
Abstract
In recent years, several experimental evidences suggest that amino acid repeats are closely linked to many disease conditions, as they have a significant role in evolution of disordered regions of the polypeptide segments. Even though many algorithms and databases were developed for such analysis, each algorithm has some caveats, like limitation on the number of amino acids within the repeat patterns and number of query protein sequences. To this end, in the present work, a new method called the internal sequence repeats across multiple protein sequences (ISRMPS) is proposed for the first time to identify identical repeats across multiple protein sequences. It also identifies distantly located repeat patterns in various protein sequences. Our method can be applied to study evolutionary relationships, epitope mapping, CRISPR-Cas sequencing methods, and other comparative analytical assessments of protein sequences.






Similar content being viewed by others

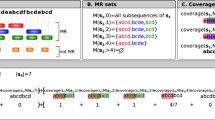
References
Abraham A-L, Rocha EPC and Pothier J 2008 Swelfe: a detector of internal repeats in sequences and structures. Bioinformatics 24 1536–1537
Altschul SF, Gish W, Miller W, et al. 1990 Basic local alignment search tool. J. Mol. Biol. 215 403–410
Babu V, Uthayakumar M, Kirti Vaishnavi M, et al. 2011 RPS: Repeats in protein sequences. J. Appl. Crystallogr. 44 647–650
Gruber M, Söding J and Lupas AN 2005 REPPER—repeats and their periodicities in fibrous proteins. Nucleic Acids Res. 33 W239–W243
Heger A and Holm L 2000 Rapid automatic detection and alignment of repeats in protein sequences. Proteins 41 224–237
Karp R and Rabin MO 1987 Efficient randomized pattern-matching algorithms. IBM J. Res. Dev. 31 249–260
Klein C and Westenberger A 2012 Genetics of Parkinson’s disease. Cold Spring Harb. Perspect. Med. 2 a008888
Kohany O, Gentles AJ, Hankus L, et al. 2006 Annotation, submission and screening of repetitive elements in Repbase: RepbaseSubmitter and Censor. BMC Bioinform. 7 474
Luo H and Nijveen H 2014 Understanding and identifying amino acid repeats. Brief. Bioinform. 15 582–591
Mansour A 2008 ClustalW©: Widespread Multiple sequences alignments program. J. Cell Mol. 7 81–82
Marcotte EM, Pellegrini M, Yeates TO, et al. 1999 A census of protein repeats. J. Mol. Biol. 293 151–160
Meena LS 2015 An overview to understand the role of PE _ PGRS family proteins in Mycobacterium tuberculosis H 37 R v and their potential as new drug targets. Biotechnol. Appl. Biochem. 62 145–153
Michael D, Gurusaran M, Santhosh R, et al. 2019 RepEx: A web server to extract sequence repeats from protein and DNA sequences. Comput. Biol. Chem. 78 424–430
Nirjhar B, Chidambarathanu N, Daliah M, et al. 2008 An Algorithm to find all identical internal sequence repeats. Curr. Sci. 95 188–195
Rajathei DM, Parthasarathy S and Selvaraj S 2019 Identification and analysis of long repeats of proteins at the domain level. Front. Bioeng. Biotechnol. 7 250
Senthilkumar R, Sabarinathan R, Hameed BS, et al. 2010 FAIR: a server for internal sequence repeats. Bioinformation 4 271–275
Szklarczyk R and Heringa J 2004 Tracking repeats using significance and transitivity. Bioinformatics 20 (Suppl 1) i311–i317
Tanabe K, Arisue N, Palacpac NM, et al. 2012 Geographic differentiation of polymorphism in the Plasmodium falciparum malaria vaccine candidate gene SERA5. Vaccine 30 1583–1593
Thompson JD, Higgins DG and Gibson TJ 1994 CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice. Nucleic Acids Res. 22 4673–4680
Ukkonen E 1995 On-line construction of suffix trees. Algorithmica 14 249–260
Uthayakumar M, Benazir B, Patra S, et al. 2012 Homepeptide repeats: implications for protein structure, function and evolution. Genom. Proteom. Bioinform. 10 217–225
Vetting MW, Hegde SS, Fajardo JE, et al. 2006 Pentapeptide repeat proteins. Biochemistry 45 1–10
Worsfold P, Townshend A, Poole CF, et al. 2019 Encyclopedia of analytical science, 3rd edition (Elsevier)
Acknowledgements
KS thanks the ICMR for funding the project ‘Do protein sequence repeats play a role in biological process and disease conditions’ (ISRM/12(34)/2020). KS, RS and DR thank the Center for Development of Advanced Computing (CDAC) for funding the project ‘An Indian Initiative on setting up a high-fidelity structural data archival/retrieval system for Life Sciences-(PDBi)’. RS thanks the Department of Science and Technology-Science and Engineering Research Board (DST-SERB), New Delhi, India, for providing research grant and postdoctoral fellowship (PDF/2019/000254). AM thanks Dr D S Kothari Postdoctoral Fellowship (BL/18-19/0320), funded by the University Grants Commission (UGC). All the authors thank the Department of Computational and Data Sciences, Indian Institute of Science, Bengaluru, India, for providing the necessary support.
Author information
Authors and Affiliations
Contributions
Prof. SK conceptualized the study. VKM and RS devised the methodology. AM, MS, RS and DR assessed the algorithm, methods. CNR and AM contributed to case studies. AM and RR wrote the manuscript. MS and CNR reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors acknowledge that there is no conflict of interest related to financial and research interest related to this manuscript.
Additional information
Corresponding editor: Deepesh Nagarajan
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Maurya, V.K., Sanjeevi, M., Rahul, C.N. et al. Finding identical sequence repeats in multiple protein sequences: An algorithm. J Biosci 49, 41 (2024). https://doi.org/10.1007/s12038-023-00410-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12038-023-00410-x