



1. Introduction: a typology for locative events
In the last two decades, cross-linguistic variation for the domain of motion events has been amply studied, mainly within the framework of Talmy’s typological distinction between satellite- and verb-framed languages.Footnote 1 In more recent years, some studies have focused on languages that cannot be adequately accounted for in Talmy’s dichotomous typology, mostly suggesting continua accounting for both inter-linguistic and intra-linguistic variations (Ameka & Essegbey, Reference Ameka and Essegbey2013; Berthele, Reference Berthele and Kortmann2004; Ibarretxe-Antuñano, Reference Ibarretxe-Antuñano, Guo, Lieven, Budwig, Ervin-Tripp, Nakamura and Özçaliskan2009; Kopecka, Reference Kopecka, Hickmann and Robert2006; Slobin, Reference Slobin, Strömkvist and Verhoeven2004, Reference Slobin, Ibarretxe-Antunano, Kopecka and Majid2014; Zlatev & David, Reference Zlatev and David2003).
The (by now well-known) variations in lexicalisation patterns that French, English, and Dutch – the three languages considered in the present paper – display in the domain of motion events are illustrated in example (1). Satellite-framed languages, like English and Dutch, encode Path in a satellite, leaving the verb slot free to express a co-event, expressing other aspects of the event, such as cause or manner. Applied to example (1), the event integration realised in the English verb run and its Dutch equivalent rennen can thus be unfolded as in (2). In French, such conflation in a single verb is (usually) not possible, and, if expressed at all, the co-event is to be expressed in a separate phrase (or clause), such as en courant ‘running’ in (1); the main verb expresses the Path.

In the domain of motion, English and Dutch are thus highly similar, framing the core of the motion event (the Path) in a satellite, as opposed to French, which frames the Path in the verb. For the domain of location, things are different, however, even if Talmy himself considers them as similar: “The basic Motion event consists of one object (the FIGURE) moving or located with respect to another object (the reference object or the GROUND)” (Talmy, Reference Talmy2000: 25, our emphasis). As illustrated in example (3), Dutch habitually encodes location via cardinal posture verbs (CPVs; ‘SIT’, ‘LIE’, ‘STAND’) conflating location and orientation of the Figure; French prefers existence verbs like être ‘be’ (omitting the expression of orientation altogether); and English – unlike for motion events – has a marked preference for a French-like pattern using be, but it still retains the possibility to (occasionally) rely on CPVs (e.g., The statue stands in the park or The book was lying on the desk). In other words, as illustrated in example (4), Dutch and, to some extent, English, express the locative event conflating the location of the bottle on the table and manner of location (standing, lying, or sitting position), while French only expresses location and (usually) leaves the WITH-THE-MANNER-OF co-event unexpressed. Importantly, in Dutch, the overt expression of the co-event (via a posture verb) is generally obligatory; using a neutral verb (such as zijn ‘be’) would result in highly reduced idiomaticity (even ungrammaticality), as indicated by the asterisk in example (3c).Footnote 2 In English, ‘manner of location’ is only occasionally expressed and the use of a posture verb often feels “stilted, more literary than colloquial, a little pretentious almost” (Newman, Reference Newman and Newman2002, 9, on stand).

Considering both domains (i.e., motion and location), English could therefore be identified as a split system of conflation, which Talmy defines as “a language [which] can characteristically employ one conflation type for one type of Motion event and characteristically employ a different conflation type for another type of Motion event.” (Talmy, Reference Talmy2000, 64). English would then be expected to behave as a satellite-framed language for motion events (encoding Path in a satellite, e.g., she swam across the river) and as a verb-framed language for locative events (encoding Path in the verb, e.g., the bottle is on the table). However, these split systems are still based on the (locus of) expression of the Path, which is problematic for locative events, as pointed out by Lemmens and Slobin (Reference Lemmens and Slobin2008). They observe that the Talmian focus on the locus of expression of one particular spatial semantic category (i.e., the Path) is not adequate for the location domain, since the Path is invariably expressed by the preposition in French, English, and Dutch (viz., on/sur/op in example (3) above).Footnote 3 The authors therefore suggest a revisited typology, focusing on what is expressed in the verb and draw the distinction between location- versus disposition-framed languages. As illustrated in example (3), French is classified as a location-framed language, since it usually uses the neutral location verb être ‘be’ to express existence or general location. In contrast, as a disposition-framed language, Dutch focuses on the manner of location. Lemmens (Reference Lemmens and Newman2022) suggests that CPVs are to be considered as static equivalents of dynamic manner of motion verbs (e.g., run). As already indicated, not specifying the manner of location leads to unidiomatic phrasing; Dutch and English, even if very close linguistic neighbours, thus reveal remarkable differences in the expression of locative events (see also Van Staden et al., Reference Van Staden, Bowerman, Verhelst, Levinson and Wilkins2006). English has an outspoken preference for expressing location with a neutral verb; the use of a CPV to express the location of an object is, in fact, very infrequent, even if it is still (sometimes) possible, unlike in French.Footnote 4 This incites Dunn et al. (Reference Dunn, Margetts, Meira and Terrill2007, 189) to speak about a “potential positional verb system” for English, as opposed to a “real positional verb system” in Dutch. In that respect, “the emphasis of descriptive detail seems to lie in different areas” (Lemmens, Reference Lemmens and Girard-Gillet2005, 230) as has been observed for motion events as well.
Drawing on the Talmian typology for motion events, Slobin (Reference Slobin, Gumprez and Levinson1996) shows that verb-framed languages generally provide more static scene-settings from which the trajectories (and the manner) of the movement can be inferred. This led Lemmens (Reference Lemmens and Girard-Gillet2005) to suggest a parallel in the domain of locative events in the form of a continuum of Figure-orientedness versus Ground-orientedness. If a language is classified as being disposition-framed, it encodes the position of the Figure and thereby displays a higher focus on the Figure; its lexicalisation patterns gravitate towards the Figure. In contrast, if a language is classified as being more location-framed, it displays a higher focus on the Ground and its lexicalisation patterns gravitate towards the Ground; the position of the Figure is often left unexpressed, the Manner co-event is not of interest to the speaker. The double hypothesis that Lemmens suggests can be summarised as in Fig. 1, visualising the cline going from the habitual expression of manner of location (or orientation) and Figure-orientedness, where Dutch is to be situated, to the other end where French is situated, with no expression of manner of location and maximal Ground-orientedness. English is situated in the middle.

Figure 1. Figure versus Ground-orientation, reproduced from Lemmens (Reference Lemmens and Girard-Gillet2005, 230).
Habitually encoded information may then constitute the most salient aspect of the event to the speaker. Lemmens and Slobin (Reference Lemmens and Slobin2008) talk about “cognitive salience” for the semantic elements that are habitually and preferably encoded (see also Gullberg, Reference Gullberg, Bohnemeyer and Pederson2011a, Reference Gullberg and Pavlenko2011b). This invites the conclusion that the orientation of the Figure would be more salient to a Dutch speaker, both cognitively and visually, because their language pushes them to attend to this systematically. This cognitive impact of language-specific preferences on non-verbal conceptualisation is at the centre of the study reported on here. As such, we situate ourselves in the recent body of studies inspired by event integration theory, which have shown how language-specific preferences in event descriptions do indeed impact attention allocation during event observation, memorisation, and categorisation (see, among others, Berman & Slobin, Reference Berman and Slobin1994; Bosse & Papafragou, Reference Bosse and Papafragou2010, Reference Bosse and Papafragou2018; Bowerman & Choi, Reference Bowerman, Choi, Bowerman and Levinson2001, Reference Bowerman, Choi, Gentner and Goldin-Meadow2003; Choi & Bowerman, Reference Choi and Bowerman1991; Filipović, Reference Filipović2011; Flecken et al., Reference Flecken, Athanasopoulos, Kuipers and Thierry2015; Flecken & Van Bergen, Reference Flecken and Van Bergen2019; Gennari et al., Reference Gennari, Sloman, Malt and Fitch2002; Hickmann, Reference Hickmann, Hickmann and Robert2006; Landau & Jackendoff, Reference Landau and Jackendoff1993; Papafragou & Selimis, Reference Papafragou and Selimis2010; Slobin, Reference Slobin, Gumprez and Levinson1996; for an account of bilinguals and learners, see, among others, Filipović, Reference Filipović2011, Reference Filipović2018). Focusing on the conceptualisation of locative events, Flecken and Van Bergen (Reference Flecken and Van Bergen2019) investigate the cognitive impact of the probabilistic differences in the linguistic encoding of relational information in English and Dutch via a picture-matching task.Footnote 5 In their experimental study, they show participants a succession of paired pictures, one with a prime Figure and the next one with a target Figure, where the target sometimes differs in vertical orientation with respect to the Ground. The prime picture, for example, shows a suitcase lying on a table, the target picture shows it in a ‘standing’ position (“position mismatch”).Footnote 6 Similar to our hypothesis, Flecken & Van Bergen hypothesise that the Dutch participants, because of the higher linguistic probability to encode dispositional nuances overtly in Dutch, would notice the orientational changes more than the English participants. This is, however, not confirmed by their study: the Dutch and the English participants were similarly affected by the orientational changes as observed both in post-perceptual judgements (as measured via the matching task) and perceptual attention (as measured via EEG). The authors attribute this to the fact that English is typologically too close to Dutch, allowing for similar patterns of reasoning in both languages, despite different probabilities with respect to the use of CPVs. The addition of a typologically different language, as we do in our study, including French, where the use of the CPVs to encode the location of inanimate entities is impossible (rather than infrequent as in English), has allowed us to show that the analogical reasoning by English speakers that Flecken & Van Bergen suggest to explain the absence of significant differences between English and Dutch does not hold. This is a point to which we will return in our discussion, where we suggest that the absence of significant differences in their study may be due to verbal interference.
Recently, particular attention has been given to the analysis of the speakers’ visual exploration of motion and locative events confirming that eye-tracking can be regarded as a supplementary, non-invasive live access to patterns of conceptualisation, allowing the researcher to identify those aspects of the event that call for the speaker’s cognitive attention (for a more general perspective, see Holmqvist et al., Reference Holmqvist, Nystrom, Andersson, Dewhurst, Jarodzka and Van de Weijer2015; for motion or placement events see, among others, Flecken et al., Reference Flecken, Gerwien, Carroll and Von Stutterheim2014a, Reference Flecken, Von Stutterheim and Carroll2014b; Hohenstein, Reference Hohenstein2005; Lesuisse, Reference Lesuisse2022a, Reference Lesuisse2022b; Papafragou et al., Reference Papafragou, Hulbert and Trueswell2008; Soroli, Reference Soroli and Botinis2011, Reference Soroli and Botinis2018; Soroli & Hickmann, Reference Soroli, Hickmann, Marotta, Lenci, Meini and Rovai2010; Soroli et al., Reference Soroli, Hickmann, Hendricks, Aurnague and Stosic2019; Trueswell & Papafragou, Reference Trueswell and Papafragou2010).
As we will show, the memorisation performance and eye-gazing analysed in our study confirm a subtle cognitive impact of the linguistic preferences in the domain of location described above (unlike Flecken & Van Bergen, Reference Flecken and Van Bergen2019). In addition, our study shows that location can indeed not be seen as fully in parallel to motion, as it cuts across the typological boundaries and this does not find a satisfactory answer in Talmy’s split systems.
The article is organised as follows. In Section 2, we present our research questions, which will be followed by a description of the methodology (Section 3). Section 4 presents the findings of our experiment, which will be further discussed in Section 5.
2. Research questions and hypotheses
This paper draws on two perspectives to study the cognitive impact of language-specific preferences: (i) the overall sensitivity to orientational features of locative events via the analysis of recognition performance and (ii) the foci of attention via the analysis of the speakers’ eye-movements during memorisation.
The research question for the recognition performance is whether there are any significant differences concerning the aspects of the locative event that are kept in memory by Dutch, English, and French speakers. Given the obligatory encoding of the locative events via the CPVs, the Dutch participants are expected to remember orientational features better than the English and the French participants. The English participants, in turn, are expected to perform better than the French participants, in view of the possibility to encode dispositional details via a CPV, something that is excluded for French. Extending the linguistic analysis in Lemmens (Reference Lemmens and Girard-Gillet2005), our hypothesis is thus that the continuum suggested in Fig. 1 is reflected in a parallel cline of sensitivity to orientational features as reflected in the speakers’ varying ability to memorise orientational details.
The analysis of the eye-movements during memorisation enables us to identify those aspects of the locative event that the Dutch, the English, and the French speakers pay (visual and cognitive) attention to. Our research question is whether the three language groups differ with regard to their foci of attention for the same locative event, in particular those features that pertain to orientation. As detailed below, this will be evaluated through two hypotheses formulated earlier (on lexical semantic Grounds) by Lemmens (Reference Lemmens and Newman2002, Reference Lemmens and Girard-Gillet2005, Reference Lemmens2021), one pertaining to the salience of the base (notably for Dutch) and the other pertaining to the distinction between Figure-orientedness versus Ground-orientedness.
First, in his cognitive semantic analysis of CPVs, Lemmens (Reference Lemmens and Newman2002) describes how the CPVs have become basic location verbs in Dutch that have to be used for the expression of the location of any entity (including inanimate entities). The vertical or horizontal orientation of the entity may play an important part in the choice between notably liggen ‘lie’ and staan ‘stand’, but these orientational dimensions do not exhaustively explain the choice of the verb. Lemmens observes that the presence of a base plays a key role in Dutch for the choice between these two verbs to describe the location of an object (with or without a base). More specifically, if an object is on its base, its canonical placement triggers the use of the Dutch CPV staan ‘stand’. The fact that an entity is resting on its base in fact often overrules its actual (‘real life’) orientation: saliently horizontally extending entities, like a plate, a bed or a car, are nevertheless said to ‘stand’ when they rest on their base. An entity not on its base is typically encoded with liggen ‘lie’ unless the context requires differently (e.g., too salient or relevant vertical orientation; see Lemmens, Reference Lemmens and Newman2002 for a more detailed discussion). Canonical position on a base thus plays an important role for Dutch. Translated to the eye-gazing behaviour, the hypothesis that we therefore set out to verify is that the Dutch participants are expected to focus more on the base of the located object, whereas the French and the English participants are expected to pay more attention to the contact zone of the Figure by looking more quickly and longer at it (given their expected Ground-orientedness). The exploration of this hypothesis via eye-gazing required the definition of three categories of Figures to draw the distinction between the contact zones (i.e., where the Figure meets the Ground) and the inherent base (i.e., the region of the Figure on which the Figure typically rests, if any). The stimuli were thus divided into three categories based on whether the object had a base on which it typically rests (to be functional): (i) On-Base, when the object has a base and rests on it (e.g., a vase standing), (ii) Not-on-Base, when the object has a base but does not rest on it (e.g., a vase on its side), and (iii) Baseless, when the object does not have a base (e.g., a ball). The canonicity of the locative event was assessed via two dimensions, one pertaining to the position of the Figure (related to it being positioned on a base or not) and one pertaining to its placement on a non-canonical Ground, such as a laptop on a bed. The reason for the latter is that such a non-canonical Ground also affects the functionality of the Figure’s placement, which, at least for Dutch, has linguistic implications, a coding with liggen ‘lie’ being common for these cases, even if the Figure is placed on its base. Also, Lemmens and Slobin (Reference Lemmens and Slobin2008) have shown that in elicited locative descriptions, the linguistic distinction between English and Dutch is more blurred for non-canonical events than for canonical events. The methodology section below provides more details on how these two dimensions were defined and how these were subsequently evaluated via eye-tracking.
The second hypothesis that we will evaluate via eye-tracking relates to the Figure- versus Ground-orientedness suggested by Lemmens (Reference Lemmens and Girard-Gillet2005) already described above (see also Fig. 1). One straightforward way in which this hypothesis could be tested is via the analysis of dwell time, that is, the amount of time the participants spend looking at the Figure and at the Ground. The cross-linguistic differences with respect to dwell time have been tested in Lesuisse (Reference Lesuisse2022b) but turned out to be non-significant for a recognition task during which verbalisation was suppressed (the one also considered here): the Dutch, the French, and the English participants all look at the Figure for approximately the same duration and they do not significantly differ with regard to the amount of time they spend looking at the Ground. This led Lesuisse (Reference Lesuisse2022b) to suggest that it may not be the Figure per se that attracts the Dutch participants’ attention but rather the association between the two entities. If this revision of Lesuisse’s hypothesis is correct, it can be expected that Dutch participants would pay more attention to the Figure–Ground association than the English and the French. Translated to eye-gazing, this would mean that they would adopt a more back-and-forth exploration of the locative event manifested in a higher number of revisits; such revisits can be considered as a marker of cognitive interest (Henderson et al., Reference Henderson, Brockmole, Catelhano, Mack, Van Gompel, Fisher, Murray and Hill2007). Section 3 provides more details on how this was tested for eye-tracking.
As should be clear from the above, the analysis of non-verbal memorisation performance and gazing patterns can inform us not only of more refined typological distinctions than suggested in the literature but also of the cognitive impact of these language-specific preferences for locative events. We shall return to this in Section 5.
3. Methodology
3.1. Participants
In total, 187 undergraduate students participated in our experiment: 60 native speakers of French (at the Université de Lille, France), 62 native speakers of Belgian Dutch (at the KU Leuven, Belgium), and 65 native speakers of English (at Kent University, England).Footnote 7 The participants recruited for French and English did not know Dutch.Footnote 8 None of the 187 participants had any known disorders or deficits and they all had normal or corrected-to-normal vision (important for the eye-tracking). A pre-experiment questionnaire enabled us to keep track of which languages they know, their stays abroad, and their study and/or work field. In exchange for course credits (France, England) and cinema tickets (Belgium), all participants took part in a series of three tasks: (i) a non-verbal recognition task, (ii) a describing-matching task, and (iii) a verbal recognition task. This paper will be restricted to the first one, the non-verbal recognition task, described next.Footnote 9 All the (de-identified/anonymised) data are available at the osf.io repository.Footnote 10
3.2. The non-verbal recognition task
The non-verbal recognition task was performed individually by the participant who sat in front of the computer screen. The task was divided into two phases: memorisation and recognition.Footnote 11 During the memorisation task (phase 1), three blocks of 12 different black-and-white pictures showing Playmobil scenes, as shown in Fig. 2, were displayed full screen one after the other in the centre of the screen for 4 seconds each (giving a total of 36 unique items).Footnote 12 During these 4 seconds of memorisation, verbalisation was blocked via an articulation suppression task, which consisted in repeating out loud nonsense strings of three syllables such as BiBaBo, MoMaMi, and DaDiDo (a method inspired by Hickmann et al., Reference Hickmann, Engemann, Soroli, Hendricks, Vincent and Ibarretxe-Antuñano2017). For each stimulus, the participant was assigned a different string of syllables that they were to repeat throughout the 4 seconds.Footnote 13 Such articulation suppression task is commonly used to ensure that inner verbalisation is suppressed and the experiment taps into non-verbal cognition (Hermes-Vazquez et al., Reference Hermes-Vazquez, Spelke and Katsnelson1999; Hickmann et al., Reference Hickmann, Engemann, Soroli, Hendricks, Vincent and Ibarretxe-Antuñano2017; Newton & De Villers, Reference Newton and De Villers2007). The participants were instructed (in their respective languages) to repeat the syllables and to memorise the pictures during 4 seconds and were told that they would have a quiz afterwards.Footnote 14

Figure 2. Example of a stimulus in the memorisation phase.
After each of the three blocks, the participants took a recognition quiz (phase 2). In each recognition quiz, 12 pictures were shown individually on the screen, as in Fig. 3, and the participant had a maximum of 8 seconds to indicate whether they had seen the picture in the memorisation phase or not; they had to do so by gazing at one of the two answer symbols ✓ (‘Yes, I have seen this before’) or ![]() (‘No, I have not seen this before’) for more than 2 seconds.Footnote 15 The participants were given a separate practice item (not included in the experiment) to ensure they knew how to provide their answer via eye-gazing (repeated until successful, if necessary).
(‘No, I have not seen this before’) for more than 2 seconds.Footnote 15 The participants were given a separate practice item (not included in the experiment) to ensure they knew how to provide their answer via eye-gazing (repeated until successful, if necessary).

Figure 3. Example of a stimulus in the recognition phase.
In the quiz, three types of stimuli were shown in random order (to minimise a cross-over effect): (i) one third were Changing Control (CC) items consisting in new pictures they had not seen before for which the participants were to answer ‘No, I have not seen this picture before’ (that is a full mismatch), (ii) one third were Non-Changing Control (NCC) items consisting in old pictures that they had seen before for which the participants were to answer ‘Yes, I have seen this picture before’ (full match), and (iii) one third were Test items (partial match), where the Figure is the same, but its orientation has changed (e.g., lying sack changed to a standing sack as shown in Figs. 2 and 3), and the participants were to answer ‘No, I have not seen this picture before’. It is specifically for this third category that cross-linguistic differences in recognition performance are expected. No differences are expected for the two sets of control items (CC and NCC) as they do not involve orientational changes.Footnote 16
The configurations involving objects without dimensional saliency (blurring the horizontal or vertical orientation feature) were used as fillers and were distributed evenly among the CC items and the NCC items. The three categories of stimuli also presented both canonical and non-canonical Figure–Ground associations (e.g., a jug on a table or a vase on a sofa) as well as canonical and non-canonical positions for the Figure (e.g., a vase standing or a vase lying). Recall that canonicity is looked at from two dimensions: the canonicity of the position of the Figure and the canonicity of the Ground. The canonicity of the Figure is defined as the object resting on its inherent base. Typically, this coincides with its functional position (e.g., a bottle on its base as in Fig. 4) but not necessarily. For example, binoculars may have a typical way in which they are to be held to be functional, but they do not have an inherent base on which they rest (see Fig. 4). The canonicity of the Ground pertains to whether the Ground is typical for the Figure in question (e.g., a bottle on a table rather than on a bed). The degree of canonicity was verified via a questionnaire that consisted in a Google Form with pictures of all the 88 events used in the three tasks. Thirty-nine French participants, recruited in the acquaintance circle of the experimenter, filled in the online questionnaire (28 women, 11 men) and assigned a score on a Likert scale from 1 to 5 to each picture depending on the normality (canonicity, score 1) or weirdness (non-canonicity, score 5) of the depicted event. The pictures were presented in a random order, differing for each participant. The responses were subsequently analysed in R, using the psych (Revelle, Reference Revelle2018) and Likert (Bryer & Speerschneider, Reference Bryer and Speerschneider2016) packages. Based on the median resulting from this questionnaire, we established the degree of canonicity of the events as assessed by (French) speakers. If an event had a median of 4 or 5, it was classified as non-canonical. If it had a median of 1 or 2, it was classified as canonical. If it had a median of 3, the mean was taken as a criterion to decide on the classification; it was considered non-canonical if the mean score was higher than 2.5. This allows us to measure the impact of event canonicity on recognition performance and attention allocation. For the 12 Test items, the division between canonical and non-canonical Ground was balanced (6 canonical and 6 non-canonical) as was the one for the canonicity of the Figure (4 baseless, 4 on-base, and 4 not-on-base). The number of non-canonical events was also balanced out between the memorisation and the recognition phase.

Figure 4. Contact zone and inherent base of the Figures for the three categories defined: On-Base (Left), Not-On-base (Middle), and Baseless (Right).
The following measures were recorded: the recognition answers (right or wrong), the eye-movements during the memorisation phase, the eye-movements during the recognition phase, and the reaction times. The discussion in this paper will be limited to recognition answers and eye-movements during the memorisation phase (4 seconds of viewing).Footnote 17 The latter restriction is justified by the fact that full apprehension of the stimulus is better appreciated in the memorisation phase (Holmqvist et al., Reference Holmqvist, Nystrom, Andersson, Dewhurst, Jarodzka and Van de Weijer2015 ). In addition, in the recognition phase, one quick glance could be enough to provide an answer (Biederman et al., Reference Biederman, Mezzanotte and Rabinowitz1982; Potter, Reference Potter and Coltheart1999; Schyns & Oliva, Reference Schyns and Oliva1994; Thorpe et al., Reference Thorpe, Fize and Marlot1996), which would not be informative with respect to our research questions.
3.3. Eye-tracking
The computer screen was equipped with a screen-based RED250 eye-tracker system. The rolling-out of the pictures was done automatically via SMI Experiment Centre coupled with SMI BeGaze. As explained above, two eye-tracking hypotheses were tested: (i) the salience of the base and (ii) the Figure versus Ground-orientedness. Each hypothesis required the definition of different areas of interest (AOIs) in BeGaze for the analyses to be run.
For the first hypothesis, the definition of the base AOI(s) resulted from the first classification of the stimuli into three categories: On-base, Not-on-base, and Baseless. For the On-base category, as illustrated on Fig. 4 (left frame), one AOI was defined, which corresponds to both the contact zone and the inherent base of the Figure. For the Not-on-base category, two AOIs were defined, one on the contact zone and one on the inherent base (see Fig. 4, middle frame). For the Baseless category, one AOI was defined around the contact zone (see Fig. 4, right frame). For each category, analyses were run on entry time and dwell time to measure prioritisation and preferences across languages.
For the second eye-tracking hypothesis, that is, Figure- versus Ground-orientedness, two AOIs were defined, one around the Figure and another around the Ground; we then checked the extent to which participants look again at an AOI they have already visited. A higher rate of such revisits points at a back-and-forth exploration of the scene and therefore some cognitive interest for the Figure–Ground relationship. A lower rate or absence of revisits suggests a more sequential exploration of the scene where AOIs are visited once, one after the other.
4. Analyses and results
4.1. Recognition performance: overall sensitivity to orientational features
According to our expectations, all participants should perform better on the Control items (NCC, CC) than on the Test items because there is no ambiguity: either the item is completely new (full mismatch) or it is completely the same (full match). In contrast, the Test items show the same Figure and the same Ground but in a different configuration (partial match), which may introduce some ambiguity (“Yes, I’ve seen this before but not in this orientation”). Secondly, we expect the Dutch participants, and to some extent the English participants, to notice orientational changes (on the Test items) more than the French participants. Both expectations seem to be confirmed as illustrated in Fig. 5 and Table 1.

Figure 5. Boxplots of the recognition performance for each language group on CC, NCC, and Test items (Whiskers indicate minimum and maximum values).
All participants across the language groups remember the CC and NCC items better than the Test items. Despite a slightly lower performance of the English group on the CC and the NCC items compared to the two other groups, the median for CC items is over 75.0% of correct rejections and over 91.7% hits for NCC items for the three language groups (Table 1).
Table 1. Number and proportions of correct answers by category for each language group in the non-verbal recognition task
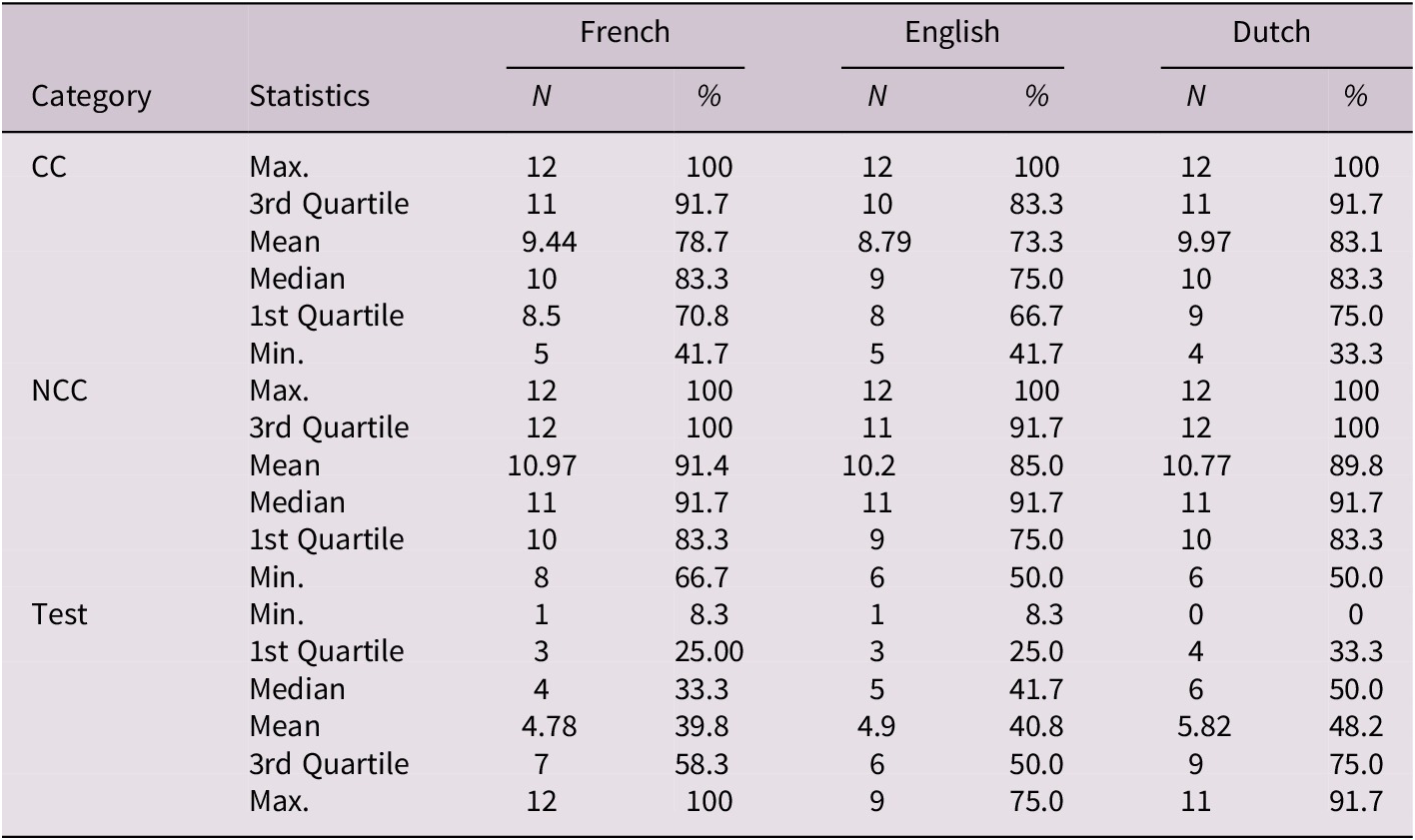
These observed tendencies are tested statistically via a binomial mixed-effect logistic regression (glmerlme4 package, Bates et al., Reference Bates, Maechler, Bolker and Walker2015), which predicts the Correctness of the recognition answer (correct, incorrect) as the response to two predictorsFootnote 18: the Language (Dutch, English, French) and the Stimulus Category (CC, NCC, Test). The model, presented in Table 2, returns a significant effect of both the Language and the Category predictors (respectively, X2LR(2) = 17.01, p = 0.0002 and X2LR(2) = 42.63, p = 5.518e-10). Emmeans pairwise comparisons with Bonferroni correctionFootnote 19 show that, for the three languages groups individually, there is no significant difference between the participants’ performance on the CC and the NCC items while there is one between the CC and the Test items (Dutch: z.ratio = −6.57, p < 0.0001; English: z.ratio = −6.57, p < 0.0001; French: z.ratio = −6.57, p < 0.0001) and between the NCC and the Test items (Dutch: z.ratio = −8.63, p < 0.0001, English: z.ratio = −8.63, p < 0.0001; French: z.ratio = −8.63, p < 0.0001). In other words, the participants, irrespectively of their language, give more incorrect answers to the Test items, as observed above already. As for the cross-linguistic differences on each stimulus category, the emmeans pairwise comparisons partially confirm the observed tendencies: the French performance on the control items does not differ significantly from the Dutch and the English performances; the English participants, however, give significantly more incorrect answers for the NCC and the CC items compared to the Dutch participants (NCC: z.ratio = −4.21, p = 0.0009, CC: z.ratio = −4.21, p = 0.0009). We do not have an immediate explanation for this at this stage; however, upon closer inspection of the data, three stimuli seem to trigger difficulties for the English speakers and each of these involve a change of the Ground only, the Figure remaining the same. This deserves a study on its own but is less relevant for the present study which looks at changes in the orientation of the Figure.
Table 2. Modelling the recognition performance for the Control and the Test items

As for the Test items, they appear to be a more challenging stimuli category for the three language groups alike, as shown above. The remainder of this section will focus on the Test items only, as they are the ones that are relevant to our hypotheses. To assess our hypotheses statistically, we set up a binomial mixed-effect logistic regression (glmer(), lme4 package, Bates et al., Reference Bates, Maechler, Bolker and Walker2015), which predicts the Correctness of the recognition answer for the Test items (correct, incorrect) as the response to four predictorsFootnote 20: Language (Dutch, English, and French), Position (Baseless, Canonical Position, Non-Canonical Position), Ground (Canonical Ground, Non-Canonical Ground), and Series (1, 2, 3). The Series predictor allows us to evaluate whether, as the experiment unfolds, the participants become better (due to practice) or worse (due to fatigue) at the task. Two random effects are added with a varying intercept on Participant and on Stimulus. The model output is presented in Table 3.
Table 3. Modelling the recognition performance for Test items

The model returns a significant effect for the Language predictor (X2LR(2) = 6.1231, p = 0.046). Turning the log odds estimates to probabilities reveals that the Dutch participants have a 47.3% probability of being incorrect (plogis (intercept)), the English participants 55.7% probability (plogis (intercept+0.34)), and the French participants 57.0% (plogis (intercept+0.39)). This suggests a confirmation of the expected cline where the French participants are more likely than the English participants to give incorrect answers to the Test items, and the English participants, in turn, are more likely than the Dutch participants to give incorrect answers to the Test items. Put differently, the Dutch participants (on the one end) seem to outperform the French participants (on the other end) and the English participants straddle the middle, as was already indicated by the box plot in Fig. 5. However, the cline itself does not reach statistical significance. Emmeans pairwise comparisons with Bonferroni correction reveal no statistically significant difference despite a trend whereby the French and the Dutch groups differ (z.ratio = −2.29, p = 0.06). The difference between the Dutch and the English group as well as the difference between the French group and the English group do not reach statistical significance (respectively, z.ratio = −1.99, p = 0.14 and z.ratio = −0.06, p = 1). This could be explained by the fact that the performance of the English group on the Test items, apparently situated between the performance of the Dutch and of the French groups, does not vary enough from the other two to reach statistical significance. The model does not identify any significant effect for the Series, Position, and Ground predictors.
In sum, irrespective of the event canonicity or the unfolding of the experiment, there is a global language effect where the Dutch participants do seem to be more sensitive to orientational changes than the English participants, who, in turn, seem to be more sensitive to such changes than the French participants. This invites the conclusion that during the memorisation phase with blocked inner verbalisation, attention to the disposition of the Figure in relation to the Ground is different across languages.
4.2. Eye-movements: foci of attention
4.2.1. Salience of the base
According to our hypotheses, the Dutch participants are expected to look more quickly and longer at the inherent base of the Figure, whereas the French and the English participants are expected to pay more attention to the contact zone of the Figure by looking more quickly and longer at it. In order to distinguish between the inherent base of the Figure and its contact zone with the Ground, the stimuli were grouped in three categories (On-base, Not-on-base, Baseless), which are discussed in turn in the remainder of this section.
4.2.1.1. On-base
When the Figure is in a canonical position on its base (e.g., a vase standing on a table), the Dutch participants are indeed more likely to visit the base of the Figure (67.3%) compared to the French (63.1%) and the English participants (58.8%). This cross-linguistic difference is also reflected on entry time and dwell time in the base AOI.
A first lmer linear mixed-effect regression is modelled on entry time as the response variable to three predictors: Language (Dutch, English, French), Ground (Canonical, Non-Canonical), and Series (1, 2, 3), with (1|Participant, 1|Stimulus) as random variables.Footnote 21 This model identifies the statistically significant effect of the Language predictor (X2LR(2) = 7.53, p = 0.02) and shows that the Dutch participants enter the base more quickly than the English participants (t.ratio = −220.6; p = 0.03). The average entry time for French stands in between the two other language groups and does not differ significantly. The model finds a significant Series effect (X2LR(2) = 10.06, p = 0.007). Emmeans pairwise comparisons show that overall, the participants enter the base zone more quickly from the second to the third series (t.ratio = 3.12, p = 0.02). No relevant effect is found for the Ground predictor. What comes up from this first analysis is that the Dutch participants tend to prioritise the base AOI compared to the English and the French participants despite an increasing interest for the base as the experiment unfolds (as indicated by the series effect).
Similar findings are obtained for the analysis of the dwell time in the base AOI: the English participants spend less time than the Dutch participants looking at the base AOI (respectively, 475 ms versus 622 ms, and 615 ms for French), and the Dutch and the French participants do not differ drastically. We set up a second linear mixed-effect regression with dwell time in the base zone as the response variable to three predictors: Language (Dutch, English, French), Ground (Canonical, Non-Canonical), and Series (1, 2, 3), with (1|Participant, 1|Stimulus) as random variables.Footnote 22 This model confirms a Language effect (X2LR(2) = 8.02, p = 0.01) with a statistically significant difference between English and Dutch (t.ratio = 2.529, p = .04) and English and French (t.ratio = −2.40, p = 0.05). This is unexpected but could be explained by the fact that on average the English participants look 260 ms less at the Figure than both the French and the Dutch participants for reasons that at this point remain unclear. The model also finds a significant Series effect (X2LR(2) = 6.82, p = 0.03) and a significant effect of the Ground predictor (X2LR(1) = 5.74, p = 0.02). When the Ground is non-canonical, the base is looked at longer, across the three language groups, a finding we shall return to later in this paper. The significant series effect remains difficult to interpret given that on average the participants spend less time looking at the base in the second series than in the first and more time in the third series (Series 1: 488 ms, Series 2: 442 ms, Series 3: 560 ms) – a finding that echoes the fact that they enter the base AOI more quickly in the third series.
The findings for the on-base category indicate that the English participants look at the base later, for a shorter period of time compared to the Dutch and the French participants who, in contrast, both seem interested in the base zone. However, the fact that the English participants seem to disfavour the base AOI may well be the result of the fact that they look less at the Figure overall (see Lesuisse, Reference Lesuisse2022b).
4.2.1.2. Not-on-base
When the Figure is in a non-canonical position, not on its base (e.g., a vase lying on a table), there is a dissociation between the contact zone and the inherent base; it is of interest to check whether the Dutch and the French participants are attracted by either the inherent base or the contact zone. This is gauged via the entry time to the AOI and the dwell time in the AOI.
A first linear mixed-effect regression analysis models the entry time as a response to Language (Dutch, English, French) * AOI (inherent base, contact zone), Ground (Canonical, Non-Canonical), and Series (1, 2, 3) with two random variables (1|Participant, 1|Stimulus).Footnote 23 The model confirms a Language * AOI interaction (X2LR(2) = 10.64, p = 0.005): overall, the three language groups hit the contact zone more quickly than the inherent base, which is estimated to be hit after 1300 ms. Nevertheless, the Dutch group hits the inherent base more quickly than the French group; the difference with the English group is not statistically significant. Ground is also statistically significant (X2LR(1) = 7.17, p = 0.007): the participants orient their gaze more quickly to the Figure (both in the base and contact AOIs) when the Ground is canonical. No Series effect is retrieved. In sum, the Dutch and the French participants are not attracted to the same base: even if the contact zone is of higher interest for all participants, the French participants turn their attention more quickly to this contact zone; the Dutch participants, more quickly to the object’s inherent base than the French and the English participants.
However, these preferences in prioritisation of (visual) attention are not reflected in the amount of time the participants spend looking at the contact zone or the inherent base AOIs. A linear mixed-effect model with dwell time as the response to Language (Dutch, English, French) * AOI (inherent base, contact zone), Ground (Canonical, Non-Canonical), and Series (1, 2, 3) with two random variables (1|Participant, 1|Stimulus)Footnote 24 does not reveal a Language * AOI interaction but a separate Language (X2LR(2) = 8.77, p = 0.01) and an AOI effect (X2LR(1) = 114.23, p < 2.2e-16). Emmeans pairwise comparisons with Bonferroni correction show that all participants look longer at the contact zone than at the object’s inherent base (Dutch: t.ratio = 7.92, p < 0.0001; English: t.ratio = 4.62, p < 0.0001; French: t.ratio = 6.57, p < 0.0001). Also, the English participants look at the contact zone for a shorter amount of time, which is significantly different compared to the Dutch (t-ratio = 3.55, p = 0.006) but not compared to the French speakers (N.S.). No Series effect is found but a Ground effect (X2LR(1) = 16.32, p = 5.354e-05) reveals a higher dwell time in both zones when the Ground is canonical in line with previous findings.
4.2.1.3. Baseless
The baseless category works as a reference category for which our language groups should not differ, since they should in those cases all be attracted to the contact zone to the same degree. The model on the entry time indeed shows no significant effect of Language, Ground, or Series even if the English participants seem to look later at the base.Footnote 25 The model on dwell time does not reveal a significant cross-linguistic difference (for the Language predictor) either.Footnote 26 No Ground and Series effect are found.
In sum, our analyses of the visual attention paid to the relevant parts of the Figure show that the Dutch participants focus significantly more than the English and the French participants on the inherent base for Figures on their base, but also focus on it when the Figure is not on its base. No interlanguage differences are found for baseless Figures.
4.2.2. Figure-versus Ground-orientedness
Our second eye-tracking hypothesis relates to the Figure- and Ground-orientedness, yet not in its original form as suggested by Lemmens (Reference Lemmens and Girard-Gillet2005) – which was not confirmed by the earlier analysis of the dwell time – but in its revised version given above, which evaluates the visual attention to the Figure–Ground association (rather than the Figure per se); we hypothesise that this would be reflected in a higher number of revisits. To identify any cross-linguistic differences with regard to the number of revisits, we set up a cumulative link mixed-effect model with the number of revisits as the response variable (clmm, Christensen, Reference Christensen2019) to five predictors: AOI (Figure, Ground) * Language (Dutch, English, French), Position (Canonical, Non-Canonical, Baseless), Ground (Canonical, Non-Canonical), and Series (1, 2, 3). The model also included random intercepts on Participant and Stimulus.Footnote 27 The model returns a significant effect for the interaction AOI * Language (X2LR(2) = 7.3, p = 0.02). Emmeans pairwise comparisons with Bonferroni correction show that there are more revisits on the Figure than on the Ground (Dutch: t.ratio = 20.26, p < 0.0001; English: t.ratio = 17.38, p < 0.0001; French: t.ratio = 21.75, p < 0.0001). However, while the descriptive statistics indicate that there are more revisits for both AOIs in Dutch (Figure: 1.62, Ground: 1.38) than in English (Figure: 1.58, Ground: 1.38) than in French (Figure: 1.39, Ground: 1.19), this finding does not reach statistical significance – probably because of the Bonferroni correction that has been applied.Footnote 28 The strong tendency for the Dutch and the English participants to revisit both AOIs more often does indicate, to some extent, a back-and-forth strategy in English and in Dutch. In contrast, the visual exploration of the French participants seems more sequential with fewer revisits overall. The model does not show any effect for the three other predictors (Position, Ground, or Series).
In sum, the global (significant) finding indicates that the Dutch and the English participants do tend to revisit both the Figure and the Ground AOIs (and not just the Figure AOI) more often than the French participants. While not confirmed in the pairwise comparisons, this finding suggests two possible distinct behavioural profiles with, on the one hand, a very sequential exploration of the scene for the French participants (with a low number of revisits), and on the other hand, a back-and-forth exploration of the Figure–Ground configuration for the Dutch and to some extent the English participants. The latter finding further suggests that it is not just the Figure per se that is salient for Dutch speakers (and to a lesser extent for the English speakers), but the association of the Figure and the Ground. This will be discussed further in the next section.
5. Discussion
When speakers of Dutch, English, and French are asked to memorise locative scenes for a later recognition test (“Have you seen this?”) in a context where language production (including possible internal verbalisation) is suppressed via an interference task, differences show up between the language groups in the recognition performances and in the eye-movements that were recorded during the memorisation.
Our findings confirm a statistically significant global effect of the language factor on the recognition performance. Cross-linguistic comparisons show a trend where Dutch speakers outperform both English and French speakers when it comes to accuracy of response throughout the task (i.e., across the different series, across canonical and non-canonical Figure–Ground associations, and across canonically or non-canonically oriented Figures). This suggests that Dutch speakers are indeed more sensitive to orientational differences that are habitually encoded in their language, notably via the opposition between liggen ‘lie’ and staan ‘staan’, which are the dimensions tested here.Footnote 29 French and English speakers are less triggered by their language patterns to pay attention to such orientational variations, but the English still outperform the French. Pairwise comparisons have, however, not replicated the statistical significance, most likely because of the fact that the effects remain quite subtle overall. In sum, the recognition results lend moderate support to the typological continuum that was suggested above (see Fig. 1) but also to the overall cognitive impact of these different linguistic preferences on the mental representation of locative events, as further confirmed by the eye-tracking analysis. Even if the effects for the recognition task may not be dramatic, there is still a difference that shows up in a condition where (internal) verbalisation is suppressed.Footnote 30
The study of eye-movements has allowed us to evaluate whether the speakers of the three languages look at different aspects of the locative scene, again with the understanding that the gazing behaviour is influenced by the habitual linguistic encoding. More specifically, two main hypotheses have been evaluated experimentally in this study. First, building on the semantic analyses presented in Lemmens (Reference Lemmens and Newman2002, Reference Lemmens2021), the expectation is that Dutch speakers would have a stronger visual focus on the inherent base of the Figure, given that this is key in the choice between staan ‘stand’ (entity on its base) and liggen ‘lie’ (entity not on its base). Secondly, revising Lemmens’ (Reference Lemmens and Girard-Gillet2005) original hypothesis concerning Figure-orientedness versus Ground-orientedness, we have evaluated whether there is a difference in the number of revisits on the Figure and the Ground to obtain a more nuanced view on the attention paid to either the Figure or the Ground, or both.
The findings do confirm a cross-linguistically different eye-gazing behaviour. The first hypothesis is statistically confirmed: Dutch speakers do focus more on the inherent base of an entity if it has one (even when it is not on its base). This confirms that the base is indeed key to the representation of orientation (as codable by either staan ‘stand’ or liggen ‘lie’). Concerning the Figure- and Ground-orientedness, the analysis of revisits confirms the earlier analysis of the dwell time (Lesuisse, Reference Lesuisse2022b) that it is not a mere focus on the Figure or the Ground per se that is at issue here. More specifically, both the Dutch and the English speakers display a strong tendency to revisit both the Figure and the Ground AOIs more often than the French participants. This confirms that it is the association of the Figure to the Ground that is relevant. In fact, this opens the door to a partial reinterpretation of the findings with respect to the visual attention to the base, at least for those Figures in canonical position resting on their base. In a locative event where a Figure is resting on its base on the Ground, it is not possible to distinguish between the (visual area) of the inherent base and that of the contact zone (part of Ground). In other words, it cannot be excluded with absolute certainty that the base AOI does not include the Ground as well, which would reinforce the finding that it is not just the Figure that is in focus, as suggested by Lemmens (Reference Lemmens and Girard-Gillet2005), but rather the association between the Figure and the Ground that is crucial. (Note that this does not invalidate the visual salience of the base evaluated in the first hypothesis which is confirmed statistically.) This important nuance to Lemmens’ (Reference Lemmens and Girard-Gillet2005) hypothesis does, however, find a linguistic underpinning in the contrast between absolute (= postural) and locative use. The absolute use of CPVs is when they occur without a locative complement, as in She does not stand, she sits or after many attempts, the pole finally stood (upright). In these uses, the posture verbs foreGround mere posture or orientation. It is only when a locative phrase is added that they extend to a (construction-induced) use which expresses both posture and location. The difference can graphically be represented as in Fig. 6, with the absolute postural use on the left (omitting the Ground from the conceptualisation) and the locational use on the right, which in addition to the posture also profiles the Ground as part of the conceptualisation. For inanimate entities, it is not the posture but rather the combination of the orientation and the (inherent) base that plays an important role, as observed above.

Figure 6. Postural (left) versus locational use (right).
In the experiment at hand, all scenes are locative scenes that visually foreGround the location of the Figure vis-à-vis the Ground, the two only items shown against a neutral, grey backGround. In other words, for the Dutch (and to a lesser extent the English) speakers, it is the relationship between the Figure and the Ground, which is central in the mental representation of the event. Unlike what is suggested by Lemmens (Reference Lemmens and Girard-Gillet2005), it does thus not seem to be a ‘pure’ Figure-orientation as such that is at issue, but rather a focus on the Figure/Ground relationship. In a verbal context, focusing on this relationship makes sense for the Dutch speakers, since the choice of the CPV for inanimate entities does not pertain exclusively to the Figure’s position but rather to its relation to the Ground (canonical or not). In English, such locative uses are also still possible even if rare.Footnote 31 This interpretation meshes nicely with our findings regarding the higher number of revisits in Dutch (and in English), which further highlights a focus on the Figure–Ground interaction. Such a focus is quite absent with the French speakers, which lines up with the impossibility of locative uses with inanimate entities for posture verbs in French.
The overall intermediate position of English raises the question of its typological position.Footnote 32 As indicated in the introduction, its ambivalent position could be explained by considering English as having a split system: it is more satellite-framed for motion events, but more verb-framed (like French) for locative events. However, the intermediate position does not neatly align with these two domains, but manifests itself within the locative domain, where English sometimes behaves more like French, but sometimes more like Dutch. This oscillating behaviour is statistically confirmed by the eye-gazing behaviour, which lines up with the trend observed in the recognition results. The intermediate position of English has been said to align with the equally ‘intermediate’ use of posture verbs in English. However, from a cognitive point of view, this explanation remains somewhat unsatisfactory, as it does not really explain the underlying cognitive trigger or motivation. One plausible explanation (still to be explored further) may reside in the semantics underlying the use of the posture verbs in English, notably as opposed to that in Dutch. In English, even if less frequent, the verbs lie and stand can still be used in reference to the location of inanimate entities; these usages seem to be motivated primarily by ‘pure’ orientational features. In other words, the dimensions of verticality and horizontality are much more important for English than they are for Dutch where, as observed above, these dimensions can be overruled by the presence of a base (and possibly the notion of functionality that often is associated with a position on its base). While the stimuli presented in the experiment clearly show orientational changes, these may not always be sufficiently salient to the English speakers to trigger any cognitive reflexes. Dutch speakers, on the other hand, are constantly engaged in an orientational focus on the locative scene, as they have to Figure out how the Figure’s base relates to the Ground.
Strikingly, the Dutch-like gazing behaviour of the English speakers is even stronger in the verbal condition of the memorisation experiment. This condition has not been discussed here (see Lesuisse, Reference Lesuisse2022a, Reference Lesuisse2022b), but the gist of the findings is that even though, overall, the English speak in a French-like manner (using the neutral verb be), their gazing behaviour in the verbal condition lines up even more with that of the Dutch than in the non-verbal condition. This suggests that, despite CPVs being uncommon in English in the verbalisations recorded during the experiment (as expected), the mobilisation of language suffices to trigger overall increased awareness, regardless of whether this language overall contains orientation-specific expressions. Flecken and Van Bergen (Reference Flecken and Van Bergen2019) draw on such underlying ‘linguistic triggering’ to explain the absence of effect between English and Dutch speakers in their study. More specifically, they suggest that the possibility in English of using the CPVs in reference to animate entities (e.g., A woman was sitting on a chair) may suffice to trigger orientational sensitivity also in the domain of inanimate entities. In other words, they argue that this sensitivity of the English speakers is based on the analogy that they draw between the use of CPVs for animate Figures and inanimate Figures. However, our findings cast doubt on this explanation because one would then expect French speakers to draw that analogy as well since in French CPVs can also be used in reference to animate Figures. Our study shows that French speakers do not make such an analogy, so it is unlikely to assume that English speakers would do this on this very same basis. As we see it, the important issue does not concern a possible parallel between animate or inanimate Figures, but the use of CPVs for just inanimate entities, which is still possible in English to some degree (e.g., The statue was standing in the park), but absolutely not in French. In other words, the probabilistic versus categorical approach by Flecken & Van Bergen is correct overall (also in line with the continuum that we have found), but the absence in their study of any effect of language on potential sensitivity to orientation (as reflected in recognition) may have to do with the (inner) verbalisation, which is not suppressed in their study. In our study, there is suppression of such potential verbalisation. Even if the effect of language in our study remains subtle, we feel justified in seeing it as a linguistic watermark leaving a modest trace on cognition. The difference in the behaviour of the English participants between the verbal and the non-verbal conditions in our larger study (summarised above; see Lesuisse, Reference Lesuisse2022a, Reference Lesuisse2022b) corroborates such an influence of language and suggests that internal verbalisation may be an important factor here.
Our study globally situates English in between French and Dutch, both for memorisation and eye-gazing. Why this is so still remains a question to be explored further, in particular via more fine-grained analysis of the individual alignments of particular types of verbalisations with particular types of eye-gazing behaviour. At this stage, such an analysis is not possible with the current data set, but is planned for the future.
Several conclusions can be drawn from the experimental study reported in this paper. First, Lemmens’ semantic analysis of Dutch posture verbs has been confirmed on a cognitive level. More specifically, our study has confirmed the cognitive salience of the base underlying the use of Dutch staan ‘stand’. The findings also confirm the Figure-orientedness of Dutch (and to a lesser extent of English), at least in its revised interpretation as representing a focus on the association between the Figure and the Ground (rather than an exclusive focus on the Figure per se). The latter finds a linguistic reflection in the fact that the locational use of posture verbs is constructionally induced via the addition of a locative phrase. When it comes to the larger typological perspective, our study has confirmed the cline of Manner-of-location with Dutch on one end (habitual expression of manner of location, via posture verbs) and French on the other (absence of expression of manner of location), and English situated in between. As the intermediate position of English manifests itself within the domain of location, it cannot satisfactorily be explained by Talmy’s idea of a split system. While the results of the recognition task remain subtle, taken together with the eye-gazing results, they do reveal some influence of language on the conceptualisation of location in a non-verbal task which, in our view, deserves further scientific consideration.
Data availability statement
All the (deidentified/anonymised) data as well as the R-scripts are available at the osf.io repository (https://osf.io/m426b/?view_only=03c5ff99993246859dfe162388d9aa99).
Appendix
Table A.1. Modelling the entry time in the base AOI for the On-Base category

Table A.2. Modelling the dwell time in the base AOI for the On-Base category

Table A.3. Modelling the entry time in the base AOI for the Not-On-Base category

Table A.4. Modelling the dwell time in the base AOI for the Not-On-Base category

Table A.5. Modelling the entry time in the base AOI for the Baseless category
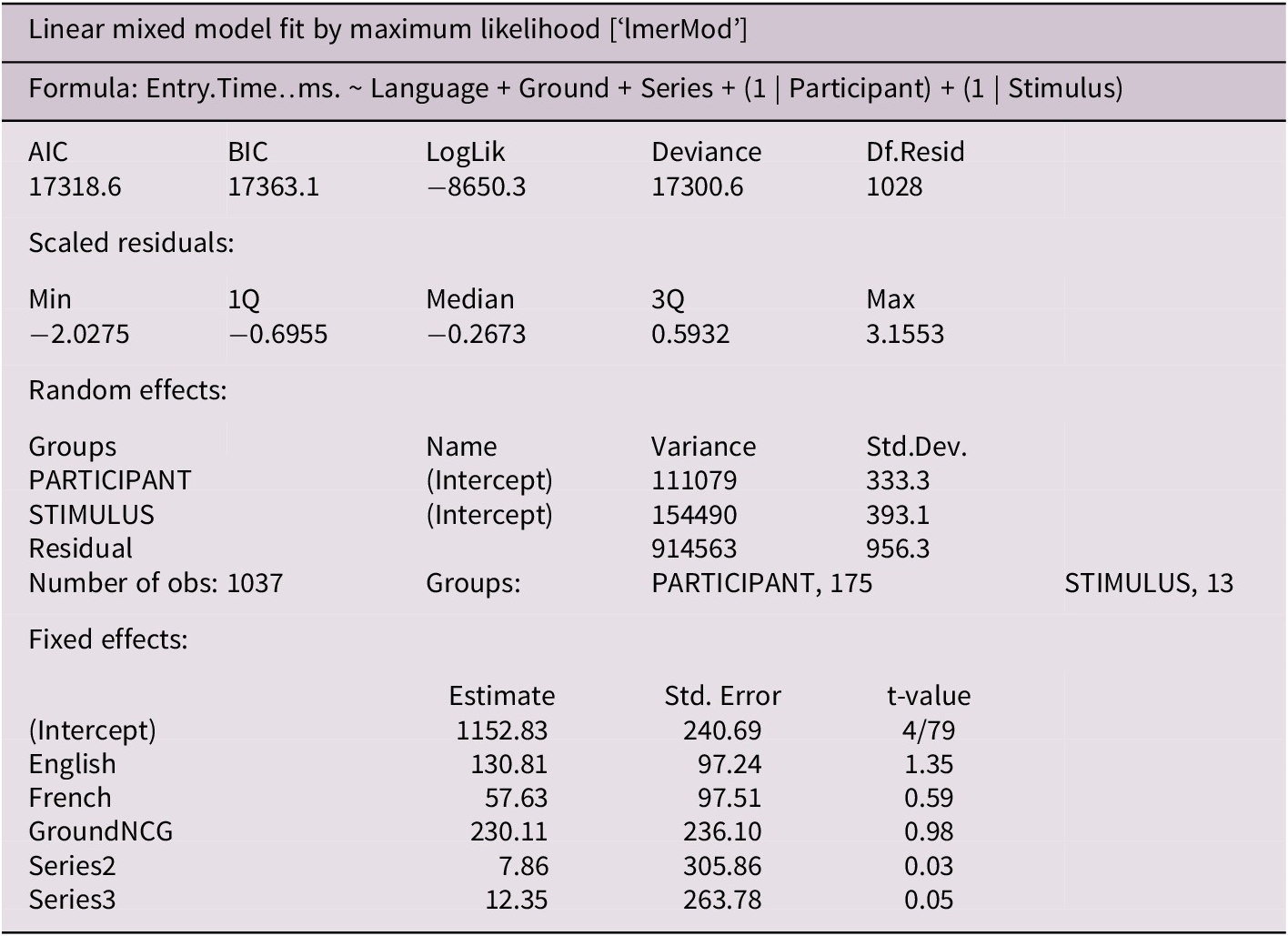
Table A.6. Modelling the dwell time in the base AOI for the Baseless category

Table A.7. Modelling the number of revisits in the Figure and the Grounds AOIs


















 Open access
Open access