Zhu, Q.; Qin, A.K.; Suganthan, P.N.; Huang, G. Evolutionary extreme learning machine. Pattern Recognit. 2005, 38, 1759–1763. [Google Scholar] [CrossRef]
- Yu, Y.; Gao, S.; Wang, Y.; Todo, Y. Global Optimum-Based Search Differential Evolution. IEEE/CAA J. Autom. Sin. 2019, 6, 379–394. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, F.; Yuan, Y. Neurocomputing A study on effectiveness of extreme learning machine*. Neurocomputing 2011, 74, 2483–2490. [Google Scholar] [CrossRef]
- Jiang, J.; Han, F.; Ling, Q.H.; Su, B.Y. An Improved Evolutionary Extreme Learning Machine Based on Multiobjective Particle Swarm Optimization. In Intelligent Computing Methodologies; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 10956, pp. 1–6. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, T.; Ma, S.; Chen, M. Dandelion Optimizer: A nature-inspired metaheuristic algorithm for engineering applications. Eng. Appl. Artif. Intell. 2022, 114, 105075. [Google Scholar] [CrossRef]
- Chen, C.; Li, W.; Su, H.; Liu, K. Spectral-Spatial Classification of Hyperspectral Image Based on Kernel Extreme Learning Machine. Remote. Sens. 2014, 6, 5795–5814. [Google Scholar] [CrossRef]
- Dai, H.; Cao, J.; Wang, T.; Deng, M.; Yang, Z. Multilayer one-class extreme learning machine. Neural Netw. 2019, 115, 11–22. [Google Scholar] [CrossRef] [PubMed]
- Purschke, O.; Sykes, M.T.; Poschlod, P.; Michalski, S.G.; Römermann, C.; Durka, W.; Kühn, I.; Prentice, H.C. Interactive effects of landscape history and current management on dispersal trait diversity in grassland plant communities. J. Ecol. 2014, 102, 437–446. [Google Scholar] [CrossRef] [PubMed]
- Ding, S.; Xu, X.; Nie, R. Extreme learning machine and its applications. Neural Comput. Appl. 2014, 25, 549–556. [Google Scholar] [CrossRef]
- Serre, D. Matrices: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2002; ISBN 0387954600. [Google Scholar]
- Huang, G.-B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.-B.; Slew, C.K. Extreme learning machine: RBF network case. In Proceedings of the ICARCV 2004 8th Control, Automation, Robotics and Vision Conference, Kunming, China, 6–9 December 2004; Volume 2, pp. 1029–1036. [Google Scholar] [CrossRef]
- Yang, X.S. A new metaheuristic Bat-inspired Algorithm. Stud. Comput. Intell. 2010, 284, 65–74. [Google Scholar] [CrossRef]
- Eberhart, R.; Kennedy, J. New optimizer using particle swarm theory. In Proceedings of the MHS’95, Proceedings of the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar] [CrossRef]
- Itoo, F.; Meenakshi; Singh, S. Comparison and analysis of logistic regression, Naıve Bayes and KNN machine learning algorithms for credit card fraud detection. Int. J. Inf. Technol. 2020, 13, 1503–1511. [Google Scholar] [CrossRef]
- Huang, C.L.; Chen, M.C.; Wang, C.J. Credit scoring with a data mining approach based on support vector machines. Expert Syst. Appl. 2007, 33, 847–856. [Google Scholar] [CrossRef]
- Zou, Y.; Gao, C. Extreme Learning Machine Enhanced Gradient Boosting for Credit Scoring. Algorithms 2022, 15, 149. [Google Scholar] [CrossRef]
- Hasan, N.; Anzum, T.; Hasan, T.; Jahan, N. Machine Learning Algorithm to Predict Fraudulent Loan Requests. In Proceedings of the 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021. [Google Scholar] [CrossRef]
- Yu, Y. The application of machine learning algorithms in credit card default prediction. In Proceedings of the 2020 International Conference on Computing and Data Science (CDS), Stanford, CA, USA, 1–2 August 2020; pp. 212–218. [Google Scholar] [CrossRef]





| Actual Transaction | |||
|---|---|---|---|
| Normal(0) | Fraud (1) | ||
| Predicted Transaction | Normal(0) | True Negative TN | False Negative FN |
| Fraud (1) | False Positive FP | True Positive TP | |
| Dataset | Abbr. | #S | #NS | #FS | #NA | #RFS |
|---|---|---|---|---|---|---|
| Australian | D1 | 690 | 307 | 383 | 14 | 55% |
| German numerical | D2 | 1000 | 700 | 300 | 24 | 30% |
| Loan prediction | D3 | 614 | 422 | 192 | 12 | 31% |
| Default of credit card clients | D4 | 30,000 | 23,364 | 6636 | 24 | 22% |
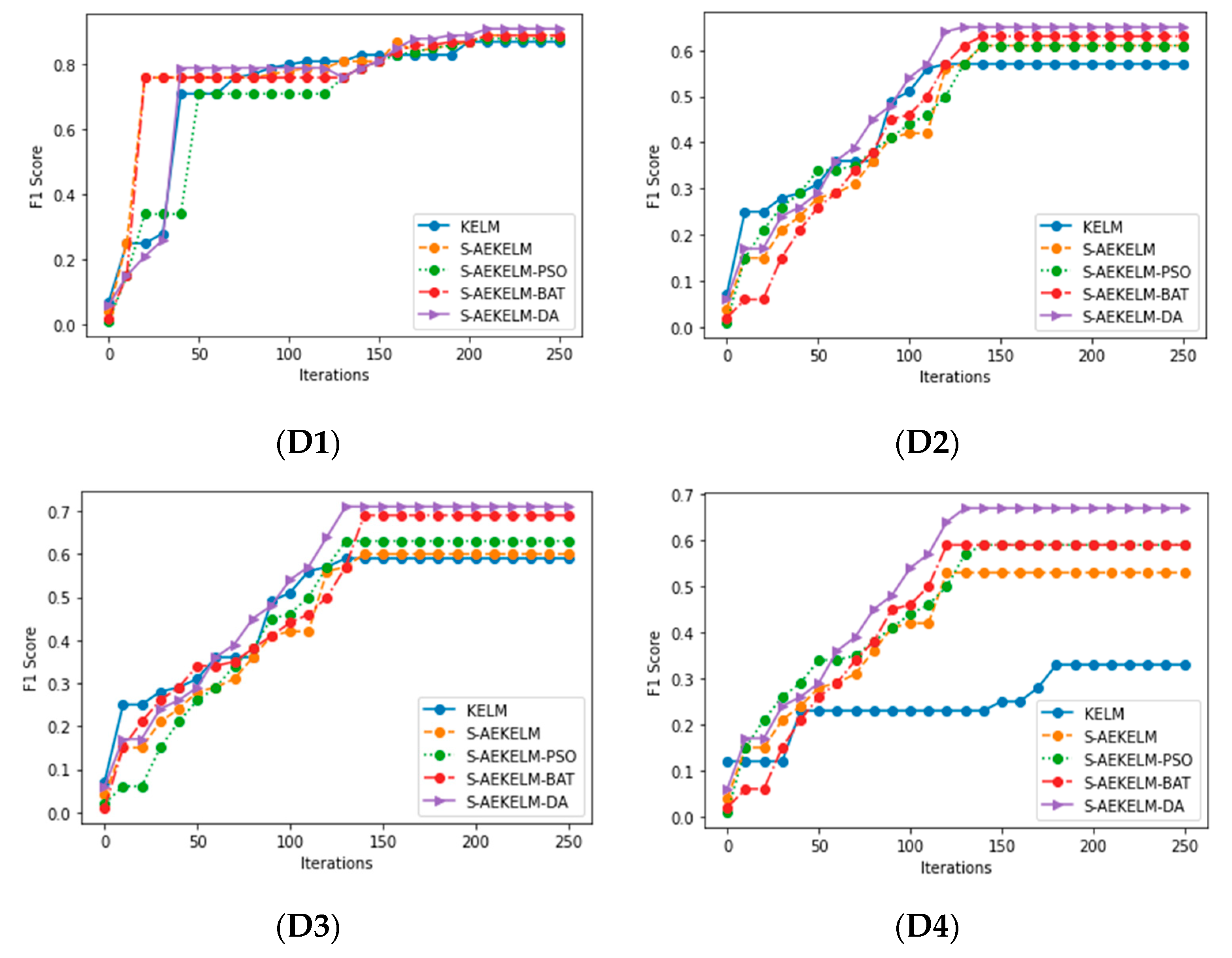
| Dataset | Metric | KELM | S-AEKELM | S-AEKELM-PSO | S-AEKELM-BA | S-AEKELM-DA |
|---|---|---|---|---|---|---|
| D1 | Acc | 0.8732 | 0.8911 | 0.8889 | 0.8997 | 0.9121 |
| Prec | 0.8747 | 0.8878 | 0.8720 | 0.8861 | 0.8945 | |
| Recall | 0.8808 | 0.8923 | 0.9047 | 0.9216 | 0.9409 | |
| AUC | 0.9129 | 0.9263 | 0.9221 | 0.9314 | 0.9568 | |
| F1-score | 0.8777 | 0.89 | 0.8873 | 0.9035 | 0.9171 | |
| D2 | Acc | 0.7811 | 0.7934 | 0.7916 | 0.8102 | 0.8217 |
| Prec | 0.7331 | 0.7524 | 0.7603 | 0.78 | 0.8023 | |
| Recall | 0.9216 | 0.9335 | 0.9321 | 0.9347 | 0.9461 | |
| AUC | 0.8817 | 0.8864 | 0.8941 | 0.9008 | 0.9031 | |
| F1-score | 0.8166 | 0.8332 | 0.8374 | 0.8503 | 0.8682 | |
| D3 | Acc | 0.7602 | 0.8142 | 0.8211 | 0.8245 | 0.8447 |
| Prec | 0.7809 | 0.7634 | 0.8444 | 0.8532 | 0.8602 | |
| Recall | 0.4618 | 0.5057 | 0.5132 | 0.5122 | 0.6118 | |
| AUC | 0.7913 | 0.7942 | 0.801 | 0.8015 | 0.8227 | |
| F1-score | 0.5803 | 0.6083 | 0.6384 | 0.6401 | 0.715 | |
| D4 | Acc | 0.7221 | 0.7548 | 0.7633 | 0.772 | 0.8322 |
| Prec | 0.481 | 0.5451 | 0.5821 | 0.6016 | 0.753 | |
| Recall | 0.3341 | 0.6036 | 0.6009 | 0.5964 | 0.6164 | |
| AUC | 0.7011 | 0.7166 | 0.7207 | 0.7241 | 0.7633 | |
| F1-score | 0.3943 | 0.5729 | 0.5914 | 0.599 | 0.6779 |
| KELM | S-AEKELM | S-AEKELM-PSO | S-AEKELM-BAT | S-AEKELM-DA | |
|---|---|---|---|---|---|
| D1 | 25 | 34 | 37 | 34 | 38 |
| D2 | 46 | 51 | 59 | 52 | 60 |
| D3 | 29 | 33 | 35 | 32 | 39 |
| D4 | 1417 | 1808 | 1759 | 1770 | 1783 |
| Dataset | Reference | Method | Accuracy | Recall | Precision | F1-Score | AUC |
|---|---|---|---|---|---|---|---|
| Australian | [48] | BPN | 0.8683 | - | - | - | - |
| GP | 0.87 | - | - | - | - | ||
| C4.5 | 0.859 | - | - | - | - | ||
| SVM + GA | 0.869 | - | - | - | - | ||
| [10] | ANN | 0.94 | - | - | - | 0.93 | |
| KNN | 0.836 | - | - | - | 0.893 | ||
| SVM-L | 0.874 | - | - | - | 0.923 | ||
| SVM-R | 0.861 | - | - | - | 0.929 | ||
| CART | 0.859 | - | - | - | 0.894 | ||
| J48 | 0.845 | - | - | - | 0.881 | ||
| LR-R | 0.862 | - | - | - | 0.940 | ||
| [49] | XGBoost | 0.8633 | 0.8487 | 0.8449 | 0.8468 | 0.9394 | |
| LightGBM | 0.8624 | 0.8422 | 0.8476 | 0.8449 | 0.9371 | ||
| AugBoost-RP | 0.8633 | 0.8487 | 0.8449 | 0.8468 | 0.9416 | ||
| AugBoost-PCA | 0.8681 | 0.8497 | 0.8533 | 0.8515 | 0.9415 | ||
| AugBoost-NN | 0.8645 | 0.8539 | 0.8435 | 0.8487 | 0.9424 | ||
| AugBoost-ELM | 0.8635 | 0.8462 | 0.8485 | 0.8462 | 0.9422 | ||
| Our study | 0.9121 | 0.9409 | 0.8945 | 0.9171 | 0.9568 | ||
| German numerical | [48] | BPN | 0.7783 | - | - | - | - |
| GP | 0.781 | - | - | - | - | ||
| C4.5 | 0.736 | - | - | - | - | ||
| SVM + GA | 0.7792 | - | - | - | - | ||
| [10] | ANN | 72.80 | - | - | - | 75.60 | |
| KNN | 66.90 | - | - | - | 70.20 | ||
| SVM-L | 74.80 | - | - | - | 79.30 | ||
| SVM-R | 75.90 | - | - | - | 80.20 | ||
| CART | 55.90 | - | - | - | 64.30 | ||
| J48 | 64.10 | - | - | - | 65.20 | ||
| LR-R | 75.40 | - | - | - | 78.50 | ||
| [49] | XGBoost | 0.7582 | 0.9208 | 0.7757 | 0.842 | 0.7811 | |
| LightGBM | 0.7615 | 0.9007 | 0.7887 | 0.841 | 0.7776 | ||
| AugBoost-RP | 0.7519 | 0.8867 | 0.7862 | 0.8335 | 0.7707 | ||
| AugBoost-PCA | 0.7605 | 0.8852 | 0.7956 | 0.838 | 0.7735 | ||
| AugBoost-NN | 0.7604 | 0.9237 | 0.7766 | 0.8438 | 0.7843 | ||
| AugBoost-ELM | 0.7617 | 0.9245 | 0.7775 | 0.8446 | 0.7861 | ||
| Our study | 0.8217 | 0.9461 | 0.8023 | 0.8682 | 0.9031 | ||
| Loan prediction | [16] | WELML | 0.7883 | 0.5782 | 0.6951 | 0.6285 | 0.7311 |
| WELMB | 0.7834 | 0.5834 | 0.6792 | 0.6244 | 0.729 | ||
| WELME | 0.7867 | 0.5837 | 0.7016 | 0.6263 | 0.7317 | ||
| [50] | KNN | 0.837 | - | - | - | - | |
| SVM | 0.831 | - | - | - | - | ||
| Decision Tree | 0.831 | - | - | - | - | ||
| Logistic Regres | 0.824 | - | - | - | - | ||
| RF | 0.798 | - | - | - | - | ||
| Our study | 0.8447 | 0.6118 | 0.8602 | 0.715 | 0.8227 | ||
| Default of credit card clients dataset | [16] | WELML | 0.7687 | 0.6032 | 0.5407 | 0.5683 | 0.7139 |
| WELMB | 0.7657 | 0.6003 | 0.5359 | 0.5645 | 0.7110 | ||
| WELME | 0.7679 | 0.5973 | 0.5391 | 0.5649 | 0.7009 | ||
| [51] | Logistic Regres | 0.8139 | - | - | - | - | |
| Decision Tree | 0.8218 | - | - | - | - | ||
| Boosting | 0.8235 | - | - | - | - | ||
| RF | 0.8212 | -s | - | - | - | ||
| Our study | 0.8322 | 0.6164 | 0.753 | 0.6779 | 0.7633 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Hlouli, F.Z.; Riffi, J.; Sayyouri, M.; Mahraz, M.A.; Yahyaouy, A.; El Fazazy, K.; Tairi, H. Detecting Fraudulent Transactions Using Stacked Autoencoder Kernel ELM Optimized by the Dandelion Algorithm. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 2057-2076. https://doi.org/10.3390/jtaer18040103
El Hlouli FZ, Riffi J, Sayyouri M, Mahraz MA, Yahyaouy A, El Fazazy K, Tairi H. Detecting Fraudulent Transactions Using Stacked Autoencoder Kernel ELM Optimized by the Dandelion Algorithm. Journal of Theoretical and Applied Electronic Commerce Research. 2023; 18(4):2057-2076. https://doi.org/10.3390/jtaer18040103
Chicago/Turabian StyleEl Hlouli, Fatima Zohra, Jamal Riffi, Mhamed Sayyouri, Mohamed Adnane Mahraz, Ali Yahyaouy, Khalid El Fazazy, and Hamid Tairi. 2023. "Detecting Fraudulent Transactions Using Stacked Autoencoder Kernel ELM Optimized by the Dandelion Algorithm" Journal of Theoretical and Applied Electronic Commerce Research 18, no. 4: 2057-2076. https://doi.org/10.3390/jtaer18040103