
Abstract
Science as a whole is organized into broad fields, and as a consequence, research, resources, students, etc., are also classified, assigned, or invited following a similar structure. Some fields have been established for centuries, and some others are just flourishing. Funding, staff, etc., to support fields are offered if there is some activity on it, commonly measured in terms of the number of published scientific papers. How to find them? There exist well-respected listings where scientific journals are ascribed to one or more knowledge fields. Such lists are human-made, but the complexity begins when a field covers more than one area of knowledge. How to discern if a particular paper is devoted to a field not considered in such lists? In this work, we propose a methodology able to classify the universe of papers into two classes; those belonging to the field of interest, and those that do not. This proposed procedure learns from the title and abstract of papers published in monothematic or “pure” journals. Provided that such journals exist, the procedure could be applied to any field of knowledge. We tested the process with Geographic Information Science. The field has contacts with Computer Science, Mathematics, Cartography, and others, a fact which makes the task very difficult. We also tested our procedure and analyzed its results with three different criteria, illustrating its power and capabilities. Interesting findings were found, where our proposed solution reached similar results as human taggers also similar results compared with state-of-the-art related work.




Similar content being viewed by others
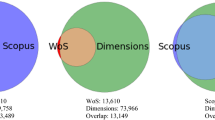

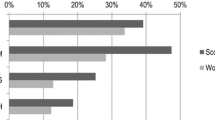
Notes
References
Shu F, Julien C-A, Zhang L, Qiu J, Zhang J, Larivière V (2019) Comparing journal and paper level classifications of science. J Inform 13(1):202–225
Waltman L, van Eck NJ (2012) A new methodology for constructing a publication-level classification system of science. J Am Soc Inf Sci Technol 63(12):2378–2392
Le Q, Mikolov T (2014) Distributed representations of sentences and documents. In: International conference on machine learning. PMLR, pp. 1188–1196
Devlin J, Chang M-W, Lee K, Toutanova K (2018) BERT: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805
Chen G, Chen J, Shao Y, Xiao L (2022) Automatic noise reduction of domain-specific bibliographic datasets using positive-unlabeled learning. Scientometrics 128:1–18
Kreutz CK, Sahitaj P, Schenkel R (2020) Evaluating semantometrics from computer science publications. Scientometrics 125(3):2915–2954
Kozlowski D, Dusdal J, Pang J, Zilian A (2021) Semantic and relational spaces in science of science: deep learning models for article vectorisation. Scientometrics 126(7):5881–5910
Roudsari AH, Afshar J, Lee W, Lee S (2022) PatentNet: multi-label classification of patent documents using deep learning based language understanding. Scientometrics 127:1–25
Chen H, Nguyen H, Alghamdi A (2022) Constructing a high-quality dataset for automated creation of summaries of fundamental contributions of research articles. Scientometrics 127:1–15
Wang Q, Waltman L (2016) Large-scale analysis of the accuracy of the journal classification systems of web of science and Scopus. J Informet 10(2):347–364
Lv Y, Xie Z, Zuo X, Song Y (2022) A multi-view method of scientific paper classification via heterogeneous graph embeddings. Scientometrics 127(8):4847–4872
Shen S, Liu J, Lin L, Huang Y, Zhang L, Liu C, Feng Y, Wang D (2022) SsciBERT: a pre-trained language model for social science texts. Scientometrics 128:1–23
Raan AV (2003) The use of bibliometric analysis in research performance assessment and monitoring of interdisciplinary scientific developments. TATuP-Z Technikfolgenabschätzung Theorie Praxis 12(1):20–29
de Solla Price DJ (1965) Networks of scientific papers. Science 149:510–515
Small H (1973) Co-citation in the scientific literature: a new measure of the relationship between two documents. J Am Soc Inf Sci 24(3):265–269
Klavans R, Boyack K (2017) Which type of citation analysis generates the most accurate taxonomy of scientific and technical knowledge? J Am Soc Inf Sci 68:984–998
Pech G, Delgado C, Sorella SP (2022) Classifying papers into subfields using abstracts, titles, keywords and keywords plus through pattern detection and optimization procedures: an application in physics. J Assoc Inf Sci Technol 73:1–16
Leydesdorff L, Bornmann L (2016) The operationalization of “fields’’ as WoS subject categories (WC s) in evaluative bibliometrics: the cases of “library and information science’’ and “science & technology studies’’. J Am Soc Inf Sci 67(3):707–714
Boyack KW, Newman D, Duhon RJ, Klavans R, Patek M, Biberstine JR, Schijvenaars B, Skupin A, Ma N, Börner K (2011) Clustering more than two million biomedical publications: comparing the accuracies of nine text-based similarity approaches. PLoS ONE 6(3):18029
Wang S, Mao J, Cao Y, Li G (2022) Integrated knowledge content in an interdisciplinary field: identification, classification, and application. Scientometrics 127(11):6581–6614
Liu B, Lee WS, Yu PS, Li X (2002) Partially supervised classification of text documents. In: International conference on machine learning, ICML. Sydney, NSW, vol 2, pp 387–394
Priem J, Piwowar H, Orr R (2022) Openalex: A fully-open index of scholarly works, authors, venues, institutions, and concepts. arXiv preprint arXiv:2205.01833
Selivanova IV, Kosyakov DV, Dubovitskii DA, Guskov AE (2021) Expert, journal, and automatic classification of full texts and annotations of scientific articles. Autom Doc Math Linguist 55:178–189
Muller M, Wolf C, Andres J, Desmond M, Joshi NN, Ashktorab Z, Sharma A, Brimijoin K, Pan Q, Duesterwald E (2021) Designing ground truth and the social life of labels. In: Proceedings of ACM human factors in computing systems (CHI’21), Article No 94, pp 1–16
Huang W (2022) What were GIScience scholars interested in during the past decades? J Geovis Spat Anal 6(1):1–21
López-Vázquez C, Gonzalez-Campos ME, Bernabé-Poveda MA, Moctezuma D, Hochsztain E, Barrera MA, Granell-Canut C, León-Pazmiño MF, López-Ramírez P, Morocho-Zurita V et al (2022) Building a gold standard dataset to identify articles about geographic information science. IEEE Access 10:19926–19936
Clark S, Pulman S (2007) Combining symbolic and distributional models of meaning. Retrieved from https://www.aaai.org/Papers/Symposia/Spring/2007/SS-07-08/SS07-08-008.pdf
Bender EM, Koller A (2020) Climbing towards NLU: on meaning, form, and understanding in the age of data. In: Proceedings of the 58th annual meeting of the association for computational linguistics (ACL2020). ACL, pp 5185–5198
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need. In: Advances in neural information processing systems, vol 30
González-Carvajal, S, Garrido-Merchán EC (2020) Comparing BERT against traditional machine learning text classification. arXiv preprint arXiv:2005.13012
Rodrigues J, Gomes L, Silva J, Branco A, Santos R, Cardoso HL, Osório T (2023) Advancing neural encoding of Portuguese with transformer Albertina PT
Cañete J, Chaperon G, Fuentes R, Ho J-H, Kang H, Pérez J (2020) Spanish pre-trained BERT model and evaluation data. In: PML4DC at ICLR 2020
Akhtar Z (2020) BERT base vs BERT large. https://iq.opengenus.org/bert-base-vs-bert-large/. Accessed on 10 Nov 2022
Briggs J (2021) BERT For next sentence prediction. https://towardsdatascience.com/bert-for-next-sentence-prediction-466b67f8226f. Accessed on 10 Nov 2022
Wu X, Dong W, Wu L, Liu Y (2022) Research themes of geographical information science during 1991–2020: a retrospective bibliometric analysis. Int J Geogr Inf Sci 37:243
Wiebe J, Bruce R, O’Hara TP (1999) Development and use of a gold-standard data set for subjectivity classifications. In: Proceedings of the 37th annual meeting of the association for computational linguistics, pp 246–253
McCulloh I, Burck J, Behling J, Burks M, Parker J (2018) Leadership of data annotation teams. In: 2018 International workshop on social sensing (SocialSens). IEEE, pp. 26–31
Goldstein EB, Buscombe D, Lazarus ED, Mohanty SD, Rafique SN, Anarde KA, Ashton AD, Beuzen T, Castagno KA, Cohn N et al (2021) Labeling poststorm coastal imagery for machine learning: measurement of interrater agreement. Earth Space Sci 8(9):e2021EA001896
Boesser CT (2020) Comparing human and machine learning classification of human factors in incident reports from aviation. PhD thesis, University of Central Florida
Krippendorff K (2009) Testing the reliability of content analysis data. The content analysis reader, 350–357
Krippendorff K (2011) Agreement and information in the reliability of coding. Commun Methods Meas 5(2):93–112
Acknowledgements
The authors thank the grant provided by IDEAIS Project—CYTED: Programa Iberoamericano de Ciencia y Tecnología para el Desarrollo, Number 519RT0579.
Author information
Authors and Affiliations
Contributions
DM: Conceptualization, Methodology, Data Curation, Software, Investigation, Writing—original draft, Visualization, Funding acquisition. CL-V: Conceptualization, Methodology, Investigation, Writing—original draft, Visualization, Funding acquisition. LLR: Methodology, Data Curation, Software, Investigation, Writing—original draft, Visualization. NTR: Methodology, Investigation, Writing. JdJPA: Methodology, Investigation, Writing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Moctezuma, D., López-Vázquez, C., Lopes, L. et al. Text-based paper-level classification procedure for non-traditional sciences using a machine learning approach. Knowl Inf Syst 66, 1503–1520 (2024). https://doi.org/10.1007/s10115-023-02023-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-023-02023-0