
Abstract
Purpose
Various molecular profiles are needed to classify malignant brain tumors, including gliomas, based on the latest classification criteria of the World Health Organization, and their poor prognosis necessitates new therapeutic targets. The Todai OncoPanel 2 RNA Panel (TOP2-RNA) is a custom-target RNA-sequencing (RNA-seq) using the junction capture method to maximize the sensitivity of detecting 455 fusion gene transcripts and analyze the expression profiles of 1,390 genes. This study aimed to classify gliomas and identify their molecular targets using TOP2-RNA.
Methods
A total of 124 frozen samples of malignant gliomas were subjected to TOP2-RNA for classification based on their molecular profiles and the identification of molecular targets.
Results
Among 55 glioblastoma cases, gene fusions were detected in 11 cases (20%), including novel MET fusions. Seven tyrosine kinase genes were found to be overexpressed in 15 cases (27.3%). In contrast to isocitrate dehydrogenase (IDH) wild-type glioblastoma, IDH-mutant tumors, including astrocytomas and oligodendrogliomas, barely harbor fusion genes or gene overexpression. Of the 34 overexpressed tyrosine kinase genes, MDM2 and CDK4 in glioblastoma, 22 copy number amplifications (64.7%) were observed. When comparing astrocytomas and oligodendrogliomas in gene set enrichment analysis, the gene sets related to 1p36 and 19q were highly enriched in astrocytomas, suggesting that regional genomic DNA copy number alterations can be evaluated by gene expression analysis.
Conclusions
TOP2-RNA is a highly sensitive assay for detecting fusion genes, exon skipping, and aberrant gene expression. Alterations in targetable driver genes were identified in more than 50% of glioblastoma. Molecular profiling by TOP2-RNA provides ample predictive, prognostic, and diagnostic biomarkers that may not be identified by conventional assays and, therefore, is expected to increase treatment options for individual patients with glioma.
Similar content being viewed by others
Introduction
Gliomas, a clinically heterogeneous group of primary brain tumors, are thought to be derived from genetically or epigenetically aberrant cells with neuroglial stem/progenitor-like properties and are found in approximately 100,000 people per year worldwide [1]. They are among the most common and deadly types of primary brain tumors, accounting for approximately 28% of all brain tumors but the majority of deaths [2]. Adult gliomas are currently classified into two major groups based on the mutational status of isocitrate dehydrogenase (IDH)1/2, the key glioma driver gene encoding IDH [3,4,5,6]. IDH-mutant gliomas typically present as lower histologic grades with improved prognosis and a median survival of > 12 years [7]; however, later in the natural history of the disease, they often transform into higher grades with aggressive clinical behavior.
In contrast, IDH-wildtype gliomas usually present as glioblastomas (GBM), the most common and clinically aggressive World Health Organization (WHO) grade IV gliomas, with a median survival of 15–18 months despite aggressive multimodality therapy [8, 9].
Over the past decade, comprehensive molecular characterization has identified complex genetic, epigenetic, and chromosomal changes that segregate gliomas into distinct molecular subtypes, with some genetic differences affecting their response to therapy [10,11,12]. For example, MGMT promoter methylation is both prognostic and predictive of temozolomide benefits [13]. However, relatively few patients with gliomas benefit from genome-driven oncology [14, 15]. However, biomarker-driven targeted therapy has proven effective in GBM based on case stories with specific aberrations [16, 17]. This includes gene fusions that have resulted in the approval of tropomyosin receptor kinase (TRK) inhibitors for TRK fusion-positive cancers, regardless of histology [18, 19] or dabrafenib–trametinib combination for solid tumors with BRAF mutations [20].
As clinical sequencing is implemented in global clinical practice, the clinical utility of DNA panels that interrogate several hundred genes has been evaluated. Although RNA-sequencing (RNA-seq) technologies greatly promote the exploration of the complex and dynamic nature of cancer [21] and can provide insights into previously undetected changes occurring in a disease, the clinical utility of RNA-seq has not been comprehensively evaluated [22]. RNA-seq data have been successfully used to identify single nucleotide variant mutations [23], alternative splicing [24], fusion genes [25], and RNA editing [26].
The Todai OncoPanel (TOP) is a dual DNA–RNA panel as well as a paired tumor–normal matched test developed by our group [27]. Two hundred patients with cancer without standard treatment or those who had already undergone standard treatment underwent TOP as part of Advanced Medical Care B (UMIN000033647). The percentage of patients who received therapeutic or diagnostic recommendations was 61% (120/198 patients). One hundred and four samples (53%) harbored gene alterations that were detected using the DNA panel and had potential treatment implications. Twenty-two samples (11.1%) harbored 30 fusion transcripts or MET exon 14 skipping, which were detected using the RNA panel. Overall, 12 patients (6%) received recommended treatment [28]. After the trial, we revised the TOP panel to TOP2 to expand 737 gene alterations with its DNA panel and 455 fusion transcripts and 1390 gene expression with its RNA panel. For the RNA panel, probes were designed to cover fusions reported in databases, such as COSMIC (https://cancer.sanger.ac.uk/cosmic/fusion) and FusionGDB (https://ccsm.uth.edu/FusionGDB/). For gene expression, probes cover all genes targeted by the DNA panel and fusion genes, as well as genes whose protein expression is commonly evaluated by immunohistochemistry in pathological diagnosis.
As RNA-seq is a reliable method for detecting fusion genes, molecular profiling of gliomas using the TOP2 RNA Panel (TOP2-RNA) was performed in this study, and its validity and potential utility in the molecular diagnosis and stratification of patients for clinical trial enrollment were evaluated.
Materials and methods
Study design and patient specimens
The study cohort was comprised of 131 patients with gliomas who underwent surgical resection between 2005 and 2017 at the National Cancer Center, Japan. Seven cases with poor RNA quality isolated from the specimens were excluded. Analysis was conducted on the remaining 124 patients. Fresh frozen specimens of surgically resected tumors were obtained. This study was approved by the Ethics Committee of the National Cancer Center, Japan (No. 2013–042). All patients provided written informed consent, except for those who could not be reached because of loss to follow-up or death after registration. In these cases, the Institutional Review Board at the National Cancer Center granted permission to use existing tissue samples for research. No samples from patients who opted out of participation were used.
RNA-seq with the TOP2 cancer gene panel for mutation calls
Total RNA was extracted from fresh frozen samples using the RNeasy Mini Kit (QIAGEN, Hilden, Germany). Then, 200 ng of RNA was converted to cDNA using the ProtoScript II First Strand cDNA Synthesis Kit and NEBNext Ultra II Non-Directional RNA Second Strand Synthesis Module (New England Biolabs, Ipswich, MA, USA) and subjected to subsequent target enrichment using TOP-RNA-V6 probes with the Twist Library Preparation EF Kit (Twist Bioscience, South San Francisco, CA, USA). Using a paired-end option, massive parallel sequencing of the isolated fragments was conducted using a NovaSeq 6000 (Illumina). Paired-end reads containing masked nucleotides with a quality score < 20 were aligned to the human reference genome (hg38) using STAR (v2.5.2a; https://github.com/alexdobin/STAR). Mutations were called using an in-house mutation caller based on the SAMtools’ mpileup results. Mutations were discarded if any of the following criteria were met: read depth < 20, variant allele frequency < 0.001, and the presence of the variant in normal human genomes in either the 1000 Genomes Project dataset (https://www.internationalgenome.org/) or our in-house database. Gene mutations were annotated using SnpEff (http://snpeff.sourceforge.net).
Detection of fusion genes and exon skipping, and expression analysis
Gene fusion was detected using STAR-Fusion (v1.2.0; https://github.com/STAR-Fusion) and an in-house pipeline. The detection criterion was set to ≥ 10 reads. In the in-house pipeline, BWA (v0.7.12; https://bio-bwa.sourceforge.net/) was used to map hypothetical fusion gene sequences obtained from the reported fusion gene information. Reads matching ≥ 30 bp from the breakpoints were considered. This pipeline can also be used to identify exon skipping based on the same principle. For expression-level analysis, transcripts per million (TPM) of 1,390 genes from BAM files mapped to hg38 with STAR were calculated using an in-house program.
Clustering and prognostic marker identification using expression data
All statistical analyses were performed using R software version 4.2.0 and related packages. Hierarchical clustering was performed using Ward’s method with log-transformed TPM as the input. In survival assessment, overall survival (OS) period was defined as the time from the start of treatment to the date of death from any cause or the date of the last follow-up. Cox regression was performed using the RegParallel (1.14.0) package, with log-transformed TPM converted to Z-scores as the input, and each of the seven genes was p < 0.001. For ATXN3 expression, which was the most significant, survival curves were generated for the two groups, > 0 and < 0, and evaluated using the log-rank test.
Copy-number analysis using digital droplet polymerase chain reaction (ddPCR)
DNA samples were analyzed by measuring concentrations using a Qubit 3.0 fluorometer (Thermo Fisher Scientific), and those that met the quality evaluation criteria (DNA quantity and quantity) were used. The reaction mix for the assay was prepared as follows: 20 ng of DNA per reaction, 1.1 μL of probes for individual target genes and the control reference gene, 11.0 μL of ddPCR Supermix, 0.5 μL of restriction enzyme, DNA up to 8 μL, and DNase-free water up to 22 μL. DNase-free water was used as the negative control for the assay, and human reference genomic DNA (NA18943; Coriell Institute, Camden, NJ) was used as the positive control. The reaction mixture was subjected to restriction enzyme treatment (MseI, R0525L, New England Biolabs, Ipswich, MA, USA), followed by droplet generation using an automated droplet generator (Bio-Rad Laboratories Inc., Hercules, CA, USA) and PCR using a Veriti Thermal Cycler (Thermo Fisher Scientific). After PCR, the fluorescence signal of each droplet was measured using a QX200 Droplet Reader (Bio-Rad Laboratories, Inc.). The obtained measurement data were subjected to copy-number analysis using QuantaSoft Analysis Pro software (Bio-Rad Laboratories Inc.). RPP30 was used as the reference gene.
Data collection from center for cancer genomics and advanced therapeutics (C-CAT) and GENIE
The C-CAT is a national datacenter for cancer genomic medicine. Clinical information and genomic data from comprehensive genomic profiling tests conducted in Japan are stored in the C-CAT [29]. The AACR Project GENIE is an international data-sharing consortium focused on generating an evidence base for precision cancer medicine by integrating clinical-grade cancer genomic data with clinical outcome data for tens of thousands of patients with cancer treated at multiple institutions worldwide [30]. The C-CAT data were accessed on Aug. 14th 2022 through the C-CAT portal. CNS/brain is the tumor type used to extract data from 498 cases of brain tumors. GENIE data were accessed on Aug. 16th 2022 through cBioPotal. In total, 8,562 glioma cases were identified. The mutation status of IDH1/2 was used to determine GBM, IDH-wildtype.
Statistical analysis
Information on statistical testing is provided in the description of each test in the Methods section and the corresponding result description and figure legends. No statistical method was used to pre-determine the sample size. Statistical significance was set at p < 0.05, except for in Fig. 2A, where statistical significance was set at p < 0.00625 (Bonferroni correction).
Results
Patient characteristics
The study cohort comprised 124 patients with gliomas who presented with a Karnofsky Performance Status (KPS) ≥ 70 and underwent surgical resection between 2005 and 2017 at the National Cancer Center in Japan. The demographic and clinical data of the patients are summarized in Table 1 and Supplementary Data 1. The median age was 39 years, which was comparable between female and male patients (mean, 59.4 vs. 62.6 years; p = 0.5, Student’s t-test). The diagnosis was based on the 2016 WHO classification criteria for GBM (grade IV), anaplastic astrocytomas (grade III), anaplastic oligoastrocytomas (grade III), anaplastic oligodendrogliomas (grade III), diffuse astrocytomas (grade II), oligodendrogliomas, oligoastrocytomas (grade II), pilocytic astrocytomas (grade I), and other tumors, such as anaplastic ependymomas, subependymomas, gangliogliomas, and low-grade gliomas. All patients underwent surgery, and after the initial treatment during the median follow-up time of 69.2 months, recurrence was observed in 92.7% of the patients.
Molecular profiling of gliomas by cancer gene panel sequencing
RNA-seq with TOP2-RNA was performed to detect mutations in glioma-related genes, oncogenic fusion genes, and gene overexpression (defined as > average + 3 standard deviation) for receptor tyrosine kinase (TK) (Supplementary Data 2). Initially, mutation analysis of IDH1/2 and H3F3A was conducted to convert the diagnosis into one based on the 2021 WHO classification criteria. IDH1, IDH2, and H3F3A mutations were identified in 56, 5, and 4 cases, respectively. The molecular status was converted in the cohort into 55 cases of GBM, IDH-wildtype, grade 4; 32 cases of astrocytomas, IDH-mutant, grade 2/3/4; 27 cases of oligodendrogliomas, IDH-mutant, and 1p/19q-codeleted, grade 2/3; and 10 cases of other gliomas, including 4 cases of diffuse midline glioma, H3 K27-altered (Supplementary Fig. 1).
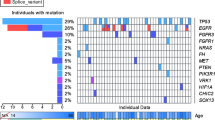
Mutational analysis identified recurrent oncogenic mutations in GBM, including 10 cases with EGFR mutations and 3 with BRAF mutations (Fig. 1A and B). Pathogenic mutations in tumor suppressor genes such as TP53, PTEN, and NF1 were also identified in 13, 14, and 4 GBM cases, respectively. Frequent mutations in TP53 (n = 26, 81.3%) and ATRX (n = 20, 62.5%) were identified in astrocytomas (A), whereas no frequent mutations other than IDH1/2 were identified in oligodendrogliomas. These mutation frequencies are consistent with those reported in previous studies [31].

Mutational profile of gliomas. A Frequently mutated genes with color coding of their alteration status for each tumor. The sheet on the top (highlighted in green) shows the results of mutation analysis on IDH1/2, EGFR, BRAF, TP53, ATRX, PTEN, NF1, and H3F3A. The sheet on the middle (highlighted in blue) shows the results of fusion and exon skipping detection, and expression analysis. The sheet on the bottom (highlighted in orange) shows the results of copy-number analysis by digital droplet PCR. SNV; single nucleotide variant, CN; copy number. B Frequency of driver mutations in glioblastoma (GBM), astrocytomas (A), and oligodendrogliomas (O) in the cohort. C A schematic diagram depicting TK fusions. EGFR, FGFR2, FGFR3, and MET fusions identified by RNA-seq is shown with their functional domains. Exon 24 of EGFR (NM_005228) was ligated to exon 10 of SEPT14 (NM_207366). EGFR variant III revealed the ligation of exons 1–8. Exon 17 of FGFR2 (NM_000141) was ligated to exon 12 of TACC2 (NM_006997). FGFR3 (NM_000142) was disrupted downstream of exon 17 and was subsequently ligated upstream of either exon 8 of TACC3 (NM_006342) or exon 7 of PDE4DIP (NM_014644). Exons 3, 15, or 2 of MET (NM_001324402) were ligated to exon 1 of CAPZA2 (NM_001987), exon 4 of CTTNBP2 (NM_033427), or exon 1 of LINC01004 (ENST00000450686.1), respectively. The TK domain was maintained in all identified fusions. CC, coiled-coil domain; TKD, tyrosine kinase domain. D Frequency of fusion and exon skipping identified in the cohorts of C-CAT, GENIE, and this study (TOP2-RNA). E Mutation frequency of glioma-related genes in C-CAT (left) and GENIE (right). MUT, mutation; AMP, gene amplification; HOMDEL, homozygous deletion
Fusion and exon skipping analyses identified EGFR-SEPT14, EGFR variant III, FGFR2–TACC2, FGFR3–PDE4DIP, FGFR3–TACC3, CAPZA2–MET, CTTNBP2–MET, and LINC01004–MET, which retained the TK domain (Fig. 1C). CTTNBP2-MET and LINC01004–MET were novel fusion genes. CTTNBP2–MET contains a coiled-coil domain that promotes TK dimerization, suggesting oncogenic fusion. LINC01004–MET did not harbor any functional domains in LINC01004. The frequency of fusion genes in this study was higher than that reported in previous studies [32, 33].
Expression analysis revealed the mRNA overexpression of EGFR, FGFR1, FGFR2, FGFR3, MET, PDGFRA, PDGFRB, MET, MDM2, and CDK4 in four, two, three, two, three, seven, three, five, and five cases, respectively (Fig. 1A and Supplementary Fig. 2). Tyrosine kinase gene overexpression was observed in 15 (27.3%) GBM cases. In contrast, gene overexpression was barely observed in astrocytomas or oligodendrogliomas. Overall, alterations in targetable driver genes were identified in 54.5% of GBM (Fig. 1B).
Comparison of the frequency of gene fusion in GBMs in Japan and the USA
To evaluate the clinical utility of RNA-seq in GBM, the frequency of fusion genes identified in this study was compared with that of clinical sequencing cohorts in Japan and the USA. The frequency of EGFR, MET, and FGFR1/2/3 fusions was higher in our cohort, suggesting that RNA-seq is superior to DNA-seq for fusion detection, which has been commonly used for clinical sequencing to date (Fig. 1D). The frequency of gene alterations in GBM was comparable between the GENIE and C-CAT cohorts, suggesting a comparable performance of the gene panels used in the two cohorts (Fig. 1E).
Evaluation of the relationship between gene mutation and gene expression
To evaluate the relationship between gene mutation and expression, mRNA expression was compared between cases with mutations and those without mutations in eight genes that were commonly mutated in GBM, A and O (EGFR, ATRX, PTEN, NF1, IDH1, IDH2, BRAF, TP53). A high EGFR expression level was observed in cases with EGFR mutations, whereas decreased expression was observed in cases with ATRX mutations (p = 3.3 × 10–7, 2.6 × 10–4, respectively, Student’s t-test) (Fig. 2A and Supplementary Fig. 3). No alterations in IDH1/2, BRAF, or TP53 expression levels were observed between cases with and without mutations in the respective genes.

Correlation of gene expression with mutations. A mRNA expression was compared between cases with mutations and those without mutations in eight genes that were commonly mutated in the GBM, A and O. A high EGFR expression level was observed in cases with EGFR mutations, whereas decreased expression was observed in cases with ATRX mutation (p = 1.0 × 10–4, 2.0 × 10–4, respectively, Student’s t-test). No alteration in the expression levels of IDH1/2, BRAF, and TP53 expression was observed between cases with and without mutations of the respective genes (p = 0.14, 0.86, 0.84, 0.36, respectively, Student’s t-test). The dotted line indicates threshold for outlier (> average + 3SD or < average−3SD). mut, mutation; N, number of cases. B Copy-number analysis by ddPCR for cases with gene overexpression. For cases with gene overexpression (defined as > average + 3SD), copy-number analysis was conducted. Gene copy number and gene expression were highly concordant in EGFR (r = 1), whereas moderate concordance was observed in MET, CDK4, and PDGFRA (r = 0.71, 0.81, and 0.79, respectively). No strong or moderate positive correlation was observed in FGFR1/2/3, MDM2 and PDGFRB (r = -1, -0.73, 0.39, 0.26 and -0.76, respectively)
Evaluation of the concordance between copy-number amplification and gene overexpression
For cases with overexpression of TK genes, MDM2, and CDK4, copy number analysis was conducted to assess if copy number amplification was the cause of gene overexpression (Supplementary Fig. 4). Gene copy number and gene expression were strongly positively correlated with EGFR (r = 1), whereas moderate positive correlations were observed for MET, CDK4, and PDGFRA (r = 0.71, 0.81, and 0.8, respectively) (Fig. 2B). No strong or moderate positive correlations were observed for FGFR1/2/3, MDM2 or PDGFRB (r = -1, -0.73, 0.39, 0.26 and -0.76, respectively). Overall, among 34 cases of overexpression in GBM, 22 copy number amplifications (64.7%) were observed, suggesting the involvement of other genetic or epigenetic alterations in gene overexpression.
Identification of prognostic biomarker of glioma by transcriptional profiling
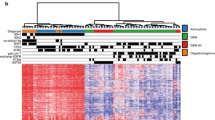
Clustering analysis was conducted using top 100 genes with the greatest variation in expression. The cohort was divided into two groups: Cluster 1 and Cluster 2 (left and right clusters in Fig. 3A). Patients with GBM were enriched in cluster 1 (p < 0.01, Fisher’s exact test). Most of cluster 1 was composed of GBM (46/56, 82.1%), while most of cluster 2 was composed of astrocytoma and oligodendroglioma (57/68, 83.8%), suggesting a distinct gene expression profile of GBM compared to the other subtypes of glioma. Patients with tumors located in the frontal lobe were enriched in cluster 2 (p < 0.01, Fisher’s exact test). Cluster 2 comprised of younger patients (p < 0.01 vs Cluster 1, Student’s t-test). The median overall survival (OS) period was 56.7 and 87.4 months for clusters 1 and 2, respectively, and was not significantly different (p = 0.38, log-rank test; 95% confidence interval [CI] of ratio = 0.37–1.14 and 0.87–2.71) (Supplementary Fig. 5A).

Gene expression profile of gliomas. A K-means clustering analysis was conducted using RNA-seq data. Clinical information (histology, gender, age, KPS, location, and region) is shown with color codes in the upper part. The RNA expression of the 100 most variable genes among samples is depicted as a heatmap at the bottom. B Kaplan–Meier curves of overall survival (OS) in the cohort stratified by ATXN3 expression. Univariate Cox proportional hazards regression analysis showed ATXN3 as the most significant correlation with OS. The survival curves were generated for the two groups, ATXN3 high (z-score > 0) and ATXN3 low (z-score ≤ 0), and its expression well stratified the prognosis of patients with GBM (p = 0.0089, log-rank test) (C) GSEA results with all gene sets differentially enriched among glioblastoma (GBM) vs. astrocytomas (A) + oligodendrogliomas (O) (left panel) or A vs. O (right panel) clusters defined by k-means clustering. Full GSEA results can be found in Supplementary Data 5 and 6. D Of 64 genes, the expression of 29 genes was moderately (0.5 < r ≦ 0.8) or highly (0.8 < r) correlated with the total z-score of gene expressions. The heat map of these 29 genes and their total z-score are shown with histology information. The right violin plot reveals that the total z-score of these 29 genes is lower in oligodendrogliomas than in astrocytomas (p < 0.001, Student’s t-test)
The data are bulk transcriptomes, and the two clusters reflect the microenvironment composition of the individual tumors. The expression of macrophage marker genes CD68 and CD163 or genes related to T-cell activation, namely CCL5, CD58, and CXCL10, was elevated specifically in cluster 1, suggesting immune cell activation of tumors in cluster 1 (Supplementary Fig. 5B and Supplementary Data 3).
Risk of 55 GBM patients was assessed using RNA-seq data. The median OS period was 32.8 (95% CI = 21.3–NA) months. Univariate Cox proportional hazards regression analysis showed a significant correlation between the seven genes and OS (p ≤ 1 × 10–3, log-rank test) (Supplementary Data 4). The most significant gene was ATXN3, and its expression strongly stratified the prognosis of patients with GBM (p = 0.0089, log-rank test; 95% confidence interval [CI] ratio = 32.8–NA and 10.1–NA) (Fig. 3B).
Expression of genes on chr1p36 and chr19q13 is a diagnostic marker to distinguish oligodendroglioma
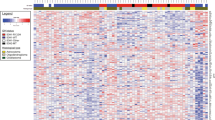
Gene set enrichment analysis (GSEA) between GBMs and astrocytomas or oligodendrogliomas identified 26 and 25 gene sets enriched in each group (Nominal p value < 0.01, one cluster vs. the other) (Supplementary Data 5). Among these gene sets, “ZHANG_PROLIFERATING_VS_QUIESCENT” and “GSE28726_NAIVE_VS_ACTIVATED_CD4_TCELL_DN” were enriched in GBM, whereas “MIR299_5P” and “HP_HEMIANOPIA” were enriched in astrocytomas and oligodendrogliomas (Fig. 3C). GSEA between astrocytomas and oligodendrogliomas identified 11 and 19 upregulated gene sets, respectively (p < 0.01, one cluster vs. the others) (Supplementary Data 6). Among these gene sets, “CHR19Q13” and “CHR1P36” were enriched in astrocytomas, whereas “GSE21033_3H_VS_12H_POLYIC_STIM_DC_UP” and “GSE2585_AIRE_KO_VS_WT_CD80_HIGH_MTEC_DN” were enriched in oligodendrogliomas (Supplementary Fig. 6).
Of the 1,390 genes targeted by TOP2-RNA, 28 and 36 were located at the chr1p36 and chr19q13 loci, respectively. The correlation between the z-scores of individual genes and the total z-score among the samples was calculated. Of the 64 genes, the expression levels of 29 genes were moderately (0.5 < r ≤ 0.8) or highly (0.8 < r) correlated with total gene expression. The total z-score and average TPM for the 29 genes of oligodendrogliomas were lower than those of astrocytomas, indicating that the co-deletion of chr1p36 and chr19q13 led to decreased expression of genes located at the locus (p < 0.001, Student’s t-test) (Fig. 3D and Supplementary Fig. 7), indicating that the z-score of these genes may be applicable as a diagnostic marker for oligodendroglioma.
Discussion
This is the first study to evaluate the feasibility and utility of RNA-seq for the detection of fusion genes and aberrant transcription in malignant gliomas using TOP2-RNA. The utility of RNA-seq has been demonstrated in the detection of fusion genes. Specifically, we identified targetable FGFR2/3 and MET fusions in nine cases (16.4% of GBM). In terms of biological sampling, including ethnicity, our cohort is the same as the C-CAT cohort, suggesting that the difference in the frequency of fusion is related to the technologies used. The method used in the C-CAT and GENIE cohorts is DNA-seq, whereas our method uses RNA-seq, which is more suitable for fusion detection [34]. Additionally, KIAA1549-BRAF and C11orf95-RELA were found in cases of pilocytic astrocytoma and subependymoma, respectively (data not shown). There have been recent developments and approvals of therapies targeting fusion oncogenes, such as those for cholangiocarcinomas with FGFR2 fusions and solid tumors with NTRK fusions in the area.
CAPZA2–MET and LINC01004–MET fusions did not have dimerization domains, which are usually found in TK fusion genes and promote constitutive kinase activation. However, MET was overexpressed in both the samples. Copy-number amplification (copy number = 15.3) was identified in samples with LINC01004–MET, suggesting the involvement of gene rearrangement in amplification. A recent study reported that LINC01004 is a novel super-enhancer-associated lncRNA and crucial oncogene in hepatocellular carcinoma [35]. Therefore, promoter swapping by LINC01004 may further promote MET overexpression and augment the transformation potential of this fusion.
In contrast, copy number was normal in the sample with CAPZA2-MET, suggesting that MET overexpression was caused via promoter swapping by CAPZA2. A recent study reported a patient with cholangiocarcinoma harboring a CAPZA2–MET fusion along with MET amplification, who dramatically responded to capmatinib, a specific MET TK inhibitor [36].
In addition, EGFR VIII was detected using an analytical pipeline to detect exon skipping. Considering that the identification of gene alterations affecting relatively long regions of the genome (> 100 nt) by short-read sequencing is difficult, the detection of exon skipping caused by structural variations is another advantage of RNA-seq.
This study evaluated the utility of expression analysis using RNA-seq and successfully identified TK overexpression cases. Subsequent ddPCR analysis showed that approximately half of the cases with gene overexpression harbored gene amplification. Specifically, EGFR RNA expression and copy number amplification were highly concordant, suggesting that genetic control is dominant for EGFR expression in gliomas.
The expression analysis distinguished GBMs from astrocytomas or oligodendrogliomas, suggesting distinctive features of the microenvironment composition of GBM. Across cohorts, transcriptome analyses of human GBM have repeatedly been classified into three subtypes: classic (CL), mesenchymal (MES), and proneural (PN) [37,38,39,40]. Several studies have established correlations between subtype-specific gene expression signatures, differential response to therapy, and overall patient survival; the latter is poor in highly mesenchymal tumors that exhibit innate immune cell infiltration at recurrence [40]. In this study, the comparison of RNA expression with prognosis identified several genes, namely, ATXN3, GOLGA5, CRBN, MAX, TGFB3, SETD3, and SFTPA1, as prognostic markers that may be related to the mesenchymal subtype.
ATXN3 (Ataxin 3) encodes a deubiquitinating enzyme involved in protein homeostasis, transcription, cytoskeleton regulation, myogenesis, and degradation of misfolded chaperone substrates [41,42,43,44]. ATXN3-associated diseases occur as Machado–Joseph disease and Machado–Joseph disease type 1, which is an autosomal dominant neurodegenerative disorder predominantly involving the cerebellar, pyramidal, extrapyramidal, motor neuron, and oculomotor systems. A recent study reported that ATXN3 is targeted by piRNAs and miRNAs and that its upregulation might induce cell proliferation through G-protein-coupled receptor or AKT signaling in GBM [45].
Although the methylation status of the MGMT promoter was positively correlated with prolonged survival in patients who received TMZ-based therapy [8], MGMT mRNA expression was not significantly related to OS in our cohort (p = 0.32, hazard ratio = 1.24). Further studies on the correlation between MGMT promoter status and the prognosis of IDH-wildtype GBM are needed.
Another utility of TOP2-RNA is its diagnostic capability in astrocytomas and oligodendrogliomas. Although oligodendrogliomas are associated with CIC mutations (up to 70%) [46, 47], astrocytomas frequently harbor TP53 and ATRX mutations [48] and confirmation of 1p/19q co-deletion is needed to distinguish both tumors according to the 2021 WHO classification. The assessment of gene expression on the 1p/19q locus with TOP2-RNA may be used as a substitute for fluorescence in situ hybridization or SNP arrays, which are common assays in routine clinical settings. Although copy-number variants such as 1p/19q co-deletion by whole genome sequencing, exome sequencing, and targeted NGS assays have been explored in brain tumors using various bioinformatics analysis pipelines [49,50,51,52,53,54], few studies have reported the utility of targeted RNA-seq for 1p/19q co-deletion.
In addition to 1p/19q co-deletion in oligodendrogliomas, GSEA revealed intriguing features of glioblastoma. For instance, ZHANG_PROLIFERATING_VS_QUIESCENT is upregulated in proliferating HDMEC cells (microvascular endothelium). This is a reasonable result considering that GBM is characterized by extensive vascularization, and its tumor angiogenesis is known to be a multi-step process involving the proliferation, migration, and differentiation of brain microvascular endothelial cells under the stimulation of specific signals derived from cancer cells [55]. GSE28726_NAIVE_VS_ACTIVATED_CD4_TCELL_DN was downregulated in activated CD4 + T cells. This result suggests that GBM has a specific immunosuppressive microenvironment as it has a distinct pattern of genomic aberrations that could be neoantigens. A recent study reported that T cell dysfunction in the glioblastoma microenvironment is mediated by myeloid cells [56]. Combining single-cell RNA sequencing of the immune compartment with spatially resolved transcriptomic sequencing in different types of glioma will deepen our understanding of how GBM creates an immunosuppressive microenvironment.
This study had several limitations. First, DNA analysis was not performed to comprehensively assess mutational profiles. Although mutational analysis by RNA-seq may overlook mutations in low-expression genes, hotspot mutations in oncogenes such as IDH1/2 were successfully identified, and cases with IDH1/2 mutations were highly consistent with the pathological diagnosis. Second, the cause of the gene overexpression was not fully identified. Approximately half of the cases with high gene expression showed copy number amplification. The structural rearrangements that cause promoter or enhancer swapping may be involved in the other half. Thus, whole-genome sequencing may help elucidate the underlying causes of gene overexpression. Third, this study only evaluated fresh-frozen specimens, which is not common in the pathology department. In our previous study, we validated the capability of TOP-RNA for fusion detection using 38 FFPE specimens of non-small cell lung cancer and sarcoma, which were confirmed to harbor fusion genes in fresh-frozen samples. TOP-RNA detected the respective fusions in all 38 samples, including small biopsy specimens [27]. Expression analysis was also conducted for seven tumors to compare the performance of the TOP RNA panel using FFPE specimens with that of poly(A)-RNA-seq using frozen specimens. The mRNA expression values of the 109 genes in the TOP RNA Panel were highly concordant with those determined by poly(A)-RNA sequencing, even though the former data were obtained using FFPE specimens (r = 0.94–0.99). Fourth, we did not have information on the copy numbers of chr1p and 19q. A confirmatory study to evaluate the concordance between FISH and TOP-RNA remains to be conducted.
This study confirms that TOP2-RNA is a highly sensitive assay for detecting fusion genes, exon skipping, and aberrant gene expression. We identified alterations in targetable driver genes in more than 50% of GBM cases. Above, expression profiling has identified several candidate markers that could directly predict the prognosis of GBM. Expression analysis also suggested that TOP2-RNA could precisely differentiate oligodendroglioma from astrocytoma. In summary, molecular profiling by TOP2-RNA provides ample predictive, prognostic, and diagnostic biomarkers that may not be identified by conventional assays, and therefore, increases treatment options for patients with gliomas.
Data availability
We have deposited the raw sequencing data in the Japanese Genotype-Phenotype Archive, which is hosted by the DNA Data Bank of Japan, under accession number JSUB000932.
Abbreviations
- TOP2-RNA:
-
Todai OncoPanel 2 RNA Panel
- RNA-seq:
-
RNA-sequencing
- GSEA:
-
Gene set enrichment analysis
- ddPCR:
-
Digital droplet polymerase chain reaction
- IDH:
-
Isocitrate dehydrogenase
- GBM:
-
Glioblastomas
- WHO:
-
World Health Organization
- TPM:
-
Transcripts per million
- KPS:
-
Karnofsky Performance Status
- TK:
-
Tyrosine kinase
- A:
-
Astrocytomas
- OS:
-
Overall survival
- CI:
-
Confidence interval
References
Molinaro AM, Taylor JW, Wiencke JK, Wrensch MR (2019) Genetic and molecular epidemiology of adult diffuse glioma. Nat Rev Neurol 15:405–417. https://doi.org/10.1038/s41582-019-0220-2
Ostrom QT, Price M, Neff C, Cioffi G, Waite KA, Kruchko C, Barnholtz-Sloan JS (2022) CBTRUS statistical report: primary brain and other central nervous system tumors diagnosed in the United States in 2015–2019. Neuro Oncol 24:v1–v95. https://doi.org/10.1093/neuonc/noac202
Parsons DW, Jones S, Zhang X, Lin JC, Leary RJ, Angenendt P, Mankoo P, Carter H, Siu IM, Gallia GL, Olivi A, McLendon R, Rasheed BA, Keir S, Nikolskaya T, Nikolsky Y, Busam DA, Tekleab H, Diaz LA Jr, Hartigan J, Smith DR, Strausberg RL, Marie SK, Shinjo SM, Yan H, Riggins GJ, Bigner DD, Karchin R, Papadopoulos N, Parmigiani G, Vogelstein B, Velculescu VE, Kinzler KW (2008) An integrated genomic analysis of human glioblastoma multiforme. Science 321:1807–1812. https://doi.org/10.1126/science.1164382
Yan H, Parsons DW, Jin G, McLendon R, Rasheed BA, Yuan W, Kos I, Batinic-Haberle I, Jones S, Riggins GJ, Friedman H, Friedman A, Reardon D, Herndon J, Kinzler KW, Velculescu VE, Vogelstein B, Bigner DD (2009) IDH1 and IDH2 mutations in gliomas. N Engl J Med 360:765–773. https://doi.org/10.1056/NEJMoa0808710
Hartmann C, Meyer J, Balss J, Capper D, Mueller W, Christians A, Felsberg J, Wolter M, Mawrin C, Wick W, Weller M, Herold-Mende C, Unterberg A, Jeuken JW, Wesseling P, Reifenberger G, von Deimling A (2009) Type and frequency of IDH1 and IDH2 mutations are related to astrocytic and oligodendroglial differentiation and age: a study of 1,010 diffuse gliomas. Acta Neuropathol 118:469–474. https://doi.org/10.1007/s00401-009-0561-9
Louis DN, Perry A, Wesseling P, Brat DJ, Cree IA, Figarella-Branger D, Hawkins C, Ng HK, Pfister SM, Reifenberger G, Soffietti R, von Deimling A, Ellison DW (2021) The 2021 WHO classification of tumors of the central nervous system: a summary. Neuro Oncol 23:1231–1251. https://doi.org/10.1093/neuonc/noab106
Franceschi E, Tosoni A, Bartolini S, Minichillo S, Mura A, Asioli S, Bartolini D, Gardiman M, Gessi M, Ghimenton C, Giangaspero F, Lanza G, Marucci G, Novello M, Silini EM, Zunarelli E, Paccapelo A, Brandes AA (2020) Histopathological grading affects survival in patients with IDH-mutant grade II and grade III diffuse gliomas. Eur J Cancer 137:10–17. https://doi.org/10.1016/j.ejca.2020.06.018
Stupp R, Mason WP, van den Bent MJ, Weller M, Fisher B, Taphoorn MJ, Belanger K, Brandes AA, Marosi C, Bogdahn U, Curschmann J, Janzer RC, Ludwin SK, Gorlia T, Allgeier A, Lacombe D, Cairncross JG, Eisenhauer E, Mirimanoff RO, European Organisation for R, Treatment of Cancer Brain T, Radiotherapy G, National Cancer Institute of Canada Clinical Trials G (2005) Radiotherapy plus concomitant and adjuvant temozolomide for glioblastoma. N Engl J Med 352:987–996.https://doi.org/10.1056/NEJMoa043330
Wen PY, Weller M, Lee EQ, Alexander BM, Barnholtz-Sloan JS, Barthel FP, Batchelor TT, Bindra RS, Chang SM, Chiocca EA, Cloughesy TF, DeGroot JF, Galanis E, Gilbert MR, Hegi ME, Horbinski C, Huang RY, Lassman AB, Le Rhun E, Lim M, Mehta MP, Mellinghoff IK, Minniti G, Nathanson D, Platten M, Preusser M, Roth P, Sanson M, Schiff D, Short SC, Taphoorn MJB, Tonn JC, Tsang J, Verhaak RGW, von Deimling A, Wick W, Zadeh G, Reardon DA, Aldape KD, van den Bent MJ (2020) Glioblastoma in adults: a society for neuro-oncology (SNO) and European society of neuro-oncology (EANO) consensus review on current management and future directions. Neuro Oncol 22:1073–1113. https://doi.org/10.1093/neuonc/noaa106
Berger TR, Wen PY, Lang-Orsini M, Chukwueke UN (2022) World health organization 2021 classification of central nervous system tumors and implications for therapy for adult-type gliomas: a review. JAMA Oncol 8:1493–1501. https://doi.org/10.1001/jamaoncol.2022.2844
Bush NA, Butowski N (2017) The effect of molecular diagnostics on the treatment of glioma. Curr Oncol Rep 19:26. https://doi.org/10.1007/s11912-017-0585-6
Diamandis P, Aldape KD (2017) Insights from molecular profiling of adult glioma. J Clin Oncol 35:2386–2393. https://doi.org/10.1200/JCO.2017.73.9516
Hegi ME, Diserens AC, Gorlia T, Hamou MF, de Tribolet N, Weller M, Kros JM, Hainfellner JA, Mason W, Mariani L, Bromberg JE, Hau P, Mirimanoff RO, Cairncross JG, Janzer RC, Stupp R (2005) MGMT gene silencing and benefit from temozolomide in glioblastoma. N Engl J Med 352:997–1003. https://doi.org/10.1056/NEJMoa043331
Marquart J, Chen EY, Prasad V (2018) Estimation of the percentage of US patients with cancer who benefit from genome-driven oncology. JAMA Oncol 4:1093–1098. https://doi.org/10.1001/jamaoncol.2018.1660
Haslam A, Kim MS, Prasad V (2021) Updated estimates of eligibility for and response to genome-targeted oncology drugs among US cancer patients, 2006–2020. Ann Oncol 32:926–932. https://doi.org/10.1016/j.annonc.2021.04.003
Kaley T, Touat M, Subbiah V, Hollebecque A, Rodon J, Lockhart AC, Keedy V, Bielle F, Hofheinz RD, Joly F, Blay JY, Chau I, Puzanov I, Raje NS, Wolf J, DeAngelis LM, Makrutzki M, Riehl T, Pitcher B, Baselga J, Hyman DM (2018) BRAF inhibition in BRAF(V600)-mutant gliomas: results from the VE-BASKET study. J Clin Oncol 36:3477–3484. https://doi.org/10.1200/JCO.2018.78.9990
Mellinghoff IK, Penas-Prado M, Peters KB, Burris HA 3rd, Maher EA, Janku F, Cote GM, de la Fuente MI, Clarke JL, Ellingson BM, Chun S, Young RJ, Liu H, Choe S, Lu M, Le K, Hassan I, Steelman L, Pandya SS, Cloughesy TF, Wen PY (2021) Vorasidenib, a dual inhibitor of mutant IDH1/2, in recurrent or progressive glioma; results of a first-in-human phase I Trial. Clin Cancer Res 27:4491–4499. https://doi.org/10.1158/1078-0432.CCR-21-0611
Doz F, van Tilburg CM, Geoerger B, Hojgaard M, Ora I, Boni V, Capra M, Chisholm J, Chung HC, DuBois SG, Gallego-Melcon S, Gerber NU, Goto H, Grilley-Olson JE, Hansford JR, Hong DS, Italiano A, Kang HJ, Nysom K, Thorwarth A, Stefanowicz J, Tahara M, Ziegler DS, Gavrilovic IT, Norenberg R, Dima L, De La Cuesta E, Laetsch TW, Drilon A, Perreault S (2022) Efficacy and safety of larotrectinib in TRK fusion-positive primary central nervous system tumors. Neuro Oncol 24:997–1007. https://doi.org/10.1093/neuonc/noab274
Drilon A, Laetsch TW, Kummar S, DuBois SG, Lassen UN, Demetri GD, Nathenson M, Doebele RC, Farago AF, Pappo AS, Turpin B, Dowlati A, Brose MS, Mascarenhas L, Federman N, Berlin J, El-Deiry WS, Baik C, Deeken J, Boni V, Nagasubramanian R, Taylor M, Rudzinski ER, Meric-Bernstam F, Sohal DPS, Ma PC, Raez LE, Hechtman JF, Benayed R, Ladanyi M, Tuch BB, Ebata K, Cruickshank S, Ku NC, Cox MC, Hawkins DS, Hong DS, Hyman DM (2018) Efficacy of larotrectinib in TRK fusion-positive cancers in adults and children. N Engl J Med 378:731–739. https://doi.org/10.1056/NEJMoa1714448
Wen PY, Stein A, van den Bent M, De Greve J, Wick A, de Vos F, von Bubnoff N, van Linde ME, Lai A, Prager GW, Campone M, Fasolo A, Lopez-Martin JA, Kim TM, Mason WP, Hofheinz RD, Blay JY, Cho DC, Gazzah A, Pouessel D, Yachnin J, Boran A, Burgess P, Ilankumaran P, Gasal E, Subbiah V (2022) Dabrafenib plus trametinib in patients with BRAF(V600E)-mutant low-grade and high-grade glioma (ROAR): a multicentre, open-label, single-arm, phase 2, basket trial. Lancet Oncol 23:53–64. https://doi.org/10.1016/S1470-2045(21)00578-7
Kukurba KR, Montgomery SB (2015) RNA sequencing and analysis. Cold Spring Harb Protoc 2015:951–969. https://doi.org/10.1101/pdb.top084970
Piskol R, Ramaswami G, Li JB (2013) Reliable identification of genomic variants from RNA-seq data. Am J Hum Genet 93:641–651. https://doi.org/10.1016/j.ajhg.2013.08.008
Goya R, Sun MG, Morin RD, Leung G, Ha G, Wiegand KC, Senz J, Crisan A, Marra MA, Hirst M, Huntsman D, Murphy KP, Aparicio S, Shah SP (2010) SNVMix: predicting single nucleotide variants from next-generation sequencing of tumors. Bioinformatics 26:730–736. https://doi.org/10.1093/bioinformatics/btq040
Climente-Gonzalez H, Porta-Pardo E, Godzik A, Eyras E (2017) The functional impact of alternative splicing in cancer. Cell Rep 20:2215–2226. https://doi.org/10.1016/j.celrep.2017.08.012
Di Stefano AL, Fucci A, Frattini V, Labussiere M, Mokhtari K, Zoppoli P, Marie Y, Bruno A, Boisselier B, Giry M, Savatovsky J, Touat M, Belaid H, Kamoun A, Idbaih A, Houillier C, Luo FR, Soria JC, Tabernero J, Eoli M, Paterra R, Yip S, Petrecca K, Chan JA, Finocchiaro G, Lasorella A, Sanson M, Iavarone A (2015) Detection, characterization, and inhibition of FGFR-TACC fusions in IDH wild-type glioma. Clin Cancer Res 21:3307–3317. https://doi.org/10.1158/1078-0432.CCR-14-2199
Song J, Singh M (2009) How and when should interactome-derived clusters be used to predict functional modules and protein function? Bioinformatics 25:3143–3150. https://doi.org/10.1093/bioinformatics/btp551
Kohsaka S, Tatsuno K, Ueno T, Nagano M, Shinozaki-Ushiku A, Ushiku T, Takai D, Ikegami M, Kobayashi H, Kage H, Ando M, Hata K, Ueda H, Yamamoto S, Kojima S, Oseto K, Akaike K, Suehara Y, Hayashi T, Saito T, Takahashi F, Takahashi K, Takamochi K, Suzuki K, Nagayama S, Oda Y, Mimori K, Ishihara S, Yatomi Y, Nagase T, Nakajima J, Tanaka S, Fukayama M, Oda K, Nangaku M, Miyazono K, Miyagawa K, Aburatani H, Mano H (2019) Comprehensive assay for the molecular profiling of cancer by target enrichment from formalin-fixed paraffin-embedded specimens. Cancer Sci 110:1464–1479. https://doi.org/10.1111/cas.13968
Kage H, Shinozaki-Ushiku A, Ishigaki K, Sato Y, Tanabe M, Tanaka S, Tanikawa M, Watanabe K, Kato S, Akagi K, Uchino K, Mitani K, Takahashi S, Miura Y, Ikeda S, Kojima Y, Watanabe K, Mochizuki H, Yamaguchi H, Kawazoe Y, Kashiwabara K, Kohsaka S, Tatsuno K, Ushiku T, Ohe K, Yatomi Y, Seto Y, Aburatani H, Mano H, Miyagawa K, Oda K (2023) Clinical utility of Todai OncoPanel in the setting of approved comprehensive cancer genomic profiling tests in Japan. Cancer Sci 114:1710–1717. https://doi.org/10.1111/cas.15717
Kohno T, Kato M, Kohsaka S, Sudo T, Tamai I, Shiraishi Y, Okuma Y, Ogasawara D, Suzuki T, Yoshida T, Mano H (2022) C-CAT: the national datacenter for cancer genomic medicine in Japan. Cancer Discov 12:2509–2515. https://doi.org/10.1158/2159-8290.CD-22-0417
Consortium APG (2017) AACR project GENIE: powering precision medicine through an international consortium. Cancer Discov 7:818–831. https://doi.org/10.1158/2159-8290.CD-17-0151
Kalidindi N, Or R, Babak S, Mason W (2020) Molecular classification of diffuse gliomas. Can J Neurol Sci 47:464–473. https://doi.org/10.1017/cjn.2020.10
Mata DA, Benhamida JK, Lin AL, Vanderbilt CM, Yang SR, Villafania LB, Ferguson DC, Jonsson P, Miller AM, Tabar V, Brennan CW, Moss NS, Sill M, Benayed R, Mellinghoff IK, Rosenblum MK, Arcila ME, Ladanyi M, Bale TA (2020) Genetic and epigenetic landscape of IDH-wildtype glioblastomas with FGFR3-TACC3 fusions. Acta Neuropathol Commun 8:186. https://doi.org/10.1186/s40478-020-01058-6
Polivka J, Svajdler M, Priban V, Mracek J, Kasik P, Martinek P, Ptakova N, Sharif Bagheri M, Shetti D, Pesta M, Potuznik P, Topolcan O (2022) Oncogenic fusions in gliomas: an institutional experience. Anticancer Res 42:1933–1939. https://doi.org/10.21873/anticanres.15671
Heydt C, Wolwer CB, Velazquez Camacho O, Wagener-Ryczek S, Pappesch R, Siemanowski J, Rehker J, Haller F, Agaimy A, Worm K, Herold T, Pfarr N, Weichert W, Kirchner T, Jung A, Kumbrink J, Goering W, Esposito I, Buettner R, Hillmer AM, Merkelbach-Bruse S (2021) Detection of gene fusions using targeted next-generation sequencing: a comparative evaluation. BMC Med Genomics 14:62. https://doi.org/10.1186/s12920-021-00909-y
Li J, Wang J, Wang Y, Zhao X, Su T (2023) E2F1 combined with LINC01004 super-enhancer to promote hepatocellular carcinoma cell proliferation and metastasis. Clin Epigenetics 15:17. https://doi.org/10.1186/s13148-023-01428-6
Turpin A, Descarpentries C, Gregoire V, Farchi O, Cortot AB, Jamme P (2023) Response to Capmatinib in a MET fusion-positive cholangiocarcinoma. Oncologist 28:80–83. https://doi.org/10.1093/oncolo/oyac194
Verhaak RG, Hoadley KA, Purdom E, Wang V, Qi Y, Wilkerson MD, Miller CR, Ding L, Golub T, Mesirov JP, Alexe G, Lawrence M, O'Kelly M, Tamayo P, Weir BA, Gabriel S, Winckler W, Gupta S, Jakkula L, Feiler HS, Hodgson JG, James CD, Sarkaria JN, Brennan C, Kahn A, Spellman PT, Wilson RK, Speed TP, Gray JW, Meyerson M, Getz G, Perou CM, Hayes DN, Cancer Genome Atlas Research N (2010) Integrated genomic analysis identifies clinically relevant subtypes of glioblastoma characterized by abnormalities in PDGFRA, IDH1, EGFR, and NF1. Cancer Cell 17:98–110.https://doi.org/10.1016/j.ccr.2009.12.020
Phillips HS, Kharbanda S, Chen R, Forrest WF, Soriano RH, Wu TD, Misra A, Nigro JM, Colman H, Soroceanu L, Williams PM, Modrusan Z, Feuerstein BG, Aldape K (2006) Molecular subclasses of high-grade glioma predict prognosis, delineate a pattern of disease progression, and resemble stages in neurogenesis. Cancer Cell 9:157–173. https://doi.org/10.1016/j.ccr.2006.02.019
Sturm D, Witt H, Hovestadt V, Khuong-Quang DA, Jones DT, Konermann C, Pfaff E, Tonjes M, Sill M, Bender S, Kool M, Zapatka M, Becker N, Zucknick M, Hielscher T, Liu XY, Fontebasso AM, Ryzhova M, Albrecht S, Jacob K, Wolter M, Ebinger M, Schuhmann MU, van Meter T, Fruhwald MC, Hauch H, Pekrun A, Radlwimmer B, Niehues T, von Komorowski G, Durken M, Kulozik AE, Madden J, Donson A, Foreman NK, Drissi R, Fouladi M, Scheurlen W, von Deimling A, Monoranu C, Roggendorf W, Herold-Mende C, Unterberg A, Kramm CM, Felsberg J, Hartmann C, Wiestler B, Wick W, Milde T, Witt O, Lindroth AM, Schwartzentruber J, Faury D, Fleming A, Zakrzewska M, Liberski PP, Zakrzewski K, Hauser P, Garami M, Klekner A, Bognar L, Morrissy S, Cavalli F, Taylor MD, van Sluis P, Koster J, Versteeg R, Volckmann R, Mikkelsen T, Aldape K, Reifenberger G, Collins VP, Majewski J, Korshunov A, Lichter P, Plass C, Jabado N, Pfister SM (2012) Hotspot mutations in H3F3A and IDH1 define distinct epigenetic and biological subgroups of glioblastoma. Cancer Cell 22:425–437. https://doi.org/10.1016/j.ccr.2012.08.024
Wang Q, Hu B, Hu X, Kim H, Squatrito M, Scarpace L, deCarvalho AC, Lyu S, Li P, Li Y, Barthel F, Cho HJ, Lin YH, Satani N, Martinez-Ledesma E, Zheng S, Chang E, Sauve CG, Olar A, Lan ZD, Finocchiaro G, Phillips JJ, Berger MS, Gabrusiewicz KR, Wang G, Eskilsson E, Hu J, Mikkelsen T, DePinho RA, Muller F, Heimberger AB, Sulman EP, Nam DH, Verhaak RGW (2017) Tumor evolution of glioma-intrinsic gene expression subtypes associates with immunological changes in the microenvironment. Cancer Cell 32:42-56.e46. https://doi.org/10.1016/j.ccell.2017.06.003
Li F, Macfarlan T, Pittman RN, Chakravarti D (2002) Ataxin-3 is a histone-binding protein with two independent transcriptional corepressor activities. J Biol Chem 277:45004–45012. https://doi.org/10.1074/jbc.M205259200
Seki T, Gong L, Williams AJ, Sakai N, Todi SV, Paulson HL (2013) JosD1, a membrane-targeted deubiquitinating enzyme, is activated by ubiquitination and regulates membrane dynamics, cell motility, and endocytosis. J Biol Chem 288:17145–17155. https://doi.org/10.1074/jbc.M113.463406
Mao Y, Senic-Matuglia F, Di Fiore PP, Polo S, Hodsdon ME, De Camilli P (2005) Deubiquitinating function of ataxin-3: insights from the solution structure of the Josephin domain. Proc Natl Acad Sci U S A 102:12700–12705. https://doi.org/10.1073/pnas.0506344102
Ashkenazi A, Bento CF, Ricketts T, Vicinanza M, Siddiqi F, Pavel M, Squitieri F, Hardenberg MC, Imarisio S, Menzies FM, Rubinsztein DC (2017) Polyglutamine tracts regulate beclin 1-dependent autophagy. Nature 545:108–111. https://doi.org/10.1038/nature22078
Nayak R, Chattopadhyay T, Gupta P, Mallick B (2023) Integrative analysis of small non-coding RNAs predicts a piRNA/miRNA-CCND1/BRAF/HRH1/ATXN3 regulatory circuit that drives oncogenesis in glioblastoma. Mol Omics 19:252–261. https://doi.org/10.1039/d2mo00245k
Yip S, Butterfield YS, Morozova O, Chittaranjan S, Blough MD, An J, Birol I, Chesnelong C, Chiu R, Chuah E, Corbett R, Docking R, Firme M, Hirst M, Jackman S, Karsan A, Li H, Louis DN, Maslova A, Moore R, Moradian A, Mungall KL, Perizzolo M, Qian J, Roldan G, Smith EE, Tamura-Wells J, Thiessen N, Varhol R, Weiss S, Wu W, Young S, Zhao Y, Mungall AJ, Jones SJ, Morin GB, Chan JA, Cairncross JG, Marra MA (2012) Concurrent CIC mutations, IDH mutations, and 1p/19q loss distinguish oligodendrogliomas from other cancers. J Pathol 226:7–16. https://doi.org/10.1002/path.2995
Bettegowda C, Agrawal N, Jiao Y, Sausen M, Wood LD, Hruban RH, Rodriguez FJ, Cahill DP, McLendon R, Riggins G, Velculescu VE, Oba-Shinjo SM, Marie SK, Vogelstein B, Bigner D, Yan H, Papadopoulos N, Kinzler KW (2011) Mutations in CIC and FUBP1 contribute to human oligodendroglioma. Science 333:1453–1455. https://doi.org/10.1126/science.1210557
Liu XY, Gerges N, Korshunov A, Sabha N, Khuong-Quang DA, Fontebasso AM, Fleming A, Hadjadj D, Schwartzentruber J, Majewski J, Dong Z, Siegel P, Albrecht S, Croul S, Jones DT, Kool M, Tonjes M, Reifenberger G, Faury D, Zadeh G, Pfister S, Jabado N (2012) Frequent ATRX mutations and loss of expression in adult diffuse astrocytic tumors carrying IDH1/IDH2 and TP53 mutations. Acta Neuropathol 124:615–625. https://doi.org/10.1007/s00401-012-1031-3
de Biase D, Acquaviva G, Visani M, Marucci G, De Leo A, Maloberti T, Sanza V, Di Oto E, Franceschi E, Mura A, Ragazzi M, Serra S, Froio E, Bisagni A, Brandes AA, Pession A, Tallini G (2021) Next-generation sequencing panel for 1p/19q codeletion and IDH1-IDH2 mutational analysis uncovers mistaken overdiagnoses of 1p/19q codeletion by FISH. J Mol Diagn 23:1185–1194. https://doi.org/10.1016/j.jmoldx.2021.06.004
Pallavajjala A, Haley L, Stinnett V, Adams E, Pallavajjala R, Huang J, Morsberger L, Hardy M, Long P, Gocke CD, Eshleman JR, Rodriguez FJ, Zou YS (2022) Utility of targeted next-generation sequencing assay to detect 1p/19q co-deletion in formalin-fixed paraffin-embedded glioma specimens. Hum Pathol 126:63–76. https://doi.org/10.1016/j.humpath.2022.05.001
Dubbink HJ, Atmodimedjo PN, van Marion R, Krol NMG, Riegman PHJ, Kros JM, van den Bent MJ, Dinjens WNM (2016) Diagnostic detection of allelic losses and imbalances by next-generation sequencing: 1p/19q Co-deletion analysis of gliomas. J Mol Diagn 18:775–786. https://doi.org/10.1016/j.jmoldx.2016.06.002
Sharaf R, Pavlick DC, Frampton GM, Cooper M, Jenkins J, Danziger N, Haberberger J, Alexander BM, Cloughesy T, Yong WH, Liau LM, Nghiemphu PL, Ji M, Lai A, Ramkissoon SH, Albacker LA (2021) FoundationOne CDx testing accurately determines whole arm 1p19q codeletion status in gliomas. Neurooncol Adv 3:vdab017. https://doi.org/10.1093/noajnl/vdab017
Zacher A, Kaulich K, Stepanow S, Wolter M, Kohrer K, Felsberg J, Malzkorn B, Reifenberger G (2017) Molecular diagnostics of gliomas using next generation sequencing of a glioma-tailored gene panel. Brain Pathol 27:146–159. https://doi.org/10.1111/bpa.12367
Na K, Kim HS, Shim HS, Chang JH, Kang SG, Kim SH (2019) Targeted next-generation sequencing panel (TruSight Tumor 170) in diffuse glioma: a single institutional experience of 135 cases. J Neurooncol 142:445–454. https://doi.org/10.1007/s11060-019-03114-1
Testa E, Palazzo C, Mastrantonio R, Viscomi MT (2022) Dynamic interactions between tumor cells and brain microvascular endothelial cells in glioblastoma. Cancers (Basel) 14. https://doi.org/10.3390/cancers14133128
Ravi VM, Neidert N, Will P, Joseph K, Maier JP, Kuckelhaus J, Vollmer L, Goeldner JM, Behringer SP, Scherer F, Boerries M, Follo M, Weiss T, Delev D, Kernbach J, Franco P, Schallner N, Dierks C, Carro MS, Hofmann UG, Fung C, Sankowski R, Prinz M, Beck J, Salie H, Bengsch B, Schnell O, Heiland DH (2022) T-cell dysfunction in the glioblastoma microenvironment is mediated by myeloid cells releasing interleukin-10. Nat Commun 13:925. https://doi.org/10.1038/s41467-022-28523-1
Acknowledgements
The authors would like to thank A. Maruyama-Shiino for technical assistance.
Funding
This study was supported by grants from the Grant-in-Aid for Rare Cancer Research under grant number 1–7 from the National Cancer Center, Japan.
Author information
Authors and Affiliations
Contributions
Conception and design; M. Takahashi and S. Kohsaka, Development of methodology; T. Ueno, H. Mano and S. Kohsaka, Acquisition of data; Y. Shirai and H. Ikeuchi, Analysis and interpretation of data; Y. Shirai, T. Ueno, Y. Narita, M. Takahashi and S. Kohsaka, Administrative, technical, or material support; S. Kojima, T. Koyama, F. Takahashi, K. Takahashi, K. Ichimura A. Yoshida, H. Sugino and Y. Narita, Writing, review, and/or revision of the manuscript; Y. Shirai, T. Ueno, R. Kitada, Y. Narita, H. Mano, M. Takahashi and S. Kohsaka.
Corresponding authors
Ethics declarations
Ethics approval
This study was approved by The Ethics Committee of the National Cancer Center, Japan (No. 2013–042).
Informed consent
All patients provided written informed consent to participate in the study and publish the data, except for those who could not be reached because of follow-up loss or death after registration. In these cases, the Institutional Review Board at the National Cancer Center granted permission to use existing tissue samples for research. No samples from patients who opted out of participation were used.
Conflict of interest
Dr. Shinji Kohsaka received research funding from Konica Minolta. The other authors certify that no actual or potential conflicts of interest exist in relation to this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
11060_2024_4563_MOESM2_ESM.pptx
ESM 1 Supplementary Figure 1. Diagnosis conversion into the WHO 2021 classification criteria. Mutation analysis of IDH1/2 and H3F3A was conducted based on the WHO 2021 classification criteria to convert the diagnosis into one. The molecular status converted the cohort into 55 cases of GBM, IDH-wildtype, grade 4; 32 cases of astrocytomas, IDH-mutant, grade 2/3/4; 27 cases of oligodendrogliomas, IDH-mutant and 1p/19q-codeleted, grade 2/3; and 10 cases of other gliomas, including four cases of diffuse midline glioma, H3 K27-altered. Supplementary Figure 2. Expression analysis of glioma-related oncogenes. Expression analysis identified the mRNA overexpression of EGFR, FGFR1, FGFR2, FGFR3, MET, PDGFRA, PDGFRB, MET, MDM2, and CDK4 in four, two, three, two, three, seven, three, five, and five cases, respectively. Samples with gene overexpression (defined as >average + 3SD) are circled in red. Supplementary Figure 3. mRNA expression of EGFR, ATRX, PTEN and NF1 without outlier cases. mRNA expression was compared between patients with and without mutations in EGFR, ATRX, PTEN and NF1. Cases with outlier expression (>average + 3SD or <average - 3SD) were excluded. A high EGFR expression level was observed in cases with EGFR mutations, whereas decreased expression was observed in cases with ATRX mutations (p = 1.0 × 10-11, 2.4 × 10-4, respectively, Student’s t-test). The dotted line indicates the threshold for outliers (>average + 3SD or <average - 3SD). Supplementary Figure 4. Copy-number analysis using ddPCR. The copy numbers (CNs) of CDK4, EGFR, FGFR1, FGFR2, FGFR3, MDM2, ERBB2, MET, PDGFRA, and PDGFRB obtained using ddPCR are shown in a two-dimensional plot. The X-axis indicates the amplitude of the target genes (Ch1), whereas the y-axis indicates the amplitude of the reference gene (Ch2). The black clusters in the plots represent both negative droplets (Ch1− and Ch2−), green clusters represent droplets positive for the RPP30 reference gene (Ch1− and Ch2+), blue clusters represent droplets positive for target genes (Ch1+ and Ch2−), and orange clusters represent droplets positive for both genes (Ch1+ and Ch2+). CNs were calculated based on the number of copies of the target genes, assuming that the reference gene had two copies. Supplementary Figure 5. Comparison of clusters 1 and 2 in prognosis and gene expression. (A) Kaplan–Meier curves of overall survival in the cohort stratified by k-means clustering as clusters 1–2. (B) GSEA results with the indicated gene sets differentially enriched among clusters defined by k-means clustering. The full GSEA results can be found in Supplementary Data 3. Supplementary Figure 6. Heatmap of the expression of the genes on chr19q13 and chr1p36. The heatmap revealed the expression of 36 genes on chr19q13 and 28 genes on chr1p36 across astrocytomas and oligodendrogliomas. Supplementary Figure 7. Heatmap of the TPM for 29 genes on chr19q13 and chr1p36. The heat map shows the TPM for 29 genes on chr19q13 and chr1p36 and their average TPM with histological information. The violin plot revealed that the average TPM of these 29 genes was lower in oligodendrogliomas than that in astrocytomas (p = 0.0001, Student’s t-test). (PPTX 2474 KB)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shirai, Y., Ueno, T., Kojima, S. et al. The development of a custom RNA-sequencing panel for the identification of predictive and diagnostic biomarkers in glioma. J Neurooncol 167, 75–88 (2024). https://doi.org/10.1007/s11060-024-04563-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11060-024-04563-z