
Abstract
Clustering is a well-known and studied problem, one of its variants, called contiguity-constrained clustering, accepts as a second input a graph used to encode prior information about cluster structure by means of contiguity constraints i.e. clusters must form connected subgraphs of this graph. This paper discusses the interest of such a setting and proposes a new way to formalise it in a Bayesian setting, using results on spanning trees to compute exactly a posteriori probabilities of candidate partitions. An algorithmic solution is then investigated to find a maximum a posteriori partition and extract a Bayesian dendrogram from it. The interest of this last tool, which is reminiscent of the classical output of a simple hierarchical clustering algorithm, is analysed. Finally, the proposed approach is demonstrated with experiments on simulated data and real applications. A reference implementation of this work is available in the R package gtclust that accompanies the paper.
Similar content being viewed by others


1 Context, motivations and related works

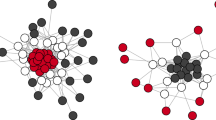
Two graphs and partitions examples between blue  and yellow
and yellow  vertices, edges that belong to the subgraph induced by yellow vertices are depicted in yellow and edges that belong to the subgraphs induced by blue vertices are depicted in blue. Edges in black belong to the cutset of yellow and blue vertices, i.e. they do not belong to any of the subgraph induced by the partition elements. The partition of figure a full-fills the contiguity constraints any blue vertex is reachable from any blue vertex by only taking blue edges and the same applies for yellow vertices. The partition shown in figure b does not satisfy the contiguity constraints, since the subgraph induced by the yellow vertices and edges is disconnected. (Color figure online)
vertices, edges that belong to the subgraph induced by yellow vertices are depicted in yellow and edges that belong to the subgraphs induced by blue vertices are depicted in blue. Edges in black belong to the cutset of yellow and blue vertices, i.e. they do not belong to any of the subgraph induced by the partition elements. The partition of figure a full-fills the contiguity constraints any blue vertex is reachable from any blue vertex by only taking blue edges and the same applies for yellow vertices. The partition shown in figure b does not satisfy the contiguity constraints, since the subgraph induced by the yellow vertices and edges is disconnected. (Color figure online)

Two input graph examples for contiguity-constrained clustering; a neighbourhood graph derived from spatial polygons with shared boundaries (queen adjacency); b neighbourhood graph derived from line intersections of a road network: a network between road segments (white dots) is built by connecting any two segments connected to a common road intersection (red dots). (Color figure online)
Contiguity-constrained clustering combines two pieces of information: on the one hand, a classical data set \(\textbf{X}\) corresponding to a sample of observations \(\{\textbf{x}_1,\ldots ,\textbf{x}_N\}\) living for example in \(\mathbb {R}^d\) or \(\mathbb {N}^d\); and on the other hand, an undirected graph \(G=(V,E)\) between the same N observations (\(V=\{1,\ldots ,N\}\)) and with edges set E. The informal objective being to find a partition \(\varvec{c}=\{\varvec{c}_1,\ldots ,\varvec{c}_K\}\) of the data points that explains well \(\textbf{X}\) and where each cluster \(\varvec{c}_k\) forms a connected sub-graph of G. A subgraph \(G[\varvec{c}_k]=\left( \varvec{c}_k,\{(u,v) \in E: u, v\in \varvec{c}_k\}\right) \) is said to be connected if, for any pair of nodes u and v in \(\varvec{c}_k\), there is at least one path (a sequence of distinct edges) connecting them without leaving \(\varvec{c}_k\). Figure 1 illustrates this point by showing two partitions of the same graph, partition (a) fully satisfies the contiguity constraints, any blue vertex is reachable from any other blue vertex by taking only blue edges, and the same applies to yellow vertices, while partition (b) does not, since the subgraph induced by the yellow vertices and edges is disconnected.
We will note \(\varvec{c}\prec G\) a partition that fulfils this property. Such a problem allows the use of prior information about the clusters to ensure, for example, that they correspond to spatially coherent regions or time segments. These constraints are quite natural in several applications and greatly reduce the size of the space of possible solutions. Such constraints are therefore interesting from both a computational and an application point of view. Contiguity-constrained clustering has a long history, particularly in geography, where this approach is known as regionalisation and has been studied since the seminal papers of Masser and Brown (1975) and Openshaw (1977). The interest for such a problem in spatial statistics seems natural, since contiguity graphs and distance graphs play an important role in this area (Anselin 2001). For example, a contiguity graph can be inferred from spatial polygon data by looking at common boundaries, as shown in Fig. 2a, or from geographic networks (such as road networks) by looking at the intersections between segments, as shown in Fig. 2b. In the former case, contiguity constraints ensure that the clusters found correspond to coherent spatial regions, and in the latter case to connected roads. Since these pioneering contributions, several research papers in the field of quantitative geography have revisited this issue. The Spatial ‘K’luster Analysis by Tree Edge Removal (SKATER) proposed by Assunção et al. (2006) is a graph-based method that uses a minimal spanning tree to reduce the search space. The regions are then defined by removing edges from the minimal spanning tree. The removed edges are chosen to minimise a dissimilarity measure. Inspired by SKATER, Guo (2008) proposed REDCAP (Regionalization with Dynamically Constrained Agglomerative clustering and Partitioning), which discusses several variants of agglomerative approaches to solving contiguity constrained clustering problems by varying the affinity metrics and considering full order and partial order constraints.
Statisticians have also been studying contiguity constrained clustering for some time, and relevant references include the work of Lebart (1978), Murtagh (1985), Grimm (1987) and Gordon (1996), which study hierarchical agglomerative approaches to solving such a problem. As these references show, the interest in contiguity-constrained clustering and the fact that such constraints can be easily combined with an agglomerative approach has long been known in the statistical community. In addition to applications in geography and statistics, contiguity constraints have also been studied in the context of sequence analysis. Sequences, of course, can be equipped with simple line-graph and therefore benefit from contiguity constraints to solve segmentation tasks. This has led to applications of such an approach in genetics to study genome sequences (Ambroise et al. 2019) or in time series analysis (Barry and Hartigan 1993; Schwaller and Robin 2017). Finally, in the network analysis community, the Louvain (Blondel et al. 2008) and Leiden algorithms (Traag et al. 2019), two of the most well-known graph clustering approaches, leverage, even if not explicitly stated, contiguity constraints to speed up computations and extract communities.
In the Bayesian context, a first line of related work deals with the use of Spatial Product Partition Models (SPPM), see Hegarty and Barry (2008); Page and Quintana (2016). Product Partition Models (PPM) were first introduced by Hartigan (1990) and assume that the partition prior \(\varvec{c}\) is a product of subjective non-negative functions \(\kappa (\varvec{c}_k)\) called prior cohesions. The cohesion functions measure how likely it is that elements in a given cluster are clustered a priori. This generic setting was then used to define priors that enforce the spatial coherence of the clusters. To do so, Hegarty and Barry (2008) defines these cohesion functions by counting the number of zones that are neighbours of an element of clusters \(\varvec{c}_k\) but do not belong to \(\varvec{c}_k\), while Page and Quintana (2016) considers the locations and spatial distances between the elements of the clusters. Both approaches favour spatially coherent clustering, but do not strictly enforce the contiguity constraints, as we will do in this proposal. This line of research can also be linked to approaches that try to incorporate spatial information into classical clustering approaches, see for example (Chavent et al. 2018), where a Ward-like hierarchical clustering algorithm is extended to minimise, at each stage, a convex combination of a homogeneity criterion computed in feature space and a homogeneity criterion incorporating the spatial dimension of the problem. We can also mention approaches based on space partitioning (using recursive space partitioning à la CART Breiman (1984), i.e treed partitioning) to deal with non-stationarity problems, since one of the outputs of such approaches is the partitioning itself. The works of Gramacy and Lee (2008) is a good example of such an approach where Gaussian processes are used together with treed partitioning to build a tractable nonstationary model for nonparametric regression.
Finally, the approach of Teixeira et al. (2019) is the closest to our proposal since it also relies on spanning trees to define a prior over partitions that strictly enforce contiguity constraints. However, it differs from the present work since it is based on Markov Chain Monte Carlo (MCMC) computations to solve the estimation problem and does not use exactly the same prior/criterion. The interest of our proposal with respect to this approach lies in it’s cheaper computational cost and the ease of interpretation of the results (dendrogram and MAP partition).
As we have just seen, clustering with adjacency constraints is an important problem in unsupervised learning that has been studied for a long time and has important applications in various fields. This paper proposes to revisit this problem and aims at proposing a hierarchical Bayesian approach to solve it. This proposal is based on the definition of a prior on the partition space that enforces the graph-induced contiguity constraints and favours partitions that are easy to disentangle. To this end, the main contributions of the paper are as follows:
-
The definition of a partition prior to ensure the contiguity constraints induced by a graph
-
The derivation of an analytical expression to compute exactly this prior
-
A hierarchical agglomerative algorithm to find an approximate maximum a posteriori partition
-
A simple approach to building a dendrogram from the computed cluster hierarchy
Finally, the open source R package (R Core Team 2019) gtclust provides a reference implementation of the algorithm presented in this paper. The implementation is extensible and new models can be integrated. The main computationally intensive methods have been developed in Cpp thanks to the Rcpp package (Eddelbuettel and Balamuta 2017), exploiting the computational efficiency of sparse matrices thanks to the Matrix packages (Eddelbuettel and Sanderson 2014; Bates and Maechler 2019) and the cholmod library. The c library (Chen et al. 2008) for sparse Cholesky matrix factorisation. Finally, the sf package (Pebesma 2018) was used to seamlessly integrate the package with the standards used to handle spatial datasets in R.
The rest of this paper is structured as follows: in Sect. 2 we present details of our methodology, in Sect. 2.1 we discuss the prior we propose, in Sect. 2.2 we present the mathematical framework we will use and how it can be adapted to different observational models. We then derive some results necessary to compute this prior efficiently and discuss them in Sect. 2.3. In Sect. 2.4 we describe the algorithm we propose to search for an optimal partition, and in Sect. 2.5 we show how to build a dendrogram from its output. Finally, in Sect. 3 we describe several applications of the method to real and simulated data sets. The Sect. 4 concludes the paper.
2 Method
Since we will be relying on a non-parametric Bayesian approach, the target we are looking for is a partition of N points with an unknown number of clusters K in \(\{1,\ldots ,N\}\). More formally, let \(\varvec{c}\in \mathcal {P}_N\) be an ordered partition of \(\{1,\ldots ,N\}\), that is:
Following Peixoto (2019), we will further assume, to ensure the distinguishability of the groups, which we require, that \(\varvec{c}\) is ordered meaning that, two identical partitions but with different ordering of their elements will be different for us, so for example:
To establish, the model we will work with, we start by defining the prior distribution over ordered partitions with contiguity constrains that we propose.
2.1 Contiguity-constrained partition prior
In the unconstrained case, the classical solutions to define a prior over the space of partitions \(p(\varvec{c})\) are mainly based on the Dirichlet process (Rasmussen and Ghahramani 2001) or on uniform priors (Peixoto 2019). We will follow a path closer to the latter approach here, and we will start by recognising that a contiguity-constrained prior can be easily defined if the graph G is a tree. A tree is a graph in which any two vertices are connected by exactly one path, or equivalently a connected acyclic graph. Trees have the interesting property of being minimally connected, so removing any edges will create two connected components, and removing \(K-1\) edges will create K connected subgraphs. This property shows that there is a one-to-one relationship between combinations of edges and compatible partitions. Thus, if G is a tree, there are \(C_{N-1}^{K-1}\) ways of partitioning the vertices into K groups that satisfy the constraints induced by G, since removing any \((K-1)\) edges in the tree creates K connected subgraphs and the tree has \(N-1\) edges. Furthermore, there are K! ways of ordering the K clusters, and so we can easily define a uniform distribution for \(\varvec{c}\mid K,G\) when G is a tree:
where \(\textbf{1}_{\{\varvec{c}: \vert \varvec{c}\vert = K, \varvec{c}\prec G \}}\) is an indicator function assuming 1, if the partition \(\varvec{c}\) has K clusters and is compatible with the graph G, and 0, otherwise. Note that in the rest of the paper we will use the notation \(\vert .\vert \) to denote the cardinality of any set, and therefore use \(\vert \varvec{c}\vert \) to denote the number of clusters in a partition. For the prior distribution on the number of clusters we propose to use the truncated geometric distribution. In fact, considering that the expected value of this random quantity is known, the maximum entropy prior over \(\{1,\ldots ,N\}\) is given by the truncated geometric distribution:
Such a prior is therefore a natural way of providing information about the number of clusters. This prior also has the attractive property of including the uniform distribution as a special case. In fact, the prior parameter \(\alpha \) allows a smooth interpolation between the extreme prior cases, when \(\alpha \) is equal to 1 a uniform prior is recovered, and when \(\alpha \) is equal to 0 this prior is equivalent to a Dirac distribution at \(K=1\). Using a small value of \(\alpha \) will therefore lead to solutions with fewer clusters. The interest of such prior on the number of cluster will be further in Sect. 2.5. Using such prior for the number of cluster leads to the following prior for a partition, if G is a tree:
where \(\textbf{1}_{\{\varvec{c}: \varvec{c}\prec G \}}\) is an indicator function assuming 1, if the partition \(\varvec{c}\) is compatible with the graph G, and 0, otherwise.
The interesting properties of trees that we have just highlighted give us an interesting prior when G is a tree, but do not solve the general case. To do so, following Teixeira et al. (2019), we will introduce in the setting the set of all spanning tree of G, denoted by \(\mathcal {T}_G\). A spanning tree \(\varvec{t}\in \mathcal {T}_G\) of a graph G is a connected subgraph with no cycles containing all nodes of G. Since a spanning tree is a tree (having no cycles and being connected), it inherits the tree properties: any two nodes of G are connected by a unique path in \(\varvec{t}\), the number of edges in \(\varvec{t}\) is \(N-1\), and removing any \((K-1)\) edges divides the vertices of G into K clusters, each cluster being a connected subgraph of G. The spanning trees of G can thus be used to define a two-stage prior, as follows:
-
1.
Sample a spanning tree \(\varvec{t}\) of G uniformly:
$$\begin{aligned} p(\varvec{t}\mid G) = \frac{1}{ |\mathcal {T}_G |}\textbf{1}_{\{\varvec{t}\in \mathcal {T}_G\}}, \end{aligned}$$with \(\mathcal {T}_G\) the set of all spanning tree of G and \(|\mathcal {T}_G |\) the size of this set.
-
2.
Then remove \(K-1\) edges, and draw an ordering for the corresponding clusters:
$$\begin{aligned} p(\varvec{c}\mid \varvec{t},K) = \frac{1}{C_{K-1}^{N-1}K!}\textbf{1}_{\{\varvec{c}: \vert \varvec{c}\vert =K,\varvec{c}\prec \varvec{t}\}}. \end{aligned}$$
This generative scheme for partitions will produce partitions that are compatible with G, since the clusters form connected subgraphs of \(\varvec{t}\), and the edges of \(\varvec{t}\) are by definition contained in the edges of G. To obtain a prior on partition from this process, and since the specific spanning tree used to generate the clustering is not of particular interest, it is natural to marginalise this random variable, which results in the following expression:
with \(|\{\varvec{t}: \varvec{c}\prec \varvec{t}\}|\) the number of spanning trees of G compatible with \(\varvec{c}\). Eventually, taking into account the prior on the number of cluster leads to:
We will denoted this prior distribution over partition with contiguity constrains as \({\mathcal {S}}{\mathcal {P}}(G,\alpha )\). At this point, the introduction of spanning trees may seem artificial, but such a prior has interesting properties. This prior is quite informative, since it depends on the constraints defined by G, but it goes even further, since it does not correspond to a uniform prior on feasible partitions. In fact, it is known that the probability that an edge e is used in a uniformly sampled spanning tree is a good way of measuring how crucial that edge is for the graph to be connected. This measure, known as spanning tree centrality, (Angriman et al. 2020; Hayashi et al. 2016), gives us an interesting perspective on the proposed prior. This prior can be seen as a way of extending this measure to partitions of the graph vertices, measuring how easily the different elements of a given partition can be disentangled in the graph by cutting a few edges. This formalises in an interesting way the kind of prior that practitioners want to express with the contiguity graph.
The small difference between our proposed prior and the one defined in (Teixeira et al. 2019) concerns the way the number of clusters is treated. In our proposal, the number of clusters has its own a priori distribution, and the partition is conditionally drawn on it by removing exactly \(K-1\) edges in the spanning trees, whereas in (Teixeira et al. 2019) each edge has a probability of being deleted, the number of clusters being a consequence of the number of edges effectively deleted. A consequence of this difference is that in our case the prior distribution on the number of clusters is independent of the graph topology, whereas this is not the case for the one defined in (Teixeira et al. 2019).
One of the main contribution of the paper, will be to establish how to compute exactly the prior defined by Eq. 4, this point will be covered in Sect. 2.3. But, before tackling this question we present, the remaining parts of the model we propose and in particular the observations models that it may handle with ease.
2.2 Model and MAP derivation
Let \(\varvec{X}=\left( \varvec{X}_1,\ldots ,\varvec{X}_N\right) \) denote the observable variables (with \(\left( \textbf{x}_1,\ldots ,\textbf{x}_N\right) \) their realisations) and \(\varvec{\theta }=\left( \varvec{\theta }_1,\ldots ,\varvec{\theta }_N\right) \) the vector of parameters for the N data-points. We associate \((\varvec{X}_i, \varvec{\theta }_i)\) with the vertex (i) in the graph. Assume that, given a partition \(\varvec{c}= \{\varvec{c}_1,\ldots ,\varvec{c}_K\}\), there are common parameters \(\varvec{\theta }_{\varvec{c}_k}, k \in \{1,\ldots , \vert \varvec{c}\vert \}\), such that, for all nodes with labels belonging to \(\varvec{c}_k\), we have that \(\varvec{\theta }_i = \varvec{\theta }_{\varvec{c}_k},\forall k,\forall i\in \varvec{c}_k\). The set of observations associated with vertices in cluster \(\varvec{c}_k\), will be denoted by \(\varvec{X}_{\varvec{c}_k}\).
-
1.
Given a graph G and \(\alpha \), the partition \(\varvec{c}\) is sampled according to:
$$\begin{aligned} \varvec{c}\sim \mathcal{S}\mathcal{P}(G,\alpha ). \end{aligned}$$ -
2.
Given \(\varvec{c}\prec G\) and \(\varvec{\theta }_{\varvec{c}_1},\ldots , \varvec{\theta }_{\varvec{c}_K}\) the observations \(\varvec{X}_{\varvec{c}_k},\ldots , \varvec{X}_{\varvec{c}_K}\) are independent and such that:
$$\begin{aligned} \varvec{X}_i \mid \varvec{\theta }_{\varvec{c}_k} \overset{iid}{\sim }\ \mathcal {F} (\varvec{\theta }_{\varvec{c}_k} ), \forall i \in \varvec{c}_k, \end{aligned}$$with \(\mathcal {F}(\varvec{\theta })\) a distribution from the exponential family.
-
3.
Given \(\varvec{c}\prec G\), the common parameters \(\varvec{\theta }_{\varvec{c}_1},\ldots , \varvec{\theta }_{\varvec{c}_K}\) are iid:
$$\begin{aligned} \varvec{\theta }_{\varvec{c}_k} \mid \varvec{c}\overset{iid}{\sim } \mathcal {L} (\varvec{\beta },\nu ),\forall k \in \{1,\ldots ,\vert \varvec{c}\vert \}, \end{aligned}$$with prior distribution \(\mathcal {L}(\varvec{\beta },\nu )\) the conjugate prior of distribution \(\mathcal {F}\) with parameter \(\left( \varvec{\beta },\nu \right) \).
Assuming a clustering objective, we will try to find the MAP partition:
The clusters parameters, will be therefore marginalized and not estimated at all by the algorithm we propose. Such a criterion, already successfully used in clustering application (Côme et al. 2021), corresponds to an exact version of the Integrated Classification Likelihood (Biernacki et al. 2000, 2010) and is thus a penalised criterion. It will therefore allow to automatically tune the number of clusters. To simplify the derivation, we will mainly work with the un-normalised log posterior and drop the dependence on prior parameter values \(\varvec{\beta },\nu \) which will be considered fixed during the optimisation:
Thanks to hypothesis (2) and (3) we may marginalise analytically the cluster parameters so that the probability of the observed data knowing the partition and the prior parameters is given by:
will be easy to compute. In fact, since, we are working with exponential family distributions the integrals involved in this computations have an analytical expression in almost all cases. In Annexe A, we show that \(\mathscr {L}^{obs}(\textbf{X},\varvec{c})=\log p(\varvec{X}\mid \varvec{c},\varvec{\beta },\nu )\) depends on the data \(\varvec{X}\) and the partition \(\varvec{c}\) only through the sum of sufficient statistics over clusters \(\textbf{T}_{\varvec{c}_k}=\sum _{i \in \varvec{c}_k}\textbf{T}(\textbf{x}_i)\) in exponential family distributions, and that the integral can be computed analytically, when the conjugate prior has an explicit partition function \(H(\varvec{\beta },\nu )\). In this case, the integrated observational log-likelihood is obtained thanks to:
where cst is a constant independent of \(\varvec{c}\).Thus, any greedy merge heuristics relying on computations of \(\mathscr {L}^{obs}(\textbf{X},\varvec{c})\) only has to compute:
these will easily fit into a hierarchical approach where there are N evaluations of the \(\textbf{T}_i\)’s at the beginning and then merging two clusters \(\varvec{c}_g \cup \varvec{c}_h\) only amounts to summing their respective sufficient statistics \(\textbf{T}_{\varvec{c}_g \cup \varvec{c}_h} = \textbf{T}_{\varvec{c}_g} + \textbf{T}_{\varvec{c}_h}\). This property allows the use of a simple stored-data approach Murtagh and Contreras (2012), where the stored data are the cluster sufficient statistics, to design an agglomerative hierarchical clustering algorithm, and this article will follow this line of work. Note that such an approach could be costly without the contiguity constraints, since all possible merges have to be considered, but that it becomes very competitive in the constrained case, since the constraints remove a lot of candidates, especially when the contiguity graph has a small average degree. Finally, note that a similar approach can be used for swap moves and allows efficient computations for several classical observation models i.e. Gaussian, Poisson, Multinomial. We refer the reader to the supplementary material of Côme et al. (2021) for derivations of specific models. Let us now introduce the main contribution of this work, which concerns the definition of the contiguity-constrained partition prior.
2.3 Prior computation
Let us now discuss how to analytically compute the quantities involved in the prior. To use such a prior, we need to compute \(|\mathcal {T}_G |\) the number of spanning trees of G and \(|\{\varvec{t}: \varvec{c}\prec \varvec{t}\}|\) the number of spanning trees of G that are compatible with a given partition \(\varvec{c}\). These quantities, which at first sight may seem quite difficult to compute, are in fact perfectly amenable to analytical expressions, thanks to the Kirchhoff’s theorem; which relates the number of spanning trees of a graph to the spectrum of its Laplacian Kirchhoff (1847) and Cayley (1889).
Theorem 1
(Kirchhoff’s theorem) The number of spanning tree of a graph or multi-graph G, without self-loops is given by:
with \(\lambda _i\) be the non-zero eigenvalues of the Laplacian matrix L of G, given by:
where A is the adjacency matrix of G, with \(A_{ij}\) equal to the multiplicity of edge (i, j) for multi-graphs.
Using this theorem, it is therefore possible to compute \(\log (|\mathcal {T}_G|)\). There are several solutions to this, but from a computational point of view it is interesting to note that a consequence of this theorem is that the number of spanning trees is given by any cofactor of L, and is thus equal to the determinant of L with one of its rows and columns (j) removed. The Laplacian matrix with row and column (j) removed is denoted by \(L_{\text {-}j,\text {-}j}\). To avoid numerical problems, the logarithm of the determinant is used:
Finally, if the graph is sparse, the computation of the determinant can be solved in reasonable time using a sparse Cholesky decomposition for medium-sized problems. Such a factorisation will give sparse matrices U and D such that \(L_{\text {-}j,\text {-}j}=U.D.U^t\) and where U is a lower triangular matrix (with ones on the diagonal) and D is a diagonal matrix and hence \(\log (|\mathcal {T}_G|)=\sum _{i=1}^{N-1}\log (D_{ii})\). This approach solves the problem of computing the number of spanning trees of a given graph, but does not answer the question of the number of spanning trees compatible with a given partition. However, we will see that it can be used as a building block for this. To this end, we can decompose the problem by studying the inter-cluster and intra-cluster connectivity of G. The intra-cluster connectivity is easy to analyse by considering the subgraphs given by each element of the partition:
To study the connectivity between clusters, the main objects of interest are the cutsets between the different elements of the partition, i.e. the set of edges connecting the different clusters:
Using these cutsets, we can count the number of edges between any pair of clusters which is given by \(\vert \varvec{cutset}(G,\varvec{c}_g,\varvec{c}_h)\vert \) and define an aggregate multi-graph that we will denote by \(G \diamond \varvec{c}\), which describes the connection patterns between the clusters. This graph will have the clusters as vertices and as many edges between them as their are elements in the corresponding cutset, i.e. the multiplicity of an edge between two vertices g and h is given by the size of the corresponding cutset in G. Thus, formally \(G \diamond \varvec{c}\) is given by:
with
where (g, h, m) represents m edges between g and h. Using this tool, the following proposition can be used to find the number of spanning trees that may have led to a given partition:
Proposition 1
(Compatible spanning trees) The number of spanning trees in a graph G compatible with a given partition \(\varvec{c}\) of its vertices is given by:
Proof
To form a compatible spanning tree we need to take (\(\vert \varvec{c}\vert -1\)) edges in the union of the \(\varvec{cutset}(G,\varvec{c}_g,\varvec{c}_h)\) of each cluster pairs. To get a spanning tree \(\varvec{t}\) of G these edges must define a spanning tree of \(G\diamond \varvec{c}\), i.e. belongs to \(\mathcal {T}_{G \diamond \varvec{c}}\). However, any combination of intra-cluster spanning trees and inter-cluster spanning tree when combined will be compatible with the partition by definition and they will also form a spanning tree of G. \(\square \)
This proposition can then be combined with Kirchhoff’s theorem to compute exactly the desired quantity needed to compute the prior defined in Eq. 4, since the latter formula only involves the number of spanning trees of given graphs, and Kirchhoff’s theorem generalises to multi-graphs. So that,
can be computed exactly.
2.4 A greedy agglomerative algorithm
This section deals with the algorithmic details that must be taken into account in order to design an efficient agglomerative algorithm from the previous proposal. In particular, we will see that great care must be taken to avoid unnecessary computations when computing the prior probability of a partition along the merge tree.
In its simplest form, greedy agglomerative clustering simply reduces to iteratively selecting the best merge action to perform until only one cluster remains. Such a process builds a complete cluster hierarchy, since at each step t of the algorithm with the current partition \(\varvec{c}^{(t)}\), the number of clusters is reduced by one, and the process starts with each individual data point in its own cluster:
Ideally, we are interested in all partitions that maximize \(\mathscr {L}^{post}\), given by the Eq. 13 for all values of \(\alpha \). Such an output can then be used to find the partition \(\varvec{c}^*\) with maximum a posteriori probability for a fixed value of \(\alpha \), and to construct a dendrogram as shown in the next section. A greedy agglomerative algorithm with proper merge ranking can be seen as a way to approximate this set of solutions by selecting the best partition \(\varvec{c}^{(t+1)}\) from the partitions that can be constructed by merging two clusters of \(\varvec{c}^{(t)}\). The specific value of \(\alpha \) will have no effect on such a decision since \(\alpha \) affects the value of the prior probabilities through the terms \(\alpha ^{\vert \varvec{c}\vert -1}\). Therefore, the best partition (in terms of posterior probability) with a constrained number of clusters K is the same regardless of the value of \(\alpha \). In other words, changing \(\alpha \) can change the size of the selected partition, but not the merge tree of the hierarchical algorithm. Therefore, it is possible to work in two steps, i.e. build the merge tree and then make a decision on the number of clusters (best partition), for any value of \(\alpha \) without recomputing the merge tree.
Contiguity constraints can, of course, speed up this process by reducing the space of possible merges at each step. More formally, the possible merges compatible with the constraints and a current partition \(\varvec{c}^{(t)}\) correspond to the support of the multiset of edges of \(G\diamond \varvec{c}^{(t)}\) that we introduced earlier. At the first iteration, \(G\diamond \varvec{c}^{(0)}=G\) and therefore the possible merges are defined by the initial graph, so every \((g,h)\in E\) must be inspected and the best one \(e^*\) taken. When a merge occurs, the contiguity graph between clusters \(G\diamond \varvec{c}^{(t)}\) must be updated. This can be done by contracting the edge \(e^*=(g,h)\): all edges between (g, h) are removed, as well as their two incident vertices g and h, which are merged into a new vertex u, where the edges incident to u each correspond to an edge incident to either g or h, keeping possible duplicate edges leading to a multi-graph. This ensures that the support of the muti-graph edges always corresponds to all potential merges that fulfil the constraints. We will denote the multi-graph resulting from such an edge contraction by G/(g, h), which allows us to write down the following recurrence relation:
where \(e^{(t+1)}\) is the edge (and thus the merge) selected at step \(t+1\) in \(G\diamond \varvec{c}^{(t)}\). The use of edge contraction thus allows the cluster contiguity graphs \(G\diamond \varvec{c}\) to be efficiently updated.
To design a greedy agglomerative algorithm for the contiguity constrained problem, the main technical difficulty is to define how to rank the possible merges in an efficient way. Formally, a merge corresponds to modifying the current partition \(\varvec{c}\), leaving all clusters as they were, except two clusters g and h, which are removed and replaced by a single cluster corresponding to their union. We will refer to this merged partition as \(\varvec{c}^{g\cup h}\):
To rank the merges compatible with the constraints, we are naturally interested in the effect of this change on the log posterior:
This quantity can be decomposed into two parts, one coming from the \(\mathscr {L}^{obs}\) terms and one from the priors:
Removing the terms appearing on both the initial partition and the one with the two clusters merged, it is easy to see that, this quantity can be easily evaluated using Eq. 8 from the cluster sufficient statistics \(\textbf{T}_{\varvec{c}_g},\textbf{T}_{\varvec{c}_h}\) and \(\textbf{T}_{\varvec{c}_g\cup \varvec{c}_h}=\textbf{T}_{\varvec{c}_g}+\textbf{T}_{\varvec{c}_h}\). Furthermore, this quantity depends only on \(\varvec{c}_g\) and \(\varvec{c}_h\), and is therefore independent from the other elements of \(\varvec{c}^{(t)}\). This property is important because we didn’t want to update all the possible merge scores \(\Delta (g,h)\) at each step, but only the new ones. Following a similar approach for the second term in the right hand side of Eq. 16 and simplifying we obtain:
This second term is more problematic from a computational point of view, because it depends on the number of cluster \(\vert \varvec{c}\vert \) together with \(\alpha \) and on the whole partition. The terms \(|\mathcal {T}_{G\diamond \varvec{c}/(g,h)}|\) and \(|\mathcal {T}_{G\diamond \varvec{c}}|\) depend on the whole partition and not only on the clusters g and h, and as already explained, this must be avoided. The dependence on \(\vert \varvec{c}\vert \) and \(\alpha \) is actually not a problem: at each iteration of the algorithm, the merge to be compared will result in the same number of clusters \(\vert \varvec{c}\vert -1\), and therefore the second term on the right and side of Eq. 17 can be safely ignored to rank the merges. Regarding the dependence on the entire partition, this can also be relaxed by considering a lower bound on \(\Delta ^{prior}\). In fact, we can use the deletion-contraction recurrence for multigraphs given by Lemma 1 to get a lower bound on the ratio of the two problematic terms. This bound depends only on the size of the cutset between clusters g and h and is given in Proposition 2.
Lemma 1
(Deletion-contraction recurrence for multi-graphs) Given a multigraph G, without self-loops and more than 3 vertices, for any pair of vertices g and h, connected by at least one edge, we have:
with m the multiplicity of edge (g, h) and \(G-(g,h)\) the multigraph with all the m edges between g and h removed.
Proof
This Lemma is an extension of spanning tree deletion-contraction recurrence (Bondy and Murty 2011, Theorem 2.8) to multi-graph. \(|\mathcal {T}_{G}|\) is the sum of the number of spanning trees that use one of the (g, h) edges and the number of spanning trees of G that do not pass through any of the (g, h) edges. The number of spanning trees of G that do not pass through any of the (g, h) edges is given by \(|\mathcal {T}_{G-(g,h)}|\) since every spanning tree of \(G-(g,h)\) is a spanning tree of G that do not contains any (g, h) edge and conversely any spanning tree of G that do not contains any (g, h) edge is a spanning tree of \(G-(g,h)\). If \(\varvec{t}\) is a spanning tree of G containing one of the (g, h) edges, the contraction of (g, h) in both \(\varvec{t}\) and G results in a spanning tree \(\varvec{t}/(g,h)\) of G/(g, h). But, if \(\varvec{t}^*\) is a spanning tree of G/(g, h), there exists m spanning trees \(\varvec{t}\) of G, one for each of the m edges between g and h, such that \(\varvec{t}/(g,h) = \varvec{t}^*\). Thus, the number of spanning trees of G passing trough one the (g, h) edges is \(m.|\mathcal {T}_{G/(g,h)}|\). Hence \(|T_{G/(g,h)}|= m.|\mathcal {T}_{G/(g,h)}|+|\mathcal {T}_{G-(g,h)}|.\) \(\square \)
Proposition 2
(Lower bound on merge score) Given a graph G, for all possible partition of its vertices \(\varvec{c}\), with at least two elements \(\varvec{c}_g\) and \(\varvec{c}_h\), the following inequality holds:
Proof
This is a direct consequence of applying Lemma 1 with \(G\diamond \varvec{c}\) and vertices g and h, which gives \(|\mathcal {T}_{G\diamond \varvec{c}}|=|\varvec{cutset}(G,\varvec{c}_g,\varvec{c}_h)||\mathcal {T}_{G\diamond \varvec{c}/(g,h)}|+|\mathcal {T}_{G\diamond \varvec{c}-(g,h)}|\), and since \(|\mathcal {T}_{G\diamond \varvec{c}-(g,h)}|\ge 0\) the inequality holds. \(\square \)
Putting the previous elements together, we get the following lower bound for the merge scores, which depends only on the clusters g and h:
This quantity can be computed quite efficiently. During the merging process we keep track of the cluster contiguity graph, updating it with edge contraction, so the size of the cutset between two clusters is readily available. The other terms can also be computed efficiently, noting that we can compute \(|\mathcal {T}_{G[\varvec{c}_g\cup \varvec{c}_h]}|\) with a small rank update of the Cholesky factorisation used to compute \(|\mathcal {T}_{G[\varvec{c}_g]}|\) and \(|\mathcal {T}_{G[\varvec{c}_g]}|\) since the Laplacian matrix of \(G[\varvec{c}_g\cup \varvec{c}_h]\) can be written as the sum of a block diagonal matrix with the Laplacian matrices of \(G[\varvec{c}_g]\) and \(G[\varvec{c}_h]\) on the diagonal plus an update for each edge in the (g, h) cutset:
with L(G) the Laplacian matrix of graph G and \(l_{(e)}\), the column vector for edge \(e=(u,v)\) with all elements equal to zero, except element u equal to 1 and element v equal to \(-1\). This allows the use of efficient numerical routines for updating a sparse Cholesky factorization as the ones provided by the cholmod library (Davis and Hager 1999, 2001, 2005). Finally, once the merging process has stopped, a similar approach can be used, but backwards, to compute the terms \(|\mathcal {T}_{G\diamond \varvec{c}^{(t)}}|\) from a previous decomposition of the Laplacian of \(\mathcal {T}_{G\diamond \varvec{c}^{(t-1)}}\). This allows us to compute \(\mathscr {L}^{post}(\varvec{c}\mid \varvec{X},G,\alpha )\) for all the partitions extracted by the hierarchical algorithm, and thus select the best one for any desired value of \(\alpha \). We will even see in the next session that we can easily extract the set of dominant partitions and the range of \(\alpha \) values where they are dominant, allowing the construction of a dendrogram. For an overview of the entire algorithm, see Algorithm 1.

Bayesian Hierarchical Contiguity-constrained clustering
2.5 Dendrogram and prior for the number of clusters

Example of posterior front (a) and corresponding dendrogram (b)
The previous sections has shown how to define a contiguity constrained prior and extract a MAP partition for a given value of \(\alpha \), typically 1 to get a uniform prior over the number of cluster. In this section we will see how to extract the set of dominant partition for all \(\alpha \) values from the partitions extracted by the hierarchical algorithm. This can be useful since in a clustering application, practitioners may have some prior knowledge about the desired number of clusters and would prefer to gain some insight into the evolution of the model description capabilities with respect to this parameter. A classic tool often used in such a setting is the so-called dendrogram, which represents the merge tree of a hierarchical agglomerative clustering algorithm, with branch heights proportional to the difference in criterion values induced by the corresponding merge. A dendrogram is therefore a binary tree in which each node corresponds to a cluster. The edges connect the two clusters (nodes) merged in a given step of the algorithm. The height of the leaves is generally assumed to be 0. The leaves are ordered by a permutation of the initial clusters that ensures that successive merges are neighbours in the dendrogram. The height of the node corresponding to the cluster created at merge t, \(h_t\), is often the value of the linkage criterion.
We propose to revisit this classical tool in the Bayesian context on which this paper is based. Adapting the approach previously proposed in (Côme et al. 2021) to the non-parametric Bayesian setting of the current proposal, we will show that using this prior together with a greedy agglomerative algorithm that produces a hierarchy of nested partitions allows the exact computation of the sequence of regularisation parameters that unlock the fusions. A difference with the previous proposal is that here the sequence of \(\alpha \) values that enable the fusion is computed in an exact manner, without relying on any approximation of the posterior. Going back to the definition of the un-normalised posterior given by Eq. 13 we may aggregate into \(I(\varvec{c},\varvec{X},G)\) all the terms that do not involve \(\alpha \) then we obtain:
The last term of Eq. 19 does not depend on the size of the solutions (i.e. their number of clusters \(\vert \varvec{c}\vert \)) and can therefore be ignored when comparing partitions. This shows that it is sufficient to compute the intersection of two lines to get the exact \(\alpha \) value where one partition outperforms the other. In fact, we can examine the front of all solutions extracted by a greedy agglomerative algorithm in the \(\left( -\log (\alpha ),\mathscr {L}^{post}(\varvec{c}\mid \varvec{X},G,\alpha )\right) \) plane as shown in Fig. 3 a and extract the sequence of regularisation parameters that unlocks the fusions.
These tipping points \(-log(\alpha ^{(t)})\) can then be used to draw a dendrogram, as shown in Fig. 3a. An important point to note is that some of the partitions extracted by an agglomerative greedy algorithm may not be dominant over the others anywhere in \(\alpha \in ]0,1]\). This corresponds to situations where combining several merges in one step is better than performing them sequentially. This is quite natural, since \(\mathscr {L}^{post}\) is a penalised criterion, so it does not necessarily increase with model complexity. Since such partitions cannot belong to the approximated Pareto front over \(\alpha \in [0,1]\), it is sufficient to remove them and to record only the point corresponding to the real change of the partition on the front; with such an approach, several merges may appear at the same level in the dendrogram, as can be seen by looking carefully at Fig. 3b. This approach offers an interesting solution to the problem encountered with classical dendrograms when working with contiguity constraints. Indeed, when using contiguity constraints, it is not guaranteed that the classical criterion (i.e. loss of information) increases (Randriamihamison et al. 2020), leading to difficulties (reversal) which are avoided here. In conclusion, this approach, although reminiscent of classical dendrograms, has several advantages: it naturally avoids the overplotting problems encountered at the bottom of classical dendrograms, since it focuses only on the interesting part of the merging process; it solves the possible reversal problem. Finally, it provides a natural way to interpret the heights of the merges in the dendrograms as the prior parameter value needed to accept the merge.
3 Results and discussion
3.1 Simulation study
To study the performance of the algorithm, we first compare its performance on simulated data in a controlled setting with state-of-the-art clustering algorithms with and without adjacency constraints. Two sets of simulations were performed. We have compared our proposal with several state-of-the-art approaches:
-
mclust: A Gaussian mixture model without contiguity constraints, with automatic model selection. The implementation of the R package mclust, (Scrucca et al. 2016) was used to derive the results. We will also give results for, mclust (K), the same implementation and algorithm with the number of clusters fixed to K, the true number of clusters.
-
skater: The skater algorithm, Assunção et al. (2006), with a number of clusters equal to the real number of clusters. The implementation used is the one available in the rgeoda package.
-
redcap: The redcap algorithm, Guo (2008), with a number of clusters equal to the true number of clusters. The implementation used is the one available in the rgeoda package.
-
azpg: The azp algorithm, Openshaw (1977), with greedy optimization and a number of clusters equal to the true number of clusters. The implementation used is the one available in the rgeoda package.
-
azpsa: The azp algorithm with simulated-annealing optimization (Openshaw and Rao 1995) and a number of clusters equal to the real number of clusters. The implementation used is the one available in the rgeoda package.
-
sppm: The MCMC sampler proposed by Teixeira et al. (2019), for clustering with contiguity constraints.Footnote 1 In each experiment, the sampler was run for 1000 iterations, with a burn-in period of 100 samples and a thinning of 10. To generate the final partition that we will compare to, we used the mcclust.ext package, which allows computing a representative partition of the posterior by minimizing either the posterior expected Binder’s loss (Binder 1978; Fritsch and Ickstadt 2009) or the lower bound of the posterior expected variation of information from Jensen’s inequality (Wade and Ghahramani 2018). We denote these two variants as sspm (VI) and sspm (binder). For all experiments, the parameters of the priors were set as follows: the parameters of the beta prior for edge deletion were set to 5 and 1000 to obtain a rather uninformative prior. The Normal/Gamma prior parameters for the cluster means and variances were set to \(\bar{x}\) the empirical mean of the whole dataset, 0.01, 0.1s with s the sample variance of the dataset, and 1. Using such values one gets a broad prior centered on the dataset mean and variance.
-
sppmsuite: The MCMC sampler proposed by Page and Quintana (2016), for clustering with a spatial product partition model based on distances between cluster centers. The implementation used is the one available in the sppmsuite package. Similar to sppm,the chain was run for 1000 iterations, with a burn-in of 100 iterations and a thinning of 10. To generate the final partition, the same strategy was used as for sppm, so two variants are used sppmsuite (VI) and sppmsuite (binder). The cohesion function used in all experiments was the double-dipper similarity. The grid positions were centered and reduced before being fed into the algorithm and the the cohesion function prior parameters were left at their default values (center of 0, Gaussian scale parameter of 1, inverse Gamma degrees of freedom of 2, inverse Gamma scale of 2). The remaining prior and hyper-prior parameters were set to \(\bar{x}\) for the Gaussian hyper-prior means, 2.s for the Gaussian hyper-prior variance and also 2.s for the upper bound of the uniform distribution on the cluster variances.

Some visual results of the clustering found on the simulated data, the first column corresponds to the simulated data set, other columns correspond to the solutions found by gtclust, mclust, skater, azpg, sppm (binder) and sppmsuite (binder). Each row corresponds to a different value of \(\sigma \in \{0.25,0.75,1.25,1.75\}\). Small clusters with less than 5 elements are shown in white (Skater and Sppmsuite (binder)). (Color figure online)
The solutions obtained with these algorithms were compared with those obtained with our implementation of the algorithm presented in this paper and available in the gtclust R package with a classical Gaussian model. For the analysis, we extracted two solutions from the hierarchy:
-
gtclust: the MAP partition found by the algorithm with \(\alpha =1\).
-
gtclust (K): the partition with K clusters, where K is the real number of simulated clusters.
We use the same prior parameter as for sppm for the normal/gamma i.e. \(\bar{x}\) the empirical mean of the whole data set, 0.01, 0.1s where s is the sample variance of the data set and 1.
We will compare the performance of the algorithm in terms of Normalized Mutual Information (NMI) between the extracted partition and the simulated one. The NMI is an information-theoretic measure that takes values in [0, 1] and allows to compare the results with the ground truth partition (Vinh and Epps 2010). The mutual information describes how much is learned about the true partition when the estimated one is known, and vice versa, and is defined by
Mutual information is not an ideal similarity measure when the two partitions have different numbers of clusters, so it is preferable to use a normalized version of mutual information such as
where \(H(\varvec{c})\) is the entropy of the partition given by
For methods that estimate the number of clusters we will also investigate their behavior with respect to this point and we will also compare the running time of the different algorithms.
3.1.1 Small scale setting

Boxplots of the Normalized Mutual Information with the simulated partition distribution for each algorithm and \(\sigma \) value. Results of optimisation based approach are in blue, those of MCMC approaches in red and those of gtclust in green. (Color figure online)
The data for the first simulation setting, were generated on a regular grid that can be assimilated to an image of 30 by 30 pixels. These images were then divided into 9 square regions (i.e. clusters) of equal size (10 pixels by 10 pixels), each with a different mean, given by:
The data were then simulated with a Gaussian distribution whose mean is determined by the region to which the pixel belongs and whose variance \(\sigma \) varied between \(\{0.25,0.75,1.25,1.5,1.75\}\). These simulations allow us to study the performance of the different algorithms in simple situations (\(\sigma =0.25,0.75\)) as well as in more difficult situations (\(\sigma =1.75\)). The first column of Fig. 4 shows a random sample of simulated images for different values of \(\sigma \). For each \(\sigma \) value on the grid, 50 simulations were performed and the results of each algorithm were recorded.
All algorithms were given the same contiguity graph (constructed with rook adjacency). Some example of the results obtained are shown in Figs. 4 and 5 shows the boxplots of the results obtained by the algorithms in terms of NMI. The results obtained by gtclust are quite good. At low noise levels, it achieves perfect recovery in all the simulations, and at higher noise levels it remains competitive with the MCMC approaches (sppm and sppmsuite) and has better performances than the other methods (which need to know the number of clusters in advance, whereas gtclust has to estimate it). Furthermore, gtclust is also more stable than the other optimization based approaches. Finally, at \(\sigma =1.75\), the MCMC approaches seem to benefit from using other losses than the \(0\backslash 1\) loss, with slightly better results for both versions of sppm and sppmsuite (VI), but these results are achieved at a much higher computational cost has shown by the average running time of the different algorithms given in Table 1. Even in this small scale experiment, the advantage of the proposed approach is clear, its running time around 0.13 s is close to the optimization based approaches (around 0.8 s for mclust which also has to estimate the number of clusters) and much shorter than those of the MCMC approaches (around 16 s for sppmsuite and around 6 min for sppm).
In terms of estimated number of clusters (Table 2), gtclust almost always picks the right number of clusters when \(\sigma \) is below 1.75, for this noise level the MAP partition found is conservative and an average of 6.9 clusters are recovered. sppm (VI) and sppmsuite (VI) are also very good with an average number of estimated clusters around 9. Binder loss seems to be less suitable for this task, especially for sppmsuite, as it leads to an overestimation of the number of clusters, especially for sppmsuite with more than a hundred clusters on average for \(\sigma =1.75\). This is less visible for sppm, but the number of clusters is still over 9. Finally, mclust, which does not use contiguity constraints, suffers quite quickly and finds only two or three clusters even when the noise level is moderate (\(\sigma =0.75\)), clearly demonstrating the interest of contiguity constraints and spatial product partition models to deal with this type of problem. Finally, we also investigated the effect of \(\alpha \) on the performance of the proposed algorithm. The results are detailed in Appendix 1, but they show that the proposed prior and algorithm are quite robust to changes in \(\alpha \) in this experiment. The results with \(\alpha =0.001\) and \(\alpha =1\) are similar for \(\sigma \in \{0.25,0.75,1.25\}\) and decrease slightly for \(\alpha =0.001\) and \(\sigma =1.75\).
3.1.2 Medium scale setting

A sample data set for all possible noise level values for the medium scale setting

Boxplots of the Normalized Mutual Information with the simulated partition distribution for each algorithm and \(\sigma \) value. Results of optimisation based approach are in blue, those of MCMC approaches in red and those of gtclust in green. (Color figure online)
The second set of experiments deals with slightly larger problems than the first. The grid used is a regular grid of 60 pixels by 60 pixels. And the grid contains 36 clusters plus a background cluster. Each cluster is a square of 8 by 8 pixels and all clusters have the same mean of 4 except the background cluster which has a mean of 0. The clusters are aligned leaving a space of two pixels from the background clusters between them. As before we will vary the noise level which in this experiment will take values in \(\{0.5,1,1.5\}\). Figure 6 shows an example data set for each of the possible noise levels. Each experiment was run ten times. As before, the contiguity constrained approaches were fed with the same contiguity graph based on rook adjacency. We designed this set of experiments to analyse two things: the scaling of the different approaches with the problem size and the ability of contiguity constrained based clustering and of gtclust in particular to extract such structure where there is a background cluster that surrounds the others. One hypothesis we wanted to test is that the contiguity constrained and spanning tree prior are better suited for this type of problem than the product partition model of Page and Quintana (2016).
The results in terms of NMI are shown in Fig. 7. In this set of experiments, the results of gtclust are even better, since it achieves results of the same quality as those of sppm, and even slightly better when \(\sigma =1.5\). These two approaches are the best by far. In fact, as expected, the prior used by sppmsuite is less suitable for this problem, resulting in poor performance compared to the two approaches mentioned above. Finally, the optimization-based approaches (skater, redcap, azpg, azpsa) do not reach the performance of the proposed approach and have difficulties in finding the simulated partition even in the low-noise regime. This is especially true for skater, which shows a significant variation in its results.
With respect to the running times of the algorithms given in Table 3, the advantage of gtclust is obvious. In fact, gtclust is the fastest, with a running-time between 0.75 and 3.5 s on a par with the optimisation-based approaches (which work with a fixed number of clusters) and about 100 times faster than sppmsuite and 1500 times faster than sppm.
Finally, with respect to the number of estimated clusters, the results are reported in Table 4. They confirm the trend observed in the previous experiment, gtclust remains close to the true value even when \(\sigma =1.5\), sppmsuite underestimates the number of clusters with VI loss and overestimates it by a large amount with Binder loss. Finally, sppm gives better results with binder loss and underestimates the number of clusters with VI loss for \(\sigma =1.5\).
As before, we also investigated the effect of \(\alpha \) on the performance of the proposed algorithm. The results are detailed in Appendix 1 and, as before, they show that the proposed prior and algorithm are quite robust to changes in \(\alpha \). The results for \(\alpha =0.01\) and \(\alpha =1\) are similar for \(\sigma \in \{0.5,1\}\), it is only when the noise level is high (\(\sigma =1.5\)) that the difference appears with a lower number of estimated clusters and therefore a lower NMI for \(\alpha =0.001\).
To conclude on these experimental results, they show that gtclust is a competitive approaches for contiguity constrained clustering giving results in par with much more costly approaches based on MCMC sampling, and giving better and more stable results than the other approaches like skater, redcap and azp. This confirms the potential of this approach for exploratory analysis with clustering of spatial data and networks. To illustrate this, we present two applications on real datasets.
3.2 Regionalization of french mobility statistics
The first results on real data that we describe come from the analysis of the mobility statistics of the 2018 French census, provided by the French National Institute of Statistics and Economic Studies (INSEE).Footnote 2 Among the information collected for the census, several pieces of information on the main mode of transport are collected, and we analysed the share of residents using: car/transit/motorised two-wheelers/bicycle/footwalking or any other mode as the main mode of transport in the " region centre " of France at a sub-municipal division level called IRIS which stands for Ilots Regroupés pour l’Information Statistique in french. IRIS are geographical units that divide the French municipalities into regions of around 2000 inhabitants. There are 2150 IRIS in the dataset used and they are described by the six variables mentioned above. Geographical units with less than 50 inhabitants were smoothed with a weighted average of their neighbourhood values. We considered the data as compositional and transformed them using an additive log-ratio transformation with the car variable as the reference variable, leaving 5 variables to be analysed. A multivariate Gaussian mixture model with diagonal covariance matrices and Normal-Gamma prior was then applied to these transformed data. The Norma-Gamma conjugate prior is given by \(\mu _k\sim \mathcal {N}\left( \mu ,(\tau . V_kI)^{-1}\right) ,V_k\sim Gam(\kappa ,\beta ),\) with I the identity matrix. The prior parameters were set to \((\tau = 0.01\), \(\kappa = 1\), \(\beta = 0.64\), \(\mu = \bar{\textbf{x}}\)) by studying the dataset mean and variance.

Bayesian dendrogram on the “region centre mobility statics dataset”

Regionalization results on the “region centre mobility statics dataset”

Network clustering results on the "Shenzhen speeds dataset". Data from 9th September 2011, average speed during the 7h30-7h45 timeslot; speed per link map (top-left); clusters map (top-right); dendrogram (bottom-left); boxplots of speeds distributions per clusters (bottom-right). (Color figure online)
The dendrogram of the solution found is shown in Fig. 8 and starts with 23 clusters. As shown in Fig. 9, the main characteristics of the territory are clearly extracted by the algorithm, the main agglomerations (highlighted with labels) form specific clusters, the two largest (Tours and Orléans) are even represented by two clusters (one for the inner city and another for the suburbs), which is easily explained by the higher share of walking and transit use in these regions. Two large clusters divide the region in a north–south direction, with a lower use of transit (and a higher use of walking) in the southern part of the region. Finally, a final cluster in the north-east of the map presents a heavy use of transit and can be explained by important commuting flows with Paris and made to a large extent by transit.
3.3 Traffic speed clustering
The second application on real data that we have carried out deals with traffic speeds on a road network. Such an application is of interest because finding homogeneous traffic zones in road networks can be very helpful for traffic control. An important open question in traffic theory for the application of the Macroscopic Fundamental Diagram (MFD), a classical tool in traffic control, is how best to segment an urban network into regional subnetworks and how to treat endogenous heterogeneity in the spatial distribution of congestion (Ji and Geroliminis 2012; Haghbayan et al. 2021). This segmentation must fulfil several properties: first, the regions must be of reasonable and similar size, and second, they must be topologically connected and compact. Finally, the traffic conditions in each region must be approximately homogeneous (i.e. congestion must be approximately homogeneous in the region). Contiguity constrained clustering therefore seems a natural way to solve this problem and we have investigated the use of the proposed algorithm in this context.
The data used in this section is one of the benchmark datasets used to study this task (Bellocchi and Geroliminis 2019). This dataset concerns the road network of Shenzhen, where the average speed of road segments is estimated every 5 min from map-matched traces of about 20,000 taxi GPS points collected over three days in 2011. In order to replicate the preprocessing steps used in previous studies (Haghbayan et al. 2021), the following preprocessing steps were performed: nodes with no structural role (i.e. that are not intersections) were smoothed (their incoming edges were merged and the associated speed value was taken as the mean of the speeds of the combined edges); average speed values were also computed over 15-minute time intervals. Finally, the graph between road segments was constructed by connecting any two segments connected by an intersection, as shown in Fig. 2. A Gaussian mixture model with Norma-Gamma conjugate prior \(\mu _k\sim \mathcal {N}\left( \mu ,(\tau . V_k)^{-1}\right) ,V_k\sim Gam(\kappa ,\beta ),\) with prior parameters (\(\tau = 0.01\), \(\kappa = 1\), \(\beta = 0.1s^2 \approx 0.62\), \(\mu = \bar{x} \approx 9\)) and the velocities in m/s were then used to cluster the data set.
We present in Fig. 10 the clustering results obtained over the 7h30-7h45 time slot of the 9th of September. The figure shows the observed velocity in a first map and the extracted clusters in another. These two maps are accompanied by the computed dendrogram and per cluster box plots of the observed velocities. The uniform prior leads to 11 clusters, from the dendrogram we can see that the next interesting solutions contain only 5 clusters. The traffic conditions are homogeneous in each cluster, two clusters correspond to free flow zones with an average speed around 50 km/h, the others correspond to congested zones with speeds around 20 km/h or 35 km/h. When aggregated to the next level of interest in the dendrogram, the remaining clusters are the pink, light green and dark blue clusters, the others being merged into a single "non-congested" cluster. Again, the segmentation obtained by clustering seems to be quite coherent and meaningful, showing the interest of the proposal for this type of applications.
4 Conclusion and future works
This paper has introduced a Bayesian approach to contiguity constrained clustering that allows semi-automatic tuning of the model complexity (number of clusters), together with an efficient algorithm for finding a MAP partition and building a Bayesian dendrogram from it. A simulation study has shown the interest of this algorithm compared to other solutions for contiguity constrained clustering and its ability to recover the number of clusters. Finally, two experiments on real data have demonstrated the applicability of the proposal on real test cases. From an algorithmic point of view, it would be interesting to compare the hierarchical approach used in this proposal with other solutions that will also leverage the results obtained in this paper in Sect. 2.3 to efficiently compute the posterior distribution of the partition. It would be possible to consider algorithms based on local swap moves (in the spirit of the Louvain and Leiden algorithms) or a more classical Bayesian approach of the MCMC type, which would make it possible to obtain a complete sample of the a posteriori distribution of the partition. The latter could use a Metropolis-Hasting type algorithm as in Peixoto (2019), and take advantage of the contiguity constraints to limit the number of possible swaps and thus the number of rejected moves. Such a full Bayesian treatment would allow the use of other losses such as VI or Binder loss (Wade and Ghahramani 2018), which could be useful in the high noise regime.
From a modelling point of view, we have mainly illustrated the proposal with Gaussian Mixture Models, but as the proposal is quite general, other models should be investigated (Poisson, Mulitnomial,...). In this spirit, we are currently working on a solution based on the Laplace approximation to deal with more complex observation models where conjugate priors do not exist.
5 Supplementary information
All codes and data needed to reproduce the results of this paper are bundled in the R package gtclust available at http://github.com/comeetie/gtclust.
Notes
References
Ambroise, C., Dehman, A., Neuvial, P., et al.: Adjacency-constrained hierarchical clustering of a band similarity matrix with application to genomics. Algorithms Mol. Biol. 14(1), 22 (2019)
Angriman, E., Predari, M., van der Grinten, A., et al.: Approximation of the diagonal of a Laplacian’s pseudoinverse for complex network analysis. In: Grandoni, F., Herman, G., Sanders, P. (eds.) 28th Annual European Symposium on Algorithms (ESA 2020), Leibniz International Proceedings in Informatics (LIPIcs), vol. 173, pp. 6:1–6:24. Schloss Dagstuhl-Leibniz-Zentrum für Informatik, Dagstuhl, Germany (2020). https://doi.org/10.4230/LIPIcs.ESA.2020.6, https://drops.dagstuhl.de/opus/volltexte/2020/12872
Anselin, L.: Spatial Econometrics, vol. 310330, pp. 310–330. Wiley, Hoboken (2001)
Assunção, R.M., Neves, M.C., Câmara, G., et al.: Efficient regionalization techniques for socio-economic geographical units using minimum spanning trees. Int. J. Geogr. Inf. Sci. 20(7), 797–811 (2006). https://doi.org/10.1080/13658810600665111
Barry, D., Hartigan, J.A.: A Bayesian analysis for change point problems. J. Am. Stat. Assoc. 88(421), 309–319 (1993). https://doi.org/10.1080/01621459.1993.10594323
Bates, D., Maechler, M.: Matrix: Sparse and Dense Matrix Classes and Methods (2019). https://CRAN.R-project.org/package=Matrix, r package version 1.2-17
Bellocchi, L., Geroliminis, N.: Shenzhen Whole Day Speeds (2019). https://doi.org/10.6084/m9.figshare.7212230.v2, figshare.com/articles/dataset/Shenzhen_whole_day_Speeds/7212230
Biernacki, C., Celeux, G., Govaert, G.: Assessing a mixture model for clustering with the integrated completed likelihood. IEEE Trans. Pattern Anal. Mach. Intell. 7, 719–725 (2000)
Biernacki, C., Celeux, G., Govaert, G.: Exact and Monte Carlo calculations of integrated likelihoods for the latent class model. J. Stat. Plan. Inference 140, 2991–3002 (2010)
Binder, D.: Bayesian cluster analysis. Biometrika 65, 31–38 (1978)
Blondel, V.D., Guillaume, J.L., Lambiotte, R., et al.: Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008(10), P10,008 (2008)
Bondy, A., Murty, U.: Graph theory. In: Graduate Texts in Mathematics. Springer, London (2011). https://books.google.fr/books?id=HuDFMwZOwcsC
Breiman, L.: Classification and Regression Trees. The Wadsworth & Brooks/Cole (1984)
Cayley, A.: A theorem on trees. Quat. J. Math. 23, 376–378 (1889)
Chavent, M., Kuentz-Simonet, V., Labenne, A., et al.: ClustGeo: an R package for hierarchical clustering with spatial constraints. Comput. Stat. 33(4), 1799–1822 (2018). https://doi.org/10.1007/s00180-018-0791-1
Chen, Y., Davis, T., Hager, W., et al.: Algorithm 887: CHOLMOD, supernodal sparse Cholesky factorization and update/downdate. ACM Trans. Math. Softw. 35, 22:1-22:14 (2008). https://doi.org/10.1145/1391989.1391995
Côme, E., Latouche, P., Jouvin, N., et al.: Hierarchical clustering with discrete latent variable models and the integrated classification likelihood. Adv. Data Anal. Classif. (2021). https://doi.org/10.1007/s11634-021-00440-z
Davis, T.A., Hager, W.W.: Modifying a sparse Cholesky factorization. SIAM J. Matrix Anal. Appl. 20, 606–627 (1999). https://doi.org/10.1137/S0895479897321076
Davis, T.A., Hager, W.W.: Multiple-rank modifications of a sparse Cholesky factorization. SIAM J. Matrix Anal. Appl. 22, 997–1013 (2001). https://doi.org/10.1137/S0895479899357346
Davis, T.A., Hager, W.W.: Row modifications of a sparse Cholesky factorization. SIAM J. Matrix Anal. Appl. 26, 621–639 (2005). https://doi.org/10.1137/S089547980343641X
Diaconis, P., Ylvisaker, D.: Conjugate priors for exponential families. Ann. Stat. 7, 269–281 (1979)
Eddelbuettel, D., Balamuta, J.J.: Extending extitR with extitC++: A Brief Introduction to extitRcpp. PeerJ Preprints 5, e3188v1 (2017). https://doi.org/10.7287/peerj.preprints.3188v1
Eddelbuettel, D., Sanderson, C.: RcppArmadillo: accelerating r with high-performance C++ linear algebra. Comput. Stat. Data Anal. 71, 1054–1063 (2014). https://doi.org/10.1016/j.csda.2013.02.005
Fritsch, A., Ickstadt, K.: An improved criterion for clustering based on the posterior similarity matrix. Bayesian Anal. (2009). https://doi.org/10.1214/09-BA414
Gordon, A.: A survey of constrained classification. Comput. Stat. Data Anal. 21, 17–29 (1996)
Gramacy, R.B., Lee, H.K.H.: Bayesian treed gaussian process models with an application to computer modeling. J. Am. Stat. Assoc. 103(483), 1119–1130 (2008). https://doi.org/10.1198/016214508000000689
Grimm, E.C.: CONISS: a FORTRAN 77 program for stratigraphically constrained analysis by the method of incremental sum of squares. Comput. Geosci. 13, 13–35 (1987)
Guo, D.: Regionalization with dynamically constrained agglomerative clustering and partitioning (redcap). Int. J. Geogr. Inf. Sci. 22(7), 801–823 (2008). https://doi.org/10.1080/13658810701674970
Haghbayan, S.A., Geroliminis, N., Akbarzadeh, M.: Community detection in large scale congested urban road networks. PLoS ONE 16(11), 1–14 (2021). https://doi.org/10.1371/journal.pone.0260201
Hartigan, J.: Partition models. Commun. Stat. Theory Methods 19(8), 2745–2756 (1990). https://doi.org/10.1080/03610929008830345
Hayashi, T., Akiba, T., Yoshida, Y.: Efficient algorithms for spanning tree centrality. In: Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), pp. 3733–3739 (2016)
Hegarty, A., Barry, D.: Bayesian disease mapping using product partition models. Stat. Med. 27(19), 3868–3893 (2008). https://doi.org/10.1002/sim.3253
Ji, Y., Geroliminis, N.: On the spatial partitioning of urban transportation networks. Transp. Res. Part B Methodol. 46, 1639–1656 (2012)
Kirchhoff, G.: Über die auflösung der gleichungen, auf welche man bei der untersuchung der linearen vertheilung galvanischer ströme geführt wird. Ann. Phys. 148, 497–508 (1847). https://doi.org/10.1002/andp.18471481202
Lebart, L.: Programme d’agrégation avec contraintes. Cahiers de l’analyse des données 3(3):275–287 ( 1978). http://www.numdam.org/item/CAD_1978__3_3_275_0/
Masser, I., Brown, P.J.B.: Hierarchical aggregation procedures for interaction data. Environ. Plan. A 7, 509–523 (1975)
Murtagh, F.: A survey of algorithms for contiguity-constrained clustering and related problems. Comput. J. 28, 82–88 (1985)
Murtagh, F., Contreras, P.: Algorithms for hierarchical clustering: an overview. WIREs Data Min. Knowl. Discov. 2(1), 86–97 (2012). https://doi.org/10.1002/widm.53
Openshaw, S.: A geographical solution to scale and aggregation problems in region-building, partitioning and spatial modeling. Trans. Inst. Br. Geogr. 2, 459–72 (1977)
Openshaw, S., Rao, L.: Algorithms for reengineering the 1991 census geography. Environ. Plan. A 27, 425–46 (1995)
Page, G.L., Quintana, F.A.: Spatial product partition models. Bayesian Anal. 11(1), 265–298 (2016). https://doi.org/10.1214/15-BA971
Pebesma, E.: Simple features for R: standardized support for spatial vector data. R J. 10(1), 439–446 (2018). https://doi.org/10.32614/RJ-2018-009
Peixoto, T.P.: Bayesian Stochastic Blockmodeling, vol. 11, pp. 289–332. John Wiley & Sons Ltd, Hoboken (2019). https://doi.org/10.1002/9781119483298.ch11
Core Team, R.: R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria (2019). https://www.R-project.org/
Randriamihamison, N., Vialaneix, N., Neuvial, P.: Applicability and interpretability of ward hierarchical agglomerative clustering with or without contiguity constraints. J. Classif. (2020). https://doi.org/10.1007/s00357-020-09377-y
Rasmussen, C., Ghahramani, Z.: Infinite mixtures of gaussian process experts. In: Dietterich, T., Becker, S., Ghahramani, Z. (eds.) Proceedings of NIPS, vol. 14. pp. 881–888. MIT Press (2001)
Schwaller, L., Robin, S.: Exact Bayesian inference for off-line change-point detection in tree-structured graphical models. Stat. Comput. 27, 1331–1345 (2017). https://doi.org/10.1007/s11222-016-9689-3
Schwaller, L., Robin, S.: Exact Bayesian inference for off-line change-point detection in tree-structured graphical models. Stat. Comput. 27, 1331–1345 (2017). https://doi.org/10.1007/s11222-016-9689-3
Teixeira, L.V., Assunção, R.M., Loschi, R.H.: Bayesian space-time partitioning by sampling and pruning spanning trees. J. Mach. Learn. Res. 20(85), 1–35 (2019)
Traag, V.A., Waltman, L., Van Eck, N.J.: From Louvain to Leiden: guaranteeing well-connected communities. Sci. Rep. 9(1), 1–12 (2019)
Vinh, N.X., Epps, J.: Information theoretic measures for clusterings comparison: variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 11, 2837–2854 (2010)
Wade, S., Ghahramani, Z.: Bayesian cluster analysis: point estimation and credible balls (with discussion). Bayesian Anal. 13(2), 559–626 (2018). https://doi.org/10.1214/17-BA1073
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Exponential family evidences
Since the \(\varvec{X}_i\)’s follow an exponential family distribution the pdf for one data can be written as:
with \(\Phi (\varvec{\theta })\) the natural parameter. The likelihood of one cluster is then given by:
with \(\textbf{T}_{\varvec{c}_k}=\sum _{i\in \varvec{c}_k}\textbf{T}(\textbf{x}_i)\). Following Diaconis and Ylvisaker (1979) and taking a prior of the form:
we observe it’s conjugacy:
and the posterior over \(\varvec{\theta }_{\varvec{c}_k}\) is thus:
And since
the evidence for cluster \(\varvec{c}_k\) is given by:
and consequently:
with \(cst=\sum _{i=1}^N\log \left( b(\textbf{x}_i)\right) \) independent of \(\varvec{c}\). As an example, if we take a Poisson / Gamma model, we may write:
thus:
and therefore:
with cst a constant independent of \(\varvec{c}\).
Appendix B: Stability of the results with respect to alpha for simulation 1
See Table 5
Appendix C: Stability of the results with respect to alpha for simulation 2
See Table 6
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Côme, E. Bayesian contiguity constrained clustering. Stat Comput 34, 64 (2024). https://doi.org/10.1007/s11222-023-10376-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-023-10376-3