
Abstract
Based on a large real-world dataset comprising Instagram posts of popular influencers, this study empirically analyzes the impact of disclosed and undisclosed advertising on consumers’ engagement with (a) the advertisement and (b) future non-advertising posts of the same author. As extant research reports inconsistent effects of ad disclosures based on inferred motives, persuasion knowledge, and source credibility, this study develops a conceptual framework incorporating these theoretical concepts. To identify undisclosed advertisements, we use data from regions with proper disclosure culture to train a model to predict if posts are advertising. Based on the predictions for > 65,000 posts of 239 macro-influencers, we find that advertising posts gather less engagement than non-advertising posts. Regarding immediate ad engagement, we find that disclosed ads gather less engagement than undisclosed ads. Contrastingly, when analyzing future engagement, we identify positive persistent effects of disclosed advertising and negative persistent effects of undisclosed advertising on consumers’ engagement with future posts of the same author. We conclude that source credibility explains the effect of disclosures on future posts, while the Persuasion Knowledge Model can explain the effect of disclosures on the current advertisement. Thus, consumers’ coping strategies triggered by activated persuasion knowledge are mostly limited to the advertisement. Our findings can explain the opposing results of extant research. From a managerial perspective, we find that by not disclosing advertising posts, influencers and marketers increase an ad’s engagement levels at the expense of persistently lowered attitudes. Conversely, in the long run, they may benefit from transparent disclosures.
Similar content being viewed by others


Introduction
During the last decade, marketing activities of companies experienced a shift from mass media (above-the-line) to more targeted (below-the-line) marketing (Hinz, Skiera, Barrot, & Becker, 2011). Especially influencer marketing has risen fast and is now a widely accepted part of a company’s marketing mix (Influencer Marketing Hub, 2020; F. Li, Larimo, & Leonidou, 2021; Mediakix, 2019; Steinhoff, Arli, Weaven, & Kozlenkova, 2019). As a highly personal form of online marketing, influencer marketing differs from traditional celebrity endorsement (Waltenrath, Brenner, & Hinz, 2022) and is considered effective because consumers maintain a close parasocial relationship with the influencer — i.e., a one-sided relationship that consumers build through media — with the individual that communicates the marketing message, the so-called influencer. Influencers foster such parasocial relationships by regularly interacting with their audience and sharing private content. Their product recommendations are thus perceived as more relevant (Chung & Cho, 2017; Colliander & Dahlén, 2011; De Veirman, Cauberghe, & Hudders, 2017).
Influencers are users who regularly post about some areas of expertise or passion, accumulate large audiences, and are recruited by firms to influence potential buyers (Audrezet, de Kerviler, & Guidry Moulard, 2020; De Jans, Cauberghe, & Hudders, 2018; De Veirman et al., 2017). In practice, influencers mix editorial or personal content with advertisements, which makes it hard for consumers to recognize advertising content (Boerman, Willemsen, & Van Der Aa, 2017; De Veirman & Hudders, 2020; Wojdynski & Evans, 2016). Advertising disclosures can improve consumers’ ad recognition (Boerman et al., 2017; Eisend, van Reijmersdal, Boerman, & Tarrahi, 2020; Evans, Phua, Lim, & Jun, 2017; D. Y. Kim & Kim, 2021). However, as advertisers fear the negative effects of disclosures (Sahni & Nair, 2020), they are tempted to avoid disclosing content as advertising and employ covert tactics to make advertisements appear less disruptive and evoke more favorable attitudes towards the ad, product, and brand (De Veirman & Hudders, 2020; Evans, Wojdynski, & Hoy, 2019). Influencers may avoid disclosures for the same reasons or because advertisers persuade them to do so (Touma & Chamas, 2021). To protect consumers from such deceptive advertising practices, government institutions all over the world responded to the ongoing public discussion (Steward, 2019; Thomasson & Neely, 2021) by stressing the need for advertising disclosures (Federal Trade Commission, 2019; S. J. Kim, Maslowska, & Tamaddoni, 2019; Sahni & Nair, 2020; Steward, 2019; Zialcita, 2019).
In light of this conflict of interests, researchers analyzed the effect of disclosuresFootnote 1 in various social media settings. Interestingly, extant research reports opposing results based on conflicting theoretical arguments, which makes it hard to derive meaningful practical and theoretical insights (Hudders, De Jans, & De Veirman, 2021; Lou, 2021; Ye, Hudders, De Jans, & De Veirman, 2021). On the one hand, related studies find that ad disclosures enhance ad recognition, which activates coping strategies such as increased skepticism and lowers consumers’ engagement intentions (Boerman et al., 2017; Eisend et al., 2020; Evans et al., 2017; D. Y. Kim & Kim, 2021; X. Wang, Xu, Luo, & Peng, 2022). On the other hand, in line with industry recommendations (Touma & Chamas, 2021), other studies question if the application of covert tactics is optimal in online (Sahni & Nair, 2020; W. Wang & Wang, 2019) and influencer marketing contexts (De Jans et al., 2018; Evans et al., 2019; Saternus & Hinz, 2021). These studies argue, among other things, that consumers understand an influencer’s need to earn money and value transparent disclosures (Lou, 2021), implying a positive effect of disclosures on consumers’ engagement intentions.
A possible explanation for the opposing results of extant research is that some studies may not adequately incorporate the enduring parasocial relationships between an influencer and its audience. As these parasocial relationships are considered key for influencer marketing effectiveness and the effect of disclosures (Chung & Cho, 2017; Saternus, Weber, & Hinz, 2022; X. Wang et al., 2022), incorporating them as close to reality as possible is essential. Specifically, as most extant studies are based on surveys or laboratory experiments, their artificial settings may — despite these methods’ undisputed advantages — not always adequately reflect consumers’ real-world behavior (Evans et al., 2017; Sahni & Nair, 2020). An empirical approach, such as the one carried out by this study, can overcome this limitation.
Further, from a theoretical perspective, extant research explains their results based on various concepts such as source credibility, inferred motives, or persuasion knowledge which take effect through different mechanisms. In this study’s conceptual framework, we outline that these mechanisms operate differently on different time horizons, depending on the subject of study. For example, while the message’s sender induces the effect through source credibility which may thus persist and also affect an author’s future posts, the consumers’ ad recognition triggers the effect through persuasion knowledge which may (mostly) be limited to the current advertisement as its prerequisite is an active persuasion attempt.
Thus, to contribute to the mostly survey-based discussion, this study presents the concepts and mechanisms of extant literature and develops an appropriate conceptual framework. Based on this framework, we conduct two large-scale empirical analyses to quantify the current (study 1) and persistent (study 2) effects of ad disclosures in influencer marketing. In the first study, we focus on the advertisement, i.e., the advertising (sponsored) social media post, and compare the performance of disclosed advertising to the performance of undisclosed advertising to infer the net effect of disclosures on ad engagement. We introduce ad engagement as a proxy for consumers’ attitudes towards the post and the associated products, brands, and author (van Doorn et al., 2010). In the second study, we investigate the persistent effects of disclosed and undisclosed advertising on future, non-advertising (organic) posts of the same author. Thereby, this study provides empirical evidence that may be valuable for decision-makers such as influencers, regulators, and firms. From a theoretical perspective, we align the mechanisms identified in extant research with the results of two large-scale empirical analyses to identify the dominant mechanisms regarding the current (study 1) and persistent (study 2) effects of ad disclosures. Thereby, this study sheds light on the reasons for the opposing results of extant research.
Conceptual framework
Consumers’ attitudes
This framework presents theoretical concepts and develops hypotheses based on the theory associated with disclosures in extant research. To derive the effect of disclosures, we rely on findings related to consumers’ attitudes. The concept of consumers’ attitudes comprises the feelings, beliefs, and behavioral intentions of consumers towards an object such as a social media post, influencer, brand, or product. Consumers’ attitudes are one of the most important factors that affect engagement behavior (van Doorn et al., 2010) and are positively related to social media engagement metrics (de Vries, Gensler, & Leeflang, 2012; Farace et al., 2020). In this framework, we derive the effect of disclosures on consumers’ attitudes, which we operationalize as engagement, based on three main concepts that literature associates with adverse effects: inferred motives, persuasion knowledge, and source credibility.
Inferred motives
The multiple inference model (Reeder, Vonk, Ronk, Ham, & Lawrence, 2004) describes the process of deriving multiple motives from a person’s behavior. According to the multiple inference model, motives can be affective, normative, or calculative (Woisetschläger, Backhaus, & Cornwell, 2017). In influencer marketing, consumers react to influencers’ content based on their inferred motives (Rosengren & Campbell, 2021). While inferred affective or normative motives are associated with higher attitudes and positive responses, the opposite holds for calculative motives (D. Y. Kim & Kim, 2021; Woisetschläger et al., 2017). In influencer marketing, genuine emotion is an affective motive, whereas being motivated by a (possibly financial) compensation depicts a calculative motive (D. Y. Kim & Kim, 2021). A good fit of influencer and product can signal genuine intentions, i.e., foster inferred affective motives (D. Y. Kim & Kim, 2021). Further, the discounting principle (Kelley, 1973) applies to the inferred motives, suggesting that a specific motive’s effect is reduced if multiple motives are present and plausible, leaving consumers in doubt about an influencer’s true motivation.
Persuasion knowledge
We describe the set of knowledge and skills to cope with advertising by the term persuasion knowledge (Friestad & Wright, 1994). If consumers recognize a persuasion attempt by an influencer, they use their persuasion knowledge to infer the underlying motives and evaluate if they want to resist the persuasion (De Veirman & Hudders, 2020).
The Persuasion Knowledge Model (PKM) (Friestad & Wright, 1994) forms the theoretical base for most research on ad disclosures. It states that consumers who recognize a persuasion attempt may show reactance as they do not like to be manipulated (Brehm, 1989). Once their persuasion knowledge is activated, consumers select and execute coping strategies, such as increased skepticism or resistance (Boerman, van Reijmersdal, & Neijens, 2015; Boerman et al., 2017; De Jans et al., 2018; Evans et al., 2017; Rozendaal, Lapierre, van Reijmersdal, & Buijzen, 2011). Thereby, they rely on their prior experience such that being familiar with advertising practices affects consumers’ reactions (W. Wang & Wang, 2019). If activated, persuasion knowledge alters consumer behavior (Boerman, van Reijmersdal, & Neijens, 2012, 2014), affects ad effectiveness (Campbell, Mohr, & Verlegh, 2013), and eventually leads to negative effects on attitudes (Campbell & Kirmani, 2000; Eisend & Tarrahi, 2022; S. J. Kim et al., 2019). However, if consumers do not infer calculative motives, they might impair the application of coping strategies (De Veirman & Hudders, 2020; Friestad & Wright, 1994; Isaac & Grayson, 2016). High persuasion knowledge does not always activate undesired behaviors; instead, it reflects consumers’ confidence and prior experience in coping with (the given type of) persuasion attempts (Friestad & Wright, 1994; Isaac & Grayson, 2016; Jung & Heo, 2019; J. Lee, Kim, & Ham, 2016; Saternus et al., 2022).
Source credibility
Source credibility describes if a person is perceived as believable, factual, unbiased, or true; and is attached to the sender of the message (Hass, 1981). Thus, source credibility may affect the sender’s current and future messages, providing the theoretical base for the persistent effects that carry over to an author’s future posts and were identified in extant research (Unnava & Aravindakshan, 2021). The source credibility model decomposes credibility into the dimensions expertness (expertise, knowledge), trustworthiness (honesty, morality), and likability (or attractiveness) (Flanagin & Metzger, 2007; Hovland, Janis, & Kelley, 1953; McGuire, 1985; Ohanian, 1990; Stubb & Colliander, 2019). Generally, the level of source credibility affects related attitudes and influences the effect of disclosures by favoring the inference of either calculative or genuine (normative, affective) motives (Hudders et al., 2021; D. Y. Kim & Kim, 2021; Lou & Yuan, 2019; X. Wang et al., 2022). In influencer marketing, consumers’ close parasocial relationships with influencers foster perceived source credibility (Reinikainen, Munnukka, Maity, & Luoma-aho, 2020; Saternus et al., 2022).
Development of hypotheses and results of extant research
Disadvantages of disclosing
Disclosures help consumers to recognize advertising content, interrupt their experience, and activate persuasion knowledge, negatively affecting ad effectiveness (Eisend et al., 2020). Since disclosures are a strong lead for calculative motives (D. Y. Kim & Kim, 2021; S. J. Kim et al., 2019), they may negatively affect consumers’ attitudes. Conversely, following the discounting principle, the absence of disclosures leaves genuine motives plausible, mitigating the negative effects of calculative motives (D. Y. Kim & Kim, 2021). Further, disclosures may cause consumers to perceive influencers as biased (De Veirman et al., 2017; Hwang & Jeong, 2016) or feel deceived when recognizing that an influencer has been paid (Campbell & Kirmani, 2000; De Jans et al., 2018; Eisend et al., 2020). These reactions can reduce source credibility, which has a negative impact on consumers’ attitudes (De Veirman & Hudders, 2020; Eisend et al., 2020; Friestad & Wright, 1994; Lou & Yuan, 2019). Because consumers’ attitudes are one of the most important factors that affect consumers’ engagement behavior (van Doorn et al., 2010), we formulate H1a.
-
H1a: Disclosed advertising posts gather less engagement than undisclosed advertising posts.
Benefits of disclosing
Some research argues that ad recognition is determined mostly by characteristics other than disclosures, such as the post’s creative elements and consumers’ prior experience with the given type of advertising (Boerman & Müller, 2022; Jung & Heo, 2019). Disclosures may increase ad recognition only moderately (De Jans et al., 2018; Jung & Heo, 2019), while many consumers recognize undisclosed ads anyway (Evans et al., 2019). Consumers, especially those experienced with this type of advertising (high persuasion knowledge), may recognize undisclosed ads, infer calculative motives, and experience a negative effect on attitudes towards the post (Boush, Friestad, & Rose, 1994; Evans et al., 2019; Waiguny, Nelson, & Terlutter, 2014). Compared to disclosed ads, undisclosed ads may evoke an even greater degree of reactance as they are perceived as particularly manipulative (Evans et al., 2019) which implies strong calculative motives. Therefore, recognized undisclosed ads may substantially reduce source credibility (Carr & Hayes, 2014) and, in turn, gather less engagement than disclosed ads. Conversely, ad disclosures depict a credible tactic that enhances perceived transparency — i.e., a consumer’s perception of the clarity of the message’s paid nature (Wojdynski, Evans, & Hoy, 2018) — which may lead to a positive effect on source credibility and attitudes towards the post (Amazeen & Wojdynski, 2019; Evans et al., 2019; Isaac & Grayson, 2016; Krouwer, Poels, & Paulussen, 2020). Especially consumers experienced with this type of advertising (high persuasion knowledge) may understand an influencer’s need to earn money and thus value clear disclosures instead of taking them as a hint for calculative motives (Lou, 2021; Saternus et al., 2022; W. Wang & Wang, 2019). Most importantly, the close parasocial relationships of influencers with their audiences may moderate the effect of disclosures and make consumers more likely to value clear disclosures rather than to perceive ads as deceptive (Boerman, 2020; Saternus & Hinz, 2021; W. Wang & Wang, 2019). Contradicting H1a, we can thus also hypothesize that disclosed ads gather more engagement:
-
H1b: Disclosed advertising posts gather more engagement than undisclosed advertising posts.
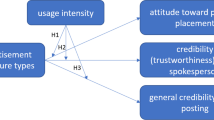
To illustrate the rationales of H1a and H1b, we visualize the proposed effects through inferred motives, source credibility, and persuasion knowledge in Fig. 1.

Illustration of the study’s conceptual framework (H1a/H1b)
Effects of disclosed and undisclosed advertising on future posts of the same author
Both H1a and H1b rely on arguments based on source credibility, inferred motives, and persuasion knowledge. As source credibility is attached to the sender of the message, the associated effects may not be limited to the advertisement but carry over to future posts of the same author. Based on this mechanism, all proposed effects via source credibility may affect consumers’ engagement intentions with an author’s future posts and thus persistently affect engagement levels. On the other hand, the arguments on inferred motives and persuasion knowledge draw on the presence of monetary incentives (to infer calculative motives) and active persuasion attempts. Therefore, they do not apply to future posts and, instead, may affect future engagement only indirectly via source credibility. For example, a current ad’s persuasion attempt or calculative motive may, in the first place, not affect engagement with a future non-advertising post, but reduce source credibility which, in turn, affects how consumers perceive future posts.
By reiterating the arguments on source credibility from above, we hypothesize persistent effects equivalent to H1a: Disclosures may signal that influencers are biased, which lowers source credibility and reduces consumers’ attitudes towards future posts. As engagement is a behavioral manifestation of consumers’ attitudes (van Doorn et al., 2010), we formulate:
-
H2a: Disclosed advertising is negatively associated with consumers’ engagement with future posts of the same author.
Similarly, we adapt the arguments on source credibility of H1b: If consumers recognize undisclosed ads, they may feel deceived, reducing source credibility and leading to less engagement with future posts. Conversely, clear ad disclosures may enhance perceived transparency, leading to a positive effect on source credibility and more favorable evaluations of future posts.
-
H2b: Disclosed advertising is positively associated with consumers’ engagement with future posts of the same author.
To illustrate the rationales of H2a and H2b, we visualize the proposed effects in Fig. 2.

Illustration of the study’s conceptual framework (H2a/H2b)
We conclude that the composition of the audience and their relationship with the author may be crucial for identifying which of the contradicting hypotheses (H1a/H1b and H2a/H2b) dominate. According to theory, the individual level of persuasion knowledge and perceived source credibility might tip the scales regarding consumers’ perception of disclosures.
Review of extant literature
A recent meta-analysis concludes that disclosures reduce attitudes via ad recognition, persuasion knowledge, resistance, and credibility (Eisend et al., 2020), which supports the arguments behind H1a/H2a. Relatedly, studies in the context of social media find that disclosures enhance ad recognition while decreasing consumers’ attitudes (D. Y. Kim & Kim, 2021), purchase intention (X. Wang et al., 2022), intention to engage with the social media post (Boerman et al., 2017; Evans et al., 2017), or perceived source credibility (De Jans et al., 2018; De Veirman & Hudders, 2020). For sponsored news, disclosures were found to decrease the perceived quality, attitude towards the sponsor, and intention to share (Wojdynski, 2016). Finally, a study on green living influencers supports that inferred calculative motives result in reduced attitudes (Pittman & Abell, 2021).
Contrary, in line with the arguments of H1b/H2b, other extant research finds that persuasion knowledge may not always lead to less engagement. Instead, the effect may be driven by perceived intrusiveness and manipulativeness (J. Lee et al., 2016). Persuasion knowledge may even result in positive evaluations if agents employ credible tactics (Isaac & Grayson, 2016). Also, ads are not always associated with negative attitudes because consumers value the contained information (Boerman, 2020; Djafarova & Trofimenko, 2019). Empirically, disclosures have been shown to foster conversions in a large-scale field experiment on paid search advertising (Sahni & Nair, 2020). H1b and H2b are also supported by results suggesting that disclosures do not damage the relationship with the influencer (Boerman, 2020; De Jans et al., 2018). Instead, high perceived transparency (De Jans et al., 2018; Evans et al., 2019) or genuine motives (D. Y. Kim & Kim, 2021) mitigate the negative effects of ad recognition. In online contexts, multiple studies on influencer marketing support that disclosures are a credible tactic that can achieve positive evaluations of posts and influencers, especially in the presence of parasocial relationships (Kay, Mulcahy, & Parkinson, 2020; Saternus & Hinz, 2021; Saternus et al., 2022; W. Wang & Wang, 2019). Relatedly, impartiality or honesty disclosures can enhance credibility and induce positive reactions (Hwang & Jeong, 2016; Stubb & Colliander, 2019).
Methodology
Two-step transfer approach
Generally, this study employs machine learning techniques to identify undisclosed ads, investigate consumers’ perceptions, and derive theoretical implications. It thus relates to the research genre of computationally intensive theory construction described by Miranda, Berente, Seidel, Safadi, and Burton-Jones (2022). The main idea of this study is to perform a large-scale empirical analysis to investigate the effects associated with disclosed and undisclosed advertising. Due to the large sample size, we cannot rely on manual coding to identify undisclosed ads, which would be the preferred method for smaller sample sizes. To overcome this problem, we propose a two-step transfer approach, which relies on training a model based on properly disclosed posts to predict a post’s advertising nature. For model training, we use data from a region with high disclosure compliance. We then apply (“transfer”) the trained model to our main dataset. Based on the model’s predictions, we identify undisclosed ads within the main dataset. In the second step, we can then perform analyses to investigate the effects associated with disclosed and undisclosed ads. By applying this approach, we can estimate the effects of disclosures based on a large sample, which enables us to empirically investigate the opposing results of extant research. To assure the quality of model predictions, we perform several validation checks.
Specifically, we exploit that disclosure compliance is high in German-speaking countries, whereas, on a global scale, the attempts of government institutions to enforce proper disclosures have not yet been successful. A recent assessment finds that only 14% of influencer posts comply with guidelines (Influencer Marketing Hub, 2020). In Germany, laws are strict and lawsuits against well-known influencers have drawn public attention — including seven cases brought to the German supreme court in 2021 (Lenhardt, 2020; Terhaag & Schwarz, 2021; Thomasson & Neely, 2021). This attention fostered a rather strict disclosure culture in German-speaking countriesFootnote 2. We exploit this situation by training the model based on data from English-speaking influencers of German-speaking regions. We train the model to identify posts that resemble the ads of the training set, i.e., to predict the advertising nature of social media posts (step 1.1 in Fig. 3). After validating model performance, we calculate model predictions for a different, global (English-speaking) dataset (step 1.2 in Fig. 3). We then use the model predictions to identify undisclosed advertisements (step 2.1 in Fig. 3) and perform two analyses based on the global dataset (step 2.2 in Fig. 3). Figure 3 illustrates this approach.

Visualization of this study’s two-step transfer approach
Data and variable operationalization
Influencers seek attention that consumers express by interacting, i.e., engaging with the influencers’ posts (Smith & Fischer, 2021; van Krieken, 2019). Consumers’ attitudes are one of the most important factors that affect engagement behavior (van Doorn et al., 2010). By clicking the like button of a post, consumers express that they appreciate its content. This action depicts a behavioral manifestation of ad engagement and thus works as an indicator of ad success (Boerman et al., 2017; Eslami, Ghasemaghaei, & Hassanein, 2021; Peters, Chen, Kaplan, Ognibeni, & Pauwels, 2013; van Doorn et al., 2010), which may positively influence the behavior of other consumers (Grahl, Hinz, Rothlauf, Abdel-Karim, & Mihale-Wilson, 2023; K. Lee, Lee, & Oh, 2015; Naylor, Lamberton, & West, 2012). Since engagement is considered the top influencer marketing metric (Mediakix, 2019) and depicts a key activity for social media marketing (F. Li et al., 2021) which can positively influence purchase likelihood (Bhattacharyya & Bose, 2020), this study uses the number of likes (LIKES) that are gathered by a post as an operationalization of post success. To measure how effectively an advertising post conveys its message, this study compares the success of advertising posts to the success of non-advertising posts. Typically, one expects advertising posts to be less successful, i.e., gather less engagement (LIKES), than non-advertising posts. Thus, we expect advertising posts to experience an engagement penalty in comparison to non-advertising posts. The size of this penalty (for being advertising) describes how effectively an advertising post reaches an influencers audience. A penalty of zero implies that it conveys its messages just as effective as a non-advertising post. Formally, we define the engagement penalty that is experienced by advertising posts as the likes-gap between advertising and non-advertising posts relative to the number of likes of non-advertising posts:
This study focuses on Instagram, which is the most relevant platform for influencer marketing (Influencer Marketing Hub, 2020; Mediakix, 2019). We investigate the effect of ad disclosures on the example of macro-influencers with more than one million followers because this group of influencers is associated with a high level of professionalism and internationalism. Also, within this group of influencers, posting in English is common irrespective of the influencer’s origin. These characteristics are important for the validity of our transfer approach that relies on training a predictive model based on a locally restricted sample (cf. Fig. 3).
In August 2019, we gathered names and regions of all influencers with at least one million followers from the platform likeometer.co (Rüegg, 2019), which employs an independent, manual, and curated influencer selection process. Initially, we extracted all posts for the period from 28/08/2019 to 31/03/2021 from Instagram. We gathered data on individual posts no earlier than 16/04/2021 as engagement levels are mostly stable after 15 days (D. Lee, Hosanagar, & Nair, 2018). To obtain metadata, we tracked the influencers’ profile pages (i.e., the accounts’ landing pages) weekly from 28/08/2019 to 31/03/2021.
To obtain an English-speaking dataset, we employ language detection techniques (Danilk, 2020; Shuyo, 2014) and exclude all non-English posts. For our analyses, we discard authors for whom English is not the most frequently used language or who deleted more than 10% of their posts.Footnote 3 Excluding the German-speaking region (DACH region), this results in a dataset containing 65,354 posts from 239 influencers (hereafter called the global dataset). Additionally, we obtain 9496 English posts from 86 influencers of German-speaking (DACH) countries.
To analyze disclosure effects, we aim to identify undisclosed ads by training a model that predicts a post’s advertising nature from its characteristics (step 1.1 in Fig. 3). In the training set, we detect disclosed advertisements in two ways: We consider posts as disclosed ads if they contain a signal wordFootnote 4 or use the built-in feature of Instagram to present a disclosure at the top of the post (see Fig. 4).

Example of a post containing both types of disclosures. Source: https://www.instagram.com/p/B46Kz73gxXb/ (Retrieved October 30, 2023)
As model input, we acquire various features from posts’ creative elements (image and text) that can trigger consumers’ ad recognition (Boerman & Müller, 2022; Jung & Heo, 2019). To extract features from images, we use Google Cloud Vision API (GCV), which can detect meaningful concepts in images (Google Inc., 2020). GCV has already been applied and proven effective for research purposes several times (Klostermann, Plumeyer, Böger, & Decker, 2018; Y. Li & Xie, 2020; Ahmadi, Waltenrath, & Janze, 2022; Rietveld, van Dolen, Mazloom, & Worring, 2020). Using GCV, we extract objects, labels, faces, landmarks, logos, and explicit-content indicators. To illustrate the output of GCV, we provide examples in the online appendix (Fig. A.1 to A.6). Further, we track tagged accounts and their descriptions (also called profile text or biographies). From the textual information of the posts, we compute a document-term-matrix including 1- and 2-grams with a sparsity of 99% while excluding the aforementioned signal words that indicate advertisements. We illustrate the processing of the textual data in the online appendix (Table B.1) in more detail. In total, we use 28 features and four document-term matrices (> 3000 columns; calculated from the message text, profile text, image information extracted by GCV, and tagged accounts) for model training. We describe the full dataset in Table C.1 of the online appendix, where we mark all characteristics used for model training with an apostrophe. Fig. 5 illustrates all elements extracted from the posts.

Illustration of the elements extracted from the social media posts. Sources: https://www.instagram.com/p/B3pyBJjg5ms/ and https://www.instagram.com/p/ClYuPXTsvvX/?img_index=2 (Retrieved October 30, 2023)
For our analyses, we use a different, much smaller set of control variables that may determine post success (LIKES). To control for recent activity, we calculate the number of posts within the last 14 days. Because a u-shape might be present, we also calculate the squared number of posts. In addition to the posts’ likes and the presence of advertising disclosures, we calculate dummy variables for each influencer and each month-year combination describing the posts’ publication dates. Further, we track all influencers’ numbers of followers weekly and interpolate linearly. For each post, we calculate its readability using the SMOG formula that estimates the years of education needed to comprehend a text (Mc Laughlin, 1969). We retrieve whether the post’s main item is a video; the total number of items (images or videos), if another account is tagged; and the cumulated number of followers of tagged accounts. We also extract whether a post mentions a currency, a URL, or provides a coupon code. From GCV, we get indications of explicit content (safesearch) regarding adult, medical, racy, spoof, or violent image content. Further, we extract whether a face, logo, or prominent landmark is present. To capture message sentiment, we use the binary classification of SentiStrength, which focuses on sentiment detection in short, informal texts of the social web (Thelwall, Buckley, Paltoglou, Cai, & Kappas, 2010). Table C.2 of the online appendix provides an overview of all features and descriptive statistics. In this Table, we mark all characteristics used in the analyses with an asterisk.
Model and validation
Figure 6 illustrates the derivation and purposes of the datasets we use for model training, model validation, and analysis. To predict the advertising nature of posts from the global dataset (excluding DACH posts), we rely on English-speaking data from German-speaking regions (DACH). This approach is possible because, due to the strict regional legal requirements, we assume that authors of the DACH region properly disclose their posts as advertisements. The fact that 21.7% of gathered DACH posts (2058 of 9496) are disclosed, which is well in line with the recent recommendation regarding the optimal share of sponsored posts (10 to 30%) of an influencer marketing agency (IMA, 2019), backs this assumption. Contrasting the agency’s recommendation, we find that in the global dataset, only 4.8% of gathered posts (3804 of 79,635) are disclosed as advertisements. In line with other assessments (Influencer Marketing Hub, 2020), this indicates poor disclosure compliance and provides face validity for our approach.

Illustration of the derivation of datasets and their purposes
Recruiting of human coders for validation
The main idea of our approach is to use a model to predict the advertising nature of undisclosed posts. To validate our approach that relies on transferring a (mostly) DACH-trained model to the global dataset, we compare the annotations of human coders to model predictions within the global validation sample comprising 400 posts drawn from the global sample (cf. global validation sample in Fig. 6). Additionally, to assess disclosure compliance in the DACH region, we compare the actual disclosures to the annotations of human coders and draw 100 posts from the DACH sample (cf. DACH validation sample in Fig. 6). In both validation samples, we foster representativeness by drawing one post from each influencer before drawing randomly from all remaining posts.
We recruit coders via Amazon Mechanical Turk. All coders are located in the USA, hold an Instagram account, and use social media multiple times a week. All of them report being familiar with influencer marketing and remember encountering a situation of paid advertising on social media. To further enhance coders’ ad recognition abilities, we instruct them as follows: We tell coders that all posts are from professional influencers with more than 1 million followers and instruct them to pay attention to image, text, and minor cues like links to accounts of brands because such cues have proven effective for ad recognition (Boerman & Müller, 2022). Naturally, we exclude all posts of the validation samples from the training set. We recruit three coders per task and ask them to indicate the extent to which they think the Instagram post is advertising on a 7-point scale. Previous research has used similar questions to measure advertising recognition or persuasion knowledge (Boerman et al., 2012, 2017; Ham, Nelson, & Das, 2015). We consider a post as advertising if the median of answers that potentially ranges from 1 (strongly disagree) to 7 (strongly agree) is greater than 4.
Construction of the training set and model training
For training the model, we use the properly disclosed (English-speaking) data from the DACH region and enlarge it with all disclosed (English-speaking) ads from the global sample. As a result, ads and non-ads are nearly balanced in the training set (see online appendix D for more reasoning regarding this practice). After excluding the two validation samples, the final training set consists of 13,172 observations (cf. Fig. 6).
To predict a post’s advertising nature, we train a stochastic gradient boosting model using the R-packages caret (Kuhn, 2008) and catboost (Prokhorenkova, Gusev, Vorobev, Dorogush, & Gulin, 2017). We chose this model as stochastic gradient boosting achieved the best predictive performance compared to other approaches such as random forests, neural networks, or support vector machines. We chose catboost over other implementations as it combines good predictive performance and high training speed (see the “Robustness checks” section for a discussion of other implementations). Within the training set, we achieve a 5-fold cross-validation accuracy of 88.8% and an area under the curve (AUC) of 0.955. We present the classification report of the training set in Table 1. For the classification report of the DACH validation set, see Table C.3 of the online appendix.
Validation of the transfer approach
To validate that influencers from the DACH region disclose ads properly, we compare the results of human coding of DACH posts to the presence of disclosures. For the 100 posts drawn from the DACH sample, this comparison yields an accuracy of 77.0%, indicating that disclosure compliance is decent within our training set. Thus, we argue that our training set provides sufficient opportunity for the model to learn the relevant patterns of advertising posts. When repeating this analysis for the global sample, we reach a relatively poor accuracy of 55.8%, which provides face validity for the poor disclosure compliance within the global sample.
To assess the performance of the trained model, we compare model predictions to human coding in the hold-out set drawn from the global sample. We reach a good accuracy of 79.8%, providing evidence for the validity of this study’s approach. If we drop 61 borderline cases where respondents were undecided (median of 3, 4, or 5), accuracy rises to 83.2%, which shows the capability of the model to detect clear cases. In Table 2, we present the corresponding classification reports. Among human coders, Krippendorff’s alpha is 0.59, indicating moderate agreement among participants.
Model
To simplify interpretation and avoid multicollinearity, we use the model predictions to calculate the binary variable NON_DISCLOSED_ADVERTISING. This variable corresponds to the model prediction (of a post’s advertising nature) if a post is not disclosed as advertising and is set to zero otherwise. The final global sample contains 3190 disclosed ads and 62,164 undisclosed posts (cf. global dataset in Fig. 6), of which the model predicts 25,235 posts as advertising (cf. Table C.2 in the online appendix).
As we aim to model count data that has a right-skewed distribution (cf. Fig. C.1 in the online appendix), we employ negative binomial regressions with robust standard errors. Equation (1) illustrates the regression model for our main specification:
where yi > 0 (cf. Table C.1 and Table C.2 in the online appendix) is the number of likes of post i (= 1, 2, …, N), α−1 > 0 is the scaling parameter, and Γ(.) is the gamma distribution. As our focus lies on effects associated with binary variables, this study reports incidence rate ratios (IRR) which we calculate for coefficient \({\beta }_{i}\) by \(\mathrm{IRR}\left({\beta }_{i}\right)={e}^{{\beta }_{i}}\). IRR are interpreted as multiplicative effects on the dependent variable per one-unit change of the independent variable.
Results
Study 1: effects on current engagement with the advertisement
First, we estimate the effects of undisclosed advertising (NON_DISCLOSED_ADVERTISING), the two types of disclosures (AD_DISCLOSURE_FEATURE and AD_DISCLOSURE_TEXT), and a set of control variables on ad success (LIKES). In Table 3, we present the results obtained from the global sample. We estimate that, depending on the type of disclosure, disclosed advertising posts gather 73.5% or 82.6% of engagement (LIKES) compared to non-advertising posts. The posts using Instagram’s built-in feature to display a more prominent disclosure type experience the greater penalty. We further estimate that undisclosed advertising posts gather 93.4% of engagement of non-advertising posts. Depending on the type of disclosure, this represents approximately one quarter (i.e., (1–93.4%)/(1–73.5%) = 24.9%) to two fifths (1–93.4%)/(1–82.6%) = 37.9%) of the penalty that is experienced by disclosed ads. Thus, disclosures are associated with 11.6% ((93.4–82.6%)/93.4%) to 21.3% ((93.4–73.5%)/93.4%) less engagement compared to undisclosed ads, implying acceptance H1a and rejection of H1b.
Regarding the control variables, we find that a link, currency, video, or logo is associated with less engagement. Further, lower readability (i.e., higher SMOG grade) is associated with less engagement. A positive effect on engagement is associated with positive or negative sentiment, the number of items (images or videos), the influencer’s number of followers, and the presence of a face or well-known landmark. Regarding the influencer’s recent activity, we interpret the IRR of N_POSTS_14D and its squared term jointlyFootnote 5 but detect no relevant u-shape as the minimum of the u-shaped function lies outside the relevant area. Tagging of other accounts has a negative effect which is partly offset by the tagged accounts’ followersFootnote 6. Indicators of explicit content (safesearch) are all significantly effective, while violent or medical content is associated with less engagement, and the others are associated with more engagement. Finally, mentioning a coupon code is only associated with less engagement for non-advertising posts. For advertising posts, the negative effect of HAS_CODE is fully compensated by the effect of the interaction term.
Study 2: persistent effects on engagement with future posts
To enrich these results with another perspective, we conduct a second analysis that focuses on the persistent effects of disclosed and undisclosed advertising on future non-advertising posts of the same influencer.Footnote 7 We define non-advertising posts as all posts that are neither disclosed nor predicted to be advertising by our model. Based on different horizons of 14, 28, and 42 days before each post’s posting time, we construct variables that, respectively, capture the share of disclosed and undisclosed ads among all advertising posts of the same author within the given horizon (AD_SHARE; see Table C.4 in the online appendix for descriptive statistics). If an author posted no ads within the respective horizon, we set the variables to zero. We perform separate regressions for the share of disclosed and undisclosed ads as these two variables are strongly negatively correlated and present results in Table 4. We find that a high share of undisclosed advertising is associated with lower success of future posts, while a high share of disclosed advertising is associated with higher success of future posts. We detect positive persistent effects of up to + 5.5% for 100% disclosed ads and negative persistent effects of up to − 4.3% for 100% undisclosed ads within the last 42 days. Therefore, we accept H2b and reject H2a.
Robustness checks
To strengthen our results, we perform several robustness checks. We acknowledge that we should interpret the presented IRR with care as the method of this study may overestimate the success of undisclosed ads for the following reason: Since the advertising nature of posts is predicted by a model that is not perfectly accurate, the estimated variable NON_DISCLOSED_ADVERTISING is noisy. Since false-positive predictions (non-advertising posts that are predicted as advertising) may typically receive more engagement than true positives (advertising posts that are predicted correctly), the penalty of undisclosed advertising is possibly underestimated, i.e., the estimated IRR may be biased upwards. Therefore, we view the IRR for undisclosed advertising as upper bounds. Put differently, if we had been able to detect a post’s advertising nature flawlessly, we might (based on a less noisy independent variable) attribute a higher share of the disclosure penalty to the post’s inherent advertising nature. Following Yang, Adomavicius, Burtch, and Ren (2018), we check this rationale by running an MC-SIMEX simulation (Cook & Stefanski, 1994; Küchenhoff, Mwalili, & Lesaffre, 2006) that corrects for the effect of measurement error by extrapolating from results based on different degrees of artificially introduced measurement error. MC-SIMEX estimates indeed deliver lower IRR for NON_DISCLOSED_ADVERTISING indicating that 45.3% ((1–0.866)/(1–0.704)) to 60.1% ((1–0.866)/(1–0.781)) (depending on disclosure type; see Table C.5 in the online appendix) of the disclosure penalty can be attributed to the posts’ inherent advertising nature. This supports that the estimated IRR serve as upper bounds. We conclude that up to 60.1% of the effect of disclosures stems from a post’s inherent advertising nature rather than from the disclosure.
To check the validity of our transfer approach once more, we construct subsets of posts similar to the posts from the DACH region training set. We do this by employing one-to-one nearest neighbor propensity score matching without replacement. At first, we perform matching at the author level while considering mean values of LIKES, FOLLOWERS, ACTIVITY (see Table C.2 in the online appendix for variable descriptions), and model predictions of posts’ advertising nature. In another approach, we match at the post level based on the post characteristics used in regressions.Footnote 8 The estimated results are in line with those for the full sample (see Table C.6 in the online appendix). Since both subsamples are small, they may serve as robustness checks and strengthen results. Further, we swap month-year dummies for week-year dummies; see Table C.7 in the online appendix. Also, we recalculate results while omitting all influencers that do not meet the recommendation regarding the optimal share of advertising posts (10 to 30% (IMA, 2019); see Table C.5 in the online appendix). In another attempt, we omit all additional control variables; see Table C.8 in the online appendix. All of these robustness checks yield results similar to those presented above.
To underline the results regarding the persistent effects, we vary our approach and construct binary variables that capture if the author posted a disclosed/undisclosed ad within the respective horizon; see Table C.9 in the online appendix. Also, we reperform the analysis while including all observations of the global dataset; see Table C.10 in the online appendix. Both results are in line with the presented results. Further, to show the generalizability of our results to an author’s future advertisements, we reperform the analysis based on advertising posts only. Table C.11 in the online appendix shows that the persistent effects on future ads may be even stronger. Finally, we extend our analyses to greater time horizons of 56, 70, 84, 98, 112, and 126 days. The results in Table C.12 and Table C.13 of the online appendix show that the estimated persistent effects increase with greater horizons, reaching up to + 11.5% and − 11.3%, respectively.
Above, we mention that influencers can delete their posts anytime. As they might delete posts that do not perform well (Wies, Bleier, & Edeling, 2022), they might be more likely to delete advertising posts. We investigate this claim by looking at a sample we gathered in March 2020 for a preliminary study (Waltenrath, 2021). In this sample, we identify 360 posts that authors deleted afterwards. Indeed, we discover that deleted posts are more likely advertising (disclosed or undisclosed). Also, deleted posts gather fewer likes than other posts of the same author. To eliminate any related bias, we reperform the analysis with stricter conditions on the share of deleted posts. When omitting all influencers that delete more than 1, 2, or 5% of posts, we estimate results similar to those above. Thus, we conclude that this does not introduce any substantial bias because the number of deleted posts is small (see Table C.5, Table C.14, and Table C.15 in the online appendix for results based on authors that delete < 1% of posts).
Furthermore, we reperform our analyses for the number of comments, representing another form of engagement. We present the corresponding results in Table C.5, Table C.16, and Table C.17 in the online appendix. They are less significant but in line with the results presented above and allow for the same conclusions regarding the current and persistent effects of disclosures.
To show robustness against changing the classification model, we train two more classifiers using other implementations, namely XGBOOST (Chen et al., 2020) and GBM (Greenwell, Boehmke, Cunningham, & Developers, 2019). We present accuracy measures and key results in the online appendix in Table C.18. They are similar to the results presented above.
Finally, we base our analyses on a negative binomial model and control for influencer-specific effects only by including dummy variables. However, the data possesses a hierarchical structure as it consists of posts crafted by influencers. To control for this structure, we fit a negative binomial mixed model with random effects for the intercept and the respective variables of interest.Footnote 9 We present fixed effects results in Tables C.19 and C.20 in the online appendix. The results are similar but less significant. While the negative persistent effects associated with undisclosed advertising (mostly) persist, we estimate insignificant fixed effects associated with disclosed advertising. This suggests that the positive persistent effects associated with disclosed advertising may, to some extent, be influencer-specific and depend on influencer characteristics such as source credibility. Nevertheless, the estimated results are in line with the results presented above (H2b) and imply that disclosing ads is favorable with respect to consumers’ engagement with an author’s future posts.
Discussion
As extant research reports opposing effects of disclosures based on conflicting theoretical arguments (Hudders et al., 2021; Lou, 2021; Ye et al., 2021), we conduct two empirical studies that take into account the presence of parasocial relationships and consumers’ prior experience with this type of advertising. To shed light on the reasons for the opposing results of extant research, we analyze the current (study 1) and persistent (study 2) effects of ad disclosures based on a conceptual framework that incorporates the theory of extant research.
Theoretical contributions
In study 1, we estimate that disclosures lead to a decrease in engagement compared to undisclosed ads (H1a). However, from the significant penalty for undisclosed ads, which amounts to at least one quarter (and possibly up to 60%) of the penalty for disclosed ads, we conclude that consumers recognize ads and activate coping strategies without the presence of disclosures. The negative effect of mentioning a coupon code in undisclosed ads supports research suggesting that such characteristics trigger ad recognition in the absence of disclosures (Boerman & Müller, 2022; Evans et al., 2019; Jung & Heo, 2019). This finding is in line with previous research that suggests that consumers rely on their prior experience to improve ad recognition (W. Wang & Wang, 2019). Still, we estimate that disclosed ads experience a greater penalty than undisclosed ads, which implies that consumers are more likely to recognize ads with disclosures. Thus, the presence of disclosures plays a significant role in ad recognition. While some research suggests that disclosures can work in favor of the advertisement because consumers appreciate honesty (Amazeen & Wojdynski, 2019; Boerman, 2020; De Jans et al., 2018; Evans et al., 2019; Isaac & Grayson, 2016; Krouwer et al., 2020; Lou, 2021; Saternus et al., 2022; W. Wang & Wang, 2019), study 1 does not provide empirical evidence for this effect (reject H1b). Instead, we conclude that disclosures are most likely processed as a hint for calculative motives and trigger persuasion knowledge (H1a). Undisclosed ads suffer less penalty because other, affective motives remain plausible (discounting principle).
In study 2, however, the positive persistent effects that we associate with disclosed advertising (H2b) indicate that, in the long run, consumers value clear disclosures and disapprove of undisclosed ads. This is in line with the aforementioned literature (Amazeen & Wojdynski, 2019; Boerman, 2020; De Jans et al., 2018; Evans et al., 2019; Isaac & Grayson, 2016; Krouwer et al., 2020; Lou, 2021; Saternus et al., 2022; W. Wang & Wang, 2019) and implies that the Persuasion Knowledge Model cannot fully explain the effects of disclosures. Considering consumers’ engagement with future posts of the same author, the proper use of disclosures in advertising posts may foster trust and rule out calculative motives. Most importantly, properly disclosing ads may raise source credibility because consumers perceive the author as transparent and honest. Hence, consumers are more likely to infer genuine (affective) motives for future undisclosed posts, which fosters engagement. Contrasting the results of study 1, we find no evidence that associates disclosed advertising with a negative effect on consumers’ engagement with future posts (reject H2a), indicating that consumers’ coping strategies triggered by ad disclosures may be limited to the current advertisement at hand. From the negative persistent effects that we associate with undisclosed advertising, we conclude that undisclosed ads may leave consumers in doubt about the motives of future non-advertising posts. Further, if consumers recognize undisclosed ads, they might perceive them as extraordinarily deceptive (Carr & Hayes, 2014; Evans et al., 2019), which lowers perceived source credibility. This makes consumers more likely to infer calculative motives for future undisclosed posts and lowers consumers’ future engagement intentions. Our results further suggest that posts from authors with a high share of undisclosed ads among their advertisements, i.e., who regularly perform undisclosed advertising, experience a greater penalty, confirming that consumers recognize undisclosed ads.Footnote 10 Conversely, posts from authors that regularly disclose advertising posts benefit the most. More importantly, the increasing estimates for greater horizons show that the effects endure and persistently affect consumers’ attitudes and the success of future posts.
In Table 5, we summarize the hypotheses and results. Interestingly, we find support for different mechanisms in studies 1 and 2: While, in study 1, we associate disclosures with less engagement with the advertisement, we find a positive impact of disclosed advertising on consumers’ engagement with future posts of the same author in study 2. We conclude that disclosures signal calculative motives and activate persuasion knowledge, which reduces current ad engagement (H1a). However, disclosures also raise source credibility, which fosters future engagement (H2b). Drawing on our conceptual framework, we further conclude that the source credibility model (H2b) explains the effect of disclosures on future posts (see Fig. 2). In contrast, the traditional Persuasion Knowledge Model and the rationales on inferred motives (H1a) explain the effect of disclosures on the advertisement (see Fig. 1). From this, we conclude that the negative effects of consumers’ coping strategies triggered by disclosure-activated persuasion knowledge may mostly be limited to the advertisement, whereas the positive effects of disclosures on source credibility persist. We illustrate these findings in Fig. 7. Generally, we find that the mechanisms associated with disclosures work differently on the different horizons of study 1 (current effects) and study 2 (persistent effects). Our findings may explain the opposing results of extant research by adding the time horizon (current vs. future posts) as an additional layer of complexity that moderates the effect of disclosures on consumer engagement. Further, our findings may also apply to related quantities such as the number of followers.

Summary of theoretical findings: illustration of the dominant effects of ad disclosures on engagement with the advertisement and with future posts
Managerial contributions
As we find that only a low share of ads is disclosed correctly, this provides evidence supporting that, globally, government institutions (Federal Trade Commission, 2019; Steward, 2019; Zialcita, 2019) have not yet been successful in enforcing the use of disclosures. Legal authorities should therefore continue to foster compliant disclosures. In contrast, we detect higher disclosure compliance in DACH regions, where legislation is stricter. Further, as we estimate a greater penalty for the built-in disclosure, we conclude that the type of disclosure matters and that the built-in disclosure is more interruptive and gathers more attention. This finding confirms recent experimental studies (Boerman, 2020; Boerman & Müller, 2022) and contradicts statements of the FTC (Federal Trade Commission, 2017; Lawler, 2017).
From a practitioner’s view, our results support that in terms of engagement, influencers should avoid performing undisclosed advertising, as it has prolonged negative effects. Although disclosed advertising posts gather fewer likes than undisclosed advertising posts, influencers can increase future engagement by disclosing sponsorships. From a marketer’s perspective, it may still be tempting to encourage influencers not to disclose advertising posts as we find that these posts gather more engagement. However, literature suggests that the persistent effects may not only be directed towards the influencer but also towards the advertised brand or product (De Veirman & Hudders, 2020; Evans et al., 2019; Stubb & Colliander, 2019; Wojdynski, 2016). Thus, by not disclosing advertising posts, marketers may gain some engagement from consumers who do not recognize the ad, while other consumers may perceive this behavior as manipulative and experience prolonged negative effects on their attitudes. As there is no “dislike” button on Instagram, negative effects are not immediately transparent and may only be discovered by qualitatively assessing responses. Conversely, fostering transparent disclosures can signal ethical practices, similar to cause-related marketing or cost disclosures, which improves perceived corporate social responsibility (CSR) (Brønn & Vrioni, 2001; Nan & Heo, 2007; A. Wang, 2009). CSR, in turn, signals that firms are reliable and honest, and fosters firm performance and value (Luo & Bhattacharya, 2006; McWilliams & Siegel, 2001; Servaes & Tamayo, 2013).
Therefore, marketers and influencers should carefully consider whether the risk of performing undisclosed advertising is worth taking or if they want to benefit from the positive persistent effects associated with properly disclosed ads. Especially since many consumers recognize undisclosed ads and authorities introduce legal risks by increased enforcement (Saliba, 2023), we believe that influencers and marketers should have an interest in disclosing their ads because the short-term upside of undisclosed advertising may not outweigh the downside of possibly prolonged reduced attitudes.
Limitations and future research
The crucial assumption of this study is that the trained model learns patterns of advertising posts sufficiently well from the training set. This assumption implies that the training set is mostly free from incorrect annotations and achieves a decent predictive performance. We use human coding to validate these claims, perform robustness checks, and provide arguments that explain why the estimated IRR serve as upper bounds. Still, as predictions are imperfect, the outcome is noisy, so we should interpret the results with care.
First, one might question the validation by human coders. Although we took several steps to increase coders’ ad recognition performance, the results from manual coding are likely not perfectly accurate because human coders might not recognize all advertisements correctly. Therefore, the presented validations can only serve as an approximation of the true model performance. Further, the validation samples are small. Although descriptive statistics, e.g., regarding disclosures, are very similar, and we foster the representativeness of validation samples by drawing at least one observation from each influencer, they may not perfectly reflect the original dataset.Footnote 11 Additionally, we do not distinguish between self-promoting ads and other ads. Self-promoting ads are unpaid, and most might come from genuine emotion. While some self-promoting posts might be non-advertising, others might be more calculative and closely related to advertisements. Because authors do not need to disclose such posts, the model cannot learn to predict self-promotion. However, the model will recognize some self-promoting posts — those that are similar to other ads — because of their characteristics. Consumers might also perceive such posts as advertising. Therefore, we believe that this does not bias the analyses. To verify this claim, future research could investigate consumers’ perceptions of disclosures in self-promoting and other ads.
The moderate agreement among survey participants is another limitation. As influencers aim to present advertisements as genuine recommendations, they may try to hide the advertising nature of their posts. This deceptive practice may foster uncertainty among participants about a post’s true nature. Additionally, the above-explained ambiguity of self-promoting posts adds to this. Oftentimes, there may be arguments for either side, and even experts may not know if a post is genuine or paid unless the influencers disclose it, resulting in the observed moderate agreement among survey participants. However, we believe that, on average, participants recognize ads correctly and that our validation procedure provides a good approximation of the true model performance.
Another limitation is that we use a model trained on data from a specific region to predict advertisements of another region without considering regional or cultural differences, except for language. Although we focus on international influencers and the validation shows decent performance, we might miss some local or other aspects such as cultural differences in consumers’ trustfulness or if English is an author’s first language or not. The impact of such aspects could be investigated by future research. Similarly, our focus on English-speaking influencers introduces a focus on English-speaking countries and cultures. While prominent influencers have followers all over the world, an overrepresentation of their country of origin (e.g., the UK or USA) is likely. Thus, smaller countries and societies might be underrepresented due to the threshold of one million followers. Also, it is unclear whether our results can be generalized to less prominent influencers. Some research suggests that such influencers differ (Appel, Grewal, Hadi, & Stephen, 2020), while others claim that the type of influencer does not moderate the effect of disclosures (Boerman, 2020).
Further, we cannot control for the size and positioning of products in undisclosed ads. Findings from related fields indicate that consumers may perceive a more intrusive positioning as deceptive with greater probability (J. Lee et al., 2016). Thus, intrusiveness may moderate if a disclosure increases perceived transparency or inferred calculative motives.
While influencers try to build a relationship and interact with their community to foster engagement, marketers may target other metrics, such as clicks or conversions (Waltenrath et al., 2022). It remains unclear how disclosures affect these metrics. Although we associate disclosures with less engagement with the ad, there might be a positive effect on these metrics via increased credibility/transparency, similar to the effect on future posts’ engagement. As we find that coping strategies are limited mostly to the ad, it seems worthwhile to test if metrics such as sales follow similar patterns. That is, ad disclosures could be associated with a positive long-term and adverse short-term effect on sales. Our results and conceptual framework can provide foundations for such hypotheses that remain to be tested by future research. Further, to shed more light on the effects of disclosed and undisclosed advertising, which vary depending on the time horizon and subject of study, future research could investigate their persistence or rate of decay. As a starting point, we provide results on the effect of posting no advertising content for 42, 84, 91, 98, 119, and 182 days in Table C.42 of the online appendix. Results suggest that transparent disclosures have similar effect on consumers’ engagement with future posts compared to not posting ads for around 90 days. For shorter periods of time, consumers might remember the previous ads and have doubts about the motives of the current post. For longer periods, the author might have built up sufficient source credibility such that the majority of consumers assumes genuine motives as the author does seem to not (anymore) post advertising content, implying more engagement. However, this process needs further investigation.
Further, as this study identified the overall effects and prevailing mechanisms that determine the effects of ad disclosures, future research could investigate the relative importance of the proposed theoretical concepts regarding current and future engagement. Finally, to disentangle the effects of disclosures in social media and derive the optimal behavior of marketers and influencers, it seems desirable to investigate how characteristics such as the strength of parasocial relationships, source credibility, or ad intrusiveness influence the current and persistent effects of disclosed and undisclosed advertising on engagement, attitudes (towards influencer or brand), or economic metrics such as clicks or conversions. The theory and results discussed in this manuscript may provide the foundations for such analyses.
Data Availability
The social media post data belongs to the respective authors/influencers and is not available due to copyright laws.
Notes
In this study, we use the term disclosure to refer to advertising disclosures. We state it explicitly when referring to other types of disclosures (e.g., impartiality or honesty disclosures).
Swiss and Austrian influencers must comply with German regulations if they target DACH (i.e., German, Austrian, and Swiss) consumers (Juno, 2017).
Since we tracked profiles weekly, we observe deletions on this basis. See the “Robustness checks” section for a discussion of deleted posts.
Posts are marked as an ad if they contain “advertisement,” “ad,” “collab,” “collaboration,” “sponsored,” or the German equivalents “werbung,” “anzeige,” or “bezahltepartnerschaft” and are not preceded by a negation.
The joint IRR depending on the level of N_POSTS_14D is given by f(N_POSTS_14D) = e^(βN_POSTS_14D ∗ N_POSTS_14D + βN_POSTS_14D_SQUARED ∗ N_POSTS_14D_SQUARED) with βx= ln(IRRx).
Coefficients of tagged accounts and their followers are robust against excluding each other.
See the “Robustness checks” section for a generalization to future advertising posts.
For PSM, we drop influencer and month-year dummies. We also drop the disclosure-related variables and instead include the raw model predictions (ADVERTISING).
We use the R-package lme4 (Bates, Mächler, Bolker, & Walker, 2015).
Table C.9 in the online appendix presents results with AD_SHARE replaced with dummy variables. The results are less significant, indicating that share of disclosed/undisclosed ads matters.
References
Amazeen, M. A., & Wojdynski, B. W. (2019). Reducing native advertising deception: Revisiting the antecedents and consequences of persuasion knowledge in digital news contexts. Mass Communication and Society, 22(2), 222–247. https://doi.org/10.1080/15205436.2018.1530792
Appel, G., Grewal, L., Hadi, R., & Stephen, A. T. (2020). The future of social media in marketing. Journal of the Academy of Marketing Science, 48(1), 79–95. https://doi.org/10.1007/s11747-019-00695-1
Audrezet, A., de Kerviler, G., & Guidry Moulard, J. (2020). Authenticity under threat: When social media influencers need to go beyond self-presentation. Journal of Business Research, 117, 557–569. https://doi.org/10.1016/j.jbusres.2018.07.008
Ahmadi, I., Waltenrath, A., & Janze, C. (2022). Congruency and Users’ Sharing on Social Media Platforms: A Novel Approach for Analyzing Content. Journal of Advertising, 1–18. https://doi.org/10.1080/00913367.2022.2055683
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
Bhattacharyya, S., & Bose, I. (2020). S-commerce: Influence of Facebook likes on purchases and recommendations on a linked e-commerce site. Decision Support Systems, 138. https://doi.org/10.1016/j.dss.2020.113383
Boerman, S. C. (2020). The effects of the standardized instagram disclosure for micro- and meso-influencers. Computers in Human Behavior, 103, 199–207. https://doi.org/10.1016/j.chb.2019.09.015
Boerman, S. C., & Müller, C. M. (2022). Understanding which cues people use to identify influencer marketing on Instagram: An eye tracking study and experiment. International Journal of Advertising, 41(1), 6–29. https://doi.org/10.1080/02650487.2021.1986256
Boerman, S. C., van Reijmersdal, E. A., & Neijens, P. C. (2012). Sponsorship disclosure: effects of duration on persuasion knowledge and brand responses: Sponsorship disclosure. Journal of Communication, 62(6), 1047–1064. https://doi.org/10.1111/j.1460-2466.2012.01677.x
Boerman, S. C., van Reijmersdal, E. A., & Neijens, P. C. (2014). Effects of sponsorship disclosure timing on the processing of sponsored content: A study on the effectiveness of European disclosure regulations. Psychology & Marketing, 31(3), 214–224. https://doi.org/10.1002/mar.20688
Boerman, S. C., van Reijmersdal, E. A., & Neijens, P. C. (2015). Using eye tracking to understand the effects of brand placement disclosure types in television programs. Journal of Advertising, 44(3), 196–207. https://doi.org/10.1080/00913367.2014.967423
Boerman, S. C., Willemsen, L. M., & Van Der Aa, E. P. (2017). “This post is sponsored”: Effects of sponsorship disclosure on persuasion knowledge and electronic word of mouth in the context of Facebook. Journal of Interactive Marketing, 38, 82–92. https://doi.org/10.1016/j.intmar.2016.12.002
Boush, D. M., Friestad, M., & Rose, G. M. (1994). Adolescent skepticism toward TV advertising and knowledge of advertiser tactics. Journal of Consumer Research, 21(1), 165. https://doi.org/10.1086/209390
Brehm, J. W. (1989). Psychological reactance: Theory and applications. ACR North American Advances.
Brønn, P. S., & Vrioni, A. B. (2001). Corporate social responsibility and cause-related marketing: An overview. International Journal of Advertising, 20(2), 207–222. https://doi.org/10.1080/02650487.2001.11104887
Campbell, M. C., & Kirmani, A. (2000). Consumers’ use of persuasion knowledge: The effects of accessibility and cognitive capacity on perceptions of an influence agent. Journal of Consumer Research, 27(1), 69–83. https://doi.org/10.1086/314309
Campbell, M. C., Mohr, G. S., & Verlegh, P. W. J. (2013). Can disclosures lead consumers to resist covert persuasion? The important roles of disclosure timing and type of response. Journal of Consumer Psychology, 23(4), 483–495. https://doi.org/10.1016/j.jcps.2012.10.012
Carr, C. T., & Hayes, R. A. (2014). The effect of disclosure of third-party influence on an opinion leader’s credibility and electronic word of mouth in two-step flow. Journal of Interactive Advertising, 14(1), 38–50. https://doi.org/10.1080/15252019.2014.909296
Chen, T., He, T., Benesty, M., Khotilovich, V., Tang, Y., Cho, H., Li, Y. (2020). xgboost: Extreme Gradient Boosting. Retrieved from https://CRAN.R-project.org/package=xgboost
Chung, S., & Cho, H. (2017). Fostering parasocial relationships with celebrities on social media: Implications for celebrity endorsement. Psychology and Marketing, 34(4), 481–495. https://doi.org/10.1002/mar.21001
Colliander, J., & Dahlén, M. (2011). Following the fashionable friend: The power of social media: Weighing publicity effectiveness of blogs versus online magazines. Journal of Advertising Research, 51(1), 313–320. https://doi.org/10.2501/JAR-51-1-313-320
Cook, J. R., & Stefanski, L. A. (1994). Simulation-extrapolation estimation in parametric measurement error models. Journal of the American Statistical Association, 89(428), 1314–1328. https://doi.org/10.1080/01621459.1994.10476871
Danilk, M. (2020). Langdetect. Retrieved October 5, 2020, from https://pypi.org/project/langdetect/
De Veirman, M., & Hudders, L. (2020). Disclosing sponsored Instagram posts: The role of material connection with the brand and message-sidedness when disclosing covert advertising. International Journal of Advertising, 39(1), 94–130. https://doi.org/10.1080/02650487.2019.1575108
De Jans, S., Cauberghe, V., & Hudders, L. (2018). How an advertising disclosure alerts young adolescents to sponsored vlogs: The moderating role of a peer-based advertising literacy intervention through an informational vlog. Journal of Advertising, 47(4), 309–325. https://doi.org/10.1080/00913367.2018.1539363
De Veirman, M., Cauberghe, V., & Hudders, L. (2017). Marketing through instagram influencers: The impact of number of followers and product divergence on brand attitude. International Journal of Advertising, 36(5), 798–828. https://doi.org/10.1080/02650487.2017.1348035
de Vries, L., Gensler, S., & Leeflang, P. S. H. (2012). Popularity of brand posts on brand fan pages: An investigation of the effects of social media marketing. Journal of Interactive Marketing, 26(2), 83–91. https://doi.org/10.1016/j.intmar.2012.01.003
Djafarova, E., & Trofimenko, O. (2019). ‘Instafamous’ – Credibility and self-presentation of micro-celebrities on social media. Information, Communication & Society, 22(10), 1432–1446. https://doi.org/10.1080/1369118X.2018.1438491
Eisend, M., & Tarrahi, F. (2022). Persuasion knowledge in the marketplace: A meta-analysis. Journal of Consumer Psychology, 32(1), 3–22. https://doi.org/10.1002/jcpy.1258
Eisend, M., van Reijmersdal, E. A., Boerman, S. C., & Tarrahi, F. (2020). A meta-analysis of the effects of disclosing sponsored content. Journal of Advertising, 49(3), 344–366. https://doi.org/10.1080/00913367.2020.1765909
Eslami, S. P., Ghasemaghaei, M., & Hassanein, K. (2021). Understanding consumer engagement in social media: The role of product lifecycle. Decision Support Systems. https://doi.org/10.1016/j.dss.2021.113707
Evans, N. J., Phua, J., Lim, J., & Jun, H. (2017). Disclosing Instagram influencer advertising: The effects of disclosure language on advertising recognition, attitudes, and behavioral intent. Journal of Interactive Advertising, 17(2), 138–149. https://doi.org/10.1080/15252019.2017.1366885
Evans, N. J., Wojdynski, B. W., & Hoy, M. G. (2019). How sponsorship transparency mitigates negative effects of advertising recognition. International Journal of Advertising, 38(3), 364–382. https://doi.org/10.1080/02650487.2018.1474998
Farace, S., Roggeveen, A., Villarroel Ordenes, F., De Ruyter, K., Wetzels, M., & Grewal, D. (2020). Patterns in motion: How visual patterns in ads affect product evaluations. Journal of Advertising, 49(1), 3–17. https://doi.org/10.1080/00913367.2019.1652120
Federal Trade Commission (2017) The FTC’s endorsement guides: What people are asking. Retrieved October 15, 2021, from Federal Trade Commission website: https://www.ftc.gov/tips-advice/business-center/guidance/ftcs-endorsement-guides-what-people-are-asking
Federal Trade Commission (2019) FTC releases advertising disclosures guidance for online influencers. Retrieved September 28, 2020, from Federal Trade Commission website: https://www.ftc.gov/news-events/press-releases/2019/11/ftc-releases-advertising-disclosures-guidance-online-influencers
Flanagin, A. J., & Metzger, M. J. (2007). The role of site features, user attributes, and information verification behaviors on the perceived credibility of web-based information. New Media & Society, 9(2), 319–342. https://doi.org/10.1177/1461444807075015
Friestad, M., & Wright, P. (1994). The Persuasion Knowledge Model: How people cope with persuasion attempts. Journal of Consumer Research, 21(1), 1–31. https://doi.org/10.1086/209380
Google Inc. (2020). Vision API. Retrieved October 5, 2020, from https://cloud.google.com/vision/docs
Grahl, J., Hinz, O., Rothlauf, F., Abdel-Karim, B. M., & Mihale-Wilson, C. (2023). How do likes influence revenue? A randomized controlled field experiment. Journal of Business Research, 167, 114133. https://doi.org/10.1016/j.jbusres.2023.114133
Greenwell, B., Boehmke, B., Cunningham, J., & Developers, G. B. M. (2019). Gbm: Generalized boosted regression models. R package version 2.1.5. Retrieved November 6, 2020, from https://CRAN.R-project.org/package=gbm
Ham, C.-D., Nelson, M. R., & Das, S. (2015). How to measure persuasion knowledge. International Journal of Advertising, 34(1), 17–53. https://doi.org/10.1080/02650487.2014.994730
Hass, R. G. (1981). Effects of source characteristics on cognitive responses in persuasion. In Cognitive responses in persuasion (pp. 141–172). Hillsdale, N.J: L. Erlbaum Associates.
Hinz, O., Skiera, B., Barrot, C., & Becker, J. U. (2011). Seeding strategies for viral marketing: An empirical comparison. Journal of Marketing, 75(6), 55–71. https://doi.org/10.1509/jm.10.0088
Hovland, C. I., Janis, I. L., & Kelley, H. H. (1953). Communication and persuasion. Yale University Press.
Hudders, L., De Jans, S., & De Veirman, M. (2021). The commercialization of social media stars: A literature review and conceptual framework on the strategic use of social media influencers. International Journal of Advertising, 40(3), 327–375. https://doi.org/10.1080/02650487.2020.1836925
Hwang, Y., & Jeong, S.-H. (2016). “This is a sponsored blog post, but all opinions are my own”: The effects of sponsorship disclosure on responses to sponsored blog posts. Computers in Human Behavior, 62, 528–535. https://doi.org/10.1016/j.chb.2016.04.026
IMA. (2019, March 7). The new metric in town: The saturation rate. Retrieved October 11, 2020, from https://imagency.com/news/influencer-marketing-metrics-saturation-rate
Influencer Marketing Hub. (2020, March 1). The State of Influencer Marketing 2020: Benchmark report. Retrieved September 28, 2020, from Influencer Marketing Hub website: https://influencermarketinghub.com/influencer-marketing-benchmark-report-2020/
Isaac, M. S., & Grayson, K. (2016). Beyond skepticism: Can accessing persuasion knowledge bolster credibility? Journal of Consumer Research, ucw063. https://doi.org/10.1093/jcr/ucw063
Jung, A.-R., & Heo, J. (2019). Ad disclosure vs ad recognition: How persuasion knowledge influences native advertising evaluation. Journal of Interactive Advertising, 19(1), 1–14. https://doi.org/10.1080/15252019.2018.1520661
Juno, U. (2017, July 18). Faktensammlung: Rechtliche Rahmenbedingungen im Influencermarketing. Retrieved October 10, 2021, from MOKS website: https://www.moks.at/blog/rechtliche-rahmenbedingungen-im-influencermarketing/
Kay, S., Mulcahy, R., & Parkinson, J. (2020). When less is more: The impact of macro and micro social media influencers’ disclosure. Journal of Marketing Management, 36(3–4), 248–278. https://doi.org/10.1080/0267257X.2020.1718740
Kelley, H. H. (1973). The processes of causal attribution. American Psychologist, 28(2), 107–128. https://doi.org/10.1037/h0034225
Kim, D. Y., & Kim, H.-Y. (2021). Influencer advertising on social media: The multiple inference model on influencer-product congruence and sponsorship disclosure. Journal of Business Research, 130, 405–415. https://doi.org/10.1016/j.jbusres.2020.02.020
Kim, S. J., Maslowska, E., & Tamaddoni, A. (2019). The paradox of (dis)trust in sponsorship disclosure: The characteristics and effects of sponsored online consumer reviews. Decision Support Systems, 116, 114–124. https://doi.org/10.1016/j.dss.2018.10.014
Klostermann, J., Plumeyer, A., Böger, D., & Decker, R. (2018). Extracting brand information from social networks: Integrating image, text, and social tagging data. International Journal of Research in Marketing, 35(4), 538–556. https://doi.org/10.1016/j.ijresmar.2018.08.002
Krouwer, S., Poels, K., & Paulussen, S. (2020). Moving towards transparency for native advertisements on news websites: A test of more detailed disclosures. International Journal of Advertising, 39(1), 51–73. https://doi.org/10.1080/02650487.2019.1575107
Küchenhoff, H., Mwalili, S. M., & Lesaffre, E. (2006). A general method for dealing with misclassification in regression: The misclassification SIMEX. Biometrics, 62(1), 85–96. https://doi.org/10.1111/j.1541-0420.2005.00396.x
Kuhn, M. (2008). Building predictive models in R using the caret package. Journal of Statistical Software, Articles, 28(5), 1–26. https://doi.org/10.18637/jss.v028.i05
Lawler, R. (2017, September 20). FTC warns influencers about relying on Instagram’s ad marker. Retrieved October 15, 2021, from Engadget website: https://www.engadget.com/2017-09-20-ftc-youtube-instagram-ad-notification-influencer.html
Lee, K., Lee, B., & Oh, W. (2015). Thumbs up, sales up? The contingent effect of Facebook likes on sales performance in social commerce. Journal of Management Information Systems, 32(4), 109–143. https://doi.org/10.1080/07421222.2015.1138372
Lee, J., Kim, S., & Ham, C.-D. (2016). A double-edged sword? Predicting consumers’ attitudes toward and sharing intention of native advertising on social media. American Behavioral Scientist, 60(12), 1425–1441. https://doi.org/10.1177/0002764216660137
Lee, D., Hosanagar, K., & Nair, H. S. (2018). Advertising content and consumer engagement on social media: Evidence from Facebook. Management Science, 64(11), 5105–5131. https://doi.org/10.1287/mnsc.2017.2902
Lenhardt, S. (2020, June 25). Influencer in sozialen Medien: Schleichwerbung oder Meinung? Retrieved September 28, 2020, from Tagesschau.de website: https://www.tagesschau.de/inland/influencer-werbung-kennzeichnungspflicht-101.html
Li, Y., & Xie, Y. (2020). Is a picture worth a thousand words? An empirical study of image content and social media engagement. Journal of Marketing Research, 57(1), 1–19. https://doi.org/10.1177/0022243719881113
Li, F., Larimo, J., & Leonidou, L. C. (2021). Social media marketing strategy: Definition, conceptualization, taxonomy, validation, and future agenda. Journal of the Academy of Marketing Science, 49(1), 51–70. https://doi.org/10.1007/s11747-020-00733-3
Lou, C., & Yuan, S. (2019). Influencer marketing: How message value and credibility affect consumer trust of branded content on social media. Journal of Interactive Advertising, 19(1), 58–73. https://doi.org/10.1080/15252019.2018.1533501
Lou, C. (2021). Social media influencers and followers: Theorization of a trans-parasocial relation and explication of its implications for influencer advertising. Journal of Advertising, 1–18. https://doi.org/10.1080/00913367.2021.1880345
Luo, X., & Bhattacharya, C. B. (2006). Corporate social responsibility, customer satisfaction, and market value. Journal of Marketing, 70(4), 1–18. https://doi.org/10.1509/jmkg.70.4.001
Mc Laughlin, G. H. (1969). SMOG grading-a new readability formula. Journal of Reading, 12(8), 639–646. JSTOR. Retrieved from http://www.jstor.org/stable/40011226
McGuire, W. J. (1985). Attitudes and attitude change. In L. Gardner & E. Aronson (Eds.), Handbook of social psychology (pp. 233–346). Random House.
McWilliams, A., & Siegel, D. (2001). Corporate social responsibility: A theory of the firm perspective. The Academy of Management Review, 26(1), 117. https://doi.org/10.2307/259398
Mediakix. (2019). Influencer marketing survey results: 2019 industry benchmarks. Retrieved September 28, 2020, from Mediakix website: https://mediakix.com/influencer-marketing-resources/influencer-marketing-industry-statistics-survey-benchmarks/
Miranda, S., Berente, N., Seidel, S., Safadi, H., & Burton-Jones, A. (2022). Editor’s comments: Computationally intensive theory construction: A primer for authors and reviewers. MIS Quarterly, 46(2), iii–xviii.
Nan, X., & Heo, K. (2007). Consumer responses to corporate social responsibility (CSR) initiatives: Examining the role of brand-cause fit in cause-related marketing. Journal of Advertising, 36(2), 63–74. https://doi.org/10.2753/JOA0091-3367360204
Naylor, R. W., Lamberton, C. P., & West, P. M. (2012). Beyond the “Like” button: The impact of mere virtual presence on brand evaluations and purchase intentions in social media settings. Journal of Marketing, 76(6), 105–120. https://doi.org/10.1509/jm.11.0105
Ohanian, R. (1990). Construction and validation of a scale to measure celebrity endorsers’ perceived expertise, trustworthiness, and attractiveness. Journal of Advertising, 19(3), 39–52. https://doi.org/10.1080/00913367.1990.10673191
Peters, K., Chen, Y., Kaplan, A. M., Ognibeni, B., & Pauwels, K. (2013). Social media metrics—A framework and guidelines for managing social media. Journal of Interactive Marketing, 27(4), 281–298. https://doi.org/10.1016/j.intmar.2013.09.007
Pittman, M., & Abell, A. (2021). More trust in fewer followers: Diverging effects of popularity metrics and green orientation social media influencers. Journal of Interactive Marketing, S1094996821000347. https://doi.org/10.1016/j.intmar.2021.05.002
Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. (2017). CatBoost: Unbiased boosting with categorical features. Retrieved from https://arxiv.org/abs/1706.09516
Reeder, G. D., Vonk, R., Ronk, M. J., Ham, J., & Lawrence, M. (2004). Dispositional attribution: Multiple inferences about motive-related traits. Journal of Personality and Social Psychology, 86(4), 530–544. https://doi.org/10.1037/0022-3514.86.4.530
Reinikainen, H., Munnukka, J., Maity, D., & Luoma-aho, V. (2020). ‘You really are a great big sister’ – Parasocial relationships, credibility, and the moderating role of audience comments in influencer marketing. Journal of Marketing Management, 36(3–4), 279–298. https://doi.org/10.1080/0267257X.2019.1708781
Rietveld, R., van Dolen, W., Mazloom, M., & Worring, M. (2020). What you feel, is what you like influence of message appeals on customer engagement on Instagram. Journal of Interactive Marketing, 49, 20–53. https://doi.org/10.1016/j.intmar.2019.06.003
Rosengren, S., & Campbell, C. (2021). Navigating the future of influencer advertising: Consolidating what is known and identifying new research directions. Journal of Advertising, 50(5), 505–509. https://doi.org/10.1080/00913367.2021.1984346
Rozendaal, E., Lapierre, M. A., van Reijmersdal, E. A., & Buijzen, M. (2011). Reconsidering advertising literacy as a defense against advertising effects. Media Psychology, 14(4), 333–354. https://doi.org/10.1080/15213269.2011.620540
Rüegg, B. (2019). Likeometer. Retrieved August 28, 2019, from https://likeometer.co/weltweit/alle/?lang=en
Sahni, N. S., & Nair, H. S. (2020). Sponsorship disclosure and consumer deception: Experimental evidence from native advertising in mobile search. Marketing Science, 39(1), 5–32. https://doi.org/10.1287/mksc.2018.1125
Saliba, E. (2023, June 1). France passes law to regulate paid influencers, combat fraud. Retrieved June 4, 2023, from ABC News website: https://abcnews.go.com/International/france-passes-law-regulate-paid-influencers-combat-fraud/story?id=99763427
Saternus, Z., Weber, P., & Hinz, O. (2022). The effects of advertisement disclosure on heavy and light Instagram users. Electronic Markets, 32(3), 1351–1372. https://doi.org/10.1007/s12525-022-00546-y
Saternus, Z., & Hinz, O. (2021). To# ad or not to# ad–Disclosing Instagram influencer advertising. PACIS 2021 Proceedings, 122. Retrieved from https://aisel.aisnet.org/pacis2021/122
Servaes, H., & Tamayo, A. (2013). The impact of corporate social responsibility on firm value: The role of customer awareness. Management Science, 59(5), 1045–1061. https://doi.org/10.1287/mnsc.1120.1630
Shuyo, N. (2014, March 3). Language detection library for Java. Retrieved October 13, 2020, from http://code.google.com/p/language-detection/
Smith, A. N., & Fischer, E. (2021). Pay attention, please! Person brand building in organized online attention economies. Journal of the Academy of Marketing Science, 49(2), 258–279. https://doi.org/10.1007/s11747-020-00736-0
Steinhoff, L., Arli, D., Weaven, S., & Kozlenkova, I. V. (2019). Online relationship marketing. Journal of the Academy of Marketing Science, 47(3), 369–393. https://doi.org/10.1007/s11747-018-0621-6
Steward, R. (2019, September 5). ASA says #ad is ‘necessary as a minimum’ as it ups the ante on influencer disclosure. Retrieved September 28, 2020, from The Drum website: https://www.thedrum.com/news/2019/09/05/asa-says-ad-necessary-minimum-it-ups-the-ante-influencer-disclosure
Stubb, C., & Colliander, J. (2019). “This is not sponsored content” – The effects of impartiality disclosure and e-commerce landing pages on consumer responses to social media influencer posts. Computers in Human Behavior, 98, 210–222. https://doi.org/10.1016/j.chb.2019.04.024
Terhaag, M., & Schwarz, C. (2021). Verhandlungen beim BGH zum Influencer-Marketing. Retrieved September 4, 2021, from https://www.aufrecht.de/beitraege-unserer-anwaelte/wettbewerbsrecht/bgh-werbekennzeichnung-influencer.html
Thelwall, M., Buckley, K., Paltoglou, G., Cai, D., & Kappas, A. (2010). Sentiment strength detection in short informal text. Journal of the American Society for Information Science and Technology, 61(12), 2544–2558. https://doi.org/10.1002/asi.21416
Thomasson, E., & Neely, J. (2021, September 9). Paid influencers must label posts as ads, German court rules. Retrieved September 11, 2021, from Reuters website: https://www.reuters.com/technology/paid-influencers-must-label-posts-ads-german-court-rules-2021-09-09/
Touma, R., & Chamas, Z. (2021, September 19). ‘A freebie is enough’: Influencer gift posts trigger breaches in Australian ad standards. Retrieved September 28, 2021, from The Guardian website: https://www.theguardian.com/media/2021/sep/20/a-freebie-is-enough-influencer-gift-posts-trigger-breaches-in-australian-ad-standards
Unnava, V., & Aravindakshan, A. (2021). How does consumer engagement evolve when brands post across multiple social media? Journal of the Academy of Marketing Science, 49(5), 864–881. https://doi.org/10.1007/s11747-021-00785-z
van Krieken, R. (2019). Georg Franck’s ‘The economy of attention’: Mental capitalism and the struggle for attention. Journal of Sociology, 55(1), 3–7. https://doi.org/10.1177/1440783318812111
van Doorn, J., Lemon, K. N., Mittal, V., Nass, S., Pick, D., Pirner, P., & Verhoef, P. C. (2010). Customer engagement behavior: Theoretical foundations and research directions. Journal of Service Research, 13(3), 253–266. https://doi.org/10.1177/1094670510375599
Waiguny, M. K. J., Nelson, M. R., & Terlutter, R. (2014). The relationship of persuasion knowledge, identification of commercial intent and persuasion outcomes in advergames—The role of media context and presence. Journal of Consumer Policy, 37(2), 257–277. https://doi.org/10.1007/s10603-013-9227-z
Waltenrath, A. (2021). Empirical Evidence on the Impact of Disclosed vs. Undisclosed Advertising in Context of Influencer Marketing on Instagram. ECIS 2021 Research Papers. Retrieved from https://aisel.aisnet.org/ecis2021_rp/4
Waltenrath, A., Brenner, C., & Hinz, O. (2022). Some Interactions Are More Equal Than Others: The Effect of Influencer Endorsements in Social Media Brand Posts on Engagement and Online Store Performance. Journal of Interactive Marketing, 57(4), 541–560. https://doi.org/10.1177/10949968221096591
Wang, A. (2009). Advertising disclosures and CSR practices of credit card issuers. Management Research News, 32(12), 1177–1191. https://doi.org/10.1108/01409170911006920
Wang, W., & Wang, M. (2019). Effects of sponsorship disclosure on perceived integrity of biased recommendation agents: Psychological contract violation and knowledge-based trust perspectives. Information Systems Research, 30(2), 507–522. https://doi.org/10.1287/isre.2018.0811
Wang, X., Xu, F., Luo, X. R., & Peng, L. (2022). Effect of sponsorship disclosure on online consumer responses to positive reviews: The moderating role of emotional intensity and tie strength. Decision Support Systems, 156, 113741. https://doi.org/10.1016/j.dss.2022.113741
Wies, S., Bleier, A., & Edeling, A. (2022). Finding Goldilocks influencers: How follower count drives social media engagement. Journal of Marketing, 87, 002224292211251. https://doi.org/10.1177/00222429221125131
Woisetschläger, D. M., Backhaus, C., & Cornwell, T. B. (2017). Inferring corporate motives: how deal characteristics shape sponsorship perceptions. Journal of Marketing, 81(5), 121–141. https://doi.org/10.1509/jm.16.0082
Wojdynski, B. W. (2016). The deceptiveness of sponsored news articles: How readers recognize and perceive native advertising. American Behavioral Scientist, 60(12), 1475–1491. https://doi.org/10.1177/0002764216660140
Wojdynski, B. W., & Evans, N. J. (2016). Going native: Effects of disclosure position and language on the recognition and evaluation of online native advertising. Journal of Advertising, 45(2), 157–168. https://doi.org/10.1080/00913367.2015.1115380
Wojdynski, B. W., Evans, N. J., & Hoy, M. G. (2018). Measuring sponsorship transparency in the age of native advertising: Measuring sponsorship transparency in the age of native advertising. Journal of Consumer Affairs, 52(1), 115–137. https://doi.org/10.1111/joca.12144
Yang, M., Adomavicius, G., Burtch, G., & Ren, Y. (2018). Mind the gap: Accounting for measurement error and misclassification in variables generated via data mining. Information Systems Research, 29(1), 4–24. https://doi.org/10.1287/isre.2017.0727
Ye, G., Hudders, L., De Jans, S., & De Veirman, M. (2021). The value of influencer marketing for business: A bibliometric analysis and managerial implications. Journal of Advertising, 50(2), 160–178. https://doi.org/10.1080/00913367.2020.1857888
Zialcita, P. (2019). FTC issues rules for disclosure of ads by social media influencers. Retrieved September 28, 2020, from https://www.npr.org/2019/11/05/776488326/ftc-issues-rules-for-disclosure-of-ads-by-social-media-influencers
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Declarations
All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript.
Additional information
Responsible Editor: Andreja Pucihar
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Waltenrath, A. Consumers’ ambiguous perceptions of advertising disclosures in influencer marketing: Disentangling the effects on current and future social media engagement. Electron Markets 34, 8 (2024). https://doi.org/10.1007/s12525-023-00679-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12525-023-00679-8
Keywords
- Sponsorship disclosures
- Persuasion knowledge
- Source credibility
- Inferred motives
- Consumer attitudes
- Transparency