
Abstract
Creating abbreviated measures from lengthy questionnaires is important for reducing respondent burden while improving response quality. Though factor analytic strategies have been used to guide item retention for abbreviated questionnaires, item retention can be conceptualized as a feature selection task amenable to machine learning approaches. The present study tested a machine learning-guided approach to item retention, specifically item-level importance as measured by Shapley values for the prediction of total score, to create abbreviated versions of the Penn State Worry Questionnaire (PSWQ) in a sample of 3,906 secondary school students. Results showed that Shapley values were a useful measure for determining item retention in creating abbreviated versions of the PSWQ, demonstrating concordance with the full PSWQ. As item-level importance varied based on the proportion of the worry distribution predicted (e.g., high versus low PSWQ scores), item retention is dependent on the intended purpose of the abbreviated measure. Illustrative examples are presented.
Similar content being viewed by others


Abbreviated versions of existing questionnaires and rating scales that demonstrate high reliability and validity are often desirable, particularly in settings where lengthy assessment procedures are not feasible (Volpe et al., 2005; Volpe and DuPaul, 2001). Abbreviated measures can also substantially reduce respondent burden, maximizing respondent attentiveness and response quality (Credé et al., 2012; Gibbons et al., 2008; Schroeders et al., 2016). In fact, long questionnaires and rating scales are often associated with high missing response rates and poor data quality (Galesic & Bosnjak, 2009). However, shortening measures can lead to lower reliability and validity of the measure if careful consideration is not used in deciding which items to remove and which to retain (Schroeders et al., 2016; Smith et al., 2000). To mitigate poor data quality, abbreviated measures are often created from pre-existing measures using factor analytic strategies to inform item retention. For example, items with the highest factor loadings are often retained as they are thought to be the most accurate indicators of the construct of interest (Tabachnick & Fidell, 2007). However, factor analytic strategies favor retaining items which most reliably predict the underlying construct without considering the unique variance in total score contributed by each item, meaning that factor analytic strategies may favor items which are highly redundant (Gonzalez, 2020).
Other strategies for creating efficient abbreviated questionnaires include computerized adaptive testing, which administers items in an efficient and dynamic way tailored to each respondent until a certain standard error of measurement or reliability of the measured latent construct is reached, reducing completion time (Embretson & Reise, 2000; Magis et al., 2017; van der Linden & Glas, 2006). However, others have suggested that selecting items to retain for an abbreviated measure could be conceptualized as a feature selection task, which differentiates itself from factor analytic strategies by focusing on the impact each item has on model predictions (Gonzalez, 2020; Kuhn & Johnson, 2013). Defining the importance of an item as its contribution to model predictions, rather than its reliability as a measure of a latent construct, lends itself to machine learning approaches which aim to predict relevant outcomes rather than to make statistical inferences (Orrù et al., 2020). Shapley Additive Explanations (SHAP) values are a measure of feature importance that describe the impact of each feature (e.g., item) on model output. SHAP values can explain which specific features contributed to a specific classification (Lundberg & Lee, 2017). From the perspective of creating an abbreviated questionnaire, SHAP values look for unique variance in a total score that each item can explain, maximizing the amount of variance that can be explained by the fewest number of questions. Redundant items are likely to be disfavored as they would not explain additional variance in total score. Whereas ablation studies typically involve removing or disabling specific features of a model to evaluate the global impact on the model’s performance, SHAP independently computes the contribution of each feature, providing a more granular understanding how each feature additively influences model output (Chen et al., 2022). Thus, SHAP values are an ideal method to quantify the importance of specific items when choosing which items to retain to create an abbreviated measure.
The present study tested the utility of feature importance, defined by SHAP values, for creating abbreviated measures of the Penn State Worry Questionnaire (PSWQ; Meyer et al., 1990), a self-report measure of excessive worry. We chose the PSWQ as it is a popular measure used in research and clinical settings, and it is used as a screener for generalized anxiety disorder (Behar et al., 2003; Fresco et al., 2003). Additionally, the PSWQ has been abbreviated to a five-item and three-item version using factor analytic strategies (Berle et al., 2011; Topper et al., 2014). We hypothesized that retaining items with the highest SHAP values would result in abbreviated questionnaires that would demonstrate higher agreement with the full PSWQ compared to abbreviated questionnaires based on retaining items with the lowest SHAP values. Additionally, an illustrative example of how machine learning derived SHAP values can be used to create abbreviated questionnaires is provided. Finally, we tested the effectiveness of our SHAP-guided item retention strategy by comparing classification accuracy with a five-item abbreviated version of the PSWQ derived using factor analysis from the same dataset (Topper et al., 2014).
Methods
Participants
This study is a secondary data analysis of de-identified data. The data used were collected from 3,906 adolescents, aged 14–19 years-old (53.6% female), from 13 secondary schools in the Netherlands who completed the Dutch version of the PSWQ as part of a recruitment procedure for a randomized controlled trial (see Topper et al., 2014 for details and ethics approval statement).
Questionnaire
The PSWQ is a 16-item, self-report, unidimensional measure of worry that has demonstrated high internal inconsistency (Cronbach’s α = 0.93) and high test–retest reliability (r = 0.92; Meyer et al., 1990). Additionally, the PSWQ demonstrates good convergent validity with measures of generalized anxiety disorder (Liu et al., 2021; Meyer et al., 1990). Each item is rated on a five-point Likert scale with “1” indicating that the question asked is not very typical of the participant to “5”, signifying that the question is very typical. 11 of the items are positively worded while five of the items are negatively worded and reverse scored. As the negatively worded items have demonstrated limited validity and predictive utility (Liu et al., 2021), only the 11 positively worded items were used in the present study. The 11 positively-worded items showed high internal consistency (Cronbach’s α = 0.91), and the total of the 11 items was approximately normally distributed (Skew = 0.67, Kurtosis = 0.13). Inter-item correlations, item-level skew and kurtosis, and content of each item can be found in Supplementary Materials Tables S1-S3. Data missingness rate was 0.68% and Little’s MCAR test was not significant (p > 0.05). Missing data were handled using multiple imputation. When directly comparing to the Topper et al. (2014) results, all 16 items were used for parity.
Data Analysis Overview
Several steps were taken to develop and perform classification on abbreviated versions of the PSWQ. First, a classification strategy was developed to divide participants into equally sized partitions, ranging from two to eight partitions or bins in an ordered array, based on their PSWQ total score (e.g., upper or lower 50% of PSWQ total score in the two-bin case). Next, a neural network was trained on each bin array creating a classification model, using participant’s responses to each individual question as input to classify which bin their PSWQ total score belonged to. Each model was used, together with DeepExplainer (part of the SHAP library) to determine the order of importance for each PSWQ item based on SHAP values. Finally, for each classification model a question configuration was returned in which abbreviated PSWQ questionnaires were created by sequentially adding items based on their SHAP values. The abbreviated PSWQ forms were evaluated using multiple metrics (e.g., accuracy, precision, and bin-averaged F1 score) in classifying each participant’s PSWQ total score. Each of these steps is elaborated below.
Model Building
To build a classification model, each subject’s total PSWQ score was partitioned into one of n possible bins for a given bin array (Fig. 1). Arrays of two through eight bins were tested in the present study. In each of the bin arrays, lower bins corresponded to lower PSWQ total scores (i.e., lower levels of endorsed worry) whereas higher bins corresponded to higher PSWQ total scores (i.e., higher levels of endorsed worry).

N-Bin Arrays for Classification Models. The normal distribution was partitioned into two through eight bin arrays to develop the classification models for predicting PSWQ total score. As illustrated here, an eight-bin array would have eight bins, each with approximately 12.5% of worry scores
Next, for each bin array, participants were classified into the appropriate bin based on item-level PSWQ responses using multiple machine learning (ML) methods. That is, item-level responses were used to predict the appropriate bin representing total PSWQ score. We evaluated multiple machine learning (ML) models to determine the most effective approach for our classification task. This comparison included models such as K-Nearest Neighbors (KNN), Random Forest, Decision Tree, among others, in addition to neural networks (NNs), support vector machines (SVMs), and logistic regression (LR) (see Supplementary Materials Figure S1). Models that consistently returned > 95% prediction accuracies across binning schemes (NNs, SVMs LRs) were retained. Only the 11 positively worded items were used in the creation of the brief questionnaires (Liu et al., 2021) for a given ML algorithm. Each model’s classification metrics were then compared and evaluated to guide the best approach for worry classification (Fig. 2).

Accuracy and F1 Scores for Two-, Four-, and Eight-Bin Models. Accuracy and weighted-F1 scores are compared among the different algorithms for two-, four-, and eight-bin models
Each model was trained on a randomly selected 80% (N = 3,125) of the sample and tested on the remaining unseen 20% (N = 781) Scikit learn version 0.24.2 was used for SVM and LR classifications. Each model’s hyperparameters were found using Gridsearch (Table 1). The SVM was comprised of a radial basis function (RBF) kernel, a penalty (C) parameter set to 1000, and the gamma value of 0.001 while the LR used the l2 penalty function with the penalty value set to 100. All other parameters for both the SVM and LR were left to their defaults. Keras version 2.4.3 was used to model the NN. The NN was composed of two layers; the first was composed of 50 neurons, the second with 60 (Fig. 3). The sigmoid activation function was used for all neurons, the RMSProp optimizer was applied, and the fitting metric was set to accuracy. For classification using each ML algorithm for each n-bin model, training and testing were standardized separately. Unless otherwise noted, weighted averaging was used for precision, recall, and bin-averaged F1 metrics in order to avoid biased weighting from unbalanced classifications due to a less than perfect normal distribution for participants’ total PSWQ scores. It should be noted that, as recall is weighted, it becomes the same as accuracy. All classification metrics were determined by averaging over 100 unique classification models that were trained and tested on random subsamples.

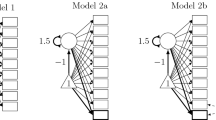
Chosen Neural Network Architecture. Gridsearch results (Table 1) returned a neural network with two hidden layers of 50 and 60 neurons. The input layer is comprised of individual questions (features), and the output layer is the number of bins used for classification. For example, in our chosen model the input layer consists of 11 questions and two- through eight-bins so the output layer would have two to eight neurons, respectively
Item-level Importance
SHAP values were calculated via the DeepExplainer method to determine relative PSWQ item-level importance for each n-bin model. Applying the DeepExplainer method to each of the n-bin classification models returned a configuration of questions for each bin in the model. Each question configuration represented the relative item-level importance determined by the corresponding averaged absolute SHAP values (Molnar, 2020) and was then used for classifying participants’ worry level. For example, applying the DeepExplainer method to a model created using two, four, or eight bins returns a question configuration for each of the respective bin arrays (see Fig. 4).

Item Importance for each N-Bin Model. Each row demonstrates SHAP values for a two-bin, four-bin, and eight-bin model, respectively. The graphs on the left display question configurations for each bin. Graphs on the right stack SHAP values per configuration for each item giving an average configuration
Abbreviated versions of the PSWQ were created by averaging each of the SHAP values for each question across each bin-specific question configuration for a given n-bin array, and then building an ordered list of items weighted by total SHAP value. For example, to build an n-item abbreviated version of the PSWQ over an eight-bin model, DeepExplainer was applied to the model trained on the 11-item questionnaire, resulting in eight question configurations, with each of the eight bins containing SHAP values for the 11 positively worded questions (Fig. 5, left panel). Next, the SHAP value for each of the questions was averaged across each question configuration for each bin (e.g., item one bin one SHAP value averaged with item one bin two SHAP value, and likewise all first-items in the consecutive bins through bin eight are combined to give the first-question average) resulting in averaged SHAP values, one for each question (Fig. 5 right panel). Using this method, the first n questions with the highest averaged SHAP values for a given n-bin array were selected to create an abbreviated PSWQ. Relatedly, this same procedure was used to select items with the lowest average SHAP values with which to compare PSWQ total score bin prediction accuracy.

SHAP Values in a Targeted vs. Averaged Configuration. Example of an eight-bin model question configuration based on SHAP values. The graph on the left shows item-level importance configuration per bin. Each of the respective items in each of the configurations in the left graph were averaged across bins to get the total averaged SHAP value displayed in the graph on the right
Using the methods described above, abbreviated versions of the PSWQ were created by averaging SHAP values for each question configuration across all bins and subsequently choosing items to retain. However, an averaged configuration is often different from a question configuration of a particular bin, and it may be desirable to develop an abbreviated questionnaire to target a specific level of worry. As each bin is used to classify worry scores, using the question configuration associated with a specific bin corresponding to a particular level of worry can be used to develop an abbreviated measure. To test feature importance for an abbreviated measure to screen for elevated worry, question configurations associated with the top 25% of scores (bin four) from a four-bin classification model were used. Question configurations based on feature importance from the top 25% of scores were then compared to question configurations based on feature importance from the lowest 25% of scores (bin one) and averaged feature importance across all bins. We also applied the same procedure to those falling in the top 5% of PSWQ scores. This was done to understand which questions may be useful in screening for the highest level of worry.
To test abbreviated versions of the PSWQ that best approximated full questionnaire performance, each of the 11 items were ranked by their SHAP values in descending order from highest to lowest. An iterative process was used by selecting a single question with the highest SHAP value and adding another question with the next highest SHAP value, and so on, until a desired abbreviated questionnaire length or classification metric was obtained, or until all items were used. The classification metrics for the abbreviated questionnaires were determined by comparing each participant’s bin classification based on the abbreviated questionnaire against the actual bin each participant’s full PSWQ score belonged.
Comparison with Factor-Analytic Approach
To evaluate the utility of our SHAP based approach in creating abbreviated questionnaires, we used all 16 PSWQ items to directly compare with Topper et al.’s (2014) five-item questionnaire derived from a factor analytic approach. From the 16 items, the top five questions (those questions with the highest SHAP averaged values) were selected to create a comparable brief questionnaire. To directly compare with the Topper et al. (2014) results, we used binary classification to predict the top quartile of PSWQ total scores with micro-averaged classification metrics. Notably, we used the same sample as Topper et al. (2014).
Transparency and Openness
De-identified data for the present study were obtained by emailing the original study author (Topper et al., 2014). This study was not preregistered. All data and data analysis code for the present study are publicly available on the Open Science Framework (https://osf.io/ejwyp/?view_only=6347e5adcf2946d69f96bc18285e4c3e).
Results
Model Selection
Multiple ML algorithms were compared based on their n-bin classification metrics. All ML algorithms performed with a score of more than 95% for all classification metrics. However, the NN model performed slightly better on all metrics than the SVM and LR models for each of the two-, four-, and eight- bin cases (Fig. 2). Therefore, NN models were used to assess model performance and evaluate item importance.
N-Bin Model Performance
For each model (two through eight bins), classification for each bin was performed on sets of questions ordered by their SHAP values in descending order. Prediction accuracy and averaged-F1 metrics for each n-bin model are shown in Fig. 6. As might be expected, classification metrics for abbreviated questionnaires over larger bin arrays performed worse. That is, classification using a two-bin model performed better than an eight-bin model, due to the possibility of more misclassifications relative to models with fewer bins. For all models, classification metrics depended nearly linearly on the number of questions used for each abbreviated questionnaire, such that there was no apparent cutoff in which an additional question returned only marginal increases in classification metrics (Fig. 6). These results are consistent with factor analytic research demonstrating that the factor loadings for each of the positively worded PSWQ items significantly loaded on to a common worry factor (Liu et al, 2021; Meyer et al., 1990).

Averaged Configuration Classification Metrics for All N-Bin Models. Displays accuracy and weighted-F1 (average of the weighted bin-wise harmonic means between precision and recall) classification metrics for the total number of items per bin based on the highest SHAP values. The x-axis represents the total number of questions used in classification (e.g., classifying worry scores using a three-item abbreviated version of the PSWQ in a five-bin model yields approximately 60% accuracy and weighted-F1 score). The questions on the x-axis are arranged in descending order according to item importance such that first question represents the highest SHAP value
Item Importance and Selection
Relative item importance varied with each binned model (two through eight bins), affecting the items retained for abbreviated versions of the PSWQ. Figure 4 displays results using DeepExplainer to classify worry levels into two, four, and eight-bins. In the two-bin case, both low and high bins (bin one and two, respectively) demonstrated nearly identical SHAP values for each item. In the four-bin and eight-bin cases, item-level SHAP values began to shift between the low and high bins. For example, Q16 (question number 16) has a subsequently lower SHAP value as higher levels of worry are screened for (Fig. 4). This shift in SHAP values is also seen in the top 5% of worry as question seven becomes the item with the highest SHAP value (Table 2 and Table 3). As demonstrated in Fig. 5, per item SHAP values varied among the n-bin models tested, and averaging SHAP values across configurations for a given n-bin model returned averaged configurations that may be different than a particular bin. Creating abbreviated questionnaires from averaged configurations across all bins may offer an increase in classification. However, targeting a particular proportion of the worry distribution (e.g., highest or lowest range of PSWQ scores) may be desirable and can yield better results relative to abbreviated questionnaires that are based on averaged configurations across all bins. Next, we provide an illustrative example of how a four-bin model performs using averaged SHAP configurations and SHAP configurations from the top 25% (bin four, the highest bin).
Illustrative Example: Creating an Abbreviated Questionnaire for a Non-targeted Sample
Using two, four-bin models, items with high and low relative importance were tested in terms of their prediction accuracy of total PSWQ score. As displayed in Table 4, questions were ordered based on their relative importance using averaged item-level SHAP values, and the classification metrics represent the addition of consecutive questions. That is, classification metrics for Q5 in the top half of Table 4 are derived using that single question to predict total PSWQ score whereas classification metrics for Q6 (question number six) are derived from using Q5 and Q6 to predict total PSWQ score. The comparison of the forward (questions ordered from highest to lowest degree of importance based on averaged SHAP values) and reversed (questions ordered from lowest to highest degree of importance based on averaged SHAP values) configuration arrays is done to contrast the predictive ability among abbreviated questionnaire versions based on the items retained. While it was expected that the forward questionnaires would give better results, several percentage points were added to the prediction ability for smaller abbreviated questionnaires. As the number of items grew, the abbreviated questionnaires gave increasingly similar metrics. In general, an abbreviated PSWQ can be developed by choosing the level of the desired classification metric and the particular items needed to reach that metric. For example, using the four-bin array illustrated in Table 4, a six-item abbreviated PSWQ consisting of questions five, six, sixteen, four, thirteen, and seven achieves at least 79% across classification metrics.
Illustrative Example: Creating Abbreviated Measures to Target High Levels of Worry
Abbreviated versions of the PSWQ described above and displayed in Table 4 were created by averaging SHAP values for each question configuration across all bins in a four-bin array and subsequently choosing items to retain. However, in settings where screeners for high worry are needed, developing an abbreviated version of the PSWQ that targets a specific population (e.g., the top quartile) may be desirable. Three, eight-bin models were run to test prediction metrics targeting excessive worry, defined as the top 12.5% (bin eight). As illustrated in Table 5, creating abbreviated questionnaires that target a specific part of the PSWQ total score distribution become categorical as there are only two prediction possibilities. For example, a configuration targeting the highest level of worry in an eight-bin model would default to predicting the top 12.5% or the lower 87.5%, resulting in two prediction possibilities. It is important to note that the classification metrics in Table 5 appear to be much higher than the classification metrics derived from the four-bin model (Table 4) as Table 5 displays only two prediction possibilities (top 12.5% or lower 87.5%) allowing for fewer misclassifications due to the reduced number (from four to two) of classification categories.
Targeting individuals with excessive worry by using the question configuration associated with the highest bin (top 12.5%) in the eight-bin model offered small benefits in the classification metrics of accuracy and weighted-F1 scores but increased precision by > 8% for a single question (Q5 vs. Q16: Table 5). As expected, as more questions were added, classification metrics using each configuration became similar. Interestingly, while Q16 had the lowest SHAP value when targeting the highest 12.5% of worry using the eight-bin configuration, it had the highest SHAP value when predicting the lowest 12.5% of worry (Fig. 4). This demonstrates that when targeting particular levels of worry, the relative importance of items differs and using an optimized question ordering based on a targeted level of worry may provide better classification metrics (Table 5).
Illustrative Example: Highest Levels of Worry and the Importance of Retained Items
Using SHAP to target the top 12.5% of worriers highlights the importance of question ordering in targeting worry. If, however, we were interested in targeting individuals reporting even higher degrees of worry, the threshold for worry classification can be adjusted to screen for individuals who might be prioritized for intervention. Applying the same methodology as was done for classifying the top 12.5% of worriers, we instead targeted individuals with worry scores in the top 5%. We found that a single item abbreviated questionnaire was able to classify individuals correctly over 90% of the time. In targeting the highest levels of worry, questions with lower SHAP values in the non-targeted two- and four-bin cases increased in value; for example, while having a lower SHAP value in the non-targeted case, question seven became the item with the highest SHAP value when predicting the highest levels of worry (Table 3).
SHAP-Informed Abbreviated Questionnaire Outperforms Factor Analytic Approach
A direct comparison between our approach and the traditional factor analysis method used by Topper et al. (2014) to create a five-item abbreviated questionnaire is shown in Table 6. Across all classification metrics, the SHAP-informed NN method outperformed the factor analytic approach as reported in Topper et al. (2014) in predicting the highest 25% of PSWQ scores. Despite different approaches, four items overlapped with Topper et al. (2014) demonstrating that applying SHAP to the NN model returns screener results similar to that derived using loading factors. However, question seven, which had the highest SHAP valued when predicting the top 5% of worry (Table 3), did not appear in those questions retained when using factor loadings. This shows that NNs in conjunction with SHAP allows for the possibility of finding items that other methods may miss.
In conclusion, classification using targeted and average question configurations can offer distinct predictive advantages in creating abbreviated questionnaires.
Discussion
Abbreviated questionnaires created from retaining specific items from existing questionnaires are desirable for purposes of decreasing respondent burden and maximizing response quality, particularly when used for screening or progress monitoring. However, choosing which items to retain should be done in such a way that maximizes reliability and validity of the abbreviated questionnaire. Pursuant to the idea that item retention can be seen as a feature selection task (Gonzalez, 2020; Kuhn & Johnson, 2013), this study employed machine learning methods to test feature importance, measured by SHAP values, of individual items from the PSWQ in predicting the bin, or an approximate range, of a participant’s total score. An illustrative example of how feature importance could then be used to guide item retention using the PSWQ was discussed. Finally, we tested the effectiveness of our SHAP-guided item retention approach by comparing classification metrics with a factor analytic derived five-item abbreviated version of the PSWQ using the same dataset (Topper et al., 2014). Results demonstrated that items with higher feature importance had greater incremental predictive utility for a given individual’s total PSWQ score (Fig. 6) across a wide range of the worry distribution. Additionally, using SHAP in combination with an NN outperformed a traditional factor analytic approach across classification metrics and highlighted an item (question seven, Table 6) with high predictive utility in screening for excessive worry that was not captured by factor loadings. Overall, results demonstrate that retaining items with higher feature importance is an effective strategy for creating brief and reliable forms of questionnaires.
Using a binning strategy to first separate the PSWQ total score distribution into equally sized bins, two-bin through eight-bin arrays of classified scores were used as reference groups to test classification accuracy and item importance using our machine learning models. Results indicated that as the number of bins increased, classification metrics decreased, which is to be expected as the model is required to accurately classify more levels of worry with greater precision. Still, across all bin arrays, the models performed substantially better than chance in classification accuracy, even when using very few questions (Table 4). This is likely due to a combination of the PSWQ’s high internal consistency and neural network models’ ability to use item-level data in classification; when a measure’s item-level responses demonstrate high agreement, then a respondent’s tendency of item-level responses to be higher or lower is more predictable based on individual responses, which corresponds to higher classification metrics for the total score. However, our results show that the granularity by which total score can be predicted is limited. For example, the accuracy of an abbreviated PSWQ questionnaire in predicting PSWQ total score with less than four-items drops to about 70% when trying to classify beyond four bins (Fig. 6). Still, as Table 4 shows, retaining items with the highest SHAP values yielded higher classification metrics than using items with the lowest SHAP values, illustrating that SHAP values are useful in identifying items that will yield greater classification metrics.
As our results show, the importance of items depends on the degree of worry being predicted; that is, the SHAP value for each item changes depending on the specific bin being predicted (e.g., the top 12.5%, Table 5; or the top 5%, Table 3). There are advantages and disadvantages depending on the purpose of the abbreviated questionnaire. For example, if the brief questionnaire is meant as a progress monitoring tool, then it is important that the brief questionnaire is sensitive to changes across the entire spectrum of potential scores, meaning that retaining items with the highest average SHAP values is more desirable. However, if the brief questionnaire is meant as a screening tool to identify patients who are at risk for GAD, then increased precision in predicting elevations in PSWQ scores should be the focus, meaning that retaining items based on the SHAP values specific to the highest bin may be more effective. Results demonstrated that using optimized question configurations to predict high degrees of worry revealed a shift in item importance and potentially better prediction scores (Table 3 and Table 5). Therefore, the intended purpose of the brief questionnaire should be considered, as this will change the way in which items should be retained.
Finally, our results show that NNs perform as a top classifier in comparison with other popular and very effective machine learning approaches such as SVMs and LR (Fig. 2). Results demonstrate that the multi-bin classification of worry can be predicted above the 95th percentile range. In summary, the usage of NNs together with SHAP may offer new insights into which questions are the most meaningful predictors of phenomena of interest as well which subsets of questions might be retained to create abbreviated questionnaires. Furthermore, the methods introduced give an alternative approach to factor analysis while giving comparable results.
Limitations
While this study used a large sample of adolescents to explore the creation of brief versions of the PSWQ, the exclusive focus on adolescents means that results may not generalize to other populations. For example, younger respondents are known to have different patterns of response bias than older participants, possibly related to differences in social desirability (Kozma & Stones, 1988; Soubelet & Salthouse, 2011). Another concern is that the choice of algorithm used in machine learning is justified by its performance (Orrù et al., 2020), though its interpretability may be limited. In the present study, multi-layer neural network models outperformed logistic regression and support vector machine models in terms of classification accuracy, but neural network models, particularly those with multiple layers, are more difficult to interpret in regard to how each item leads to a particular prediction, than logistic regression or support vector machine models. Additionally, though repeated re-sampling procedures were performed using randomized partitions of the full sample, a second independent sample would need to be used to test the models trained on the current sample to ensure the external validity of the results. Another potential limitation is that SHAP values can be sensitive to correlated features, potentially leading to imprecise and misleading interpretations (e.g., Kumar et al., 2021). However, given known properties of SHAP values such as accounting for interactions among features, SHAP values may offer a more robust approach to evaluating feature importance relative to classic ablation studies. A classical ablation study without SHAP values may struggle to disentangle the effects of correlated features, potentially leading to less accurate assessments of feature importance. Further empirical research directly comparing these two methods in the presence of correlated features would provide valuable insights into their relative performance. Finally, it is difficult to gauge whether differences in classification metrics, such as the higher classification metrics for the highest SHAP value compared to the lowest SHAP value question configurations, are significant or reliable. Therefore, inferences based on values of classification metrics should be made with caution.
SHAP values for SVMs and LR were not performed as the large datasets made using KernelExplainer computationally impractical. However, we used DeepExplainer, which is optimized for NNs and aligns well with our study's neural network model, which is characterized by a simple structure and a limited number of input features, enhancing the interpretability of SHAP values. Our model's straightforward architecture minimizes complex non-linear relationships, contributing to its strong performance, as shown by the near-linear progression of predictions with additional questions (Fig. 6). The use of a large dataset in DeepExplainer enhances its robustness, ensuring SHAP values are not overly influenced by outliers, a common issue in smaller datasets. Furthermore, to ensure reliability in assessing feature importance, we averaged SHAP values across 100 different models, each trained on randomized splits of the same dataset. This ensemble approach helps to smooth out individual model discrepancies, offering a more consistent interpretation of feature significance. While the high prediction metrics with a simple NN model and observed linearity in our results does not categorically prove the absence of higher-order interactions, it does provide strong support for linear relationships and for the use of DeepExplainer with our model. Still, future work could use KernelExplainer to validate whether SHAP values for SVMs and LRs are consistent with SHAP values derived from NNs using DeepExplainer.
Future Directions
While this study showed the feasibility of using SHAP values to guide the creation of brief versions of the PSWQ, future work is needed to determine whether this same approach can be used for other measures, which may differ in important ways like inter-item reliability. This study was focused on the approximation of full PSWQ total scores based on shortened PSWQ versions, meaning that SHAP values reflect how well individual items predict the full PSWQ total score. Future studies exploring how SHAP values perform in estimating the utility of each individual PSWQ item in predicting responses to similar self-report questionnaires of worry, such as the Student Worry Scale, would serve as further validation of our approach (Osman et al., 2001). However, another possibility is to use shortened PSWQ versions to predict other clinically relevant outcomes, such as generalized anxiety disorder (GAD), to test which items are the best indicators of risk for GAD. Another potential avenue for exploration is how correlated SHAP values are with other indicators of item importance used in machine learning, such as recursive feature analysis, Local Interpretable Model-Agnostic Explanations values, as well as coefficients in logistic regression or factor loadings derived from a factor-analytic approach.
Conclusions
This study tested the feasibility of using SHAP values as a measure of item importance to guide item retention for the creation of abbreviated measures. Results showed that SHAP values were a useful measure in determining which items led to greater prediction accuracy of the full measure’s total score. However, item importance varied depending on the portion of the distribution, higher or lower total scores, being predicted. Therefore, while SHAP values can serve as a useful guide for the creation of abbreviated measures, the intended purpose of the brief questionnaire should be considered when deciding how to apply SHAP values for item retention.
Data Availability
All data and data analysis code for the present study are publicly available on the Open Science Framework (https://osf.io/ejwyp/?view_only=6347e5adcf2946d69f96bc18285e4c3e)
References
Behar, E., Alcaine, O., Zuellig, A. R., & Borkovec, T. (2003). Screening for generalized anxiety disorder using the Penn State Worry Questionnaire: A receiver operating characteristic analysis. Journal of Behavior Therapy and Experimental Psychiatry, 34(1), 25–43.
Berle, D., Starcevic, V., Moses, K., Hannan, A., Milicevic, D., & Sammut, P. (2011). Preliminary validation of an ultra-brief version of the Penn State Worry Questionnaire. Clinical Psychology & Psychotherapy, 18(4), 339–346.
Chen, H., Lundberg, S. M., & Lee, S. I. (2022). Explaining a series of models by propagating Shapley values. Nature Communications, 13(1), 4512. https://doi.org/10.1038/s41467-022-31384-3
Credé, M., Harms, P., Niehorster, S., & Gaye-Valentine, A. (2012). An evaluation of the consequences of using short measures of the Big Five personality traits. Journal of Personality and Social Psychology, 102(4), 874–888. https://doi.org/10.1037/a0027403
Embretson, S. E., & Reise, S. P. (2000). Item response theory for psychologists. Item Response Theory for Psychologists., xi, 371–xi, 371.
Fresco, D. M., Mennin, D. S., Heimberg, R. G., & Turk, C. L. (2003). Using the Penn State Worry Questionnaire to identify individuals with generalized anxiety disorder: A receiver operating characteristic analysis. Journal of Behavior Therapy and Experimental Psychiatry, 34(3), 283–291. https://doi.org/10.1016/j.jbtep.2003.09.001
Galesic, M., & Bosnjak, M. (2009). Effects of Questionnaire Length on Participation and Indicators of Response Quality in a Web Survey. Public Opinion Quarterly, 73(2), 349–360. https://doi.org/10.1093/poq/nfp031
Gibbons, R. D., Weiss, D. J., Kupfer, D. J., Frank, E., Fagiolini, A., Grochocinski, V. J., Bhaumik, D. K., Stover, A., Bock, R. D., & Immekus, J. C. (2008). Using Computerized Adaptive Testing to Reduce the Burden of Mental Health Assessment. Psychiatric Services, 59(4), 361–368. https://doi.org/10.1176/ps.2008.59.4.361
Gonzalez, O. (2020). Psychometric and Machine Learning Approaches to Reduce the Length of Scales. Multivariate Behavioral Research, 1–17. https://doi.org/10.1080/00273171.2020.1781585
Kozma, A., & Stones, M. (1988). Social desirability in measures of subjective well-being: Age comparisons. Social Indicators Research: An International and Interdisciplinary Journal for Quality-of-Life Measurement, 20(1), 1–14.
Kuhn, M., & Johnson, K. (2013). Applied Predictive Modeling. Springer New York. https://books.google.com/books?id=xYRDAAAAQBAJ
Kumar, I., Scheidegger, C., Venkatasubramanian, S., & Friedler, S. (2021). Shapley Residuals: Quantifying the limits of the Shapley value for explanations. Advances in Neural Information Processing Systems, 34, 26598–26608.
Liu, K., Nijmeh, J. S., & Warren, S. L. (2021). Factor Structure, Measurement Invariance, and Concurrent Validity of the Penn State Worry Questionnaire Across Development, Psychopathology, and Culture. Assessment, 1073191121993223. https://doi.org/10.1177/1073191121993223
Lundberg, S. M., & Lee, S.-I. (2017). A Unified Approach to Interpreting Model Predictions. Proceedings of the 31st International Conference on Neural Information Processing Systems, 4768–4777.
Magis, D., Yan, D., & Von Davier, A. A. (2017). Computerized adaptive and multistage testing with R: Using packages catR and mstR. Springer.
Meyer, T. J., Miller, M. L., Metzger, R. L., & Borkovec, T. D. (1990). Development and validation of the Penn State Worry Questionnaire. Behaviour Research and Therapy, 28(6), 487–495. https://doi.org/10.1016/0005-7967(90)90135-6
Molnar, C. (2020). Interpretable machine learning: a guide for making black box models explainable. Leanpub.
Schroeders, U., Wilhelm, O., & Olaru, G. (2016). Meta-Heuristics in Short Scale Construction: Ant Colony Optimization and Genetic Algorithm. PLOS ONE, 11(11), e0167110. https://doi.org/10.1371/journal.pone.0167110
Osman, A., Gutierrez, P. M., Downs, W. R., Kopper, B. A., Barrios, F. X., & Haraburda, C. M. (2001). Development and psychometric properties of the Student Worry Questionnaire-30. Psychological Reports, 88(1), 277–290. https://doi.org/10.2466/pr0.2001.88.1.277
Orrù, G., Monaro, M., Conversano, C., Gemignani, A., & Sartori, G. (2020). Machine Learning in Psychometrics and Psychological Research. Frontiers in Psychology, 10, 2970. https://doi.org/10.3389/fpsyg.2019.02970
Smith, G. T., McCarthy, D. M., & Anderson, K. G. (2000). On the sins of short-form development. Psychological Assessment, 12(1), 102–111. https://doi.org/10.1037//1040-3590.12.1.102
Soubelet, A., & Salthouse, T. A. (2011). Influence of social desirability on age differences in self-reports of mood and personality. Journal of Personality, 79(4), 741–762. https://doi.org/10.1111/j.1467-6494.2011.00700.x
Tabachnick, B. G., & Fidell, L. S. (2007). Using multivariate statistics, 5th ed. Using Multivariate Statistics, 5th Ed., xxvii, 980–xxvii, 980.
Topper, M., Emmelkamp, P. M. G., Watkins, E., & Ehring, T. (2014). Development and assessment of brief versions of the Penn State Worry Questionnaire and the Ruminative Response Scale. The British Journal of Clinical Psychology, 53(4), 402–421. https://doi.org/10.1111/bjc.12052
van der Linden, W. J., & Glas, C. A. (2006). 25 Statistical Aspects of Adaptive Testing. Handbook of Statistics, 26, 801–838.
Volpe, R. J., & DuPaul, G. J. (2001). Assessment with brief behavior rating scales. Handbook of Psychoeducational Assessment: Ability, Achievement, and Behavior in Children., 357–387. https://doi.org/10.1016/B978-012058570-0/50014-8
Volpe, R. J., Heick, P. F., & Guerasko-Moore, D. (2005). An agile behavioral model for monitoring the effects of stimulant medication in school settings. Psychology in the Schools, 42(5), 509–523. https://doi.org/10.1002/pits.20088
Acknowledgements
The authors wish to thank Dr. Maurice Topper for his data contributions to the work reported here.
Funding
Open access funding provided by SCELC, Statewide California Electronic Library Consortium No funding was received for the work reported here.
Author information
Authors and Affiliations
Contributions
Brian Droncheff (Conceptualization: Lead; Formal analysis: Lead; Methodology: Lead; Software: Lead; Writing – original draft: Equal; Writing – review & editing: Supporting) Kevin Liu (Conceptualization: Equal; Methodology: Supporting; Writing – original draft: Equal; Writing – review & editing: Supporting) Stacie L Warren, Ph.D. (Conceptualization: Equal; Methodology: Supporting; Project administration: Lead; Supervision: Lead; Writing – original draft: Supporting; Writing –review & editing: Lead).
Corresponding author
Ethics declarations
Conflict of Interest
The authors have no known relevant financial or non-financial interests to disclose.
Experiment Participant
This study is a secondary data analysis of de-identified data (see Topper et al., 2014 for details and ethics approval statement). All data and data analysis code for the present study is publicly available on the Open Science Framework (https://osf.io/ejwyp/?view_only=6347e5adcf2946d69f96bc18285e4c3e).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Droncheff, B., Liu, K. & Warren, S.L. Item Retention as a Feature Selection Task: Developing Abbreviated Measures Using Shapley Values. J Psychopathol Behav Assess 46, 220–234 (2024). https://doi.org/10.1007/s10862-024-10120-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10862-024-10120-9