
Public Perception of Online P2P Lending Applications



1
Department of Management Studies, Indian Institute of Information Technology Allahabad, Prayagraj 211015, India
2
Department of Finance and Real Estate, Kogod School of Business, American University, Washington, DC 20016, USA
3
Department of Information Technology, Indian Institute of Information Technology Allahabad, Prayagraj 211015, India
*
Author to whom correspondence should be addressed.
J. Theor. Appl. Electron. Commer. Res. 2024, 19(1), 507-525; https://doi.org/10.3390/jtaer19010027
Submission received: 19 January 2024
/
Revised: 23 February 2024
/
Accepted: 26 February 2024
/
Published: 1 March 2024
(This article belongs to the Topic Online User Behavior in the Context of Big Data)
Abstract
:This study examines significant topics and customer sentiments conveyed in reviews of P2P lending applications (apps) in India by employing topic modeling and sentiment analysis. The apps considered are LenDenClub, Faircent, i2ifunding, India Money Mart, and Lendbox. Using Latent Dirichlet Allocation, we identified and labeled 11 topics: application, document, default, login, reject, service, CIBIL, OTP, returns, interface, and withdrawal. The sentiment analysis tool VADER revealed that most users have positive attitudes toward these apps. We also compared the five apps overall and on specific topics. Overall, LenDenClub had the highest proportion of positive reviews. We also compared the prediction abilities of six machine-learning models. Logistic Regression demonstrates high accuracy with all three feature extraction techniques: bag of words, term frequency-inverse document frequency, and hashing. The study assists borrowers and lenders in choosing the most appropriate application and supports P2P lending platforms in recognizing their strengths and weaknesses.
1. Introduction
In today’s business landscape, understanding customer needs is crucial. Web 2.0 and social media have fueled direct interaction, creating many user-generated insights. Companies harness these data to refine their offerings [1]. Mobile apps play a key role in attracting and engaging customers, offering intuitive interfaces through software installed on smartphones and devices [2,3].
App stores like Google Play and the Apple App Store offer paid and free options [3,4]. Additionally, user reviews, expressed through star ratings and text feedback on these mobile applications (apps), serve as a source of information for customers and developers [3,5]. Consumers can judge app quality, while developers gain valuable feedback on strengths and weaknesses [5,6,7]. This dynamic two-way communication is a hallmark of the customer-centric approach in the mobile app era.
Textual analysis, topic modeling, and sentiment analysis unlock insights from the vast world of online comments, identifying key features, topics, and even emotional undertones [1,5]. This power extends across diverse fields, from gauging stock market sentiment to analyzing tourist experiences [1,8]. In the realm of alternative finance, where models bridge the gap between unbanked populations and traditional institutions, sentiment plays a crucial role [9,10,11]. Crowdfunding, which disrupts the traditional market with its innovative approach, is a prime example [12]. By gathering small contributions from a wide audience, crowdfunding bypasses intermediaries and democratizes fundraising [9,13]. Crowdfunding campaigns thrive on positive user sentiment expressed in reviews and comments when categorized into debt, equity, reward, and donation models [14].
Our study focuses on P2P lending, a debt-based alternative finance model where borrowing and lending occur directly, bypassing banks. P2P platforms like Zopa (2005) and Prosper (2006) were pioneers, inspired by earlier file-sharing models like Napster (1999) [15,16]. Lenders can access borrower information on the platform to make informed decisions.
Although P2P platforms do not guarantee loan repayment [17], they offer benefits like lower interest rates for borrowers and higher returns for lenders [18]. These platforms bypass traditional banks, minimizing costs and expanding credit access [19]. Compared to banks, they boast greater transparency, flexibility, and convenience [17]. In 2019 and 2020, P2P lending dominated the alternative finance market, with a global volume of USD 68.3 billion [12]. However, lenders shoulder the risk solely, unlike traditional banks [20].
Although China, the United States, and the United Kingdom lead, P2P platforms also fuel developing economies like India. They boost financial inclusion, economic growth, and access to capital for individuals and small businesses [17,21]. The Reserve Bank of India (RBI) regulates the scene with its 2017 master directions, currently overseeing 25 registered NBFC-P2P platforms [22]. Trust and transparency are crucial in this nascent market, where success hinges on understanding between strangers. Studying user-generated comments and reviews becomes vital for platforms to build a thriving lending ecosystem [23,24].
Prior studies examined the impact of descriptive text sentiments on the probability of P2P lending success and the default risk of borrowers with the help of natural language processing tools [10,11,25,26,27]. Still, no study examines user reviews and comments to identify the significant features, dominant topics, and public opinions on P2P lending apps. Additionally, the literature does not include a comparative study of multiple P2P lending apps. Therefore, our study fills this research gap by examining user reviews on five Indian NBFC P2P lending apps (LenDenClub, Faircent, i2i funding, India Money Mart, and Lendbox) available in the Google Play Store.
Our findings contribute to this research area in several ways. First, they can be useful to investors and borrowers in selecting suitable apps based on users’ sentiments about desired features through topic modeling and sentiment analysis. Second, entrepreneurs can understand what potential users think about their services, identify their concerns and preferences, and tailor their offerings accordingly. Third, we compared six machine-learning (ML) models (Logistic Regression, Random Forest, XGBoost, Decision Tree, Support Vector Machine, and K-Nearest Neighbor) to recommend an optimal ML algorithm for predicting sentiment in upcoming reviews. Implementing an ML model allows entrepreneurs to respond with counter feedback and address complaints, thereby improving customer satisfaction. Fourth, P2P lending can offer alternative financing options to underserved communities. Understanding public perception in these communities can help policymakers design targeted initiatives to raise awareness and address specific concerns, ultimately promoting financial inclusion.
Considering the gaps in the current research, we address the following research questions:
- RQ1.
- Do any dominant topics emerge from the features that are being shared by user reviews?
- RQ2.
- What emotions/sentiments do users have when reviewing and rating P2P lending apps?
- RQ3.
- Do the sentiments of user reviews differ between the apps?
- RQ4.
- How do machine-learning models perform in predicting the sentiments of reviews?
The remainder of the paper is organized as follows. Section 2 provides an overview of previous related research. Section 3 outlines the methods and proposed approach, while Section 4 presents the results. Section 5 offers the discussion and implications. Section 6 includes the conclusion, limitations, and future work.
2. Related Research
From crowdfunding to P2P lending, finance transforms as user voices take center stage. Here, we explore how text and sentiment analysis illuminate user perspectives on these models.
2.1. Analysis of User-Generated Content in P2P Lending and Other Crowdfunding Models
Web 2.0’s child, P2P lending, empowers under-banked borrowers despite lacking traditional gatekeepers [1]. Yet, success hinges on trust and understanding between borrowers and lenders [28]. Hence, platforms prioritize deciphering the expectations and desires of both lenders and borrowers. Some even see user-generated content as more reliable data, finding it refreshingly honest [1]. This situation underscores the crucial role of user voices in navigating the new financial frontier.
Past research in P2P lending and crowdfunding examines how user comments and their sentiment affect topics like funding success, interest rates, and defaults. Some find that only positive shifts in media and social media buzz negatively affected the P2P lending platform default probability and cost of capital [29]. Others show that investor comment sentiment influences trading volume [30]. Evidence suggests that business-oriented loans attract more funding [10]. Some researchers propose detailed narratives and financial information to boost funding success [11]. Yet, for predicting credit risk, the best results come from combining financial data with softer factors, like sentiment [27,31].
Past studies mined crowdfunding comments on platforms like Dreamore and Kickstarter to predict campaign success. They identify factors like positive sentiment, comment quantity, quick replies, and detailed project descriptions that all lead to better performance [32,33,34,35,36]. However, too much information can hurt, with an inverted U-shaped relationship emerging between content quantity and success [35].
2.2. Analysis of Text Mining and Sentiment Analysis Models on Customer Reviews
In various domains, text mining and sentiment analysis unlock hidden treasures in textual data. In crowdfunding, where text reigns supreme, studies mine words and topics to reveal critical concepts [1,5,37]. The sentiment analysis, also known as opinion mining, further delves into emotional undertones, helping us understand public perception and customer reactions [6]. These tools empower organizations to glean valuable insights from the vast world of online text. There are three paths to sentiment analysis: (1) knowledge-based methods; (2) statistical methods, like ML and deep learning; and (3) a hybrid approach blending both, unlocking deeper insights [38].
The world of app reviews crackles with opinions, and researchers use clever tools to understand them. ML reigns supreme, with hybrid approaches like GRU-CNN achieving an impressive 94% accuracy in classifying sentiment [2]. Even for complex tasks like predicting stock prices, hybrid models shine. Some propose a mutual information-based sentimental analysis (MISA) and deploy a kernel-based extreme learning machine model (KELM) method to enhance the prediction speed of stock prices [37]. Beyond text, hybrid models like H-SATF-CSAT-TCN-MBM combine audio, video, and text for even deeper insights [7]. From understanding user preferences to predicting market trends, these versatile techniques are unlocking the power of user text.
In an app review analysis, SVM with a self-voting classifier achieves 100% accuracy [14]. Conversely, another research study identified the Gradient Boosting Classifier as the most accurate predictor for campaign success [39]. Additionally, the AdaBoost regressor demonstrated high accuracy at 97.7% in sentiment analysis [35]. Despite these findings, SVM remains widely favored, with studies conducted by [3,26,27,40,41,42] highlighting its versatility.
In the parlance of the knowledge-based approach, also known as the lexicon or rule-based approach, various studies have used the Valence Aware Dictionary and Sentiment Reasoner (VADER) to provide sentiment intensity scores [1,2,14,43,44]. Others have used alternative lexicon-based techniques, such as the ontology Library of Chinese Emotional Vocabulary [31], Linguistic Inquiry and Word Count (LIWC) and WordNet software packages [11,34], snowNLP [43], SentiWordNet [38], TextBlob [42], LSTM (long short-term memory) [44], bidirectional long-term, short-term memory (BiLSMT) [45], and DomainSenticNet, which is a hybrid aspect-based sentiment analysis system [46].
A text analysis is needed to obtain indicators and critical variables from a textual database [40]. Various studies have deployed text analysis methods for feature extraction, such as BOW, the Rake algorithm, Word2Vec, TFIDF, and hashing [26,47]. However, researchers commonly use TF-IDF [2,3,40,43].
Following feature extraction, prior studies have used topic modeling methods such as LDA and NMF. Topic modeling aids researchers in extracting fundamental themes, subjects, and topics from an extensive body of text. Essentially, it consolidates two or more features that can be categorized under the same topic [48]. The most popular model is the LDA [2,10,14,26,33,35,42,43,49,50]. Correspondingly, the Pattern-Based Topic Detection and Analysis System (PTDAS) employs the CP-Miners for topic modeling [51].
3. Approach and Proposed Methodology
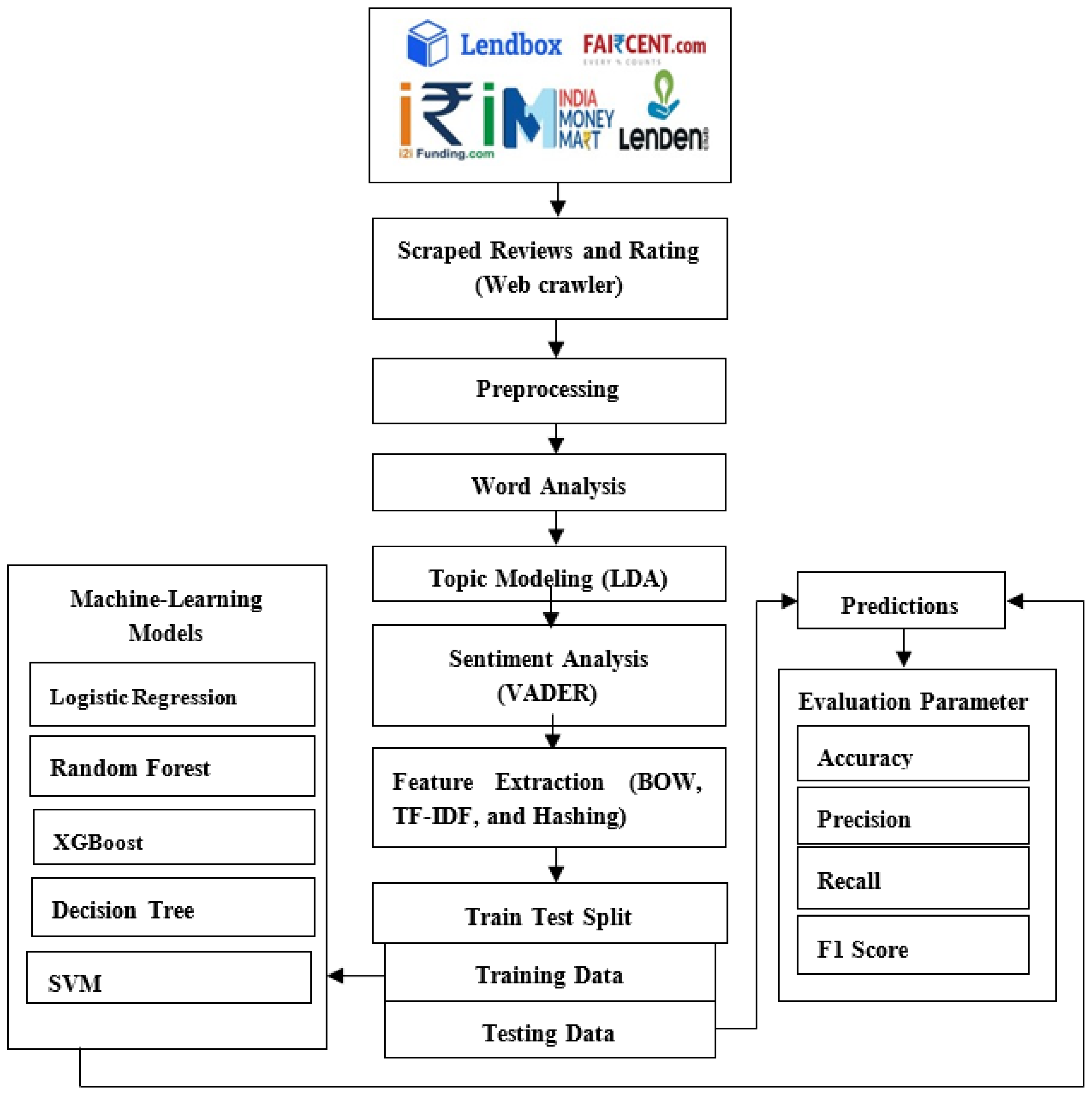
We conducted a topic-based sentiment analysis on reviews of P2P lending applications in India to evaluate which app stands out for different features. We also trained ML models by using a labeled dataset to forecast the sentiment of reviews. Figure 1 shows the proposed method’s structure.
First, we gathered data from the Google Play Store, using a web scraping tool. This dataset comprised unprocessed app reviews pertaining to P2P lending platforms, including excessive and redundant details. We applied various preprocessing measures to clean and simplify the review text. We then used word analysis to identify the most common words and LDA to cluster similar words and discern meaningful topics. Next, the dataset underwent annotation through a lexicon-based method called VADER. We used three distinct feature extraction methods—bag of words (BoW), TF-IDF, and hashing—to train the model. Next, we split the text into training and testing sets, with 0.75 to 0.25 ratios, respectively. We used several ML models, such as Support Vector Machines (SVMs), Decision Trees (DTs), XGBoost, Logistic Regression (LR), K-Nearest Neighbors (KNNs), and Random Forests (RFs), for prediction and classification. Finally, we examined the models based on metrics such as accuracy, precision, recall, and F1 score.
3.1. Data Description
Our dataset comprised reviews of five Indian P2P lending platforms: LenDenClub, Faircent, i2i funding, India Money Mart, and Lendbox from the Google Play Store. As of 10 January 2022, the Google Play Store was the largest online mobile app marketplace, offering over 2.6 million free and paid apps [3]. We extracted the data through a web scraping tool that needs three Python libraries: pandas, google_web_scraper, and numpy. A data file contains the username, date and time, thumbs-up count, textual feedback, and numerical rating, often ranging from 1 to 5. Table 1 provides an overview of the dataset, encompassing company names, review counts, and the time range.
3.2. Data Preprocessing
User reviews come in various forms, such as text-based feedback, emoji-based feedback, symbolic expressions, and punctuation usage. We cleaned the data to extract useful information, reduce complexity, and transform the data for word analysis, topic modeling, sentiment analysis, and ML. We adopted several preprocessing steps, as explained in [50,51].
- (a)
- Rectifying errors related to grammar, spelling, and punctuation.
- (b)
- Fixing slang, acronyms, and informal language.
- (c)
- Removing numerical values and digits.
- (d)
- Excluding special characters.
- (e)
- Removing URLs.
- (f)
- Excluding emojis and emoticons.
- (g)
- Removing characters that are not ASCII, including non-UTF-8 Unicode.
- (h)
- Excluding stop words and unnecessary spaces.
- (i)
- Changing all text to lowercase.
- (j)
- Applying stemming and lemmatization to the words.
4. Results
We address our four research questions in the following subsections.
4.1. Word Analysis
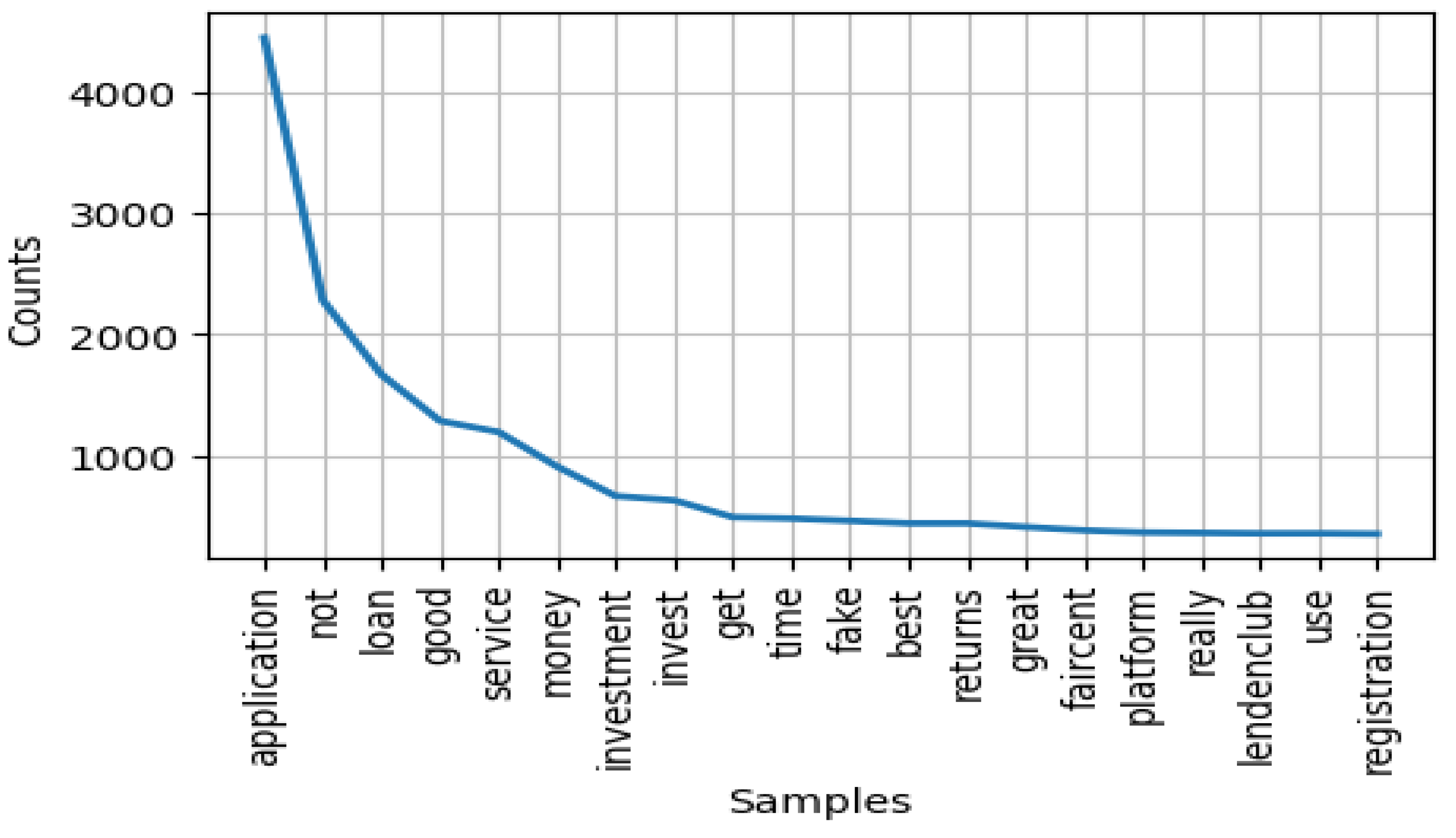
A word analysis enables the identification of key terms and phrases that indicate specific topics by analyzing the frequency of words across the dataset. The most popular words found in the reviews were “application” (4445 times), “not” (2281 times), “loan” (1669 times), “good” (1287 times), “service” (1196 times), “money” (911 times), “investment” (668 times), “invest” (632 times), “get” (494), and “time” (483 times). Figure 2 shows a sample of the most frequent words.
4.2. Topic Modeling
4.3. Sentiment Analysis
Word analysis and topic modeling are beneficial for understanding the content that users discuss in their reviews. Nevertheless, a more profound understanding of the user’s sentiments, attitudes, and emotions toward specific topics requires employing sentiment analysis. Therefore, we applied a sentiment analysis to the whole dataset and specific topics in further subheadings.
4.3.1. Overall Sentiment of Merged Dataset
We used the VADER rule-based approach. It assesses the sentiment of a text by assigning a polarity score to each word, indicating whether it conveys positivity, negativity, or neutrality. We aggregated these individual scores to compute the overall sentiment score for the entire text [52]. VADER assigns a polarity score within the range of −1 to 1 for a given text. If the score is equal to or less than −0.05, we categorize the sentence as negative. Conversely, if the score is equal to or greater than 0.05, we consider the sentence positive, as illustrated in Table 3. Notably, VADER’s exceptional capability lies in its proficiency in grasping context [1].
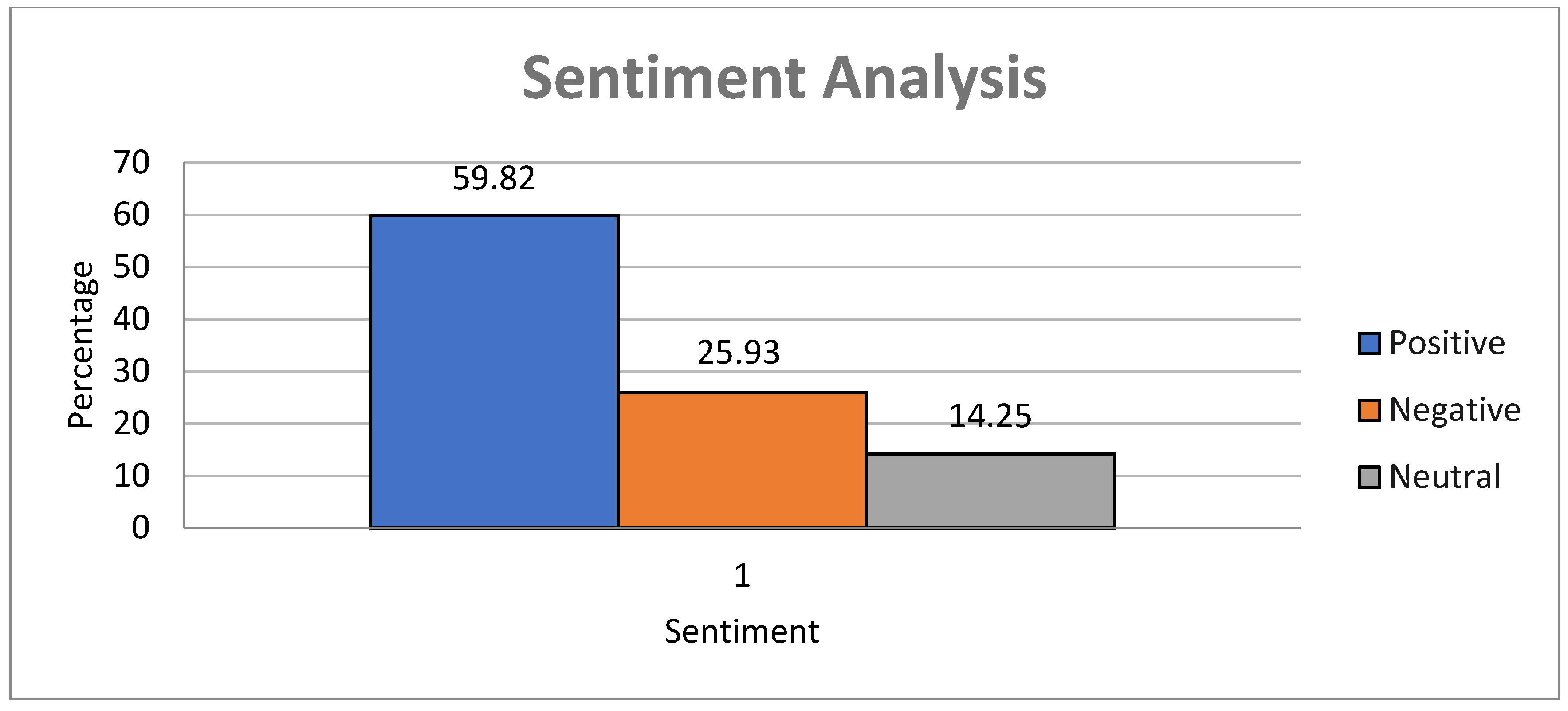
We used VADER to label the merged dataset of Indian P2P lending applications, as shown in Figure 3. We inferred from the majority of user reviews that they hold a favorable sentiment toward these applications.
4.3.2. Overall Sentiment of Apps
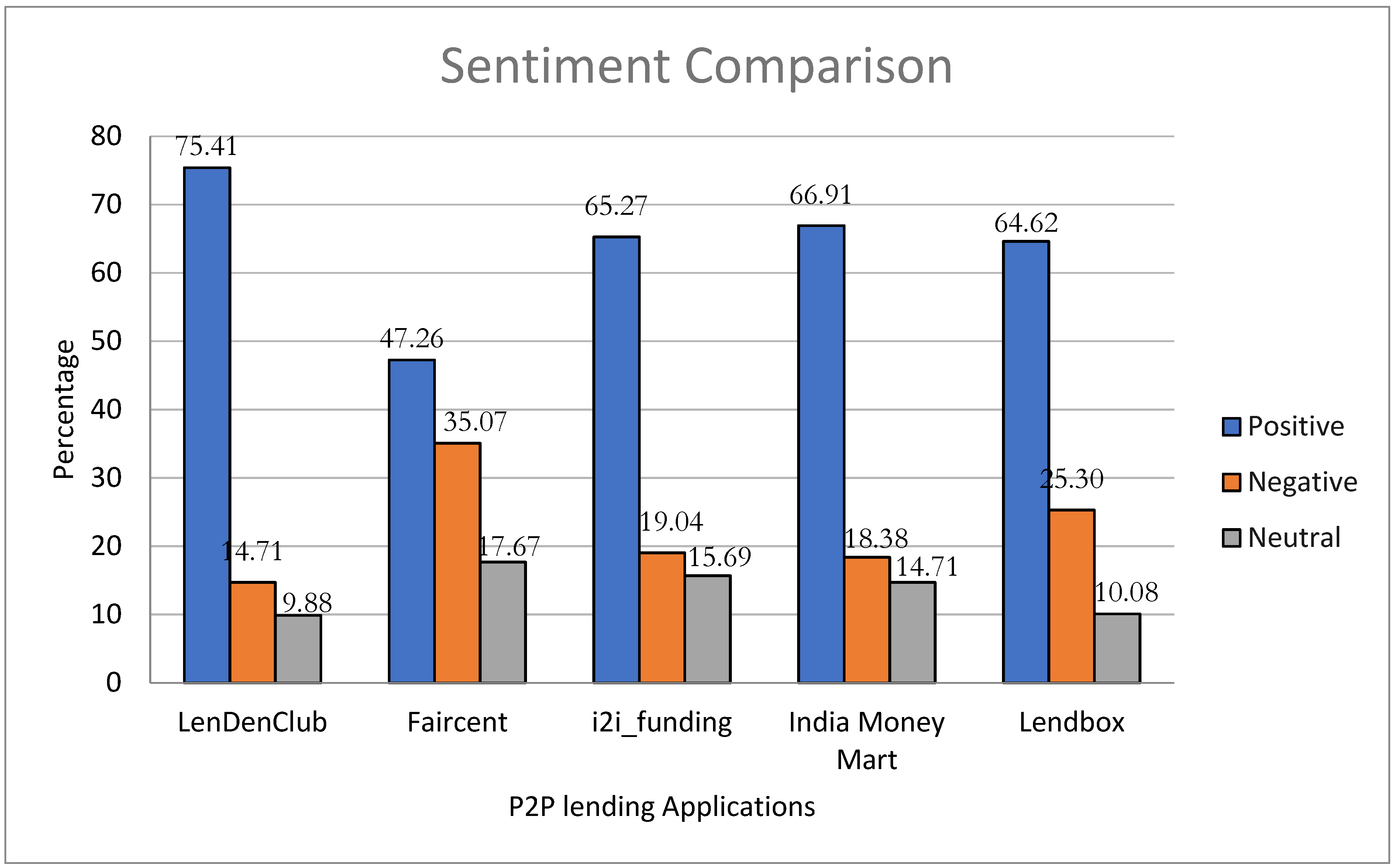
To gain a better understanding of which app has a greater share of a specific sentiment, we generated a comparative chart for all five apps, depicted in Figure 4. The data show that i2i funding, India Money Mart, and Lendbox had a similar proportion of positive reviews: 65.27%, 66.91%, and 64.62%, respectively. Faircent received a lower percentage of positive reviews (47.26%), and LenDenClub received the highest percentage of positive feedback (75.41%). Conversely, among all the P2P lending apps, Faircent received a higher percentage of negative reviews (35.07%).
4.3.3. Topic-Based Sentiment Analysis
We also conducted a sentiment analysis on particular topics identified through topic modeling. Such an analysis can be useful to app developers and prospective users for better decision making.
Overall Topic-Based Sentiment Analysis
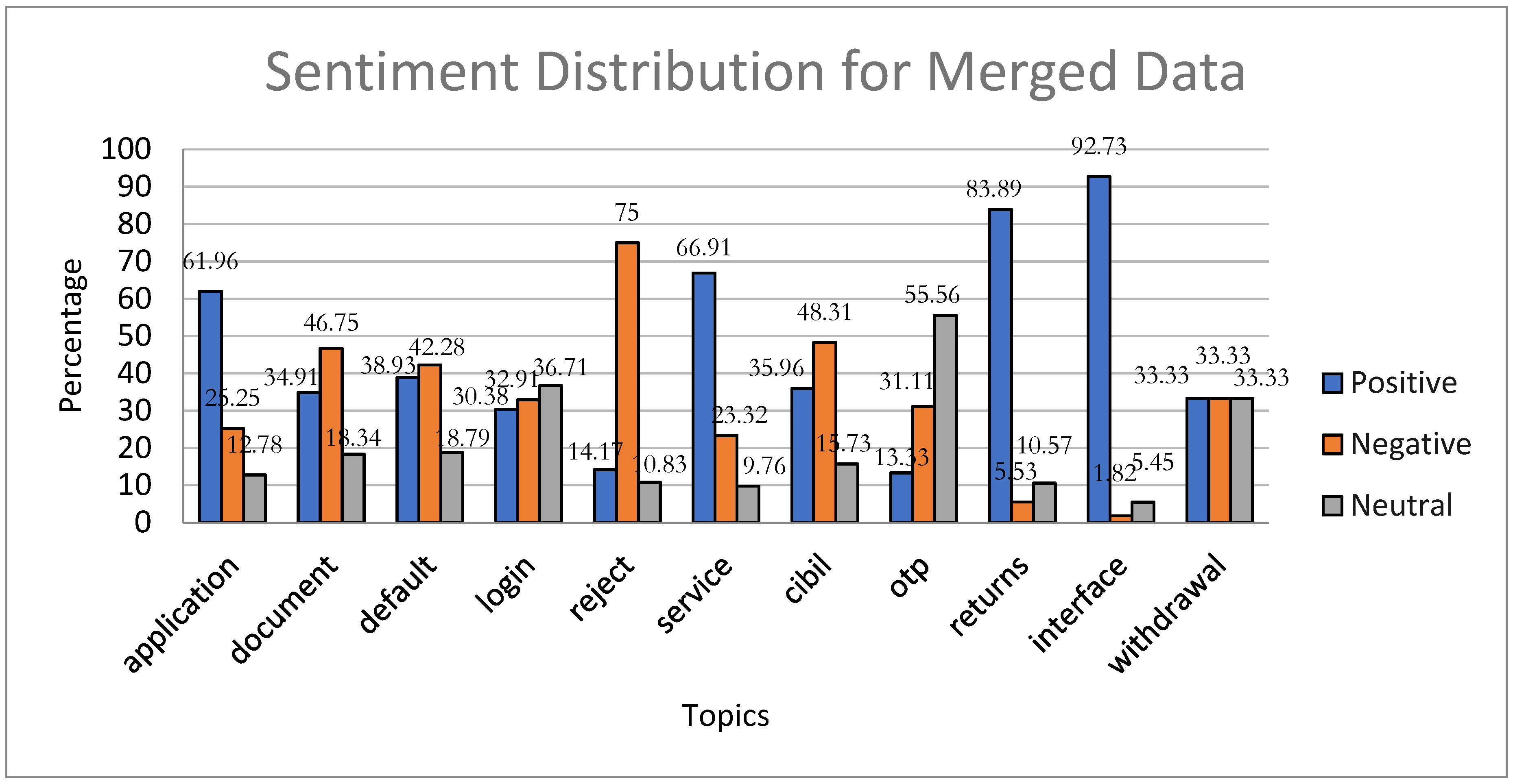
We assessed all topics for three sentiments (positive, negative, and neutral), using VADER, as shown in Figure 5. The analysis reveals that users expressed higher levels of positivity toward topics like interface (92.73%), returns (83.89%), service (66.91%), and application (61.96%) compared to other sentiments. Conversely, topics such as reject (75.76%), CIBIL (48.31%), document (46.75%), and default (42.28%) elicit more negative feedback. Users expressed a more neutral sentiment for topics like OTP (55.56%) and Login (36.71%). However, drawing a definitive conclusion for the topic of withdrawal is difficult because it gets an equal proportion (33.33%) of all three types of sentiments.
Topic Sentiments for Individual Apps
In this segment, we provide a topic-based sentiment analysis of each P2P lending app. It helps to classify the apps based on various features per user sentiment. Furthermore, this analysis identifies drawbacks in the apps that need improvements.
- (a)
- Topic sentiment analysis for LenDenClub
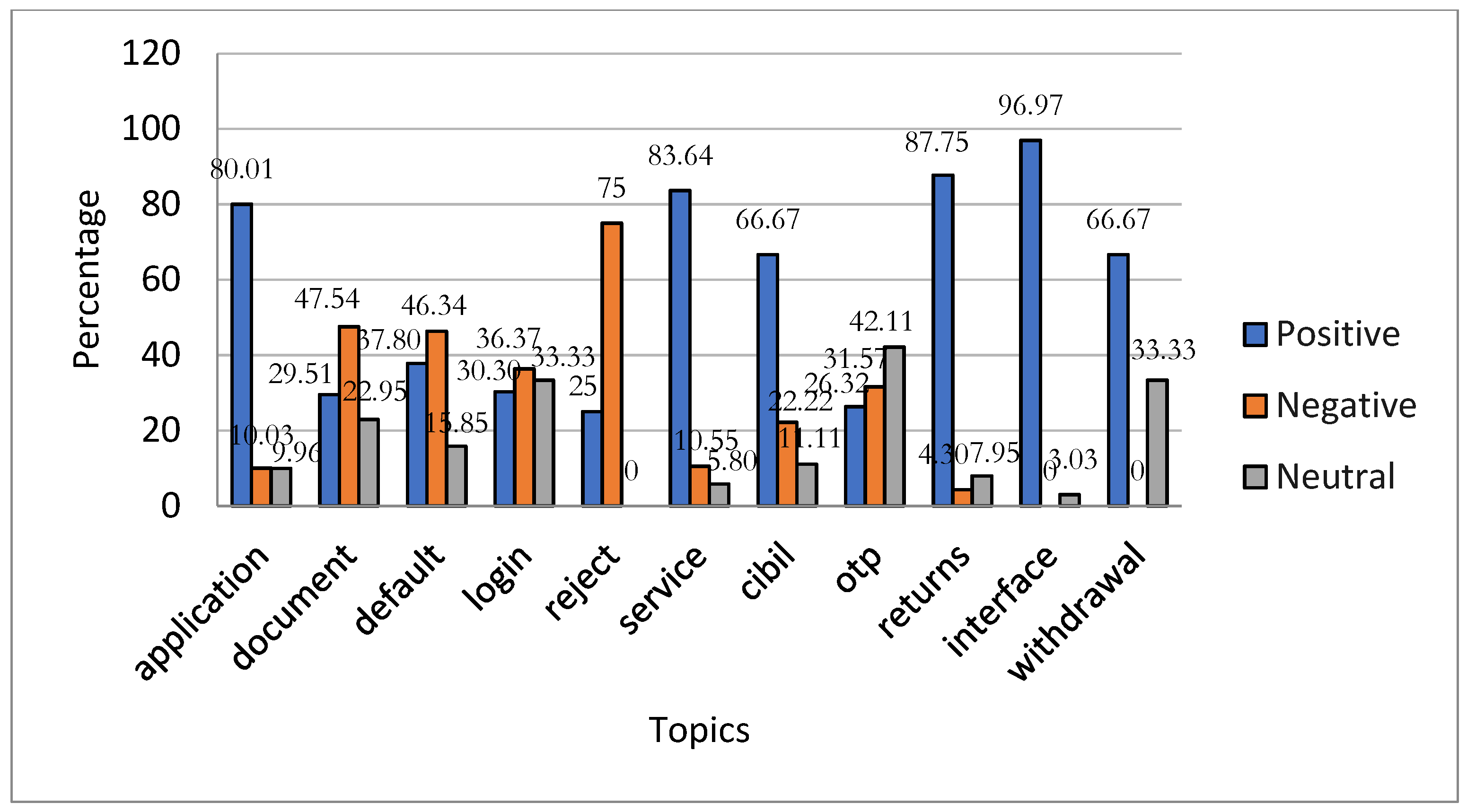
Figure 6 demonstrates that LenDenClub received more positive responses than negative or neutral ones across various topics, including its interface (96.97%), returns (87.75%), service (83.64%), application (80.01%), CIBIL (66.67%), and withdrawal (66.67%). Conversely, topics like reject (75%), document (47.54%), default (46.34%), and login (36.37%) obtained a higher proportion of negative sentiment reviews.
- (b)
- Topic sentiment analysis for Faircent
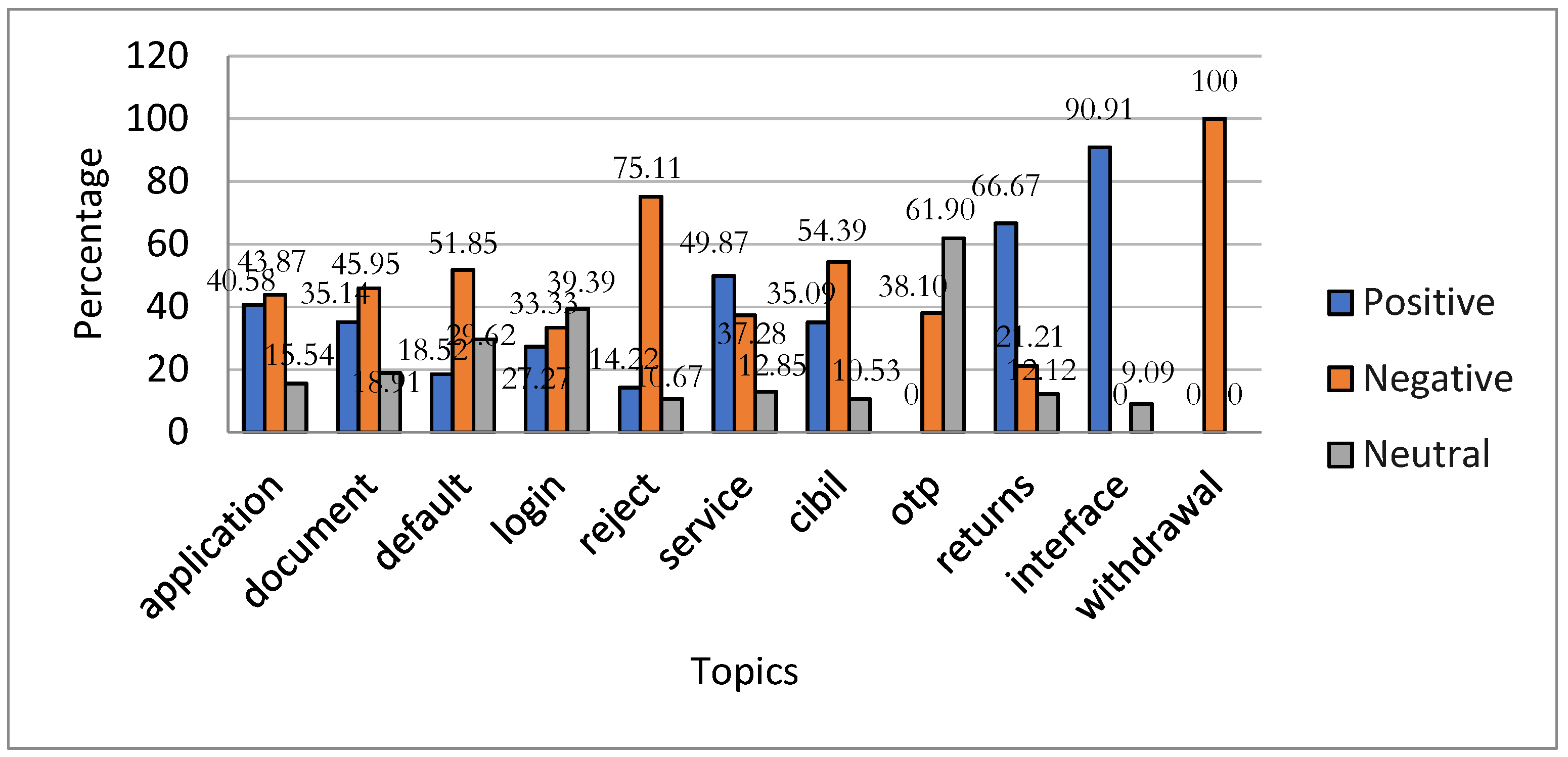
Figure 7 reveals that Faircent received more positive responses concerning its interface (90.91%), returns (60.67%), and service (49.87%) than negative or neutral ones. However, respondents reported more issues with withdrawal (100.00%), reject (75.11%), default (51.85%), CIBIL (54.39%), document (45.95%), and application (43.87%). Additionally, users exhibited a neutral stance toward the OTP (61.90%) and login (39.39%) topics.
- (c)
- Topic sentiment analysis for i2i funding
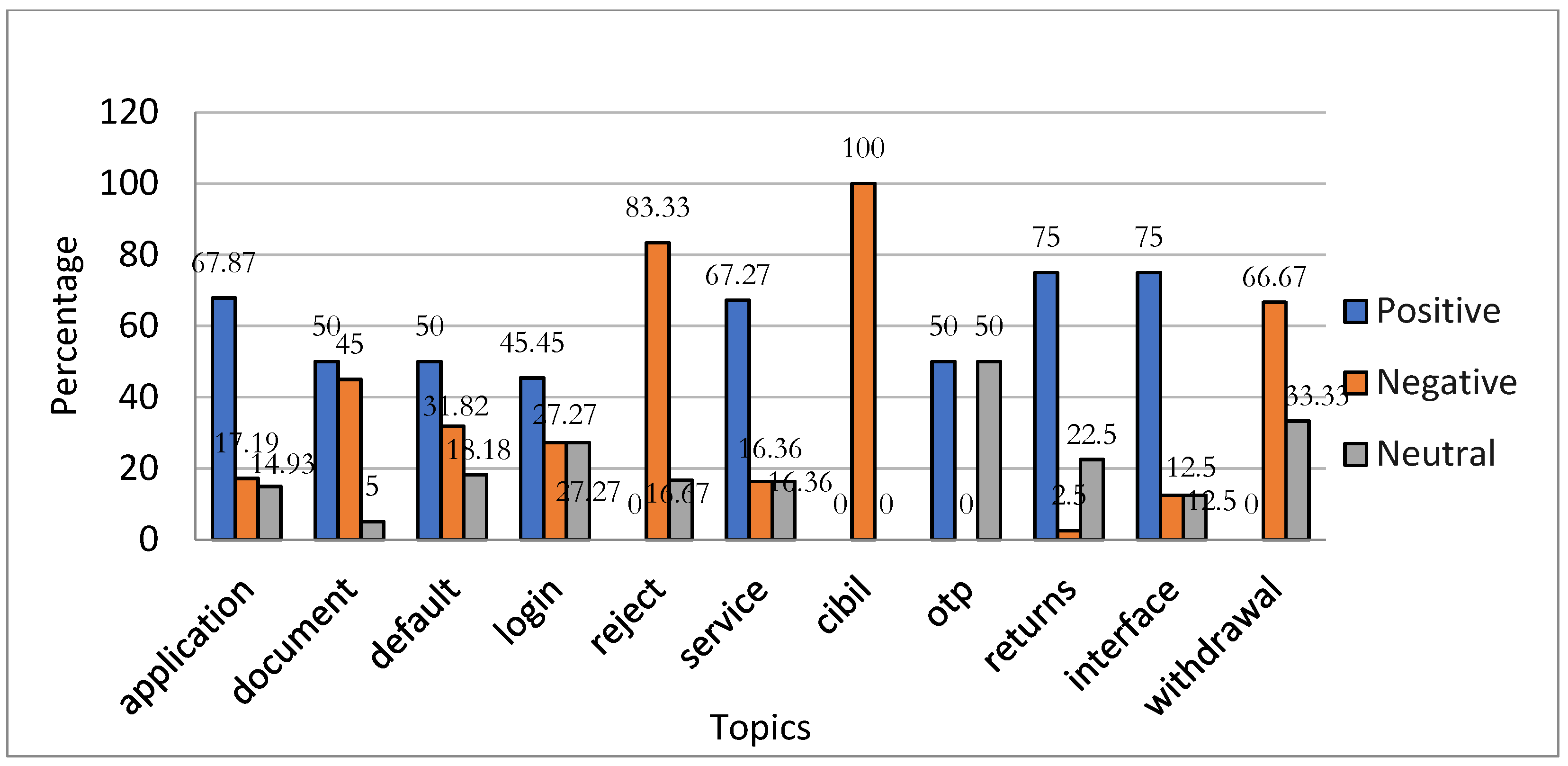
Figure 8 presents a topic-based sentiment analysis of the P2P lending app i2i funding. The findings show that i2i funding received the highest percentage of positive responses on seven topics as compared to other apps, with returns and interface tied at 75.00%, followed by application (67.87%) and service (67.27%). The highest percentage of negative sentiment reviews occurred for CIBIL (100.00%), reject (83.33%), and withdrawal (66.67%). Half the respondents (50.55%) were neutral on OTP.
- (d)
- Topic sentiment analysis for India Money Mart
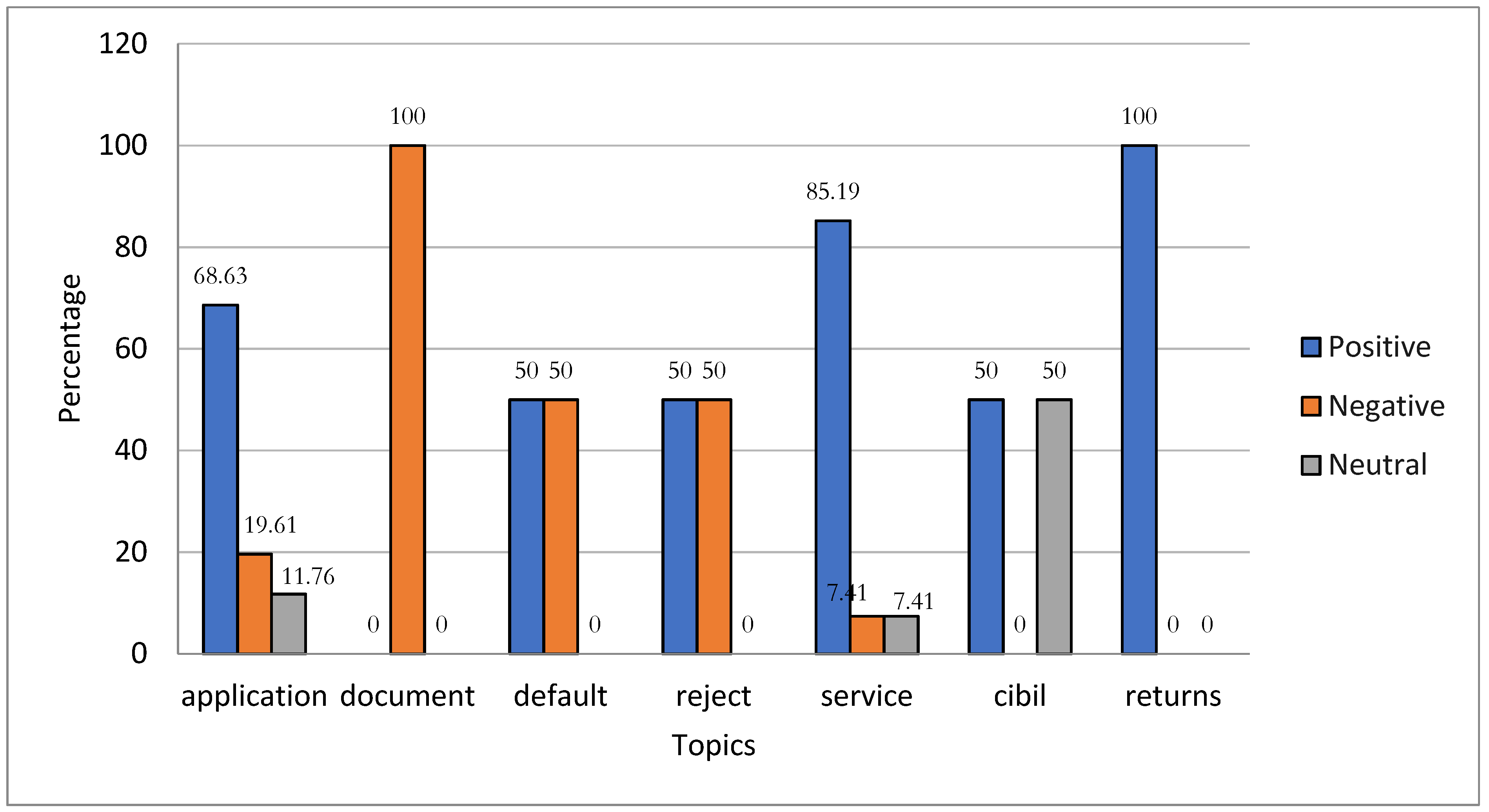
Figure 9 shows the topic-based sentiment analysis on India Money Mart discussions on topics such as login, OTP, interface, and withdrawal in the review’s dataset of the India Money Mart, which occurred due to the small dataset. The topics of default, reject, and CIBIL received an equal proportion of positive and negative reviews. The highest percentage of positive responses involved returns (100.00%), service (85.19%), and application (68.63%). The document received 100.00% negative reviews.
- (e)
- Topic sentiment analysis for Lendbox
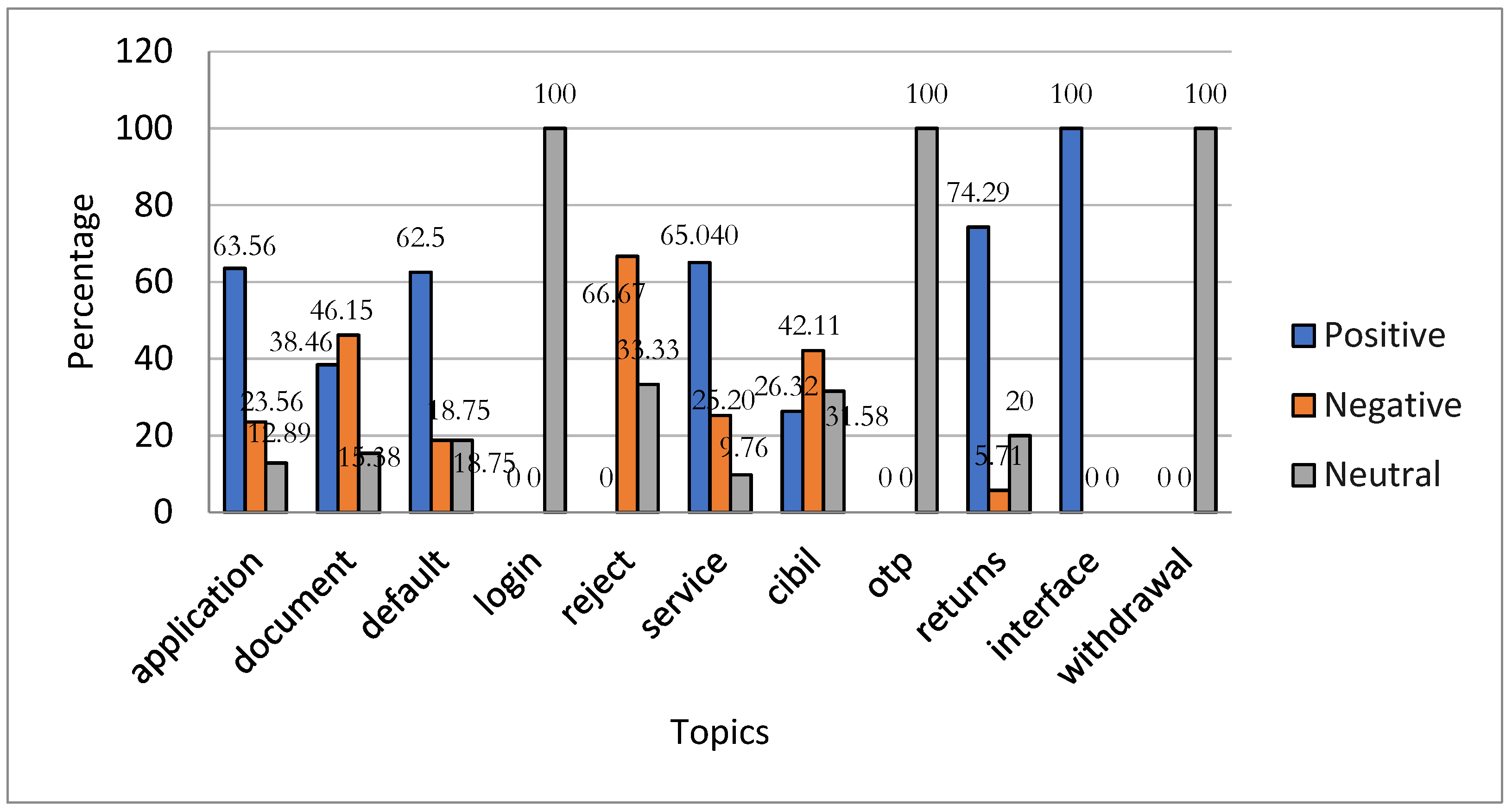
Figure 10 displays the sentiment distribution across various topics of the P2P lending app, Lendbox. The data indicate that Lendbox received a majority of positive feedback about its interface (100.00%), returns (74.29%), service (65.04%), application (63.56%), and default (62.5%). Conversely, topics with at least a 40% negative response involve reject (67.67%), document (46.15%), and CIBIL (42.11%), suggesting user dissatisfaction with these features of Lendbox. Additionally, users expressed neutral sentiments toward the login, OTP, and withdrawal topics, with 100.00% each.
4.4. Feature Extraction
We focused on preparing text for ML models by converting it into numerical data. We used three feature extraction methods: bag of words (BoW), TF-IDF, and hashing [2,14]. The BoW technique in natural language processing views the text as a set of isolated words, disregarding order or context. It establishes a vocabulary, tallies word frequencies, and produces a high-dimensional matrix [47].
TF-IDF, an alternative text representation technique, overcomes certain limitations of BoW. Unlike BoW, TF-IDF considers both word frequency in a document and its significance in the wider corpus context. TF gauges word frequency in a document, and IDF assesses a word’s uniqueness across the entire corpus. The TF-IDF score is the product of these factors, emphasizing words frequently appearing in a document but rarely in the corpus [3].
Unlike BoW and TF-IDF, which create a predefined vocabulary, hashing uses a hash function to map words directly to indices in a fixed-size array or vector. This process is called the “hashing trick.” Hashing is memory efficient and allows for fast computation, making it particularly useful when dealing with large datasets. However, it has limitations, such as the inability to perform the inverse transformation (i.e., retrieving the original words from the hash values) and the possibility of collisions. Consequently, each technique has its strengths and weaknesses. Therefore, we examined the performance of all the ML models with each feature extraction technique [2].
4.5. ML Algorithms for Prediction
We explored the potential of ML models for predicting the sentiment of forthcoming reviews. Such models provide entrepreneurs the chance to respond with counter-feedback, integrate suggestions, and address complaints to improve customer satisfaction. Sentiment prediction requires training ML algorithms based on current review sentiments. We already performed the labeling of customer reviews by using VADER and feature extraction for input into the ML models presented in Table 4. Therefore, based on the literature review, we compared the six ML models: Logistic Regression (LR), Random Forest (RF), XGBoost, Decision Tree (DT), Support Vector Machine (SVM), and K-Nearest Neighbor (KNN). These models enable a comprehensive assessment of different algorithmic approaches and are better suited for small datasets and interpretability in finance, as emphasized in the research of [27,34]. We used the best hyperparameter settings, which we determined through the fine-tuning process shown in Table 5.
4.6. Assessment of Prediction Model Performance
We assessed the performance of the ML model, using accuracy, precision, recall, and F1 score metrics, employing bag of words (BoW), TF-IDF, and hashing features. Each model’s performance ultimately depends on the dataset’s specific characteristics, so experimenting with different algorithms and evaluating their performance empirically is crucial. Table 6 shows the definitions and formulas for these performance metrics.
Table 7 showcases the outcomes of the ML models, using BoW features. LR and RF demonstrate an excellent performance, with both achieving an equivalently high accuracy rate of 0.92 and an F1 score of 0.93, respectively. By contrast, SVM exhibits a poor performance by using BoW, yielding an accuracy rate of 0.78 and an F1 score of 0.83.
Table 8 and Table 9 depict the results of the ML models employing TF-IDF and hashing features, respectively. The models’ performance is comparable to that of BoW, with LR and RF exhibiting strong performance. Notably, a significant improvement occurs in SVM’s performance, with an accuracy rate of 0.94 and an F1 score of 0.94 when using TF-IDF. Similarly, with hashing features, SVM achieved an accuracy of 0.93 and an F1 score of 0.94. Conversely, KNN experienced a notable drop in accuracy by 0.22 when using TF-IDF and a decrease of 0.12 in accuracy when employing hashing features.
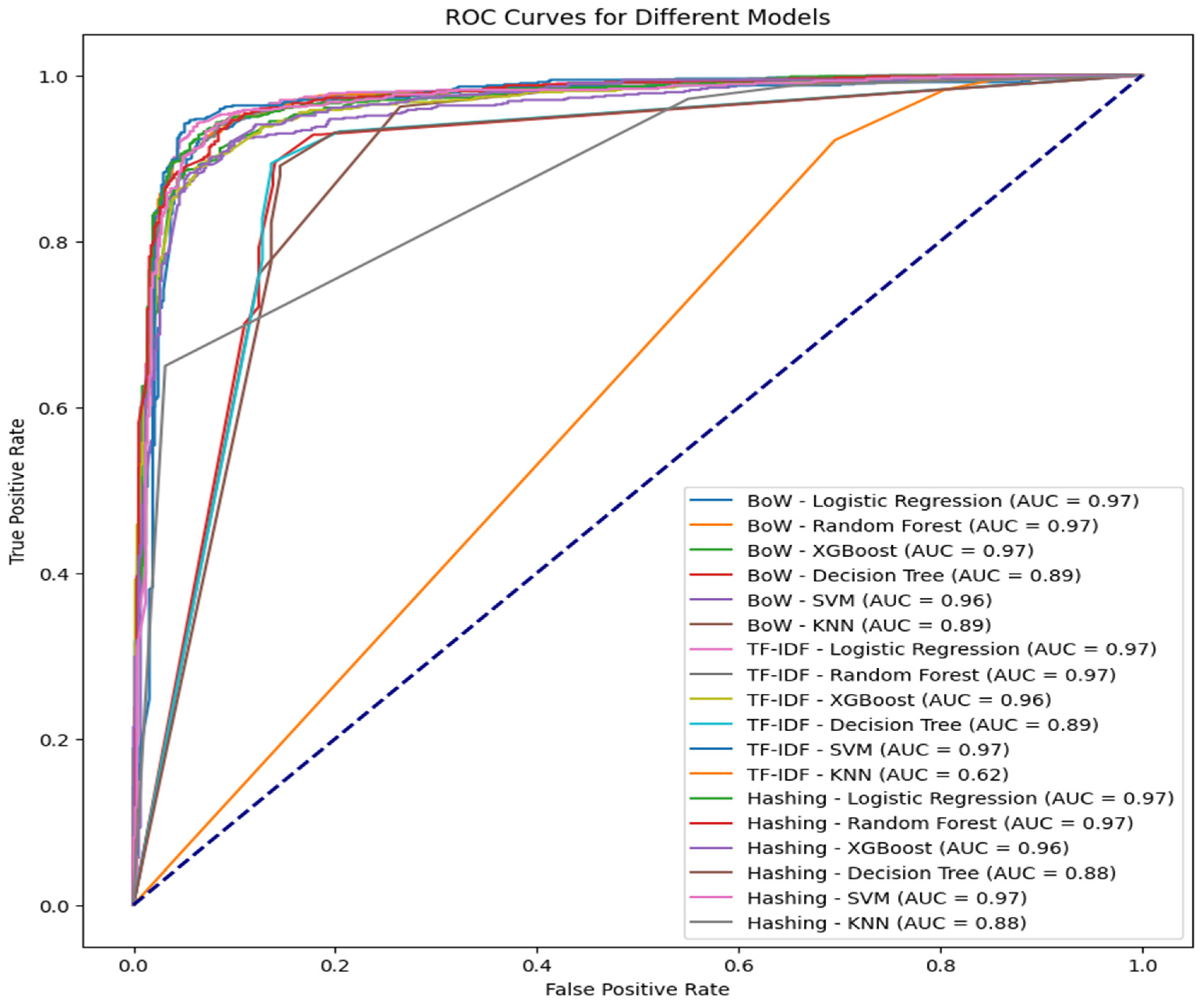
Moreover, the performance of classification models with different feature extraction techniques is graphically represented by the Receiver Operating Characteristic (ROC) curve shown in Figure 11. It illustrates the trade-off between accurately recognizing positive situations and wrongly classifying negative cases by plotting the true positive rate (sensitivity) against the false positive rate (1-specificity) for various threshold levels. The model’s overall performance is quantified by the Area Under the ROC Curve (AUC). The AUC is a measure of classification performance. It goes from 0 to 1, with 0.5 denoting random performance and 1 denoting perfect discrimination. Higher AOC values indicate a better discriminating capacity [53,54].
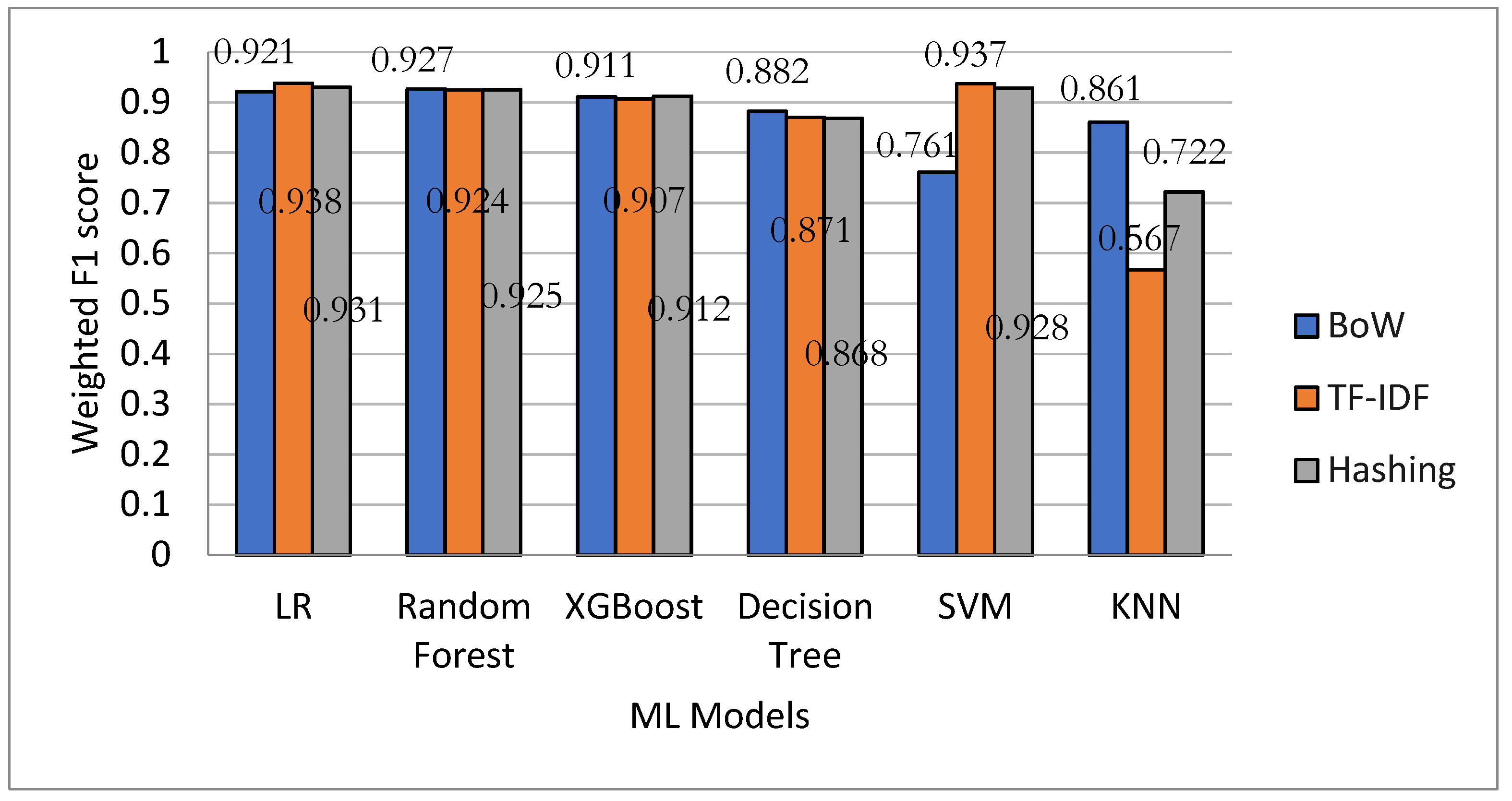
Figure 12 visually compares ML models using BoW, TF-IDF, and hashing features. This comparison is made using the weighted F1 score, which considers the class distribution by calculating the average F1 score for each class. This approach assigns greater significance to classes with a larger number of instances, resulting in a more equitable assessment of the model’s performance. LR and RF performed well with each of the feature extraction techniques.
The explanation could be that LR is simple and efficient, performing effectively with linearly separable data and offering probabilities. On the other hand, Random Forest, an ensemble technique, enhances predictive accuracy and mitigates overfitting by amalgamating numerous Decision Trees. However, SVM, XGBoost, Decision Tree, and KNN may not yield comparable results due to considerations such as computational expenses, overfitting, variability, and class imbalances.
5. Discussion and Implications
We address our four RQs, with the primary outcome delving into the sentiments expressed over important topics discussed within user reviews of P2P lending applications. Regarding RQ1, we identified 11 topics using the LDA model. These topics encompass the following: (1) application, (2) service, (3) returns, (4) reject, (5) document, (6) default, (7) CIBIL, (8) login, (9) interface, (10) OTP, and (11) withdrawal. We observed that these topics represent both broad and specific aspects where users share their experiences, which may range from negative to positive.
RQ2 seeks to grasp user sentiments or feelings within the reviews, using VADER. We examined both the complete dataset and the topics derived from it. The findings revealed that the majority of user reviews expressed a positive sentiment toward these applications. Positive public perception is essential for attracting new users and investors. Platforms can leverage positive perceptions to build trust and a good reputation, while also addressing negative perceptions in order to mitigate risk and protect their brand. Our study revealed that users are particularly satisfied with the usefulness and ease of application, customer care, returns, and interfaces. However, some users expressed dissatisfaction with document verification, default rates, loan application rejections, and the impact on CIBIL scores. Knowing what features and functionalities users value most can help platforms allocate resources efficiently and prioritize improvements.
We also provided a classification to give potential users recommendations about P2P lending applications, considering both their overall reviews and specific topics, as outlined in RQ3. Table 10 compares all the applications using topic-based sentiment analysis for decision making. Among all the apps, LenDenClub obtains the highest percentage of positive sentiments, while Faircent receives the highest percentage of negative sentiments.
However, when examining specific topics, LenDenClub receives a higher proportion of positive responses for returns (87.75%), service (83.64%), application (80.01%), CIBIL (66.67%), and withdrawals (66.67%) as compared to other apps. However, improvement is needed in such topics as reject (75.00%), document (47.54%), default (46.34%), and login (36.36%). Although India Money Mart obtains a higher percentage of positive reviews in returns (100.00%) and service (85.00%) than LenDenClub, we cannot generalize due to its smaller dataset.
Users are also satisfied with the interface (100.00%) and default rate (62.50%) of Lendbox, as it obtains a higher percentage of positive reviews than other apps. Faircent should work on such topics as withdrawal facility (100.00%), default rate (51.85%), and application (43.87%) because it receives a high proportion of negative reviews on these topics as compared to other apps. Additionally, i2i funding should work on the topic described as the impact of their loans on the CIBIL score (100.00%) of borrowers and reject (83.33%), as it gets higher negative reviews compared to other apps.
We addressed RQ4 by evaluating six ML algorithms—LR, RF, XGBoost, DT, SVM, and KNN—to make predictions about the sentiment conveyed in a given review. We concluded that LR and RF demonstrated a good performance across all three feature extraction techniques (BoW, TF-IDF, and hashing). Although SVM’s performance was poor with BoW, it demonstrated commendable accuracy and F1 scores when using TF-IDF and hashing. Furthermore, we outlined the implications for this field in Section 5.1 and Section 5.2.
5.1. Managerial Implications
Our findings provide valuable insights into existing P2P lending platforms, potential fintech companies, and traditional financial institutions already involved in or interested in this sector. The public perceives P2P lending as highly useful and convenient for borrowing or lending money, given the overwhelmingly positive sentiments expressed by users regarding these applications. This information can aid in strategic planning and business diversification.
However, our topic-based sentiment analysis, as detailed in Table 10, reveals that each application has strengths and weaknesses. Notably, certain topics, such as document, reject, and CIBIL, consistently receive negative reviews across various apps. Therefore, developers should focus on streamlining and making the document verification and application rejection processes more transparent and straightforward. Additionally, offering solutions to customers facing challenges with their CIBIL scores could enhance the user experience. It also helps policymakers to design appropriate regulations to protect consumers and foster a healthy P2P lending ecosystem. Therefore, it is necessary to establish a regulatory department that ensures the alignment of these platforms’ activities with legal regulations. Nevertheless, developers can use ML models like LR and RF to forecast sentiments in advance and offer strategic solutions. Furthermore, since the P2P lending concept in India is still in its early stages of development, these applications and platforms should intensify their promotional efforts to raise awareness.
5.2. Theoretical Contributions
Our study is the first attempt to employ topic modeling and sentiment analysis on the reviews of five Indian P2P lending applications to understand the public’s perception and experiences with them. Our analysis of the combined dataset and individual applications offers insights into overall and specific topics. We concluded that the public generally expresses favorable opinions about these applications, with LenDenClub receiving the highest positive feedback. Furthermore, topic-based sentiment analysis aids in identifying important topics and understanding reviewers’ opinions on them. Our study also offers a performance assessment of six ML models for predicting sentiments based on patterns observed in previous reviews. This information enables us to take potential actions from the customer support side.
6. Conclusions, Limitations, and Future Work
Our study aims to understand the requirements and perspectives of customers about different P2P lending applications in India, a market still in its early development phases. We concluded that performing topic modeling and sentiment analysis on user comments is an effective method for obtaining insights. As a result, we examined the reviews from five P2P lending applications: LenDenClub, Faircent, i2i funding, India Money Mart, and Lendbox, sourced from the Google Play Store.
We examined the consolidated dataset and a specific P2P lending application, aiming to encompass both an overarching view and intricate details. Using the topic modeling technique LDA, we identified 11 topics. Next, we conducted a sentiment analysis using VADER. It revealed that a majority of users expressed a positive sentiment toward these applications, with a particular affinity for LenDenClub.
We also performed a topic-based sentiment analysis to assist developers in identifying the strengths and weaknesses of their app and to aid potential customers in selecting an app based on specific attributes. Our evidence suggests that LenDenClub outperforms other apps in topics such as application, service, CIBIL, returns, and withdrawal. Users also expressed satisfaction with the interface and default rate of Lendbox, as it receives a higher percentage of positive reviews compared to others. In terms of document verification, i2i funding received the highest proportion of positive responses. Users tended to have a neutral sentiment toward topics like OTP and logging in across all the apps.
Similarly, regarding rejection, almost all the apps received a higher number of negative reviews, with i2i funding being the most criticized in this regard. We also assessed the performance of six ML models. LR achieved notable accuracy rates of 92%, 94%, and 93% while using three feature extraction techniques: BoW, TF-IDF, and hashing, respectively.
Although our study offers valuable insights, it has limitations. For example, our dataset has only 6755 reviews from the Google Play Store. However, the potential exists to incorporate a broader range of user-generated content from platforms like X, formerly Twitter. Researchers might also conduct descriptive and network analyses of P2P lending users, which were outside of our study’s scope. Nevertheless, we utilized user-generated comments, but researchers have the option to explore public perception toward P2P lending by gathering primary data through surveys.
Additionally, while we focused solely on five Indian P2P lending platforms with available applications, other platforms in India and beyond could be beneficial in subsequent research. However, as this business expands in India and other emerging countries, investigating how attitudes and tendencies shift over time as a result of shifting external circumstances would be worthwhile. Furthermore, the research could be expanded by conducting comparative analyses of public perceptions of other alternative financial models. We also compared the performance of six ML models. Future investigations could expand this scope by incorporating additional ML, deep learning, and ensemble models.
Overall, understanding public perception of P2P lending is a valuable tool for everyone involved in the ecosystem. It can inform decision making, shape policies, and ultimately contribute to a more sustainable and successful P2P lending market.
Author Contributions
S.K., conceptualization, validation, formal analysis, resources, data curation, interpretation, visualization, writing—original draft, and writing—review and editing; R.S., conceptualization, supervision, methodology, data curation, interpretation, writing—original draft, writing—review and editing, and project administration; H.K.B., supervision, formal analysis, interpretation, resources, data curation, and writing—review and editing; G.J., formal analysis, interpretation, data curation, interpretation, and writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The first author thanks the Ministry of Education, Government of India, for providing financial assistance (fellowship) during her Ph.D.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Nave, M.; Rita, P.; Guerreiro, J. A decision support system framework to track consumer sentiments in social media. J. Hosp. Mark. Manag. 2018, 27, 693–710. [Google Scholar] [CrossRef]
- Aslam, N.; Xia, K.; Rustam, F.; Hameed, A.; Ashraf, I. Using aspect-level sentiments for calling app recommendation with hybrid deeplearning models. Appl. Sci. 2022, 12, 8522. [Google Scholar] [CrossRef]
- Qureshi, A.A.; Ahmad, M.; Ullah, S.; Yasir, M.N.; Rustam, F.; Ashraf, I. Performance evaluation of machine learning models on large dataset of android applications reviews. Multimed. Tools Appl. 2023, 82, 37197–37219. [Google Scholar] [CrossRef] [PubMed]
- Singh, Y.; Suri, P.K. An empirical analysis of mobile learning app usage experience. Technol. Soc. 2022, 68, 101929. [Google Scholar] [CrossRef]
- Malik, H.; Shakshuki, E.M.; Yoo, W.S. Comparing mobile apps by identifying ‘Hot’ features. Futur. Gener. Comput. Syst. 2020, 107, 659–669. [Google Scholar] [CrossRef]
- Pawełoszek, I. Towards a smart city—The study of car-sharingsServices in Poland. Energies 2022, 15, 8459. [Google Scholar] [CrossRef]
- Xiao, G.; Tu, G.; Zheng, L.; Zhou, T.; Li, X.; Ahmed, S.H.; Jiang, D. Multimodality Sentiment Analysis in Social Internet of Things Based on Hierarchical Attentions and CSAT-TCN with MBM Network. IEEE Internet Things J. 2021, 8, 12748–12757. [Google Scholar] [CrossRef]
- Chakrapani, K.; Kempanna, M.; Safa, M.I.; Kavitha, T.; Ramachandran, M.; Bhaskar, V.; Kumar, A. An enhanced exploration of sentimental analysis in health care. Wirel. Pers. Commun. 2023, 128, 901–922. [Google Scholar] [CrossRef]
- Shneor, R.; Zhao, L.; Flåten, B.T. Advances in Crowdfunding: Research and Practice; Palgrave Macmillan: Cham, Switzerland, 2020; ISBN 9783030463090. [Google Scholar]
- Yao, J.; Chen, J.; Wei, J.; Chen, Y.; Yang, S. The relationship between soft information in loan titles and online peer-to-peer lending: Evidence from RenRenDai platform. Electron. Commer. Res. 2019, 19, 111–129. [Google Scholar] [CrossRef]
- Larrimore, L.; Jiang, L.; Larrimore, J.; Markowitz, D.; Gorski, S. Peer to Peer lending: The relationship between language features, trustworthiness, and persuasion success. J. Appl. Commun. Res. 2011, 39, 19–37. [Google Scholar] [CrossRef]
- Ziegler, T.; Shneor, R.; Wenzlaff, K.; Wang, B.; Kim, J.; de Camargo Paes, F.F.; Suresh, K.; Zhang, B.Z.; Mammadova, L.; Adams, N. The global alternative finance market benchmarking report. SSRN Electron. J. 2021, 3771509. [Google Scholar] [CrossRef]
- Demir, T.; Mohammadi, A.; Shafi, K. Crowdfunding as gambling: Evidence from repeated natural experiments. J. Corp. Financ. 2021, 77, 101905. [Google Scholar] [CrossRef]
- Aslam, N.; Xia, K.; Rustam, F.; Lee, E.; Ashraf, I. Self voting classification model for online meeting app review sentiment analysis and topic modeling. PeerJ Comput. Sci. 2022, 8, e1141. [Google Scholar] [CrossRef] [PubMed]
- De Fontenay, A.B.; De Fontenay, E.B.; Pupillo, L.M. The economics of peer-to-peer. In Peer-to-Peer Video: Economics Policy, Culture Today’s New Mass Mediu; Springer: New York, NY, USA, 2008; pp. 43–91. [Google Scholar] [CrossRef]
- Milne, A.; Parboteeah, P. The Business Models and Economics of Peer-to-Peer Lending. SSRN Electron. J. 2016. [Google Scholar] [CrossRef]
- Khatri, P. An Overview of the Peer to Peer Lending Industry of India. Int. J. Bus. Manag. Invent. ISSN 2019, 8, 1–11. [Google Scholar] [CrossRef]
- Yum, H.; Lee, B.; Chae, M. From the wisdom of crowds to my own judgment in microfinance through online peer-to-peer lending platforms. Electron. Commer. Res. Appl. 2012, 11, 469–483. [Google Scholar] [CrossRef]
- Emekter, R.; Tu, Y.; Jirasakuldech, B.; Lu, M. Evaluating credit risk and loan performance in online Peer-to-Peer (P2P) lending. Appl. Econ. 2015, 47, 54–70. [Google Scholar] [CrossRef]
- Ma, B.; Zhou, Z.; Hu, F. Pricing mechanisms in the online Peer-to-Peer lending market. Electron. Commer. Res. Appl. 2017, 26, 119–130. [Google Scholar] [CrossRef]
- Rogers, C.; Clarke, C. Mainstreaming social finance: The regulation of the peer-to-peer lending marketplace in the United Kingdom. Br. J. Polit. Int. Relat. 2016, 18, 930–945. [Google Scholar] [CrossRef]
- Kothari, V.; Jethani, K. P2P Report | India & Global 2019-20. 2019, pp. 1–78. Available online: http://vinodkothari.com (accessed on 1 June 2022).
- Wan, Q.; Chen, D.; Shi, W. Online peer-to-peer lending decision making: Model development and testing. Soc. Behav. Pers 2016, 44, 117–130. [Google Scholar] [CrossRef]
- Septiani, H.L.D.; Sumarwan, U.; Yuliati, L.N.; Kirbrandoko, K. Understanding the factors driving farmers to adopt peer-to-peer lending sharing economy. Int. Rev. Manag. Mark. 2020, 10, 13–21. [Google Scholar] [CrossRef]
- Han, J.T.; Chen, Q.; Liu, J.G.; Luo, X.L.; Fan, W. The persuasion of borrowers’ voluntary information in peer to peer lending: An empirical study based on elaboration likelihood model. Comput. Hum. Behav. 2018, 78, 200–214. [Google Scholar] [CrossRef]
- Li, L.; Feng, Y.; Lv, Y.; Cong, X.; Fu, X.; Qi, J. automatically detecting peer-to-peer lending intermediary risk—Top management team profile textual features perspective. IEEE Access 2019, 7, 72551–72560. [Google Scholar] [CrossRef]
- Jiang, C.; Wang, Z.; Wang, R.; Ding, Y. Loan default prediction by combining soft information extracted from descriptive text in online peer-to-peer lending. Ann. Oper. Res. 2018, 266, 511–529. [Google Scholar] [CrossRef]
- Zwilling, M.; Klein, G.; Shtudiner, Z. Peer-to-peer lending platforms’ legitimacy in the eyes of the general public and lenders. Isr. Aff. 2020, 26, 854–874. [Google Scholar] [CrossRef]
- Wang, Z.; Jiang, C.; Zhao, H.; Ding, Y. Mining semantic soft factors for credit risk evaluation in peer-to-peer lending. J. Manag. Inf. Syst. 2020, 37, 282–308. [Google Scholar] [CrossRef]
- Wang, N.; Li, Q.; Liang, H.; Ye, T.; Ge, S. Understanding the importance of interaction between creators and backers in crowdfunding success. Electron. Commer. Res. Appl. 2018, 27, 106–117. [Google Scholar] [CrossRef]
- Jiang, C.; Han, R.; Xu, Q.; Liu, Y. The impact of soft information extracted from descriptive text on crowdfunding performance. Electron. Commer. Res. Appl. 2020, 43, 101002. [Google Scholar] [CrossRef]
- Yuan, X.; Wang, L.; Yin, X.; Wang, H. How text sentiment moderates the impact of motivational cues on crowdfunding campaigns. Financ. Innov. 2021, 7, 46. [Google Scholar] [CrossRef]
- Wang, W.; Guo, L.; Wu, Y.J. The merits of a sentiment analysis of antecedent comments for the prediction of online fundraising outcomes. Technol. Forecast. Soc. Change 2022, 174, 121070. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, K.; Wang, H.; Wu, Y.C.J. The impact of sentiment orientations on successful crowdfunding campaigns through text analytics. IET Softw. 2017, 11, 229–238. [Google Scholar] [CrossRef]
- Chen, X.; Ding, H.; Fang, S.; Chen, W. Predicting the Success of Internet Social Welfare Crowdfunding Based on Text Information. Appl. Sci. 2022, 12, 1572. [Google Scholar] [CrossRef]
- Eiband, M.; Völkel, S.T.; Buschek, D.; Cook, S.; Hussmann, H. A method and analysis to elicit user-reported problems in intelligent everyday applications. ACM Trans. Interact. Intell. Syst. 2020, 10, 1–27. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, Y.; Rao, Q.; Li, K.; Zhang, H. Exploring mutual information-based sentimental analysis with kernel-based extreme learning machine for stock prediction. Soft Comput. 2017, 21, 3193–3205. [Google Scholar] [CrossRef]
- Subramaniyaswamy, V.; Logesh, R.; Abejith, M.; Umasankar, S.; Umamakeswari, A. Sentiment analysis of tweets for estimating criticality and security of events. J. Organ. End User Comput. 2017, 29, 51–71. [Google Scholar] [CrossRef]
- Faralli, S.; Rittinghaus, S.; Samsami, N.; Distante, D.; Rocha, E. Emotional Intensity-based Success Prediction Model for Crowdfunded Campaigns. Inf. Process. Manag. 2021, 58, 102394. [Google Scholar] [CrossRef]
- Saura, J.R.; Reyes-Menéndez, A.; Dematos, N.; Correia, M.B. Identifying startups business opportunities from ugc on twitter chatting: An exploratory analysis. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 1929–1944. [Google Scholar] [CrossRef]
- Rathore, P.; Soni, J.; Prabakar, N.; Palaniswami, M.; Santi, P. Identifying groups of fake reviewers using a semisupervised approach. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1369–1378. [Google Scholar] [CrossRef]
- Sadiq, S.; Umer, M.; Ullah, S.; Mirjalili, S.; Rupapara, V.; Nappi, M. Discrepancy detection between actual user reviews and numeric ratings of Google App store using deep learning. Expert Syst. Appl. 2021, 181, 115111. [Google Scholar] [CrossRef]
- Peng, Y.; Li, Y.; Wei, L. Positive sentiment and the donation amount: Social norms in crowdfunding donations during the covid-19 pandemic. Front. Psychol. 2022, 13, 818510. [Google Scholar] [CrossRef]
- Fu, X.; Zhang, S.; Chen, J.; Ouyang, T.; Wu, J. A sentiment-aware trading volume prediction model for P2P market using LSTM. IEEE Access 2019, 7, 81934–81944. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Lajis, A.; Alam, M.M.; Rahmat, M.K.; Nasir, H.M.; Ahmad, H.; Al-Rakhami, M.S.; Al-Amri, A.; Albogamy, F.R. A deep neural network model for the detection and classification of emotions from textual content. Complexity 2022, 2022, 8221121. [Google Scholar] [CrossRef]
- Distante, D.; Faralli, S.; Rittinghaus, S.; Rosso, P.; Samsami, N. DomainSenticNet: An ontology and a methodology enabling domain-aware sentic computing. Cognit. Comput. 2022, 14, 62–77. [Google Scholar] [CrossRef] [PubMed]
- Kumari, S.; Memon, Z.A. Extracting feature requests from online reviews of travel industry. Acta Sci.-Technol. 2022, 44, 1. [Google Scholar] [CrossRef]
- Hatamian, M.; Serna, J.; Rannenberg, K. Revealing the unrevealed: Mining smartphone users privacy perception on app markets. Comput. Secur. 2019, 83, 332–353. [Google Scholar] [CrossRef]
- Crocco, E.; Giacosa, E.; Yahiaoui, D.; Culasso, F. Crowd inputs in reward-based and equity-based crowdfunding: A latent Dirichlet allocation approach on their potential for innovation. Eur. J. Innov. Manag. 2022. [Google Scholar] [CrossRef]
- Kannnan, S.; Gurusamy, V. Preprocessing techniques for text mining. Int. J. Comput. Sci. Commun. Netw. 2014, 5, 7–16. [Google Scholar]
- Alam, S.; Yao, N. The impact of preprocessing steps on the accuracy of machine learning algorithms in sentiment analysis. Comput. Math. Organ. Theory 2019, 25, 319–335. [Google Scholar] [CrossRef]
- Campbell, J.C.; Hindle, A.; Stroulia, E. Latent Dirichlet Allocation: Extracting Topics from Software Engineering Data. Art Sci. Anal. Softw. Data 2015, 3, 139–159. [Google Scholar] [CrossRef]
- Hutto, C.J.; Gilbert, E. VADER: A parsimonious rule-based model for sentiment analysis of social media text. Proc. Int. AAAI Conf. Web Soc. Media 2014, 8, 216–225. [Google Scholar] [CrossRef]
- Gigliarano, C.; Figini, S.; Muliere, P. Making classifier performance comparisons when ROC curves intersect. Comput. Stat. Data Anal. 2014, 77, 300–312. [Google Scholar] [CrossRef]
Figure 1.
An overview of the proposed approach, illustrating the sequence of the methodology used in our study.
Figure 1.
An overview of the proposed approach, illustrating the sequence of the methodology used in our study.

Figure 2.
Overview of the words that exhibit a relatively high frequency within the dataset.

Figure 3.
The sentiment distribution, according to percentage, of the merged dataset reviews.

Figure 4.
Sentiment comparison of the five apps based on sentiment distribution.

Figure 5.
Sentiment against topics. Topic-based sentiment analysis on the merged dataset.

Figure 6.
Topic-based sentiment analysis for LenDenClub.

Figure 7.
Topic-based sentiment analysis for Faircent.

Figure 8.
Topic-based sentiment analysis for i2i funding.

Figure 9.
Topic-based sentiment analysis for India Money Mart.

Figure 10.
Topic-based sentiment analysis for Lendbox.

Figure 11.
Receiver Operating Characteristic (ROC) curve illustrating the performance of classification models with various feature extraction techniques. This ROC curve visually displays how well classification models perform with different feature extraction techniques, aiding in the evaluation of their discrimination ability.
Figure 11.
Receiver Operating Characteristic (ROC) curve illustrating the performance of classification models with various feature extraction techniques. This ROC curve visually displays how well classification models perform with different feature extraction techniques, aiding in the evaluation of their discrimination ability.

Figure 12.
Comparison between model performance using BoW, TF-IDF, and hashing features based on a weighted F1 score.
Figure 12.
Comparison between model performance using BoW, TF-IDF, and hashing features based on a weighted F1 score.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Data summary—an overview of the dataset utilized in the study, where the company apps were ranked from the highest to the lowest based on the number of rows (feedback).
Table 1.
Data summary—an overview of the dataset utilized in the study, where the company apps were ranked from the highest to the lowest based on the number of rows (feedback).
| Company | Number of Rows (Feedback) | Feedback Date Ranges (Month, Day, and Year) |
|---|---|---|
| Faircent | 3323 | 21 November 2015 to 16 June 2023 |
| LenDenClub | 2226 | 4 October 2018 to 16 June 2023 |
| Lendbox | 578 | 9 June 2019 to 11 June 2023 |
| i2i funding | 480 | 5 December 2018 to 16 June 2023 |
| India Money Mart | 148 | 11 August 2017 to 2 May 2023 |
Table 2.
Details of the 11 main topics covered in the dataset.
| S. No. | Topic Name | Frequency | Topic Information |
|---|---|---|---|
| 1 | Application | 4445 | Overall experience in application usefulness and ease of use. |
| 2 | Document | 200 | Ease of document verification. |
| 3 | Default | 186 | Experience regarding borrowers’ default rate. |
| 4 | Login | 96 | Experience with logging into the app after logging out. |
| 5 | Reject | 265 | Loan application rejection and disapproval. |
| 6 | Service | 1196 | Response and behavior from the customer care and verification team. |
| 7 | CIBIL | 106 | Impact on CIBIL score after installing and using the application. |
| 8 | OTP | 51 | The overall impression of receiving OTP. |
| 9 | Returns | 443 | Experience regarding returns on investment. |
| 10 | Interface | 55 | Experience regarding the interface of an application. |
| 11 | Withdrawal | 14 | Experience regarding withdrawal of money. |
Table 3.
VADER score range—the range of polarity scores used to evaluate text sentiment.
| Sentiment | Score Range |
|---|---|
| Negative | Score ≤ −0.05 |
| Positive | Score ≥ 0.05 |
| Neutral | Score ≥ 0.05 and <0.05 |
Table 4.
The distribution of labeled datasets for both training and testing.
| Dataset | Positive | Negative | Neutral | Total Count |
|---|---|---|---|---|
| Training set | 2928 | 1102 | 1218 | 5248 |
| Testing set | 757 | 264 | 292 | 1313 |
| Total count | 3685 | 1366 | 1510 | 6561 |
Table 5.
ML model hyperparameter settings.
| Model | Hyperparameter | Hyperparameter Tuning |
|---|---|---|
| DT | max_depth = 100 | max_depth = {50 to 500} |
| RF | n_estimators = 100, max_depth = 100 | max_depth = {50 to 500}, n_estimators = {50 to 500} |
| KNN | n_neighbors = 3 | n_neighbors = {2 to 10} |
| XGBoost | n_estimator = 100, max_depth =100 Learning_rate = 0.8 | max_depth = (50 to 500), n_estimator = (50 to 500) Learning_rate = (0.0 to 1.0) |
| SVM | Kernel = poly, C = 2.0 | Kernel = {poly, linear, sigmoid}, C = {1.0 to 5.0} |
| LR | solver = liblinear, C = 2.0, multi_class = multinomial | kernel = {liblinear, sag, sagal), C = (1.0 to 5.0) |
Table 6.
Description of performance metrics utilized for comparing ML models.
| Performance Metrics | Definition | Formulas | Citations |
|---|---|---|---|
| Accuracy | Accuracy measures the proportion of correctly classified instances out of the total instances in a dataset, indicating the model’s overall predictive performance. | [2,37] | |
| Precision | Precision assesses the proportion of correctly identified positive instances out of all instances predicted to be positive by the model. | [2,5] | |
| Recall | Recall assesses the proportion of correctly identified positive instances out of all actual positive instances in the dataset. | [1,2] | |
| F1 Score | The F1 score is the harmonic mean of precision and recall, providing a balanced assessment of a model’s performance on a binary classification task. | [2,48] |
Table 7.
Performance outcomes of ML models employing the BoW feature extraction technique.
| Classifier | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Logistic Regression | 0.92 | 0.91 | 0.95 | 0.93 |
| Random Forest | 0.92 | 0.92 | 0.95 | 0.93 |
| XGBoost | 0.91 | 0.92 | 0.93 | 0.92 |
| Decision Tree | 0.88 | 0.90 | 0.89 | 0.89 |
| SVM | 0.78 | 0.72 | 0.98 | 0.83 |
| KNN | 0.86 | 0.83 | 0.96 | 0.89 |
Table 8.
Results of the ML models using the TF-IDF feature extraction technique.
| Classifier | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Logistic Regression | 0.94 | 0.95 | 0.94 | 0.95 |
| Random Forest | 0.93 | 0.93 | 0.94 | 0.94 |
| XGBoost | 0.91 | 0.93 | 0.91 | 0.92 |
| Decision Tree | 0.87 | 0.89 | 0.89 | 0.89 |
| SVM | 0.94 | 0.96 | 0.92 | 0.94 |
| KNN | 0.64 | 0.61 | 0.98 | 0.76 |
Table 9.
Results of the ML models using the hashing feature extraction technique.
| Classifier | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Logistic Regression | 0.93 | 0.94 | 0.94 | 0.94 |
| Random Forest | 0.92 | 0.92 | 0.94 | 0.93 |
| XGBoost | 0.91 | 0.91 | 0.94 | 0.92 |
| Decision Tree | 0.87 | 0.89 | 0.89 | 0.89 |
| SVM | 0.93 | 0.94 | 0.93 | 0.94 |
| KNN | 0.74 | 0.70 | 0.97 | 0.81 |
Table 10.
Topic-based sentiment analysis of P2P lending apps and their categorization—the predominant sentiment conveyed regarding particular topics across all applications.
Table 10.
Topic-based sentiment analysis of P2P lending apps and their categorization—the predominant sentiment conveyed regarding particular topics across all applications.
| Topics | LenDenClub | Faircent | i2i Funding | India Money Mart | Lendbox |
|---|---|---|---|---|---|
| Application | Good (80.01%) | Below average (43.87%) | Good (67.87%) | Good (68.63%) | Good (63.56%) |
| Document | Below average (47.54%) | Below average (45.95%) | Good (50.00%) | Below average (100.00%) | Below average (46.15%) |
| Default | Below average (46.34%) | Below average (51.85%) | Good (50.00%) | Inconclusive | Good (62.50%) |
| Login | Below average (36.36%) | Average (39.39%) | Good (45.45%) | NA | Average (100.00%) |
| Reject | Below average (75%) | Below average (75.11%) | Below average (83.33%) | Inconclusive | Below average (66.67%) |
| Service | Good (83.64%) | Good (49.87%) | Good (67.27%) | Good (85.00%) | Good (65.04%) |
| CIBIL | Good (66.67%) | Below average (54.39%) | Below average (100.00%) | Inconclusive | Below average (42.11%) |
| OTP | Average (42.11%) | Average (61.90%) | Inconclusive | NA | Average (100.00%) |
| Returns | Good (87.75%) | Good (66.67%) | Good (75.00%) | Good (100.00%) | Good (74.28%) |
| Interface | Good (96.97%) | Good (90.91%) | Good (75.00%) | NA | Good (100.00%) |
| Withdrawal | Good (66.67%) | Below average (100.00%) | Below average (66.67%) | NA | Average (100.00%) |
Notes: positive reviews % > negative and neutral reviews = Good; neutral reviews % > positive and Negative reviews = Average; negative reviews% > positive and neutral reviews = Below Average; not available = NA; and when reviews get equal types of sentiments = Inconclusive.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Khan, S.; Singh, R.; Baker, H.K.; Jain, G. Public Perception of Online P2P Lending Applications. J. Theor. Appl. Electron. Commer. Res. 2024, 19, 507-525. https://doi.org/10.3390/jtaer19010027
AMA Style
Khan S, Singh R, Baker HK, Jain G. Public Perception of Online P2P Lending Applications. Journal of Theoretical and Applied Electronic Commerce Research. 2024; 19(1):507-525. https://doi.org/10.3390/jtaer19010027
Chicago/Turabian StyleKhan, Sahiba, Ranjit Singh, H. Kent Baker, and Gomtesh Jain. 2024. "Public Perception of Online P2P Lending Applications" Journal of Theoretical and Applied Electronic Commerce Research 19, no. 1: 507-525. https://doi.org/10.3390/jtaer19010027