
Abstract
Multimodal sentiment recognition has obtained increasing attention in recent years due to its potential to improve sentiment recognition accuracy by integrating information from multiple modalities. However, the heterogeneity issue caused by the differences in modalities poses a significant challenge for multimodal sentiment recognition. In this paper, we propose a novel framework, Cross-Modal Contrastive Learning (CMCL), which integrates multiple contrastive learning methods and multimodal data augmentation to address the heterogeneity issue. Specifically, we establish a cross-modal contrastive learning framework by leveraging diversity contrastive learning, consistency contrastive learning and sample-level contrastive learning. Through diversity contrastive learning, we constrain modality features to different feature spaces, capturing the complementary nature of modality-specific features. Additionally, through consistency contrastive learning, we map the representations of different modalities into a shared feature space, capturing the consistency of modality-specific features. We also introduce two data augmentation techniques, namely random noise and modal combination, to improve the model’s robustness. The experimental results show that our approach achieves state-of-the-art performance on three benchmark datasets and outperforms the existing baseline models. Our work demonstrates the effectiveness of cross-modal contrastive learning and data augmentation in multimodal sentiment recognition, and provides valuable insights for future research in this area.
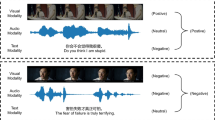
Graphical abstract







Similar content being viewed by others


Data availability
The data used in this study are sourced from a publicly available dataset. The dataset can be accessed at the following URL: https://drive.google.com/drive/folders/1A2S4pqCHryGmiqnNSPLv7rEg63WvjCSk.
References
Gandhi A, Adhvaryu K, Poria S, Cambria E, Hussain A (2023) Multimodal sentiment analysis: a systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions. Inform Fusion 91:424–444. https://doi.org/10.1016/j.inffus.2022.09.025
Chen T, Hong R, Guo Y, Hao S, Hu B (2022) MS2-GNN: Exploring GNN-based multimodal fusion network for depression detection. IEEE Trans Cybern 1–11. https://doi.org/10.1109/TCYB.2022.3197127
Tsai Y-HH, Bai S, Liang PP, Kolter JZ, Morency L-P, Salakhutdinov R (2019) Multimodal transformer for unaligned multimodal language sequences. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, pp. 6558–6569. https://doi.org/10.18653/v1/P19-1656
Zhang C, Yang Z, He X, Deng L (2020) Multimodal Intelligence: representation learning, information fusion, and applications. IEEE J Sel Top Signal Process 14:478–493. https://doi.org/10.1109/JSTSP.2020.2987728
Han W, Chen H, Gelbukh A, Zadeh A, Morency L, Poria S (2021) Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis. In: Proceedings of the 2021 International Conference on Multimodal Interaction (ICMI ‘21). Association for Computing Machinery, pp 6–15
Grill J-B, Strub F, Altché F, Tallec C, Richemond PH, Buchatskaya E et al (2020) Bootstrap your own latent a new approach to self-supervised learning. In: Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS), pp 21271 – 21284
Chen C, Hong H, Guo J, Song B (2023) Inter-intra modal representation augmentation with trimodal collaborative disentanglement network for multimodal sentiment analysis. IEEE/ACM Trans Audio Speech Lang Process 31:1476–1488. https://doi.org/10.1109/TASLP.2023.3263801
Mai S, Hu H, Xing S (2020) Modality to modality translation: an adversarial representation learning and graph fusion network for multimodal fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, vol 34, pp 164–172
Pham H, Liang PP, Manzini T, Morency L-P, Póczos B (2019) Found in translation: Learning robust joint representations by cyclic translations between modalities. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 33, pp 6892–6899
Wang D, Liu S, Wang Q, Tian Y, He L, Gao X (2022) Cross-modal enhancement network for multimodal sentiment analysis. IEEE Trans Multimedia 1–13. https://doi.org/10.1109/TMM.2022.3183830
Wang D, Guo X, Tian Y, Liu J, He L, Luo X (2023) TETFN: a text enhanced transformer fusion network for multimodal sentiment analysis. Pattern Recogn 136:109259. https://doi.org/10.1016/j.patcog.2022.109259
Huang C, Zhang J, Wu X, Wang Y, Li M, Huang X (2023) TeFNA: text-centered fusion network with crossmodal attention for multimodal sentiment analysis. Knowl Based Syst 269:110502. https://doi.org/10.1016/j.knosys.2023.110502
Liu Y, Fan Q, Zhang S, Dong H, Funkhouser T, Yi L (2021) Contrastive multimodal fusion with TupleInfoNCE. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp 734–743
Yang L, Wu Z, Hong J, Long J (2023) MCL: a contrastive learning method for multimodal data fusion in violence detection. IEEE Signal Process Lett 30:408–412. https://doi.org/10.1109/LSP.2022.3227818
Devlin J, Chang M-W, Lee K, Toutanova K (2019) BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Minneapolis, pp 4171–4186. https://aclanthology.org/N19-1423.pdf. Accessed May 2023
McFee B, Raffel C, Liang D, Ellis D, McVicar M, Battenberg E, Nieto O (2015) Librosa: Audio and music signal analysis in python. Presented Python Sci Conf Austin Tex. https://doi.org/10.25080/Majora-7b98e3ed-003
Zhang K, Zhang Z, Li Z, Qiao Y (2016) Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process Lett 23:1499–1503. https://doi.org/10.1109/LSP.2016.2603342
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need. In: Advances in neural information processing systems, pp 5998–6008. https://proceedings.neurips.cc/paper/7181-attention-is-all. Accessed May 2023
Han W, Chen H, Poria S (2021) : Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, pp. 9180–9192. https://doi.org/10.18653/v1/2021.emnlp-main.723
Hazarika D, Zimmermann R, Poria S (2020) MISA: Modality-invariant and -specific representations for multimodal sentiment analysis. In: Proceedings of the 28th ACM International Conference on Multimedia. ACM, Seattle, pp 1122–1131. https://doi.org/10.1145/3394171.3413678
Yu W, Xu H, Yuan Z, Wu J (2021) Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis. AAAI 35:10790–10797. https://doi.org/10.1609/aaai.v35i12.17289
Zhang Q, Shi L, Liu P, Zhu Z, Xu L (2022) ICDN: integrating consistency and difference networks by transformer for multimodal sentiment analysis. Appl Intell. https://doi.org/10.1007/s10489-022-03343-4
Mai S, Zeng Y, Zheng S, Hu H (2023) Hybrid contrastive learning of tri-modal representation for multimodal sentiment analysis. IEEE Trans Affect Comput 14(3):2276–2289. https://doi.org/10.1109/TAFFC.2022.3172360
Chen T, Kornblith S, Norouzi M, Hinton G (2020) A simple framework for contrastive learning of visual representations. In: Proceedings of the 37th International Conference on Machine Learning (ICML), pp 1597 – 1607
Caron M, Misra I, Mairal J, Goyal P, Bojanowski P, Joulin A (2020) Unsupervised learning of visual features by contrasting cluster assignments. In: Proceedings of the 34th International Conference on Neural Information Processing Systems, pp 9912 – 9924
Wang H, Li X, Ren Z, Wang M, Ma C (2023) Multimodal sentiment analysis representations learning via contrastive learning with condense attention fusion. Sensors 23:2679. https://doi.org/10.3390/s23052679
Zolfaghari M, Zhu Y, Gehler P, Brox T (2021) CrossCLR: Cross-modal contrastive learning for multi-modal video representations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp 1450–1459
Quan Z, Sun T, Su M, Wei J, Zhang X, Zhong S (2022) Multimodal sentiment analysis based on nonverbal representation optimization network and contrastive interaction learning. In: 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, Prague, pp 3086–3091. https://doi.org/10.1109/SMC53654.2022.9945514
Xu N, Mao W, Wei P, Zeng D (2021) MDA: Multimodal data augmentation framework for boosting performance on sentiment/emotion classification tasks. IEEE Intell Syst 36:3–12. https://doi.org/10.1109/MIS.2020.3026715
Huang J, Li Y, Tao J, Lian Z, Niu M, Yang M (2018) Multimodal continuous emotion recognition with data augmentation using recurrent neural networks. In: Proceedings of the 2018 on Audio/Visual Emotion Challenge and Workshop (AVEC’18). Association for Computing Machinery, pp 57–64. https://doi.org/10.1145/3266302.3266304
Oneata D, Cucu H (2022) Improving multimodal speech recognition by data augmentation and speech representations. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, New Orleans, pp 4578–4587. https://doi.org/10.1109/CVPRW56347.2022.00504
Nguyen DQ, Vu T, Tuan Nguyen A (2020) BERTweet: A pre-trained language model for English Tweets. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Association for Computational Linguistics, pp 9–14. Online https://doi.org/10.18653/v1/2020.emnlp-demos.2
Baltrusaitis T, Zadeh A, Lim YC, Morency L-P (2018) OpenFace 2.0: Facial behavior analysis toolkit. In: 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018). IEEE, Xi’an, pp 59–66. https://doi.org/10.1109/FG.2018.00019
Zadeh A, Zellers R, Pincus E (2016) MOSI: Multimodal corpus of sentiment Intensity and subjectivity analysis in online opinion videos. IEEE Intell Syst 31:82–88
Bagher Zadeh A, Liang PP, Poria S, Cambria E, Morency L-P (2018) Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Melbourne, pp. 2236–2246. https://doi.org/10.18653/v1/P18-1208
Yu W, Xu H, Meng F, Zhu Y, Ma Y, Wu J, Zou J, Yang K (2020) CH-SIMS: A Chinese multimodal sentiment analysis dataset with fine-grained annotations of modality. In: Proceedings of the 58th annual meeting of the association for computational linguistics, pp 3718–3727
Zadeh A, Chen M, Poria S, Cambria E, Morency L-P (2017) Tensor fusion network for multimodal sentiment analysis. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. pp 1103–1114
Liu Z, Shen Y, Lakshminarasimhan VB, Liang PP, Zadeh A, Morency L-P (2018) Efficient low-rank multimodal fusion with modality-specific factors. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp 2247–2256
Zadeh A, Liang PP, Mazumder N, Poria S, Cambria E, Morency L-P (2018) Memory fusion network for multi-view sequential learning. AAAI 32:5634–5641. https://doi.org/10.1609/aaai.v32i1.12021
Tsai Y-HH, Liang PP, Zadeh A, Morency L-P, Salakhutdinov R (2019) Learning factorized multimodal representations. In: 7th International Conference on Representation Learning. New Orleans, LA, USA. https://par.nsf.gov/biblio/10099431. Accessed May 2023
Rahman W, Hasan MK, Lee S, Zadeh A, Mao C, Morency L-P, Hoque E (2020) Integrating multimodal information in large pretrained transformers. In: Proceedings of the conference. vol. Association for Computational Linguistics, pp 2359–2369
Acknowledgements
We acknowledge and appreciate the efforts of the dataset creators in making their data available to the research community. This study utilized the dataset in accordance with its stated permissions and guidelines. Researchers interested in accessing and utilizing the data for their own analyses can refer to the provided URL to obtain the necessary files and information.
Funding
This work was supported by the Shandong Provincial Natural Science Foundation (No. ZR2021MF017) and Shandong Provincial Natural Science Foundation (No. ZR2020QF069).
Author information
Authors and Affiliations
Contributions
Shanliang Yang contributed to the conceptualization, methodology, and data analysis of the study, as well as writing the original draft. Lichao Cui participated in data collection, literature review, and reviewing/editing the manuscript. Lei Wang and Tao Wang provided project supervision and secured funding. Each author made significant contributions to the research process, ensuring the completion of a comprehensive and high-quality study.
Corresponding author
Ethics declarations
There are no financial or non-financial relationships that could be perceived as influencing the integrity or objectivity of the research conducted. This declaration ensures transparency and assures readers that there are no conflicts of interest that could compromise the validity of the findings presented in this manuscript.
Ethical and informed consent for data used
This study adheres to ethical guidelines and obtained informed consent for the data used. All data sources and participants involved in the research provided their consent for the collection, analysis, and publication of the data. This declaration affirms our commitment to conducting research in an ethical manner and upholding the principles of informed consent.
Competing interests
The authors declare no competing interests regarding the work submitted for publication.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yang, S., Cui, L., Wang, L. et al. Cross-modal contrastive learning for multimodal sentiment recognition. Appl Intell 54, 4260–4276 (2024). https://doi.org/10.1007/s10489-024-05355-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-024-05355-8