
Abstract
The barren plateau (BP) phenomenon is one of the main obstacles to implementing variational quantum algorithms in the current generation of quantum processors. Here, we introduce a method capable of avoiding the BP phenomenon in the variational determination of the geometric measure of entanglement for a large number of qubits. The method is based on measuring compatible two-qubit local functions whose optimization allows for achieving a well-suited initial condition from which a global function can be further optimized without encountering a BP. We analytically demonstrate that the local functions can be efficiently estimated and optimized. Numerical simulations up to 18 qubit GHZ and W states demonstrate that the method converges to the exact value. In particular, the method allows for escaping from BPs induced by hardware noise or global functions defined on high-dimensional systems. Numerical simulations with noise agree with experiments carried out on IBM's quantum processors for seven qubits.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
The current generation of quantum processors has been described as noisy intermediate-scale quantum (NISQ) devices, which are characterized by a number of qubits in the hundreds, low gate fidelity, short coherence times, and limited qubit connectivity [1]. These features preclude the use of error-correcting techniques [2, 3] and the implementation of deep quantum circuits, severely limiting its usability. Despite this adverse scenario, the family of variational quantum algorithms (VQAs) [4–6] emerges as a promising candidate to solve problems of practical interest in NISQ processors while offering advantages over classical computers. VQAs are hybrid quantum-classical algorithms where a cost function is efficiently evaluated on a quantum processor and is optimized using classical optimization routines. This approach is used by variational quantum eigensolvers [7], quantum approximate optimization algorithms [8], and quantum neural networks [9–11], finding applications in quantum chemistry [12–14], finances [15–18], and quantum tomography [19–25], among others.
Recently, VQAs have been applied to estimate the entanglement of quantum states [26–28]. Among them, the variational determination of geometric entanglement (VDGE) [29] estimates the geometric measure of entanglement (GME) of pure multi-qubit quantum states  . The GME is an entanglement monotone given by the distance between
. The GME is an entanglement monotone given by the distance between  and its nearest fully separable state
and its nearest fully separable state  . It was first introduced for bipartite pure states [30] and later generalized to multipartite systems [31]. The GME has been used to study the distinguishability of multipartite quantum states using local operations [32], quantum phase transitions in spin models [33], Grover's search algorithm [34], and entanglement witnesses [35]. VDGE minimizes the infidelity between
. It was first introduced for bipartite pure states [30] and later generalized to multipartite systems [31]. The GME has been used to study the distinguishability of multipartite quantum states using local operations [32], quantum phase transitions in spin models [33], Grover's search algorithm [34], and entanglement witnesses [35]. VDGE minimizes the infidelity between  and a parameterized separable state
and a parameterized separable state  to calculate the GME. This procedure requires only local unitary operations on each qubit, so the implementation in a quantum processor is direct, requiring only circuits of depth 1. VDGE has been shown to be experimentally feasible, with experiments up to five qubits on IBM's quantum processors.
to calculate the GME. This procedure requires only local unitary operations on each qubit, so the implementation in a quantum processor is direct, requiring only circuits of depth 1. VDGE has been shown to be experimentally feasible, with experiments up to five qubits on IBM's quantum processors.
Numerical simulations of VDGE for 25 qubit GHZ and W states have been performed, showing the convergence of the algorithm even in such a high dimension [29]. However, the simulations consider initial conditions close to the optimum. With random initial conditions, VDGE exhibits a clear lack of convergence. This is a common problem of current implementations of VQAs called the barren plateau (BP) phenomenon [36], which is characterized by a lack of convergence due to a gradient of the cost function with a vanishing average and a standard deviation that decreases exponentially with the number of qubits by, for example, a global cost function [37] or the presence of noise [38]. The BP strongly limits the applicability of most VQAs, so the search for techniques to avoid BP has become a significant problem today. It has been shown that BPs can be avoided in some VQA by employing a local cost function instead of a global one [37, 39–41], using better initial parameters for the optimization [42, 43], detecting the BPs with classical shadows [44], reducing the expressiveness of the parametric circuit [45], including mid-circuit measurements [46], using quantum annealing [47], geometric quantum machine learning [48], overparametrization [49], or improved gradient methods [50]. Despite the advances on this topic, there is no general indication to avoid BP in a generic VQA, and moreover, it is not clear which technique will help to avoid BPs in VDGE.
In this article, we propose a method to avoid BP in VDGE. We call this the improved VDGE (iVDGE) method, which complements VDGE by adding a previous stage to find better initial parameters in the search space so that VDGE does not fall into the BP. In this initial stage, the global infidelity is replaced by the average of two-qubit infidelities, that is, a local function, which is subsequently minimized. We show that this average bounds the infidelity, so minimizing it also minimizes the global infidelity. Furthermore, the value of these bounds can be efficiently obtained through an unbiased estimator, whose error decreases with the number of qubits. Using this local function instead of a global one drives the optimization out of the flat landscape associated with the BP with a higher probability than the standard VDGE. Our approach establishes an alternative strategy to avoid BP in the case of global functions and thus complements the arsenal of existing proposals [37, 39–41].
We carried out exhaustive numerical simulations to test the performance of iVDGE and compare it with VDGE. Simulations for random states up to six qubits show that iVDGE speeds up convergence and is more resource-efficient than VDGE. Simulations for states of 18 qubits show that while iVDGE converges near the optimum, VDGE exhibits BP. Noisy numerical simulations with seven qubits for several resources show that BPs appear with a much smaller probability in iVDGE than in VDGE, being 10% and 71%, respectively for a sample of 8192 shots. We experimentally test and corroborate our findings by running iVDGE and VDGE for a seven-qubit GHZ state on the IBM quantum processors [51].
2. Results
2.1. GME determination by VDGE
The GME  of an n-qubit quantum state
of an n-qubit quantum state  is defined through the optimization problem
is defined through the optimization problem

where

is the infidelity between two n-qubit pure states and  is the subset of pure product states of the Hilbert space
is the subset of pure product states of the Hilbert space  of n qubits. Thereby,
of n qubits. Thereby,  corresponds to the minimal infidelity between the state
corresponds to the minimal infidelity between the state  and the set
and the set  [35].
[35].
The VDGE attempts to find  by optimizing the infidelity over a variational ansatz. For this, we define the Hamiltonian
by optimizing the infidelity over a variational ansatz. For this, we define the Hamiltonian

and the variational ansatz

Here  , where
, where  is parametric single-qubit unitary operation acting on the jth qubit. Thus, the cost function
is parametric single-qubit unitary operation acting on the jth qubit. Thus, the cost function

now depends on the parameters of ansatz and can be cast as

This can be estimated by repeatedly preparing the n-qubit state  , applying the circuit that implements
, applying the circuit that implements  , and measuring on the computational basis.
, and measuring on the computational basis.
The infidelity  is minimized by an optimization method running on a classical computer. Typical choices for the optimization method are the simultaneous perturbation stochastic approximation (SPSA) method [52] and, more recently, its complex version CSPSA [21]. These methods require in each iteration the estimation of
is minimized by an optimization method running on a classical computer. Typical choices for the optimization method are the simultaneous perturbation stochastic approximation (SPSA) method [52] and, more recently, its complex version CSPSA [21]. These methods require in each iteration the estimation of  in two different points of the optimization space. Therefore, after a prescribed number of iterations, VDGE provides an estimate
in two different points of the optimization space. Therefore, after a prescribed number of iterations, VDGE provides an estimate  of GME. The minimization of GME is, however, a challenging problem since the optimization landscape might exhibit many local minima. This is usually overcome by repeating the optimization several times with different initial conditions to obtain a set of estimates
of GME. The minimization of GME is, however, a challenging problem since the optimization landscape might exhibit many local minima. This is usually overcome by repeating the optimization several times with different initial conditions to obtain a set of estimates  . The final estimate is given by the minimum over this set, that is
. The final estimate is given by the minimum over this set, that is  .
.
Numerical simulations of VDGE for 25 qubit GHZ and W states exhibit the BP phenomenon [29]. This occurs because for a n-qubit system both the infidelity  and its gradient vanish exponentially with the number of qubits when the initial parameters are randomly chosen [53]. One alternative to overcome this problem is to have a better initial condition, which can be obtained, for instance, by resorting to a priori information [42, 43] about the solution. Another alternative is to overcome the sampling noise by employing more than
and its gradient vanish exponentially with the number of qubits when the initial parameters are randomly chosen [53]. One alternative to overcome this problem is to have a better initial condition, which can be obtained, for instance, by resorting to a priori information [42, 43] about the solution. Another alternative is to overcome the sampling noise by employing more than  measurement shots, which leads to accurate evaluations of
measurement shots, which leads to accurate evaluations of  and its gradient. This, however, does not guarantee avoiding the BP, and moreover, the exponential scaling of the shot number makes the algorithm unfeasible.
and its gradient. This, however, does not guarantee avoiding the BP, and moreover, the exponential scaling of the shot number makes the algorithm unfeasible.
2.2. iVDGE
The BP phenomenon may arise due to inadequate cost functions [39, 41]. Specifically, cost functions based on global observables can lead to exponentially vanishing gradients, needing an exponential number of shots to estimate the gradient accurately. In particular, as discussed in [37], cost functions with local observables may result in a slower vanishing of the gradient, thereby avoiding the BP. To prevent the BP phenomenon from adversely affecting the performance of VDGE, we replace the global infidelity equation (5) with a local cost function, the gradient of which does not vanish exponentially with the number of qubits (see appendix

where each operator Πij acts as a rank-1 projector on qubits i and j, that is,

and as an identity operator on any other qubit. The Hamiltonian  is constructed such that
is constructed such that  is its ground state and its expected value is given by the average of the two-qubit infidelities
is its ground state and its expected value is given by the average of the two-qubit infidelities

where  is the reduced density matrix of qubits i and j from state
is the reduced density matrix of qubits i and j from state  .
.
The expectation value  can be used to obtain the following upper and lower bounds of the infidelity (see appendix
can be used to obtain the following upper and lower bounds of the infidelity (see appendix

which are tight if and only if  is a product state. According to equation (10), it is possible to obtain a first estimate of the GME by minimizing the local function
is a product state. According to equation (10), it is possible to obtain a first estimate of the GME by minimizing the local function  instead of the global function
instead of the global function  .
.
The expectation value of the Hamiltonian  can be cast in the form
can be cast in the form

where

and the set  contains all groups g of partitions of n qubits formed by non-overlapping pairs of qubits. This suggests that the expectation value
contains all groups g of partitions of n qubits formed by non-overlapping pairs of qubits. This suggests that the expectation value  can be evaluated by sampling Xg
uniformly on the set
can be evaluated by sampling Xg
uniformly on the set  . For a given group g the evaluation of the infidelities in Xg
can be performed efficiently since the measurements are local and can be carried out in parallel. To keep resource usage to a minimum, we randomly select a single Xg
as an estimator of
. For a given group g the evaluation of the infidelities in Xg
can be performed efficiently since the measurements are local and can be carried out in parallel. To keep resource usage to a minimum, we randomly select a single Xg
as an estimator of  . This estimator is unbiased, that is,
. This estimator is unbiased, that is,  , and its mean square error (MSE) is bounded and decreases inversely proportional with the number of qubits (see appendix
, and its mean square error (MSE) is bounded and decreases inversely proportional with the number of qubits (see appendix

The algorithm that we propose, which we call iVDGE, arises from concatenating the following two stages: (i) the minimization of the expectation value of the local Hamiltonian  to obtain a first estimate of the GME, and (ii) the execution of a standard VDGE, that minimizes the expectation value of the global Hamiltonian
to obtain a first estimate of the GME, and (ii) the execution of a standard VDGE, that minimizes the expectation value of the global Hamiltonian  , but using as initial guess the estimator obtained from the stage (i). The concatenation of these steps allows us to avoid BPs and accurately estimate the GME.
, but using as initial guess the estimator obtained from the stage (i). The concatenation of these steps allows us to avoid BPs and accurately estimate the GME.
Stage (i) is performed as follows:
- (a)Split the n qubits in a partition of
 pairs (i, j) at random, plus a single qubit if n is odd, or equivalently, sample a single group of non-overlapping pairs of qubits.
pairs (i, j) at random, plus a single qubit if n is odd, or equivalently, sample a single group of non-overlapping pairs of qubits. - (b)For each pair (i, j) in the partition, perform a single iteration of a classical optimization method to minimize the corresponding local infidelity (9). This is equivalent to minimizing the expected value of the local Hamiltonian.
- (c)Repeat steps (a) and (b) a predefined number of times according to a classical optimization method.




Let us note that stage (i) is only used to escape from the BP. As we are only estimating two-qubit functions, we require a number of shots that is polynomial in the number of qubits to obtain a useful estimation of the gradient. Outside the BP, the minimization of the global function converges faster than the minimization of the local function. Here we need a number of shots at least proportional to  , as we must be able to calculate the gradient of the infidelity around the value of the
, as we must be able to calculate the gradient of the infidelity around the value of the  .
.
Selecting the classical optimization method is fundamental to obtaining good performance with iVDGE. Particularly, we chose the CSPSA method [21] (see appendix
| Algorithm 1. iVDGE algorithm. |
|---|
Input: quantum state Ψ, number of local iterations  , number of global iterations , number of global iterations 
|
Initialization: parameters 
|
for
 do
do
|
if
 then
then
|
Set a pair-wise partition  of of 
|
for
 do
do
|
Compute CSPSA gradient 
|

|
| end |
| else |
Compute CSPSA gradient 
|

|
| end |
| end |
The iVDGE method might still get trapped in local optima. To avoid them, we run the optimization several times starting from different separable initial states to obtain a set of possible estimators of the GME, and keep the best value obtained as the final estimator.
2.3. Numerical simulations
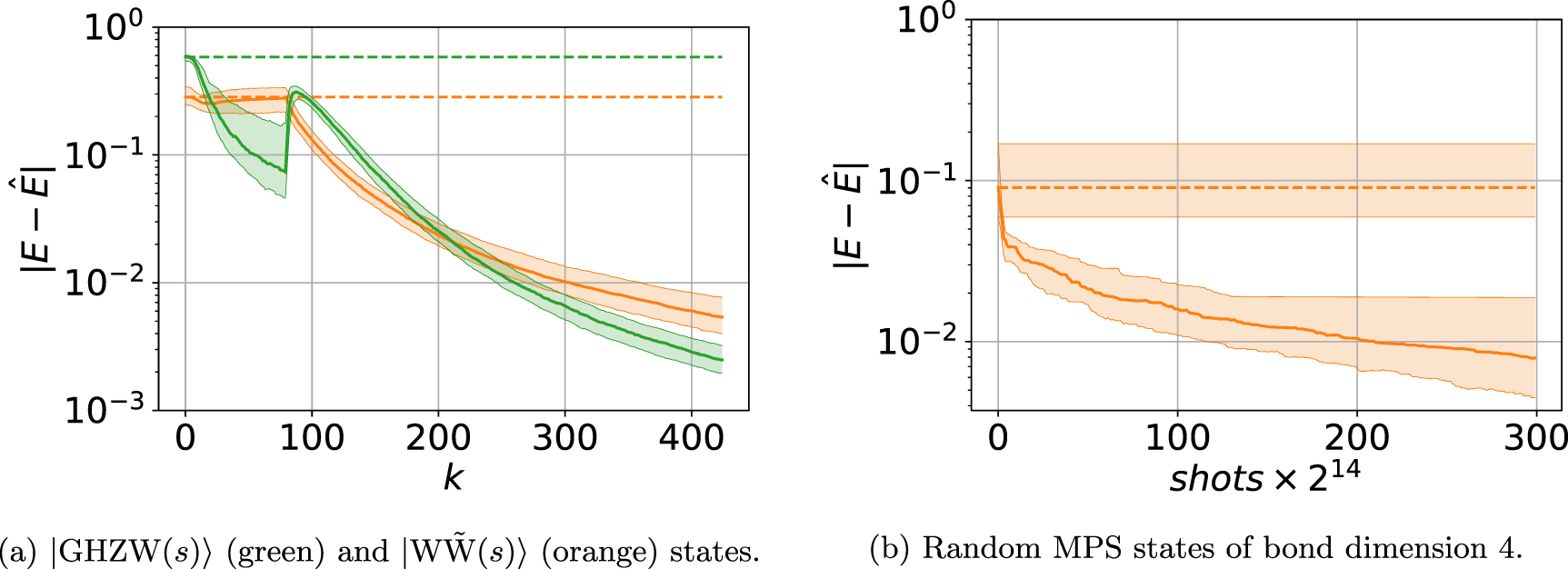
The first numerical test shows the effectiveness of replacing the local Hamiltonian  with a random Hamiltonian at each iteration of the optimization algorithm. We generate 100 random matrix product states (MPSs), each with a bond dimension of 16 and 10 qubits. Solid curves in figure 1 show the median difference
with a random Hamiltonian at each iteration of the optimization algorithm. We generate 100 random matrix product states (MPSs), each with a bond dimension of 16 and 10 qubits. Solid curves in figure 1 show the median difference  between the exact GME E and the estimated GME
between the exact GME E and the estimated GME  values. The green curve denotes optimization over the function
values. The green curve denotes optimization over the function  followed by the global function, whereas the orange curve represents optimization over the local randomized function Xg
followed by the global function. In both cases, the first stage comprises 80 local iterations, measured using 512 shots, and the second stage is composed of 295 global iterations employing 8196 shots. The exact value of the GME was calculated using the Basin-hopping optimization algorithm [54] (see appendix
followed by the global function, whereas the orange curve represents optimization over the local randomized function Xg
followed by the global function. In both cases, the first stage comprises 80 local iterations, measured using 512 shots, and the second stage is composed of 295 global iterations employing 8196 shots. The exact value of the GME was calculated using the Basin-hopping optimization algorithm [54] (see appendix  , which even exhibits stagnation in the late stages of the algorithm. According to equation (12), the minimization of Xg
corresponds to the minimization of
, which even exhibits stagnation in the late stages of the algorithm. According to equation (12), the minimization of Xg
corresponds to the minimization of  independent terms, since g is a set of disjoint pairwise partition of the set of qubits. Thereby, for a given iteration k, we have to calculate
independent terms, since g is a set of disjoint pairwise partition of the set of qubits. Thereby, for a given iteration k, we have to calculate  independent gradients, and then update the parameters of
independent gradients, and then update the parameters of  independent functions. Since these functions only depend on two qubits, they can be evaluated to a high precision with a small number of shots. On the other hand, according to equation (11), the minimization of
independent functions. Since these functions only depend on two qubits, they can be evaluated to a high precision with a small number of shots. On the other hand, according to equation (11), the minimization of  requires minimizing a sum of
requires minimizing a sum of  local functions. These are not independent anymore and thus the optimization problem cannot be split into a sum of two-qubit optimization problems. The sum of this large quantity of two-qubit functions increases the variance in the estimation of
local functions. These are not independent anymore and thus the optimization problem cannot be split into a sum of two-qubit optimization problems. The sum of this large quantity of two-qubit functions increases the variance in the estimation of  . For a fixed, small number of shots, the evaluation of Xg
has a smaller error than the evaluation of
. For a fixed, small number of shots, the evaluation of Xg
has a smaller error than the evaluation of  , which is more favorable for the optimization algorithm.
, which is more favorable for the optimization algorithm.

Figure 1. Difference  between the exact GME E and the estimated GME
between the exact GME E and the estimated GME  values obtained with iVDGE optimizing over
values obtained with iVDGE optimizing over  (green) in the first stage and iVDGE (orange) optimizing over Xg
in the first stage as a function of the number of shots. Solid lines indicate the median difference calculated over an ensemble of 100 randomly selected MPS states. Shaded areas represent the corresponding interquartile range.
(green) in the first stage and iVDGE (orange) optimizing over Xg
in the first stage as a function of the number of shots. Solid lines indicate the median difference calculated over an ensemble of 100 randomly selected MPS states. Shaded areas represent the corresponding interquartile range.
Download figure:
Standard image High-resolution imageIn our second test, we consider simulations with random initial conditions for a small number of qubits and compare iVDGE and VDGE. We generate a set of 100 pure states randomly chosen according to a Haar-uniform distribution for 3, 4, 5, and 6 qubits. For each state, we estimate the GME using both methods. For iVDGE, the first stage is implemented with 80 iterations, using 512 shots to simulate each measurement of the infidelity. The second stage is executed with 295 iterations and using 8192 shots per infidelity evaluation. The first stage uses a total of shots equal to that used in five iterations of the second stage. On the other hand, VDGE is implemented using 300 iterations with 8192 shots per infidelity evaluation. Therefore, our implementations of iVDGE and VDGE use the same number of shots. To avoid local optima, this procedure is repeated five times for each randomly generated state in both methods, and the minimum GME value obtained is the final GME estimate. We also numerically compute the exact value of the GME for each of the randomly generated states through the Basin-hopping optimization algorithm (see appendix
The comparison between the performances of iVDGE and VDGE is shown in figure 2. The orange (green) curve represents the median of the difference  between E, the exact GME value, and
between E, the exact GME value, and  , the values obtained through iVDGE (VDGE) as a function of the number of accumulated shots. Shaded areas correspond to interquartile ranges. As figure 2 indicates, iVDGE achieves faster convergence and higher accuracy than VDGE in all four cases. As the number of qubits increases, the interquartile ranges of iVDGE and VDGE do not intersect and the estimation precision of GME decreases and presents flattening, the latter being less pronounced for the iVDGE method.
, the values obtained through iVDGE (VDGE) as a function of the number of accumulated shots. Shaded areas correspond to interquartile ranges. As figure 2 indicates, iVDGE achieves faster convergence and higher accuracy than VDGE in all four cases. As the number of qubits increases, the interquartile ranges of iVDGE and VDGE do not intersect and the estimation precision of GME decreases and presents flattening, the latter being less pronounced for the iVDGE method.

Figure 2. Difference  between the exact GME E and the estimated GME
between the exact GME E and the estimated GME  values obtained with VDGE (green) and iVDGE (orange) as a function of the number of shots. Solid lines indicate the median difference calculated over an ensemble of 100 randomly selected pure states. Shaded areas represent the corresponding interquartile range.
values obtained with VDGE (green) and iVDGE (orange) as a function of the number of shots. Solid lines indicate the median difference calculated over an ensemble of 100 randomly selected pure states. Shaded areas represent the corresponding interquartile range.
Download figure:
Standard image High-resolution imageTo comparatively study the performance of iVDGE and VDGE in the high qubit number regime, where the BP phenomenon is expected to arise, we perform simulations with particular quantum states since the calculation of the GME for arbitrary states in this regime becomes unfeasible [53]. We resort to the GHZ, W, and  states for n qubits given by the expressions.
states for n qubits given by the expressions.



These states have GME values of 0.5 for the GHZ state and ![$1 - [(n-1)/n)]^{n-1}$](https://content.cld.iop.org/journals/2058-9565/9/2/025016/revision2/qstad2a16ieqn80.gif) for W and
for W and  states [35]. For superpositions of the form
states [35]. For superpositions of the form

or

with ![$s \in [0, 1]$](https://content.cld.iop.org/journals/2058-9565/9/2/025016/revision2/qstad2a16ieqn82.gif) , the GME is optimized by a symmetric separable state [55], that is,
, the GME is optimized by a symmetric separable state [55], that is,  . This reduces the optimization space to only two parameters, making it easier to evaluate the exact value of the GME using classical optimization techniques.
. This reduces the optimization space to only two parameters, making it easier to evaluate the exact value of the GME using classical optimization techniques.
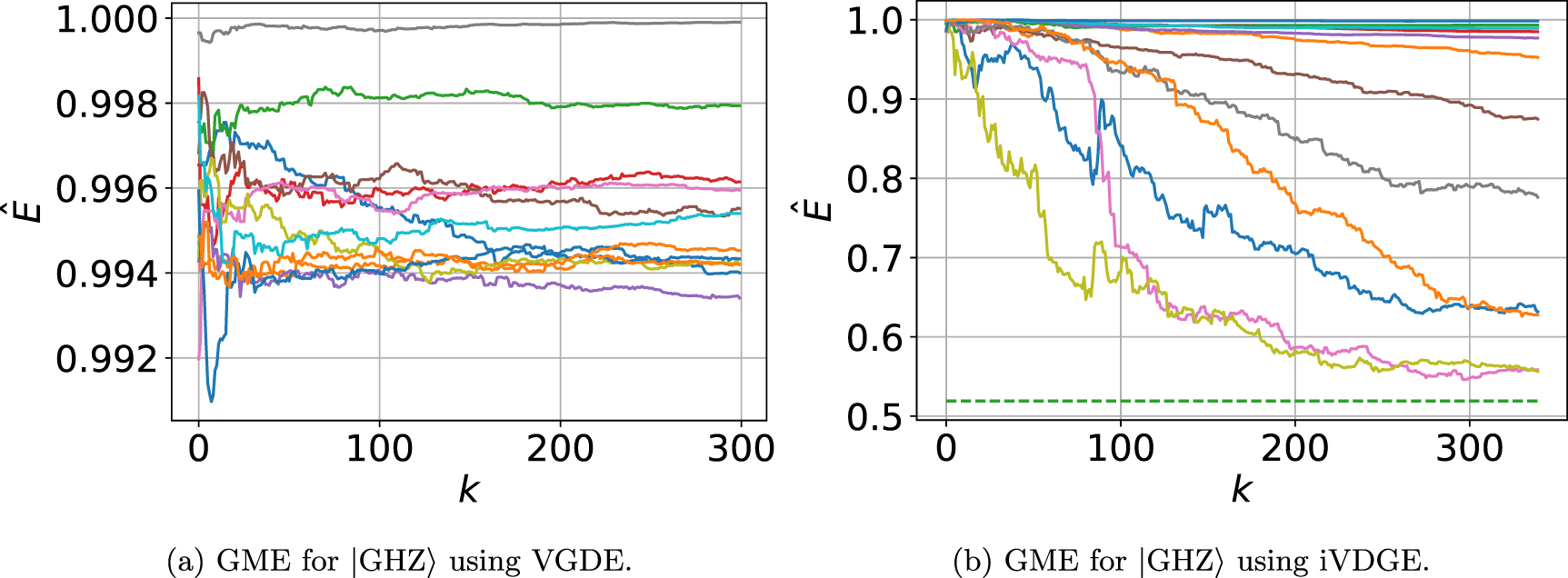
Figure 3 exhibits the value of the GME obtained with VDGE and iVDGE for the states  and
and  as a function of s and for n = 18 qubits. For each state and value of
as a function of s and for n = 18 qubits. For each state and value of  with
with  , VDGE and iVDGE are executed with five randomly selected initial conditions, and the minimum value of GME is selected as an estimate. This procedure is repeated 100 times. Orange stars represent the median value obtained using iVDGE with 80 iterations in the first stage and 295 iterations in the second stage. The infidelities were approximated with 512 and 8192 shots, respectively. Green circles represent the median value obtained using VDGE with 300 iterations, evaluating the infidelity with 8192 shots. The solid blue curve represents the exact value of the GME (see appendix
, VDGE and iVDGE are executed with five randomly selected initial conditions, and the minimum value of GME is selected as an estimate. This procedure is repeated 100 times. Orange stars represent the median value obtained using iVDGE with 80 iterations in the first stage and 295 iterations in the second stage. The infidelities were approximated with 512 and 8192 shots, respectively. Green circles represent the median value obtained using VDGE with 300 iterations, evaluating the infidelity with 8192 shots. The solid blue curve represents the exact value of the GME (see appendix

Figure 3. Value of the GME for 18 qubit  and
and  states as a function of s. Orange stars (green dots) represent the median values obtained using iVDGE (VDGE) on a set of 100 repetitions with randomly selected initial conditions. The blue curve is the exact GME value. Shaded areas correspond to interquartile ranges.
states as a function of s. Orange stars (green dots) represent the median values obtained using iVDGE (VDGE) on a set of 100 repetitions with randomly selected initial conditions. The blue curve is the exact GME value. Shaded areas correspond to interquartile ranges.
Download figure:
Standard image High-resolution imageFigure 4(a) allows us to analyze the convergence of iVDGE from a different perspective using the data from the previous simulation. This figure displays the median error  calculated on the set of 100 GME estimates for all 21 values of s for
calculated on the set of 100 GME estimates for all 21 values of s for  states (green) and
states (green) and  states (orange), as a function of the number of iterations. Solid and dashed lines display the median of iVDGE and VDGE, respectively. Shaded areas correspond to interquartile ranges. VDGE and iVDGE start at the same point in the parameter space. In the first 80 iterations, iVDGE tries to find a good starting point for global optimization in the second stage. For the orange curve, we see that although the distance from the optimum does not improve significantly in the first stage, at the beginning of the second stage, iVDGE is effectively outside the BP and also converges. For the green curve, we see that the distance from the optimum increases when iVDGE switches to the second stage. This behavior might be controlled by fine-tuning the hyper-parameters of the optimization algorithm. Nevertheless, iVDGE does not enter the BP again and converges with good accuracy. The solid (dashed) line in figure 4(b) shows the median error
states (orange), as a function of the number of iterations. Solid and dashed lines display the median of iVDGE and VDGE, respectively. Shaded areas correspond to interquartile ranges. VDGE and iVDGE start at the same point in the parameter space. In the first 80 iterations, iVDGE tries to find a good starting point for global optimization in the second stage. For the orange curve, we see that although the distance from the optimum does not improve significantly in the first stage, at the beginning of the second stage, iVDGE is effectively outside the BP and also converges. For the green curve, we see that the distance from the optimum increases when iVDGE switches to the second stage. This behavior might be controlled by fine-tuning the hyper-parameters of the optimization algorithm. Nevertheless, iVDGE does not enter the BP again and converges with good accuracy. The solid (dashed) line in figure 4(b) shows the median error  calculated on a set of 100 random MPS states of 18 qubits and bond dimension 4 using iVDGE (VDGE). We use 80 iterations in the first stage of VDGE and 295 iterations in the second stage. As can be seen from this figure, VDGE cannot provide a value of the GME, while iVDGE shows a systematic decrease of the median error toward the exact value. As in the previous cases, iVDGE also manages to escape from the BP.
calculated on a set of 100 random MPS states of 18 qubits and bond dimension 4 using iVDGE (VDGE). We use 80 iterations in the first stage of VDGE and 295 iterations in the second stage. As can be seen from this figure, VDGE cannot provide a value of the GME, while iVDGE shows a systematic decrease of the median error toward the exact value. As in the previous cases, iVDGE also manages to escape from the BP.

Figure 4. Median of the difference  between the exact GME E and the estimated GME
between the exact GME E and the estimated GME  values on the sets of 18 qubit states as a function of the number of iterations k. The first 80 iterations correspond to the optimization of local functions, and the next 345 to the optimization of the global function. Solid (dashed) lines correspond to the median of the difference
values on the sets of 18 qubit states as a function of the number of iterations k. The first 80 iterations correspond to the optimization of local functions, and the next 345 to the optimization of the global function. Solid (dashed) lines correspond to the median of the difference  obtained via iVDGE (VDGE). Shaded areas correspond to interquartile ranges.
obtained via iVDGE (VDGE). Shaded areas correspond to interquartile ranges.
Download figure:
Standard image High-resolution imageTo study the ability of the iVDGE algorithm to bypass noise-induced BPs [38], we performed noisy simulations for both VDGE and iVDGE using limited resources and the noise model of IBM Quantum system ibm_oslo, which includes one- and two-qubit gate errors as well as measurement errors. The GME of a seven-qubit GHZ state is calculated for 100 randomly generated initial conditions with VDGE and iVDGE, using different numbers of shots. For the VDGE algorithm, we performed 200 iterations, while for the iVDGE algorithm, we performed 80 local iterations plus the required number of global iterations such that the same total number of shots is used in both methods. For example, to match the 200 iterations of VDGE with 8192 shots, iVDGE uses 80 local iterations with 512 shots and 195 global iterations with 8192 shots. On the last iteration, we perform error mitigation using matrix inversion to mitigate the measurement error. Unlike the previous simulations, we do not consider extra repetitions with random initial conditions to avoid local optima. The GME of a GHZ is equal to 0.5, but the state prepared by the circuit has a GME of  due to noisy operations that decrease the amount of entanglement. We consider that the algorithm is trapped in a BP if, after the optimization, the GME is still greater than 0.9.
due to noisy operations that decrease the amount of entanglement. We consider that the algorithm is trapped in a BP if, after the optimization, the GME is still greater than 0.9.
Tables 1 and 2 show the percentage of BPs appearance for a given amount of total shots for the VDGE and iVDGE algorithms, respectively, together with the median estimated GME for the 100 different initial conditions. The simulations show that in the case of VDGE, the BP appearance is approximately independent of the number of shots, where about 70% of the realizations exhibit the BP phenomenon. On the other hand, the BP occurrence for the iVDGE simulations stays relatively low using 512 local shots and up to 1024 global shots but increases rapidly by further reducing the total number of shots. The median GME only changes drastically when using the lowest amount of shots. The iVDGE results show a better convergence compared to the VDGE method and a better median GME for every set of shots.
Table 1. Percentage of BPs appearances and median GME value of a seven-qubit GHZ state with 100 randomly generated initial conditions using the VDGE algorithm with different numbers of shots. For every case, 200 iterations are considered.
| VDGE | ||
|---|---|---|
| Global shots | BP % | Median GME |
| 8192 | 71% | 0.9822 |
| 4096 | 69% | 0.9855 |
| 2048 | 74% | 0.9830 |
| 1024 | 69% | 0.9854 |
| 512 | 74% | 0.9836 |
| 256 | 73% | 0.9866 |
| 130 | 77% | 0.9828 |
Table 2. Percentage of BPs appearances and median GME value of a seven-qubit GHZ state with 100 randomly generated initial conditions using the iVDGE algorithm with different numbers of shots. For every case, 80 iterations are performed on the local stage, while the number of iterations on the global stage is chosen such that the same total number of shots is used in both methods.
| iVDGE | |||
|---|---|---|---|
| Local shots | Global shots | BP % | Median GME |
| 512 | 8192 | 10% | 0.5322 |
| 512 | 4096 | 10% | 0.5322 |
| 512 | 2048 | 9% | 0.5331 |
| 512 | 1024 | 9% | 0.5407 |
| 256 | 512 | 16% | 0.5516 |
| 128 | 256 | 20% | 0.5951 |
| 64 | 128 | 39% | 0.7698 |
2.4. Experimental results for seven-qubit GHZ state
Following the results obtained from the noisy simulations, we can observe a BP if we consider a low number of shots compared to the dimension, and check the experimental performance of both algorithms with limited resources using the IBM quantum processor ibm_oslo.
We measure the GME of a seven-qubit GHZ state using iVDGE and VDGE, repeating the procedure 12 times with different initial conditions. For iVDGE, we perform 80 local and 260 global iterations using 128 and 256 shots, respectively, to estimate the infidelities. For VDGE we perform 300 iterations using 256 shots for each measurement of the infidelity. As the performance of the quantum device is affected by various noise sources, we can not generate an ideal GHZ state. Because of this, we perform quantum state tomography using  shots per basis with maximum likelihood estimation [56, 57] using a pure state parameterization and error mitigation [58], obtaining an estimated GHZ state that has fidelity of
shots per basis with maximum likelihood estimation [56, 57] using a pure state parameterization and error mitigation [58], obtaining an estimated GHZ state that has fidelity of  with respect to the ideal GHZ. The GME of the estimated state is obtained using the Basin-hopping optimization algorithm, which leads to a GME value of
with respect to the ideal GHZ. The GME of the estimated state is obtained using the Basin-hopping optimization algorithm, which leads to a GME value of  .
.
To estimate the experimental errors of both the fidelity and the GME, we sample 100 times from the probability distribution obtained from measuring every basis for the quantum state tomography and reconstruct a sampled state using maximum likelihood estimation. The error of the fidelity is then given by the standard deviation of the fidelity between the sampled states and the ideal GHZ state, while the error of the GME corresponds to the standard deviation of every GME value of the sampled states after the classical optimization with Basin-hopping.
Figure 5 shows the value of the GME for the experimentally estimated GHZ state provided by (a) VDGE and (b) iVDGE as a function of the number of iterations, for 12 independent realizations. The GME is calculated by evaluating the infidelity between the experimentally estimated GHZ state and the separable state provided by VDGE or iVDGE. The dotted line represents the theoretical GME value of 0.519. According to figure 5, of the 12 repetitions of VDGE, not a single one manages to escape the BP, while 5 of the 12 repetitions of iVDGE manage to surpass it, following the criteria defined in our numerical simulations. This percentage of BP appearance is higher than the one expected from the noisy simulations. One possible explanation is that the model does not consider other sources of error, like decoherence, cross-talk between qubits, state preparation error, etc.

Figure 5. GME value for a seven-qubit  state as a function of the number of iterations k using both VDGE (left) and iVDGE (right) methods. Each solid line corresponds to an optimization routine with different initial conditions. The dotted line corresponds to the exact GME value after performing quantum state tomography on the generated state.
state as a function of the number of iterations k using both VDGE (left) and iVDGE (right) methods. Each solid line corresponds to an optimization routine with different initial conditions. The dotted line corresponds to the exact GME value after performing quantum state tomography on the generated state.
Download figure:
Standard image High-resolution image2.5. Avoiding BPs in other variational algorithms
In this subsection, we discuss other variational problems where our approach to avoid BP could be applied. We can define a family of variational problems using the following global Hamiltonian,

with U an unitary matrix,  real coefficients, and
real coefficients, and  the canonical basis of the jth qubit. The coefficients
the canonical basis of the jth qubit. The coefficients  satisfy
satisfy  to bound the expected value of
to bound the expected value of  in the range
in the range  . Notice that we recover the VDGE Hamiltonian, equation (3), for
. Notice that we recover the VDGE Hamiltonian, equation (3), for  and
and  . Other problems included in this Hamiltonian are the quantum autoencoder [37], the quantum-assisted compiling [39], the variational quantum linear solver [40], and the variational quantum state diagonalization [41].
. Other problems included in this Hamiltonian are the quantum autoencoder [37], the quantum-assisted compiling [39], the variational quantum linear solver [40], and the variational quantum state diagonalization [41].
Similarly to iVDGE, we define the following two-qubit local Hamiltonian

with Πij the two-qubit operator

Notice that Πij
acts as the identity in the other qubits. Let us define hij
as the expected value of Πij
on a variational state  , that is
, that is

Analogously to iVDGE, we define an estimator of the expectation value of the local Hamiltonian  as the average of hij
over a set of non-overlapping pairs of qubits,
as the average of hij
over a set of non-overlapping pairs of qubits,

with

Following the same strategy as iVDGE, we first optimize the local Hamiltonian to escape from the flat landscape and later use its optimum as the initial condition to optimize the global Hamiltonian.
The main difference between iVDGE and an arbitrary variational problem defined by  lies in the variational ansatz. While iVDGE requires only local gates, equation (4), an arbitrary problem could require several layers of entangling gates, preventing the optimization of the local Hamiltonian
lies in the variational ansatz. While iVDGE requires only local gates, equation (4), an arbitrary problem could require several layers of entangling gates, preventing the optimization of the local Hamiltonian  by parallel optimizing the two-body reduced functions
by parallel optimizing the two-body reduced functions  . Instead, in each iteration of the variational algorithm, we randomly select a set of non-overlapping pairs of qubits
. Instead, in each iteration of the variational algorithm, we randomly select a set of non-overlapping pairs of qubits  and use directly Xg
as an estimate of
and use directly Xg
as an estimate of  to update the parameters. Despite that, we expect our approach's ability to remain as long as the variational ansatz behaves well against BPs [48].
to update the parameters. Despite that, we expect our approach's ability to remain as long as the variational ansatz behaves well against BPs [48].
3. Discussion
The GME can be evaluated in NISQ devices via the VDGE method. This is done using a parametric quantum circuit which involves local gates only. This allows us to avoid two sources of the BP phenomenon: deep parametric quantum circuits and high levels of noise. However, since the function to be optimized is global, that is, its evaluation requires measurements onto sets of many qubits simultaneously, the BP phenomenon still impairs the performance of VDGE method for a large number of qubits.
In order to avoid the BP phenomenon in the context of the GME we propose the iVDGE method, which adds a previous stage to the VDGE method. This is based on measuring a two-qubit local function, which is the expectation value  of a two-qubit Hamiltonian, that upper and lower bounds the global function. This suggests optimizing the local function allows us to optimize the global one. The local function is minimized for a fixed number of iterations, producing preliminary parameters used as a starting point for VDGE. The first stage of iVDGE can be efficiently carried out using an unbiased estimator Xg
with bounded error of the local function.
of a two-qubit Hamiltonian, that upper and lower bounds the global function. This suggests optimizing the local function allows us to optimize the global one. The local function is minimized for a fixed number of iterations, producing preliminary parameters used as a starting point for VDGE. The first stage of iVDGE can be efficiently carried out using an unbiased estimator Xg
with bounded error of the local function.
We performed several numerical simulations to investigate the performance of iVDGE to estimate the GME and its ability to avoid BP. We start by analyzing both methods for random states in a small number of qubits, as shown in figure 2. Since we are working with a low number of qubits, we can expect both VDGE and iVDGE to converge to the optimum given a suitable number of iterations. Nevertheless, we can see that iVDGE provides a speed-up in the convergence concerning VDGE for a fixed total number of shots. To assess the performance of the methods for a large number of qubits, we conducted simulations involving superpositions of GHZ and W states of 18 qubits, as well as random MPS states. As figures 3 and 4 indicate, the VDGE method stagnates at E = 1, showing the presence of the BP phenomenon. Meanwhile, iVDGE avoids it and successfully converges to the correct value of the GME. Notice that figure 4(a) shows that the first stage of iVDGE does not necessarily provide an accurate estimate for the GME. Nevertheless, the iVDGE method produces a good enough starting point so that the VDGE method will avoid the flat landscape and converge. Finally, we study the efficiency of iVDGE in the presence of noise by simulating a seven-qubit GHZ state using the model of an actual NISQ device so that a noise-induced BP arises. According to table 1, the VDGE method escapes from the BP with a probability of approximately 0.3, which leads to a median GME value of 0.98, far away from the correct GME value of 0.5, in a wide range of global shot number. The scenario in the case of iVDGE, shown in table 2, is drastically different, where iVDGE escapes from the BP and converges to the correct GME value with a high probability of approximately 0.8, even for a low global shot number of 256. This shows that iVDGE not only avoids BPs produced by global objective functions but also avoids noise-induced BPs.
To test the performance of the iVDGE method on the current quantum hardware generation, we conducted experiments on the IBM quantum processor ibm_oslo. We studied the GME of a seven-qubit GHZ state, and to illustrate the difference between the performance of VDGE and iVDGE we chose a low number of shots, such that BP emerges. In particular, we considered a number of 256 shots, which is twice the dimension of the search space. Figure 5 shows the estimated GME value of 12 independent runs, where the VDGE method does not escape the BP, while iVDGE effectively shows that most of the runs escape the BP and even some of them are close to the correct GME value.
For the experimental results, the dimension of the system is  . When we start from a random separable state, we can expect that the initial estimated GME for the GHZ will be close to
. When we start from a random separable state, we can expect that the initial estimated GME for the GHZ will be close to  , as any local state has a mean fidelity of
, as any local state has a mean fidelity of  when randomly chosen according to the Haar measure [59]. Following the noisy simulations and the size of the problem, we can expect that using only 256 shots to estimate this quantity is insufficient to construct a good approximation of the gradient. This is one of the effects seen in figure 5, where none of the trajectories of VDGE left the BP zone. On the other hand, in the first stage of iVDGE we have 128 shots to estimate fidelities in dimension 4, which can be done with more precision. Then, when we pass to the second stage, 5 of 12 trajectories escape the BP.
when randomly chosen according to the Haar measure [59]. Following the noisy simulations and the size of the problem, we can expect that using only 256 shots to estimate this quantity is insufficient to construct a good approximation of the gradient. This is one of the effects seen in figure 5, where none of the trajectories of VDGE left the BP zone. On the other hand, in the first stage of iVDGE we have 128 shots to estimate fidelities in dimension 4, which can be done with more precision. Then, when we pass to the second stage, 5 of 12 trajectories escape the BP.
Considering the previous discussion, iVDGE is effectively an improvement of VDGE. We have seen that it can avoid the BP phenomena produced by global functions in high dimensional systems and noise-induced BP. Moreover, it provides a speed-up over VDGE in scenarios where the BP phenomenon is not observed. These improvements do not add complexity to the algorithm, as the local function used in the initial stage can be efficiently evaluated, and it employs the same ansatz as VDGE. In our simulations, the number of shots required does not scale exponentially with the number of qubits. Then, we expect an accurate estimate of the GME even in high-dimensional systems.
Our protocol finds direct application in estimating the entanglement of many-body quantum states in current devices. For example, recently, 27 qubits GHZ states [60] and native-graph states [61] have been implemented. The ability of iVDGE to avoid BPs qualifies it as an efficient alternative to certify the entanglement of these states. Moreover, our proposal represents a step forward and complements previous results to handle BPs in variational algorithms. The standard approach is to optimize in the first stage a Hamiltonian composed of single-qubit observables, removing the coupling between the subsystems. In contrast, our approach uses two-qubit observables, so it preserves some of the entanglement structure of the Hamiltonian. This property can be advantageous for problems where entanglement plays a crucial role, such as estimating the ground state of molecules known to be entangled [12]. We also anticipate the applicability of our strategy in variational problems such as quantum autoencoder [37], quantum-assisted compiling [39], variational quantum linear solver [40], and variational quantum state diagonalization [41], as they share similar Hamiltonian definitions with VDGE.
The iVDGE method can be enhanced in various ways. The switch between local and global Hamiltonians is crucial in the performance of the algorithm, so establishing a precise criterion for switching without compromising fidelity is essential. This can be done, for instance, by considering a suitable set of gain coefficients on CSPSA. An alternative approach [41] has been recently suggested, where an adiabatic process is employed instead of abruptly changing the Hamiltonian from local to global. This is done evaluating the Hamiltonian  in the kth iteration of the optimization, where
in the kth iteration of the optimization, where  is a sequence of positive coefficients such that λ1 = 0 and
is a sequence of positive coefficients such that λ1 = 0 and  . This approach allows us to escape from the flat landscape using the local Hamiltonian in early iterations, while the global Hamiltonian permits precise estimation of GME in later iterations. Furthermore, our protocol is not limited to using two-qubit local Hamiltonians. Adding more stages to the protocol, where local Hamiltonians with more qubits are used, could speed up the method. For example, firstly, optimize over two-qubits local Hamiltonians, then with
. This approach allows us to escape from the flat landscape using the local Hamiltonian in early iterations, while the global Hamiltonian permits precise estimation of GME in later iterations. Furthermore, our protocol is not limited to using two-qubit local Hamiltonians. Adding more stages to the protocol, where local Hamiltonians with more qubits are used, could speed up the method. For example, firstly, optimize over two-qubits local Hamiltonians, then with  -qubits local Hamiltonians, and in the last stage, carry out a global optimization with n-qubits. These upgrades can enhance the efficiency and accuracy of the protocol, making it a valuable tool for entanglement estimation in many-body quantum systems.
-qubits local Hamiltonians, and in the last stage, carry out a global optimization with n-qubits. These upgrades can enhance the efficiency and accuracy of the protocol, making it a valuable tool for entanglement estimation in many-body quantum systems.
Acknowledgments
This work was supported by ANID—Millennium Science Initiative Program—ICN17 012. L Z was supported by the Government of Spain (Severo Ochoa CEX2019-000910-S, TRANQI, and European Union NextGenerationEU PRTR-C17.I1), Fundació Cellex, Fundació Mir-Puig and Generalitat de Catalunya (CERCA program). A D was supported by FONDECYT Grants 1231940 and 1230586. M M was supported by ANID-PFCHA/DOCTORADO-NACIONAL/2019-21190958. L P was supported by ANID-PFCHA/DOCTORADO-BECAS-CHILE/2019-772200275, the CSIC Interdisciplinary Thematic Platform (PTI+) on Quantum Technologies (PTI-QTEP+), the CAM/FEDER Project No. S2018/TCS-4342 (QUITEMAD-CM), and the Proyecto Sinérgico CAM 2020 Y2020/TCS-6545 (NanoQuCo-CM).
012. L Z was supported by the Government of Spain (Severo Ochoa CEX2019-000910-S, TRANQI, and European Union NextGenerationEU PRTR-C17.I1), Fundació Cellex, Fundació Mir-Puig and Generalitat de Catalunya (CERCA program). A D was supported by FONDECYT Grants 1231940 and 1230586. M M was supported by ANID-PFCHA/DOCTORADO-NACIONAL/2019-21190958. L P was supported by ANID-PFCHA/DOCTORADO-BECAS-CHILE/2019-772200275, the CSIC Interdisciplinary Thematic Platform (PTI+) on Quantum Technologies (PTI-QTEP+), the CAM/FEDER Project No. S2018/TCS-4342 (QUITEMAD-CM), and the Proyecto Sinérgico CAM 2020 Y2020/TCS-6545 (NanoQuCo-CM).
Data availability statement
The data cannot be made publicly available upon publication because no suitable repository exists for hosting data in this field of study. The data that support the findings of this study are available upon reasonable request from the authors.
Appendix A: Variance of global and local cost function
This section aims to show the exponential decay of the variance of the global cost function as the number of qubits increases and show how our proposed local Hamiltonian solves this. For simplicity, we will consider the separable state  as our target state. First, we notice that any single qubit state can be parameterized using the unitary
as our target state. First, we notice that any single qubit state can be parameterized using the unitary  given by:
given by:

such that

This gate can be implemented using, for example, single qubit RZ and RY rotations as

The global cost function, considering the global Hamiltonian  and the ansatz
and the ansatz  , is
, is

Upon differentiating with respect to parameter θk
and using the trigonometric identity  , we get
, we get

The expected value of the terms in the second brackets is zero, because

Therefore the mean value of the gradient is zero:

Upon taking the mean value of  and keeping only non-zero terms after integrating, we get:
and keeping only non-zero terms after integrating, we get:

where


Upon integrating and using the fact that  , we get that the variance of the gradient is given by
, we get that the variance of the gradient is given by

The variance has the following bounds,

so it vanishes exponentially in n i.e. exhibits BPs. If we consider now the local Hamiltonian as defined in equation (7) and the same target state, the local cost function becomes

Similarly as before, the mean value of the gradient is zero,

whereas now the variance of the gradient becomes

The variance now has the following bounds,

so it vanishes polynomially in n and does not exhibit BPs.
Appendix B: Bounds for the infidelity
This section aims to obtain bounds for the global infidelity equation (2). Let us consider a n-qubit Hamiltonian H with eigenstates  and possibly degenerate eigenvalues
and possibly degenerate eigenvalues  with
with  . The eigenvalues are ordered in increasing order and E0 = 0. For an arbitrary density matrix ρ, the energy expectation value is given by
. The eigenvalues are ordered in increasing order and E0 = 0. For an arbitrary density matrix ρ, the energy expectation value is given by

Removing the ground state from the sum,

and considering that  for
for  , we have that
, we have that

Due to the normalization of ρ, that is,

we obtain

Isolating the fidelity between ρ and  , we achieve a lower bound for the fidelity between the ground state and an arbitrary state ρ:
, we achieve a lower bound for the fidelity between the ground state and an arbitrary state ρ:

Furthermore, by using a similar reasoning involving the highest eigenvalue  , we obtain
, we obtain

This means that by finding a suitable Hamiltonian H we can get the upper (B6) and lower (B7) bounds for the fidelity between the ground state  and an arbitrary state ρ. In the following, we construct a n-qubit Hamiltonian with ground state
and an arbitrary state ρ. In the following, we construct a n-qubit Hamiltonian with ground state  that provides bounds for the GME.
that provides bounds for the GME.
To construct the Hamiltonian, we define the operators

with  and i ≠ j. These are projectors that act non-trivially only on qubits i and j and satisfy
and i ≠ j. These are projectors that act non-trivially only on qubits i and j and satisfy  . We now define the operator Γ as the sum of all these
. We now define the operator Γ as the sum of all these  local projectors, that is,
local projectors, that is,

The diagonal decomposition of the above operator is given by

where  is the projector onto the computational basis states
is the projector onto the computational basis states  with Hamming weight
with Hamming weight  . For example, P(0) projects onto the subspace defined by the state
. For example, P(0) projects onto the subspace defined by the state  . This state is an eigenvector of every local operator Πij
with an eigenvalue equal to 1. Therefore,
. This state is an eigenvector of every local operator Πij
with an eigenvalue equal to 1. Therefore,  is also eigenvector of Γ with eigenvalue
is also eigenvector of Γ with eigenvalue  . The next projector, P(1), is associated to the states
. The next projector, P(1), is associated to the states  , for
, for  . Each one of these states is an eigenvector of operators
. Each one of these states is an eigenvector of operators  and
and  with eigenvalue equal to 0, and eigenvector of the remaining
with eigenvalue equal to 0, and eigenvector of the remaining  operators
operators  with eigenvalue equal to 1. Then, they all have eigenvalue
with eigenvalue equal to 1. Then, they all have eigenvalue  of Γ.
of Γ.
We now use Γ to define the Hamiltonian

or equivalently

The lowest eigenvalue of  is E0 = 0, associated to
is E0 = 0, associated to  . The next eigenvalue is
. The next eigenvalue is  , associated to P(1). Meanwhile, the highest eigenvalue is
, associated to P(1). Meanwhile, the highest eigenvalue is  , associated to
, associated to  and P(n). Therefore, this Hamiltonian satisfies the requirements of the inequalities given by equations (B6) and (B7), obtaining the following bounds for the fidelity in terms of the expectation value of
and P(n). Therefore, this Hamiltonian satisfies the requirements of the inequalities given by equations (B6) and (B7), obtaining the following bounds for the fidelity in terms of the expectation value of 

This means that by minimizing the expected value of  , or equivalently, maximizing the expected value of Γ, we obtain a stricter bound for the fidelity.
, or equivalently, maximizing the expected value of Γ, we obtain a stricter bound for the fidelity.
Equation (B13) is enough to motivate our proposal. However, these bounds may not be tight or may even be trivial for some states. In the general case, both Hamiltonians  and
and  have the same ground state
have the same ground state  . Then, following the variational principle, they both should converge to the same ground state.
. Then, following the variational principle, they both should converge to the same ground state.
Appendix C: Evaluation of the expectation value of

In this section, we show how to evaluate the expectation value of the Hamiltonian  (7) using the Monte Carlo method. First, let us notice that the Hamiltonian can be rewritten as
(7) using the Monte Carlo method. First, let us notice that the Hamiltonian can be rewritten as

Thereby, the expectation value  is given by
is given by

where Iij are the two-qubit local infidelities

with  . The infidelities satisfy
. The infidelities satisfy  . To estimate
. To estimate  , we use the random variable
, we use the random variable

where  is a uniformly randomly selected non-overlapping set of pairs. Notice that
is a uniformly randomly selected non-overlapping set of pairs. Notice that  is also a random variable whose value corresponds to the local infidelity
is also a random variable whose value corresponds to the local infidelity  of the subsystem
of the subsystem  of qubits, defined by the k-th pair of the set g. Moreover, the random variables
of qubits, defined by the k-th pair of the set g. Moreover, the random variables  are correlated since the pairs
are correlated since the pairs  appearing in each
appearing in each  are sequentially taken to define a non-overlapping set of pairs. Namely, the kth pair
are sequentially taken to define a non-overlapping set of pairs. Namely, the kth pair  is randomly selected on the remaining set of
is randomly selected on the remaining set of  after removing all the pairs
after removing all the pairs  with
with  .
.
The performance of Xg
on the estimation of  is measured by the mean squared error (MSE). To calculate this function, we need to compute the marginal probabilities
is measured by the mean squared error (MSE). To calculate this function, we need to compute the marginal probabilities  and the joint probabilities
and the joint probabilities  . First, we note that for a given
. First, we note that for a given  and a fixed pair (i, j), the number of non-overlappings set of pairs in
and a fixed pair (i, j), the number of non-overlappings set of pairs in  such that
such that  is
is  , and the total number of pair orderings
, and the total number of pair orderings  is
is  . Then, for any
. Then, for any  ,
,

Therefore, all  follow the same probability distribution, with mean value
follow the same probability distribution, with mean value  . Furthermore, by an analogous computation, we obtain
. Furthermore, by an analogous computation, we obtain

for any  , and zero otherwise.
, and zero otherwise.
From the previous calculation, the expectation value of Xg is given by

Consequently Xg
is an unbiased estimator of  , and from this, we conclude that
, and from this, we conclude that

To calculate the variance of Xg , we note that

Therefore, from  together with equations (C4) and (C5), we get
together with equations (C4) and (C5), we get

This means that the MSE can be upper-bounded as

The above procedure can be implemented efficiently by simultaneously measuring all local infidelities corresponding to a set of non-overlapping pairs of qubits.
Appendix D: Necessity of the second stage of iVDGE
The global function  and the local function
and the local function  share the same minimum values, achieved at the same minimum points. Then, one might think that there is no need to transition to the global cost function. Transitioning from the local function to the global function after escaping the barren plateau accelerates the algorithm's convergence. We carried out numerical simulations on 100 randomly generated ten-qubit matrix product states (MPSs) with a bond dimension of 16 to demonstrate this phenomenon. The results, depicted in figure 6, illustrate the median difference
share the same minimum values, achieved at the same minimum points. Then, one might think that there is no need to transition to the global cost function. Transitioning from the local function to the global function after escaping the barren plateau accelerates the algorithm's convergence. We carried out numerical simulations on 100 randomly generated ten-qubit matrix product states (MPSs) with a bond dimension of 16 to demonstrate this phenomenon. The results, depicted in figure 6, illustrate the median difference  between the exact GME E and the estimated GME
between the exact GME E and the estimated GME  values. The blue curve denotes optimization solely over the local Hamiltonian
values. The blue curve denotes optimization solely over the local Hamiltonian  , the green curve denotes optimization only over the local randomized function Xg
, whereas the orange curve represents optimization over the local randomized function Xg
followed by the global function. Specifically, the orange curve comprises 80 local iterations, measured using 512 shots, and 295 global iterations employing 8196 shots. In contrast, the blue and green curves involve 300 local iterations, measured with 8196 shots. As figure 6 clearly shows, optimizing the random local function Xg
followed by the global function provides the best rate of convergence toward the exact value of the GME. As the optimization of Xg
progresses (green curve), its convergence rate decreases. This happens because the bounds equation (10) stop being tight close to the optimum, and then the error in the gradient evaluated using Xg
is larger than the error in the gradient using the global cost function. This forces us to switch to the global function.
, the green curve denotes optimization only over the local randomized function Xg
, whereas the orange curve represents optimization over the local randomized function Xg
followed by the global function. Specifically, the orange curve comprises 80 local iterations, measured using 512 shots, and 295 global iterations employing 8196 shots. In contrast, the blue and green curves involve 300 local iterations, measured with 8196 shots. As figure 6 clearly shows, optimizing the random local function Xg
followed by the global function provides the best rate of convergence toward the exact value of the GME. As the optimization of Xg
progresses (green curve), its convergence rate decreases. This happens because the bounds equation (10) stop being tight close to the optimum, and then the error in the gradient evaluated using Xg
is larger than the error in the gradient using the global cost function. This forces us to switch to the global function.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 6. Median of the difference  between the exact GME E and the estimated GME
between the exact GME E and the estimated GME  values for three optimization alternatives: optimization solely over the local Hamiltonian
values for three optimization alternatives: optimization solely over the local Hamiltonian  (blue curve), optimization only over the local randomized function Xg
(green curve), and optimization over the local randomized function Xg
followed by the global function (orange curve). Solid lines indicate the median difference calculated over 100 randomly generated ten-qubit matrix product states (MPS) with a bond dimension of 16. Shaded areas represent interquartile range.
(blue curve), optimization only over the local randomized function Xg
(green curve), and optimization over the local randomized function Xg
followed by the global function (orange curve). Solid lines indicate the median difference calculated over 100 randomly generated ten-qubit matrix product states (MPS) with a bond dimension of 16. Shaded areas represent interquartile range.
Download figure:
Standard image High-resolution image{kind=link}
Appendix E: Calculation of exact GME value
In order to benchmark the results of iVDGE and VDGE we need the exact value of the GME for different states. Unfortunately, for arbitrary states this must be done numerically. In figures 1, 2, 4(b) and 6 we parameterize 100 separable states  and minimize the function
and minimize the function

via Basin-hopping optimization algorithm. In this case, equation (E1) is calculated exactly. We repeat this procedure 20 times and keep the lowest value.
Then, we restrict our attention to symmetric states, whose GME is optimized by a symmetric separable state [55]. The ansatz is  , with
, with  . This means that the ansatz only depends on two parameters, greatly reducing the search space. We use this in figures 3 and 4(a), where we minimize
. This means that the ansatz only depends on two parameters, greatly reducing the search space. We use this in figures 3 and 4(a), where we minimize

via Basin-hopping optimization algorithm, repeating the procedure 20 times and keeping the lowest obtained GME value.
Appendix F: CSPSA algorithm
The complex simultaneous perturbation stochastic approximation (CSPSA) method [21] is a stochastic optimization algorithm [62–67], used to find a global minimum/maximum of a given real-valued function f of complex variables. Since non-constant real-valued functions of complex arguments violate the Cauchy–Riemann conditions, optimization methods based on their derivatives are not functional. CSPSA avoids this problem by a stochastic approximation of the gradient  computed by two evaluations of the target function in a similar way to the calculation of a central finite difference. CAPSA is based on Wirtinger's calculus [68, 69] where a function f depends on a complex variable z and its conjugate
computed by two evaluations of the target function in a similar way to the calculation of a central finite difference. CAPSA is based on Wirtinger's calculus [68, 69] where a function f depends on a complex variable z and its conjugate  , which are considered independent, i.e.
, which are considered independent, i.e.  . Stationary points of f are completely characterized by the vanishing of the gradient
. Stationary points of f are completely characterized by the vanishing of the gradient  or equivalently, by
or equivalently, by  . Thereby, the CSPSA stochastic gradient approximation on the kth iteration is computed by
. Thereby, the CSPSA stochastic gradient approximation on the kth iteration is computed by

where  is a random perturbation vector with d components uniformly generated from the set
is a random perturbation vector with d components uniformly generated from the set  , the perturbation magnitude is
, the perturbation magnitude is  , and the step size actualization of the parameters is given by
, and the step size actualization of the parameters is given by  . The performance of the CSPSA algorithm depends on the selection of its gain parameters
. The performance of the CSPSA algorithm depends on the selection of its gain parameters  and s. However, their optimal selection is unclear and depends on the minimized function. Since its proper selection is beyond a quick analysis, it is recommended to use some well-studied, stable gain combinations. There are two of those, called standard and asymptotic gains which are given by
and s. However, their optimal selection is unclear and depends on the minimized function. Since its proper selection is beyond a quick analysis, it is recommended to use some well-studied, stable gain combinations. There are two of those, called standard and asymptotic gains which are given by  and
and  , respectively.
, respectively.
In our numerical simulations we use the asymptotic gains and only the A gain is modified for performance improvements. In stage one, for all the simulations and experiments we use A = 0. In stage two, figures 3 and 4 are generated with A = 4. Figures 2(a)–(d) consider A = 32, A = 16, A = 8, and A = 4 respectively. The noisy simulations from tables 1 and 2, together with the experimental results shown in figures 5(a) and (b), use also the asymptotic gains, with A = 8 for the second stage of iVDGE.