
Conjunctive query answering over unrestricted OWL 2 ontologies
Abstract
Conjunctive Query (CQ) answering is a primary reasoning task over knowledge bases. However, when considering expressive description logics, query answering can be computationally very expensive; reasoners for CQ answering, although heavily optimized, often sacrifice expressive power of the input ontology or completeness of the computed answers in order to achieve tractability and scalability for the problem. In this work, we present a hybrid query answering architecture that combines various services to provide a CQ answering service for OWL. Specifically, it combines scalable CQ answering services for tractable languages with a CQ answering service for a more expressive language approaching the full OWL 2. If the query can be fully answered by one of the tractable services, then that service is used, to ensure maximum performance. Otherwise, the tractable services are used to compute lower and upper bound approximations. The union of the lower bounds and the intersection of the upper bounds are then compared. If the bounds do not coincide, then the “gap” answers are checked using the “full” service. These techniques led to the development of two new systems: (i) RSAComb, an efficient implementation of a new tractable answering service for RSA (role safety acyclic) (ii) ACQuA, a reference implementation of the proposed hybrid architecture combining RSAComb, PAGOdA, and HermiT to provide a CQ answering service for OWL. Our extensive evaluation shows how the additional computational cost introduced by reasoning over a more expressive language like RSA can still provide a significant improvement compared to relying on a fully-fledged reasoner. Additionally, we show how ACQuA can reliably match the performance of PAGOdA, a state-of-the-art CQ answering system that uses a similar approach, and can significantly improve performance when PAGOdA extensively relies on the underlying fully-fledged reasoner.
1.Introduction
Conjunctive Query (CQ) answering over Knowledge Bases (KBs) is a crucial reasoning task for many applications. However, when considering expressive Description Logic (DL) languages, query answering is computationally very expensive, even when considering only complexity w.r.t. the size of the data (data complexity) [62]. Fully-fledged reasoners oriented towards CQ answering over unrestricted OWL 2 ontologies exist but, although heavily optimized, they are only effective on small to medium datasets. In order to achieve tractability and scalability for the problem, we need to rely on limiting the expressive power of the input ontology or sacrifice the completeness of the computed answers.
Query answering procedures have been developed for several fragments of OWL 2 for which CQ answering is tractable with respect to data complexity [9]. Three such fragments have been standardized as OWL 2 profiles, and CQ answering techniques for these fragments have been shown to be highly scalable at the expense of expressive power [10,46,51,68,72,73]. An interesting fragment of OWL 2, tractable for standard reasoning tasks, is RSA, an ontology language that subsumes all the OWL 2 profiles, first presented by Carral et al. [14] and for which a CQ answering algorithm based on the combined approach technique [46,47] was proposed by Feier et al. [22].
In order to deal with more expressive ontologies, several techniques have been proposed to compute a sound subset of answers to a given CQ. One such technique is to approximate the input ontology to a tractable fragment, so a tractable algorithm can then be used to answer CQs over the approximated ontology. A particularly interesting approach to CQ answering over unrestricted OWL 2 ontologies, using a combination of the aforementioned techniques, is adopted by PAGOdA [85]. Its “pay-as-you-go” approach uses a Datalog reasoner to handle the bulk of the computation, computing lower and upper approximations of the answers to a query, while relying on a fully-fledged OWL 2 reasoner (HermiT [24]) only as necessary to fully answer the query.
While PAGOdA is able to avoid the use of a fully-fledged OWL 2 reasoner in some cases (i.e., when the lower and upper answer approximations coincide), its performance rapidly deteriorates when the input query requires (extensive) use of the underlying OWL 2 reasoner. The computation of lower and upper bounds is achieved by under- and over-approximating the ontology into the
This work borrows from this “pay-as-you-go” technique and builds upon existing CQ answering techniques over OWL 2 ontologies. We propose a new hybrid query answering architecture that combines black-box11 services to provide a CQ answering service for OWL. Specifically, it combines scalable CQ answering services for tractable languages with a CQ answering service for a more expressive language approaching the full OWL 2. If the query can be fully answered by one of the tractable services, then that service is used. Otherwise, the tractable services are used to compute lower and upper bound approximations, taking the union of the lower bounds and the intersection of the upper bounds. If the bounds do not coincide, then the “gap” answers are checked using the “full” service. When considering ontology approximations “from below”, we introduce a novel algorithm to compute a lower bound to the answers to an input query by means of approximation to RSA. This is done by ensuring that all the constraints for the RSA language are satisfied in the input KB. Similarly, we propose an algorithm to compute an approximation “from above” targetting
RSAComb | An efficient implementation [39,41] of the combined approach algorithm for RSA [22], reorganized to fit the new implementation design and the integration of RDFox [54,55,57,60] as a backend Datalog reasoner. We streamlined the execution of the algorithm by factoring out those steps in the combined approach that are query independent to make answering multiple queries over the same knowledge base more efficient. In addition, we included an improved version of the filtering step for the combined approach. The system accepts any OWL 2 KB and includes a customizable approximation step to languages compatible with the RSA combined approach. The system is further extended with a reference implementation of the novel approximation algorithms for the computation of answer bounds mentioned above. |
ACQuA | A reference implementation [42] of the hybrid architecture mentioned above, combining RSAComb, PAGOdA [85], and HermiT [24] to provide a CQ answering service for OWL. The resulting system ensures the same “pay-as-you-go” capabilities of the systems it is based on. The system has been designed to accommodate a high degree of modularity; the services it is built upon can be potentially substituted or augmented with more capable ones to improve the overall performance. |
We carried out an extensive evaluation both for RSAComb, as a standalone tool, and for ACQuA, to assess their effectiveness, and compare our results with PAGOdA, aiming, primarily, at improving some shortcomings of the latter tool. Our experimental results show that the new technique yields significant performance improvements in several important application scenarios. Both ACQuA22 and RSAComb33 have been released as free and open source software. Source code and documentation are available online.
The present paper includes some previously published work:
2.Preliminaries
We assume familiarity with standard concepts of first-order logic (FOL) such as term, variable, constant, predicate, atom, literal; refer to [1,5] for a formal introduction to these concepts.
We define a rule as an expression of the form
We will call a rule definite without negation in its body, and Datalog a function-free definite rule. A Datalog rule is disjunctive if it admits disjunction in the head. A fact is a Datalog rule with an empty body. The definition can be trivially extended to sets of rules.
A program Π is a set of rules. Let
– for every
– for every
The stratification partition of Π induced by δ is the sequence
A stratified program Π has a least Herbrand model (LHM), which is constructed using the immediate consequence operator
Given a stratified program Π, we define
2.1.Ontologies and conjunctive query answering
Next we give a brief overview of the description logic languages used in the paper. We will define them as restrictions of
Table 1
Normalized
| Axiom / Role / Assertion α | Definite rules | |
| (R1) | ||
| (R2) | ||
| (R3) | ||
| (R4) | ||
| (T1) | ||
| (T2) | ||
| (T3) | ||
| (T4) | ||
| (T5) | ||
| (T6) | ||
| (T7) | ||
| (A1) | ||
| (A2) | ||
Table 1 also introduces a normal form for each of these description logic languages, and w.l.o.g. we assume that any ontology introduced is restricted to these axioms. Each axiom in Table 1 corresponds to a single logic rule, provided on the right. We define
OWL 2 profiles [53] have been defined as fragments of OWL 2, designed to provide a desirable balance between computational complexity of standard reasoning tasks and expressiveness of the ontology language. We will define these standard profiles as fragments of Horn-
1. OWL 2 EL is based on the
2. OWL 2 RL is inspired by Description Logic Programs [29] and corresponds to a subset of Datalog; it does not contain axioms of type (T5);
3. OWL 2 QL is based on the DL-Lite
A conjunctive query (CQ) q is a formula
A knowledge base
CQs can be alternatively represented as Datalog rules. Let
We say that q is internalizable if it can be turned into an ontology axiom. This process is known as rolling-up [36] and is implemented in some solvers (e.g., Pellet [71]) to provide sound and complete CQ answering over OWL 2 DL over certain answer semantics when considering internalizable queries.
Given a knowledge base
2.2.PAGOdA
PAGOdA is a hybrid reasoner for sound and complete CQ answering over OWL 2 KBs, adopting a “pay-as-you-go” technique to compute the certain answers to a given query. The idea is to compute lower/upper bound approximations to the answers to a query by approximating the input ontology into a less expressive language and possibly provide a fallback (more expensive) algorithm to process the answers in the gap between the bounds; to achieve this, it uses a combination of a Datalog reasoner and a fully-fledged OWL 2 reasoner. PAGOdA treats the two systems as black boxes and tries to offload the bulk of the computation to the former and relies on the latter only when necessary.
The capabilities, performance, and scalability of PAGOdA inherently depend on the ability of the fully-fledged OWL 2 reasoner in use, and the ability to delegate the workload to a given Datalog reasoner. In the best scenario, with an OWL 2 reasoner, PAGOdA is able to answer internalisable queries [36] under certain answer semantics [85] over OWL 2 DL.
In the following is a high level description of the procedure adopted by PAGOdA to compute the answers to a query. This will prove useful to understand how this approach will be later integrated in our system, ACQuA. For a more in-depth description of the algorithm and heuristics in use, we refer the reader to [84].
Given a KB
1. the Datalog reasoner is exploited to compute a lower bound
The upper bound(a) the disjunctive Datalog subset of the input ontology, denoted with
(b) using a variant of shifting [18],
(c) a first materialization is performed, i.e.,
(d) the
(e) the combined approach for
(a) the ⊥ concept is substituted with a fresh concept name
(b) disjuncts in the head of an axiom are reduced to a single disjunct. The “most favourable” disjunct is chosen according to a polynomial choice function that reasons over the dependency graph of the input ontology;
(c) existential axioms of type (T5) are constant Skolemized.
2. If lower and upper bound coincide (i.e.,
3. otherwise, the “gap” between the upper and lower bound (i.e.,
4. for each
5. once all spurious answers have been removed from
Let’s take the lower bound computation as an example: the two performed approximations (i.e., to disjunctive Datalog and to
PAGOdA’s reference implementation88 uses RDFox as a Datalog reasoner and HermiT as the underlying fully-fledged reasoner. It accepts any OWL 2 DL ontology as input, alongside a dataset in Turtle format and CQs in SPARQL [33].
PAGOdA ensures that the returned answers are always complete under ground semantics, while being ultimately limited by the capabilities of HermiT when considering the returned answers under certain answer semantics. HermiT does not natively support CQ answering and the process needs to be reduced to fact entailment first. This is possible when the input query is internalisable, i.e., the query can be rolled-up into a set of DL concept assertions. In this scenario PAGOdA returns a set of answers that is sound and complete under certain answers semantics if the bounds match or the query can be internalized into a DL concept. Otherwise, PAGOdA will return a sound set of answers (complete under ground semantics) and a bound on the incompleteness of the computed answers (under certain answers semantics).
2.3.The RSA ontology language
As we mentioned above, ACQuA combines multiple ontology approximation algorithms to compute the answers to an input query. As part of this work, we propose novel approximation algorithms that target RSA (and its extension
RSA (role safety acyclic) is a class of ontologies designed to subsume all OWL 2 profiles, while maintaining tractability of standard reasoning tasks. The RSA ontology language is designed to avoid interactions between axioms that can result in the ontology being satisfied only by exponentially large (and potentially infinite) models. This problem is often called and-branching and can be caused by interactions between axioms of type (T5) with either axioms (T3) and (R1), or axioms (T4), in Table 1.
Fig. 1.
Example of exponential model enumerating numbers from 0 to
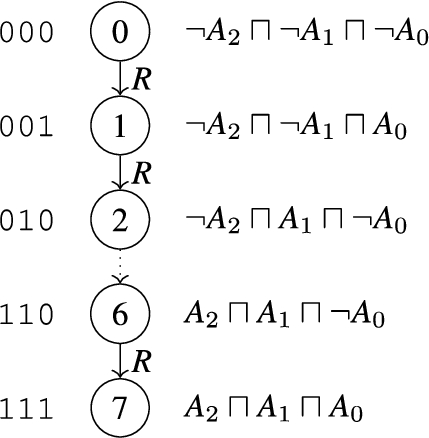
Example 2.1.
Interaction between existential quantifiers (axioms of type (T5)) and universal quantifiers (encoded by axioms of type (T3) and (R1)) can lead to an ontology that may only be satisfied by models of exponential size.
Consider the following knowledge base with ABox
RSA is based on the Horn-
Definition 2.1
Definition 2.1([22], Definition 1).
A role R in
1.
2. S is in an axiom (T4) and
Note that, all OWL 2 profiles (
Example 2.2.
In Example 2.1, R is unsafe. In fact, even for
Then, R appears in an axiom of type (T5),
The distinction between safe and unsafe roles makes it possible to strengthen the translation π from Table 1 while preserving satisfiability and entailment of unary facts.
Definition 2.2
Definition 2.2([22], Definition 2).
Let
Theorem 2.1
Theorem 2.1([14], Theorem 2).
A Horn-
Note that if
Potential bad interactions between unsafe roles can be avoided by detecting any cyclic or diamond-shape materialization involving unsafe roles. This check is performed by constant Skolemizing all existential axioms with an unsafe role, and building a graph representing the materialization process, projected on unsafe interaction. Checking that the graph is an oriented forest, along with some additional conditions which preclude harmful interactions between equality-generating axioms and inverse roles, leads to the definition of RSA.
Definition 2.3
Definition 2.3([22], Definition 3).
Let
Let
(i) for each pair of atoms
(ii) for each pair of atoms
We say that
Definition 2.4.
With reference to Definition 2.3, let
The fact that
Theorem 2.2
Theorem 2.2([14], Theorem 3).
If
Tractability of standard reasoning tasks for RSA ontologies follows from Theorem 2.1 and Theorem 2.2.
2.3.1.Combined approach for RSA
The combined approach for RSA consists of two main steps to be offloaded to a Datalog reasoner able to handle stratified negation and function symbols.
The first step computes the canonical model of an RSA ontology over an extended signature (introduced to deal with inverse roles and directionality of newly generated binary atoms). The computed canonical model is not universal and, as such, might lead to spurious answers in the evaluation of CQs.
The second step of the computation performs a filtration of the computed answers to identify only the certain answers to the input query.
Canonical model computation The computation of the canonical model for a knowledge base
First we define the Datalog program
Table 2
Translation of Horn-
| Axioms in | LP rules |
| non-(T5) axiom α | |
| R role, | |
| (T5) axiom, R unsafe | |
| (T5) axiom, R safe | |
Definition 2.5
Definition 2.5([22], Definition 4).
Let
–
–
–
Let
The set
The canonical model for an RSA input ontology is defined as
Theorem 2.3
Theorem 2.3([22],Theorem 3).
The following holds:
(i)
(ii)
(iii) if
(iv) there are no terms
Filtering spurious answers For the filtering step, a query dependent logic program
Table 3
Rules in
| (1) | |
| (2) | |
| (3a) | |
| (3b) | |
| (3c) | |
| (4a) | for all |
| (4b) | for all |
| (4c) | for all |
| for all | |
| (5a) | |
| (5b) | |
| (5c) | |
| (6) | for each |
| for each | |
| (7a) | |
| (7b) | |
| (8a) | |
| (8b) | |
| (8c) | |
| (9) |
Filtering program
Definition 2.6
Definition 2.6([22], Definition 5).
Let
Theorem 2.4
Theorem 2.4([22], Theorem 4).
Let
(i)
(ii)
(iii) if
We can then build a worst-case exponential algorithm that, given an ontology
3.Overview
We propose a hybrid query answering architecture which provides CQ answering capabilities for OWL 2 by means of combining different answering services treated as black-boxes. In particular, we combine scalable CQ answering services targeting tractable ontology languages with answering services for more expressive languages approaching the full OWL 2.
Given an input CQ over a certain knowledge base, we process the query using the tractable services; if the query can be fully answered by one of these tractable services, we simply provide the resulting answers to the user. Otherwise, we compute multiple lower and upper bounds to the answers to the query by approximating the knowledge base “from above” and “from below” and taking the union of the lower bounds and the intersection of the upper bounds. Finally, if the bounds do not coincide, the “gap” answers are validated by using the “full” service.
As part of this work, we introduce a novel algorithm to compute a lower bound to the answers to an input query by means of approximation to RSA. Similarly, we propose an algorithm to compute an approximation “from above” targetting
The reference implementation ACQuA is built on top of the following tools:
(i) RSAComb, a novel system for CQ answering over RSA ontologies, based on the combined approach, extended with algorithms to computes bounds of the answers to a query via approximation of the input KB to RSA;
(ii) PAGOdA, providing lower and upper bounds to the answers to a query and techniques to further refine these bounds to provide CQ answering capability over OWL 2 DL;
(iii) a fully-fledged reasoner (such as HermiT) for CQ answering over a certain ontology language.
Fig. 2.
Workflow of the ACQuA system.
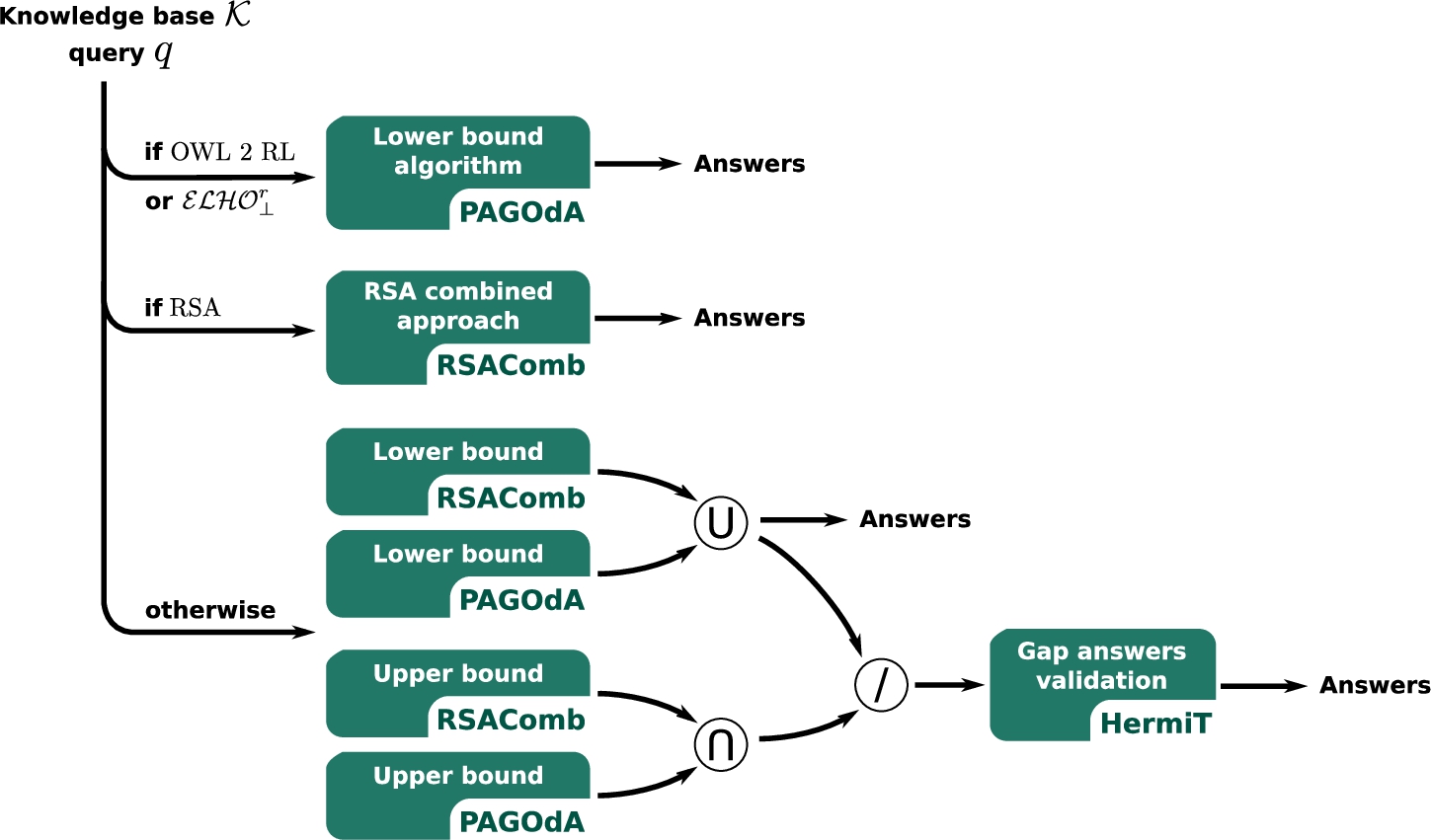
Given a generic KB
1. A preliminary satisfiability check is performed over the input knowledge base
2. If
3. If
4. Compute the bounds to the answers to q as
5. If
6. Compute
7. Use HermiT on
8. Return
The choice of fully-fledged reasoner ultimately determines the class of ontologies for which CQ answering is sound and complete under ground and/or certain answer semantics for the overall system. Thanks to RSAComb, ACQuA is sound and complete for CQ answering under certain answer semantics for ontologies in RSA [22]. With the integration of PAGOdA, and a suitable fully-fledged reasoner, like HermiT, ACQuA is able to answer internalisable queries [36] over OWL 2 DL under certain answer semantics [85].
Steps 2,6,7 and the computation of
To help the reader follow along with the description of the proposed techniques, we consider the following running example.
Example 3.1.
Consider the KB
Table 4
Running example
| (r1) | (a1) | ||
| (r2) | (a2) | ||
| (a3) | |||
| (t1) | (a4) | ||
| (t2) | (a5) | ||
| (t3) | (a6) | ||
| (t4) | (a7) | ||
| (t5) | (a8) | ||
| (t6) | (a9) | ||
| (t7) | (a10) | ||
| (t8) | |||
| (t9) | |||
| (q1) | |||
| (q2) |
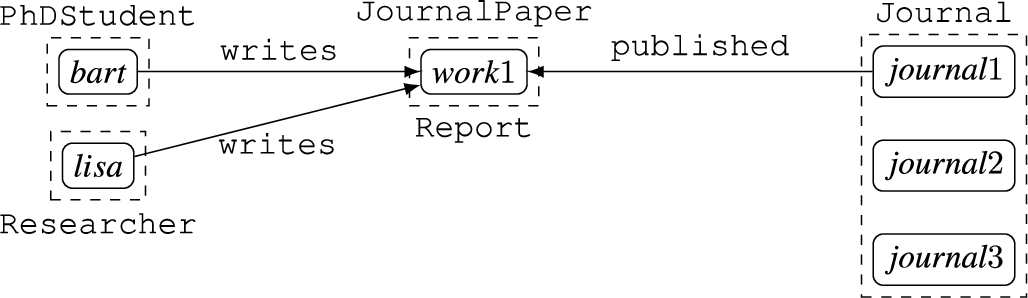
Intuitively, the ABox contains a collection of statements about researchers and their research outputs; on top of that, the ontology (RBox and TBox) models additional information about the relationships between different types of papers and their publications processes. The CQs ask about venues and works published in multiple venues. For reader’s convenience, a visual representation of the ABox
Fig. 3.
Graphical representation of the ABox
Some axioms are not expressed in normal form (see Table 1) and can be further normalized as follows: axiom (t1) can be rewritten as
4.Lower bound computation
In this section we present a technique to compute a lower bound to the answers to an input query, by means of approximating the input KB to RSA.
RSA is not purely syntactically defined, and instead introduces a set of constraints over the ontology language Horn-
1. From a generic
2. From
3. From Horn-
4.1.Approximation to ALCHOIQ
This first step is performed by discarding any axiom that is not in
Let
In Example 3.1,
4.2.Approximation to Horn-ALCHOIQ
We will now describe how to reduce an
To address this and improve the approximation to Horn-
Example 4.1.
In Example 3.1, we know that assertions
Program shifting is formally defined as follows.
Definition 4.1
Definition 4.1([85], Def. 4.3).
Let r be a normalized disjunctive Datalog rule. For each predicate P in r, let
– if r is of the form
then– if r is of the form
then
We apply this technique to our
Theorem 4.1.
Let
Proof.
See the Appendix. □
4.3.Approximation to RSA
In this section we provide a description of an algorithm to approximate the Horn-
1. checking whether
2. checking whether
We first consider step 1. If
Cycles can be broken by removing nodes from
Lemma 4.1.
Let
Proof.
This is proven by observing that, by definition of dependency graph, constant
Using the Datalog reasoner, we compute
Algorithm 1:
Cycle detection in

Next, we need to deal with equality safety (step 2). According to the definition of RSA, the following steps can be performed to ensure this property:
i. delete any (T4) axiom that involves a role S such that there exists
ii. if there is a pair of atoms
Again, by removing some selected axioms we are able to force the input Horn-
Theorem 4.2.
Let
Proof.
By Section 4.1 and Theorem 4.1 we know that
As mentioned in Section 2, PAGOdA uses a similar approach to compute a lower bound by approximating the input ontology first to disjunctive Datalog and then to Datalog; this is done by discarding any axiom that is not in the language, while introducing some additional heuristics to handle specifically disjunctive and existential axioms.
Note that, in general, the lower bound resulting from the algorithm proposed here is incomparable with the one produced by PAGOdA.
The next example shows a scenario in which the lower bound computed by our algorithm is tighter than the one produced by PAGOdA. On the other hand, the RSA language fully captures OWL 2 RL (used internally by PAGOdA) only when not considering property chain axioms.
Both approximation techniques will be later combined into ACQuA.
Example 4.2.
Consider our running Example 3.1 and
–
–
Now, let
The dependency graph
Fig. 4.
Graphical representation of
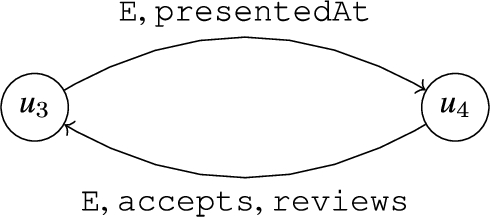
If we consider the query (q1), then:
5.Upper bound computation
We will now look at the problem of approximating a generic input KB
We adopt a similar approach to the one used in the lower bound computation and divide the procedure in steps. Given an
1. replace any occurrence of ⊥ in the knowledge base with a fresh nullary predicate
2. approximate disjunctive rules by removing all but one disjunct from the head of the rule. For each rule, the selected disjunct is chosen deterministically using an efficient choice function;
3. enforce the constraints that define the RSA ontology language on the Horn-
5.1.⊥ substitution
As described above, ACQuA performs a preliminary satisfiability check on the input KB; in spite of this, while strengthening the KB, we might cause the KB to become unsatisfiable.
In order to provide a meaningful upper bound even in cases where the approximation leads to an unsatisfiable KB, we adopt an approach initially proposed in PAGOdA. The idea is to substitute every occurrence of ⊥ with a fresh nullary predicate
This step has been included purely for theoretical purposes. RDFox, used in the implementation of the approximation algorithm, will not explicitly check for satisfiability during query answering, making it possible to consider correct the answers to a query even when the KB is unsatisfiable.
5.2.Approximation of disjunctive rules
According to Table 1, axioms of type (T1) and (T4) can introduce disjunction in the head of rules. This usually results in non-determinism in the answering process and a corresponding jump in computational complexity. In order to rewrite these axioms and avoid the introduction of this operator, we borrow a technique used in a similar fashion in PAGOdA. The approach consists in replacing any disjunction in the head of a rule with one of the disjuncts. It is easy to see that this strengthens the KB and eliminates any non-determinism introduced by the disjunction. The surviving disjunct is chosen deterministically using an efficient choice function; the idea is to analyse the dependency graph of the KB and choose a disjunct which does not eventually lead to a contradiction. To this end, a standard dependency graph of the KB is built and disjuncts are ordered according to their distance from
Given a choice function ch that returns a concept name out of an input set, we define the process of eliminating disjunction from the head of a rule as follows
Definition 5.1.
Let δ be a function from axioms to axioms eliminating disjunction from the head of any axiom of type (T1) and (T4):
Example 5.1.
Consider axioms (t3) from our running example. Let
5.3.From Horn-ALCHOIQ + RSA +
The final step of the approximation process consists in enforcing the additional constraints that the RSA language introduces on top of Horn-
Given
1. checking whether
2. checking whether
In order to ensure equality safety we proceed similarly to the lower bound case. For any pair of atoms
On the other hand, for each pair of atoms
Finally, we reduce
These steps can be summarized in the definition of
Definition 5.2.
We define
Finally, given
Theorem 5.1.
Let
(i)
(ii)
(iii) if
Proof.
See the Appendix. □
Example 5.2.
Consider, again, our running example (Example 3.1) and
If we consider the query (q2), then:
5.4.Property chain axioms
Our tests show that, general property chain axioms (axioms of type (R4) in Table 1) are quite uncommon in practice. Transitive property axioms, on the other hand, are a specialization of (R4) that can be easily found in common ontologies. While we ignored the presence of these axioms so far, it can be shown that completeness is still guaranteed when including them in the language [14, Theorem 2,Proposition 1]. Intuitively, due to monotonicity of FOL, including more axioms in the computation of the canonical model will lead to a strengthening of the KB. Furthermore, the computational complexity for the computation of the canonical model is still bound by the translation of the problem into Datalog, for which new heuristics have being recently proposed to efficiently handle transitive closure of roles [38]. Note that, in this case, we are not modifying the filtration step, which will then only be able to detect a fraction of the spurious answers, effectively computing an upper bound of the certain answers.
6.Design and architecture
We proposed a new framework to compute CQ answering over unrestricted OWL 2 ontologies by using answer bounds and further refinement steps. The approach has been implemented in a system called ACQuA [42], which, as discussed in the previous sections, offloads different steps in the computation to a selection of underlying systems used as black boxes, i.e., RSAComb, PAGOdA and HermiT.
ACQuA is inspired by the “pay-as-you-go” philosophy that drove the development of PAGOdA and as such shares similarities and capabilities with the latter tool. The idea is to take different steps depending on how the input KB is classified. The input KB needs to go through a consistency check and normalization procedure first. If the normalized KB is inside one of the two ontology languages for which PAGOdA provides full support (i.e., OWL 2 RL and
In this section we will describe some design and implementation details that led to the development of ACQuA. In particular, we will focus our attention on RSAComb, a novel implementation of the RSA combined approach for CQ answering, and how the tool can be used to compute lower and upper bounds to the answers of an input query.
6.1.RSAComb
RSAComb [41] is an optimized implementation of the combined approach for CQ answering in RSA. We streamlined and reorganized the algorithm to make the different steps either ontology or query independent. On top of that we designed and implemented an API to introduce approximation capabilities in the system; RSAComb is able to take an unrestricted ontology as input and potentially apply an approximation algorithm (targeting RSA or
The system is written in Scala and uses the OWLAPI [35] to interface with the input ontology and manipulate OWL 2 axioms. RDFox is used as an underlying Datalog reasoner; RSAComb has been designed to maximize the amount of computation to be offloaded to RDFox, by redefining problems in terms of queries over a materialized RDF store.
RDFox is used as a black box, and RSAComb can be adapted to use any Datalog reasoner with support for stratified negation and Skolemization. Nonetheless, the use of RDFox allowed us to introduce some optimizations based on particular features provided by the tool.
These are:
– a SKOLEM operator,1515 which provides a way to uniquely associate a sequence of terms with a fresh term;
– support for named graphs to isolate and cache partial computation;
– support for “TBox reasoning” in order to reason directly on the structure of an ontology even when outside the supported OWL fragment.
We designed and built RSAComb around these general principles:
Modularity | The code should be modular and different steps in the algorithm should be as independent of each other as possible. It should be easy to reimplement (or enhance) an intermediate step of the algorithm as long as the signature and the interface with the system as a whole remain unaltered. We achieved this by an extensive use of Scala traits, building a collection of interfaces that describe the behaviour of the different actors that take part in the execution of the combined approach for RSA. As explained in the following sections, the integration with RDFox was also key to providing a good level of modularity to the systems. |
Scalability | The system has to be able to scale efficiently even for large amounts of data. Partial results are computed when needed and reused whenever possible. A more detailed analysis on the performance and scalability of the system is provided in Section 8. |
Integration | It should be equally possible to use the system as a self-contained application or integrate it in another system. As such, our software presents a simple but effective command line interface alongside a well-structured set of classes exposing all the necessary tools to work with RSA ontologies, while hiding unnecessary implementation details. The different steps can also be disabled for user convenience. |
We will first provide a description of RSAComb as an implementation of the RSA combined approach and then go into details on how lower and upper bound algorithms are implemented in the system.
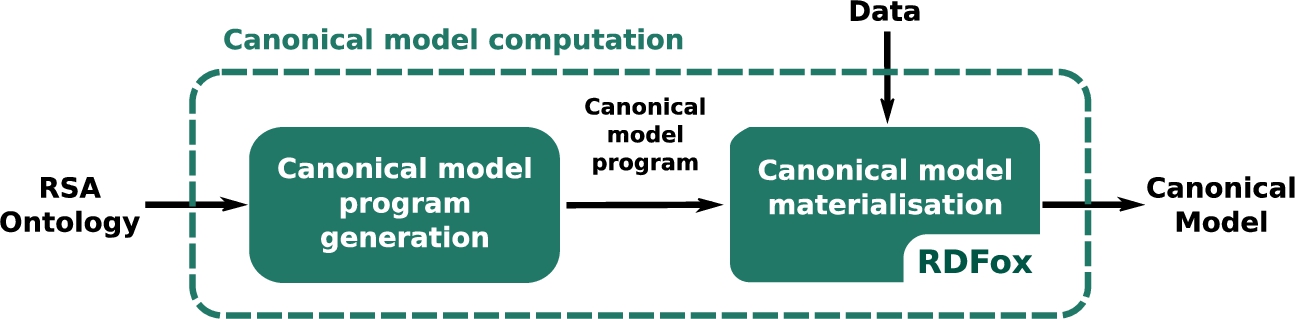
6.1.1.Overview
Fig. 5.
Workflow of the RSAComb system.

Figure 5 summarizes the workflow of RSAComb:
(i) the approximation steps take an unrestricted OWL 2 KB as input and approximate it to a target language handled by the RSA combined approach;
(ii) the canonical model for the resulting RSA KB is computed by materializing the data against a logic program derived from the input ontology;
(iii) a filtering program is derived from the input query and is combined with the canonical model to produce the set of certain answers to the input query over the approximated knowledge base.
The process of importing the input ontology (TBox, RBox) into the system is performed using the OWLAPI. Since importing large amounts of data (ABox) into the system might be expensive, data files are read and data is loaded on demand and reused whenever possible to maximize performance.
As mentioned above, two approximation algorithms ship with the system. The first approximation algorithm is an implementation of the algorithm presented in Section 4; it targets the RSA ontology language and maintains soundness w.r.t. CQ answering, i.e., answers to a CQ are a lower bound to the answers to the query over the original KB. A copy of the ontology, translated into Datalog according to Def. 2.3, is imported into RDFox along with the data and materialized by the reasoner. The dependency graph and equality safety checks (see Definition 2.3) are implemented as queries over the RDF store exposed by RDFox; the original knowledge base is altered accordingly. The second approximation is an implementation of the algorithm introduced in Section 5; it targets
The canonical model is computed for the knowledge base in Step (ii); this is done by converting each axiom in the KB into a logic rule according to Def. 2.5 and uploading it into RDFox. Note that the translation from axioms into logic rules is different from the one in Step (i), hence the need to reload them into RDFox. The data, on the other hand, is safely reused. Finally, the potentially spurious answers to the input query introduced during the canonical model computation are filtered out in Step (iii). It is worth noting that, in this scenario, steps (i),(ii) are query independent, while step (iii) is ontology independent. As such, when multiple queries are submitted over the same KB, steps (i-ii) are performed “on-demand” and only once, while the third step is performed for each input query.
6.1.2.Canonical model computation
Fig. 6.
RSAComb: canonical model computation.
The computation of the canonical model (Figure 6) involves the conversion of the input RSA ontology into logic rules as described in Def. 2.5, and where function symbols are simulated using RDFox’s built-in Skolemization feature.
Example 6.1.
A Skolemized rule derived from an existential axiom (T5)
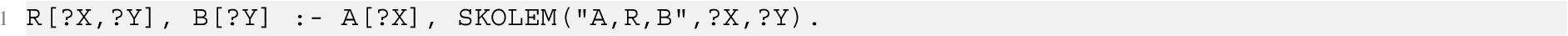
where the built-in operator SKOLEM binds ?Y to a unique value generate from the string “A,R,B” and term ?X.
The system performs the conversion and then offloads the materialization of the rules, combined with the input data, to RDFox.
Since the canonical model is query independent, this process can be performed once and the result cached and reused for every subsequent query over the same input ontology. We achieve this using RDFox’s support for RDF named graphs, which enables us to perform operations on specific “named” subsets of the data. Further operations on the graph operate and produce additional data in different named graphs, leaving the materialized canonical model intact.
Axiomatization of ⊤ and ≈ RDFox has built-in support for ⊤ (owl:Thing) and equality (owl:sameAs), so that ⊤ automatically subsumes any new class introduced within an RDF triple, and equality between terms is always consistent with its semantics.
In both cases we are not able to use these features directly: in the case of top axiomatization, we import axioms as Datalog rules, which are not taken into consideration when RDFox derives new ⊤ subsumptions;1616 in the case of equality axiomatization, the feature cannot be enabled along other features like aggregates and negation-as-failure (with the latter extensively used in our system).
To work around this, we introduce the axiomatization for both predicates explicitly. For every concept name

This gives us the correct semantics for owl:Thing.
Similar rules are introduced to axiomatize equality. We make the role reflexive, symmetric and transitive:

and introduce substitution rules to complete the axiomatization. For every concept name

The notIn and named predicates Our work also includes a few clarifications on theoretical definitions and their implementation. In the canonical model computation [22], the notIn predicate is introduced to simulate the semantics of set membership and in particular the meaning of notIn[a, b] is “a is not in set b”. During the generation of the canonical model program performed by RSAComb, we have complete knowledge of any set that might be used in a notIn atom. For each such set S, and for each element
We generate the instances of the predicate NI, representing the set of non-anonymous terms in the materialized canonical model, with the following rule:

where rsa:named is a predicate representing the set of constants in the original KB.
A final improvement has been made to the computation of the cycle function used during the generation of the canonical model program performed by RSAComb. The original definition involved a search over all possible triples
6.1.3.Filtering program and answer computation
Fig. 7.
RSAComb: answer filtering.
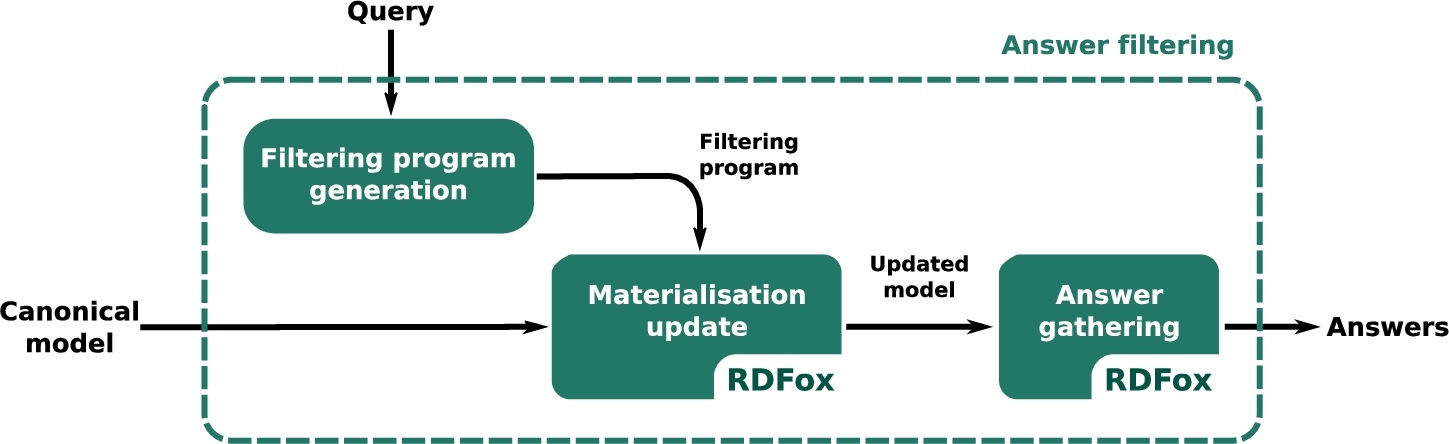
As depicted in Fig. 7, answer filtration involves the computation of the filtering program from the input query, the filtering of the materialized canonical model and the final process of gathering the answers.
RSAComb performs the translation of the query into a set of logic rules. This step was modified w.r.t. the original definition [22] to be completely ontology independent by moving the generation of rsa:named instances to the canonical model computation step. Furthermore, we redesigned the filtering step to restrict ourselves to use only unary and binary predicates and, as a result, keep the filtering somewhat closer to the realm of description logics (and to the language supported by RDFox). Filtering rules are then greatly simplified by making extensive use of the Skolemization operator provided by RDFox, hence avoiding some expensive joins that would result from a standard reification process.
Example 6.2.
Let
Using the SKOLEM functionality in RDFox, we are able to reduce the arity of a predicate P (
The complete rewriting of the filtering program is provided in Table 5. According to the documentation1818 for the SKOLEM operator in RDFox, it can be easily shown that the rewriting is not changing the semantics of the rules, but instead packs and unpacks subsets of variables in order to make rule matching more efficient.
Table 5
Improved rules for filtering step for the RSA combined approach
| (1) | |
| (2) | rsa:named instances computed in the canonical model step. |
| (3a) | |
| (3b) | |
| (3c) | |
| (4a) | for all |
| (4b) | for all |
| (4c) | for all |
| for all | |
| (5a) | |
| (5b) | |
| (5c) | |
| (6) | for each |
| for each | |
| (7a) | |
| (7b) | |
| (8a) | |
| (8b) | |
| (8c) | |
| (9) |
The filtering program is, then, loaded into RDFox and the materialization is updated taking into account the newly introduced rules. The triples produced by this materialization update are stored in a separate named graph to keep the product of filtration separate from the canonical model. This is possible because the signature of the atoms in the head of rules introduced by the filtering program is separate from the signature of the canonical model. When processing a new query, the only step we need to take is to drop the named graph associated with the filtration from the previous query, leaving unaltered all other triples. Better yet, here we have the possibility to execute queries in parallel, each one associated with a separate filtering program and hence storing their derivations in different named graphs. The materialization update for each of the queries is isolated and does not interfere with the other processes.
At this point, the task of gathering the answers to the query over the input KB is reduced to querying a materialized named graph for the atoms representing the certain answers.
Example 6.3.
Given a query 
where we first collect all instances ?K of the class rsa:Ans, and then we unpack them at line ?? using the custom RDFox syntax for the SKOLEM operator, to retrieve the actual answers. When answering BCQs, we only need to check for an rsa:Ans witness, i.e., an instance of rsa:Ans in the RDF store: 
6.2.Lower bound approximation to RSA
As described in Section 4, we propose a novel algorithm for approximating an unrestricted input KB to RSA. The procedure is composed of 3 main steps:
1. Approximation to
2. Approximation to Horn-
3. Approximation to RSA by reducing the ontology dependency graph to an oriented forest and ensuring equality safety properties.
– building and reasoning over a custom dependency graph derived from the materialization of the input data over a Horn-
– reasoning over the knowledge base itself, and in particular performing some RBox reasoning task.

RSAComb builds the dependency graph for the input KB. Using Algorithm 1 we detect and break cycles by iteratively removing nodes. The existential axioms corresponding to the nodes returned by the visit are removed from the input ontology.
For the equality safety check we need to reason over the ontology itself and in particular perform some reasoning over its RBox. Regardless of the support offered by the Datalog reasoner for this task, axioms in a knowledge base can be encoded as RDF triples.1919
RDFox supports importing OWL 2 axioms and the conversion into RDF triples is performed automatically. RBox reasoning (Listing 1) is then achieved by importing the following rules into the RDF store.
Listing 1.
Rules for role subsumption reasoning

These encode reflexivity and transitivity of sub-role axioms (R2) (lines 7–9), taking into account inverse (lines 3–5) and equivalent roles (line 1), as well.
Once both the data and the axioms have been imported and materialized according to their respective rules, the equality safety condition (i) of Definition 2.3 can be formulated as a query (see Listing 2).
For each pair of atoms
Listing 2.
Condition 1 of equality safety in RSA definition

Similarly, condition (ii) can be formulated as a query (see Listing 3).
Listing 3.
Condition 2 of equality safety in RSA definition

For each pair of atoms
6.3.Upper bound approximation to RSA
The approximation algorithm proposed in Section 5 is implemented in a similar way. Again, the procedure is divided into the following steps:
1. rewriting of ⊥ into a new nullary predicate
2. rewriting of disjunctive rules to eliminate disjunction, and
3. approximation to
The rewriting of disjunctive rules is also straightforward, and is performed directly by RSAComb. The choice function is implemented as in PAGOdA, in order to avoid the derivation of ⊥ (see Section 5.2).
Finally, the third step involves the same framework introduced in the previous section for the lower bound computation, and in particular the construction of the dependency graph and role subsumption reasoning are performed in the same way. Both the enforcing of equality safety and the reduction of the dependency graph to a forest involve a rewriting of the KB according to Def. 5.2, and are implemented directly in RDFox.
Finally, RSAComb can be used to run the combined approach algorithm on the resulting
7.Related work
Conjunctive query answering over knowledge bases is one of the foundational problems when reasoning over ontologies. This, along with its corresponding decision problem (conjunctive query entailment, CQE) have been analysed both from the theoretical point of view (with extensive research on its computational complexity) and from the practical point of view, leading to a number of algorithms and their implementation in various reasoning systems. For a summary of the complexity results on decidability of CQE for some of the ontology languages mentioned in this work, see Table 6.
Table 6
Decidability of CQE for a selection of ontology languages
| Ontology language | Combined complexity | Data complexity |
| NP–complete [72] | P–complete [69,72] | |
| OWL 2 QL | NP–complete [10,12] | AC |
| OWL 2 EL | PSpace–complete [48,72] | P–complete [48,72] |
| OWL 2 RL | NP–complete [1,29] | P–complete [1,29] |
| RSA | NP–complete [22] | P–complete [22] |
| Horn- | ExpTime–complete [13] | P–complete [13] |
| open | open | |
| open | open |
We will next provide an overview of the techniques proposed in the literature to perform CQ answering and in particular look at those tools that make use of bounds computation in order to drive the query execution. A closer comparison of ACQuA with these tools is also provided.
7.1.Query answering techniques
Support for CQ answering is offered natively by several existing reasoners. Some of them achieve this by ensuring sound and complete answers for a specific semantics over a certain family of ontology languages, while others limit the language in which the queries can be expressed. We will now give an overview of the several CQ answering techniques present in the literature.
7.2.Reduction to entailment checking
The first technique we are going to discuss is based on the reduction of CQ answering to entailment checking. Tableau–based DL reasoners like Pellet [71], HermiT [24], RacerPro [31] construct a finite structure that represents a model for the input KB and use blocking conditions to ensure the termination of the procedure. These reasoners usually target standard reasoning tasks and only offer limited support for CQ answering. Still, internalisable CQs can be rolled-up and included in the KB, effectively reducing CQ answering to entailment checking of a fresh concept entailed by the rolled-up query.
Pellet [71] provides support for CQ answering under ground semantics and supports CQ answering under certain answer semantics limited to tree-shaped queries (which can be internalized using the rolling-up technique).
HermiT [24] is a fully-fledged reasoner for OWL 2, based on the hypertableau calculus [59]; it does not provide a direct interface to answer CQs but reduction to entailment checking can be manually performed as a preliminary step.
RacerPro is a tableau–based system for the
Another tableau-based reasoner, Konclude [77], has been recently adapted to perform CQ answering over expressive ontologies [75], using an absorption-based technique [74,76]. The assertional part of a KB is divided into small packets used to parallelize the model construction of the tableau algorithm. This parallelizable approach, along with the use of caching to avoid the need of synchronization mechanisms between workers, can be used to derive possible answers to a CQ. Candidate answers are then checked using entailment checking, where bindings for the answer variables are restricted to individuals appearing in the possible answers. According to [75], the approach works best when considering ground queries, while the presence of existential variables can require a substantial amount of additional computation.
Overall, the systems described in this section are not primarily designed for CQ answering under certain answer semantics and instead target other reasoning tasks. The technique of reducing CQ answering to entailment checking is supported for expressive ontology languages but may not scale as well as other approaches. Optimizations have been proposed to further limit performance issues; examples are query execution order, based on the input KB [45] and data summarization [17].
When considering the development of fully-fledged reasoners targetting OWL 2, such as HermiT and Konclude, improvements on these reasoners can translate into improvements for hybrid systems like ACQuA and PAGOdA, which directly use these tools as black boxes.
7.3.Materialisation-based reasoners
Materialization-based reasoners are also widely in use and implement the forward chaining algorithm on top of (some fragment of) Datalog. Materialization-based systems are often built on top of RDF management systems; i.e., data management systems based on the Resource Description Framework representing knowledge as statements in the form of triples.
Triple stores like Jena [52], Sesame [8] and Virtuoso [21] offer query answering capabilities over RDBMS and support the RDFS description language. OWLim [7] provides support for OWL 2 RL ontologies. A materialisation-based reasoner extensively used in this work is RDFox [60], an RDF store supporting arbitrary Datalog rules over unary and binary predicates. The nature of the tool allows for important optimizations, e.g., incremental updates, and parallel materialization, at the expense of a limited expressivity in the supported description logic language [55–57,60]. RDFox covers most SPARQL 1.1 over an extension of Datalog. There are several other engines that support CQ answering over (extensions of) Datalog; among them, it is worth mentioning DLV [49], which provides support for CQ answering over an extension of disjunctive Datalog.
Although OWL 2 RL is expressive enough to cover a large portion of practical use cases, it lacks some common patterns like disjunctive knowledge or existentially quantified knowledge, that would potentially render the materialization process either non-deterministic or infinite. Typically, materialisation-based reasoners can still process ontologies outside OWL 2 RL, ignoring axioms that do not fall into the language. Answers to queries are still sound, but might not be complete, effectively providing a lower bound to the set of certain answers. This technique is used in the system PAGOdA [85] to effectively compute a sound lower bound to the set of certain answers to a CQ.
7.4.Ontology-mediated query rewriting
DLs are often used to model the domain of interest as collections of concepts and roles. In this sense, ontologies offer a great tool to build high-level semantics on top of some structured data (e.g., relational database).
OBDA directly applies this principle, creating a layer of abstraction on top of an existing data store; an ontology becomes an entry point for the user to access the underlying data via query answering. Another advantage of this approach is that it can rely on the underling data store (e.g., a RDBMS) to carry out the reasoning tasks. The OBDA framework [83] uses an ontology to rewrite an input query (i.e., expanding it by incorporating parts of the ontology). It then uses a set of mappings2020 to transform the rewritten query into a query over the underlying relational data sources. The process is called perfect reformulation [66] and ensures that the answers to the query over the dataset and the ontology are the same as the answers to the rewritten query over the dataset alone.
It is worth noting that, since the query addresses the data source(s) indirectly, any updates made to the source are immediately reflected into the system. This is in contrast with the materialisation-based approach, where updates in the source require the recomputation (or the update) of the materialized dataset.
The OBDA approach is based on ontologies that fall into the DL-Lite family of DL languages, and hence the OWL 2 QL profile, for which the rewriting of CQs into unions of first-order queries is guaranteed to exist [10]. Perfect reformulation is implemented in QuOnto [2] and further integrated into the MASTRO system [11]. Unfortunately, the query rewriting process can lead to an exponentially larger first-order query [10] and polynomial rewriting is guaranteed only for small fragments of OWL 2, such as OWL 2 QL. For a more in-depth analysis on the performance of the OBDA approach we refer the reader to the Optique project and their work with Equinor [37,44].
The query rewriting technique has been applied to
We briefly mention the work done in Clipper [19,20] which implements a query rewriting technique for Horn-
A different approach involves the manipulation and rewriting of the input query [25,28]. The authors propose a decision procedure for CQE for
7.4.1.Combined approaches
The combined approach is another widely known technique for computing a sound and complete set of answers to a CQ. In this scenario the dataset is first augmented by materializing entailed facts w.r.t. the ontology in order to build a model for the input knowledge base. This process is usually query-independent and performed in polynomial time. Spurious answers are then systematically identified by means of a filtration step or by rewriting the query [47,51] in order to derive the certain answers to the input query. An example is the combined approach for CQ answering over RSA ontologies (see Section 2.3.1), widely exploited in this work. The technique has been applied to several description logics in the
In general these techniques are designed for a specific ontology language and do not support unrestricted OWL 2 ontology. On the other hand, as shown in this work and in PAGOdA, the combined approach can be easily used as an intermediate step in the computation.
7.4.2.Hybrid approaches
We will now look at tools that combine more than one technique described above to implement CQ answering.
Hydrowl [78] is a reasoner for CQ answering combining an OWL 2 RL reasoner, a query rewriting system and a fully-fledged OWL 2 reasoner. Hydrowl uses a repairing strategy [79] (limited to those ontologies for which a repairing exists) and query rewriting to answer an input query q. First a query base, i.e., a set of atomic queries that can be answered using the OWL 2 RL reasoner, is derived from the query. It is checked whether the query base “covers” the query, and in that case the OWL 2 RL reasoner is used to answer the query; otherwise the tool falls back to the fully-fledged reasoner. Further investigation on the computation of the query base [85] shows that the algorithm is not always able to automatically extract a set of atomic queries, thus compromising the correctness of the approach.
Absorption-based query entailment checking [74] (inspired by the absorption technique introduced by Steigmiller et al. [76]) also falls into the category of hybrid approaches. An input query is rewritten in order to make its entailment more efficiently detected by the model constructed using an extended version of the tableau algorithm. In this sense, the rewritten query is used to identify the individuals that are involved in the entailment of the query and, at the same time, to guide the construction of the model in the tableau algorithm. The technique is sound for CQE for expressive ontology languages, such as
PAGOdA [85] uses a hybrid technique to compute the answers to a query, mixing different approaches. The idea is to compute lower/upper bound approximations to the answers to a query by approximating the input ontology into a less expressive language and possibly provide a fallback (more expensive) algorithm to process the answers in the gap between the bounds. For a more detailed description of the approach see Section 2.2 and [85]. ACQuA builds on top of these techniques.
7.4.3.Ontology approximation
The idea of approximating an expressive language into less expressive (but more tractable) languages has been exploited before. This was first introduced by Selman and Kautz [70] and Del Val [81] in the context of logic theories (both propositional and FOL) and has been applied in the context of ontologies and CQ answering as well. Besides PAGOdA, some of the systems that use ontology approximation to explore and restrict the set of answers to a given CQ are SCREECH [34], TrOWL [80] and SHER [17].
The SCREECH system [34] is able to compute an (unsound or incomplete) approximation of the answers to a query under ground semantics. It achieves that by performing a query dependent (and possibly exponential) rewriting of the input
TrOWL [80] is a system providing CQ answering capabilities over OWL 2 DL. It uses a semantic approximation [63] technique to transform an OWL 2 DL ontology into OWL 2 QL for CQ answering and a syntactic approximation [67] from OWL 2 DL to OWL 2 EL for TBox reasoning. While being sound and complete for CQ answering, approximations steps in TrOWL are ontology and query dependent, making in harder to reuse partial results in the computation. Moreover, the semantic approximation requires the use of a fully-fledged reasoner to compute a KB approximation whose axioms are valid w.r.t. the input ontology.
The SHER [17] system is a tableau-based reasoner for
In addition, a way to approximate an OWL 2 ontology into an OWL 2 QL ontology maintaining completeness for instance queries is proposed as part of the filter and refine technique presented by Wandelt et al. [82]. The idea is to transform every axiom
Under the umbrella of approximate reasoning for CQ answering, the query extension technique [26,27] is of particular relevance. This algorithm aims at improving the bounds of the answers by extending the query with additional atoms obtained analysing the input ontology. The resulting query can then be used to restrict the bounds of subqueries of the initial query.
Finally, different notions of approximation for ontology-mediated queries over a selection of expressive languages like
8.Evaluation
We provide here an extensive evaluation over a range of benchmark ontologies. We start by looking at some performance results for RSAComb [41], our implementation of the combined approach for RSA, followed by a comparison of our system ACQuA [42] with PAGOdA.2121 Section 8.1 provides an in-depth description of the benchmarks used for the evaluation. Ontologies, data, queries, and scripts used to run tests and generate the graphs shown in this section are freely available online [43].
All experiments were performed on an Intel(R) Xeon(R) CPU E5-2640 v3 (2.60GHz) with 16 real cores, extended via hyper-threading to 32 virtual cores, 512 GB of RAM and running Fedora 33, kernel version 5.10.8-200.fc33.x86_64. We were able to make use of the multicore CPU and distribute the computation across cores, especially for intensive tasks offloaded to RDFox.
8.1.Benchmarks and tools
We use two different sets of benchmark ontologies:
The PAGOdA batch consists of a selection of ontologies and benchmark data that comes with the PAGOdA distribution.2323 These resources include ontology, data, and queries for:
– LUBM and UOBM, standard benchmarks with a data generator (depending on a numerical parameter) and sample queries. When referring to a dataset generated for a particular parameter we will use LUBM(n) and UOBM(n) for some number n. PAGOdA provides an additional set of queries more challenging for the tool.
– Reactome and Uniprot, realistic ontologies for which both data and relevant queries are provided. To test scalability, the datasets of these ontologies have been sampled in subsets of increasing size.
Table 7
Benchmarks statistics, with LUBM/UOBM data generators depending on a parameter n
| # Axioms | # Facts | # Queries | |
| LUBM(n) | 93 | 35 | |
| UOBM(n) | 186 | 20 | |
| Reactome | 559 | 130 | |
| Uniprot | 442 | 240 |
This batch aims at testing the system with a set of well–established benchmark queries. These queries have been defined to stress a system on a broad range of aspects of an answering routine, and vary a lot in terms of complexity and number of answers.
For the OOR batch we selected 126 ontology from the repository with non-empty ABoxes. A summary of the statistics of the ontologies in the repository can be found online.2424
Since the Oxford Ontology Repository does not provide any test queries, we generated, for each ontology, a set of sample queries by extracting atomic concept, atomic role and existential patterns from the structure of the ontology. In order to generate a suitable number of queries we used the following step:
1. Import the ontology into RDFox as RDF triples.
2. Query for a specific pattern in the ontology, e.g.,
 to retrieve all existential axioms in the ontology.
to retrieve all existential axioms in the ontology.3. Convert those patterns into queries.

By doing so, we aimed for an empirical confirmation of our ability to produce the correct set of answers under certain answer semantics, for a set of queries that potentially provide different results when considering them under ground semantics.
While the generated queries have a limited number of atoms, the primary aim of this batch is to stress the system with a high number of queries per ontology; this allows us to draw conclusions on the behaviour of the system on a wider variety of test cases.
The collection of SPARQL queries and the scripts to generate them are part of our benchmark distribution [43].
8.2.PAGOdA batch
We now present the test result obtained using the first set of benchmarks. We first tested RSAComb as a standalone system, in order to evaluate its performance and scalability. Later we compare the performance of ACQuA against the original PAGOdA. This is particular usefully since we were able to draw a very close comparison between the two tools and improve upon the observations provided by PAGOdA [85]. This also helped us identify how and when ACQuA’s algorithm outperformed PAGOdA, solving some performance issues with the latter tool.
8.2.1.RSAComb
As part of this work, we introduced RSAComb, an improved implementation of the combined approach algorithm for RSA, released as free and open source software [39]. Given that the original reference implementation [22] was not available when we started this work, and some details about the testing process are not provided, we will not try to draw a comparison between the results provided here and those provided in the original paper.
Our implementation is written in Scala and uses RDFox2525 as the underlying Datalog reasoner. At the time of writing, development and testing have been carried out using Scala v2.13.5 and RDFox v5.2. We can easily interface Scala with Java libraries and in particular the OWLAPI [35] for easy ontology manipulation. Thanks to the Java wrapper API provided with RDFox we were able to take advantage of a tight integration with the tool and simplify the following integration into ACQuA.
In the following we provide tests result of our system against LUBM [30] and Reactome2626 using the set of queries originally used in the testing of the combined approach for RSA [22]. All results provided below are averages of at least 3 measurements.
Fig. 8.
Scalability of approximation to RSA and canonical model computation in RSAComb.
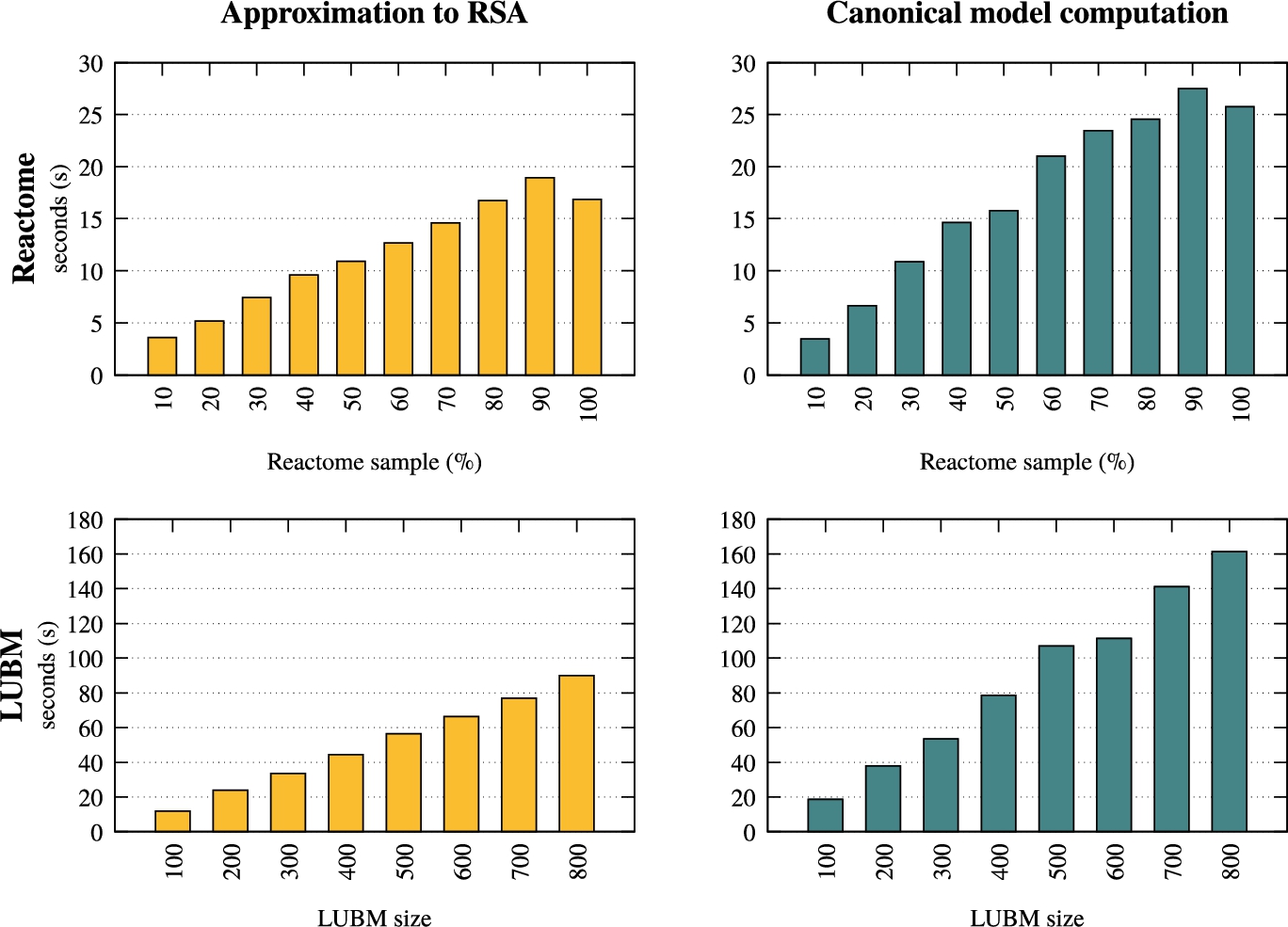
In Fig. 8 we show the scalability of our algorithm for the lower bound approximation to RSA and the computation of the canonical model for the approximated ontology. The two steps are query independent and the trend appears to be linear w.r.t. the dataset size, both in LUBM and Reactome; this can be explained by observing that the approximation algorithm involves the materialization of the input dataset against a modified version of the ontology, hence depending on the size of the whole KB;
Fig. 9.
RSAComb answer filtering in Reactome.
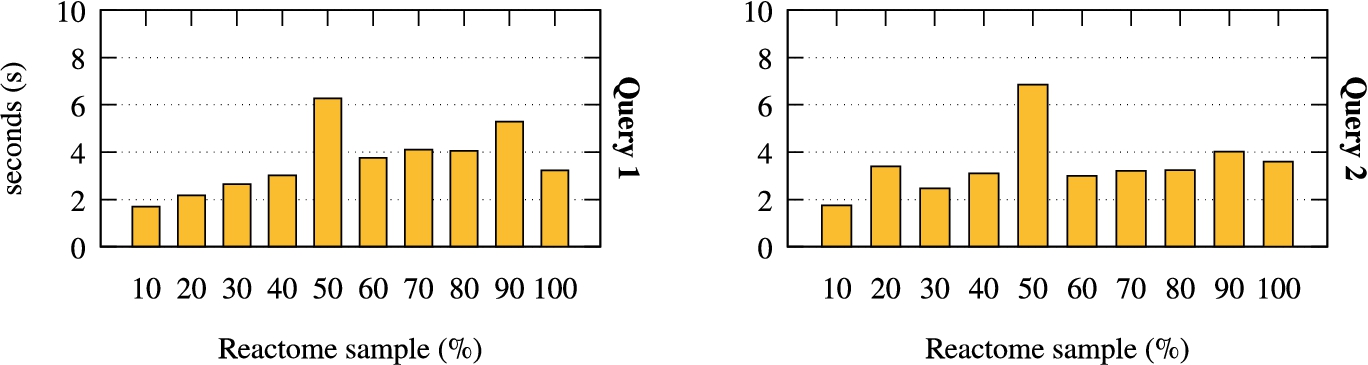
The filtering process is instead less dependent on the size of the data and more dependent on its composition and distribution. As such, a bigger dataset does not necessarily correspond to a greater amount of filtering, as shown in Fig. 9, where we reported the execution time for query 1 and 2 in Reactome. This figure also shows how the filtering depends on the data distribution; both queries take longer on a 50% sample of the data than on other datasets (even larger ones) due to its specific content. In general, we noticed that the time spent by the system on the filtering step is considerably lower than the time spent on the canonical model computation (as described below, and shown in Fig. 11).
Fig. 10.
Answer filtering in Query 2 in LUBM.
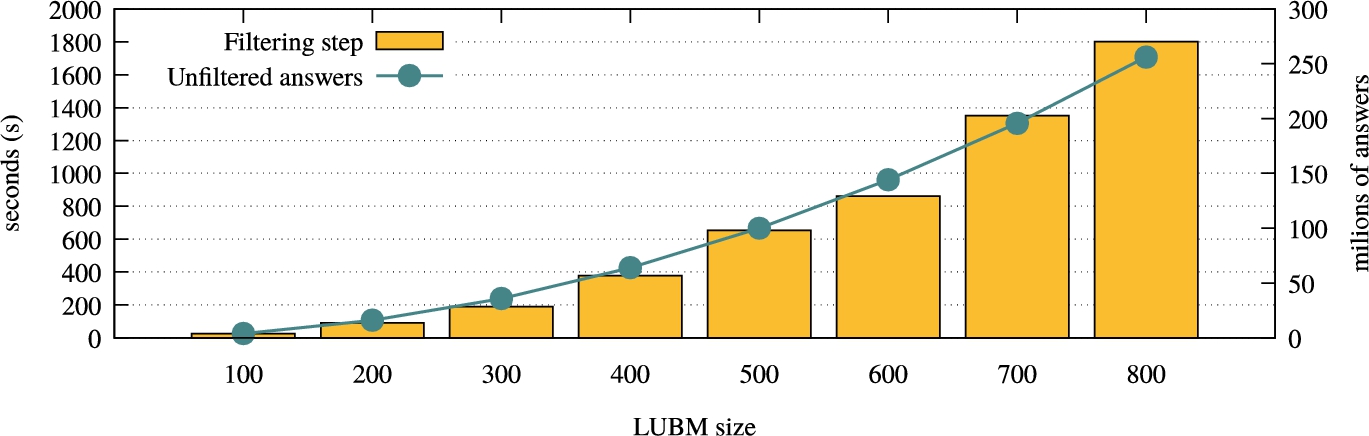
This unpredictability of the filtering step can “backfire” when a huge amount of filtering is involved. In Fig. 10 we show the filtering time for query 2 in LUBM along with the amount of unfiltered answers that the filtering program needs to process. It is worth noting that less than 1‰ of the unfiltered answers are found to be part of the certain answers. Figure 10 confirms the previous claims that the filtering step grows proportionally to the amount of filtering that is needed for a particular query. Finally, this figure shows how our system is able to handle a gigantic filtering step, processing hundreds of millions of facts in a reasonable amount of time.
Fig. 11.
Percent time distribution of canonical model computation (at the bottom, in blue) and answer filtering (at the top, in yellow) in Reactome.
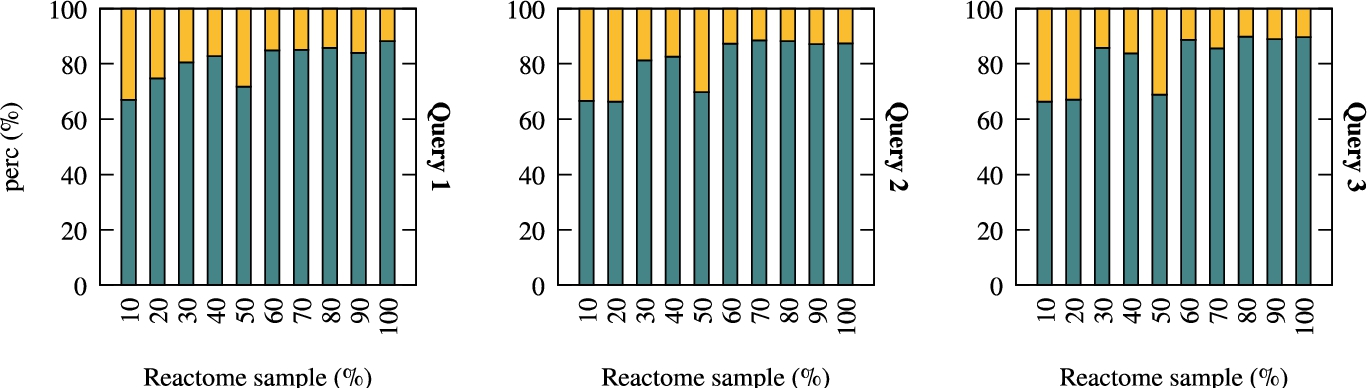
Finally, Fig. 11 shows how execution time is distributed among the two main tasks of the combined approach. Filtering takes consistently less that 20% of the total execution time, when considering bigger datasets. As mentioned before, we can limit the impact of the canonical model computation by computing it “offline” whenever we find ourselves in a scenario in which we need to perform query answering over a fixed ontology.
8.2.2.ACQuA
We will now provide test results for the PAGOdA batch against ACQuA; this will allow us to draw a direct comparison between the tool and PAGOdA [85], for which the same benchmarks were used during the evaluation phase. During our tests we were able to reproduce the results provided in the original paper except for UOBM, for which PAGOdA does not terminate with a timeout of 10h and outputs no relevant information.
We chose this as a first set of benchmarks because we were able to use the extensive analysis on PAGOdA’s performance to guide our research and easily detect those cases that our system could improve. PAGOdA initially divided its test results into three groups:
(G1) queries for which the bounds match;
(G2) queries with a non-empty gap, but for which summarization is able to filter out all remaining spurious answers;
(G3) queries where HermiT is called on at least one of the test datasets.
When considering RSAComb and PAGOdA, the building blocks of ACQuA, separately, efficiency in the two tools mainly depends on the input ontology and the type of query answered, with PAGOdA showing worse performance when heavily relying on HermiT. On the other hand, when combining the tools into ACQuA, RSAComb is able to further limit the occurrence of these cases, providing better performance overall.
In general ACQuA is able to match PAGOdA’s results in all queries in the (G1-2) groups. This should not come as a surprise, since the already excellent results from PAGOdA weren’t leaving much room for improvement and were showing that more complex CQ answering techniques were not needed for these families of queries. In particular, for query in the G1 group, ACQuA does not perform any additional step other than PAGOdA’s computation of lower and upper bounds (avoiding the use of HermiT altogether).
For this reason we will be focusing on those queries falling in the (G3) group, for which PAGOdA’s performance does not scale well.
Fig. 12.
Scalability of query processing times for LUBM, UOBM and Reactome in ACQuA vs PAGOdA.
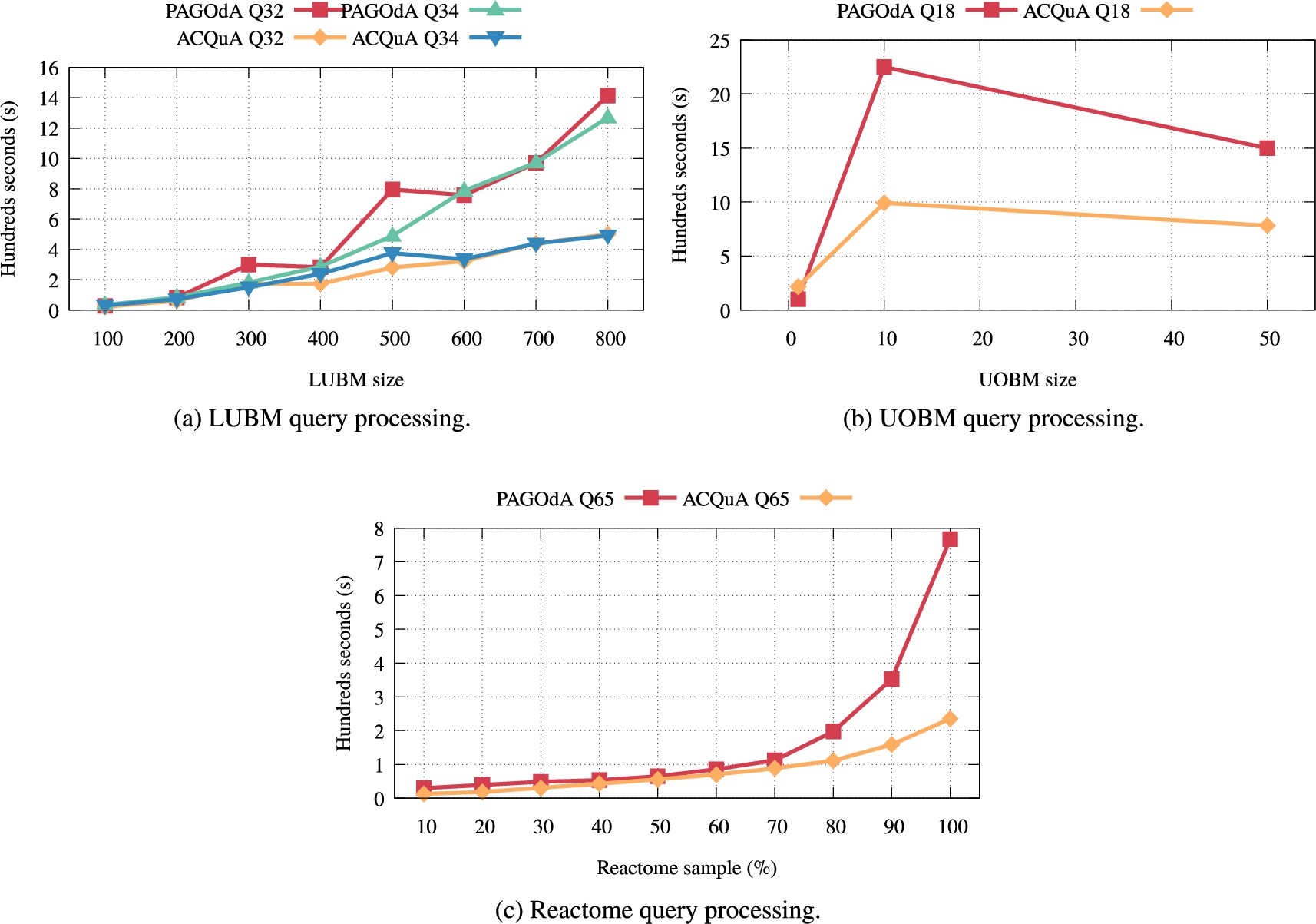
According to [85, Section 10.3.2], and partially confirmed by our tests, PAGOdA falls back to HermiT in the following queries to compute the correct set of answers: queries 32 and 34 in LUBM, query 18 in UOBM (for some data sizes) and query 65 in Reactome. Figure 12 sums up the results for our tests. Pre-processing times for the ontology are not taken into account here since the process is common to both tools and, in general, can be computed offline.
LUBM For both queries we were able to compute matching bounds, skipping the call(s) to HermiT altogether. This resulted in a significant improvement on the query processing time (Fig. 12a). It is interesting to notice that in this case the nature of the data and the queries seem to lead to a linear growth with respect to the size of the data.
Additionally, while testing the tools, we noticed that PAGOdA was having some difficulties returning a sound set of certain answers to queries involving existential knowledge, potentially falling back to ground semantics instead.
Example 8.1.
LUBM TBox contains the following axiom describing the fact that each research assistant works for at least one research group

should return all 39 instances of
UOBM We could not perform a direct comparison with UOBM since we were unable to reproduce PAGOdA’s results [85], with the tool timing out on a 10h run with no relevant output, even for the smaller datasets. Regardless, we were able to observe a recognizable pattern in the results for query 18. In Fig. 12b, we report our results against an estimate of PAGOdA’s performance; the estimation was carried out by looking at the graphs of the original paper and considering the closest values that the resolution of images allowed us to read. Even in this case we were able to avoid the use of HermiT, consequently improving the query processing time overall.
Reactome We were able to answer query 65 with matching bounds, avoiding again the use of HermiT. This resulted in an improvement of almost 600 seconds for the full Reactome dataset.
Furthermore, we found that the answers returned by PAGOdA for some of the queries in LUBM were only correct if considering CQ answering under ground semantics. Examples of these are query 15–16 from the PAGOdA benchmarks, for which PAGOdA was able to return only an incomplete set of answers.2727 In these cases ACQuA was able to fix the issue and compute the sound and complete set of answers under certain answer semantics, by avoiding the use of PAGOdA overall.
8.3.OOR batch
For the second batch of benchmarks executed on the Oxford Ontology Repository, we were able to identify a set of queries for which PAGOdA requires the use of HermiT for the full computation of the query answers.
Table 8
PAGOdA and ACQuA statistics on OOR batch (over 126 ontologies and 22462 queries)
| Ontologies processed | Queries executed | Non-empty queries | |
| PAGOdA | 103 | 18235 | 1455 |
| ACQuA | 126 | 22462 | 2256 |
As shown in Table 8, PAGOdA was able to process 103 out of 126 ontologies considered, executing around 81% of the generated queries; ACQuA, on the other hand, was able to process the entire set of ontologies, answering the full suite of generated queries. Around 10% of the queries have a non-empty answer set, and while ACQuA was able to answer all of them, PAGOdA can reliably answer only
We identified a set of 18 queries (role atomic queries) over DOLCE [23] for which PAGOdA required the use of HermiT. In these cases, only the lower bound computed by PAGOdA is exact, while ACQuA was able to compute a matching upper bound. This was detected in two different fragments of DOLCE from the repository, corresponding to ontology 14 and 24. Ontology 24 corresponds to the full DOLCE ontology, while ontology 14 is a fragment of 24 partially restricting the ABox. Both ontologies are classified as
In Fig. 13 we provide quantitative and performance results for the queries over ontology 24, where we denote the lower bound, upper bound and query processing time for the corresponding tools with L, U and T respectively. We omit ontology 14 since the results are similar to the ones reported for ontology 24.
In the first 16 queries we obtained comparable results (see Fig. 13). This is understandable since DOLCE is a relatively small ontology (with a very small ABox) and this ended up hiding the performance differences that would potentially appear with larger datasets. Moreover, it should be noted that PAGOdA is able to deal with the larger upper bound by performing a limited amount of calls to HermiT (up to 8). The number of calls increases to 19 in the last two queries; these are also the cases in which we can observe a greater gain in performance using ACQuA.
Fig. 13.
Execution time (T) on DOLCE queries in PAGOdA (red) vs ACQuA (orange), alongside quantitative results for the lower (L) and upper bounds (U) computed by the two tools.
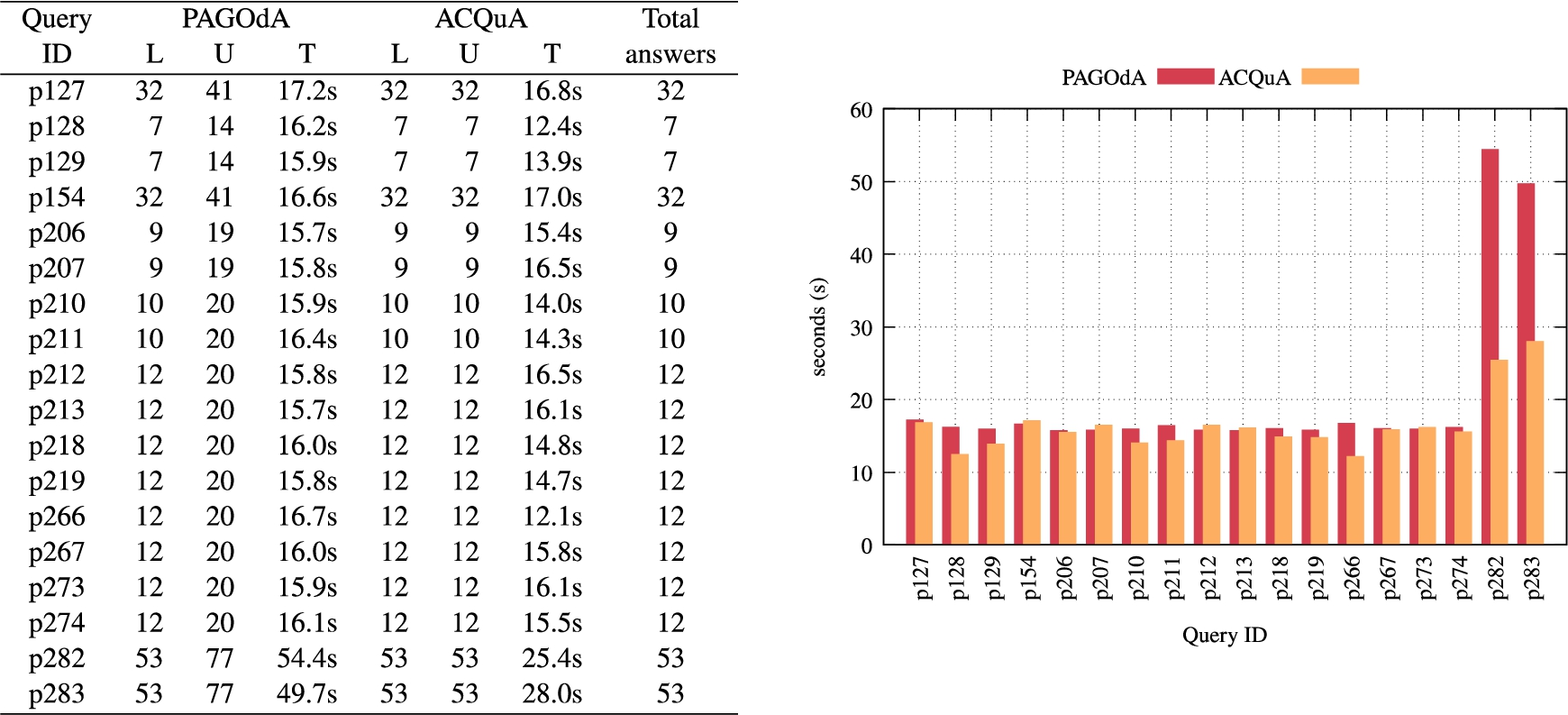
Finally, we found a set of 23 queries across multiple ontologies for which PAGOdA returned an unsound set of answers. This is the whole set of queries that PAGOdA was unable to process. This behaviour was not observed in ACQuA, which was able to compute the correct answers to the queries, without calling PAGOdA.
For the rest of the tested queries PAGOdA and ACQuA had comparable performance and were able to compute matching bounds.
To conclude this section, we provide a list of performance results and improvements highlighted by our evaluation:
– RSAComb shows linear scalability for preprocessing and canonical model computation steps. Moreover, the filtering time is lower on average than the canonical model computation;
– RSAComb handles huge amounts of data in a reasonable amount of time;
– the additional logic introduced by ACQuA is able to outperform PAGOdA in a variety of test cases, improving both the lower and upper bounds;
– ACQuA is able to fix some performance issues present in PAGOdA, by computing matching and hence further limiting the use of HermiT.
9.Discussion and conclusions
In this work, we presented a new hybrid query answering architecture that combines black-box services to provide a CQ answering system for OWL. Our system builds upon scalable CQ answering services for tractable restrictions of OWL, combining them with a CQ answering routine for a more expressive language. The technique is based on the computation of lower and upper bounds to the answers to a CQ and their progressive refinement to compute the full set of certain answers. We proposed two novel algorithms to compute lower and upper bounds to the answers to a query via approximation to RSA and
– RSAComb, an efficient implementation of the combined approach for RSA [22], introducing a new design and the use of RDFox as the underlying Datalog reasoner. The system improves upon the theoretical contribution of the original work by introducing several heuristics, in order to render the algorithm more efficient in practice. The system accepts any OWL 2 KB and includes a customizable approximation step to languages compatible with the RSA combined approach. To this end, we included a reference implementation of the novel approximation algorithms for the computation of answer bounds mentioned above.
– ACQuA, a reference implementation of the hybrid architecture combining RSAComb, PAGOdA [85], and HermiT [24] to provide a CQ answering service for OWL. By building ACQuA, we showed how the novel idea of chaining multiple services to refine answer approximations is feasible in practice. Ideally, the services it is built upon can be substituted or paired with more capable ones to improve the system performance–wise.
We intend to further extend this work in a few different directions. The RSAComb-based algorithms for the computation of answer bounds depend on a cycle-detection procedure over a KB dependency graph. We think that altering the traversal of the graph and adopting (query dependent) heuristics in the cycle-detection algorithm could improve the quality of the computed bounds.
Moreover, ACQuA mostly focuses on ontology manipulation for computing bounds and further processing gap answers. While query independent processes can be cached or computed offline, a different, complementary, approach would be to study the problem of computing answer bounds from a query perspective. An example of such a technique for computing bounds to answers to SPARQL queries has been presented by Glimm et al. [27].
To conclude, this work led us to believe that relying on hybrid frameworks and leveraging existing systems for CQ answering is a winning strategy that can render the problem more viable in practice. Thanks to its modularity, this approach can benefit from the broader research in the area of knowledge representation, description logics, and CQ answering.
Notes
1 By “black-box” we mean that the details of the reasoning process are not relevant, and indeed any reasoner providing comparable reasoning services could be used. However, the semantics are completely transparent, and the results could be interpreted/explained using a wide variety of techniques from the extensive literature on this topic (e.g., [3]). Note that this differs from the definition of the term that is often used, e.g., in the context of Machine Learning (ML), where the semantics of the system is opaque to the user.
4 In order to achieve decidability of reasoning,
5 Property chain and transitivity axioms are not taken into consideration here to keep definitions compatible with [22].
6 In the following we consider the input KB to be consistent and normalized. This is ensured by PAGOdA’s preprocessing step.
7 OWL 2 RL does not allow axioms (T5) and
9 An oriented forest is a directed acyclic graph whose underlying undirected graph is a forest.
10 It is worth noting that, to the best of our knowledge, at the moment a similar bound for
11 In this case,
12 In this case, RSAComb provides a sound and complete algorithm for CQ answering over
13 While axioms of type (T4) do not use disjunction explicitly, their translation into definite rules involve disjunction in the head of the rule.
14 This is equivalent to rewriting the axiom as
16 RDFox accepts both OWL 2 axioms encoded as RDF triples and Datalog rules; these are very different entities in the system and the semantics of special concepts/roles (like ⊤ and ≈) is applied to the former.
17 Rule 30 showcases how the SKOLEM predicate can be used in both directions: given a sequence of terms, we can pack them into a single fresh term; given a previously Skolemized term, we can unpack it to retrieve the corresponding sequence of terms.
20 Often expressed in the W3C standard R2RML language [15].
21 https://github.com/KRR-Oxford/PAGOdA (commit 8651164c).
27 This is most likely due to a bug in the PAGOdA codebase.
28 These proofs are the result of several discussions with the authors of [22].
29 Here we are using an alternative, but equivalent, definition of certain answer. Given a query
Appendices
Appendix
AppendixProofs
This chapter provides proofs for lemmas and theorems used in Sections 4–5.2828
In the following we will consider either an RSA or an
We start with the notations concerning terms and atoms. For terms s and t, we write
The derivation level of a ground atom
Theorem 4.1.
Let
Proof.
Let
(i) if
(ii) if
(iii) if
(i) If
(ii) Let
with(a)
(b)
(iii) Let
(a) there must be some rule
Since(b) For all other possible rules r that can derive
If
We next relate terms in
Lemma A.1.
Let
–
–
–
Proof.
Trivial, by definition of
Lemma A.2.
Let
–
–
–
Proof.
Trivial, by definition of
Lemma A.3.
Let
1.
2.
3.
Proof.
We prove the lemma, together with the following additional claims, by induction on the derivation level of atoms in
(i) Let
(ii) Let
In the following, let
(i) Moreover, let
Then, there must be at least one rule in
(a)
(b)
(c)
(d)
(e)
(f)
(ii) Similarly, let
Then, there must be at least one rule in
(a)
This contradicts our hypothesis that–
–
–
(b)
(c)
(d)
(e)
(f)
Now, let
(a)
–
– x is of the form
– x is of the form
(b)
(c)
–
–
Then, for transitivity of ≈,∗
∗
(d)
(e)
– If condition 1 holds for
– If condition 2 holds for
– If condition 3 holds for
Lemma A.4.
Let
1.
2.
Proof.
Similar to the proof for Lemma A.3, by induction on the derivation level of atoms in
Definition A.1.
Let Ψ be a conjunction of atoms of the form
Definition A.2.
Let
Definition A.3.
Let
1.
2.
Definition A.4.
Let
Definition A.5.
Let
Definition A.6.
Let
–
–
Lemma A.5.
For a given substitution
Proof.
Trivial, from the definitions of
Lemma A.6.
For a given substitution
Proof.
Trivial by the definition of certain answer. □
Definition A.7.
Let
1.
2.
Definition A.8.
Given
Lemma A.7.
Let σ be as in Definition A.7, and
1.
2.
3.
4.
Proof.
Given
1. We show by induction over
2. From claim 1,
3. Follows from the fact that
4. Assume
Lemma A.8.
Let σ and θ be as in Definition A.7. Then, for every
(1)
(2)
(3)
Proof.
From Lemma A.7 it follows that:
–
–
(i)
(ii)
(iii)
(i) Let
(a)
–
Then,
–
Then,
–
–
(b)
(c)
(d)
(ii) Let
(a)
(b)
(c)
(d)
(e)
(iii) Let
Lemma A.9.
Let σ and θ be as defined in Definition A.7. Then, for every
(i)
(ii)
(iii)
(iv)
(v)
(vi)
Proof.
We show that the claims of the lemma hold by induction on the derivation level of atoms in
(i)
(a)
– R is unsafe and
Then,– R is safe and
and– R is safe and
–
(b)
(c)
(d)
(e)
(ii)
(iii)
(a)
(b)
(c)
(d)
(e)
(iv)
(v)
(vi)
Lemma A.10.
For every
Proof.
Trivially proven by observing that, if
Lemma A.11.
For every
1.
2.
Proof.
By definition of canonical model and Definition 2.5. □
Lemma A.12.
For any role T and terms s and t, it is not the case that both
Proof.
Assume the opposite. Then, there must be some roles R and S and terms
Fig. 14.
Ambiguous roles in
We first deal with the case where one of
In the following, we assume that none of
– if
∗
If
andBut this is a contradiction to the fact thatA similar derivation can be done if
∗
– if both
Lemma A.13.
Let ρ be a non-anonymous match for q over
Proof.
Following from Lemma A.9,
To see that
1.
2.
To see that
From the fact that
–
– or there exist two sequences of atoms:
such that∗
∗
Then, it can be shown by induction on the length m of the sequences introduced above that
Theorem 5.1.
Let
(i)
(ii)
(iii) if
Proof.
Consider the following
(i) Both the construction of
(ii) In order to prove that
Given a model
(a) An axiom
(b) An axiom
(c) An axiom
(d) An axiom
(iii) Assume
It can be checked that
Acknowledgements
This work was supported by the AIDA project (Alan Turing Institute, EP/N510129/1), the SIRIUS Centre for Scalable Data Access (Research Council of Norway, project number 237889), Samsung Research UK, Siemens AG, and the EPSRC projects AnaLOG (EP/P025943/1), OASIS (EP/S032347/1) and UK FIRES (EP/S019111/1). For the purpose of Open Access, the author has applied a CC BY public copyright licence to any Author Accepted Manuscript (AAM) version arising from this submission.
References
[1] | S. Abiteboul, R. Hull and V. Vianu, Foundations of Databases, Addison-Wesley, (1995) , http://webdam.inria.fr/Alice/. ISBN 0-201-53771-0. |
[2] | A. Acciarri, D. Calvanese, G.D. Giacomo, D. Lembo, M. Lenzerini, M. Palmieri and R. Rosati, QuOnto: Querying ontologies, in: Proceedings, the Twentieth National Conference on Artificial Intelligence and the Seventeenth Innovative Applications of Artificial Intelligence Conference, Pittsburgh, Pennsylvania, USA, July 9–13, 2005, M.M. Veloso and S. Kambhampati, eds, AAAI Press / The MIT Press, (2005) , pp. 1670–1671, http://www.aaai.org/Library/AAAI/2005/isd05-001.php. |
[3] | C. Alrabbaa, S. Borgwardt, P. Koopmann and A. Kovtunova, Explaining ontology-mediated query answers using proofs over universal models, in: Rules and Reasoning – 6th International Joint Conference on Rules and Reasoning, RuleML+RR 2022, Proceedings, Berlin, Germany, September 26–28, 2022, G. Governatori and A. Turhan, eds, Lecture Notes in Computer Science, Vol. 13752: , Springer, (2022) , pp. 167–182. doi:10.1007/978-3-031-21541-4_11. |
[4] | F. Baader, S. Brandt and C. Lutz, Pushing the EL envelope, in: IJCAI-05, Proceedings of the Nineteenth International Joint Conference on Artificial Intelligence, Scotland, UK, July 30–August 5, 2005, L.P. Kaelbling and A. Saffiotti, eds, Professional Book Center, (2005) , pp. 364–369, http://ijcai.org/Proceedings/05/Papers/0372.pdf. |
[5] | F. Baader, I. Horrocks, C. Lutz and U. Sattler, An Introduction to Description Logic, Cambridge University Press, (2017) . |
[6] | F. Baader, C. Lutz and S. Brandt, Pushing the EL envelope further, in: Proceedings of the Fourth OWLED Workshop on OWL: Experiences and Directions, Washington, DC, USA, 1–2 April 2008, K. Clark and P.F. Patel-Schneider, eds, CEUR Workshop Proceedings, Vols 496: , CEUR-WS.org, (2008) , http://ceur-ws.org/Vol-496/owled2008dc_paper_3.pdf. |
[7] | B. Bishop, A. Kiryakov, D. Ognyanoff, I. Peikov, Z. Tashev and R. Velkov, OWLIM: A family of scalable semantic repositories, Semantic Web Journal 2: (1) ((2011) ), 33–42. doi:10.3233/SW-2011-0026. |
[8] | J. Broekstra, A. Kampman and F. van Harmelen, Sesame: A generic architecture for storing and querying RDF and RDF schema, in: The Semantic Web – ISWC 2002, First International Semantic Web Conference, Proceedings, Sardinia, Italy, June 9–12, 2002, I. Horrocks and J.A. Hendler, eds, Lecture Notes in Computer Science, Vol. 2342: , Springer, (2002) , pp. 54–68. doi:10.1007/3-540-48005-6_7. |
[9] | D. Calvanese, G. De Giacomo, D. Lembo, M. Lenzerini and R. Rosati, Data complexity of query answering in description logics, in: Proceedings, Tenth International Conference on Principles of Knowledge Representation and Reasoning, Lake District of the United Kingdom, June 2–5, 2006, AAAI Press, (2006) , pp. 260–270. |
[10] | D. Calvanese, G. De Giacomo, D. Lembo, M. Lenzerini and R. Rosati, Tractable reasoning and efficient query answering in description logics: The DL-lite family, Journal of Automated Reasoning 39: (3) ((2007) ), 385–429. doi:10.1007/s10817-007-9078-x. |
[11] | D. Calvanese, G.D. Giacomo, D. Lembo, M. Lenzerini, A. Poggi, M. Rodriguez-Muro, R. Rosati, M. Ruzzi and D.F. Savo, The MASTRO system for ontology-based data access, Semantic Web Journal 2: (1) ((2011) ), 43–53. doi:10.3233/SW-2011-0029. |
[12] | D. Calvanese, G.D. Giacomo, D. Lembo, M. Lenzerini and R. Rosati, Data complexity of query answering in description logics, Artificial Intelligence 195: ((2013) ), 335–360. doi:10.1016/j.artint.2012.10.003. |
[13] | D. Carral, I. Dragoste and M. Krötzsch, The combined approach to query answering in horn-ALCHOIQ, in: Principles of Knowledge Representation and Reasoning: Proceedings of the Sixteenth International Conference, KR 2018, Tempe, Arizona, 30 October–2 November 2018, M. Thielscher, F. Toni and F. Wolter, eds, AAAI Press, (2018) , pp. 339–348, https://aaai.org/ocs/index.php/KR/KR18/paper/view/18076. |
[14] | D. Carral, C. Feier, B.C. Grau, P. Hitzler and I. Horrocks, Pushing the boundaries of tractable ontology reasoning, in: Proceedings, Part II, The Semantic Web – ISWC 2014 – 13th International Semantic Web Conference, Riva del Garda, Italy, October 19–23, 2014, Lecture Notes in Computer Science, Vol. 8797: , Springer, (2014) , pp. 148–163. |
[15] | S. Das, S. Sundara and R. Cyganiak, R2RML: RDB to RDF Mapping Language, W3C Recommendation, W3C, 2012, https://www.w3.org/TR/2012/REC-r2rml-20120927/. |
[16] | J. Dolby, A. Fokoue, A. Kalyanpur, A. Kershenbaum, E. Schonberg, K. Srinivas and L. Ma, Scalable semantic retrieval through summarization and refinement, in: Proceedings of the Twenty-Second AAAI Conference on Artificial Intelligence, Vancouver, British Columbia, Canada, July 22–26, 2007, AAAI Press, (2007) , pp. 299–304, http://www.aaai.org/Library/AAAI/2007/aaai07-046.php. |
[17] | J. Dolby, A. Fokoue, A. Kalyanpur, E. Schonberg and K. Srinivas, Scalable highly expressive reasoner (SHER), Journal of Web Semantics 7: (4) ((2009) ), 357–361. doi:10.1016/j.websem.2009.05.002. |
[18] | T. Eiter, M. Fink, H. Tompits and S. Woltran, On eliminating disjunctions in stable logic programming, in: Principles of Knowledge Representation and Reasoning: Proceedings of the Ninth International Conference (KR2004), Whistler, Canada, June 2–5, 2004, D. Dubois, C.A. Welty and M. Williams, eds, AAAI Press, (2004) , pp. 447–458, http://www.aaai.org/Library/KR/2004/kr04-047.php. |
[19] | T. Eiter, M. Ortiz, M. Simkus, T. Tran and G. Xiao, Towards practical query answering for horn-SHIQ, in: Proceedings of the 2012 International Workshop on Description Logics, DL-2012, Rome, Italy, June 7–10, 2012, Y. Kazakov, D. Lembo and F. Wolter, eds, CEUR Workshop Proceedings, Vols 846: , CEUR-WS.org, (2012) , http://ceur-ws.org/Vol-846/paper_20.pdf. |
[20] | T. Eiter, M. Ortiz, M. Simkus, T. Tran and G. Xiao, Query rewriting for horn-SHIQ plus rules, in: Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, Ontario, Canada, July 22–26, 2012, J. Hoffmann and B. Selman, eds, AAAI Press, (2012) , http://www.aaai.org/ocs/index.php/AAAI/AAAI12/paper/view/4931. |
[21] | O. Erling and I. Mikhailov, Virtuoso: RDF support in a native RDBMS, in: Semantic Web Information Management – A Model-Based Perspective, R.D. Virgilio, F. Giunchiglia and L. Tanca, eds, Springer, (2009) , pp. 501–519. doi:10.1007/978-3-642-04329-1_21. |
[22] | C. Feier, D. Carral, G. Stefanoni, B.C. Grau and I. Horrocks, The combined approach to query answering beyond the OWL 2 profiles, in: Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, July 25–31, 2015, AAAI Press, (2015) , pp. 2971–2977. |
[23] | A. Gangemi, N. Guarino, C. Masolo, A. Oltramari and L. Schneider, Sweetening ontologies with DOLCE, in: Knowledge Engineering and Knowledge Management. Ontologies and the Semantic Web, 13th International Conference, EKAW 2002, Proceedings, Siguenza, Spain, October 1–4, 2002, A. Gómez-Pérez and V.R. Benjamins, eds, Lecture Notes in Computer Science, Vol. 2473: , Springer, (2002) , pp. 166–181. doi:10.1007/3-540-45810-7_18. |
[24] | B. Glimm, I. Horrocks, B. Motik, G. Stoilos and Z. Wang, HermiT: An OWL 2 reasoner, Journal of Automated Reasoning 53: (3) ((2014) ), 245–269. doi:10.1007/s10817-014-9305-1. |
[25] | B. Glimm, I. Horrocks and U. Sattler, Conjunctive query entailment for SHOQ, in: Proceedings of the 2007 International Workshop on Description Logics (DL2007), Brixen-Bressanone, Near Bozen-Bolzano, Italy, 8–10 June, 2007, D. Calvanese, E. Franconi, V. Haarslev, D. Lembo, B. Motik, A. Turhan and S. Tessaris, eds, CEUR Workshop Proceedings, Vols 250: , CEUR-WS.org, (2007) , http://ceur-ws.org/Vol-250/paper_63.pdf. |
[26] | B. Glimm, Y. Kazakov, I. Kollia and G.B. Stamou, OWL query answering based on query extension, in: Proceedings of the 11th International Workshop on OWL: Experiences and Directions (OWLED 2014) Co-Located with 13th International Semantic Web Conference on (ISWC 2014), Riva del Garda, Italy, October 17–18, 2014, C.M. Keet and V.A.M. Tamma, eds, CEUR Workshop Proceedings, Vol. 1265: , CEUR-WS.org, (2014) , pp. 1–12, http://ceur-ws.org/Vol-1265/owled2014_submission_1.pdf. |
[27] | B. Glimm, Y. Kazakov, I. Kollia and G.B. Stamou, Lower and upper bounds for SPARQL queries over OWL ontologies, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, Texas, USA, January 25–30, 2015, B. Bonet and S. Koenig, eds, AAAI Press, (2015) , pp. 109–115, http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/view/9715. |
[28] | B. Glimm, C. Lutz, I. Horrocks and U. Sattler, Conjunctive query answering for the description logic SHIQ, Journal of Artificial Intelligence Research 31: ((2008) ), 157–204. doi:10.1613/jair.2372. |
[29] | B.N. Grosof, I. Horrocks, R. Volz and S. Decker, Description logic programs: Combining logic programs with description logic, in: Proceedings of the Twelfth International World Wide Web Conference, WWW 2003, Budapest, Hungary, May 20–24, 2003, ACM, (2003) , pp. 48–57. |
[30] | Y. Guo, Z. Pan and J. Heflin, LUBM: A benchmark for OWL knowledge base systems, Journal of Web Semantics 3: (2–3) ((2005) ), 158–182. doi:10.1016/j.websem.2005.06.005. |
[31] | V. Haarslev, K. Hidde, R. Möller and M. Wessel, The RacerPro knowledge representation and reasoning system, Semantic Web 3: (3) ((2012) ), 267–277. doi:10.3233/SW-2011-0032. |
[32] | A. Haga, C. Lutz, L. Sabellek and F. Wolter, How to approximate ontology-mediated queries, in: Proceedings of the 18th International Conference on Principles of Knowledge Representation and Reasoning, KR 2021, Online Event, November 3–12, 2021, (2021) , pp. 323–333. doi:10.24963/kr.2021/31. |
[33] | S. Harris and A. Seaborne, SPARQL 1.1 Query Language, W3C Recommendation, W3C, 2013, https://www.w3.org/TR/2013/REC-sparql11-query-20130321/. |
[34] | P. Hitzler, M. Krötzsch, S. Rudolph and T. Tserendorj, Approximate OWL instance retrieval with SCREECH, in: Logic and Probability for Scene Interpretation, 24.02.–29.02.2008, A.G. Cohn, D.C. Hogg, R. Möller and B. Neumann, eds, Dagstuhl Seminar Proceedings, Vol. 08091: , Internationales Begegnungs- und Forschungszentrum für Informatik (IBFI), Schloss Dagstuhl, Germany, (2008) , http://drops.dagstuhl.de/opus/volltexte/2008/1615/. |
[35] | M. Horridge and S. Bechhofer, The OWL API: A Java API for OWL ontologies, Semantic Web 2: (1) ((2011) ), 11–21. doi:10.3233/SW-2011-0025. |
[36] | I. Horrocks and S. Tessaris, A conjunctive query language for description logic aboxes, in: Proceedings of the Seventeenth National Conference on Artificial Intelligence and Twelfth Conference on Innovative Applications of Artificial Intelligence, Austin, Texas, USA, July 30–August 3, 2000, H.A. Kautz and B.W. Porter, eds, AAAI Press / The MIT Press, (2000) , pp. 399–404, http://www.aaai.org/Library/AAAI/2000/aaai00-061.php. |
[37] | D. Hovland, R. Kontchakov, M.G. Skjæveland, A. Waaler and M. Zakharyaschev, Ontology-based data access to slegge, in: Proceedings, Part II, The Semantic Web – ISWC 2017 – 16th International Semantic Web Conference, Vienna, Austria, October 21–25, 2017, Lecture Notes in Computer Science, Vol. 10588: , Springer, (2017) , pp. 120–129. |
[38] | P. Hu, B. Motik and I. Horrocks, Modular materialisation of datalog programs, in: The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, the Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, the Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, Hawaii, USA, January 27–February 1, 2019, AAAI Press, (2019) , pp. 2859–2866. doi:10.1609/aaai.v33i01.33012859. |
[39] | F. Igne, S. Germano and I. Horrocks, RSAComb: Combined approach for CQ answering in RSA, in: Proceedings of the 34th International Workshop on Description Logics (DL 2021) Part of Bratislava Knowledge September (BAKS 2021), Bratislava, Slovakia, September 19th to 22nd, 2021, M. Homola, V. Ryzhikov and R.A. Schmidt, eds, CEUR Workshop Proceedings, Vols 2954: , CEUR-WS.org, (2021) , http://ceur-ws.org/Vol-2954/paper-18.pdf. |
[40] | F. Igne, S. Germano and I. Horrocks, Computing CQ lower-bounds over OWL 2 through approximation to RSA, in: The Semantic Web – ISWC 2021 – 20th International Semantic Web Conference, ISWC 2021, Proceedings, Virtual Event, October 24–28, 2021, A. Hotho, E. Blomqvist, S. Dietze, A. Fokoue, Y. Ding, P.M. Barnaghi, A. Haller, M. Dragoni and H. Alani, eds, Lecture Notes in Computer Science, Vol. 12922: , Springer, (2021) , pp. 200–216. doi:10.1007/978-3-030-88361-4_12. |
[41] | F. Igne, S. Germano and I. Horrocks, RSAComb – Combined approach for Conjunctive Query answering in RSA, Zenodo, 2022. doi:10.5281/zenodo.6564261. |
[42] | F. Igne, S. Germano and I. Horrocks, ACQuA – A hybrid framework providing a CQ answering service for OWL, Zenodo, 2022. doi:10.5281/zenodo.6564388. |
[43] | F. Igne, S. Germano and I. Horrocks, Benchmarks and scripts for ACQuA and RSAComb, Zenodo ((2022) ). doi:10.5281/zenodo.6564995. |
[44] | E. Kharlamov, D. Hovland, E. Jiménez-Ruiz, D. Lanti, H. Lie, C. Pinkel, M. Rezk, M.G. Skjæveland, E. Thorstensen, G. Xiao, D. Zheleznyakov and I. Horrocks, Ontology based access to exploration data at statoil, in: 11–15, 2015, Proceedings, Part II, The Semantic Web – ISWC 2015 – 14th International Semantic Web Conference, Lecture Notes in Computer Science, Vol. 9367: , Springer, Bethlehem, PA, USA, (2015) , pp. 93–112. |
[45] | I. Kollia and B. Glimm, Optimizing SPARQL query answering over OWL ontologies, Journal of Artificial Intelligence Research 48: ((2013) ), 253–303. doi:10.1613/jair.3872. |
[46] | R. Kontchakov, C. Lutz, D. Toman, F. Wolter and M. Zakharyaschev, The combined approach to query answering in DL-lite, in: Principles of Knowledge Representation and Reasoning: Proceedings of the Twelfth International Conference, KR 2010, Toronto, Ontario, Canada, May 9–13, 2010, AAAI Press, (2010) . |
[47] | R. Kontchakov, C. Lutz, D. Toman, F. Wolter and M. Zakharyaschev, The combined approach to ontology-based data access, in: IJCAI 2011, Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Catalonia, Spain, July 16–22, 2011, T. Walsh, ed., IJCAI/AAAI, (2011) , pp. 2656–2661. doi:10.5591/978-1-57735-516-8/IJCAI11-442. |
[48] | M. Krötzsch, S. Rudolph and P. Hitzler, Conjunctive Queries for a Tractable Fragment of OWL 1.1, 2007, pp. 310–323. ISBN 978-3-540-76297-3. |
[49] | N. Leone, G. Pfeifer, W. Faber, T. Eiter, G. Gottlob, S. Perri and F. Scarcello, The DLV system for knowledge representation and reasoning, ACM Transactions on Computational Logic 7: (3) ((2006) ), 499–562. doi:10.1145/1149114.1149117. |
[50] | C. Lutz, I. Seylan, D. Toman and F. Wolter, The combined approach to OBDA: taming role hierarchies using filters, in: The Semantic Web – ISWC 2013 – 12th International Semantic Web Conference, Proceedings, Part I, Sydney, NSW, Australia, October 21–25, 2013, H. Alani, L. Kagal, A. Fokoue, P. Groth, C. Biemann, J.X. Parreira, L. Aroyo, N.F. Noy, C. Welty and K. Janowicz, eds, Lecture Notes in Computer Science, Vol. 8218: , Springer, (2013) , pp. 314–330. doi:10.1007/978-3-642-41335-3_20. |
[51] | C. Lutz, D. Toman and F. Wolter, Conjunctive query answering in the description logic EL using a relational database system, in: IJCAI 2009, Proceedings of the 21st International Joint Conference on Artificial Intelligence, Pasadena, California, USA, July 11–17, 2009, C. Boutilier, eds, (2009) , pp. 2070–2075, http://ijcai.org/Proceedings/09/Papers/341.pdf. |
[52] | B. McBride, Jena: Implementing the RDF model and syntax specification, in: Proceedings of the Second International Workshop on the Semantic Web – SemWeb’2001, Hongkong, China, May 1, 2001, S. Decker, D.A. Fensel, A.P. Sheth and S. Staab, eds, CEUR Workshop Proceedings, Vols 40: , CEUR-WS.org, (2001) , http://CEUR-WS.org/Vol-40/mcbride.pdf. |
[53] | B. Motik, B.C. Grau, I. Horrocks, Z. Wu, A. Fokoue and C. Lutz, OWL 2 Web Ontology Language Profiles (Second Edition), W3C Recommendation, W3C, 2012, https://www.w3.org/TR/2012/REC-owl2-profiles-20121211/. |
[54] | B. Motik, Y. Nenov, R. Piro and I. Horrocks, Handling owl: SameAs via rewriting, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, Texas, USA, January 25–30, 2015, B. Bonet and S. Koenig, eds, AAAI Press, (2015) , pp. 231–237. |
[55] | B. Motik, Y. Nenov, R. Piro and I. Horrocks, Incremental update of datalog materialisation: The backward/forward algorithm, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, Texas, USA, January 25–30, 2015, B. Bonet and S. Koenig, eds, AAAI Press, (2015) , pp. 1560–1568. |
[56] | B. Motik, Y. Nenov, R. Piro and I. Horrocks, Combining rewriting and incremental materialisation maintenance for datalog programs with equality, in: Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, July 25–31, 2015, Q. Yang and M.J. Wooldridge, eds, AAAI Press, (2015) , pp. 3127–3133. |
[57] | B. Motik, Y. Nenov, R. Piro, I. Horrocks and D. Olteanu, Parallel materialisation of datalog programs in centralised, main-memory RDF systems, in: Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, Québec, Canada, July 27–31, 2014, C.E. Brodley and P. Stone, eds, AAAI Press, (2014) , pp. 129–137. |
[58] | B. Motik, P. Patel-Schneider and B. Parsia, OWL 2 Web Ontology Language Structural Specification and Functional-Style Syntax (Second Edition), W3C Recommendation, W3C, 2012, https://www.w3.org/TR/2012/REC-owl2-syntax-20121211/. |
[59] | B. Motik, R. Shearer and I. Horrocks, Hypertableau reasoning for description logics, Journal of Artificial Intelligence Research 36: ((2009) ), 165–228. doi:10.1613/jair.2811. |
[60] | Y. Nenov, R. Piro, B. Motik, I. Horrocks, Z. Wu and J. Banerjee, RDFox: A highly-scalable RDF store, in: 11–15, 2015, Proceedings, Part II, The Semantic Web – ISWC 2015 – 14th International Semantic Web Conference, M. Arenas, Ó. Corcho, E. Simperl, M. Strohmaier, M. d’Aquin, K. Srinivas, P. Groth, M. Dumontier, J. Heflin, K. Thirunarayan and S. Staab, eds, Lecture Notes in Computer Science, Vol. 9367: , Springer, Bethlehem, PA, USA, (2015) , pp. 3–20. |
[61] | G. Orsi and A. Pieris, Optimizing query answering under ontological constraints, Proceedings of the VLDB Endowment 4: (11) ((2011) ), 1004–1015, http://www.vldb.org/pvldb/vol4/p1004-orsi.pdf. doi:10.14778/3402707.3402737. |
[62] | M. Ortiz and M. Simkus, Reasoning and query answering in description logics, in: Reasoning Web. Semantic Technologies for Advanced Query Answering – 8th International Summer School 2012, Proceedings, Vienna, Austria, September 3–8, 2012, T. Eiter and T. Krennwallner, eds, Lecture Notes in Computer Science, Vol. 7487: , Springer, (2012) , pp. 1–53. doi:10.1007/978-3-642-33158-9_1. |
[63] | J.Z. Pan and E. Thomas, Approximating OWL-DL ontologies, in: Proceedings of the Twenty-Second AAAI Conference on Artificial Intelligence, Vancouver, British Columbia, Canada, July 22–26, 2007, AAAI Press, (2007) , pp. 1434–1439. |
[64] | H. Pérez-Urbina, I. Horrocks and B. Motik, Efficient query answering for OWL 2, in: The Semantic Web – ISWC 2009, 8th International Semantic Web Conference, ISWC 2009, Chantilly, VA, USA, October 25–29, 2009, Proceedings, Lecture Notes in Computer Science, Vol. 5823: , Springer, (2009) , pp. 489–504. doi:10.1007/978-3-642-04930-9_31. |
[65] | H. Pérez-Urbina, B. Motik and I. Horrocks, Tractable query answering and rewriting under description logic constraints, J. Appl. Log. 8: (2) ((2010) ), 186–209. doi:10.1016/j.jal.2009.09.004. |
[66] | A. Poggi, D. Lembo, D. Calvanese, G.D. Giacomo, M. Lenzerini and R. Rosati, Linking data to ontologies, J. Data Semant. 10: ((2008) ), 133–173. doi:10.1007/978-3-540-77688-8_5. |
[67] | Y. Ren, G. Gröner, J. Lemcke, T. Rahmani, A. Friesen, Y. Zhao, J.Z. Pan and S. Staab, Validating process refinement with ontologies, in: Proceedings of the 22nd International Workshop on Description Logics (DL 2009), Oxford, UK, July 27–30, 2009, B.C. Grau, I. Horrocks, B. Motik and U. Sattler, eds, CEUR Workshop Proceedings, Vol. 477: , CEUR-WS.org, http://ceur-ws.org/Vol-477/paper_59.pdf. |
[68] | Y. Ren, J.Z. Pan, I. Guclu and M.J. Kollingbaum, A combined approach to incremental reasoning for EL ontologies, in: Web Reasoning and Rule Systems – 10th International Conference, RR 2016, Aberdeen, UK, September 9–11, 2016, Proceedings, Lecture Notes in Computer Science, Vol. 9898: , Springer, (2016) , pp. 167–183. doi:10.1007/978-3-319-45276-0_13. |
[69] | R. Rosati, On conjunctive query answering in EL, in: Proceedings of the 2007 International Workshop on Description Logics (DL2007), Brixen-Bressanone, Near Bozen-Bolzano, Italy, 8–10 June, 2007, D. Calvanese, E. Franconi, V. Haarslev, D. Lembo, B. Motik, A. Turhan and S. Tessaris, eds, CEUR Workshop Proceedings, Vols 250: , CEUR-WS.org, (2007) , http://ceur-ws.org/Vol-250/paper_83.pdf. |
[70] | B. Selman and H.A. Kautz, Knowledge compilation and theory approximation, Journal of the ACM 43: (2) ((1996) ), 193–224. doi:10.1145/226643.226644. |
[71] | E. Sirin, B. Parsia, B.C. Grau, A. Kalyanpur and Y. Katz, Pellet: A practical OWL-DL reasoner, Journal of Web Semantics 5: (2) ((2007) ), 51–53. doi:10.1016/j.websem.2007.03.004. |
[72] | G. Stefanoni and B. Motik, Answering conjunctive queries over EL knowledge bases with transitive and reflexive roles, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, Texas, USA, January 25–30, 2015, B. Bonet and S. Koenig, eds, AAAI Press, (2015) , pp. 1611–1617, http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/view/9310. |
[73] | G. Stefanoni, B. Motik and I. Horrocks, Introducing nominals to the combined query answering approaches for EL, in: Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, Washington, USA, July 14–18, 2013, M. desJardins and M.L. Littman, eds, AAAI Press, (2013) , http://www.aaai.org/ocs/index.php/AAAI/AAAI13/paper/view/6156. |
[74] | A. Steigmiller and B. Glimm, Absorption-based query entailment checking for expressive description logics, in: Proceedings of the 32nd International Workshop on Description Logics, Oslo, Norway, June 18–21, 2019, M. Simkus and G.E. Weddell, eds, CEUR Workshop Proceedings, Vols 2373: , CEUR-WS.org, (2019) , http://ceur-ws.org/Vol-2373/paper-25.pdf. |
[75] | A. Steigmiller and B. Glimm, Parallelised ABox reasoning and query answering with expressive description logics, in: The Semantic Web – 18th International Conference, ESWC 2021, Virtual Event, Proceedings, June 6–10, 2021, R. Verborgh, K. Hose, H. Paulheim, P. Champin, M. Maleshkova, Ó. Corcho, P. Ristoski and M. Alam, eds, Lecture Notes in Computer Science, Vol. 12731: , Springer, (2021) , pp. 23–39. doi:10.1007/978-3-030-77385-4_2. |
[76] | A. Steigmiller, B. Glimm and T. Liebig, Reasoning with nominal schemas through absorption, Journal of Automated Reasoning 53: (4) ((2014) ), 351–405. doi:10.1007/s10817-014-9310-4. |
[77] | A. Steigmiller, T. Liebig and B. Glimm, Konclude: System description, Journal of Web Semantics (JWS) 27: ((2014) ), 78–85. doi:10.1016/j.websem.2014.06.003. |
[78] | G. Stoilos, Hydrowl: A hybrid query answering system for OWL 2 DL ontologies, in: Web Reasoning and Rule Systems – 8th International Conference, RR 2014, Proceedings, Athens, Greece, September 15–17, 2014, R. Kontchakov and M. Mugnier, eds, Lecture Notes in Computer Science, Vol. 8741: , Springer, (2014) , pp. 230–238. doi:10.1007/978-3-319-11113-1_20. |
[79] | G. Stoilos, Ontology-based data access using rewriting, OWL 2 RL systems and repairing, in: The Semantic Web: Trends and Challenges – 11th International Conference, ESWC 2014, Proceedings, Anissaras, Crete, Greece, May 25–29, 2014, V. Presutti, C. d’Amato, F. Gandon, M. d’Aquin, S. Staab and A. Tordai, eds, Lecture Notes in Computer Science, Vol. 8465: , Springer, (2014) , pp. 317–332. doi:10.1007/978-3-319-07443-6_22. |
[80] | E. Thomas, J.Z. Pan and Y. Ren, TrOWL: Tractable OWL 2 reasoning infrastructure, in: Proceedings, Part II, The Semantic Web: Research and Applications, 7th Extended Semantic Web Conference, ESWC 2010, Heraklion, Crete, Greece, May 30–June 3, 2010, L. Aroyo, G. Antoniou, E. Hyvönen, A. ten Teije, H. Stuckenschmidt, L. Cabral and T. Tudorache, eds, Lecture Notes in Computer Science, Vol. 6089: , Springer, (2010) , pp. 431–435. doi:10.1007/978-3-642-13489-0_38. |
[81] | A.D. Val, First order LUB approximations: Characterization and algorithms, Artif. Intell. 162: (1–2) ((2005) ), 7–48. doi:10.1016/j.artint.2004.01.003. |
[82] | S. Wandelt, R. Möller and M. Wessel, Towards scalable instance retrieval over ontologies, International Journal of Software and Informatics 4: (3) ((2010) ), 201–218, http://www.ijsi.org/ch/reader/view_abstract.aspx?file_no=i59. |
[83] | G. Xiao, D. Calvanese, R. Kontchakov, D. Lembo, A. Poggi, R. Rosati and M. Zakharyaschev, Ontology-based data access: A survey, in: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, July 13–19, 2018, ijcai.org, (2018) , pp. 5511–5519. |
[84] | Y. Zhou, PAGOdA: Pay-as-you-go ontology query answering using a datalog reasoner, PhD thesis, University of Oxford, UK, 2015, https://ethos.bl.uk/OrderDetails.do?uin=uk.bl.ethos.711817. |
[85] | Y. Zhou, B.C. Grau, Y. Nenov, M. Kaminski and I. Horrocks, PAGOdA: Pay-as-you-go ontology query answering using a datalog reasoner, Journal of Artificial Intelligence Research 54: ((2015) ), 309–367. doi:10.1613/jair.4757. |

