
Abstract
We develop an inexact primal-dual first-order smoothing framework to solve a class of non-bilinear saddle point problems with primal strong convexity. Compared with existing methods, our framework yields a significant improvement over the primal oracle complexity, while it has competitive dual oracle complexity. In addition, we consider the situation where the primal-dual coupling term has a large number of component functions. To efficiently handle this situation, we develop a randomized version of our smoothing framework, which allows the primal and dual sub-problems in each iteration to be inexactly solved by randomized algorithms in expectation. The convergence of this framework is analyzed both in expectation and with high probability. In terms of the primal and dual oracle complexities, this framework significantly improves over its deterministic counterpart. As an important application, we adapt both frameworks for solving convex optimization problems with many functional constraints. To obtain an \(\varepsilon \)-optimal and \(\varepsilon \)-feasible solution, both frameworks achieve the best-known oracle complexities.


Similar content being viewed by others
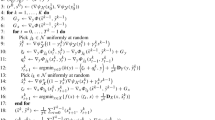

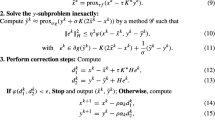
Data Availability Statement
The manuscript has no associated data.
References
Bauschke, H.H., Borwein, J.M., Combettes, P.L.: Essential smoothness, essential strict convexity, and Legendre functions in Banach spaces. Commun. Contemp. Math. 3(4), 615–647 (2001)
Beck, A.: First-Order Methods in Optimization. Society for Industrial and Applied Mathematics (2017)
Bertsekas, D.P.: Nonlinear Programming. Athena Scientific (1999)
Boyd, S., Vandenberghe, L.: Convex Optimization. Cambridge University Press (2004)
Chambolle, A., Pock, T.: On the ergodic convergence rates of a first-order primal-dual algorithm. Math. Program. 159(1), 253–287 (2016)
Chen, Y., Lan, G., Ouyang, Y.: Accelerated schemes for a class of variational inequalities. Math. Program. 165(1), 113–149 (2017)
Cover, T.M., Thomas, J.A.: Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing). Wiley-Interscience, USA (2006)
Doikov, N., Nesterov, Y.: Contracting proximal methods for smooth convex optimization. SIAM J. Optim. 30, 3146–3169 (2019)
Doikov, N., Nesterov, Y.: Affine-invariant contracting-point methods for convex optimization. Math. Program. 198, 115–137 (2023)
Hamedani, E.Y., Aybat, N.S.: A primal-dual algorithm with line search for general convex-concave saddle point problems. SIAM J. Optim. 31(2), 1299–1329 (2021)
Hamedani, E.Y., Jalilzadeh, A., Aybat, N.S., Shanbhag, U.V.: Iteration complexity of randomized primal-dual methods for convex-concave saddle point problems. arXiv:1806.04118 (2018)
Hien, L.T.K., Nguyen, C., Xu, H., Canyi, L., Feng, J.: Accelerated randomized mirror descent algorithms for composite non-strongly convex optimization. J. Optim. Theory Appl. 181, 541–566 (2019)
Juditsky, A., Nemirovski, A.: First-Order Methods for Nonsmooth Convex Large-Scale Optimization, II: Utilizing Problem’s Structure, pp. 149–184. MIT Press (2012)
Juditsky, A., Nemirovski, A., Tauvel, C.: Solving variational inequalities with stochastic mirror-prox algorithm. Stoch. Syst. 1(1), 17–58 (2011)
Kolossoski, O., Monteiro, R.: An accelerated non-Euclidean hybrid proximal extragradient-type algorithm for convex-concave saddle-point problems. Optim. Methods Softw. 32(6), 1244–1272 (2017)
Lan, G., Zhou, Y.: An optimal randomized incremental gradient method. Math. Program. 171(1), 167–215 (2018)
Lin, Q., Nadarajah, S., Soheili, N.: A level-set method for convex optimization with a feasible solution path. SIAM J. Optim. 28(4), 3290–3311 (2018)
Necoara, I., Nedelcu, V.: Rate analysis of inexact dual first-order methods application to dual decomposition. IEEE Trans. Autom. Control 59(5), 1232–1243 (2014)
Nedić, A., Ozdaglar, A.: Subgradient methods for saddle-point problems. J. Optim. Theory Appl. 142(1), 205–228 (2009)
Nemirovski, A.: Prox-method with rate of convergence \(O(1/t)\) for variational inequalities with Lipschitz continuous monotone operators and smooth convex-concave saddle point problems. SIAM J. Optim. 15(1), 229–251 (2005)
Nesterov, Y.: Excessive gap technique in nonsmooth convex minimization. SIAM J. Optim. 16(1), 235–249 (2005)
Nesterov, Y.: Smooth minimization of non-smooth functions. Math. Program. 103(1), 127–152 (2005)
Nesterov, Y.: Primal-dual subgradient methods for convex problems. Math. Program. 120(1), 221–259 (2009)
Nesterov, Y.: Gradient methods for minimizing composite functions. Math. Program. 140(1), 125–161 (2013)
Salzo, S., Villa, S.: Inexact and accelerated proximal point algorithms. J. Convex Anal. 19, 1167–1192 (2012)
Schmidt, M., Roux, N.L., Bach, F.R.: Convergence rates of inexact proximal-gradient methods for convex optimization. In: Proc. NIPS, pp. 1458–1466 (2011)
Shalev-Shwartz, S., Zhang, T.: Accelerated proximal stochastic dual coordinate ascent for regularized loss minimization. Math. Program. 155(1), 105–145 (2016)
Teboulle, M.: A simplified view of first order methods for optimization. Math. Program. 170(1), 67–96 (2018)
Thekumparampil, K.K., Jain, P., Netrapalli, P., Oh, S.: Efficient algorithms for smooth minimax optimization. In: Proc. NIPS, pp. 12680–12691 (2019)
Tseng, P.: On accelerated proximal gradient methods for convex-concave optimization. Technical Report, University of Washington, Seattle (2008)
Xiao, L., Zhang, T.: A proximal stochastic gradient method with progressive variance reduction. SIAM J. Optim. 24(4), 2057–2075 (2014)
Xu, Y.: Iteration complexity of inexact augmented Lagrangian methods for constrained convex programming. Math. Program. 185, 199–244 (2021)
Zhao, R.: Optimal algorithms for stochastic three-composite convex-concave saddle point problems. arXiv:1903.01687 (2019)
Zhao, R.: A primal dual smoothing framework for max-structured non-convex optimization. Math. Oper. Res. https://doi.org/10.1287/moor.2023.1387 (2023)
Acknowledgements
We express our sincere appreciation to the reviewers for their comments, which greatly helped improve the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Angelia Nedic.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
R. Zhao’s research is supported by AFOSR Grant No. FA9550-22-1-0356.
Appendix: Technical Proofs
Appendix: Technical Proofs
1.1 Proof of Proposition 2.2
First, for any \(\lambda \in {\mathbb {E}}_2\), we note that \(\nabla _{\lambda }{\widehat{S}}^\textrm{P}({\widetilde{x}}_{\gamma }(\lambda ),\lambda )=\nabla _{\lambda }\varPhi ({\widetilde{x}}_{\gamma }(\lambda ),\lambda )\) and \(\nabla {\widehat{\psi }}^\textrm{D}(\lambda )=\nabla _{\lambda }\varPhi (x^*(\lambda ),\lambda )\) (cf. Proposition 2.1). Therefore,
where in (a) we use (3c), in (b) we use the \(\mu \)-strong convexity of \({\widehat{S}}^\textrm{P}(\cdot ,\lambda )\) on \({\mathcal {X}}\) and in (c) we use the definition of \({\widetilde{x}}_{\gamma }(\lambda )\) in (19). This proves (28).
We next prove (29). First, for any \(\lambda ,\lambda '\in {\mathbb {E}}_2\),
where (a) follows from (13) and (b) follows from the concavity of \({\widehat{S}}^\textrm{P}({\widetilde{x}}_{\gamma }(\lambda ),\cdot )\) on \({\mathbb {E}}_2\). This proves the left-hand side (LHS) of (29). To show the right-hand side (RHS), we note that \({\widehat{\psi }}^\textrm{D}\) is concave and \(L_\textrm{D}\)-smooth on \({\mathbb {E}}_2\) (cf. Proposition 2.1). Thus, we can invoke the descent lemma [3], such that for all \(\lambda ,\lambda '\in {\mathbb {E}}_2\),
where (a) follows from (28) and (b) follows from the AM-GM inequality, i.e.,
We then rearrange (107) to obtain the RHS of (29).
1.2 Proof of Lemma 3.1
Fix any \(k\in {\mathbb {Z}}_+\). Since \({\widehat{S}}^\textrm{D}_{\rho _{k}}(x^{k},\cdot )\) is \(\rho _{k}\)-strongly concave on \(\varLambda \),
As a result, for all \(\lambda \in \varLambda \), we have
where in (a) we use (109). Define \(z_k(\lambda )\triangleq \tau _{k}\lambda ^{k}+(1-\tau _{k})\lambda \). We then multiply both sides of (110) by \(\tau _k>0\), and obtain
where we use \(\tau _k\rho _{k}=\rho _{k+1}\) in (a), the convexity of \({\widehat{S}}^\textrm{P}(\cdot ,\lambda )\), the LHS of (29) and the concavity of \({\widehat{S}}^\textrm{P}({\widetilde{x}}_{\gamma _{k}}({\hat{\lambda }}^{k}),\cdot )\) in (b), the definition of \({\widehat{S}}^\textrm{P}\) and \(S_{\rho _{k+1}}\) [in (13) and (15), respectively] in (c), and the RHS of (29) and the convexity of h in (d). Note that if we take \(\lambda ={\widetilde{\lambda }}_{\rho _{k+1},\eta _{k}}(x^{k+1})\), then \(z_k(\lambda )=\lambda ^{k+1}\) by step 7. In addition, from steps 2 and 7, we have
and from (32) and (109), we have
This observation leads us to bound \(\Vert {\widetilde{\lambda }}_{\rho _{k+1},\eta _{k}}(x^{k+1})-\lambda ^*_{\rho _{k}}(x^{k})\Vert ^{2}\) as
where in (a) we use \(\left\| a+b\right\| ^2\le 2(\left\| a\right\| ^2+\left\| b\right\| ^2)\), in (b) we use (113) and in (c) we use (112). We then substitute \(\lambda ={\widetilde{\lambda }}_{\rho _{k+1},\eta _{k}}(x^{k+1})\) and (114) into (111), and obtain
where we use (34) in (a) and \(\tau _k\in (0,1)\) and \({\rho _{k+1}}\ge {4(1-\tau _{k})^{2}}L_\textrm{D}\) in (b).
1.3 Proof of Theorem 3.2
Since \(\gamma _k=\varepsilon /(4(k+3))=O(\varepsilon /k)\) [cf. (57)], based on (41), we have
where in (a) we use the fact that \(\log (K!)\!=\!\Theta (K\log K)\) for any \(K\in {\mathbb {N}}\) and (62).
Similarly, we can analyze the dual oracle complexity for solving (32). Since \(\rho _k=O(L_\textrm{D}/k^2)\) [cf. (60)] and \(\eta _k=O(\varepsilon /k)\) [cf. (57)], based on (40), we have
where in (a) we use \(\sum _{k=1}^K k =\Theta (K^2)\), \(\sum _{k=1}^K k\log k =\Theta (K^2\log K)\) and (62). We can repeat this analysis to conclude that the dual oracle complexity for solving (34), i.e., \(C_{{\textsf{det}},2}^\textrm{D}\) has the same order as \(C_{{\textsf{det}},1}^\textrm{D}\). Since \(C_{\textsf{det}}^\textrm{D}=C_{{\textsf{det}},1}^\textrm{D}+ C_{{\textsf{det}},2}^\textrm{D}\), the proof is complete.
1.4 Proof of Lemma 4.1
To prove this lemma, one needs to properly incorporate the inexact criteria in (65)–(67) (which involve conditional expectations) into the proof of Lemma 3.1. The key steps are: i) taking conditional expectation over the steps in the proof of Lemma 3.1 by using the measurability results in (69) and ii) applying the tower property of conditional expectation by using the nested relation in (68). Specifically, at the k-th iteration, we first modify the proof of Proposition 2.1 and show that
(For notational brevity, we omit ‘a.s.’ here and for all the inequalities below.) Furthermore, since \({\mathcal {F}}_{k,0}\subseteq {\mathcal {F}}_{k,1}\), if we take \({\mathbb {E}}[\cdot |{\mathcal {F}}_{k,0}]\) over (117), then we have
In addition, from (114), we have
Now, we can take \({\mathbb {E}}[\cdot |{\mathcal {F}}_{k,0}]\) over Equation (c) in (111), and use (118), (119) and the fact that \(x^k,\lambda ^k\in {\mathcal {F}}_{k,0}\) to obtain
Again, since \({\mathcal {F}}_{k,0}\subseteq {\mathcal {F}}_{k,2}\), if we take \({\mathbb {E}}[\cdot |{\mathcal {F}}_{k,0}]\) over (67), then we have
We then substitute (121) into (120), and use the condition \({\rho _{k+1}}\ge {4(1-\tau _{k})^{2}}L_\textrm{D}\) to get
1.5 Proof of Theorem 4.2
The proof follows the same argument as that of Theorem 3.2, hence we only outline the important steps. Based on the choice of \(\gamma _k\) in (57) and the complexity of \({{\textsf{M}}}_2\) in (73),
Using the same reasoning as in the proof of Theorem 3.2, the dual oracle complexities for solving both (65) and (67) have the same order, so it suffices to only analyze the complexity for solving (65). Specifically, based on (72), we have
where (a) holds since \(n\le kn\). We obtain (76) by noting that \(C_{{\textsf{stoc}}}^\textrm{D}=\Theta \big (C_{{\textsf{stoc}},1}^\textrm{D}\big )\).
1.6 Proof of Theorem 4.3
First, let us define the events \({\mathcal {A}}_{0,0}\triangleq \varOmega \), and for any \(k\in {\mathbb {Z}}_+\),
Also, for any measurable event \({\mathcal {A}}\), denote its complement as \({\mathcal {A}}^\textrm{c}\) and its indicator function as \({\mathbb {I}}_{{\mathcal {A}}}\), i.e., \({\mathbb {I}}_{{\mathcal {A}}}(z)=1\) if \(z\in {\mathcal {A}}\) and 0 otherwise.
Fix any \(k\in \{0,\ldots ,K-1\}\). From Markov’s inequality and (77), we have
Since \(\bigcup _{i=0}^{k-1}\{{\mathcal {A}}_{i,1},{\mathcal {A}}_{i,2},{\mathcal {A}}_{i+1,0}\}\subseteq {\mathcal {F}}_{k,0}\), we have that
(When \(k=0\), define \({\mathcal {C}}_{0,0}\triangleq {\mathcal {A}}_{0,0}\).) In addition, note that \(\Pr \{{\mathcal {C}}_{k,0}\}>0\), since
We then take conditional expectation \({\mathbb {E}}[\cdot \,|\,{{\mathcal {C}}_{k,0}}]\) in (123) to obtain
On the other hand,
where (a) follows since \({{\mathcal {C}}_{k,0}}\in {\mathcal {F}}_{k,0}\). Therefore, we have
Similarly, if we define \({\mathcal {C}}_{k,1}\triangleq {\mathcal {C}}_{k,0}\cap {\mathcal {A}}_{k,1}\) and \({\mathcal {C}}_{k,2}\triangleq {\mathcal {C}}_{k,1}\cap {\mathcal {A}}_{k,2}\), then we also have
From Theorem 3.1, we know that if \(K=K_{\textsf{det}}'\) and the event \(\bigcap _{k=0}^{K-1}\big ({\mathcal {A}}_{k,1}\cap {\mathcal {A}}_{k,2}\cap {\mathcal {A}}_{k+1,0}\big )\) occurs, then \(\varDelta _{\rho _K}(x^K,\lambda ^K)\le \varepsilon \). Therefore,
where (a) follows from (127) and (128) and (b) follows from Bernoulli’s inequality. By the same reasoning, we can also show that if \(K=K_{\textsf{det}}\), then (80) holds.
1.7 Proof of Lemma 5.1
Since \(\lambda ^*\in {\mathbb {R}}_+^n\) is an optimal solution of \(\max _{\lambda \in {\mathbb {R}}_+^n}\psi ^\textrm{D}(\lambda )\), we have that \(\psi ^\textrm{D}({\overline{\lambda }})\le \psi ^\textrm{D}(\lambda ^*)\). This implies \(\varDelta _{\rho }({\overline{x}},{\lambda ^*})\le \varDelta _{\rho }({\overline{x}},{\overline{\lambda }}) \le \epsilon \). From the definition of \(\varDelta _\rho \) in (23), we have
We then choose \(x\!=\!x^{*}\) and \(\lambda \!=\!0\) in (129) to obtain
where the last step follows from \(\lambda ^*_i\ge 0\) and \(g_i(x^*)\le 0\), for any \(i\in [n]\).
Now, fix any \(\theta >0\) and \(i\in [n]\). Let \(e_i\in {\mathbb {R}}^{n}\) denote the i-th standard basis vector, i.e., \((e_i)_i=1\) and \((e_i)_j=0\) for any \(j\!\in \![n]\setminus \{i\}\). In (129), if we choose \(x=x^{*}\) and \(\lambda =\lambda ^*+\theta _i e_i\), where \(\theta _i=\theta \) if \(g_i({\overline{x}})>0\) and 0 otherwise, then
where in the last step we use \(\lambda ^*\ge 0\) and \(\theta \ge \theta _i\ge 0\). After rearranging, we have
where we take the infimum over \(\theta >0\) in (a) and use \(\sqrt{a+b}\le \sqrt{a}+\sqrt{b}\), \(\forall \, a,b\ge 0\) in (b).
1.8 Proof of Theorem 5.3
Similar to the analysis in Sect. 3.4, we have
where in (a) we use \(\gamma _k=\Theta (\varepsilon /k)\), in (b) we use \(\alpha /\sqrt{\varepsilon }=O((L+\alpha )/\varepsilon )\) and in (c) we use \(\sum _{k=1}^K k^\nu \log k = \Theta (K^{\nu +1}\log K)\), for any \(\nu \ge 0\). By noting that \(\alpha \le L+\alpha \), we obtain (103).
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Hien, L.T.K., Zhao, R. & Haskell, W.B. An Inexact Primal-Dual Smoothing Framework for Large-Scale Non-Bilinear Saddle Point Problems. J Optim Theory Appl 200, 34–67 (2024). https://doi.org/10.1007/s10957-023-02351-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-023-02351-9
Keywords
- Non-bilinear saddle point problems
- Inexact primal-dual smoothing
- Convex optimization with functional constraints
- Stochastic optimization