
Abstract
Pseudo-partitive constructions give rise to multiple interpretive ambiguities including a container interpretation (i.e. individuating) and a contents (i.e. measuring) one. There are two competing analyses: one based on structural ambiguities (Landman in Indefinites and the types of sets, Oxford University Press, Oxford, 2004; Rothstein in Brill’s J Afroasiat Lang Ling 1:106–145, 2009. https://doi.org/10.1163/187666309X12491131130783, a.o.) and one based on a uniform syntax (Lehrer in Lingua 68:109–148, 1986; Matushansky and Zwarts in Lamont and Tetzloff (eds) North East Linguistic Society (NELS) 47, Volume 2, pp 261–274, GLSA, Amherst, 2016, a.o.). I contribute to this debate with data from Alasha Mongolian (Mongolic), which differentiates each interpretation via case marking on the quantizing noun: glass-comitative = individuating vs. glass-genitive/Ø = measuring. I argue that there is no large-scale structural ambiguity: the numeral and the quantizing noun always form a constituent introduced in the specifier position of a null functional head (Schwarzschild in Syntax 9(1):67–110, 2006. https://doi.org/10.1111/j.1467-9612.2006.00083.x; Svenonius in McNally and Kennedy (eds) Adjectives and adverbs: syntax, semantics and discourse, Oxford Studies in Theoretical Linguistics, pp 16–42, Oxford University Press, Oxford, 2008; Ott in J Comp Ger Ling 4:1–46, 2011. https://doi.org/10.1007/s10828-010-9040-x). I propose that (i) case differences on the quantizing constituent boil down to the presence or absence of a case probe on a higher Agr head; (ii) and, the interpretive differences between the individuating and measuring pseudo-partitives are the result of a more subtle syntactic distinction in the feature content of the quantizing noun, i.e. an interpretable [±Container] feature.
Similar content being viewed by others


1 Introduction
Languages typically have dedicated morpho-syntactic means to express notions such as ‘number’ and ‘amount’. For instance, in English numerals like ‘2’ can modify a plural count noun as in (1). However, mass nouns like ‘water/tea’ cannot combine with numerals directly, as in (2).Footnote 1

The presence of what is sometimes referred to as a ‘quantizing noun’ (Lønning 1987; Chierchia 1998) is required to mediate between the numeral and the mass noun. These quantizing nouns can also mediate between a numeral and a plural count noun. This is shown in (3) where, in addition to the lexical nouns water/books, there is a noun such as kilos or glasses. I will be referring to these nouns as quantizing nouns.

Constructions like (3) are referred to in the literature as pseudo-partitives (Selkirk 1977; Jackendoff 1977; Lehrer 1986; Schwarzschild 2006, a.o.). One peculiarity of pseudo-partitives is that they are multiple-way ambiguous (Lønning 1987; Landman 2004; Rothstein 2009, 2017; Partee and Borschev 2012; Sutton and Filip 2021). This is illustrated with (4), from Sutton and Filip (2021, p.279: ex.1):

The interpretation of (4a) is making reference to the individual containers which are glasses and have wine in them. In other words, it is referencing the cardinality of glasses. I will call this interpretation individuating (ind). The interpretation of (4b) does not refer to the number of individual glasses, but to the quantity or volume of wine in two glass-sized contatiners. Thus, it is measuring the volume of wine. From now on, following Rothstein (2009), I refer to this interpretation as measuring (meas).Footnote 2 The interpretation of (4c) is similar to the one in (4b) because it makes reference to the quantity of wine content poured, but it does not entail the existence of a glass. This is referred to as the free portion reading. Lastly, according to Sutton and Filip (2021, p.280), the interpretation of (4d) denotes an ad hoc measure in which “only the wine is referred to and it need not have been contained by any glass”. In this paper, however, I will only concentrate on the first two, i.e. ind and meas, given that they are the most discussed in the literature and I leave the others aside for future research.
A prominent approach to deriving the ambiguity, within a single language and across languages, is based on syntactic ambiguity (Landman 2004; Rothstein 2009, 2017; Grestenberger 2015; Wilson 2018): pseudo-partitives have two distinct underlying structures, and each of them is mapped to a particular interpretation in the semantics. The specific proposals differ slightly from each other, but they all share the general idea that individuating pseudo-partitives have the cascading structure in (5) whereas measuring pseudo-partitives have some version of the structures in (6):Footnote 3

Syntactically, the structures differ in terms of the underlying constituency and headedness. In (5), glasses is the head of the nominal extended projection and takes the of-PP as a complement; the numeral is introduced in NumP and has syntactic scope over everything. In (6), glasses forms a constituent with the numeral and projects a Measure Phrase (MP).Footnote 4 The MP occupies a specifier position either of a noun as in (6b) or a functional head that is overtly realized as of as in (6a). The head of the whole phrase is thus the substance noun or the functional head that takes it as complement.
This is a very attractive proposal as it deals with the ambiguity in a way similar to interpretive differences in the domain of PPs or relative clauses, but it certainly has not been unchallenged (Brasoveanu 2009; Matushansky and Zwarts 2016; Matushansky et al. 2017). In particular, Matushansky and Zwarts (2016) and Matushansky et al. (2017) argue that measure pseudo-partitives have the cascading structure in (5), thus ruling out a syntactic ambiguity account. It is very much an open question, then, what the underlying syntax of ind and meas pseudo-partitives is.
While in some languages like English or Spanish the morpho-syntax of ind and meas pseudo-partitives is similar, at least on the surface, other languages might make an overt distinction between the two interpretations. One such language is Alasha Mongolian (Mongolic): the ind and meas interpretations correlate with a different case marker on the quantizing noun, as illustrated in (7) and (8):Footnote 5

In both (7a) and (8a), the quantizing noun bears comitative case (comit) and the interpretation can only be in terms of cardinality and never volume: the individual {pots/1-kilo containers} that contain tea are being counted, and they have a cardinality of 3. In both (7b) and (8b), the quantizing noun bears either overt genititve (gen) or no overt case marker; the only available interpretation is one in terms of volume or weight: the volume of tea as measured in two {pots/kilo-units}. In other words, for the ind interpretation to be felicitous, the quantizing noun must always be comit-marked, whereas the meas-interpretation arises when the quantizing noun is gen/Ø-marked.
The correlation between interpretation and case-marking can be corroborated by the semantic selectional (i.e. s-selection) properties of some verbal predicates. For instance, some verbs have certain s-selectional requirements that they impose on their complements, i.e. the complement must belong to a particular semantic class (Chomsky 1965; Grimshaw 1979; Cowper 1992; Pesetsky 1995). A verb like break requires its complement to be an “object” (or something that has identifiable boundaries) and not a liquid or a substance: break glass(es) vs. *break tea. On the contrary, other verbs like drink have the opposite s-selectional requirement; their complement must be a liquid: drink tea vs. *drink glass.
Applied to the pseudo-partitive data in Alasha Mongolian, we then expect that verbs like break are only compatible with complements whose quantizing noun is comitative marked, since they bring the ind interpretation. On the contrary, verbs like drink are expected to be compatible only with genitive or zero-marked pseudo-partitives, given that these give rise to the meas interpretation. This contrast is shown in (9) and (10):

As expected, comitative-marked pseudo-partitives inducing the ind interpretation are compatible with xaghalla: ‘broke’ as in (9a) but not with obsVn ‘drank’ as in (10a). The opposite pattern is observed for genitive and zero-marked pseudo-partitives: they are not acceptable with xaghalla: but they are with obsVn, as illustrated in (9b) and (10b) respectively. We can then safely conclude that every time the quantizing noun is marked comitative, the only possible interpretation is the individuating one; but, when the case marking on the quantizing noun is either genitive or zero, the only possible interpretation is the measuring one.
Given the data presented in (7) through (10), Alasha Mongolian provides an interesting case-test to the syntactic ambiguity hypothesis put forth by Landman (2004) and Rothstein (2009, 2017) among others, especially if we consider that differences in case marking might be the result of different underlying syntactic structures. If the Landman-Rothstein hypothesis is on the right track, we would expect (7a) and (8a) to have the cascading structure represented in (5). On the contrary, (7b) and (8b) should map onto a syntactic structure along the lines of (6).
The goal of the paper is to test this hypothesis from a syntactic point of view. In doing so, I show that the Landman-Rothstein hypothesis in Landman (2004) and Rothstein (2009, 2017) is not supported by the data. In fact, I argue that the underlying syntactic structures of pseudo-partitives in Alasha Mongolian are identical, as independently argued by Brasoveanu (2009), Matushansky and Zwarts (2016), Ruys (2017) and Matushansky et al. (2017), and the differences are more nuanced: the substance noun is always the head of the pseudo-partitive, and the numeral and the quantizing noun always form a constituent which is introduced by a null functional head that I call unit (Svenonius 2008; Ott 2011) in the extended projection of the substance noun. This head is similar to Schwarzschild’s (2006) Mon(onotonicity) head. I propose that the difference in case marking can be explained if (i) genitive is the unmarked case assigned to nominals as a result of an uninterpretable case feature that remains unmatched and therefore unvalued, in the sense of Bittner and Hale (1996) and Kornflit and Preminger (2015), and (ii) comitative is assigned locally under c-command.
Besides, within the MP itself, I argue that there must be an additional n which is in charge of the object-to-{container/content} shifts in pseudo-partitives (along the lines of Matushansky and Zwarts 2016). The unified syntactic structure I propose for Mongolian is potentially no different from the underlying structure of pseudo-partitives in other languages such as English, Dutch, Hebrew or Russian as argued for by Matushansky and Zwarts (2016), Ruys (2017) and Matushansky et al. (2017), modulo head-directionality. Although I do not attempt to provide a compositional semantics for the constructions in the paper, the analysis has consequences for the compositional semantics of pseudo-partitives.
The paper is structured as follows: §2 provides some background to Alasha Mongolian, both in terms of ethnography and also in terms of linguistic properties. In this section, I discuss the word order inside of NPs and the essentials of number marking in the language. §3 focuses on diagnosing the constituency of the pseudo-partitive and various word order facts. §4 spells-out the analysis, and §5 discusses some of broader implications of the analysis. §6 concludes the paper.
2 Some background essentials
Alashan Mongolian is a variety of Mongolian spoken in the Alxa League region located in west inner Mongolia.Footnote 6 The total number of speakers is unknown as there is no reference to this information in any of the modern Mongolian grammars I have consulted. The only source that reports an estimate is wikipedia, which indicates that the number of Alasha Mongolian speakers is roughly 40,000.Footnote 7
Like other languages in the Altaic family (Turkish, Sakha, Buriat a.o.), Alasha Mongolian is head final: the canonical order is SOV (11a), it has postpositions (11b) and adjectives precede the noun they modify (11c). Moreover, it has a rich case system whose exponents are spelled out in the noun. Among the relevant cases, Alasha Mongolian distinguishes acc(usative), dat(itve), gen(itve), instr(umental) abl(ative) and comit(ative). Except for certain pronouns, nominative is covert (see also Gong 2022, for the same observation in other Mongolian varieties).

Concentrating on the nominal domain, Alasha Mongolian lacks definite articles but has a demonstrative system. Demonstratives and possessors, which cannot cooccur, precede numerals, adjectives and complements of the noun. Case and number marking, if overtly expressed, are only spelled-out on the head noun. Prenominal modifiers such as numerals and gradable non-classificatory adjectives bear an attributive morpheme ‘-n’ (Toquero-Pérez 2023).Footnote 8 The basic order of the Alasha Mongolian DP is schematized in (12) with an example:

Before probing the internal structure of the pseudo-partitive, a few notes are in order with respect to number marking and numeral and adjectival modification in the language, as reported in Toquero-Pérez (2023). As already indicated, Alasha Mongolian makes a morpho-syntactic distinction between singular and plural marking on the noun: singular is unmarked, e.g. ‘Ø’, and plural is marked as ‘-v:d’, the vowel being subject to vowel harmony conditioned by the root. Some examples are given in (13):

The data in (13) show that there is a difference between unmarked inanimate nouns like nom ‘book’ and animate ones like xü ‘boy’: the former are number neutral and can make reference to singular individuals (i.e. one) or a plurality (i.e. more than one); the latter are strictly singular. This number neutrality is supported by the fact that unmarked inanimate nouns are compatible with distributive adjuncts, whereas animates ones are not as shown in (14):Footnote 9

The number neutrality of inanimate nouns is blocked if the noun is modified by non-classificatory gradable adjectives such as tam ‘big’. The noun nom ‘book’ in an example like (15) must be interpreted as a singular.Footnote 10

Count nouns can be overtly plural-marked, as shown in (13). Alasha Mongolian plural-marked nouns, regardless of animacy, behave like English plural nouns (Krifka 1995; Sauerland 2003; Sauerland et al. 2005; Zweig 2009, and others): they are exclusively plural in upward entailing contexts, e.g. (16), and inclusively plural in downward entailing contexts (and questions), e.g. (17):

The sentences in (16) are true if and only if (i) the speaker bought more than one apple or (ii) saw more than one boy. On the contrary, the sentences in (17) are false if the speaker (i) bought one apple or (ii) saw one boy.
Despite the availability of an overt plural-marker, numerically modified nouns must be unmarked. In fact, the presence of a plural marker on the noun makes the Numeral > N sequence ungrammatical. This is shown in (18):

One possibility would be to say that the noun has to be number neutral to combine with numerals as argued by Bale et al. (2011), but given that animate unmarked nouns like xü ‘boy’ are strictly singular, this hypothesis is not supported. Furthermore, numerals are incompatible with overt plural morphology on the noun, which is the other possible way to create a plurality in the language. Thus, I follow Toquero-Pérez (2023) and conclude that numerals in Alasha Mongolian require the noun they modify to be both syntactically and semantically singular (Ionin and Matushansky 2006, 2018).
3 Diagnosing the structure of pseudo-partitives
Alasha Mongolian has different classes of quantizing nouns. A non-exhaustive list is given in (19) to (21), where the terminology is borrowed from Rothstein (2017).

As evidenced by the examples in (7)–(10), the (linear) word order of pseudo-partitives in the language is schematized in (22). Moreover, quantizing nouns, like ordinary sortal nouns in (13), can be pluralized. This is illustrated in (23).

However we have seen, at the end of Sect. 2, that in the presence of a numeral the noun directly modified by the numeral must be unmarked for number (and also denote a singleton). In the pseudo-partitive construction, it is always the quantizing noun that must always be unmarked for number. This is shown in (24) for meas-pseudo-partitives and in (25) for ind-ones.

On the contrary, the substance noun of the pseudo-partitive may be pl-marked. In fact, if countable and animate, it must be plural-marked. The relevant data are given in (26):

The optionality of plural marking on inanimate substance nouns is expected if the bare noun is number neutral. Likewise, the requirement of the plural morpheme on the animate substance noun is also expected given that strict singular nouns cannot occur in pseudo-partitives (Schwarzschild 2006, e.g. two boxes of { cats/ *cat}).Footnote 11
In addition to number marking, the quantizing and substance noun in the pseudo-partitive differ with respect to case marking. Depending on the interpretation, the quantizing noun receives genitive/Ø or comitative. However, the substance noun is assigned case externally depending on the syntactic position that the nominal occupies. If the pseudo-partitive nominal is some type of applied object, the substance noun can receive instrumental case as in (27a), but if it is the direct object (and marked for [+specific], von Heusinger and Kornflit 2017) it will receive accusative as in (27b).Footnote 12

In (27) the case marker spelled-out on the substance noun is determined by the syntactic position of the pseudo-partitive DP: instrumental in (27a) and accusative in (27b). However, the case marker on the quantizing noun is invariant (modulo the ind/meas-ambiguity). A summary of the patterns found so far is given in Table 1.Footnote 13
What we can conclude from this is that there are two independent \(\varphi \)- and case-domains: one determined by the substance noun and the other determined by the quantizing noun. The singularity restriction imposed by the numeral on the quantizing noun seems to suggest that the numeral and the quantizing noun are in a more local relationship than the numeral and the substance noun. This is supported by the fact that pure mass nouns like tea or water can never be directly modified by a numeral, even in packaging and sorting contexts, as in (28).

On the contrary, the substance noun has no number markedness requirements that depend on the numeral (i.e. the substance noun can, and in some cases must, be overtly plural marked). What is more, the fact that the substance noun receives case externally can be taken as evidence that it heads the whole nominal. This contrasts with the quantizing noun which never spells out external case (for similar observations see also Matushansky et al. 2017).Footnote 14
In the remainder of this section, I probe the constituency and structure of the pseudo-partitive. In doing so, I (i) apply different constituency tests—including coordination, movement, constituent-only modification—and (ii) check for various word order facts.
3.1 Applying different constituency diagnostics
Coordination. Coordination is a fairly standard constituency test, if we operate under the assumption that only constituents can be coordinated (Phillips 2003; Carnie 2012). The goal of this test is to probe whether (i) the numeral and the quantizing noun can be coordinated or (ii) the quantizing noun and the substance noun can be coordinated.
There is a potential caveat with coordination when numerals are involved, though. As Ora Matushansky (p.c.) points out, native speakers generally struggle with coordination patterns involving a numeral and (plural) count NP. For instance in English, 4 boys and girls can lead to (at least) three possible interpretations as shown in (29).Footnote 15 These interpretations can be thought of as the result of different underlying structures, each of them provided in (30) for the relevant paraphrase.

To obtain the interpretation in (29a), what is being coordinated is the two NPs and the numeral, which in the second conjunct is covert. We can refer to this reading as the ‘numeral sum reading’. That is because, when composing the meaning of the two conjuncts and assuming that the resolution of number in coordination requires set union (Link 1983; Krifka 1990), the numeral in each conjunct is summed: the result is a totality of 8 people, 4 of whom are boys and 4 of whom are girls. The interpretation in (29b) can be regarded as the result of coordinating a larger structure: the DP four boys and the bare plural DP girls. We can refer to this interpretation as the ‘numeral + indefinte plural’ reading. The third interpretation can result from coordinating the two NPs, e.g. boys and girls, to the exclusion of the numeral, which takes scope over the coordinated constituent. There is a crucial and welcome difference between the structure in (30c) and the one in (30a): compositionally, in (30c), set union applies to the plural NPs first creating a plurality of boys and girls, and then the numeral restricts the cardinality of that plurality to four. We can refer to this interpretation as ‘overall sum reading’.
In Alasha Mongolian, coordination of numeral-noun combinations is no different than it is in English. The three interpretations available for English in (29) are also possible in Alasha Mongolian. We must bear in mind, however, the animacy distinction that the language makes: an inanimate unmarked noun in the second conjunct may be number neutral, whereas an animate one cannot; it has to be strictly singular. The relevant coordination patterns are shown in (31) and (32) for inanimates and animates respectively:

These baseline cases show that coordination of numeral-noun combinations are possible and associated with the interpretation resulting from the sum of the two numerals, as in (31a) and (32a). In addition, they show that coordination of NPs excluding the numeral is allowed, so long as the interpretation is one where the numeral restricts the cardinality of the plurality previously formed by coordinating the NPs, as in (31c) and (32c). These coordination patterns make interesting predictions about the constituency of the pseudo-partitive in Alasha Mongolian.
If the numeral and the quantizing noun belong to the same domain to the exclusion of the substance noun, they should behave as a syntactic constituent and may be coordinated. Furthermore, the ability to coordinate the sequence [Numeral Nquant] will give rise to the ‘numeral sum reading’. On the contrary, if the quantizing noun and the substance noun form a constituent and can be coordinated, we expect the ‘overall sum reading’ instead. This is because the numeral is excluded from the coordinated constituent and takes scope over it, restricting the cardinality of the plurality formed by the composition of the two conjuncts. These patterns should be observed regardless of case-marking on the quantizing noun. The predictions are summarized in (33):

The relevant data are given in (34) and (35) for meas and ind pseudo-partitives respectively. The coordinated elements are in bold. For ease of reference, I provide the translation first with the intended bracketing, and then below it I give the intended idiomatic interpretation.Footnote 16

The examples in (34a) and (35a) indicate that it is possible to coordinate the pseudo-partitive as a whole, i.e. [Numeral Nquant Nsubs], suggesting that the two potentially different domains are part of a larger nominal. The sentences in (34b) and (35b) show that it is also possible to coordinate the numeral and the quantizing noun to the exclusion of the substance noun. What is more, the interpretation is as predicted in (33a). This reinforces the hypothesis that the numeral and the quantizing noun are actually a constituent. The examples in (34c) and (35c) are slightly more involved: when attempting to coordinate the two nouns to the exclusion of the numeral as in (34c) and (35c), ungrammaticality obtains and the intended ‘overall sum reading’ is not available. Thus, a bracketing like the following, where the numeral takes scope over the coordinated constituent, is ruled out: [4 [[Nquant Nsubs] & [Nquant Nsubs]]].Footnote 17
The constituency data from coordination, thus, support the hypothesis that the numeral and the quantizing noun are syntactic constituents regardless of the ind/meas-ambiguity. It also provides promising evidence that the quantizing and the substance nouns do not form a single constituent, and thereofre belong to different domains within the larger nominal. As with any constituency test, though, failing to pass the test does not entail non-constituency. Thus, we must find additional evidence that supports this hypothesis.
Right dislocation. Another classic phrasal constituency diagnostic is movement. It is typically agreed upon that for an element to undergo displacement that element must be a constituent (Chomsky 1965, 1973, 1986, 1995, et seq.). Thus, if the numeral and the quantizing noun form a constituent, they may be able to move as a unit. As before, the data in (36) shows this is correct:

While the numeral and the quantizing noun can be displaced in (36a), the quantizing noun and the substance noun cannot be displaced stranding the numeral as in (36b). It is not unnaceptable for the substance noun to undergo movement on its own as illustrated by (36c).
It is important to rule out the possibility that the ungrammaticality of cases like (36b) may be due to stranding a numeral, rather than to the rightward movement of a non-constituent.Footnote 18 We can demonstrate that this is not the case by showing that NP extraction stranding the numeral is acceptable in the language. As illustrated in (37), an NP like nom can appear dislocated while the numeral stays in situ inside the DP.

Furthermore, the data in (36) involve movement rather than base-generation on the right as indicated by extraction out of complex NPs. The subject of the embedded clause in Alasha Mongolian may be overtly marked genitive. Complex NPs disallow constituents to move out of them as the example in (38) shows (see also Lee 2023):

In (38b), extraction of the accusative-marked object results in ungrammaticality. If we embed the pseudo-partitive inside a complex NP and attempt to extract a part out of it, the same result obtains. This is illustrated in (39) for meas-pseudo-partitives, although the pattern with ind-ones is identical.

Once again, the data support the hypothesis that the numeral and the quantizing noun must form a constituent regardless of the individuating or measuring interpretation.
Modification by only. In Alasha Mongolian, there are two focus particles meaning only: the adverbial dzuxun and the suffix -l (Lee 2023). The standalone adverbial dzuxun must precede the phrase it modifies. That is, when modifying DPs it must occur in a pre-DP position. While it is possible for dzuxun to precede, and thus modify, the numeral and the quantizing noun, it cannot be followed by the quantizing noun and the substance noun. The paradigm for meas is given in (40) and the one for ind is given in (41).

As the b-examples indicate, dzuxun cannot modify the sequence [Nquant Nsubs]. However, when it occurs before the numeral, as in the a-examples, the sentences are ambiguous: dzuxun can modify just the numeral and quantizing noun or the whole pseudo-partitive DP. We can take this interpretive ambiguity to be the result of a structural difference depending on the pre-DP position of dzuxun. In particular, it can attach to two places: (i) to the edge of the nominal containing the quantizing noun and the numeral, in which case the interpretations in (40a-I) and (41a-I) are obtained; and (ii) to the edge of the whole nominal, in which case the interpretations in (40a-II) and (41a-II) are possible. Schematically the two different structures would look as in (42):

One might wonder whether the position of dzuxun is really as in (42a), directly modifying the DP formed by the numeral and quantizing noun, or whether it is direcly modifying the numeral. There are good reasons to side with the former and not the latter. First, cross-linguistically, as argued by Ionin and Matushansky (2018, ch. 9), modifiers of numerals including superlative phrases like at least/at most and adverbials such as approximately never form a constituent with the numeral. They are AdvPs that function as DP-internal adjuncts. We can consider only/dzuxun to be no different.
Second, the affixal focus particle -l also meaning ‘only’ must attach to the head of the phrase that is being focused. This is shown in the example in (43) taken from Lee (2023):

If -l attaches to the head of the phrase that is being focused and that element is the quantizing noun modified by the numeral, then we expect that -l surfaces as an affix to the noun. If instead what is being focused is the numeral, we expect the suffix to be spelled out on the numeral itself. As the data in (44) and (45) show, the latter option is ungrammatical.Footnote 19

In addition to the distribution in (44) and (45), affixal only can attach to the substance noun. In that case, the interpretation is as in (42b). The relevant examples for meas and ind pseudo-partitives are given in (46).

The examples of affixal ‘only’ replicate the patterns observed for dzuxun. We can thus conclude that neither focus morpheme directly modifies the numeral, but the DP in which the numeral is contained.
Summary Taken together the constituency diagnostics applied in this section are summarized in Table 2. The diagnostics reveal that in terms of internal structure, the two types of pseudo-partitives pattern together: the numeral and quantizing noun (i.e. the MP), regardless of case-marking, form a constituent to the exclusion of the substance noun. This seems to go against the syntactic ambiguity hypothesis put forth by Landman (2004) and Rothstein (2009, 2017).
3.2 Word order in the pseudo-partitive
The data in subsection 3.1 help us diagnose the constituency of the pseudo-partitive, but they do not tell us much about the fine-grained structure of the NP. In order to do that, we must look at the position of the MP and nominal modifiers, arguments of nouns, and possessors.
It was shown in (12) that APs linearly preceded both nouns and their complements. Thus, APs like xortotstei ‘fast’ or xunde ‘expensive’ must appear to the left of the complement+N compound as in (47), and after a numeral as in (48).

While the position of the numeral and the adjective is invariant, the complement of the noun may optionally appear to the left of the numeral. An example is given in (49): the gen-marked complement xol-ni ‘food-gen’ precedes everything else in the noun phrase. As far as I can tell, there is no informational-structural difference between (48b) and (49)

With respect to possessors, we also saw in (12) that possessors occupied the leftmost position in the NP. When there are a possessor and a complement of a noun, the canonical order is \(\textsc {Poss> (\#> AP>) Comp > N}\) as in (50a). The complement of the noun may still surface higher than the possessor as in (50b); but if the possessor binds a recriprocal anaphor inside the noun’s complement, the complement cannot precede the possessor, e.g. (51):

The facts in (50) and (51) are showing two separate things: (i) complements, or arguments, of nouns may undergo movement to the leftmost position in the NP across possessors; (ii) movement of the complement of the noun across a possessor that binds it results in ungrammaticality.Footnote 20
That said, there are two possible word orders inside the NP summarized in (52), with any deviation being ungrammatical. Given these sets of facts, the general observation seems to be that complements or arguments of the noun are generated low, below gradable adjectives, and may optionally (Ā-)move to a higher position disrupting the canonical AP> Comp> N order and above possessors.

We can assume, based on these ordering patterns, that possessors are (externally) merged in the highest position within the DP and that any phrasal constituent that appears to the left of the possessor must have been internally merged above possessors. We can use these sets of facts to probe the position of the MP in pseudo-partitives relative to these NP-internal elements.
With respect to the MP constituent composed of the quantizing noun and the numeral, it must appear to the left of APs as (53).

If the substance noun takes a complement, the base order is in (54a); but as we have already seen, the noun’s complement may optionally move to the left. If that occurs, it will appear to the left of the MP. This is seen in (54b):

With respect to possessors, we observe that, like complements of nouns, MPs can appear to the right of possessors, but also to their left. This is shown in (55):

(55a) could in principle be ambiguous between two interpretations: one where the possessum is the seven boxes, and an other in which the possessum is only the books. We can hypothesize that the former interpretation arises as a result of the possessor being contained in the MP, whereas the latter is the result of the possessor being MP-external, taking scope over the whole DP. In fact, this can be disambiguated in two different ways: (i) when the MP appears displaced to the left of the possessor, as in (55b), only the MP-external possessive reading is possible; (ii) also, the MP can have its own possessor. For example, Batrin ‘Batar-gen’ in (55c) is the possesor of the book while xüchüdin ‘child-pl-gen’ possesses the 7 boxes.Footnote 21.
In this section, I have shown what the possible DP-internal word order patterns are. We have seen that MPs precede everything but possessors, which occupy the highest position in the DP. Any other deviation from this orders that is grammatical has to be derived by movement. The possible orders are as summarized below in (56) and (57):

3.3 Summary
I have applied a series of diagnostics that probed the internal constituency of pseudo-partitive constructions in Alasha Mongolian. The results support the observation that the numeral and the quantizing noun form a unit, which I have referred to as MP so far, regardless of the case marking on the quantizing noun. The substance noun, however, does not belong within the MP. In addition, word order facts reveal no evidence that supports the claim that MPs occupy different positions depending on whether they are gen/Ø-marked or comit-marked. In fact, there are two possible word order patterns for internal MP-constituents: (i) MPs are higher than complements of nouns—if there are any—and adjectives, but lower than possessors; (ii) MPs can precede everything including possessors. In fact, this suggests that the MP and complements of nouns enter the derivation in distinct positions and have slightly different properties.
4 Analysis
4.1 Spelling out the assumptions
Before moving to the proposal, I want to outline some of the ancillary assumptions that I will be adopting. First, I assume that all syntactic operations—Agree and Merge (both internal and external)—are feature driven (Svenonius 1994; Adger 2003; Lechner 2004; Pesetsky and Torrego 2006; Heck and Müller 2007; Müller 2010, a.o.). In particular, following Heck and Müller (2007) and Müller (2010), I assume that features come into two classes depending on the operations that they trigger: structure building features responsible for Merge, and probe features that participate in Agree operations. Structure building features are represented as [\(\bullet \hbox {F}\bullet \)], and are discharged upon merger of the subcategorized element. Probe features include uninterpretable and interpretable feautres. The uninterpretable features, notated as uF, are probe features. Interpretable features will be noted as bivalent ±F pairs following Harbour (2011): [+F] \(\sim \) [-F]. uFs can themselves be unvalued or inherently valued (Pesetsky and Torrego 2007): [uF: val] \(\sim \) [uF:_].
In addition, I assume, also following Müller (2010), that (i) the two types of features are organized into separate feature stacks and that (ii) at least the features within the structure building stack are ordered. This ordering ensures that, for example, internal arguments are merged before external arguments.
Following Chomsky (2000) and others, I will assume that there is an operation called Agree between a probe and a goal. We can adopt the standard definition in (58) for the operation, taken from Zeijlstra (2012, p.492):

I further assume, as it has become standard in the literature on Agree, a two-step model of Agree that separates the matching operation (Agree-Link) from the valuation one (Agree-Copy), (Benmamoun et al. 2009; Bhatt and Walkow 2013; Arregi and Nevins 2012; Smith 2021). This is defined in (59), adapted from Smith (2021).

While the Agree-Link operation is obligatory, i.e. the search procedure must take place, its successful culmination, i.e. the probe finding an appropriate matching goal, is not (Preminger 2014). If Agree-Link fails, Agree-Copy will not occur. However, this does not entail that the derivation will crash upon transferring the structure to the interfaces.
The workings of the system are illustrated in (60) for a transitive v. The derivation of the vP is given in (61), where \(\varphi \) is a placeholder for features including, but not limited to person (\(\pi \)), number (Num) or gender (\(\gamma \)).

Transitive v has two separate feature stacks. v subcategorizes for two KPs, the internal and external argument. Thus, it subcategorizes for two [\(\bullet \)K\(\bullet \)] features. In addition, v has two probe features: an unvalued phi-probe feature [\(u\varphi \):_] and a valued case probe feature [uCase:acc]. The topmost [\(\bullet \)K\(\bullet \)] feature is discharged upon the merger of the internal argument (61a). The probes search their c-command domain for potential matching goals and they find the just-merged K in the complement position. Agree-Link has been successful: the result is \(\varphi \)-feature valuation on the probe and case assignment to the goal, as in (61b). Last but not least, the second [\(\bullet \)K\(\bullet \)] feautre is discharged when the external argument is merged, saturating v’s features, as shown in (61c).
4.2 Motivating the structure
First, I assume, following Harbour (2007, 2011, 2014), Kramer (2017) and Martí (2020), that number neutral NPs, and also mass nouns (Borer 2005; Harbour 2007, 2011), lack a NumP. NumP, and other individuation-based projections, are not projected unless there is morpho-syntactic evidence to do so: overt plural morpheme, non-classificatory adjectives, and numerals. The structure for inanimate number neutral NPs and mass NPs in Alasha Mongolian is in (62). However, animate NPs always project NumP, given that they are strictly singular, as in (63). I am assuming that (i) class features, such as animacy or gender, are located on n following Kramer (2015, 2016) and others; and (ii) Num, when present, will bear the interpretable features [±atomic] (Harbour 2014): [+atomic] marks the NP as singular, while [-atomic] is responsible for creating pluralities.

The more articulated structure of the nominal is provided in (64). This is the structure that includes possessors, numerals, non-classificatory adjectives, and complements of nouns. Features on the relevant heads have been removed for ease of representation.

The root adjoins to the categorizing head n which labels it as a noun (Halle and Marantz 1993; Embick and Noyer 2001; Levinson 2007). If the noun takes a complement (e.g. of/about food), the complement will be selected by n following Merchant (2019). When NumP is projected, it encodes singular or plural number (Ritter 1991; Harley and Ritter 2002; Cowper 2005; Harbour 2007) and it may introduce non-classificatory gradable adjectives in its specifier. This is based on the observation that the presence of these adjectives has an effect on the number interpretation of the NP (e.g. (15)). Numerals are introduced by their own functional head (Zabbal 2005; Kayne 2005; Cinque 2010, 2023; Scontras 2013; Pancheva 2021) which I label here as card(inality)P following Scontras (2013). If there is a possessor, I assume that it is generated in the specifier of the D head (Abney 1987; Corver 1990).Footnote 22 The highest head in the extended projection of the noun is K, projecting a KP (Bittner and Hale 1996).
The structure in (64) accounts for the base word order in (12), repeated in (52a), and straightforwardly derives the order in (52b) via movement of the noun’s complement above the possessor. The complex n+\(\sqrt{\textit{nom}}\) heads the whole extended projection and, thus, number morphemes and external case are spelled-out on it. K, and only K, is the locus of unvalued uninterpretable case features; thus any K will bear unvalued case features: [uCase:_]. In order for the nominal to receive case externally, the KP has to enter into a dependency with a head outside the nominal, e.g. v, T, Appl.
Now that the basic assumptions about the nominal spine have been laid out, we can go back to pseudo-partitives. The constituency and word order data discussed do not support the syntactic ambiguity proposed by Landman (2004), Rothstein (2009, 2017), Wilson (2018) and others. And yet, the language makes a morpho-syntactic distinction on the quantized noun: when the quantized noun shows comitative case, the interpretation is an individuating one; when the quantizing noun is genitive, the interpretation is a measuring one. What is more, in both cases, the quantizing noun is never the head of the full extended projection. Instead, its distribution is more like that of a DP-internal argument. Crucially, it cannot occupy the complement position of n because complements are structurally lower than the pseudo-partitive MP, e.g. (57).
I take these facts to indicate that the MP is not introduced by n, but a different functional head in the nominal spine that is available for both mass nouns and count ones (this rules out Num, under the assumption that Num is absent in the mass domain, and in number neutral inanimate nouns). The function of this head is to map a substance or a content to a unit that contains it. This is one of the functions displayed by classifiers (Cheng and Sybesma 1999; Borer 2005; Svenonius 2008). Thus, I propose to analyze this functional head as a null classifier that appears above nP. I call this head unit following Svenonius (2008) and Ott (2011) to distinguish it from traditional numeral or mensural classifiers. In addition, I propose that quantizing nominals include a layered n that is responsible for deriving objects into containers.
The syntax I propose for pseudo-partitives is represented in the structure in (65).

There are three main pieces that pseudo-partitives make reference to: (i) an entity, i.e. the substance; (ii) the measure of the substance relative to a unit, i.e. the container; and (iii), the dimension along which the entity is measured. The role of unit is to glue (i) and (ii) by mapping the entity and the unit, and introducing a measure role. The structure and the function of unit are very much in line with Schwarzschild’s (2006) Mon(otonicity) head. In fact, for Schwarzschild (2006) Mon takes the substance noun as complement and introduces the relevant MP in its specifier, and ensures that the dimension of measurement is extensive, i.e. it tracks the part-whole relation of the domain being measured (e.g. cardinality, volume or weight, but not speed or temperature).
The unit head introduces a KP in its specifier. This KP is what so far we have been referring to as MP, and will introduce the measuring unit (pots, kilos, bowls etc.). We know that the quantizing phrase has to be a full KP since it receives case and is able to host possessors, which are both compelling evidence for them being fully fleshed nominals. In addition, by looking at the structure in (65), we observe that the constituency facts are explained: the quantizing KP can be coordinated, moved and modified by dzuxun ‘only’ to the exclusion of the substance noun. Likewise, the word order facts in (56) and (57) also follow: being higher than nP, the quantizing KP is linearized to the left of the noun’s complement; being lower than DP, it is c-commanded by possessors.Footnote 23 I assume that there is a DP-internal AgrP responsible for triggering Agree-operations within the DP. This AgrP immediately dominates, and therefore subcategorizes for, unitP.Footnote 24 The proposal will derive the individuating-measuring ambiguity from two interacting factors: the different flavors of the Agr head, and the features on the layered n above the nominalized root inside the quantizing KP.
Within the quantizing constituent, what sets these nominals apart from regular entities or objects is the presence of an additional head (cf. Matushansky and Zwarts 2016). I labeled this head in (65) as an n head which is responsible for deriving the quantizing interpretation of the noun. Container-content nouns are polysemous between a regular object interpretation and a container-like interpretation (Pelletier 1975; Allan 1980; Duek and Brasoveanu 2015, et seq.). Following Kiss et al. (2021), I take this polysemy to be the result of added syntactic structure to the basic noun spine. Thus, the proposed n head may transform a regular object like box, glass or kilo into a container that is instantiated by that object, whether it is concrete (like box) or abstract (like kilo). I propose to encode this in n as an interpretable feature [±Container]. The positive value of the feature shifts the nP to a container shaped-object. The negative value, by contrast, indicates that there is some container-like element, its nP complement, that will be filled with some substance portion. In other words, it entails the existence of a container that will serve as measuring unit; but most importantly it foregrounds its (to-be filled) contents. We can define these features in prose as in (66).Footnote 25

A few words are in order with respect to this quantizing n. Positing this layered n head in the syntax might seem like a stipulation driven to facilitate semantic compositionality. However, we must note that quantizing n heads can have their own morphological exponent in some languages, and show the same morpho-syntactic behavior as other ns. For instance, in English, a [-Container] n can be spelled-out as -ful, in which case it appears between the root and number morphemes. In fact, it can block irregular plural morphology triggered by the root as in (67):

The fact that -ful may block irregular number suppletion can be taken to signal that container information may enter the syntactic derivation as a functional head between n and Number. In the case of Alasha Mongolian, this quantizing n is null.
With these pieces in our toolbox, I propose that Agr has the set of features provided in (68):

Agr selects for unit and bears an unvalued probe container feature. Since this feature is unvalued, it must probe for a goal via Agree-Link and copy its features. On the other hand, the quantizing KP, regardless of its interpretation, has an unvalued case feature and an interpretable quantizing feature that it has inherited from n’s projection. This is shown in (69):

Considering now the feature matrices for Agr and quantizing KPs, we can observe that they are able to enter an Agree dependency: Agr is the target of the agreement and requires its container feature to receive a value by copying it from an available controller. The only available goal in its c-command domain is the quantizing KP in Spec,unitP. Thus, Agree-Link and subsequent Copy can apply. This is shown in (70):

As a result of successful Agree-Link, the container feature is copied onto the probe. If the container feature is set to [-] the semantic interpretation should come out as a measuring one, given the content of the container feature in (66) (also see footnote 25). If the value of the container feature is [+], by contrast, the only possible interpretation given our proposal should be an individuating one.
The dependency in (70) is not about case. In fact, case on KP will remain unvalued. This is a challenge since there is no way to distinguish how comitative gets assigned to some quantizing KPs, but genitive case is assigned to others. In the next section, I argue that there is a general difference between comitative and genitive case with respect to how they are assigned. I survey their distribution and conclude that, while comitative is lexically assigned by designated heads, genitive is unmarked. This will lead to positing a difference within the Agr heads in terms of the probe features that they bear.
4.3 Accounting for the case difference
Any nominal-internal embedded KP (e.g. complements of nouns or possessors) will receive case internally, within the matrix KP. With the exception of complements of nominalized verbs which receive accusative, as shown in (47), typically, all other nominal-internal embedded KPs bear genitive case. In fact, if we look at the environments where genitive case occurs in the language, provided in Table 3, we find that its distribution is very diverse and does not fully comprise a natural class.
As opposed to genitive, comitative is more restricted in its distribution. There are only three environments where it surfaces: complement of an adposition xampt, roughly ‘with’ as in (71a), possessive ‘have’ constructions as in (71b), and individuating pseudo-partitives. All these contexts have in common the notion of ‘having’ or ‘possession’.

Given the distribution of both genitive and comitative cases, I propose to analyze genitive as the unmarked case in the sense of Bittner and Hale (1996), Kornflit and Preminger (2015) (and Gong (2022) for other varieties of Mongolian): genitive arises as a result of the absence of valued case features. In other words, the unvalued case feature on the measure KP will fail to enter an Agree-Link dependency with a c-commanding probe and will subsequently not copy a value from such c-commanding case probe. Comitative, however, is idiosyncratically assigned via Agree.Footnote 26
If comitatitve is assigned via Agree, whereas genititve is unmarked, this entails that the Agr head that I have proposed in (68) must come in two different versions, depending on whether it bears a case probe or not. This is shown in (72):

The two heads share the structure building feature set: they both subcategorize for a [\(\bullet \) unit\(\bullet \)]. But they differ in their probe features. Agr\(_1\) in (72a) has an uninterpretable case feature inherently specified for comitative, and an unvalued uninterpretable container feature. On the contrary, while Agr\(_2\) in (72b) has an uninterpretable container feature which is unvalued, it lacks a case probe.
That said, we can now derive how individuating pseudo-partitives are assigned comitative while measuring ones receive genitive. First, the structure for an individuating quantizing KP is given in (73). The relevant changes from (65) include the inherent value on the interpretable quantizing feature on n, which is [+Container], and the percolation of features to the KP node (Lieber 1989; Anderson 1992; Grimshaw 2000; Norris 2014; Grabovac 2022):

The unit head introducing the quantizing KP has the composition in (74), after discharging its topmost structure building feature, e.g. [\(\bullet \)N\(\bullet \)]. Given the order of the structure building features, the next step in the derivation is to merge the KP in (73) in its specifier.

The next step in the derivation is to merge the Agr\(_1\) head in (72a). Upon merger, its structure building feature is discharged. Then, the probe features initiate the Agree-Link search. The derivation is shown in (76).

The valued [uCase: comit] feature on Agr\(_1\) probes its c-command domain and matches the unvalued case feature on the KP. Likewise, Agree-Link between the [uContainer] feature on Agr\(_1\) and the interpretable [+Container] feature on the same KP is also successful, as illustrated in (76b). The relevant values are then copied onto the unvalued features, as in (76c): the KP receives comitative case, and Agr\(_1\) receives a container value.
The derivation of the measuring pseudo-partitive is different. First, although the geometry of the quantizing KP is the same as the one in (73) for the individuating pseudo-partitive, the inherent value of layered n is set to [-Container]. This is illustrated in (77).

Crucially, the Agr\(_2\) head in the extended projection of the substance noun is also different. After it is merged with the unitP, the structure is as in (78).

Agr\(_2\) has only one unvalued probe feature, e.g. [uContainer]. This feature searches its c-command domain for a potential matching goal which is the [-Container] feature on the KP. The linking dependency is successful and the goal’s value is subsequently copied onto the probe. This is represented in (79b).

As illustrated in the derivation, there is only an Agree dependency between Agr\(_2\) and KP. There is no linking or matching with respect to case. Thus, the case feature on the KP remains unvalued. Instead of leading to a crash at the point of transfer, the [uCase] feature on the quantizing KP receives the unmarked case value, which in the case of Alasha Mongolian is genitive: [uCase: gen] \(\Leftrightarrow \) {-in/Ø}.
The derivation of the measuring pseudo-partitive thus contains the same morpho-syntactic pieces as the individuating one, i.e. the unit, a quantizing KP, a substance/content noun, and Agr head; but what sets the two apart is the feature make-up of the elements involved. In particular, the Agr head responsible for the measuring pseudo-partitive lacks a case probe feature resulting in the emergence of the unmarked case on the KP; the quantizing n is specified as [-Container] which foregrounds the substance and entails the presence of a container that is set as the measure-unit whose value will be mapped onto a scale of volume, length, or weight, but not cardinality. As a result, the individuating-measuring ambiguity is more intricate and nuanced than just a simple structural ambiguity.Footnote 27
5 Broader cross-linguistic impact
The account proposed to analyze the properties of pseudo-partitives in Alasha Mongolian relies on there being one underlying syntactic structure for individuating and measuring pseudo-partitives. Any differences between them boil down to the content of the functional heads involved in the syntactic derivation feeding the semantic composition. This raises the questions of how languages differ, if they actually do, and how we can capture cross-linguistic variation.
First, the data and syntactic structure proposed do not align with the Landman-Rothstein hypothesis that individuating and measuring pseudo-partitives have an underlyingly distinct syntax. Instead, the proposed geometry is in line with Matushansky and Zwarts (2016), Ruys (2017) and Matushansky et al. (2017). After discussing data from a varied number of languages, including English, Russian, Dutch, Greek, Albanian and Hebrew, they argue that in none of these languages is there significant evidence for ambiguity and, in fact, a uniform syntax is empirically supported. Furthermore, similar findings of a uniform syntax have been reported by Hankamer and Mikkelsen (2018, 2008) for Scandinavian (with an emphasis on Danish) and Toquero-Pérez (2022a, 2022b) for Spanish. To this pool of languages, we can now add Alasha Mongolian. There are some differences between the syntax proposed by these authors and the one advocated for here: for Matushansky and Zwarts (2016); Ruys (2017) and Matushansky et al. (2017) the structure is always as in (5); and for Hankamer and Mikkelsen (2008, 2018), Toquero-Pérez (2022a, 2022b), the phrase containing the substance is always a sister to a DP node rather than the complement of n. I have argued that neither of them could be accurate for Alasha Mongolian based on the possible word orders.
However, the three analyses share the same underlying hypothesis: there is no headedness or constituency difference between individuating and measuring pseudo-partitives. In fact, we could recast the two analyses under the proposal here. For head-initial languages like those analyzed by these authors where the head of the NP is the quantizing noun, the constituent containing the substance noun is introduced as an argument of the layered quantizing n:

The fact that the of wine phrase might appear higher on the surface, as Hankamer and Mikkelsen (2008, 2018), Toquero-Pérez (2022a, 2022b) propose, can be due to DP-internal extraposition. This is not an unreasonable solution: Matushansky and Zwarts (2016) observe that DP-internal extraposition is in fact possible in pseudo-partitives in some languages like Basque and, similarly, Norris (2011) reports that DP-internal extraposition is obligatory independently in Icelandic. In short, the fact that there is growing compelling evidence for a uniform syntax calls for a re-examination of the data to assess whether the ambiguity hypothesis is supported, and for a careful consideration of the syntactic diagnostics used to motivate the structure.
In addition, the syntactic analysis proposed here based on interpretable features also opens up the possibility of developing a compositional semantic analysis that does not rely on multiple ambiguities in the meanings of numerals and quantizing nouns (Rothstein 2009, 2017).Footnote 28 Instead, the syntax advocated for here presupposes that any differences in compositional semantics should stem from the denotations of the different values of interpretable features borne by the syntactic elements: the container feature. We can speculate that the output of these values can then interact with the measure morphemes introducing the measure functions that will map an element (container or its content) to a degree on a scale (Schwarzschild 2006; Rett 2014; Pancheva 2015; Wellwood 2015, 2019). The compositional semantics for pseudo-partitives is not trivial, though, and thus I must leave this as a potentially promising avenue to pursue in the future.
In addition to these issues, the paper provides novel data from a head-final language where the head of the construction is the substance noun. This is of special importance since this type of head-finality has been argued to be involved in bleeding individuating interpretations in head-final languages (Sağ 2020). Sağ (2020) reports that pseudo-partitives in Turkish are unambiguous: they only allow the measuring interpretation. A sentence like (81) from Sağ (2020), ex.23 can only refer to the volume of water contained in two glasses or two liters.

Sağ (2020) notes that Turkish differs from English (and other languages) with respect to head-directionality and the absence of a connecting preposition like of. Thus, she proposes that the lack of the individuating interpretation is due precisely to these two facts, and in particular to headedness. The rationale is as follows: (i) of is responsible for mapping substances to their measure-units, but if it is absent, that task is passed onto the semantics of the quantizing noun; (ii) if the head is always the substance noun, as in Turkish, it will determine the referent of the pseudo-partitive in the measure reading; but if the head is the quantizing noun, it will be the referent of the pseudo-partitive in the individuating reading. Sağ assumes that English allows both structures and thus the ambiguity is accounted for.
However, the data from Alasha Mongolian discussed here shows that Sağ’s (2020) observation is not accurate. Both Turkish and Alasha Mongolian instantiate the same value of the head-directionality parameter, and yet the former lacks the individuating interpretation while the latter does not. The observations are summarized in Table 4.
The analysis I propose here leaves room for an alternative account of the cross-linguistic difference between Turkish and Alasha Mongolian. We must note that a crucial ingredient in the syntactic derivation driving the individuating-measuring distinction was the value of [±Container] on the layered n. Alasha Mongolian has both positive and negative settings of the container value. The lack of individuating interpretations in Turkish can be due to the absence of the positive value of the container feature on the quantizing layered n. This entails that the only value that is available on the quantizing n is [-Container], bleeding the individuating interpretation in pseudo-partitive structures. If this account of the variation is on the right track, we predict the existence of the typology of languages in Table 5 regarding the availability or lack thereof of individuating/measuring pseudo-partitives.
Container-Contents languages are those in which both feature values are available and comprise the most well-studied group. Contents-only languages are those which lack a [+Container] value. The only language reported of this type so far is Turkish (Sağ 2020). The analysis of the variation predicts that there might also be Container-only languages, which would be the mirror image of Turkish, but also languages that may lack both feature values and disallow either interpretation. As far as I am aware, there is no reference in the literature (yet) to languages that only allow the individuating interpretation and languages that allow neither, thus leaving both Container-only and languages allowing neither unattested. We should not take this to mean that these language types are unattested because they are impossible. A note is in order, however. It has been observed in typological work that languages do generally have morpho-syntactic means of expressing pseudo-partitive constructions (Koptjevskaja-Tamm 2001, 2009; Seržant 2021). While these works do not focus on the semantic ambiguity of the pseudo-partitive, we can conclude from the simple fact that the construction is typologically widespread that most, if not all, languages have one way to form a pseudo-partitive. Thus, it would be surprising to find a language that lacks the construction altogether (in fact, no language referenced in these works is said to lack it). This would mean that the container feature must be part of the feature inventory of natural languages, either privatively as in Turkish or bivalently as in Alasha Mongolian, English and other languages. This, nevertheless, is an educated speculation and more research should be done to probe the distribution and interpretation of pseudo-partitives.
6 Conclusion
In this paper, I have focused on individuating and measuring pseudo-partitives. There is a open question in the literature as to whether the two types of pseudo-partitives are structurally ambiguous (Landman 2004; Rothstein 2009, 2017; Wilson 2018) or whether they have a single underlying syntax regardless of their semantic interpretation (Lehrer 1986; Matushansky and Zwarts 2016; Ruys 2017; Matushansky et al. 2017). The goal has been to shed light on this debate by describing and analyzing individuating and measuring pseudo-partitives in Alasha Mongolian. Alasha Mongolian is of special relevance because it marks the distinction morpho-syntactically via case on the quantizing noun: comitatitve corresponds to an individuating interpretation and genititve maps to a measuring one. In spite of this difference, the constituency and word order facts do not support two distinct syntactic structures and they are best explained by a uniform syntax. Although the overall syntactic geometry is the same for both, there are some nuanced differences between the two types of pseudo-partitives that eventually feed the relevant semantic interpretation and case marking: the feature content of the quantizing noun and the probe features on the Agr heads. Although many questions remain unanswered, the paper illuminates our understanding of form-meaning mappings in general and pseudo-partitive constructions in particular. It keeps the syntax largely uniform while leaving room for variation in the feature composition and properties of functional elements.
Notes
For some like Rothstein (2009, 2017) the numeral is the head of Num and of is inserted as a last resort at PF, so the substance noun projects an NP rather than a PP, making it the head of the whole nominal. We must bear in mind that the fact that P-stranding is possible in languages like English casts doubt on the hypotheses that (i) of is a case marker (Scontras 2014) or (ii) is introduced as a last resort and does not project a P (Rothstein 2009). For others like Wilson (2018) Num is vacuous and number information enters the derivation higher than the DP in the spirit of Sauerland (2003). I remain neutral as to the specifics of these proposals.
I will be using the label MP purely descriptively, to refer to the constituent that contains a numeral and the quantizing noun. Later on in the paper, I show that the appropriate syntactic label is in fact a KP (Bittner and Hale 1996) or a DP.
Throughout the paper I ignore IPA and phonetic transcription. I use the following orthographic conventions that map onto the corresponding IPA symbols. The conventions for vowels are the following: a = [
 ]; ö = [ø]; ü = [y]; u = [o/u]; o = [
]; ö = [ø]; ü = [y]; u = [o/u]; o = [ ]; V = [
]; V = [ ] or highly reduced unstressed vowels; small caps \({\textsc {v}}\) is a placeholder for any vowel. Long vowels are represented with [ : ] after the vowel. The conventions for consonants are as follows: ch = [t
] or highly reduced unstressed vowels; small caps \({\textsc {v}}\) is a placeholder for any vowel. Long vowels are represented with [ : ] after the vowel. The conventions for consonants are as follows: ch = [t ]; j = [d
]; j = [d ]; gh = [g]; sh = [
]; gh = [g]; sh = [ ]; v = [
]; v = [ ]; x = [x/
]; x = [x/ /h]; ng = [
/h]; ng = [ ]; w = [w].
]; w = [w].The data collection took place during the spring of 2022 as part of a field methods class in Los Angeles, California. In addition to the general class (20 1.5h sessions), there were a total of 8 1h individual sessions. The data come from one speaker.
If the modifier does not end in a vowel, the attributive morpheme is covert. For example, this is shown in (11c) for the adjective tam: ‘big’.
The aspect and tense system of Mongolian is complex and in some cases subject to syncretism (Binnick 2011; Janhunen 2012; Gong 2022). The suffix -sVn, in particular, can be used as a perfective aspectual marker, but also as a finite past tense ending. In non-finite contexts, it acts as a perfect participle marker. From now on, I will be indicating in the glosses the relevant meaning: pst.perf for finite contexts and perf.part for the non-finite ones.
For a similar observation in Turkish see Sağ (2022).
One might coerce the interpretation to a mass one in case the substance noun is unmarked, just like in English. If so, the interpretation that arises is a gory one: “two boxes of cat-stuff”.
By applied object, I am not solely referring here to indirect objects, but to any argument which is not the complement of a purely transitive verb.
The unmarkedness of number in Nsubs depends on two factors: [± animacy], as shown in (26), and the count/mass distinction labeled here as [±count]. That is why Nsubs in Table 1 is broken down into 3 different categories. In the case of mass nouns, we should note that ‘pure’ or ‘canonical’ mass nouns like tsaV ‘tea’ or us ‘water’ cannot be pluralized (even in packaging or sorting contexts, i.e. Bunt (1985), Bach (1986)): *tsaVg-o:d ‘tea-pl’, *us-u:d ‘water-pl’. What is crucial, though, is the fact that plural marking is possible with substance nouns that are countable but impossible with quantizing nouns when there is a numeral.
In Sect. 4 , I show that genitive is the case generally assigned to complements of nouns (with the exception of deverbal nouns), in addition to it surfacing in NPs that are complements of most adpositions and subjects of certain non-tensed embedded clauses. There I also show that comitative is more restricted to possessive-have constructions and NP complements of adposition xampt ‘with’.
The same observation occurs with higher cardinals like 1,000: a 1,000 boys and girls. In the case of the third interpretation, it need not be the case that the number of boys is 500 and the number of girls is also 500; any combination will do, as long as there is a total of 1,000. The same applies to (29c).
I am omitting the meas-interpretation where the quantizing noun is unmarked for case for reasons of space. I have found no context in which overt genitive is allowed but ‘Ø’ is not, and viceversa. Their distribution is the same.
A pause is generally needed after the numeral in (34c) and (35c) to disambiguate that the numeral is not part of the coordinated constituent. If there is no pause, the numeral is taken to be directly modifying the adjacent noun in which case the sentences are acceptable but only under the ‘numeral + indefinite plural reading’:
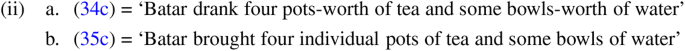
This observation does not undermine the hypothesis that numerals form a constituent with the quantizing noun or supports the hypothesis that the two nouns form a constituent to the exclusion of the numeral. That is because what is being coordinated to obtain this reading, as illustrated with the baseline cases in (31b) and (32b), is two full DPs; only the DP in the first conjunct has a numeral while the DP in the second one is bare.
I would like to thank an anonymous reviewer for this observation.
When the noun ends in a consonant, an unstressed vowel surfaces between the final consonant and the -l suffix.
It is orthogonal to the goal of the paper whether this movement is A or Ā. If we reverse the positions of reciprocal and R-expression in (51), ungrammaticality still obtains after the movement as in (iii). This shows that the movement must obligatorily reconstruct.

A possible explanation is weak cross-over (Chomsky 1977; May 1977; Barss 1986, a.o.). However, as Daiko Takahashi points out, we cannot rule out the possibility that the ungrammaticality of (iii) and (51b) is due to A-movement feeding a Condition A violation (Chomsky 1981). I leave this question open.
Batar in (55c) is the possessor and not the noun’s complement. This is evidenced by examples like (iv) where food occupies the complement position of the noun:
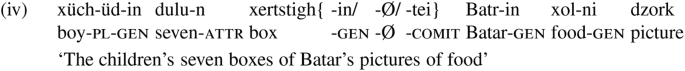
Gong (2022) proposes that the possessor is generated in the specifier of a PossP below KP and DP. In terms of the proposal here, nothing crucial hinges on assuming that the possessor is on Spec,DP instead.
If NumP is projected, there are two options: either unitP is externally merged immediately above NumP or it is always externally merged immediately above nP but the quantizing KP moves to Spec,AgrP after Agree has occurred. This is because the quantizing KP must be higher than non-classificatory gradable APs which are assumed to adjoin as specifiers of NumP.
The two values of the interpretable feature roughly correspond to Matushansky and Zwarts’ (2016) semantic functions CONT and CONT\(^{\text {--}}\), modified below in (v) to be faithful to the proposed syntactic structure and the meanings they introduce:
We should note that being the “unmarked” case does not necessarily correlate with a null case morpheme (Levin and Preminger 2015, fn.2, 233). Alasha Mongolian supports this observation given that genitive can be phonologically overt in some contexts. In the case of comitative, it must be assigned by the head that has the relevant inherently valued case feature.
An issue that could be of concern is the possibility that a KP bearing [-Container] could in principle be merged with Agr\(_1\) and be assigned comitative case. Conversely, the opposite could also be true: a KP bearing [+Container] could be merged with Agr\(_2\) and receive genitive after transfer. This would result in measuring pseudo-partitive with comitative case and individuating ones with genitive case. To rule these out, we can speculate that these options are ruled out directly in the numeration: there is no possible numeration in which Agr\(_1\) coexists with [-Container]; and likewise, Agr\(_2\) could not co-occur with [+Container]. Thus, the presence of [±Container] is contingent on the presence of Agr\(_{1/2}\). This is, however, a stipulation, and a more principled explanation is in order.
For Rothstein (2009, 2017), on the one hand, in the individuating interpretation, the numeral is a modifier of type \(\langle e,t\rangle \) that introduces a cardinality measure function and the noun is an entity, also of type \(\langle e,t\rangle \), and has a container function as part of its meaning. For measuring pseudo-partitives, on the other hand, the numeral is a degree, i.e. d, and the quantizing noun denotes a function from properties to a function of degrees to properties, i.e. \(\langle et,\langle d, et\rangle \rangle \), that introduces a measure function restricted to the quantizing unit: \(\mu _{glasses}(x) = d\) where x is bound by the substance.

 ]; ö = [ø]; ü = [
]; ö = [ø]; ü = [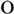 ]; V = [
]; V = [ ] or highly reduced unstressed vowels; small caps
] or highly reduced unstressed vowels; small caps  ]; j = [d
]; j = [d ]; gh = [
]; gh = [ ]; v = [
]; v = [ ]; x = [x/
]; x = [x/ /h]; ng = [
/h]; ng = [ ]; w = [w].
]; w = [w].

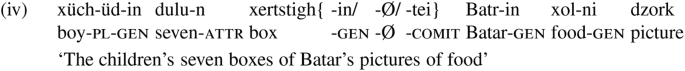
References
Abney, S. 1987. The English Noun Phrase in its Sentential Aspect . Ph. D. thesis. Cambridge: MIT.
Adger, D. 2003. Core Syntax. Oxford: Oxford University Press.
Allan, K. 1980. Nouns and countability. Language 56: 541–567.
Anderson, S. 1992. A-Morphous Morphology. Cambridge: Cambridge University Press.
Arregi, K., and A. Nevins. 2012. Morphotactics: Basque Auxiliaries and the Structure of Spellout. Dordrecht: Springer.
Bach, E. 1986. Natural language metaphysics. In R. Barcan Marcus, G. J. Dorn, and P. Weingartner (Eds.), Logic, Methodology and Philosophy of Science VII, pp. 573–595. Amsterdam: Elsevier Science.
Bale, A., M. Gagnon, and H. Khanjian. 2011. Cross-linguistic representations of numerals and number marking. In N. Li and D. Lutz (Eds.), Proceedings of Semantics and Linguistic Theory (SALT) 20, Cornell University, pp. 582–598. CLC Publications.
Barss, A. 1986. Chains and Anaphoric Dependence: On Reconstruction and its Implications. Ph.D. thesis, MIT.
Benmamoun, E., A. Bhatia, and M. Polinsky. 2009. Closest conjunct agreement in head final languages. Linguistic Variation Yearbook 9: 67–88.
Bhatt, R., and M. Walkow. 2013. Locating agreement in grammar: An argument from conjunctions. Natural Language and Linguistic Theory 31: 951–1013.
Binnick, R. 2011. The Past Tenses of the Mongolian Verb: Meaning and Use. Leiden: Brill.
Bittner, M., and K. Hale. 1996. The structural determination of case and agreement. Linguistic Inquiry 27: 1–68.
Borer, H. 2005. In Name Only, Structuring Sense, vol. 1. Oxford: Oxford University Press.
Brasoveanu, A. 2009. Measure noun polysemy and monotonicity: Evidence from Romanian pseudopartitives. In North East Linguistic Society (NELS) 38, ed. M. Walkow, A. Schardl, and M. Abdurrahman, 139–150. GSLA.
Bunt, H. 1985. Mass Terms and Model-Theoretic Semantics. New York: Cambridge University Press.
Carnie, A. 2012. Syntax: A Generative Introduction, 3rd ed. Oxford: Wiley-Blackwell.
Cheng, L.-L., and R. Sybesma. 1999. Bare and not-so-bare nouns and the structure of NP. Linguistic Inquiry 30: 509–542.
Chierchia, G. 1998. Reference to kinds across languages. Natural Language Semantics 6 (4): 339–405. https://doi.org/10.1023/A:1008324218506.
Chomsky, N. 1965. Aspects of the Theory of Syntax. Cambridge, MA: MIT Press.
Chomsky, N. 1973. Conditions on transformations. In A Festschrift for Morris Halle, ed. S. Anderson and P. Kiparsky, 232–286. New York: Holt Rinehart and Winston.
Chomsky, N. 1977. Conditions on transformations. In Essays on Form and Interpretation, pp. 81–162. New York: Elsevier North-Holland, Inc.
Chomsky, N. 1981. Lectures on Government and Binding. Dordrecht: Foris Publications.
Chomsky, N. 1986. Barriers. Cambridge, MA: MIT Press.
Chomsky, N. 1995. The Minimalist Program. Cambridge, MA: MIT Press.
Chomsky, N. 2000. Minimalist inquiries: the framework. In Step by Step: Essays on Minimalist Syntax in Honor of Howard Lasnik, ed. R. Martin, D. Michaels, and J. Uriagereka, 89–156. Cambridge, MA: MIT Press.
Cinque, G. 2010. The Syntax of Adjectives. Cambridge, MA: MIT Press.
Cinque, G. 2023. On Linearization. Cambridge, MA: MIT Press.
Corver, N. 1990. The Syntax of Left Branch Extractions. Ph.D. thesis, Katholieke Universiteit Brabant.
Cowper, E. 1992. A Concise Introduction to Syntactic Theory. Chicago, Illinois: University of Chicago Press.
Cowper, E. 2005. A note on Number. Linguistic Inquiry 36: 441–455.
Doetjes, J. 1997. Quantifiers and Selection: On the Distribution of Quantifying Expressions in French, Dutch and English. The Hague: Holland Academic Graphics.
Duek, K., and A. Brasoveanu. 2015. The polysemy of container pseudo-partitives. In E. Csipak and H. Zeijlstra (Eds.), Sinn und Bedeutung 19, pp. 214–231.
Embick, D., and R. Noyer. 2001. Movement operations after syntax. Linguistic Inquiry 32: 555–595. https://doi.org/10.1162/002438901753373005.
Gong, M. 2022. Issues in the Syntax of Movement: Cross-Clausal Dependencies, Reconstruction, and Movement Typology. Ph.D. thesis, Cornell University.
Grabovac, A. 2022. Maximizing the Concord Domain: Concord as Spell-Out in Slavic. Ph.D. thesis, University College London.
Grestenberger, L. 2015. Number marking in German measure phrases and the syntax of pseudo-partitives. Journal of Comparative Germanic Linguistics 18: 93–138.
Grimshaw, J. 1979. Complement selection and the lexicon. Linguistic Inquiry 10: 279–326.
Grimshaw, J. 2000. Locality and extended projection. In Lexical Specification and Insertion, ed. P. Coopmans, J. Grimshaw, and M. Everaert, 115–134. Amsterdam: John Benjamins Publishing Company.
Halle, M., and A. Marantz. 1993. Distributed Morphology and the pieces of inflection. In The View from Building 20, ed. K. Hale and S.J. Keyser, 111–176. Cambridge, MA: MIT Press.
Hankamer, J., and L. Mikkelsen. 2008. Definiteness marking and the structure of Danish pseudopartitives. Journal of Linguistics 49: 61–84.
Hankamer, J., and L. Mikkelsen. 2018. Definiteness marking and the structure of Danish pseudopartitives. Linguistic Inquiry 44: 317–346.
Harbour, D. 2007. Morphosemantic Number: From Kiowa Noun Classes to UG Number Features. Studies in Natural Language and Linguistic Theory. Berlin: Springer.
Harbour, D. 2011. Valence and atomic number. Linguistic Inquiry 42: 561–594. https://doi.org/10.1162/LING_a_00061.
Harbour, D. 2014. Paucity, abundance and the theory of number. Language 90: 185–229. https://doi.org/10.1353/lan.2014.0003.
Harley, H., and E. Ritter. 2002. Person and number in pronouns: A feature geometric analysis. Language 78: 482–526.
Heck, F., and G. Müller. 2007. Extremely local optimization. In West Coast Conference in Formal Linguistics (WCCFL) 34, ed. E. Brainbridge and B. Agbayani, 170–182. Cascadilla Proceedings Project.
Ionin, T., and O. Matushansky. 2006. The composition of complex cardinals. Journal of Semantics 23: 315–360. https://doi.org/10.1093/jos/ffl006.
Ionin, T., and O. Matushansky. 2018. Cardinals: The Syntax and Semantics of Cardinal-containing Expressions. Cambridge, MA: MIT Press.
Jackendoff, R. 1977. X’ Syntax. Cambridge, MA: MIT Press.
Janhunen, J. 2012. Mongolian. Amsterdam: John Benjamins.
Kayne, R. 2005. Movement and Silence. Oxford: Oxford University Press.
Kiss, T., J. Pelletier, and H. Husić. 2021. Polysemy and the count-mass distinction: What can we derive from a lexicon of count and mass senses? In Things and Stuff: The Semantics of the Mass-Count Distinction, ed. T. Kiss, J. Pelletier, and H. Husić, 377–397. Cambridge: Cambridge University Press.
Koptjevskaja-Tamm, M. 2001. A piece of the cake and a cup of tea: Partitive and pseudopartitive nominal constructions in the Circum-Baltic languages. In Ö. Dahl and M. Koptjevskaja-Tamm (Eds.), The Circum-Baltic languages. Typology and Contact, Volume 2, pp. 523–568. John Benjamins.
Koptjevskaja-Tamm, M. 2009. A lot of grammar with a good portion of lexicon: Towards a typology of partitive and pseudopartitive nominal constructions. In Form and Function in Language Research: Papers in Honour of Christian Lehmann, ed. J. Helmbrecht, Y. Nishina, Y.-M. Shin, S. Skopeteas, and E. Verhoeven, 329–346. Mouton de Gruyter.
Kornflit, J., and O. Preminger 2015. Nominative as no case at all: An argument from raising-to-acc in sakha. In A. Joseph and E. Predolac (Eds.), 9th Workshop on Altaic Formal Linguistics (WAFL 9), Volume 76, pp. 109–120. MIT Working Papers in Linguistics.
Kramer, R. 2015. The Morphosyntax of Gender. Oxford: Oxford University Press.
Kramer, R. 2016. A split analysis of plurality: Number in Amharic. Linguistic Inquiry 47: 527–599. https://doi.org/10.1162/LING_a_00220.
Kramer, R. 2017. General number nouns in Amharic lack NumP. In Asking the Right Questions: Essays in Honor of Sandra Chung, ed. J. Ostrove, R. Kramer, and J. Sabbagh, 39–54. UC Santa Cruz: Linguistics Research Center.
Krifka, M. 1990. Boolean and non-boolean ‘and’. In Papers from the Second Symposium on Logic and Language, Budapest, ed. L. Kálmán and L. Pólos, 161–187. Akadémiai Kiadó.
Krifka, M. 1995. Common nouns: A contrastive analysis of English and Chinese. In The Generic Book, ed. G. Carlson and J. Pelletier, 398–411. Chicago: University of Chicago Press.
Landman, F. 2004. Indefinites and the Types of Sets. Oxford: Oxford University Press.
Lechner, W. 2004. Ellipsis in Comparatives. Berlin/New York: Mouton de Gruyter.
Lee, T.T.-M. 2023. Last but not least: a comparative perspective on right dislocation in Alasha Mongolian. (accepted Journal of East Asian Linguistics) lingbuzz/006889.
Lehrer, A. 1986. English classifier constructions. Lingua 68: 109–148.
Levin, T., and O. Preminger. 2015. Case in Sakha: Are two modalities really necessary? Natural Language and Linguistic Theory 33: 231–250.
Levinson, L. 2007. The Roots of Verbs. Ph.D. dissertation, New York University.
Lieber, R. 1989. On percolation. Yearbook of. Morphology 2: 95–138.
Link, G. 1983. The logical analysis of plurals and mass terms: A lattice-theoretical approach. In Meaning, Use and Interpretation of Language, ed. R. Bäuerle, C. Schwarze, and A. von Stechow, 302–323. Berlin: De Gruyter.
Lønning, J.T. 1987. Mass terms and quanitification. Linguistics and Philosophy 10: 1–52.
Martí, L. 2020. Inclusive plurals and the theory of number. Linguistic Inquiry 51: 37–74. https://doi.org/10.1162/ling_a_00330.
Matushansky, O., E. Ruys, and J. Zwarts 2017. On the structure and composition of pseudo-partitives. Handout from Séminaire LaGraM, UMR 7023 Paris, January 16.
Matushansky, O., and J. Zwarts. 2016. Making space for measures. In North East Linguistic Society (NELS) 47, vol. 2, ed. A. Lamont and K. Tetzloff, 261–274. GLSA Amherst.
May, R. 1977. The Grammar of Quantification. Ph.D. thesis, MIT.
Merchant, J. 2019. Roots don’t select, categorial heads do: Lexical-selection of PPs may vary by category. The Linguistic Review 36: 325–341.
Müller, G. 2010. On Deriving CED Effects from the PIC. Linguistic Inquiry 41 (1): 35–82. https://doi.org/10.1162/ling.2010.41.1.35.
Norris, M. 2011. Extraposition and definiteness effects in Icelandic dps. In UC Santa Cruz: Festschrifts. Morphology at Santa Cruz: Papers in Honor of Jorge Hankamer, pp. 1–26. Linguistics Research Center, UC Santa Cruz.
Norris, M. 2014. A Theory of Nominal Concord. Ph.D. thesis, UC Santa Cruz.
O’Connor, E., and P. Biswas. 2015. Dual Modes of Masurement in Language. University of Southern California: Unpublsihed Ms.
Ott, D. 2011. Diminutive-formation in German: Spelling out the classifier analysis. Journal of Comparative Germanic Linguistics 14: 1–46. https://doi.org/10.1007/s10828-010-9040-x.
Pancheva, R. 2015. Quantity superlatives: The view from Slavic and its cross-linguistic implications. In Chicago Linguistic Society (CLS) 49, ed. H. Aparicio, G. Flinn, K. Franich, J. Pietraszko, and T. Vardomskaya. CLS Publications.
Pancheva, R. 2021. Morphosyntactic variation in numerically-quantified noun phrases in Bulgarian. University of Southern California: Unpublished Ms.
Partee, B., and V. Borschev. 2012. Sortal, relational, and functional interpretations of nouns and Russian container constructions. Journal of Semantics 29: 445–486.
Pelletier, J. 1975. Non-singular reference: Some preliminaries. Philosophia 5: 451–465.
Pesetsky, D. 1995. Zero Syntax. Cambridge, MA: MIT Press.
Pesetsky, D., and E. Torrego 2006. Probes, goals and syntactic categories. In Y. Otsu (Ed.), 7th Annual Tokyo Conference on Psycholinguistics, lingbuzz/000321.
Pesetsky, D., and E. Torrego. 2007. The syntax of valuation and the interpretation of features. In Phrasal and Clausal Architecture, ed. S. Karimi, V. Samllam, and W. Wilkins, 262–294. John Benjamins.
Phillips, C. 2003. Linear order and constituency. Linguistic Inquiry 34: 37–90.
Preminger, O. 2014. Agreement and its failures. Cambridge, MA: MIT Press.
Rett, J. 2014. The polysemy of measurement. Lingua 143: 242–266. https://doi.org/10.1016/j.lingua.2014.02.001.
Ritter, E. 1991. Two functional categories in noun phrases: Evidence from Modern Hebrew. In Syntax and Semantics 25: Perspectives on Phrase Structure: Heads and Licensing, ed. S. Rothstein. New York: Academic Press.
Rothstein, S. 2009. Individuating and measure readings of classifier constructions: Evidence from Modern Hebrew. Brill’s Journal of Afroasiatic Languages and Linguistics 1: 106–145. https://doi.org/10.1163/187666309X12491131130783.
Rothstein, S. 2017. Semantics for Counting and Measuring. Cambridge: Cambridge University Press.
Ruys, E. G. 2017. Two Dutch many’s and the structure of pseudo-partitives. Glossa: A Journal of General Linguistics 2, 1–33.
Sauerland, U. 2003. A new semantics for number. In R. Young and Y. Zhou (Eds.), Proceedings of Semantics and Linguistic Theory (SALT) 13, pp. 258–275. CSLI Publications.
Sauerland, U., J. Anderssen, and K. Yatsuhiro. 2005. The plural is semantically unmarked. In Linguistic Evidence: Empirical, Theoretical and Computational perspectives, Studies in Generative Grammar, ed. S. Kepser and M. Reis, 413–434. Berlin: De Gruyter.
Sağ, Y. 2020. The curious case of measure semantics. In Ö. Eren, A. Giannoula, S. Gray, C.-D. Lam, and A. Martinez Del Rio (Eds.), Proceedings of Chicago Linguistic Society 55, University of Chicago, pp. 351–364. CLS Publications.
Sağ, Y. 2022. Bare singulars and singularity in Turkish. Linguistics and Philosophy 45: 741–793.
Schwarzschild, R. 2006. The role of dimensions in the syntax of noun phrases. Syntax 9 (1): 67–110. https://doi.org/10.1111/j.1467-9612.2006.00083.x.
Scontras, G. 2013. Accounting for counting: A unified semantics for measure terms and classifiers. In T. Snider (Ed.), Semantics and Linguistic Theory (SALT) 23, pp. 549–569. CLC Publications. https://doi.org/10.3765/salt.v23i0.2656.
Scontras, G. 2014. The Semantics of Measurement. Ph.D. thesis, Harvard University.
Selkirk, E. 1977. Some remarks on noun phrase structure. In Formal Syntax, ed. P. Culicover, T. Wasow, and A. Akmajian, 285–386. New York: Academic Press.
Seržant, I. 2021. Typology of partitives. Linguistics 59: 881–947. https://doi.org/10.1515/ling-2020-0251.
Smith, P. 2021. Morphology–Semantics Mismatches and the Nature of Grammatical Features. John Benjamins.
Sutton, P., and H. FIlip. 2021. Container, portion, and measure interpretations of pseudo-partitive constructions. In Things and Stuff: The Semantics of the Mass-Count Distinction, ed. T. Kiss, J. Pelletier, and H. Husić, 279–304. Cambridge: Cambridge University Press.
Svenonius, P. 1994. Dependent Nexus: Subordinate Predication Structures in English and the Scandinavian Languages. Ph. D. thesis, University of California, Santa Cruz.
Svenonius, P. 2008. The position of adjectives and other phrasal modifiers in the decomposition of dp. In Adjectives and Adverbs: Syntax, Semantics and Discourse, Oxford Studies in Theoretical Linguistics, ed. L. McNally and C. Kennedy, 16–42. Oxford: Oxford University Press.
Toquero-Pérez, L.M. 2022. Superlatives, partitives and apparent \(\varphi \)-feature mismatch in Spanish. University of Southern California: Unpublished Ms.
Toquero-Pérez, L.M. 2022. There is no meas, only much: the case of 3 kgs of cashews. Handout of talk given at California Annual Meeting in Semantics and Pragmatics (CUSP) 13. University of California Los Angeles, May 06, 2022.
Toquero-Pérez, L.M. 2023. Number neutrality is syntactically encoded: the case of Alasha Mongolian. University of Southern California: Unpublished Ms.
von Heusinger, K., and J. Kornflit. 2017. Partitivity and case marking in Turkish and related languages. Glossa: A Journal of General Linguistics 2: 1–40.
Wellwood, A. 2015. On the semantics of comparison across categories. Linguistics and Philosophy 38: 67–101. https://doi.org/10.1007/s10988-015-9165-0.
Wellwood, A. 2019. The Meaning of More. Oxford: Oxford University Press.
Wilson, C. 2018. Amount Superlatives and Measure Phrases. Ph.D. thesis, City University of New York.
Zabbal, Y. 2005. The syntax of numeral expressions. Upublished Ms., University of Massachusetts, Amherst. https://ling.auf.net/lingbuzz/005104.
Zeijlstra, H. 2012. There is only one way to agree. The Linguistic Review 29: 491–539. https://doi.org/10.1515/tlr-2012-0017.
Zweig, E. 2009. Number-neutral bare plurals and the multiplicity implicature. Linguistics and Philosophy 32: 353–407.
Acknowledgements
I am incredibly grateful to Brian Tsagaadai for sharing his language and culture with me. Without his generosity and time, none of this would have been possible. I would also like to thank the attendees of the USC Spring 2022 field methods class, UCLA’s Syn/Sem seminar, and the Universidad Autónoma de Buenos Aires’ Ling-Phil reading group, as well as the audience of CUSP13 at UCLA. I am also indebted to Roumi Pancheva for our extended and numerous discussions of pseudo-partitives where we raised some of the observations described here. In addition, I would like to thank Antonio Cleani, Elango Kumaran, Carol-Rose Little, Travis Major, Ora Matushansky, Tommy Tsz-Ming Lee, Alexis Wellwood and Sam Zukoff for comments and feedback. Last but not least, I thank an anonymous reviewer and the editors of the Journal of East Asian Linguistics; in particular, Andrew Simpson, who encouraged me to submit this project as part of the special issue on Mongolain, and Daiko Takahashi for style and formatting suggestions. Any errors are my own.
Funding
Open access funding provided by SCELC, Statewide California Electronic Library Consortium
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Toquero-Pérez, L.M. The syntax of individuating and measuring pseudo-partitives in Alasha Mongolian. J East Asian Linguist 32, 551–593 (2023). https://doi.org/10.1007/s10831-023-09267-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10831-023-09267-5