
Abstract
Magnetic resonance (MR) imaging is widely used for assessing infant head and brain development and for diagnosing pathologies. The main goal of this work is the development of a segmentation framework to create patient-specific head and brain anatomical models from MR images for clinical evaluation. The proposed strategy consists of a fusion-based Deep Learning (DL) approach that combines the information of different image sequences within the MR acquisition protocol, including the axial T1w, sagittal T1w, and coronal T1w after contrast. These image sequences are used as input for different fusion encoder–decoder network architectures based on the well-established U-Net framework. Specifically, three different fusion strategies are proposed and evaluated, namely early, intermediate, and late fusion. In the early fusion approach, the images are integrated at the beginning of the encoder–decoder architecture. In the intermediate fusion strategy, each image sequence is processed by an independent encoder, and the resulting feature maps are then jointly processed by a single decoder. In the late fusion method, each image is individually processed by an encoder–decoder, and the resulting feature maps are then combined to generate the final segmentations. A clinical in-house dataset consisting of 19 MR scans was used and divided into training, validation, and testing sets, with 3 MR scans defined as a fixed validation set. For the remaining 16 MR scans, a cross-validation approach was adopted to assess the performance of the methods. The training and testing processes were carried out with a split ratio of 75% for the training set and 25% for the testing set. The results show that the early and intermediate fusion methodologies presented the better performance (Dice coefficient of 97.6 ± 1.5% and 97.3 ± 1.8% for the head and Dice of 94.5 ± 1.7% and 94.8 ± 1.8% for the brain, respectively), whereas the late fusion method generated slightly worst results (Dice of 95.5 ± 4.4% and 93.8 ± 3.1% for the head and brain, respectively). Nevertheless, the volumetric analysis showed that no statistically significant differences were found between the volumes of the models generated by all the segmentation strategies and the ground truths. Overall, the proposed frameworks demonstrate accurate segmentation results and prove to be feasible for anatomical model analysis in clinical practice.
Similar content being viewed by others
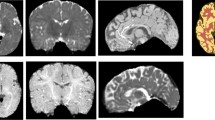

1 Introduction
Abnormalities in head shape and brain size during the neonatal period are commonly associated with poor neurodevelopment, determining life-long competencies [1, 2]. Magnetic resonance (MR) imaging is a non-invasive and safe technique that has been widely used for the assessment of infant head and brain structures, specifically to evaluate their shape and growth and to detect abnormalities. It provides detailed images of the cranium and brain tissues, gathering valuable information about the infant’s head and brain. In particular, MR is widely used for structural analysis, where size and shape of different regions can be evaluated to understand how head and brain are developing. Additionally, MR is highly effective for detecting changes in the tissues associated with brain injuries and abnormalities, such as tumors, autism, or cerebral palsy [3, 4], as well as identifying cranial deformities.
Medical image segmentation plays a critical role in extracting anatomical information from MR images, aiding its interpretation [5]. Segmentation of the brain region enables the monitoring of brain growth, evaluation of brain regions, and assessment of the abovementioned pathologies [3, 6, 7]. Head segmentation can be used to construct an anatomical model of the infant’s head from where cranial measurements can be extracted to perform head shape evaluation and detect cranial abnormalities [8,9,10,11]. However, manual segmentation of these structures is very challenging even for experienced radiologists, being time-consuming, labor-intensive, and highly prone to intra- and inter-observer variability. For these reasons, automatic brain and head segmentation methods are claimed and have been explored in the literature [5, 12]. However, most of these methods are typically designed to work with a single MR image or a set of MR sequences obtained in the same acquisition plane and containing the same complete anatomical information (e.g., T1w, T2w, FLAIR). In contrast, the traditional clinical MR acquisition protocol for an infant’s head involves a combination of various multiplanar MR sequences, each optimized for assessing a specific region of the head, and therefore, only containing partial anatomical information (Fig. 1). As a result, different head regions are acquired in each sequence, allowing to obtain complementary information about the tissues and, therefore, maximizing the diagnostic quality. This makes it more challenging to apply automated segmentation methods across the different multiplanar sequences. Thus, the methods proposed in the literature were not developed or applied for multiparametric MRI scans, precluding their application for entire head and brain segmentation. Thus, since state-of-the-art methods may not be optimal for the task addressed in this work, the need for advanced segmentation methods that can effectively leverage complementary information from multiplanar MR sequences to achieve accurate head and brain segmentation is highlighted.

Different multiplanar image sequences acquired during a MR scan. First row: axial T1w sequence; second row: coronal T1w sequence (after contrast); third row: sagittal T1w sequence
In this work, we propose a framework that uses fusion-based deep learning (DL) to accurately segment the brain and head in multiplanar MR scans of infants. This study aims to generate accurate anatomical models of the entire head and brain, enabling in-depth structural analysis concerning growth and shape. The proposed method leverages complementary partial information of distinct MR image sequences to maximize the information available for accurate segmentation. This approach allows us to create complete anatomical models even if partial information is found in the image sequences. Specifically, three sequences of the MR acquisition protocol are used to construct the anatomical models of the entire head and brain, corresponding to the axial T1w, sagittal T1w, and coronal T1w after contrast (Fig. 1). Moreover, three fusion DL networks are introduced and compared, namely early, intermediate, and late fusion. This comparative analysis allows us to understand the best approach for multimodal segmentation. For all the fusion techniques, an encoder–decoder network is applied to perform the segmentation. Hereto, the contributions of this work can be outlined as follows:
-
An automatic framework to accurately segment infants’ brain and head using different multiplanar sequences acquired in the traditional MR protocol. This enables the creation of anatomical models of the structures for volumetric assessments, diagnostic applications, and structural analyses;
-
Development and comparative analysis of three distinct fusion-based segmentation approaches implemented in an encoder–decoder configuration, encompassing early, intermediate, and late fusion network architectures;
-
Validation of the proposed approaches in a clinical database of MR images of infants, where the methods’ performance is evaluated in terms of segmentation accuracy and clinical volumetric measurements.
The remainder of the paper is structured as follows. In Sect. 2, an overview of the literature related to the driving topic of this work is presented. In Sect. 3, the proposed methodology is described. The experiments performed are detailed in Sect. 4, with the results presented in Sect. 5. In Sect. 6, the results obtained are discussed, and the conclusions are presented in Sect. 8.
2 Related work
Several methods have been proposed in the literature for processing the head in MR, with a particular focus on brain segmentation [12, 13]. Early state-of-the-art included methods based on thresholding and mathematical morphology [14,15,16,17], intensity-based methods [18,19,20,21,22,23], deformable models [24,25,26], or atlas-based approaches [27,28,29] In recent years, supervised classification techniques have been proposed. In [30], an ensemble approach was developed, where features were extracted from super-pixels of the image, and Support Vector Machine, K-Nearest Neighbors, and Decision Tree classifiers were used to classify brain tissues. DL algorithms have also emerged and superseded the remaining segmentation methodologies due to their improved performance. In [31], a deep neural network was proposed for brain segmentation. Other DL-based techniques focused on convolutional neural networks (CNN) were described to perform the segmentation [32,33,34]. In [32], the VoxResNet, consisting of a deep voxel-wise residual network based on ResNet architecture, was presented for brain segmentation. In [34], a complementary-based information approach was used, where a CNN is applied to segment the brain and the non-brain tissues, arguing that the complementary information given by the non-brain tissues can improve brain segmentation. In [35], a graph attention auto-encoder (GATE) and a convolution network were applied for brain tumor segmentation, where the CNN is used to process the graph generated by the GATE. Brain tumor segmentation was also addressed in [36], where the well-known mask-RCNN and a squeeze-and-excitation residual network are used together to achieve the segmentation. The well-known U-Net [37] was also largely used. In [38] and [39], the U-Net network was directly used to extract the brain region from the MR image. In the work of [40], the U-Net was also used but in a multiclass segmentation scheme to extract both the brain and skull from the image. Segmentation of different brain tissues using U-Net was addressed in [41], where a transfer learning scheme was applied to overcome the scarcity of manually labeled tissues. The work proposed in [42] also applies U-Net for brain tissue segmentation, but in a 2.5D approach where the U-Net is applied to the three anatomical views and learns to efficiently fuse them based on the intersection points and hierarchical relations. A dual encoder residual U-Net based on texture features and background knowledge was proposed in the work of [43]. Here, dual encoders for T1-w images and texture features are combined to achieve the segmentation.
The abovementioned methods were mainly used to process an independent image sequence. Other works focused on the development of methods to simultaneously process different image sequences acquired in the same anatomical plane. A hyper-dense network that integrates dense connections to a CNN and receives different MR sequences simultaneously was proposed in [44, 45] for brain segmentation. In [46], a DL method based on a decoder–encoder architecture was proposed where the information of different MR image sequences was used jointly to segment the brain. A similar approach was proposed in [47]. In [48], an encoder–decoder architecture was also used, but with multiple encoders to process different image sequences. In [49], instead of an encoder–decoder architecture, a fully convolutional network with different branches for each image sequence was implemented. Other studies have focused on segmenting brain lesions or tumors. The work proposed in [50] uses multiple encoders to process the different MR sequences and cross-connections and attentional feature fusion are also added to achieve tumor segmentation. In [51], a multi-task model for brain tumor segmentation was proposed. The model includes an auxiliary task of image fusion, which aims to better relate the multimodal features to improve the segmentation task, similar to the idea of the network proposed in [52]. The recently introduced transformers were also applied in the literature for multimodal tumor segmentation. In [53], transformers and an encoder–decoder U-Net-based network were combined to segment the brain tumor, where the different MR sequences are fed together to the network. In [54], a semantic segmentation module based on transformers, an edge detection module based on CNNs, and a feature fusion module to relate the previous modules are used for the segmentation. Nevertheless, the abovementioned methods were proposed to process different images among the different MR modalities, where all images present the same anatomical information since they are acquired in the same acquisition plane. Thus, to the best of our knowledge, head and brain segmentation in multiplanar images with specific partial information was not addressed in the literature yet.
3 Methods
The proposed method consists of three main parts: 1) pre-processing stage; 2) segmentation via fusion-based DL; and 3) the post-processing stage. The goal of the pre-processing stage is to align the distinct multiplanar MR sequences acquired in specific anatomical planes, by transforming the sequences initially acquired with its individual reference system into a common coordinate system. In the segmentation stage, three different fusion-based approaches are proposed and compared to segment the infants’ heads and brains. The aligned MR sequences obtained in the pre-processing stage are used as input for the networks. In the final stage, the segmentation results are post-processed to eliminate mis-segmented regions and fill segmentation gaps, generating accurate anatomical models.
3.1 Dataset creation
To develop the segmentation method to create patient-specific anatomical models of the head and brain, a clinical in-house dataset was used. The clinical dataset was composed of 19 MR scans, each with different sequences. Table 1 summarizes the study population of the dataset. MRI was acquired using AVANTO SIEMENS (1.5 T) and pediatric head coils (INVIVO) with patients positioned in the Head First-Supine orientation. Spin-echo (SE) sequences were used, with varying pulse parameters including repetition time (TR) in the range of 350 to 787 ms and echo time (TE) ranging from 8 to 13 ms. The acquired images had diverse resolutions, with the number of rows and columns per slice varying between 256 to 512 and 176 to 384, respectively. Pixel spacing within slices ranged from 0.4 × 0.4 to 0.7 × 0.7 mm. The slice thickness varied between 3 to 5 mm, and there was a spacing between the slices ranging from 2.5 to 6 mm between slices. The ground truth for the brain was manually created using the MITK software [44]. Multiple 2D slices were manually selected and segmented by the observer and then interpolated to obtain a final 3D surface. After 3D interpolation, 2D corrections were performed if required. The ground truth for the head was constructed using a semi-automatic approach. The three sequences were weight-averaged to create one image with all the information of them. The weights were manually selected by one observer for each scan. The resulting image was then binarized and post-processed with mathematical morphology. As a final step, non-relevant segmentation areas were manually clipped, and manual corrections were performed to obtain the final head segmentation.
3.2 Pre-processing
During one examination using MR, different regions and planes of the head and brain are evaluated independently, originating multiplanar sequences. Each sequence has its 3D position with respect to a global coordinate system, as well as its voxel spacing across different anatomical planes. Thus, the first step of the proposed method is to transform all image sequences into a common isotropic normalized space (Fig. 2) defined to have a voxel size of 0.5 × 0.5 × 0.5 mm. To perform the alignment, all sequences are mapped into the scanner world by mapping each sequence voxel coordinates to the respective \(x,y,z\) world coordinate in the reference system, using the affine transformation matrices of the images. The aligned world coordinates are then converted to the final image coordinate system, which corresponds to an isotropic coordinate space aligned with the scanner world. Interpolation is used to ensure that all voxels of the image coordinate system contain intensity values. After this process, the final image sizes ranged from 375 × 242 × 317 to 642 × 380 × 637, while maintaining a uniform voxel size of 0.5 × 0.5 × 0.5 mm. Finally, the images’ intensities are normalized to a common range to reduce intensity variations between different images. Please note that no noise reduction or motion correction strategies were performed during the pre-processing stage since no discernible motion artifacts or noise were found in the images.

Transformation of the different image sequences to the same isotropic coordinate system. The original images were initially represented on their own coordinate system (colored axes) and are afterward transformed to the same system (yellow axes)
3.3 Segmentation via fusion-based deep learning
To create three different fusion-based network configurations, the well-known U-Net was customized [37]. The traditional U-Net is composed of two paths: (1) an encoding network and (2) a decoding network (Fig. 3). The encoding network consists of a stack of five down-sampling encoding blocks used to capture context from the image and to learn scale invariance. Each encoding block is composed of two convolutional layers followed by instance normalization and a leaky rectified linear unit. At each block, the first convolutional layer is strided to obtain the down-sampling. The decoding path corresponds to a symmetric up-sampling path used to compensate for the spatial information loss caused by the down-sampling process. Each one of the five decoder blocks is also composed of two convolutional layers, instance normalization, and a leaky rectified linear unit. A transposed convolution is applied between each decoding block to perform the up-sampling process. Besides the two paths, skip connections are used to enable information sharing between the encoder and decoder. After the last decoding block, a convolution layer is applied to generate a two-channel output, corresponding to the brain and head segmentation masks. In this work, the configuration of the U-Net is adapted to deal with the different multiparametric MRI scans simultaneously, using fusion-based techniques. Specifically, three fusion methodologies are implemented, namely early, intermediate, and late fusion.

Architecture of the network used as basis for the proposed segmentation approaches. SConv strided convolution, Conv convolution, InsN instance normalization, LreLu leaky rectified linear unit, Tconv transpose convolution
3.3.1 Early fusion configuration
Early fusion methodologies consist of merging separated image sequences into a unified representation before its processing by the network. This type of approach is commonly called input-level fusion network (Fig. 4). In the proposed early fusion network, the three MR image sequences are concatenated into a single image comprising three channels, with each channel corresponding to one image sequence. The resulting image is then used as input for the traditional U-Net without any intrinsic modifications. Consequently, the network processes the image sequences jointly, with all network layers fully exploiting the information retrieved from the different sequences.

Early fusion DL: input-level fusion network
3.3.2 Intermediate fusion configuration
An intermediate fusion approach involves the independent processing of different image sequences by a set of layers, after which the learned individual feature representations are fused and processed by another set of network layers. This strategy can be also called layer-level fusion network (Fig. 5). To achieve the intermediate fusion network, the U-Net architecture was modified. Specifically, the adapted U-Net architecture incorporates three encoder paths alongside a unified decoder path. Each encoder path processes an individual image sequence, and the feature representations retrieved from each encoder path are concatenated and processed by the decoder path. This configuration allows the decoder path to process multimodal feature maps jointly, which are the feature maps retrieved from each encoder. Additionally, skip connections are used between the three encoders and the decoder. This feature-level merging enables the integration of different image sequences at a higher level of abstraction in comparison with input-level fusion, allowing the learning of highly non-linear relationships between the features of the different sequences.

Intermediate fusion DL: layer-level fusion network
3.3.3 Late fusion configuration
In late fusion methodologies, each image sequence is processed independently by a segmentation network, and the results of the networks are subsequently fused to obtain the final segmentation. This originates a decision-level fusion network (Fig. 6). In this work, the U-Net architecture is used to process each image sequence independently. Thus, the overall late fusion network adopts a multibranch architecture, where each branch consists of an unmodified U-Net designed to process an individual image sequence. Each of these branches results in an individual segmentation. The final segmentation map is obtained by averaging the individual segmentation maps generated by each U-Net, prior to the final activation layer.

Late fusion DL: decision-level fusion network
3.3.4 Loss function
A sigmoid activation layer was applied at the end of each fusion-based architecture to force the segmentation results to be bounded in the interval between 0 and 1. This enabled the use of the Dice loss function to guide the network during training. This loss function measures the overlap between two segmentation masks, namely the predicted and the ground-truth ones, following the equation:
where \({p}_{m}^{i}\) is the output of the segmentation network and \({g}_{m}^{i}\) is the ground truth segmentation map for the pixel \(i \epsilon (1, 2, ...,N)\) and class\(m\). \(N\) is the number of pixels per image and \(M\) is the number of classes of the multi-class segmentation method (i.e., two, namely brain and head).
3.4 Post-processing
Small image clusters may be erroneously segmented as head or brain by the networks. To address this issue, a post-processing step is applied to the segmentation results. Firstly, since both head and brain are constituted by one single structure, the largest component of each segmentation map is retained, while small clusters and isolated points are removed. Afterward, a hole-filling approach is implemented to fill gaps that may appear in the segmentation masks. The post-processing procedure is applied to each segmentation mask, i.e., brain and head, independently.
4 Experimental setup
4.1 Implementation details
The clinical dataset described in Sect. 3.1 was divided into training, validation, and testing sets. The training set was used to train the fusion-based DL networks and the testing set was used to test the methods’ performance once trained. The validation set was used to evaluate the training convergency and it was composed of 3 MR scans that were maintained across all experiments. A four-fold cross-validation strategy was implemented for the remaining scans, dividing it into 4 folders with 12 training and 4 testing scans. Thus, the overall accuracy of the proposed fusion-based methods was evaluated in a total of 16 MR scans.
The three fusion-based DL architectures were trained with the same configuration parameters to avoid biases in the comparison between them. The networks were trained with a mini-batch size of 2 and using the Adam optimizer with an initial learning rate of 0.0001 which was updated using a polynomial learning rate decay policy. The encoders’ first and second levels were defined to have 16 feature maps, which double in each double convolution operation in the subsequent three levels. As a result, the encoders’ last level comprises 128 feature maps. The decoders were configured to be symmetric to the encoders, meaning that the same number of feature maps were defined at corresponding levels of the U-Net configuration, before concatenating the feature maps generated by the encoder through the skip connections. Thus, the feature maps are reduced to 16 after the last upsampling block and further to a two-channel output by the final convolutional layer. The convolution kernel size is 3 × 3 × 3 in all convolutional layers. Considering these network configurations, the number of learning parameters of the early fusion, intermediate fusion, and late fusion configurations is ≈1.4 M, 4.3 M, and 4.2 M, respectively.
To prevent overfitting during training, dropout with probability 0.2 was incorporated in the convolutional layers. Additionally, data augmentation techniques consisting of intensity-based transformations were applied, including Gaussian noise addition, brightness and contrast modification, and blur. Due to computational efficiency, a patch strategy was employed during training, where patches with size 256 × 256 × 256 per sequence were randomly generated as input of the network. During testing, a sliding window approach was implemented to generate the complete segmentation maps.
4.2 Evaluation metrics
Two types of analyses were conducted, including surface analysis and volumetric analysis. The surface analysis focuses on the segmentation accuracy, and it was assessed in terms of Dice coefficient, Jaccard coefficient, average symmetric surface distance (ASD), and Hausdorff distance without outliers (HD95) for all the fusion-based networks proposed in this study. These evaluation metrics are retrieved between the segmentation mask \(S\) and respective ground truth \(G\) and can be described as:
where \(S^{\prime}\) and \(G^{\prime}\) denote the contour of \(S\) and \(G\), respectively, and \({n}_{S}\) and \({n}_{G}\) represent the number of contour points.
The volumetric analysis concerns the volumetric assessment of the anatomical models. In this analysis, the volumes of the segmented surfaces and the manual ones were compared through a Bland–Altman analysis. The volumetric analysis aligns with conventional clinical practice, which relies on accurate volume estimation for the evaluation of head and brain growth.
4.3 Comparison with the state-of-the-art
To justify the performance of the proposed approaches, we compare them with three state-of-the-art fusion-based segmentation methods, which are briefly introduced below:
-
EnNet [46]: an ensemble convolutional neural network that fuses different magnetic resonance modalities into a single input before its processing by the network.
-
SegResNetVAE [52]: an encoder–decoder convolutional neural network that contains an auxiliary variational auto-encoder to reconstruct the input images, aiming to regularize the shared decoder that processes all the image modalities simultaneously.
-
HyperDenseNet [45]: a convolutional neural network that contains an independent path for each image modality and dense connections between the different paths to better relate the different modalities.
5 Results
Tables 2 and 3 summarize the surface analysis, presenting the fusion methods' performance for the head and brain, respectively, assessed in terms of Dice, Jaccard, ASD, and HD95. The comparison with state-of-art methods is also presented in Tables 2 and 3. In Fig. 7, the boxplots for each evaluation metric are presented to provide an in-depth analysis concerning the performance in terms of percentiles and outlier points. To assess the performance differences among the proposed fusion approaches, a two-tailed paired T-test was performed between each pair of methods, allowing to analyze statistically significant differences between them. The outcomes of this analysis are presented in Fig. 7. To visually demonstrate the method’s performance, Fig. 8 and Fig. 9 contain examples of segmentation results (for head and brain, respectively), including a good and a bad segmentation.

Segmentation performance for the different fusion methods. First row: head segmentation; Second row: brain segmentation. The ends of the whiskers represent the 10th and 90th percentiles. The crosses represent the average value for each boxplot. The dot points are outliers. *p < 0.05 in a two-tailed paired t-test between the respective pair

The results are presented as a surface distance map (in mm) between manual ground-truth (dark green model) and predicted segmentation (colorized models). First row: good segmentation result; second row: bad segmentation result. Second column: early fusion; third column: intermediate fusion; fourth column: late fusion

Example of segmentation results for the brain segmentation task. The results are presented as a surface distance map (in mm) between manual ground-truth (dark green model) and predicted segmentation (colorized models). First row: good segmentation result; second row: bad segmentation result. second column: early fusion; third column: intermediate fusion; fourth column: late fusion
The volumetric analysis can be seen in Fig. 10, which presents the Bland–Altman plots for each fusion method using the manual segmentation as reference. The biases (average difference between the predictions generated by the fusion methods and manual segmentation) and limits of agreement (LOA, 1.96σ) were assessed. A two-tailed paired T-test was also applied between the segmentation results and the ground truth to evaluate statistically significant differences.

Bland–Altman analysis for the different fusion methods. First row: head segmentation; second row: brain segmentation. The results are presented in dm3
6 Discussion
Infant head and brain segmentation present high importance in clinical practice for the construction of anatomical models for shape and growth evaluation. In this work, a framework for the segmentation of these structures was described. Concerning the task of whole-head segmentation, both early and intermediate fusion strategies were shown to be feasible since high segmentation accuracy was achieved using both strategies (Table 2 and Fig. 7). No statistically significant differences (\(p<0.05\) in the two-tailed paired T-test) were found between these two fusion strategies for all the evaluation metrics addressed. The high values found for the accuracy of the head segmentation task can be easily explained since the infant's head presents distinguishable intensities when compared with the background of the MR images. However, since traditional MR protocol sequences only present partial head information in each sequence, direct application of traditional intensity-based methods can be difficult since each image sequence needs to be adequately leveraged to achieve a coherent head segmentation result. Moreover, the presence of noise and imaging artifacts in the MR images also claims more robust methods. Using the proposed framework based on fusion mechanisms, the network automatically learns how to leverage the information of the partial sequences to accurately achieve the final segmentation (Fig. 8).
Regarding brain segmentation, the intermediate fusion strategy was shown to achieve better results (Table 3 and Fig. 7). This specific approach can integrate the advantages of both early fusion and late fusion. Early fusion strategies just merge the sequences in a common input space, not exploiting each independent sequence or the relations among them. In the late fusion, each network branch independently exploits the unique features of each sequence, but there is no integration regarding the exploited information, nor about how they relate to each other. The intermediate fusion approach can solve the abovementioned issues. This strategy presents specific network layers for the individual analysis of each sequence, while also connecting them to capture complex relations between sequences. This nature of layer-level fusion strategies can potentially help the network to learn richer information, achieving better performance. Thus, for more challenging segmentation problems, such brain segmentation, this type of approach can lead to better results. In fact, from the analysis of Tables 2 and 3, it can be also verified that the task of brain segmentation is more challenging when compared with head segmentation. This is expected due to the intrinsic properties of the MR. Indeed, the intensities of different brain structures often overlap with the intensities of non-brain tissues, such as the neck and scalp, hampering their differentiation. Moreover, the brain contains different independent structures that are not homogeneous and vary between individuals, also complicating the segmentation task. Nevertheless, high-accuracy segmentation results were also obtained for the brain using the proposed framework.
Concerning the comparison with state-of-the-art methods, for the whole-head segmentation task (Table 2), it can be seen that the proposed early and intermediate fusion approaches outperform the competing methods on all metrics except for the HD95. For this metric, the EnNet achieved slightly better results, which can suggest that the literature method generates fewer outliers in head contours. However, the proposed approaches exhibit improved performance in all other metrics, indicating accurate segmentations that are competitive with state-of-the-art methods. For brain segmentation (Table 3), the proposed intermediate fusion strategy showed to produce competitive results with the state-of-the-art, outperforming the methods in all metrics.
Despite these findings concerning the segmentation accuracy, the volumetric analysis performed (Fig. 10) showed that all fusion strategies are feasible to be applied in clinical practice for volumetric measurements extracted. Indeed, no statistically significant differences (\(p<0.05\) in the two-tailed paired T-test) were found between the volumes of all the segmentation results and the manual ones, indicating that no statistically significant biases (red dashed lines on Fig. 10) were observed. Moreover, narrow LOAs (green dashed lines) were obtained, particularly for the early and intermediate fusion approaches. These results demonstrate the added value of the proposed approaches for clinical evaluation of the shape and growth of an infant’s head and brain.
6.1 Study limitations
The present study presents a few limitations. First, image pre-processing methods, such as inhomogeneity correction or image enhancement, were not applied to improve the quality of the input images before processing them with the fusion-based networks. Including such methods could potentially improve the segmentation performance. Second, the predicted segmentations may not produce smooth and accurate contours near the structures’ boundaries, since no contour-aware losses are used during the training or smoothness constraints were applied to the predicted segmentations. Another potential limitation is that only the traditional encoder–decoder architecture, i.e., U-Net, was adapted for the different fusion methods. However, more complex implementations, such as including self-attention mechanisms or dense connections, can be explored to improve the segmentation performance. Additionally, other types of segmentation network architectures could also be adapted to the driving topic of this work. The small dataset used in the present work is also a limitation since the development and validation of the methods were performed on a database with only 19 scans acquired in only one clinical center. Thus, the proposed work would benefit from a larger dataset. Finally, in this work, only the head and brain were addressed. However, the segmentation of the inner structures of the brain could facilitate the analysis of brain pathologies. Additionally, the segmentation of the bone structures that compose the skull can be also useful for evaluating the cranial structure. Since the proposed framework already consists of a multiclass segmentation approach, incorporating different segmentation classes, i.e., the brain parts and skull, could be easily performed to increase the clinical potential of the framework.
7 Conclusion and future work
In this work, a fusion-based DL framework was proposed for the task of head and brain segmentation in MR scans of infants. Three fusion strategies were compared, namely early fusion, intermediate fusion, and late fusion. The layer-level fusion approach, i.e., the intermediate fusion method, showed to be more efficient for the overall multiclass segmentation task, achieving slighter better results when compared with the remaining methods. Nevertheless, all fusion network architectures showed to be feasible for the segmentation task, achieving reliable anatomical models comparable with the manual ones. Thus, the present work demonstrated its potential to be used in clinical practice for the creation of anatomical models for shape and growth evaluation.
To further improve the performance of the proposed fusion-based models and to increase their generality, the acquisition of a larger dataset of MR sequences is envisioned in future. The improvement of the segmentation performance will be also investigated by studying additional loss functions designed to specifically optimize the contour of the predicted segmentations, such as distance-based or contour-aware loss functions. These loss functions may help in the recovery of the fine details of the structures, significantly enhancing the quality of the predicted segmentations, and thus leading to the construction of improved anatomical models. Additionally, besides brain and head segmentation, other brain structures will be added to the framework, thereby expanding the potential clinical applications of this work. Finally, the versatility of the proposed fusion-based approaches allows for their potential application in other multimodal datasets, containing not only MR images but also images from different imaging modalities. Thus, the proposed method can be extended to address various segmentation tasks in future work.
References
Cheong, J.L.Y., et al.: Brain volumes at term-equivalent age are associated with 2-year neurodevelopment in moderate and late preterm children. J. Pediatr. 174, 91-97.e1 (2016)
Martiniuk, A.L.C., Vujovich-Dunn, C., Park, M., Yu, W., Lucas, B.R.: Plagiocephaly and developmental delay: a systematic review. J. Dev. Behav. Pediatr. 38(1), 67–78 (2017)
Despotović, I., Goossens, B., Philips, W.: MRI segmentation of the human brain: challenges, methods, and applications. Comput. Math. Methods Med.. Math. Methods Med. 2015, 113 (2015)
Ingeborg, K., Horber, V.: The role of magnetic resonance imaging in elucidating the pathogenesis. Dev. Med. Child Neurol. 49(2), 144–151 (2007)
Devi, C.N., Chandrasekharan, A., Sundararaman, V.K., Alex, Z.C.: Neonatal brain MRI segmentation: a review. Comput. Biol. Med.. Biol. Med. 64, 163–178 (2015)
Dimitrova, N., et al.: Brain volume and shape in infants with deformational plagiocephaly. PLoS ONE 32(7), 736–740 (2017)
Burkhardt, W., Schneider, D., Hahn, G., Konstantelos, D., Maas, H.G., Rüdiger, M.: Non-invasive estimation of brain-volume in infants. Early Hum. Dev. 132(January), 52–57 (2019)
Beaumont, C.A.A., et al.: Three-dimensional surface scanners compared with standard anthropometric measurements for head shape. J. Cranio-Maxillofac. Surg. 45(6), 921–927 (2017)
Torres, H.R., et al.: Anthropometric landmarking for diagnosis of cranial deformities : validation of an automatic approach and comparison with intra- and interobserver variability. Ann. Biomed. Eng. 50, 8 (2022)
Torres, H. R. et al.: Deep learning-based detection of anthropometric landmarks in 3D infants head models: In SPIE Medical Imaging, p. 112 (2019).
Torres, H.R., et al.: Anthropometric landmark detection in 3D head surfaces using a deep learning approach. IEEE J. Biomed. Health Inform. 2194, 1–1 (2020)
Kalavathi, P., Prasath, V.B.S.: Methods on skull stripping of MRI head scan images—a review. J. Digit. Imaging 29(3), 365–379 (2016)
Fatima, A., Shahid, A.R., Raza, B., Madni, T.M., Janjua, U.I.: State-of-the-art traditional to the machine- and deep-learning-based skull stripping techniques, models, and algorithms. J. Digit. Imaging 33(6), 1443–1464 (2020)
Dogdas, B., Shattuck, D.W., Leahy, R.M.: Segmentation of skull and scalp in 3-D human MRI using mathematical morphology. Hum. Brain Mapp. 26(4), 273–285 (2005)
Shattuck, D.W., Sandor-Leahy, S.R., Schaper, K.A., Rottenberg, D.A., Leahy, R.M.: Magnetic resonance image tissue classification using a partial volume model. Neuroimage 13(5), 856–876 (2001)
Somasundaram, K., Kalaiselvi, T.: Automatic brain extraction methods for T1 magnetic resonance images using region labeling and morphological operations. Comput. Biol. Med. 41(8), 716–725 (2011)
Somasundaram, K., Kalaiselvi, T.: Fully automatic brain extraction algorithm for axial T2-weighted magnetic resonance images. Comput. Biol. Med. 40(10), 811–822 (2010)
Hahn, H.K., Peitgen, H.O.: The skull stripping problem in MRI solved by a single 3D watershed transform. Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 1935, 134–143 (2000)
Park, J.G., Lee, C.: Skull stripping based on region growing for magnetic resonance brain images. Neuroimage 47(4), 1394–1407 (2009)
Somasundaram, K., Kalavathi, P.: Brain segmentation in magnetic resonance human head scans using multi-seeded region growing. Imaging Sci. J. 62(5), 273–284 (2014)
Tuan, T.A., Kim, J.Y., Bao, P.T.: Adaptive region growing for skull, brain, and scalp segmentation from 3D MRI. Biomed. Eng. Appl. Basis Commun. 31, 5 (2019)
Sadananthan, S.A., Zheng, W., Chee, M.W.L., Zagorodnov, V.: Skull stripping using graph cuts. Neuroimage 49(1), 225–239 (2010)
Mahapatra, D.: Skull stripping of neonatal brain MRI: Using prior shape information with graph cuts. J. Digit. Imaging 25(6), 802–814 (2012)
Zhuang, A.H., Valentino, D.J., Toga, A.W.: Skull-stripping magnetic resonance brain images using a model-based level set. Neuroimage 32, 79–92 (2006)
Hwang, J., Han, Y., Park, H.: Skull-stripping method for brain MRI using a 3D level set with a speedup operator. J. Magn. Reson. Imaging 456, 445–456 (2011)
Tuan, T.A.: 3D brain magnetic resonance imaging segmentation by using bitplane and adaptive fast marching. Int. J. Imaging Syst. Technol. 2017, 9 (2018)
Wang, Y., Nie, J., Yap, P., Shi, F., Guo, L.: Robust deformable-surface-based skull-stripping for large-scale studies. In: MICCAI, pp. 635–642 (2011).
Leung, K.K., et al.: Brain MAPS: an automated, accurate and robust brain extraction technique using a template library. Neuroimage 55(3), 1091–1108 (2011)
Torrado-Carvajal, A., et al.: Multi-atlas and label fusion approach for patient-specific MRI based skull estimation. Magn. Reson. Med. 75(4), 1797–1807 (2016)
Iqbal, M.J., Bajwa, U.I., Gilanie, G., Iftikhar, M.A., Anwar, M.W.: Automatic brain tumor segmentation from magnetic resonance images using superpixel-based approach. Multimed. Tools Appl. 81(27), 38409–38427 (2022)
Sikka, A., Mittal, G., Bathula, D. R., Krishnan, N. C.: Supervised deep segmentation network for brain extraction. In: ACM International Conference Proceeding Series (2016).
Chen, H., Dou, Q., Yu, L., Qin, J., Heng, P.: A: VoxResNet: deep voxelwise residual networks for brain segmentation from 3D MR images. Neuroimage 170, 446–455 (2018)
Lucena, O., Souza, R., Rittner, L., Frayne, R., Lotufo, R.: Convolutional neural networks for skull-stripping in brain MR imaging using silver standard masks. Artif. Intell. Med. 98, 48–58 (2019)
Dey, R., Hong, Y.: Compnet: Complementary segmentation network for brain MRI extraction. Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 11072, 628–636 (2018)
Mishra, L., Verma, S.: Graph attention autoencoder inspired CNN based brain tumor classification using MRI. Neurocomputing 503, 236–247 (2022)
Kumar, P.R., Bonthu, K., Meghana, B., Vani, K.S., Chakrabarti, P.: Multi-class brain tumor classification and segmentation using hybrid deep learning network (Hdln) model. Scalable Comput. 24(1), 69–80 (2023)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 234–241 (2015).
Hwang, H., Ur Rehman, H.Z., Lee, S.: 3D U-Net for skull stripping in brain MRI. Appl. Sci. 9(3), 1–15 (2019)
Hsu, L.M., et al.: Automatic skull stripping of rat and mouse brain MRI data using U-Net. Front. Neurosci. 14(October), 1–9 (2020)
da Silva, R.D.C., Jenkyn, T.R., Carranza, V.A.: Development of a convolutional neural network based skull segmentation in MRI using standard tesselation language models. J. Pers. Med. 11, 4 (2021)
Liu, Y., Huo, Y., Dewey, B., Wei, Y., Lyu, I., Landman, B.A.: Generalizing deep learning brain segmentation for skull removal and intracranial measurements. Magn. Reson. ImagingReson. Imaging 88, 44–52 (2022)
Ghazi, M. M., Nielsen, M.: FAST-AID Brain: Fast and Accurate Segmentation Tool Using Artificial Intelligence Developed for Brain (2022).
Wu, L., Hu, S., Liu, C.: MR brain segmentation based on DE-ResUnet combining texture features and background knowledge. Biomed. Signal Process. Control 75, 103541 (2022)
Dolz, J., Ben Ayed, I., Yuan, J., Desrosiers, C.: Isointense infant brain segmentation with a hyper-dense connected convolutional neural network. In: Proceedings of the International Symposium on Biomedicine Imaging, vol. 2018, pp. 616–620 (2018).
Dolz, J., Gopinath, K., Yuan, J., Lombaert, H., Desrosiers, C., Ben Ayed, I.: HyperDense-Net: A hyper-densely connected CNN for multi-modal image segmentation. IEEE Trans. Med. Imaging 38(5), 1116–1126 (2019)
Pei, L., et al.: A general skull stripping of multiparametric brain MRIs using 3D convolutional neural network. Sci. Rep. 12(1), 1–11 (2022)
Nie, D., Wang, L., Adeli, E., Lao, C., Lin, W., Shen, D.: 3-D fully convolutional networks for multimodal isointense infant brain image segmentation. IEEE Trans. Cybern. 49(3), 1123–1136 (2019)
Kumar, S., Conjeti, S., Roy, A. G., Wachinger, C., Navab, N.: InfiNet: Fully convolutional networks for infant brain MRI segmentation. In Proceedings of the International Symposium on Biomedicine Imaging, vol. 2018, pp. 145–148 (2018).
Nie, D., Wang, L., Gao, Y. & Sken, D.: Fully convolutional networks for multi-modality isointense infant brain image segmentation. In Proceedings of the International Symposium on Biomedicine Imaging, vol. 2016, pp. 1342–1345 (2016).
Zhou, T.: Modality-level cross-connection and attentional feature fusion based deep neural network for multi-modal brain tumor segmentation. Biomed. Signal Process. Control 81, 104524 (2023)
Liu, Y., Mu, F., Shi, Y., Chen, X.: SF-Net: A multi-task model for brain tumor segmentation in multimodal MRI via image fusion. IEEE Signal Process. Lett. 29, 1799–1803 (2022)
Myronenko, A.: 3D MRI brain tumor segmentation using autoencoder regularization. Lect. Notes Comput. Sci. (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 11384, 311–320 (2019)
Jiang, Y., Zhang, Y., Lin, X., Dong, J., Cheng, T., Liang, J.: SwinBTS: a method for 3D multimodal brain tumor segmentation using Swin transformer. Brain Sci. 12, 6 (2022)
Zhu, Z., He, X., Qi, G., Li, Y., Cong, B., Liu, Y.: Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI. Inf. Fusion 91, 376–387 (2023)
Funding
Open access funding provided by FCT|FCCN (b-on). This work was funded by the projects “NORTE-01-0145-FEDER-000045” and “NORTE-01-0145-FEDER-000059”, supported by Northern Portugal Regional Operational Programme (NORTE 2020), under the Portugal 2020 Partnership Agreement, through the European Regional Development Fund (FEDER). It was also funded by national funds, through the FCT (Fundação para a Ciência e a Tecnologia) and FCT/MCTES in the scope of the projects UIDB/00319/2020, UIDB/05549/2020 (https://doi.org/10.54499/UIDB/05549/2020), UIDP/05549/2020 (https://doi.org/10.54499/UIDP/05549/2020), CEECINST/00039/2021 and LASI-LA/P/0104/2020. This project was also funded by the Innovation Pact HfFP—Health From Portugal, co-funded from the “Mobilizing Agendas for Business Innovation” of the “Next Generation EU” program of Component 5 of the Recovery and Resilience Plan (RRP), concerning “Capitalization and Business Innovation”, under the Regulation of the Incentive System “Agendas for Business Innovation”. The authors also acknowledge support from FCT and the European Social Found, through Programa Operacional Capital Humano (POCH), in the scope of the PhD grant SFRH/BD/136670/2018, SFRH/BD/136721/2018, and COVID/BD/154328/2023.
Author information
Authors and Affiliations
Contributions
HRT was responsible for the methodology development, for the validation, and for the writing of the original draft. BO and PM contributed to the methodology development and manuscript structuring and editing. AF, MR, and GH provided the clinical images and provided the clinical knowledge needed to interpret the images. JCF and JLV were responsible for the supervision and funding acquisition. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
Data were obtained as part of routine clinical care during hospital treatment. The MR scanner is an approved technical device used for routine clinical care. Ethical approval was given by the ethics committee of the Medical Faculty Carl Gustav Carus of the Technical University Dresden to analyze the routine clinical data (study number EK 261082012). The need for specific parental consent was waived by the ethics committee since only anonymized data are analyzed.
Consent to participate
Not applicable.
Consent to publication
Not applicable.
Additional information
Communicated by C. Yan.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Torres, H.R., Oliveira, B., Morais, P. et al. Infant head and brain segmentation from magnetic resonance images using fusion-based deep learning strategies. Multimedia Systems 30, 71 (2024). https://doi.org/10.1007/s00530-024-01267-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-024-01267-2