
Abstract
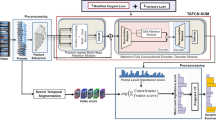
It is important to generate both diverse and representative video summary for massive videos. In this paper, a convolution neural network based on dual-stream attention mechanism(DA-ResNet) is designed to obtain candidate summary sequences for classroom scenes. DA-ResNet constructs a dual stream input of image frame sequence and optical flow frame sequence to enhance the expression ability. The network also embeds the attention mechanism into ResNet. On the other hand, the final video summary is obtained by removing redundant frames with the improved hash clustering algorithm. In this process, preprocessing is performed first to reduce computational complexity. And then hash clustering is used to retain the frame with the highest entropy value in each class, removing other similar frames. To verify its effectiveness in classroom scenes, we also created ClassVideo, a real dataset consisting of 45 videos from the normal teaching environment of our school. The results of the experiments show the competitiveness of the proposed method DA-ResNet outperforms the existing methods by about 8% in terms of the F-measure. Besides, the visual results also demonstrate its ability to produce classroom video summaries that are very close to the human preferences.











Similar content being viewed by others


Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Shambharkar PG, Goel R (2022) From video summarization to real time video summarization in smart cities and beyond: a survey. Front Big Data. https://doi.org/10.3389/fdata.2022.1106776
Li Z, Tang J, Wang X, Liu J, Lu H (2016) Multimedia news summarization in search. ACM Trans Intell Syst Technol (TIST) 7(3):1–20. https://doi.org/10.1145/2822907
Li Z, Tang J (2021) Semi-supervised local feature selection for data classification. Sci China Inf Sci 64(9):192108. https://doi.org/10.1007/s11432-020-3063-0
Li Z, Sun Y, Zhang L, Tang J (2021) CTNet: context-based tandem network for semantic segmentation. IEEE Trans Pattern Anal Mach Intell 44(12):9904–9917. https://doi.org/10.1109/TPAMI.2021.3132068
Kumar A, Singh N, Kumar P, Vijayvergia A, Kumar K (2017) A novel superpixel based color spatial feature for salient object detection. In: 2017 conference on information and communication technology (CICT). IEEE, pp 1–5. https://doi.org/10.1109/INFOCOMTECH.2017.8340630
Chen G, Chen Q, Long S, Zhu W, Yuan Z, Wu Y (2023) Quantum convolutional neural network for image classification. Pattern Anal Appl 26(2):655–667. https://doi.org/10.1007/s10044-022-01113-z
Zhang K, Chao W.-L, Sha F, Grauman K (2016) Video summarization with long short-term memory. In: Computer vision–ECCV 2016: 14th European conference, Amsterdam, The Netherlands, October 11–14, proceedings, Part VII 14. Springer, pp 766–782. https://doi.org/10.1007/978-3-319-46478-7_47
Fajtl J, Sokeh H.S, Argyriou V, Monekosso D, Remagnino P (2019) Summarizing videos with attention. In: Computer vision–ACCV 2018 workshops: 14th Asian conference on computer vision, Perth, Australia, December 2–6, 2018, revised selected papers 14. Springer, pp 39–54. https://doi.org/10.1007/978-3-030-21074-8_4
Zhang Y, Liu Y (2023) Video summarization via global feature difference optimization. Optoelectron Lett 19(9):570–576. https://doi.org/10.1007/s11801-023-2212-0
Li Z, Tang J, Zhang L, Yang J (2020) Weakly-supervised semantic guided hashing for social image retrieval. Int J Comput Vis 128:2265–2278. https://doi.org/10.1007/s11263-020-01331-0
Li W, Qi D, Zhang C, Guo J, Yao J (2020) Video summarization based on mutual information and entropy sliding window method. Entropy 22(11):1285. https://doi.org/10.3390/e22111285
Luo Y, Zhou H, Tan Q, Chen X, Yun M (2018) Key frame extraction of surveillance video based on moving object detection and image similarity. Pattern Recognit Image Anal 28:225–231. https://doi.org/10.1134/S1054661818020190
Wang F, Chen J, Liu F (2021) Keyframe generation method via improved clustering and silhouette coefficient for video summarization. J Web Eng 20:147–170. https://doi.org/10.13052/jwe1540-9589.2018
Li P, Tang C, Xu X (2021) Video summarization with a graph convolutional attention network. Front Inf Technol Electron Eng 22(6):902–913. https://doi.org/10.1631/FITEE.2000429
Kumar K, Shrimankar D. D, Singh N (2018) V-less: a video from linear event summaries. In: Proceedings of 2nd international conference on computer vision & image processing: CVIP 2017, vol 1. Springer, pp 385–395
Wang J, Wang W, Wang Z, Wang L, Feng D, Tan T (2019) Stacked memory network for video summarization. In: Proceedings of the 27th ACM international conference on multimedia, pp 836–844. https://doi.org/10.1145/3343031.3350992
Zhou K, Qiao Y, Xiang T (2018) Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward. In: Proceedings of the AAAI conference on artificial intelligence, vol 32. https://doi.org/10.1609/aaai.v32i1.12255
Kumar K, Shrimankar DD (2017) F-des: fast and deep event summarization. IEEE Trans Multimedia 20(2):323–334. https://doi.org/10.1109/TMM.2017.2741423
Solanki A, Bamrara R, Kumar K, Singh N (2020) Vedl: a novel video event searching technique using deep learning. In: Soft computing: theories and applications: proceedings of SoCTA 2018. Springer, pp 905–914
Kumar K, Shrimankar D. D, Singh N (2018) SOMES: an efficient SOM technique for event summarization in multi-view surveillance videos. In: Recent findings in intelligent computing techniques: proceedings of the 5th ICACNI 2017, vol 3. Springer, pp 383–389
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. Adv Neural Inf Process Syst. https://doi.org/10.48550/arXiv.1706.03762
Ji Z, Xiong K, Pang Y, Li X (2019) Video summarization with attention-based encoder-decoder networks. IEEE Trans Circuits Syst Video Technol 30(6):1709–1717. https://doi.org/10.1109/TCSVT.2019.2904996
Apostolidis E, Balaouras G, Mezaris V, Patras I (2022) Summarizing videos using concentrated attention and considering the uniqueness and diversity of the video frames. In: Proceedings of the 2022 international conference on multimedia retrieval, pp 407–415. https://doi.org/10.1145/3512527.3531404
Apostolidis E, Balaouras G, Mezaris V, Patras I (2021) Combining global and local attention with positional encoding for video summarization. In: 2021 IEEE international symposium on multimedia (ISM). IEEE, pp 226–234. https://doi.org/10.1109/ISM52913.2021.00045
Zeng H, Shu X, Wang Y, Wang Y, Zhang L, Pong T-C, Qu H (2020) Emotioncues: emotion-oriented visual summarization of classroom videos. IEEE Trans Visual Comput Graph 27(7):3168–3181. https://doi.org/10.1109/TVCG.2019.2963659
Kanafani H, Ghauri J.A, Hakimov S, Ewerth R (2021) Unsupervised video summarization via multi-source features. In: Proceedings of the 2021 international conference on multimedia retrieval, pp 466–470. https://doi.org/10.1145/3460426.3463597
Xu W, Zheng H, Yang Z, Yang Y (2021) Micro-expression recognition base on optical flow features and improved mobilenetv2. KSII Trans Internet Inf Syst. https://doi.org/10.3837/tiis.2021.06.002
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778. https://doi.org/10.1109/CVPR.2016.90
Woo S, Park J, Lee J-Y, Kweon IS (2018) Cbam: convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV), pp 3–19. https://doi.org/10.48550/arXiv.1807.06521
Lucas BD, Kanade T (1981) An iterative image registration technique with an application to stereo vision. In: IJCAI’81: 7th international joint conference on artificial intelligence, vol 2, pp 674–679
Potapov D, Douze M, Harchaoui Z, Schmid C (2014) Category-specific video summarization. In: Computer vision–ECCV 2014: 13th European conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VI 13. Springer, pp 540–555. https://doi.org/10.1007/978-3-319-10599-4_35
Song Y, Vallmitjana J, Stent A, Jaimes A (2015) Tvsum: summarizing web videos using titles. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5179–5187. https://doi.org/10.1109/CVPR.2015.7299154
Gygli M, Grabner H, Riemenschneider H, Van Gool L (2014) Creating summaries from user videos. In: Computer vision–ECCV 2014: 13th European conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VII 13. Springer, pp 505–520
Otani M, Nakashima Y, Rahtu E, Heikkila J (2019) Rethinking the evaluation of video summaries. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 7596–7604. https://doi.org/10.1109/CVPR.2019.00778
Zhu W, Lu J, Li J, Zhou J (2020) Dsnet: a flexible detect-to-summarize network for video summarization. IEEE Trans Image Process 30:948–962. https://doi.org/10.1109/TIP.2020.3039886
Chen Z, Chen P, Shen J (2021) Model of video summarization integrating GRU and non-maximum suppressi. Comput Sci Appl 11:604. https://doi.org/10.12677/CSA.2021.113062
De Avila SEF, Lopes APB, Luz A Jr, Albuquerque Araújo A (2011) VSUMM: a mechanism designed to produce static video summaries and a novel evaluation method. Pattern Recogn Lett 32(1):56–68. https://doi.org/10.1016/j.patrec.2010.08.004
Jadon S, Jasim M (2020) Unsupervised video summarization framework using keyframe extraction and video skimming. In: 2020 IEEE 5th international conference on computing communication and automation (ICCCA). IEEE, pp 140–145. https://doi.org/10.1109/ICCCA49541.2020.9250764
Naveen Kumar G, Reddy V (2020) Detection of shot boundaries and extraction of key frames for video retrieval. Int J Knowle-Based Intell Eng Syst 24(1):11–17. https://doi.org/10.3233/KES-200024
Author information
Authors and Affiliations
Contributions
Yuxiang Wu and Tianpan Chen are primarily accountable for experimental implementation and writing the full-text manuscript. Xiaoyan Wang and Yan Dou are mainly responsible for the architectural design and content review of the full-text manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no confict of interest.
Consent for publication
All authors agree with the content and give explicit consent to submit.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wu, Y., Wang, X., Chen, T. et al. DA-ResNet: dual-stream ResNet with attention mechanism for classroom video summary. Pattern Anal Applic 27, 32 (2024). https://doi.org/10.1007/s10044-024-01256-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10044-024-01256-1