
Abstract
The main purpose of this paper is to investigate the well-posedness for mean field game with finite state and action space (FSASMFG) by using nonlinear analysis methods. First, we set up the bounded rationality model of the FSASMFG in the topological space. Next, we study some sufficient conditions of generalized strong well-posedness (GS-wp) and strong well-posedness (S-wp) for a class of FSASMFGs. Finally, we give some characterizations of GS-wp and S-wp for FSASMFGs with the help of set-valued analysis methods. These new results presented in the paper develop and improve the corresponding conclusions in the recent literature.
Similar content being viewed by others

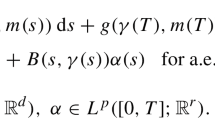
1 Introduction
Mean field games (MFGs) have been introduced independently by Lasry-Lions [26] and Huang-Malhamé-Caines [20], which provided a framework for dynamic stochastic games in continuous time with a continuum of players, whose equilibria act as approximate Nash equilibria for corresponding n-person games. MFGs as a game between a continuum of players is usually set up as an optimal control problem of a representative player responding to a flow of measures, such that the distribution of the player under optimality and the flow of measures coincide. From the perspective of economics, these games allow for tractable models of the interaction of a continuum of players with explicit interaction (in contrast to the classical assumption in general equilibrium theory that “prices mediate all social interaction” [18]) and heterogeneous states (in contrast to representative player models [16]). Thus, a wide variety of economic models depending on MFGs emerged, which includes growth models, the production of an exhaustible resource by a continuum of producers and opinion dynamics [9, 16, 18]. In recent years, more and more attention has been focused on MFGs owning to numerous applications in economic theory [11, 15], communication networks [7], public health [6] and some other fields.
So far, there is a variety of literature concentrating on the existence of equilibria of MFGs. Lacker [25] proved the existence of Markovian equilibria of MFGs under the framework of controlled martingale problems. Saldi et al. [35] proposed the existence of mean field equilibrium in the infinite-population under some mild assumptions, and then showed that mean field equilibrium can approximate Markov-Nash equilibrium when the number of players is sufficiently large. Belak et al. [8] modeled a mathematical framework for continuous time MFGs with finitely many states and common noise, and proved the existence and uniqueness for the forward-backward systems of (random) ordinary differential equations. However, the majority of theoretical results for MFGs with finite state model rely on the assumption that there is a unique optimizer of the Hamiltonian. For finite action space, this assumption will generally not be satisfied such as Kolokoltsov-Bensoussan [22] and Kolokoltsov-Malafeyev [23]. Hence, Doncel et al. [14] studied the existence results of dynamic equilibria for the FSASMFG and obtained the relations of these equilibria to Nash equilibria of associated n-person games. Neumann [32] proved the existence of stationary mean field equilibria in mixed strategies of FSASMFGs by utilizing Kakutani’s fixed point theorem. On the existence of equilibria of MFGs, interested readers can refer to [12, 13, 19] for more details.
On the one hand, there is few existing literature investigating the stability of stationary equilibria for MFGs. Guéant [17] considered the closest stability results for the diffusion models by using Hermite polynomials where the perturbations of the initial and terminal conditions. Adlakha-Johari [1] and Light-Weintraub [29] investigated the comparative statics results of oblivious equilibria for MFGs with a parameter, where transition probabilities and payoffs are monotonic. Recently, Neumann [31, 33] studied some results on the essential stability of stationary mean field equilibria for FSASMFGs when these equilibria are slightly disturbed, and obtained that most of FSASMFGs are essential in the sense of Baire’s category by Fort theorem. The above interesting and important results were obtained under the assumption of complete rationality. By Simon [37], the assumption of complete rationality is far too strict, and it has many restrictions in real applications. Anderlini-Canning [4] established the abstract bounded rationality model by relaxing the assumption of complete rationality and studied that the model is structurally stable if and only if the model is robustness to \(\epsilon \)-equilibria. Later, Yu et al. [42] extended the model of [4] under weaker conditions and proved that the model is structurally stable and robust to \(\epsilon \)-equilibria for almost all parameter values. Miyazaki and Azuma [30] studied \((\lambda , \varepsilon )\)-stability implies \((\lambda , \varepsilon )\)-robustness. Hung et al. [21] researched a new class of generalized multi-objective game with fuzzy mappings in bounded rationality model and proved \((\lambda , \varepsilon )\)-stability of this model implies that it is \((\lambda , \varepsilon )\)-robustness to \(\varepsilon \)-equilibrium. Further results on the bounded rationality model can be seen [43, 44, 46, 48].
On the other hand, well-posedness is a significant aspect of the study of stability and approximation for optimization problems. Generally speaking, the notions of well-posedness can be divided into two aspects. The first notion was derived from Tykhonov well-posedness(T-wp) with unconstrained optimization [38] and Levitin-Polyak well-posedness(LP-wp) with constrained optimization [28]. The second notion was Hadamard well-posedness(H-wp), which means the continuous dependence of the solution on the data of the problem. Afterward, different well-posedness types were applied to some other related problems, such as Nash equilibria [34], variational inequalities [40], discontinuous games [36], and fixed point problems [27]. Recently, Yu [45] provided a unified approach and obtained some new well-posedness results of nonlinear problems from the perspective of bounded rationality, such as optimization problems, multi-objective optimization problems, n-person noncooperative games and generalized games. Yu et al. [47] further studied the well-posedness of various nonlinear problems in the framework of bounded rationality model including Ky Fan’s point, quasi-variational inequality and the Nash equilibrium problems of three models for noncooperative game. Wang et al. [39] obtained some well-posedness results of generalized fuzzy game under the framework of bounded rationality model. Yu and Yang [41] investigated the Hadamard well-posedness and Tykhonov well-posedness for different applications by using a unified method. Very recently, Cardaliaguet et al. [10] first proved the well-posedness of the associated systems of master equation of MFGs in short time under weaker assumptions. Ambrose et al. [3] studied the well-posedness of short time classical solutions for a class of master equations involving non-separable local Hamiltonians in the theory of MFGs. In contrast to the proof of the well-posedness presented in literature [3, 10], we only rely on some nonlinear analysis methods, and the proof crucially depends on our probabilistic representation of the problem.
Motivated by the above-mentioned researches, we are interested in studying the well-posedness for a class of FSASMFGs by employing nonlinear analysis methods. We first set up the abstract bounded rationality model for the FSASMFG in the topological space, and obtain the relations of various well-posedness types. Next, we obtain some sufficient conditions of GS-wp and S-wp for a group of FSASMFGs. Finally, based on the Kuratowski measure of noncompactness, we give some characterizations of GS-wp and S-wp. These new results develop and improve some previous results.
The rest of the paper is structured as follows. In Sect. 2, we introduce some necessary prerequisites and definitions of well-posedness in the framework of bounded rationality, and further review the model of FSASMFGs. In Sect. 3, we set up the bounded rationality model of a class of FSASMFGs and give some sufficient conditions of GS-wp and S-wp for the game by nonlinear analysis methods. In Sect. 4, we obtain some characterizations of GS-wp and S-wp for the game by the method of set-valued analysis. Finally, we make some brief and concise conclusions.
2 Preliminaries and Model
In this section, we review some necessary preliminaries and the model of FSASMFGs.
2.1 Preliminaries
First, we introduce some definitions of the continuity of set-valued correspondence [2, 5]. Assume that X and Y are two metric spaces, \(T: X \rightarrow 2^Y\) represents the set-valued correspondence, where \(2^Y\) denotes all nonempty subsets of Y. T is said to be
-
Upper semicontinuous (usc) at \(x \in X\), if for all open set U of Y with \(U \supset T(x)\), there exists an open neighborhood O(x) of x such that \(U \supset T(x')\), \(\forall x'\in O(x)\);
-
Lower semicontinuous (lsc) at \(x \in X\), if for all open set U of Y with \(T(x) \cap U \ne \varnothing \), there exists an open neighborhood O(x) of x such that \(T(x') \cap U \ne \varnothing \), \(\forall x'\in O(x)\);
-
Continuous at \(x \in X\), if T is both usc and lsc at x;
-
A usco mapping on X, if \(T: X \rightarrow 2^Y\) is usc with nonempty compact values for any \(x \in X\);
-
Closed, if \(\textrm{Graph}(T)=\{(x, y) \in X \times Y: y \in T(x)\}\) is closed in \(X \times Y\).
Lemma 2.1
(see [5]) Let X and Y be two metric spaces. If the set-valued correspondence \(T: X \rightarrow 2^{Y}\) is a usco mapping, then \(\forall x_n \in X\), \(x_n \rightarrow x\), \(y_n \in T(x_n)\), there exists a subsequence \(\{y_{n_k}\}\) of \(\{y_{n}\}\) such that \(y_{n_k} \rightarrow y \in T(x)\).
In order to obtain the characterizations of well-posedness, we first recall the concept of Kuratowski measure of noncompactness.
Definition 2.1
(see [24]) Assume that X is a (complete) metric space, W is a bounded set of X, \(X \supset W\), the diameter of W is defined as
Then, the Kuratowski measure of noncompactness is defined as follows:
Lemma 2.2
(see [24]) Let W be a bounded set of X, \(\alpha (W)=0\) if and only if \({\overline{W}}\) is compact set, where \({\overline{W}}\) denotes the closure of W.
2.2 The Well-Posedness Under Bounded Rationality
Next, we introduce some definitions of well-posedness based on the bounded rationality model, see [41, 44, 45, 47] and the references therein. Let the bounded rationality model consist of a quadruple \(\langle \varLambda , X, f, {\varPhi } \rangle \), where \(\varLambda \) is a parametric space, X is an action space, \(\varLambda \) and X are both metric spaces. \(F: \varLambda \times X \rightarrow 2^{X}\) is a feasible correspondence and induces a further consistent behavior correspondence \(f: \varLambda \rightarrow 2^{X}\), \(f(\chi )=\{x \in X: x \in F(\chi , x) \}\), \(\forall \chi \in \varLambda \). \(\Phi : \textrm{Graph}(f) \rightarrow {\mathbb {R}}^{+}\) is a rationality function, the set of equilibria at \(\chi \) is defined as \(E(\chi )=\{x \in f(\chi ): \Phi (\chi , x) = 0\}\), where \(\Phi (\chi , x)=0\) corresponds to the complete rationality. For any \( \chi \in \varLambda \), \( \zeta \ge 0\), the set of \(\zeta \)-equilibrium at \(\chi \) is denoted by \(E(\chi , \zeta )=\{x \in f(\chi ): \Phi (\chi , x) \le \zeta \}\), where \(\Phi (\chi , x) \le \zeta \) corresponds to the bounded rationality.
Definition 2.2
- (i):
-
If \(\forall \chi _n \in \varLambda \), \(\chi _n \rightarrow \chi \), \(\forall x_n \in E(\chi _n, \zeta _n)\), where \(\zeta _n \rightarrow 0\), there exists a subsequence \(\{x_{n_k}\}\) of \(\{x_n\}\) such that \(x_{n_k} \rightarrow x \in E(\chi )\), then \(\chi \) is called G-wp.
- (ii):
-
If \(E(\chi )=\{x\}\) (a single point set), \(\forall \chi _n \in \varLambda \), \(\chi _n \rightarrow \chi \), \(\forall x_n \in E(\chi _n, \zeta _n)\), where \(\zeta _n \rightarrow 0\), there is \(x_n \rightarrow x\), then \(\chi \) is wp.
Definition 2.3
- (i):
-
If \(\forall x_n \in E(\chi , \zeta _n)\), where \(\zeta _n \rightarrow 0\), there exists a subsequence \(\{x_{n_k}\}\) of \(\{x_n\}\) such that \(x_{n_k} \rightarrow x \in E(\chi )\), then \(\chi \) is called GT-wp.
- (ii):
-
If \(E(\chi )=\{x\}\) (a single point set), \(\forall x_n \in E(\chi , \zeta _n)\), where \(\zeta _n \rightarrow 0\), there is \(x_n \rightarrow x\), then \(\chi \) is T-wp.
Definition 2.4
- (i):
-
If \(\forall \chi _n \in \varLambda \), \(\chi _n \rightarrow \chi \), \(\forall x_n \in E(\chi _n)\), there exists a subsequence \(\{x_{n_k}\}\) of \(\{ x_n \}\) such that \(x_{n_k} \rightarrow x \in E(\chi )\), then \(\chi \) is called GH-wp.
- (ii):
-
If \(E(\chi )=\{x\}\) (a single point set), \(\forall \chi _n \in \varLambda \), \(\chi _n \rightarrow \chi \), \(\forall x_n \in E(\chi _n)\), there is \(x_n \rightarrow x\), then \(\chi \) is H-wp.
Definition 2.5
- (i):
-
If \(\forall x_n \in X \), \( {\varPhi }(\chi , x_n) \le \zeta _n\), where \(\zeta _n \rightarrow 0\) and the distance \(\hbar (x_n, f(\chi )) \rightarrow 0\), there exists a subsequence \(\{x_{n_k}\}\) of \(\{ x_n \}\) such that \( x_{n_k} \rightarrow x \in E(\chi )\), then \(\chi \) is called GLP-wp.
- (ii):
-
If \(E(\chi )=\{x\}\) (a single point set), \(\forall x_n \in X\), \( {\varPhi }(\chi , x_n) \le \zeta _n\), where \(\zeta _n \rightarrow 0\) and the distance \(\hbar (x_n, f(\chi )) \rightarrow 0\), there is \(x_n \rightarrow x\), then \(\chi \) is LP-wp.
Definition 2.6
- (i):
-
If \(\forall \chi _n \in \varLambda \), \(\chi _n \rightarrow \chi \), \(\forall x_n \in X\), \(\hbar (x_n, f(\chi _n)) \rightarrow 0\), \( {\varPhi }(\chi _n, x_n) \le \zeta _n\), where \(\zeta _n \rightarrow 0\), there exists a subsequence \(\{x_{n_k}\}\) of \(\{ x_n\}\) such that \( x_{n_k} \rightarrow x \in E(\chi )\), then \(\chi \) is called GS-wp.
- (ii):
-
If \(E(\chi )=\{x\}\) (a single point set), \(\forall \chi _n \in \varLambda \), \(\chi _n \rightarrow \chi \), \(\forall x_n \in X\), \(\hbar (x_n, f(\chi _n)) \rightarrow 0\), \( {\varPhi }(\chi _n, x_n) \le \zeta _n\), where \(\zeta _n \rightarrow 0\), there is \(x_n \rightarrow x\), then \(\chi \) is S-wp.
Remark 2.1
(see, [41, 45, 47]) As shown in Fig. 1, Yu [45] pointed that GS-wp unifies G-wp and GLP-wp; G-wp unifies GH-wp and GT-wp; GLP-wp can derive GT-wp, see Fig. 1(a). In addition, S-wp unifies wp and LP-wp; wp unifies H-wp and T-wp; LP-wp can derive T-wp, see Fig. 1(b). Therefore, GS-wp and S-wp can derive the relations of various well-posedness types, respectively.

Relations of various G-wp types (left), the relations of various wp types (right)
2.3 The Model of MFGs with Finite State and Action Space
In this section, the FSASMFG model can be described by (i) a common state space; (ii) all players feasible action spaces; (iii) a transition rate; (iv) immediate payoff that depends on state, action profile and population distribution flow; and (v) a discounted factor for each player. Formally, the FSASMFG is denoted by a tuple \(\langle {\mathcal {S}}, {\mathcal {A}}, (Q_{ija}), (r_{ia}), \gamma \rangle , \forall i,j \in {\mathcal {S}}, \forall a \in {\mathcal {A}}\), where
-
\({\mathcal {S}}=\{1, \cdots , S\}\) is the set of possible states of all players, S denotes the number of all states. The state space \(\triangle ({\mathcal {S}})\) is denoted by
$$\begin{aligned} \triangle ({\mathcal {S}})=\left\{ s=(s_{1}, \cdots , s_{S}): s_{k}\ge 0, k=1,\cdots , S, \sum \limits _{k=1}^{S} s_{k}=1 \right\} , \end{aligned}$$that is, \(\triangle ({\mathcal {S}})\) denotes the probability simplex over \({\mathcal {S}}\).
-
\({\mathcal {A}}=\{1, \cdots , A\}\) is the set of possible actions of all players, A denotes the number of all actions. The action space \(\triangle ({\mathcal {A}})\) is denoted by
$$\begin{aligned} \triangle ({\mathcal {A}})=\left\{ a=(a_{1}, \cdots , a_{A}): a_{l}\ge 0, l=1,\cdots , A, \sum \limits _{l=1}^{A} a_{l}=1 \right\} , \end{aligned}$$that is, \(\triangle ({\mathcal {A}})\) denotes the probability simplex over \({\mathcal {A}}\).
-
A (mixed) strategy is a measurable mapping \(\pi : {\mathcal {S}} \times [0, \infty ) \rightarrow \triangle ({\mathcal {A}})\), \((i, t)\mapsto \pi _{i a}(t)_{a \in {\mathcal {A}}}\), where \(\pi _{i a}(t)\) is the probability that the player selects action a in state i and at time t. If a strategy \(d: {\mathcal {S}} \times [0, \infty ) \rightarrow \triangle ({\mathcal {A}})\) satisfies \(\forall t \ge 0\), \(\forall i \in {\mathcal {S}}\) that there exists \(a \in {\mathcal {A}}\) such that \(d_{ia}(t)=1\) and \(d_{ia'}(t)=0\), \(\forall a' \in {\mathcal {A}} {\setminus } \{a\}\), then d is called a deterministic strategy. \(\Pi _i (i \in {\mathcal {S}})\) denotes the (mixed) strategy set in state i, \(\Pi =\Pi _1 \times \cdots \times \Pi _S\) represents the Cartesian product of all mixed strategies.
-
Given a Lipschitz continuous flow of \(m: [0, \infty ) \rightarrow \triangle ({\mathcal {S}})\) and a strategy \(\pi : {\mathcal {S}} \times [0, \infty ) \rightarrow \triangle ({\mathcal {A}})\), respectively, the individual dynamic of each player is given by a Markov decision process (MDP) \(X^{\pi }(m)\) with given initial distribution \(x_0 \in \triangle ({\mathcal {S}})\) and the infinitesimal generator denoted by Q(t)-matrix
$$\begin{aligned} (Q^{\pi }(m(t), t))_{ij} = \sum \limits _{a \in {\mathcal {A}}} Q_{ija}(m(t))\pi _{ia}(t), \end{aligned}$$where \(Q_{ija}(m)\) denotes the transition rates of the player when taking action a from state i to state j and with the population distribution m. The matrix \(Q_{..a}(m)\) denotes the conservative generators, in other words, \(Q_{ija}(m) \ge 0, \forall i, j \in {\mathcal {S}}\) with \(i \ne j\), and \(\sum \limits _{j \in {\mathcal {S}}} Q_{ija}(m) =0, \forall i \in {\mathcal {S}}\).
-
The real-valued function is defined as \(r_{ia}: \triangle ({\mathcal {S}}) \rightarrow {\mathbb {R}}\), \(\forall i \in {\mathcal {S}}\), \(\forall a \in {\mathcal {A}}\), where \(r_{ia}(m)\) denotes the immediate reward of the player when selecting action a in state i and with the population distribution flow being m.
-
\(\gamma \in (0, 1)\) denotes the discounted factor. When \(\gamma \rightarrow 0\), the player is myopic and cares more about the immediate reward. When \(\gamma \rightarrow 1\), the player is farsighted and cares more about the future reward.
To ensure the existence of stationary mean field equilibria for the FSASMFG, Neumann [32, 33] introduced the following some continuity assumptions.
Assumption 2.1
For any \(i, j \in {\mathcal {S}}\), \(a \in {\mathcal {A}}\), the function \(Q_{ija}: \triangle ({\mathcal {S}}) \rightarrow {\mathbb {R}}\) is Lipschitz continuous at m. For any \(i \in {\mathcal {S}}\), \(a \in {\mathcal {A}}\), the function \(r_{ia}: \triangle ({\mathcal {S}}) \rightarrow {\mathbb {R}}\) is continuous at m.
The main aim of every player is to maximize his/her expected discounted payoff when the initial distribution condition \(x_0 \in \triangle ({\mathcal {S}})\), which is given by
where \(\gamma \) denotes the discounted factor and \(r_{ia}: \bigtriangleup ({\mathcal {S}}) \rightarrow {\mathbb {R}}\) is a real-valued function. By [32], we need to face a MDP with excepted discounted payoff, time-inhomogeneous payoff functions and transition rates for a fixed population distribution m. Since the continuity of \(Q_{ija}\) and \(r_{ia}\), it follows that the function \(V_{x_0}: \triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}}) \rightarrow {\mathbb {R}}\) is also continuous.
For the sake of defining stationary mean field equilibria, we need to introduce the concept of stationary strategy. If a strategy \(\pi : {\mathcal {S}} \times [0, \infty ) \rightarrow \triangle ({\mathcal {A}})\) such that \(\pi _{ia}(t)=\pi _{ia}\), \(\forall t \ge 0\), then \(\pi \) is called a stationary strategy. \(\Pi _i^{s} (i \in {\mathcal {S}})\) represents the stationary strategy set in state i, \(\Pi ^{s} = \Pi _{1}^{s} \times \cdots \times \Pi _{S}^{s}\) denotes the Cartesian product of all stationary strategies.
Definition 2.7
(see [33]) A strategy pair \((\pi , m)\) is called stationary mean field equilibrium of the FSASMFG, if there exist a vector \(m \in \triangle ({\mathcal {S}})\) and a stationary strategy \(\pi \in \Pi ^s\) satisfy the following conditions.
- (i):
-
For any \(t \ge 0\), the marginal distribution of the MDP \(X^{\pi }(m)\) at time t is given by m,
- (ii):
-
For any given \(x_{0} \in \triangle ({\mathcal {S}})\), we obtain \( V_{x_{0}}(\pi , m) \ge V_{x_{0}}({\tilde{\pi }}, m), ~\forall {\tilde{\pi }} \in \Pi .\)
The concept is a reasonable formalized definition of stationary equilibrium. Given \(m(0)=m\) and the strategy \(\pi \), then the distribution of population is m for all time points. If a player would like to shift his/her strategy \(\pi \), the condition (ii) of Definition 2.7 guarantees that no player can obtained higher payoff. Therefore, these players have no motivation to alter the equilibrium strategy \(\pi \), which means that the population will indeed remain in a stationary equilibrium regime of playing \(\pi \). Meanwhile, the advantages of any stationary mean field equilibria are that these strategies only depend on the data related to payoff in the game.
In order to better understand the FSASMFG model, we give a concrete example as below.
Example 2.1
We consider a simplified version of the corruption model introduced by Kolokoltsov-Malafeyev [23], which aims to capture the influence of social pressure on the spread of corruption in a society. In the model, a player can be in one of three states corrupt (C), honest (H) and reserved (R). Besides, we set the payoffs of three states to \(r_{C}=10\), \(r_{H}=5\) and \(r_{R}=0\), respectively. The players can choose, given that these players are not reserved, whether they want to maintain corrupt/honset or whether they want to change behavior. The social pressure has an impact on two aspects. On the one hand, the more players are corrupt, the higher is the pressure to also become corrupt. On the other hand, the more players are honest, the higher is the rate to become convicted to be corrupt. For the convenience of simplifying the model of [23], assume that there is no principal agent that convicts the players, that is, we decided to ignore this feature of the model.
Formally, the state spaces are given by \({\mathcal {S}}=\{C, H, R\}\), and the action spaces are given by \({\mathcal {A}}=\{{change, stay}\}\). In state C, the player shifts to state R with rate \(q_{\textrm{soc}} m_{H}\), which increases in the share \(m_{H}\) of players in state H. The player shifts from state C to state H with rate 0 if the player selects action stay, and with rate b if the player selects action change. In state H, the player moves to state C with rate \(q_{\textrm{inf}} m_{C}\) if the player selects the action stay, and with rate \(b+ q_{\textrm{inf}} m_{C}\) if the player selects the action change. In state R, the player shifts to state H with rate \(\lambda \). Other transitions are not directly possible, that is to say, the corresponding transition rates are 0. In conclusion, the transition rate matrices of the individual player are as follows:
An individual player can select any measurable mapping \(\pi : {\mathcal {S}} \times [0, \infty ) \rightarrow \triangle ({\mathcal {A}})\) as a strategy, for instance, for every \(T \ge 0\) the player could select
Given this strategy, the player selects the stay whenever the player is not corrupt or the time is larger than T. If the player is in corrupt and the time is given by \(t \le T\), then the player selects the action change with probability \(e^{t}\), and the action stay with probability \(1 - e^{t}\). The definition of deterministic strategy is denoted by
and the definition of deterministic stationary strategy is expressed by
The payoff functions are given by
Therefore, given a Lipschitz continuous function \(m: [0, \infty ) \rightarrow \triangle ({\mathcal {S}})\), and a player chooses a measurable strategy \(\pi \) such that the formula (1) is maximized, where his/her individual dynamics are given by the time-inhomogeneous Markov chain with initial distribution \(x_0\) and generator \( Q^{\pi }(m(t), t)= \)
Remark 2.2
It is noteworthy that the matrix \(Q_{ij}^{\pi }(m, t)\) is independent of time t in this paper, denoted by \(Q_{ij}^{\pi }(m) = Q_{ij}^{\pi }(m, t)\). Therefore, we acquire that the condition (i) of Definition 2.7 is equivalent to
Besides, the condition (ii) of Definition 2.7 demands that there exists a stationary strategy that simultaneously achieves the highest possible reward value among all strategies for all initial conditions. Furthermore, it has been shown in Sect. 5.1 of [33] that any stationary mean field equilibrium is optimal when an associated MDP satisfies Definition 2.7.
3 Bounded Rationality Model and Well-Posedness
In this section, we set up the bounded rationality model of the FSASMFG and give some sufficient conditions of GS-wp and S-wp for the game problem. Moreover, we obtain the relations of different well-posedness types for the game.
3.1 Bounded Rationality Model
The problem space with abstract bounded rationality function for the FSASMFG is given by
For any \( \chi _1=( Q_{ija}^1, r_{ia}^1 )_{i,j \in {\mathcal {S}}, a\in {\mathcal {A}}} \in \varLambda \), \(\chi _2=( Q_{ija}^2, r_{ia}^2 )_{i,j \in {\mathcal {S}}, a\in {\mathcal {A}}} \in \varLambda \), we define the distance as follows:
By [31], \((\varLambda , \rho )\) is a complete metric space. Next, we define its bounded rationality model given by Anderlini-Canning-Yu [4, 41, 44, 45, 47] to study the well-posedness for the game. The bounded rationality model of the FSASMFG is composed of a quadruple \(\langle \varLambda , (\triangle ({\mathcal {A}}), \triangle ({\mathcal {S}}) ), f, {\varPhi } \rangle \) with the following these conditions.
(H1) The feasible correspondence is \(F: \varLambda \times \triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}}) \rightarrow 2^{\triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})}\) and induces a behavior correspondence \(f: \varLambda \rightarrow 2^{\triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})}\),
Obviously, the correspondence f is usc, and \(\forall \chi \in \varLambda , f(\chi )\) is a nonempty compact subset. The graph of the correspondence f is given by
(H2) For any given \( x_0 \in \triangle ({\mathcal {S}})\), for any \(\chi \in \varLambda \), \((\pi , m) \in \triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})\), the rational function of the FSASMFG is defined by
It is easy to see that \( {\varPhi }(\chi , \pi , m)\ge 0\), and \({\varPhi }(\chi , \pi , m)=0\) is corresponding to the complete rationality.
(H3) A stationary mean field equilibrium correspondence is defined as \(E: \varLambda \rightarrow 2^{\triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}}) }\), which maps every game \(\chi =(Q, r)\) to the set of all stationary mean field equilibria of the FSASMFG. For any \(\chi \in \varLambda \), \(\zeta \ge 0\), the \(\zeta \)-equilibrium solution set of \(\chi \) is defined as
In particular, when \(\zeta =0\),
where \(E(\chi )\) denotes all stationary mean field equilibria solutions set of \(\chi \). Clearly, \(E(\chi ) \ne \varnothing \), \(\forall \chi \in \varLambda \).
In order to obtain some sufficient conditions of well-posedness for the FSASMFG, we first prove the bounded rationality function is lsc.
Lemma 3.1
For any \(\chi \in \varLambda \), \((\pi , m) \in \triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})\), \({\varPhi }\) is lsc at \((\chi , \pi , m)\).
Proof
It only needs to prove that for any \(\zeta >0\), \(\chi _{n} \rightarrow \chi \), \((\pi _{n}, m_{n}) \rightarrow (\pi , m)\), there exists a positive integer N such that \(\forall n \ge N\), we have
that is, for any given \( x_0 \in \triangle ({\mathcal {S}})\),
Since \(V^{n}_{x_0} \rightarrow V_{x_0}\), \((\pi _{n}, m_{n}) \rightarrow (\pi , m)\) and \(V_{x_0}\) is usc at \((\pi , m)\), then there exists a positive integer N such that \(\forall n \ge N\), \(\forall x_0 \in \triangle ({\mathcal {S}})\), we obtain
and
Moreover,
and there exists an initial distribution \((\pi _0, m_0) \in \triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})\) such that
we have
then
we obtain
Hence, \( {\varPhi }\) is lsc at \((\chi , \pi , m)\). \(\square \)
Next, we give some sufficient conditions of GS-wp and S-wp for the game problem.
Theorem 3.1
Given bounded rationality model \(\langle \varLambda , (\triangle ({\mathcal {A}}), \triangle ({\mathcal {S}})), f, {\varPhi } \rangle \), \(\chi \in \varLambda \), \(E(\chi ) \ne \varnothing \), and the following conditions are satisfied.
- (i):
-
\(f: \varLambda \rightarrow 2^{\triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})}\) is usc at \(\chi \), and \(f(\chi )\) is a nonempty compact set;
- (ii):
-
\( {\varPhi }: \varLambda \times \triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}}) \rightarrow {\mathbb {R}}^{+}\) satisfies \( {\varPhi }(\chi , \pi , m) \ge 0\) when \((\pi , m) \in f(\chi )\), and \( {\varPhi }\) is lsc at \((\chi , \pi , m)\).
Then,
-
(a)
\(\chi \) is GS-wp;
-
(b)
if \(E(\chi )=\{(\pi , m)\}\) (a single point set), then \(\chi \) is S-wp.
Proof
(a) For any \(\chi _n \in \varLambda \), \(\chi _n \rightarrow \chi \), \(n=1,2,\cdots \), \((\pi _{n}, m_{n}) \in \triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})\), we have
where \(\zeta _n \rightarrow 0\), then there exists \(({\tilde{\pi }}_{n}, {\tilde{m}}_{n}) \in f(\chi _n)\) such that
By Lemma 2.1, then there exists a subsequence \(\{({\tilde{\pi }}_{n_k}, {\tilde{m}}_{n_k}) \}\) of \(\{({\tilde{\pi }}_{n}, {\tilde{m}}_{n}) \}\) such that \(({\tilde{\pi }}_{n_k}, {\tilde{m}}_{n_k}) \rightarrow (\pi , m) \in f(\chi )\). Since
we obtain \((\pi _{n_k}, m_{n_k}) \rightarrow (\pi , m) \in f(\chi )\). Also, since \( {\varPhi }\) is lsc at \((\chi , \pi , m)\) and \( {\varPhi }(\chi , \pi , m)\) \( \ge 0\), we obtain
it is easy to see that \( {\varPhi }(\chi , \pi , m) =0\). Thus, \((\pi , m) \in E(\chi )\), the game \(\chi \) is GS-wp.
(b) By the method of contradiction, we suppose that \((\pi _{n}, m_{n})\) does not converge to \((\pi , m)\), then there exist an open neighborhood \(O(\pi , m)\) of \((\pi , m)\) and a subsequence \(\{(\pi _{n_k}, m_{n_k})\}\) of \(\{(\pi _{n}, m_{n})\}\) such that \((\pi _{n_k}, m_{n_k}) \notin O(\pi , m)\). Since \(E(\chi )=\{(\pi , m)\}\) (a single point set), by the above conclusion (a), there exists a subsequence \(\{(\pi _{n_k}, m_{n_k})\}\) of \(\{(\pi _{n}, m_{n})\}\) such that \((\pi _{n_k}, m_{n_k}) \rightarrow (\pi , m)\), which obviously contradicts the fact \((\pi _{n_k}, m_{n_k}) \notin O(\pi , m)\). Then, \(\chi \) is S-wp, the proof is complete. \(\square \)
Remark 3.1
By Remark 2.1 and Theorem 3.1, we can easily obtain the following results.
-
(a)
The problem \(\chi \) is G-wp (resp. GT-wp, GH-wp, GLP-wp) for every \(\chi \in \varLambda \).
-
(b)
Suppose that \(E(\chi ) =\{(\pi , m)\}\) (a singleton set), \(\forall \chi \in \varLambda \), then the problem \(\chi \) is wp (resp. T-wp, H-wp, LP-wp).
4 Characterizations of Strong Well-Posedness for FSASMFGs
In the section, we investigate some characterizations of GS-wp and S-wp for the game. Given a bounded rational model \( \langle \varLambda , (\triangle ({\mathcal {A}}), \triangle ({\mathcal {S}})), f, {\varPhi } \rangle \) for the FSASMFG, where \(\varLambda \) is a metric space, \(\forall \chi \in \varLambda \), \(E(\chi ) \ne \varnothing \), \(f: \varLambda \rightarrow 2^{ \triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})}\) is usc with nonempty compact value. For any \(\chi \in \varLambda \), \((\pi , m) \in f(\chi )\), \( {\varPhi }(\chi , \pi , m) \ge 0\), and \( {\varPhi }\) is lsc at \((\chi , \pi , m)\). For any \(\delta > 0\), \( \varepsilon > 0\), \( \zeta > 0\), where \((\delta , \varepsilon , \zeta ) \rightarrow (0, 0, 0)\),
where \(B(\chi , \delta )\) signifies an open ball with a center \(\chi \) and a radius \(\delta \). Obviously, for all \(\chi \in \varLambda \), we have
- (i):
-
\(W(\chi , 0, 0, 0)=E(\chi )\);
- (ii):
-
for any \(\delta>0, \varepsilon>0, \zeta >0\), \(W(\chi , \delta , \varepsilon , \zeta )\supseteq E(\chi ) \);
- (iii):
-
if \(0 \le \delta _2 \le \delta _1\), \(0 \le \varepsilon _2 \le \varepsilon _1\), \(0 \le \zeta _2 \le \zeta _1\), then \(W(\chi , \delta _1, \varepsilon _1, \zeta _1) \supseteq W(\chi , \delta _2, \varepsilon _2, \zeta _2)\).
Theorem 4.1
-
(a)
If \(\chi \) is GS-wp, then the measure of noncompactness \(\alpha ( W(\chi , \delta , \varepsilon , \zeta )) \rightarrow 0\), where \((\delta , \varepsilon , \zeta ) \rightarrow (0, 0, 0)\).
-
(b)
If \(f(\chi )\) is a nonempty closed set and the measures of noncompactness \(\alpha (W(\chi , \delta , \varepsilon , \zeta )) \rightarrow 0\), where \((\delta , \varepsilon , \zeta ) \rightarrow (0, 0, 0)\), then \(\chi \) is GS-wp.
Proof
(a) Given any sequence \(\{(\pi _{n}, m_{n})\} \subset E(\chi )\), it implies that \((\pi _{n}, m_{n}) \in W(\chi , \delta _n, \varepsilon _n, \zeta _n)\), where \((\delta _n, \varepsilon _n, \zeta _n) \rightarrow (0, 0, 0)\). Since \(\chi \) is GS-wp, there exists a subsequence \(\{(\pi _{n_k}, m_{n_k})\}\) of \(\{(\pi _{n}, m_{n})\}\) such that \((\pi _{n_k}, m_{n_k}) \rightarrow (\pi , m) \in E(\chi )\). Therefore, \(E(\chi )\) is a compact set. For any \(\kappa > 0\), there exists open covers \(C_{\kappa }\) of \(E(\chi )\), and \(C_{\kappa }\) is composed of finite open sets, where \(\hbar (C_{\kappa }) \le \kappa \). Next, we only need to prove that for sufficiently small numbers \( \delta>0, \varepsilon>0, \zeta >0\), we have \(\alpha (W(\chi , \delta , \varepsilon , \zeta )) \le \kappa \) and \(\alpha (W(\chi , \delta , \varepsilon , \zeta )) \rightarrow 0\), where \((\delta , \varepsilon , \zeta ) \rightarrow (0, 0, 0)\).
By the method of contradiction, if the above conclusion is not true, then there exist \(\delta _n >0\), \(\varepsilon _n>0\), \(\zeta _n >0\), where \((\delta _n, \varepsilon _n, \zeta _n) \rightarrow (0, 0, 0)\), and sequence \(\{(\pi _{n}, m_{n})\}\) of \(\triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})\) such that \((\pi _{n}, m_{n}) \in W(\chi , \delta _n, \varepsilon _n, \zeta _n)\), but \( (\pi _{n}, m_{n}) \notin C_{\kappa }\). Since \(\chi \) serves as GS-wp, there is a subsequence \(\{(\pi _{n_k}, m_{n_k})\}\) of \(\{(\pi _{n}, m_{n})\}\) such that \((\pi _{n_k}, m_{n_k}) \rightarrow (\pi , m) \in E(\chi ) \subset C_{\kappa }\). Since \((\pi , m)\) is the inner point of \(C_{\kappa }\), which contradicts with \((\pi _{n_k}, m_{n_k}) \notin C_{\kappa }\).
(b) For every \((\pi _{n}, m_{n}) \in W(\chi , \delta _n, \varepsilon _n, \zeta _n)\), \(n=1,2,\cdots \), where \((\delta _n, \varepsilon _n, \zeta _n) \rightarrow (0, 0, 0)\), assume that \(\delta _{n+1} \le \delta _n\), \(\varepsilon _{n+1} \le \varepsilon _n\) and \(\zeta _{n+1} \le \zeta _n\), we have
Denoted by \(C_{n}= \{(\pi _i, m_i): i \ge n\}\), then \( W(\chi , \delta _n, \varepsilon _n, \zeta _n) \supseteq C_n\). Furthermore, let \(\alpha (C_1) =\alpha (C_n)\), \(n=2,3, \cdots \), \(\alpha (C_n) \le \alpha (W (\chi , \delta _n, \varepsilon _n, \zeta _n))\) and \(\alpha (W(\chi , \delta _{n}, \varepsilon _{n}, \zeta _{n})) \rightarrow (0, 0, 0)\) when \(n \rightarrow \infty \), we obtain \(\alpha (C_1)=0\). Since \(\triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})\) is a complete metric space, by Lemma 2.2, we obtain that \({\overline{C}}_1\) is a compact set. Since \(\{(\pi _{n}, m_{n})\} \subset {\overline{C}}_1\), there exists a subsequence \(\{(\pi _{n_k}, m_{n_k})\}\) of \(\{(\pi _{n}, m_{n})\}\) such that \((\pi _{n_k}, m_{n_k}) \rightarrow (\pi , m)\). Because \(\{(\pi _{n_k}, m_{n_k})\} \in W(\chi , \delta _{n_k}, \varepsilon _{n_k}, \zeta _{n_k} )\), we have \(\hbar ((\pi _{n_k}, m_{n_k}), f(\chi ) ) \le \varepsilon _{n_k}\). Let \(n_k \rightarrow \infty \), then \(\hbar ((\pi , m), f(\chi ) ) = 0\). Since \(f(\chi )\) is closed, we can obtain \((\pi , m) \in f(\chi )\).
Next we prove \((\pi , m) \in E(\chi )\). Since \({\varPhi }\) is lsc at \((\chi , \pi , m)\) and \( {\varPhi } (\chi , \pi , m) \ge 0\), we obtain
and thereby \( {\varPhi }(\chi , \pi , m) =0\). This means that \((\pi , m) \in E(\chi )\), and we conclude that the FSASMFG \(\chi \) is GS-wp. \(\square \)
Theorem 4.2
-
(a)
If \(\chi \) is S-wp, then the diameter \(\hbar (W(\chi , \delta , \varepsilon , \zeta ) )\rightarrow 0\) where \((\delta , \varepsilon , \zeta ) \rightarrow (0, 0, 0)\).
-
(b)
If \(f(\chi )\) is a nonempty closed set and the diameter \(\hbar ( W(\chi , \delta , \varepsilon , \zeta )) \rightarrow 0\) where \((\delta , \varepsilon , \zeta ) \rightarrow (0, 0, 0)\), then \(\chi \) is S-wp.
Proof
(a) By contradiction, assume that there exist \(\epsilon >0\) and some sequences \(\{\delta _n\}\), \(\{\varepsilon _n\}\) as well as \(\{\zeta _n\}\), where \((\delta _n, \varepsilon _n, \zeta _n ) \rightarrow (0, 0, 0)\), then \(\hbar (W(\chi , \delta _n, \varepsilon _n, \zeta _n ))\) \( \ge \epsilon \). This implies that there are two sequences \(\{u_n\}\) and \(\{v_n\}\) that satisfy \(u_n, v_n \in W(\chi , \delta _n, \varepsilon _n, \zeta _n)\) and \(\hbar (u_n, v_n) > \frac{\epsilon }{2}\). Since \(\chi \) is S-wp, we obtain \(E(\chi ) = \{(\pi , m)\}\) (a singleton set), \(u_n \rightarrow (\pi , m)\), \(v_n \rightarrow (\pi , m)\) and \( \hbar (u_n, v_n) \rightarrow 0\), which contradict with \( \hbar (u_n, v_n) > \frac{\epsilon }{2}\).
(b) First, we show that \(W(\chi , \delta , \varepsilon , \zeta )\) is closed. Suppose that for any \(\delta >0\), \( \varepsilon >0\), \( \zeta >0\) and for each \( w_n \in W(\chi , \delta , \varepsilon , \zeta )\), \(w_n \rightarrow w\), \(\chi _n \rightarrow \chi '\), then
Furthermore, let \(n \rightarrow \infty \), we have
this means that \(w \in W(\chi , \delta , \varepsilon , \zeta )\), where \((\delta , \varepsilon , \zeta ) \rightarrow (0, 0, 0)\). Thus, \(W(\chi , \delta , \varepsilon , \zeta )\) is closed set.
For any \((\pi _{n}, m_{n}) \in W(\chi , \delta _n, \varepsilon _n, \zeta _n)\), \(n=1,2,\cdots \), where \(\delta _n>0, \varepsilon _n>0, \zeta _n >0\) and \((\delta _n, \varepsilon _n, \zeta _n) \rightarrow (0, 0, 0)\), let \(\delta _{n+1} \le \delta _n\), \(\varepsilon _{n+1} \le \varepsilon _n\) and \(\zeta _{n+1} \le \zeta _n\), we have \(W(\chi , \delta _n, \varepsilon _n, \zeta _n) \supseteq W(\chi , \delta _{n+1}, \varepsilon _{n+1}, \zeta _{n+1})\) and
Since \(\triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})\) is a complete metric space, we have
and \(\hbar ( \overline{W(\chi , \delta _n, \varepsilon _n, \zeta _n)}) \rightarrow 0( n \rightarrow \infty )\). By open cover theorem, then there exists a unique point \((\pi , m) \in \triangle ({\mathcal {A}}) \times \triangle ({\mathcal {S}})\) such that
Because \((\pi _{n}, m_{n}) \in \overline{W(\chi , \delta _n, \varepsilon _n, \zeta _n)}\), we have \((\pi _{n}, m_{n}) \rightarrow (\pi , m)\). And since \((\pi _{n}, m_{n}) \in W(\chi , \delta _n, \varepsilon _n, \zeta _n)\), we can obtain
Let \(n \rightarrow \infty \), it follows that \(\hbar ((\pi , m), f(\chi ))= 0\) and \(f(\chi )\) is closed set, we can obtain \((\pi , m) \in f(\chi )\).
Next we prove \((\pi , m) \in E(\chi )\). Since \( {\varPhi }\) is lsc at \((\chi , \pi , m)\) and \( {\varPhi } (\chi , \pi , m) \ge 0\), we have
and thereby \({\varPhi } (\chi , \pi , m) =0\). This means that \((\pi , m) \in E(\chi )\) and we conclude that the game \(\chi \) is S-wp. \(\square \)
Remark 4.1
According to Theorems 4.1 and 4.2, we verify some characterizations of GS-wp and S-wp for FSASMFGs. In essence, we obtain some sufficient and necessary conditions of GS-wp and S-wp for the game problem.
5 Conclusion
The FSASMFG problems are important, which have been extensively studied by some researchers. Little attention has been devoted to study the stability of stationary mean field equilibria for the FSASMFG. In this paper, we have investigated the well-posedness for a class of FSASMFGs under some mild assumptions. We obtain the following some results.
-
(i)
By constructing an abstract bounded rationality function of the FSASMFG, some sufficient conditions of GS-wp and S-wp of the game are obtained. Furthermore, we have obtained the relations of different well-posedness types, and it is shown that GS-wp unifies G-wp, GT-wp, GH-wp, GLP-wp. Similar conclusions are drawn for S-wp.
-
(ii)
For the GS-wp of FSASMFGs, the approximate solution set for the game is nonempty and the limit of the Kuratowski measure of noncompactness of the approximate solution set for the game converges to 0. For the S-wp of FSASMFGs, the approximate solution set for the game is nonempty, and the limit of the diameter of the approximate solution set for the game converges to 0. In other words, we have obtained some sufficient and necessary conditions of GS-wp and S-wp for the game.
-
(iii)
Compared with the essential stability results introduced by Neumann [31], we have studied the well-posedness and characterizations for FSASMFGs by using nonlinear analysis methods. Yu et al. [48] pointed that the structural stability implies the essentiality relative to \(\varLambda \) under the framework of bounded rationality model. Thus, if the essential equilibrium of the game is a singleton set, then the game must be well-posedness. That is, there exists a dense residual subset of \(\varLambda \) such that for each \(\chi \) belongs to the dense residual subset, then the game \(\chi \) is T-wp and H-wp. These results are some developments and improvements with respect to Neumann’s researches.
In the future, the study of well-posedness based on bounded rationality model will be applied to the mean field game under the premise of diffusion model by giving some suitable conditions. In addition, under weaker continuity assumptions than those in [31], such as semi-continuity, pseudo-continuity or even discontinuity, we further study the stability of stationary mean field equilibria solutions of the FSASMFG.
References
Adlakha, S., Johari, R.: Mean field equilibrium in dynamic games with strategic complementarities. Operat. Res. 61(4), 971–989 (2013)
Aliprantis, C.D., Border, K.C.: Infinite Dimensional Analysis. A Hitchhiker’s Guide. Springer, Berlin (2006)
Ambrose, D.M., Mészáros, A.R.: Well-posedness of mean field games master equations involving non-separable local Hamiltonians. Trans. Am. Math. Soc. 376(4), 2481–2523 (2023)
Anderlini, L., Canning, D.: Structural stability implies robustness to bounded rationality. J. Econ. Theory 101(2), 395–422 (2001)
Aubin, J.P., Ekeland, I.: Applied Nonlinear Analysis. Springer-Verlag, New York (1984)
Aurell, A., Carmona, R., Dayanikli, G., et al.: Optimal incentives to mitigate epidemics: A Stackelberg mean field game approach. Siam J. Control Optim. 60(2), S294–S322 (2022)
Bauso, D., Tembine, H., Başar, T.: Opinion dynamics social networks through mean-field games. Siam J. Control Optim. 54(6), 3225–3257 (2016)
Belak, C., Hoffmann, D., Seifried, F.T.: Continuous-time mean field games with finite state space and common noise. Appl. Math. Optim. 84(3), 3173–3216 (2021)
Caines, P.E., Huang, M.Y., Malhamé, R.P.: Mean Field Games. In: Basar, Tamer, Zaccour, Georges (eds.) Handbook of Dynamic Game Theory. Springer, Cham (2017)
Cardaliaguet, P., Cirant, M., Porretta, A.: Splitting methods and short time existence for the master equations in mean field games. J. Eur. Math. Soc. 25(5), 1823–1918 (2023)
Carmona, R., Delarue, F., Lacker, D.: Mean field games of timing and models for bank runs. Appl. Math. Optim. 76(1), 217–260 (2017)
Carmona, R., Wang, P.: A probabilistic approach to extended finite state mean field games. Math. Operat. Res. 46(2), 471–502 (2021)
Cecchin, A., Fischer, M.: Probabilistic approach to finite state mean field games. Appl. Math. Optim. 81(2), 253–300 (2020)
Doncel, J., Gast, N., Gaujal, B.: Discrete mean field games: existence of equilibria and convergence. J. Dyn. Games 6(3), 1–19 (2019)
Gomes, D.A.: A mean-field game approach to price formation. Dyn. Games Appl. 11(1), 29–53 (2021)
Gomes, D.A., Nurbekyan, L., Pimentel, E.A.: Economic models and mean-field games theory. Printed in Brazil (2015)
Guéant, O.: A reference case for mean field games models. J. Math. Pures Appl. 92(3), 276–294 (2009)
Guéant, O.: From infinity to one: The reduction of some mean field games to a global control problem. hal-00628531 (2011)
Hadikhanlooa, S., Silva, F.: Finite mean field games: fictitious play and convergence to a first order continuous mean field game. J. Math. Pures Appl. 132, 369–397 (2019)
Huang, M.Y., Malhamé, R.P., Caines, P.E.: Large population stochastic dynamic games: closed-loop McKean-Vlasov systems and the Nash certainty equivalence principle. Commun. Inf. Syst. 6(3), 221–252 (2006)
Hung, N.V., Tam, V.M., O’Regan, D., et al.: A new class of generalized multiobjective games in bounded rationality with fuzzy mappings: structural \((\lambda , \varepsilon )\)-stability and \((\lambda , \varepsilon )\)-robustness to \(\varepsilon \)-equilibria. J. Comput. Appl. Math. 372, 112735 (2020)
Kolokoltsov, V.N., Bensoussan, A.: Mean-field-game model for botnet defense in cyber-security. Appl. Math. Optim. 74(3), 669–692 (2016)
Kolokoltsov, V.N., Malafeyev, O.A.: Mean-field-game model of corruption. Dyn. Games Appl. 7(1), 34–47 (2017)
Kuratowski, C.: Sur less espaces complets. Fundamenta Mathematicae 15(1), 301–309 (1930)
Lacker, D.: Mean field games via controlled martingale problems: existence of Markovian equilibria. Stochastic Process. Appl. 125(7), 2856–2894 (2015)
Lasry, J.M., Lions, P.L.: Mean field games. Japan. J. Math. 2(1), 229–260 (2007)
Lemaire, B.: Well-posedness, conditioning and regulation of minimization, inclusion and fixed-point problems. Pliska Stud. Math. Bulgar 12(1), 71–84 (1998)
Levitin, E.S., Polyak, B.T.: Convergence of minimizing sequences in conditional extremum problem. Soviet Math. Dokl. 7, 764–767 (1966)
Light, B., Weintraub, G.Y.: Mean field equilibrium: Uniqueness, existence, and comparative statics. Operat. Res. 70(1), 585–605 (2022)
Miyazaki, Y., Azuma, H.: \((\lambda , \varepsilon )\)-stable model and essential equilibria. Math. Soc. Sci. 65(2), 85–91 (2013)
Neumann, B.A.: Essential stationary equilibria of mean field games with finite state and action space. Math. Soc. Sci. 120, 85–91 (2022)
Neumann, B.A.: Stationary equilibria of mean field games with finite state and action space. Dyn. Games Appl. 10(4), 845–871 (2020)
Neumann, B.A.: Stationary Equilibria of Mean Field Games with Finite State and Action Space: Existence, Computation, Stability, and a Myopic Adjustment Process. Staatsund Universitätsbibliothek Hamburg Carl von Ossietzky (2019)
Revalski, J.P.: Various aspects of well-posedness of optimization problems. In: Lucchetti, R., Revalski, J. (eds.) Recent Developments in Well-posedness Variational Problems. Kluwer Academic Publishers, Netherlands (1995)
Saldi, N., Başar, T., Raginsky, M.: Markov-Nash equilibria in mean-field games with discounted cost. Siam J. Control Optim. 56(6), 4256–4287 (2018)
Scalzo, V.: Hadamard well-posedness in discontinuous non-cooperative games. J. Math. Anal. Appl. 360(2), 697–703 (2009)
Simon, H.A.: The New Science of Management Decision. Prentice-Hall Inc., New Jeresy (1977)
Tykhonov, A.N.: On the stability of the functional optimization problem. USSR J. Comput. Math. Math. Phys. 6, 28–33 (1966)
Wang, N.F., Yang, Z.: The well-posedness for generalized fuzzy games. J. Syst. Sci. Complex 30, 921–931 (2017)
Xiao, Y.B., Huang, N.J.: Well-posedness for a class of variational-hemivariational inequalities with perturbations. J. Optim. Theory Appl. 151(1), 33–51 (2011)
Yang, H., Yu, J.: Unified approaches to well-posedness with some applications. J. Global Optim. 31(3), 371–381 (2005)
Yu, C., Yu, J.: On structural stability and robustness to bounded rationality. Nonlinear Anal. TMA 65(3), 583–592 (2006)
Yu, C., Yu, J.: Bounded rationality in multiobjective games. Nonlinear Anal. TMA 67(3), 930–937 (2007)
Yu, J.: Bounded Rationality and the Stability of Equilibrium Points Set in Game Theory. Science Press, Beijing (2017). ((in Chinese))
Yu, J.: On well-posedness problems. Acta Math. Applicatae Sinica 34(6), 1007–1022 (2011). ((in Chinese))
Yu, J., Yang, H., Yu, C.: Structural stability and robustness to bounded rationality for non-compact cases. J. Global Optim. 44(1), 149–157 (2009)
Yu, J., Yang, H., Yu, C.: Well-posedness Ky Fan’s point, quasi-variational inequality and Nash equilibrium problems. Nonlinear Anal. TMA 66(4), 777–790 (2007)
Yu, J., Yang, Z., Wang, N.F.: Further results on structural stability and robustness to bounded rationality. J. Math. Econ. 67, 49–53 (2016)
Acknowledgements
The authors are grateful to the editor and the reviewers for their valuable comments.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 12061020, 71961003), the Science and Technology Foundation of Guizhou Province (Grant No. 2021088, 20215640). The authors acknowledge these supports.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Negash G. Medhin.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, Lp., Jia, Ws. Well-Posedness for Mean Field Games with Finite State and Action Space. J Optim Theory Appl 201, 36–53 (2024). https://doi.org/10.1007/s10957-024-02379-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-024-02379-5