
Multi-Layer Perceptron-Based Classification with Application to Outlier Detection in Saudi Arabia Stock Returns
 ,
,
Abstract
:1. Introduction
2. Material and Methods
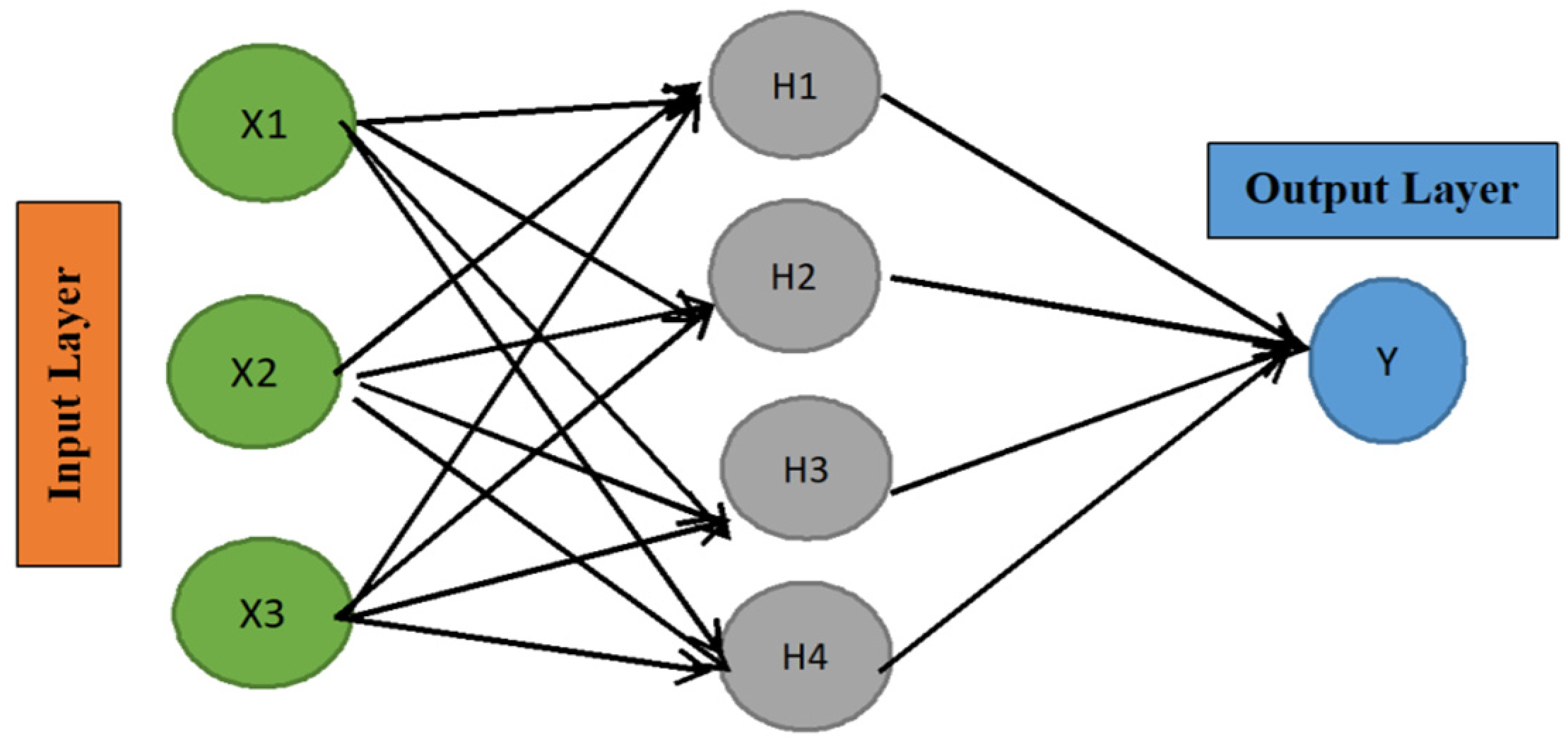
3. Multi-Layer Perceptron
3.1. Learning Parameters
3.2. Resilient Propagation (Rprop)
3.3. Evaluation Measures
- -
- Recall, also called sensitivity, is the true positive rate (TP rate) or the probability of detection. This metric computes the proportion of actual positives that are correctly identified as such and is given by the formula:
- -
- Specificity is also referred to as the true negative rate (TN rate). It computes the proportion of actual negatives that are correctly identified as such, as given in the formula:
- -
- Precision is the positive predictive value, computed by the formula:
- -
- False positive rate (FPrate), also referred to as type I error, is given in the formula:
- -
- False negative rate (FNrate), also referred to as type II error, is given in the formula:
- -
- The F-measure, also called the F-score, is the harmonic mean of precision and sensitivity and is given by the formula:with the worst value = 0 and the best value = 1.
- -
- Matthews correlation coefficient (MCC) is a measure of the quality of the binary classification and is given by the formula:It ranges between −1 and +1, and it reaches −1 for perfect misclassification and +1 for perfect classification.
- -
- Accuracy (ACC) is the measure of the proportion of correct predictions among the total number of cases examined, as shown in the formula:where P and N are the total cases labeled as positive and negative, respectively.
- -
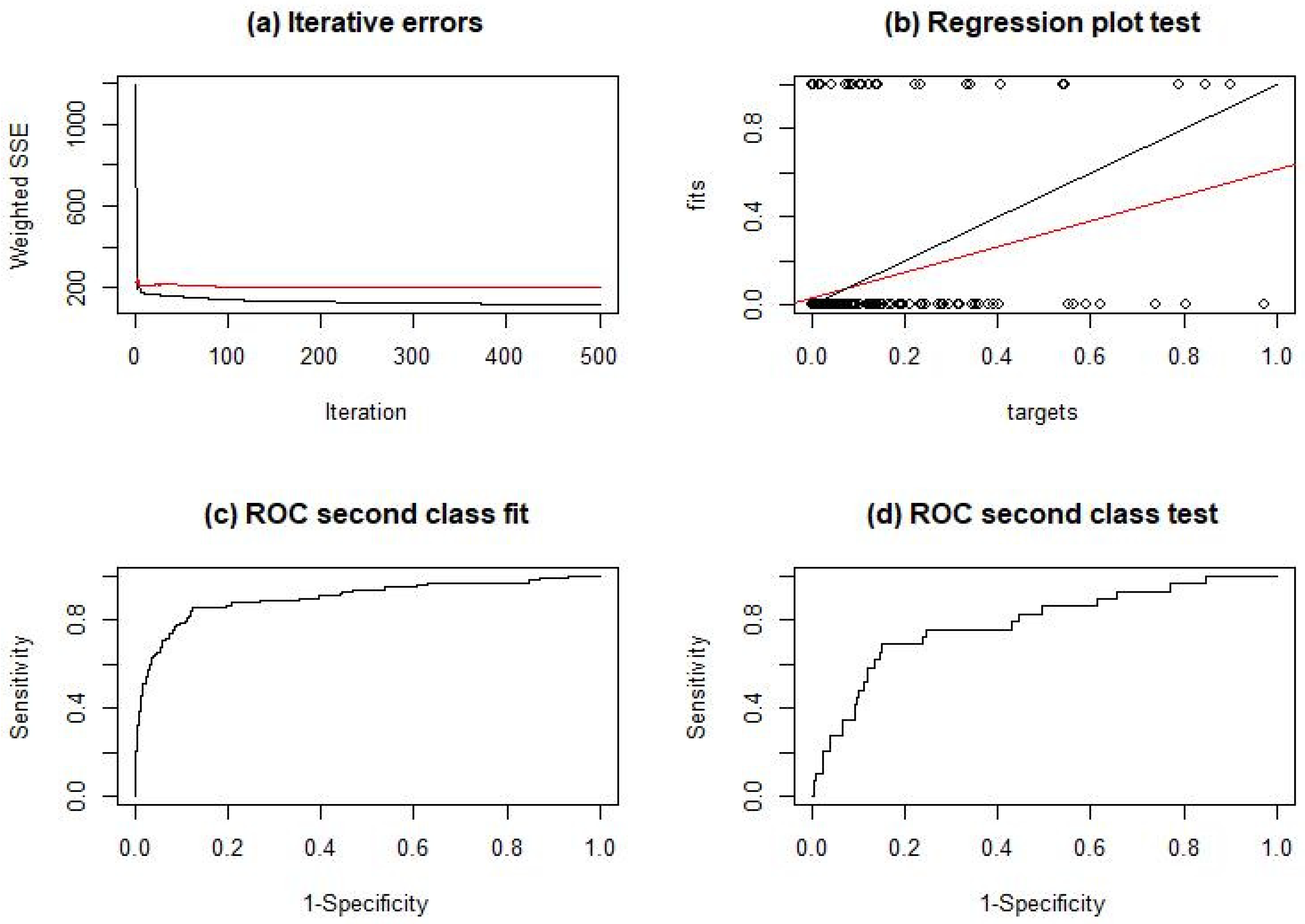
- The area under the ROC curve (AUC). The ROC is a popular graphical performance measure for binary classifiers. The ROC curve is plotted with TPrate against FPrate, where TPrate is on the y-axis and FPrate is on the x-axis. The higher the AUC, the better the model is at predicting 0 classes as 0 and 1 classes as 1.
- -
- The kappa-like statistic is discussed in Zell et al. (1998). In the traditional 2 × 2 confusion matrix employed in machine learning to evaluate the accuracy of binary classifications, the Cohen’s Kappa formula can be written as follows:If the original values show great similarity with the expected values, then . If there is no similarity, then 0.
4. Results
4.1. Data Description
4.1.1. Correlations
4.1.2. Engle and Granger Cointegration Test
4.1.3. Multiple Regression Model
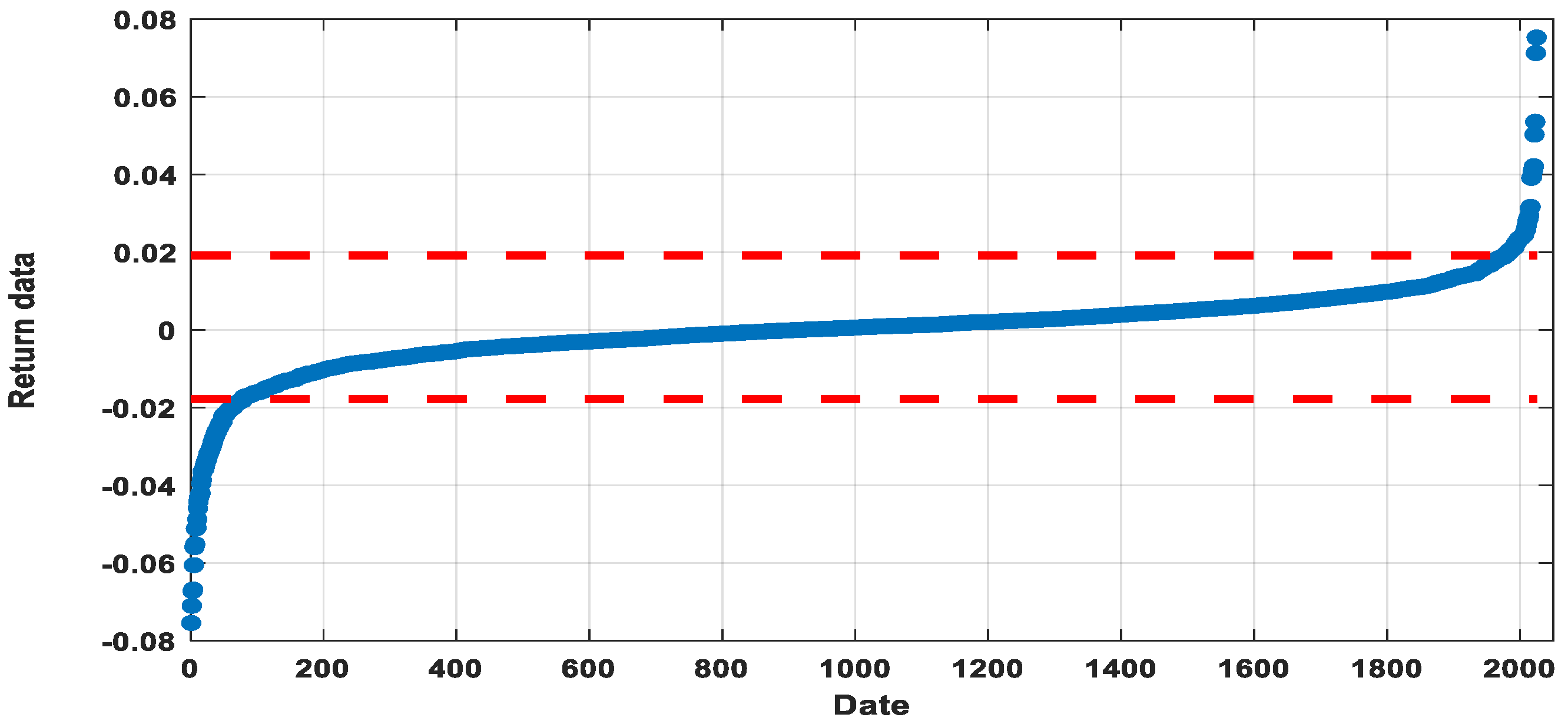
4.2. Outlier Detection
4.2.1. Tukey Method
4.2.2. MLP Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Agahian, Saeid, and Taymaz Akan. 2022. Battle royale optimizer for training multi-layer perceptron. Evolving Systems 13: 563–75. [Google Scholar] [CrossRef]
- Al-Saif, Adel M., Mahmoud Abdel-Sattar, Abdulwahed M. Aboukarima, and Dalia H. Eshra. 2021. Application of a multilayer perceptron artificial neural network for identification of peach cultivars based on physical characteristics. PeerJ 9: e11529. [Google Scholar] [CrossRef]
- Bakhshande, Fateme, Daniel Adofo Ameyaw, Neelu Madan, and Dirk Söffker. 2022. New Metric for Evaluation of Deep Neural Network Applied in Vision-Based Systems. Applied Sciences 12: 3251. [Google Scholar] [CrossRef]
- Bani-Salameh, Hani, Shadi M. Alkhatib, Moawyiah Abdalla, Mo’taz Al-Hami, Ruaa Banat, Hala Zyod, and Ahed J. Alkhatib. 2021. Prediction of diabetes and hypertension using multi-layer perceptron neural networks. International Journal of Modeling, Simulation, Scientific Computing 12: 2150012. [Google Scholar] [CrossRef]
- Bergmeir, Christoph Norbert, and José Manuel Benítez Sánchez. 2012. Neural networks in R using the Stuttgart neural network simulator: RSNNS. Journal of Statistical Software 46. [Google Scholar] [CrossRef]
- Boughaci, Dalila, Abdullah A. K. Alkhawaldeh, Jamil J. Jaber, and Nawaf Hamadneh. 2021. Classification with segmentation for credit scoring and bankruptcy prediction. Empirical Economics 61: 1281–309. [Google Scholar] [CrossRef]
- Chen, Jinghui, Saket Sathe, Charu Aggarwal, and Deepak Turaga. 2017. Outlier detection with autoencoder ensembles. Paper presented at SIAM International Conference on Data Mining, Houston, TX, USA, April 27–29; pp. 90–98. [Google Scholar]
- Engle, Robert F., and Clive W. J. Granger. 1987. Co-integration and error correction: Representation, estimation, and testing. Econometrica: Journal of the Econometric Society 55: 251–76. [Google Scholar] [CrossRef]
- Gouda, Walaa, Sidra Tahir, Saad Alanazi, Maram Almufareh, and Ghadah Alwakid. 2022. Unsupervised Outlier Detection in IOT Using Deep VAE. Sensors 22: 6617. [Google Scholar] [CrossRef] [PubMed]
- Hounmenou, Castro Gbememali, Kossi Essona Gneyou, and Romain Lucas Glele Kakaï. 2021. A Formalism of the General Mathematical Expression of Multilayer Perceptron Neural Networks. Preprints, 2021050412. [Google Scholar] [CrossRef]
- Kaastra, Iebeling, and Milton J. Boyd. 1996. Designing a neural network for forecasting financial and economic time series. Neurocomputing 10: 215–36. [Google Scholar] [CrossRef]
- Mas, Jean-François. 2018. Receiver operating characteristic (ROC) analysis. In Geomatic Approaches for Modeling Land Change Scenarios. Cham: Springer, pp. 465–67. [Google Scholar]
- McClelland, James L., David E. Rumelhart, and Geoffrey E. Hinton. 1986. The Appeal of Parallel Distributed Processing. Cambridge: MIT Press, Volume 3, p. 44. [Google Scholar]
- Metz, Charles E. 1978. Basic principles of ROC analysis. Seminars in Nuclear Medicine 8: 283–98. [Google Scholar] [CrossRef] [PubMed]
- Powers, David M. W. 2020. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv arXiv:2010.16061. [Google Scholar] [CrossRef]
- Rashedi, Khudhayr A., Mohd Tahir Ismail, Nawaf N. Hamadneh, S. Al Wadi, Jamil J. Jaber, and Muhammad Tahir. 2021. Application of radial basis function neural network coupling particle swarm optimization algorithm to classification of Saudi Arabia stock returns. Journal of Mathematics 2021: 5593705. [Google Scholar] [CrossRef]
- Riedmiller, Martin, and Heinrich Braun. 1993. A direct adaptive method for faster backpropagation learning: The RPROP algorithm. Paper presented at IEEE International Conference on Neural Networks, San Francisco, CA, USA, March 28–April 1; pp. 586–91. [Google Scholar]
- Rosenblatt, Frank. 1958. The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review 65: 386. [Google Scholar] [CrossRef] [PubMed]
- Saha, Sunil, Gopal Chandra Paul, Biswajeet Pradhan, Khairul Nizam Abdul Maulud, and Abdullah M Alamri. 2021. Integrating multilayer perceptron neural nets with hybrid ensemble classifiers for deforestation probability assessment in Eastern India. Geomatics, Natural Hazards Risk 12: 29–62. [Google Scholar] [CrossRef]
- Sathe, Saket, and Charu Aggarwal. 2016. LODES: Local Density Meets Spectral Outlier Detection. Paper presented at 2016 SIAM International Conference on Data Mining (SDM), Miami, Florida, USA, May 5–7. [Google Scholar]
- Tukey, John W. 1977. Exploratory Data Analysis. Volume 2, pp. 131–60. [Google Scholar]
- Werbos, P. 1989. Back-propagation and neurocontrol: A review and prospectus. In Paper presented at IEEE Proceedings of the International Joint Conference on Neural Networks (IJCNN’89); pp. 209–16. [Google Scholar]
- Zell, A., G. Mamier, M. Vogt, N. Mache, R. Hübner, S. Döring, K. Herrmann, T. Soyez, M. Schmalzl, and T. Sommer. 1998. SNNS: Stuttgart Neural Network Simulator. User Manual, Version 4.2. Technical Report (6/95). Institute for Parallel Distributed High Performance Systems. [Google Scholar]
- Zurada, Jacek. 1992. Introduction to Artificial Neural Systems. St Paul: West Publishing Co. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Measurements | Stock Prices | Inflation | Repo | Loil |
|---|---|---|---|---|
| Size | 2026 | 2026 | 2026 | 2026 |
| Mean | 7736.387 | 0.016 | 0.696 | 4.299 |
| Std. dev. | 1156.632 | 0.02 | 0.28 | 0.354 |
| Minimum | 5416.47 | −0.032 | 0.127 | 3.328 |
| Maximum | 11149.36 | 0.053 | 4.549 | 4.838 |
| Variables | Closed Prices | Inflation | Repo | Loil |
|---|---|---|---|---|
| Closed prices | 1 | |||
| Inflation | −0.732 | 1 | ||
| Repo | −0.251 | 0.061 | 1 | |
| Loil | −0.556 | 0.501 | 0.327 | 1 |
| Variables | Estimate | Std.Error | t-Stat (ϕ) | p-Value | R-Squared | Causality Detection |
|---|---|---|---|---|---|---|
| Inflation | −0.88575 | 0.02925 | −30.286 | <2 × 10−16 | 0.4331 | Causality |
| Repo | −0.89178 | 0.02930 | −30.436 | <2.2 × 10−16 | 0.4348 | Causality |
| Loil | −0.88806 | 0.02927 | −30.343 | <2 × 10−16 | 0.4338 | Causality |
| Dependent Variable | Independent Variables | OLS | ||
|---|---|---|---|---|
| Estimate | Std.Error | T-Stat | ||
| Intercept | 9.5017 | 0.0278 | 341.4130 *** | |
| Ln(Closed prices) | Inflation | −4.4809 | 0.1185 | −37.8010 *** |
| Repo | −0.0683 | 0.0077 | −8.8990 *** | |
| Loil | −0.1020 | 0.0070 | −14.5850 *** | |
| R-square/Adjusted R-square | 0.6203/0.6197 | |||
| F-stat. | 1102 *** | |||
| Iterations | Sample | Matrix | TP Rate | TN Rate | FP Rate | FN Rate | ||
|---|---|---|---|---|---|---|---|---|
| No Outliers | Outliers | |||||||
| n = 500 | Train (80%) | No outliers | 1511 | 93 | 0.9420 | 0.7222 | 0.2778 | 0.0580 |
| Outliers | 5 | 13 | ||||||
| Test (20%) | No outliers | 378 | 20 | 0.9497 | 0.2857 | 0.7143 | 0.0503 | |
| Outliers | 5 | 2 | ||||||
| n = 1000 | Train (80%) | No outliers | 1510 | 76 | 0.9521 | 0.8571 | 0.1429 | 0.0479 |
| Outliers | 5 | 30 | ||||||
| Test (20%) | No outliers | 378 | 19 | 0.9521 | 0.3750 | 0.6250 | 0.0479 | |
| Outliers | 5 | 3 | ||||||
| n = 1500 | Train (80%) | No outliers | 1511 | 76 | 0.9521 | 0.8571 | 0.1429 | 0.0479 |
| Outliers | 5 | 30 | ||||||
| Test (20%) | No outliers | 376 | 19 | 0.9519 | 0.3000 | 0.7000 | 0.0481 | |
| Outliers | 7 | 3 | ||||||
| Iterations | Sample | ACC | ROC Area | MCC | Precision | F-Score | Cohen’s Kappa |
|---|---|---|---|---|---|---|---|
| n = 500 | Train (80%) | 0.9396 | 0.8321 | 0.2816 | 0.9967 | 0.9686 | 0.1944 |
| Test (20%) | 0.9383 | 0.6177 | 0.1354 | 0.9869 | 0.9680 | 0.1147 | |
| n = 1000 | Train (80%) | 0.9500 | 0.9046 | 0.4758 | 0.9967 | 0.9739 | 0.4063 |
| Test (20%) | 0.9407 | 0.5617 | 0.2008 | 0.9869 | 0.9692 | 0.1761 | |
| n = 1500 | Train (80%) | 0.9501 | 0.9046 | 0.4758 | 0.9967 | 0.9739 | 0.4063 |
| Test (20%) | 0.9358 | 0.5590 | 0.1725 | 0.9817 | 0.9666 | 0.1589 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rashedi, K.A.; Ismail, M.T.; Al Wadi, S.; Serroukh, A.; Alshammari, T.S.; Jaber, J.J. Multi-Layer Perceptron-Based Classification with Application to Outlier Detection in Saudi Arabia Stock Returns. J. Risk Financial Manag. 2024, 17, 69. https://doi.org/10.3390/jrfm17020069
Rashedi KA, Ismail MT, Al Wadi S, Serroukh A, Alshammari TS, Jaber JJ. Multi-Layer Perceptron-Based Classification with Application to Outlier Detection in Saudi Arabia Stock Returns. Journal of Risk and Financial Management. 2024; 17(2):69. https://doi.org/10.3390/jrfm17020069
Chicago/Turabian StyleRashedi, Khudhayr A., Mohd Tahir Ismail, Sadam Al Wadi, Abdeslam Serroukh, Tariq S. Alshammari, and Jamil J. Jaber. 2024. "Multi-Layer Perceptron-Based Classification with Application to Outlier Detection in Saudi Arabia Stock Returns" Journal of Risk and Financial Management 17, no. 2: 69. https://doi.org/10.3390/jrfm17020069