
Abstract
This paper introduces CUQIpy, a versatile open-source Python package for computational uncertainty quantification (UQ) in inverse problems, presented as Part I of a two-part series. CUQIpy employs a Bayesian framework, integrating prior knowledge with observed data to produce posterior probability distributions that characterize the uncertainty in computed solutions to inverse problems. The package offers a high-level modeling framework with concise syntax, allowing users to easily specify their inverse problems, prior information, and statistical assumptions. CUQIpy supports a range of efficient sampling strategies and is designed to handle large-scale problems. Notably, the automatic sampler selection feature analyzes the problem structure and chooses a suitable sampler without user intervention, streamlining the process. With a selection of probability distributions, test problems, computational methods, and visualization tools, CUQIpy serves as a powerful, flexible, and adaptable tool for UQ in a wide selection of inverse problems. Part II of the series focuses on the use of CUQIpy for UQ in inverse problems with partial differential equations.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Inverse problems arise in various scientific and engineering fields such as materials science, medical imaging, and geoscience, [8, 11, 20, 60]. In these problems we compute hidden or un-observable features from indirect measurements, and the result is often uncertain due to noise in the data and inaccuracies in the models [22, 29]. We need to characterize and evaluate this uncertainty, such that we can make informed and safe decisions based on the computed results.
The field of uncertainty quantification (UQ) for inverse problems takes its basis in a Bayesian formulation. This approach builds upon theory and methods from Bayesian inference that provide a powerful and flexible framework for UQ. For inverse problems, it integrates prior knowledge with observed data and the computational model to yield posterior probability distributions that characterize the uncertainty in the computed solution [2, 9, 29, 52, 55].
1.1. Computational UQ and CUQIpy
The field of UQ for inverse problems is in a phase of rapid growth due to the development of new theory and methods; see, e.g. [4, 56]. The same is true for computational UQ for inverse problems, that focuses on the development of efficient computational methods for performing UQ of large-scale inverse problems. Several software packages have already been developed for forward and inverse UQ, including UQLab [35], SIPPI [24] and MUQ [40]. The latter takes a general approach, but many of these packages often target specific applications and have limited generality. In particular few if any UQ software packages handling large-scale imaging problems such as x-ray computed tomography (CT) and image deblurring appear to be available.
For this reason we have developed CUQIpy (pronounced "cookie pie"), an open-source Python package, currently in version 1.0.0, for computational UQ that targets a range of imaging-type inverse problems and includes a number of efficient computational methods. With CUQIpy, the user can specify a Bayesian inverse problem (or use one of the built-in ones) and then perform UQ computations using a number of methods that we provide. The name of the software is derived from the research project CUQI, computational uncertainty quantification for inverse problems, that funds the software development.
CUQIpy builds on an abstraction layer aimed at helping non-experts in Bayesian inference—and at the same time we give expert users flexibility and full control of the computational methods. A key ingredient of CUQIpy is a high-level modelling framework for working with inverse problems in the Bayesian setting. This framework includes a syntax that closely matches the underlying mathematics and statistics, thus enabling users to specify their inverse problem, a priori information, and other statistical information in a concise and intuitive way. CUQIpy's framework also offers experienced users access to the 'machine room' such that they can modify or define the underlying sampling strategies, analysis methods, etc.
Probabilistic programming refers to software that facilitates the specification and inference of probabilistic problems, typically using Bayesian inference. General-purpose probabilistic programming languages such as PyMC [51], STAN [10], Pyro [5], Turing.jl [15] have been very successful in enabling users to focus on their modelling while leaving the sampling details to the library. Enabled by automatic differentiation (AD) these languages utilize gradient information of the posterior distribution for efficient sampling via highly optimized versions of the so-called No-U-Turn sampler (NUTS) [27]. However, for large-scale inverse problems where computational efficiency is crucial, more specialized sampling strategies that take different types of problem structure into account are often required. CUQIpy addresses this issue by supporting different sampling strategies that exploit various types of problem structures such as linearity of operators or relations between distributions.
CUQIpy has been designed to support large-scale imaging-type inverse problems, such as CT. In this way, it allows users to incorporate and extend existing implementations of their inverse problem models and plotting tools. It also has an array-agnostic modeling framework that enables users to substitute classic array libraries, such as NumPy [25], with other libraries, such as PyTorch [41, 42], to benefit from AD or GPU acceleration.
CUQIpy is designed as a stand-alone Python library providing core functionality that allows the user to model and solve a variety of inverse problems. We include a selection of probability distributions, test problems, computational methods, and visualization tools. Additional functionality, e.g. via third-party libraries, is available through a plugin interface. Currently, three CUQIpy plugins have been released, proving tools for CT with Core Imaging Library CIL [28, 39], automated differentiation with PyTorch [42] and finite-element modelling through FEniCS [33], see section 3.1.
1.2. A motivating example
To demonstrate the basic usage of CUQIpy we consider a 2D deconvolution problem, which is a linear inverse problem that we write as  . Here, the matrix
A
(which is assumed known) is the forward model, and in case of 2D deconvolution
A
represents blurring by a point spread function. The vector
y
represents a random variable for the blurred and noisy image, of which we are given a particular observed realization
. Here, the matrix
A
(which is assumed known) is the forward model, and in case of 2D deconvolution
A
represents blurring by a point spread function. The vector
y
represents a random variable for the blurred and noisy image, of which we are given a particular observed realization  . From this forward model and data we are to infer the sharp image represented by the random variable
x
. We load a particular example forward model and observed data from the collection of test problems in CUQIpy:
. From this forward model and data we are to infer the sharp image represented by the random variable
x
. We load a particular example forward model and observed data from the collection of test problems in CUQIpy:

Download figure:
Standard image High-resolution imageThe underlying sharp image and the observed blurred and noisy image are shown in figure 1. Other inverse problems can be represented in the same way and CUQIpy provides tools for users to specify their own forward model—see the example in section 4.

Figure 1. Figures generated by CUQIpy's automatic UQ analysis of the built-in 2D deconvolution test problem Deconvolution2D with a blurred cookie. Far left: true sharp image. Middle left: observed blurred and noisy image. Middle right: deblurred image (posterior mean). Far right: quantification of uncertainty (posterior width).
Download figure:
Standard image High-resolution imageCUQIpy provides a modelling language to express what is known or assumed about the parameters in terms of probability distributions in a so-called Bayesian Problem; see section 2.1. Here we assume additive Gaussian white noise on the data y with zero mean and an unknown precision s (inverse variance) which is assumed to follow a Gamma distribution. For the image x we choose an edge-preserving Laplace Markov random field (LMRF) prior, cf section 2.3, with an unknown scale parameter d−1, where d is also assumed to follow a Gamma distribution. The Bayesian Problem then takes the form




The parameters d and s are called hyperparameters (see section 2.1). In CUQIpy the syntax closely matches the mathematical specification of the Bayesian Problem:

Download figure:
Standard image High-resolution imageHere, lambda functions are used to define relations through algebraic operations on a parameter, e.g.  and
and  ; and the 'geometry' keyword to specify that the LMRF prior is defined on the domain of the forward operator A, which is represented by a so-called Image2D geometry—see section 3.
; and the 'geometry' keyword to specify that the LMRF prior is defined on the domain of the forward operator A, which is represented by a so-called Image2D geometry—see section 3.
With the Bayesian Problem fully specified, we can immediately ask CUQIpy to perform a UQ analysis of the problem:

Download figure:
Standard image High-resolution imageThe UQ() method analyzes the problem, selects a suitable sampler, samples the posterior distribution, and returns a summary and selected visualizations of the results, as shown in figure 1. The deblurred image (posterior mean) demonstrates the impact of the LMRF prior in that it preserves the edge details in the image. The posterior width is also shown; providing an estimation of uncertainty in the deblurring, here highlighting that edges are subject to the most uncertainty.
In addition to estimating the image
x
, also the hyperparameters d and s are estimated along with their uncertainty, which can be illustrated in various ways but is omitted here for brevity. The true value of s is defined to be  in the Deconvolution2D test problem, and the posterior mean and
in the Deconvolution2D test problem, and the posterior mean and  credibility interval are found to be
credibility interval are found to be  and
and ![$[7.535\cdot 10^4, 7.744\cdot 10^4]$](https://content.cld.iop.org/journals/0266-5611/40/4/045009/revision2/ipad22e7ieqn8.gif) . A true value for d is not known but its posterior mean and credibility interval are found to be
. A true value for d is not known but its posterior mean and credibility interval are found to be  and
and ![$[3.824\cdot 10^1, 3.918\cdot 10^1]$](https://content.cld.iop.org/journals/0266-5611/40/4/045009/revision2/ipad22e7ieqn10.gif) .
.
This illustrates the high-level usage of CUQIpy, where the user does not need to select a specific sampler or tune any parameters since CUQIpy does so automatically based on the problem structure. The following sections describe what happens 'under the hood' and how users can fully select and configure problem specification, samplers, visualization, etc.
1.3. Overview and notation
The present paper, which is the first of a two-part series, focuses on the core functionality of the CUQIpy package and its use for linear and nonlinear inverse problems. The companion paper [1] is dedicated to the modeling and UQ analysis of inverse problems based on partial differential equations (PDEs). We emphasize that both papers are written from a user's perspective, with a focus on descriptions of the software's functionality and examples of the use of CUQIpy.
Our paper is organized is follows. Section 2 briefly summarizes the theoretical background of Bayesian inference and computational UQ for inverse problems, and section 3 gives an overview of some important tools provided by CUQIpy demonstrated by a deconvolution problem. This is followed by three case studies that demonstrate the capabilities of CUQIpy: section 4 presents a case study of gravity anomaly detection with a nonlinear forward model illustrating how users can specify and solve their own inverse problem with CUQIpy. Section 5 describes a case study in x-ray CT using the CUQIpy-CIL plugin. Section 6 describes how the CUQIpy-PyTorch plugin expands CUQIpy with automatic differentation from PyTorch and efficient sampling using Pyro and demonstrates this by specifying and solving the well-known benchmark problem 'Eight Schools' [16, 49]. Finally, section 7 discusses the current results and capabilities of CUQIpy, outlines future directions, and concludes the work.
We use the following notation: bold upper case such as
A
and  denote a linear and non-linear operator, respectively, with
I
p
denoting the p × p identity matrix; bold lower case such as
x
denotes a vector-valued random variable, and lower case such as s and f denotes a scalar random variable or a scalar function with p denoting a probability density function; the superscript k in
denote a linear and non-linear operator, respectively, with
I
p
denoting the p × p identity matrix; bold lower case such as
x
denotes a vector-valued random variable, and lower case such as s and f denotes a scalar random variable or a scalar function with p denoting a probability density function; the superscript k in  denotes the kth state in a Markov chain. A superscript text on a random variable such as
denotes the kth state in a Markov chain. A superscript text on a random variable such as  denotes a realization.
denotes a realization.
2. Theoretical background
This section sets the stage for describing the software by summarizing important definitions and concepts in UQ; see [2, 13, 29] for more details and background.
2.1. Bayesian inverse problems
Many discretized inverse problems take their basis in the generic formulation

where the vector
y
denotes the noisy data, the vector
x
represents the solution parameters to be found, and the operator
A
(which, in the linear case, is a matrix) represents the forward model. In the Bayesian setting, the solution parameters
x
and the data
y
are random variables. A statistical model for (2) is then characterized by the joint probability distribution
 of the parameters and data.
of the parameters and data.
A useful representation of the joint distribution is to list what is known or assumed about the parameters and data, as well as their relation through what we call a Bayesian Problem. In statistics this is sometimes referred to as a generative model [16, 17]. For the joint distribution  associated with (2), we define the generic Bayesian Problem in terms of two distributions:
associated with (2), we define the generic Bayesian Problem in terms of two distributions:


We use the terms prior and data distribution for the distributions associated with the solution parameters and the data, respectively, in (3). For brevity in our notation, the statistical dependence  is omitted from the left-hand-side in (3b
).
is omitted from the left-hand-side in (3b
).
In Bayesian inverse problems, the goal is to infer the solution parameters given a particular realization of the data. The posterior distribution
 characterizes the distribution of the solutions
x
to the inverse problem, given the data
y
. Via Bayes' theorem for continuous probability densities, we can express the posterior as
characterizes the distribution of the solutions
x
to the inverse problem, given the data
y
. Via Bayes' theorem for continuous probability densities, we can express the posterior as

Given fixed observed data  ,
,  considered as a function of
x
is known as the likelihood function or just likelihood, denoted
considered as a function of
x
is known as the likelihood function or just likelihood, denoted  ). Furthermore,
). Furthermore,  is a normalization constant that is usually omitted and we write the posterior as proportional to the product of the likelihood and prior:
is a normalization constant that is usually omitted and we write the posterior as proportional to the product of the likelihood and prior:

In CUQIpy the user is generally only expected to (i) define statistical assumptions about parameters and data via a Bayesian Problem and (ii) provide observed data. CUQIpy will then automatically formulate the posterior distribution by combining likelihood(s) and prior(s) through Bayes' theorem.
2.2. Hyperparameters
It is often the case that the distributions depend on one or more unknown parameters. In the Bayesian paradigm, we can assign probability densities to them and include them in the Bayesian Problem. For example assuming the distributions in (3) depend on hyperparameters
d and s respectively, the generic Bayesian Problem for the joint probability distribution  would be
would be




The posterior associated with this Bayesian Problem becomes

meaning that the task is now to infer about x as well as d and s, which is indeed possible in CUQIpy. This is usually referred to as hierarchical modeling and we refer to such additional model parameters as hyperparameters. See, e.g. [2, section 5.2] for details. Another example in CUQIpy is given in section 3.5.
2.3. Markov random field priors
In addition to well-known distributions such as the Gaussian, gamma and inverse-gamma, we also need a few distributions associated with Markov random fields. In CUQIpy, these are specifically used for the modeling of certain priors. For definitions and details about Markov random fields, see [32].
Let xi
denote the elements of the n-dimensional random vector
x
and consider the differences  for
for  . Then, following [2, chapter 4], we say that
x
is a zero-mean Gaussian Markov random field (GMRF) if
. Then, following [2, chapter 4], we say that
x
is a zero-mean Gaussian Markov random field (GMRF) if  , where d is a precision parameter. With zero boundary conditions (other conditions are also possible), this implies that
, where d is a precision parameter. With zero boundary conditions (other conditions are also possible), this implies that

which we for brevity denote  . When used as a prior, this GMRF induces regularity (smoothness) on the samples—similar to first-order Tikhonov regularization [22, section 8.1]. Higher-order differences can also be used in a GMRF (see, e.g. [50]).
. When used as a prior, this GMRF induces regularity (smoothness) on the samples—similar to first-order Tikhonov regularization [22, section 8.1]. Higher-order differences can also be used in a GMRF (see, e.g. [50]).
In some applications we prefer a prior that allows less regularity—giving samples that may resemble total-variation regularized solutions [22, section 8.6]. This is possible if we replace the Gaussian distribution for  with a Laplace or Cauchy distribution, i.e. we assume
with a Laplace or Cauchy distribution, i.e. we assume  or
or  . Again assuming zero boundary conditions, the corresponding densities for
x
are, respectively,
. Again assuming zero boundary conditions, the corresponding densities for
x
are, respectively,

and

When used as a prior  they are called Laplace and Cauchy MRF priors, respectively, and we use the short-hand notations
they are called Laplace and Cauchy MRF priors, respectively, and we use the short-hand notations  and
and  , for a scalar parameter
, for a scalar parameter  .
.
If
 represents a square N × N image with pixel values
represents a square N × N image with pixel values  for
for  , and the vector
, and the vector  of length
of length  consists of the columns of
consists of the columns of  stacked on top of each other, then we can define a GMRF in which the horizontal and vertical differences between pixel values follow
stacked on top of each other, then we can define a GMRF in which the horizontal and vertical differences between pixel values follow  . In this case
. In this case  and, with zero boundary conditions, the precision matrix
Q
in (8) takes the form
and, with zero boundary conditions, the precision matrix
Q
in (8) takes the form  in which ⊗ denotes the Kronecker product. Similarly, for LMRF and CMRF with zero boundary conditions the densities take the form
in which ⊗ denotes the Kronecker product. Similarly, for LMRF and CMRF with zero boundary conditions the densities take the form

and

with zero values in all boundary pixels Xij just outside the N × N domain. For more details, see [2, section 4.3] and [54].
2.4. Sampling methods in CUQIpy
Selecting the most suited sampling method for exploring the posterior in a particular problem—as well as configuring and running it to obtain high-quality samples—is not always straightforward. Indeed, one of the aims of CUQIpy is to aid the user in this by providing automated sampler selection and configuration for problems of recognized structure.
In a few cases a closed-form expression exists for the posterior, which can be used for direct sampling. A classic example is that of a Gaussian prior and Gaussian data distribution with linear forward model which results in the posterior being Gaussian as well. For problems of modest size one can exploit this for efficient direct sampling based on the analytical expression. This is automatically detected and used by CUQIpy in BayesianProblem.
In some cases it is possible to obtain a tractable and computationally efficient approximation of the posterior distribution. One such example is the Laplace approximation [19, 53], with which one obtains a Gaussian distribution centered at the maximum-a-posteriori (MAP) estimate having covariance of the inverse Hessian of the negative logarithm of the targeted posterior distribution.
In most cases, however, computation of samples are based on Markov chain Monte Carlo (MCMC) algorithms [44]; these produce a sequence of samples  that represents a Markov chain, whose stationary distribution is the target posterior. The initial part of the chain, called the burn-in, is discarded because these samples may not be representative of the desired distribution. Moreover, we typically thin the sequence of samples to reduce the correlation.
that represents a Markov chain, whose stationary distribution is the target posterior. The initial part of the chain, called the burn-in, is discarded because these samples may not be representative of the desired distribution. Moreover, we typically thin the sequence of samples to reduce the correlation.
We now summarize some of the MCMC samplers that are available in CUQIpy, highlighting their unique features and which problems they can be used for. For reviews of the methods we refer to [7, 38, 44]. CUQIpy also provides several common MCMC diagnostics to help monitor convergence and independence of samples; these are described at the end of this section.
2.4.1. Metropolis–Hastings (MH) sampling [26].
This classical method uses a two-stage procedure with proposal step and acceptance/rejection steps. The first step computes a proposal  from the density
from the density  which is the conditional probability of
x
given the proposed state
which is the conditional probability of
x
given the proposed state  . The second step computes the acceptance ratio
. The second step computes the acceptance ratio

which expresses the probability of accepting  . At state k of the MH algorithm, the next state
. At state k of the MH algorithm, the next state  is chosen by first sampling a candidate point
is chosen by first sampling a candidate point  from the proposal density
from the proposal density  . Then
. Then  is accepted with probability (13) and
is accepted with probability (13) and  , otherwise it is rejected and
, otherwise it is rejected and  .
.
2.4.2. Preconditioned Crank–Nicolson (pCN) sampling [12].
This method assumes that the prior has a Gaussian distribution. It uses the Crank–Nicolson finite-difference scheme to solve an underlying stochastic differential equation (SDE) that is invariant with respect to the posterior [21, 47]. When we choose the prior covariance matrix
S
as preconditioner, we obtain the following mechanism for producing the proposed state  in the MH method, see [12]:
in the MH method, see [12]:

Given a current state  , it follows from (14) that the associated proposal distribution is Gaussian with mean vector
, it follows from (14) that the associated proposal distribution is Gaussian with mean vector  and covariance matrix
and covariance matrix  , where
, where  is a tunable parameter controlling the acceptance rate. We remark that while pCN is designed for a Gaussian prior, it can be extended to more general priors by applying a transformation to a standard Gaussian distribution.
is a tunable parameter controlling the acceptance rate. We remark that while pCN is designed for a Gaussian prior, it can be extended to more general priors by applying a transformation to a standard Gaussian distribution.
2.4.3. Gradient-based sampling methods based on the Langevin SDE [37, 46].
As mentioned above, the pCN method is based on the numerical solution of a certain SDE. There are, in fact, many sampling methods that take such an approach; here we focus on methods based on the overdamped Langevin SDE

where  and
and  is standard Brownian motion in
is standard Brownian motion in  . Under certain conditions, as
. Under certain conditions, as  the solution
the solution  follows a distribution with density
follows a distribution with density  .
.
The connection between (15) and posterior sampling methods arises when we choose

and apply a numerical scheme to solve the SDE, thus producing a sequence of discretized solutions  . The standard choice is the forward Euler methods which leads to a scheme known as the unadjusted Langevin algorithm (ULA):
. The standard choice is the forward Euler methods which leads to a scheme known as the unadjusted Langevin algorithm (ULA):

where a new  is drawn in each step, and h is a step size that controls the convergence and discretization error. We note that ULA can be interpreted as using a proposal distribution
is drawn in each step, and h is a step size that controls the convergence and discretization error. We note that ULA can be interpreted as using a proposal distribution  but without an acceptance/rejection step, hence the name unadjusted and we stress that it is not an MH method.
but without an acceptance/rejection step, hence the name unadjusted and we stress that it is not an MH method.
A related method, known as the Metropolis-adjusted Langevin algorithm (MALA), applies the MH acceptance/rejection step (13) to the above-mentioned ULA proposal which guarantees that samples follow the posterior distribution. More advanced gradient-based methods are the Hamiltonian Monte Carlo method and its adaptive version the NUTS; we refer to [7, 34].
2.4.4. Randomize-then-optimize (RTO) sampling [2, 3].
This method, which was originally designed for nonlinear problems, uses an acceptance/rejection step (13) similar to the MH method, but the proposal strategy is different in that it involves solution of a (nonlinear) least-squares problem.
Our current implementation targets linear problems (Gaussian posteriors) and does not require an acceptance/rejection step; we refer to this version as linear RTO. We draw an independent sample of the proposal  by solving a linear least-squares problem:
by solving a linear least-squares problem:

where  . Moreover,
µ
is the prior mean and
C
is a matrix such that
. Moreover,
µ
is the prior mean and
C
is a matrix such that  equals the precision matrix
Q
for the prior; typically,
C
is the Cholesky factor of
Q
. The independence of the computed posterior samples depends on the accuracy of the algorithm used to solve (18); in CUQIpy we use the well-known CGLS iterative algorithm (see, e.g. [22, section 6.3.2]) which is suited for large-scale problems. The linear RTO algorithm can be used to compute samples from the unadjusted Laplace approximation method proposed in [58], which is tailored to linear problems with LMRF priors.
equals the precision matrix
Q
for the prior; typically,
C
is the Cholesky factor of
Q
. The independence of the computed posterior samples depends on the accuracy of the algorithm used to solve (18); in CUQIpy we use the well-known CGLS iterative algorithm (see, e.g. [22, section 6.3.2]) which is suited for large-scale problems. The linear RTO algorithm can be used to compute samples from the unadjusted Laplace approximation method proposed in [58], which is tailored to linear problems with LMRF priors.
2.4.5. Gibbs sampling [18].
This method is useful when the posterior is expressed as a joint distribution via conditional densities, and in connection with hierarchical models such as (7). Specifically, Gibbs sampling is useful when computing samples from the joint distribution is impractical, but drawing samples from the conditional distributions of given parameter components is feasible.
To illustrate Gibbs sampling, consider a generic joint distribution  ; this could e.g. be the joint posterior in (7). The next state in the chain for
x
,
y
,
z
is generated from the previous state as follows:
; this could e.g. be the joint posterior in (7). The next state in the chain for
x
,
y
,
z
is generated from the previous state as follows:



The special case of sampling a single random vector involves treatment of the elements component-by-component, and this scheme is known as the component-wise Metropolis–Hastings (CWMH) algorithm. There are different strategies to choose the scanning order of a Gibbs sampler; see [14, 38].
2.4.6. Conjugacy-based samplers.
Application of the Gibbs sampler is useful when we can easily sample from the posterior distribution of each parameter conditioned on all the other ones. For example, in case of a conjugate prior (where the posterior is in the same probability distribution family as the prior), the conditionals are often available in closed form. In some cases pairs of distributions can also be approximated by a conjugate relation; this is the case, e.g. for the Gaussian-LMRF pair [58]. In other cases it is necessary to use MCMC methods to sample (some of) the conditionals; in this case the Gibbs sampler is referred to as hybrid. A classical example is the so-called Metropolis-within-Gibbs algorithm [45]. One of the strengths of CUQIpy is to automatically detect when conditionals are easy to sample and use this within Gibbs sampling.
2.5. Common MCMC diagnostics
Samples computed via MCMC methods are dependent. The effect of dependencies on the accuracy of MC estimates can be quantified in terms of the autocorrelation between the samples,  , assuming they have already reached stationarity. For dependent samples, the variance of an MC estimate—compared to estimates based on independent samples—is modified by a factor τ called the integrated autocorrelation time (IACT) given by
, assuming they have already reached stationarity. For dependent samples, the variance of an MC estimate—compared to estimates based on independent samples—is modified by a factor τ called the integrated autocorrelation time (IACT) given by

where  is the number of samples,
is the number of samples,  is the sample estimate of the normalized autocorrelation function for lag
is the sample estimate of the normalized autocorrelation function for lag  . Related to this is the effective sample size (ESS) which expresses the amount by which autocorrelation within the chain influences uncertainty in the computed estimates:
. Related to this is the effective sample size (ESS) which expresses the amount by which autocorrelation within the chain influences uncertainty in the computed estimates:

ESS and the so-called R-hat diagnostic [59] are available in CUQIpy provided via ArviZ [30]. For more background on MCMC diagnostics, we refer the reader to [48].
3. Specifying and solving Bayesian inverse problems with CUQIpy
In the following sections we describe the most important software components of CUQIpy. We first provide an overview of the package and then take a step-by-step approach through some fundamental tools to illustrate a typical process of specifying and solving a Bayesian inverse problem.
3.1. Overview
CUQIpy is a Python package for Computational UQ for Inverse Problems developed at the Technical University of Denmark (DTU). It is available from:
https://cuqi-dtu.github.io/CUQIpy/ along with information on how to install and get started, full documentation, and numerous demos and tutorials. The package is released under a permissive Apache v2.0 license and is developed fully open source on GitHub.
CUQIpy is object-oriented and consists of a number of classes representing the building blocks needed to specify and solve Bayesian inverse problems. This includes distributions, forward models, samplers and so-called geometry for representing the context of a problem e.g. whether 1D or 2D (figure 2). In addition, a number of plug-ins are available as separate packages that expand the functionality of CUQIpy:

Figure 2. Diagram of CUQIpy with some of the main modules shown, as well as the plug-ins that each expand the core functionality.
Download figure:
Standard image High-resolution imageOnce CUQIpy is installed, one may import the required components, for example—and for completeness—these are the classes needed for the examples in the present and introduction sections:

Download figure:
Standard image High-resolution image3.2. Test problems and forward models
CUQIpy provides a number of testproblem (cf table 1) which contain pre-made, configurable test problems. Those considered in this paper take the generic form  , see (2), and they provide a forward model
A
, the underlying true signal
, see (2), and they provide a forward model
A
, the underlying true signal  , as well as a clean data set
, as well as a clean data set  and an observed noisy data set
and an observed noisy data set  . Similar test problems, discussed in the companion paper [1], take their basis in a PDE formulation.
. Similar test problems, discussed in the companion paper [1], take their basis in a PDE formulation.
Table 1. First block: test problems in CUQIpy not involving a PDE. Second block: test problems in CUQIpy involving a PDE and covered in companion article [1]. Third block: test problem in CUQIpy-CIL.
| Test problem name | Description |
|---|---|
| Deconvolution1D | 1D signal deblurring |
| Deconvolution2D | 2D image deblurring |
| Abel1D | Rotationally symmetric computed tomography |
| WangCubic | Problem with nonlinear two-parameter forward model |
| Heat1D | Discrete heat problem (time-dependent linear PDE) |
| Poisson1D | Discrete 1D Poisson problem (steady-state linear PDE) |
| ParallelBeam2D | 2D parallel-beam CT using CIL |
As running examples for this section we set up two Deconvolution1D linear test problems  (recall also the Deconvolution2D test problem from section 1.2). First, we consider a smooth signal given by a sinc function which is subject to the default Gaussian blur, i.e. it is convolved with a Gaussian function:
(recall also the Deconvolution2D test problem from section 1.2). First, we consider a smooth signal given by a sinc function which is subject to the default Gaussian blur, i.e. it is convolved with a Gaussian function:

Download figure:
Standard image High-resolution imageSecond, we consider a piecewise constant signal (see documentation for further configuration options for signal type, blurring point spread function, noise level etc):

Download figure:
Standard image High-resolution imageHere we simply return the main components of the test problem, namely the forward model A, the observed data y_obs and additional information about the test problem in info. The info contains information about the test problem including the underlying true signal and exact data without noise that we extract here for convenience:

Download figure:
Standard image High-resolution imageIn CUQIpy, deterministic vectors such as  or
or  are represented by our CUQIarray data structure, which includes information about the type of signal in an attribute geometry. We can take a look at this for example for the clean signal
are represented by our CUQIarray data structure, which includes information about the type of signal in an attribute geometry. We can take a look at this for example for the clean signal

Download figure:
Standard image High-resolution imagewhich for the 1D cases tells us that the signal has 128 elements and is of a 1D type:

Download figure:
Standard image High-resolution imageCUQIarray supports plotting, and the geometry also makes context-aware plotting simple by automatically making the correct type of plot associated with the class (see figures 1 and 3):

Download figure:
Standard image High-resolution image
Figure 3. Deconvolution1D test problem with Gaussian blur. Left: a sinc function for the exact signal, the exact blurred and the blurred and noisy observed signal, and the additive noise. Right: Same for exact signal 'square'.
Download figure:
Standard image High-resolution imageIn the last line we make use of the fact that CUQIarray is subclassed from conventional NumPy arrays meaning that all algebra is available; here we use that to determine and plot the noise that was added by the test problem to the clean blurred signal.
The forward model A is of the type LinearModel which has methods A.forward and A.adjoint to compute forward and adjoint operations on a vector; as well as short hand NumPy-style matrix-vector multiplication syntax:

Download figure:
Standard image High-resolution imageThe last line explicitly creates and applies the adjoint operator, here the transposed matrix  . CUQIpy handles non-linear forward models using the short hand syntax:
. CUQIpy handles non-linear forward models using the short hand syntax:

Download figure:
Standard image High-resolution imageTable 2 gives an overview of the types of models provided by CUQIpy as well as the CUQIpy-CIL plugin. Users can easily specify their own linear or nonlinear forward model representing the inverse problem of interest; an example is given in section 4.
Table 2. Forward models in CUQIpy (top) and CUQIpy-CIL (bottom).
| Model name | Model description |
|---|---|
| LinearModel | Linear model 
|
| Model | General linear or non-linear model 
|
| PDEModel | Model represented by a partial differential equation |
| CILModel | General model for CT problem with CIL |
| ParallelBeam2DModel | 2D parallel-beam scan model |
| FanBeam2DModel | 2D fan-beam scan model |
| ShiftedFanBeam2DModel | 2D fan-beam scan with shifted source/detector model |
Models are 'aware' of the spaces associated with the operator; in terms of geometries for the range and domain; these can be queried by

Download figure:
Standard image High-resolution imageand since for the current deblurring examples the range and domain are identical both of these return the same geometry, in the 1D case Continuous1D(128,). We can also query the dimensions and store these for later convenience, along with a zero vector:

Download figure:
Standard image High-resolution imageA variety of different geometries is provided (table 3) handling for example discrete labelled data as well as providing a way to parametrize solutions in terms of basis functions or a finite element mesh. Several examples of the use of geometries are given later (e.g. in section 4) and in the companion paper [1].
Table 3. Overview of common geometry classes in CUQIpy. A geometry represents the type of parameter, i.e. whether its elements are pixel values of an image or coefficients in an expansion etc and enables dedicated plotting according to signal type. The geometries are also responsible for transforming the underlying parameter vector to the so-called function values that are then passed to the forward model operator making the forward Model class agnostic to the array implementation.
| Geometry name | Description |
|---|---|
| Continuous1D | Signal in one (space, time, etc) dimension |
| Continuous2D | Signal in two (space or similar) dimensions |
| Image2D | Pixelated image signal |
| Discrete | Collection of individual labelled scalar parameters |
| MappedGeometry | Maps another geometry by a callable function |
| KLExpansion | Karhunen–Loéve expansion of 1D signal |
| StepExpansion | Piecewise constant/step expansion of 1D signal |
3.3. Probability distributions and simple sampling
To specify prior and data distributions in a Bayesian Problem we need implementations of probability distributions and CUQIpy provides the Distribution class for this.
While in general the data distribution should be chosen based on knowledge or assumptions about noise and/or the forward model, choosing a prior is somewhat more of a subjective task. Gaussian priors are often used, in part due to simplicity and because they often lead to computationally efficient sampling, but also because they provide a flexible framework for constructing expressive priors. One such example is GMRFs, which are often used to express smoothness in the prior [2], akin to Tikhonov regularization. On the other hand, Laplace and Cauchy distributions can be used as sparsity-inducing priors due to their heavy tails, while Laplace and Cauchy Markov random field (LMRF and CMRF) priors provide edge-preservation [2], similarly to TV regularization.
As of now, CUQIpy provides a selection of commonly used distributions, see table 4, including those mentioned above. Furthermore, the framework is general and it is easy to add new distributions. Users can also set up their own distributions through UserDefinedDistribution by providing a function to evaluate the logarithm of the PDF and/or a function to generate a single sample.
Table 4. Common distribution classes in CUQIpy. First block: simple distributions. Second block: composite distributions and Markov random fields. Third block: distributions used to specify Bayesian inverse problems. Fourth block: utility distribution classes providing access to benchmark and user-defined distributions.
| Distribution name | Description |
|---|---|
| Beta | Beta distribution |
| Cauchy | Cauchy distribution |
| Gamma | Gamma distribution |
| Gaussian | Multivariate Gaussian distribution |
| InverseGamma | Inverse Gamma distribution |
| Laplace | Laplace distribution |
| Lognormal | Log-normal distribution |
| Uniform | Uniform Distribution |
| CMRF | Cauchy Markov random field |
| GMRF | Gaussian Markov random field |
| JointGaussianSqrtPrec | Gaussian of multiple square-root precision matrices |
| LMRF | Laplace Markov random field |
| JointDistribution | Joint distribution of multiple parameters |
| Posterior | Posterior distribution |
| DistributionGallery | Collection of benchmark distributions |
| UserDefinedDistribution | Defined by functions for logarithm of probability density function logpdf and/or sample |
The rest of this section illustrates different choices of priors and how they perform when applied to a Bayesian inverse problem with a smooth signal and a piecewise constant signal, respectively.
To express an i.i.d. Gaussian prior on x with zero mean and standard deviation 0.1,

The CUQIpy command would be

Download figure:
Standard image High-resolution imageThe last part equips the distribution with the domain geometry of A ; this is not required but will prove convenient.
Distributions can evaluate probability density function (pdf), cumulative density function (cdf), logarithm of pdf (logpdf) and gradient of the logpdf (gradient) for a particular element, e.g.

Download figure:
Standard image High-resolution imageDistributions can be sampled; for simple distributions this is done directly (i.e. without MCMC) using the sample method. Here we generate three samples and plot them:

Download figure:
Standard image High-resolution imageSampling returns a Samples object, which knows of the geometry from the distribution, so that the generated samples can automatically be displayed in the appropriate way, see figure 4 for 1D and 2D cases of the Gaussian distribution.

Figure 4. Top left: three samples from the Gaussian distribution for the 1D geometry. Top right: two samples for the 2D geometry. Bottom left: three samples from GMRF on 1D geometry. Bottom right: two samples for the 2D geometry.
Download figure:
Standard image High-resolution imageAnother distribution example is a GMRF prior as discussed in section 2.3:

which can be specified both in 1D as

Download figure:
Standard image High-resolution imageand in 2D by passing an Image2D geometry as in section 1.2; samples shown in figure 4.
As previously discussed, parameters such as a standard deviation may not be known and to be inferred along with the main parameter of interest. To set the stage for modelling of this in a later section we describe here conditional distributions in CUQIpy. For example in the Gaussian case, we can let d be the unknown standard deviation

by expressing this in CUQIpy using the syntax

Download figure:
Standard image High-resolution imagePrinting shows this is a conditional distribution, expressing that x is conditional on d:

Download figure:
Standard image High-resolution imageHere a simple squared dependence on d is specified via a lambda function; it is possible to express more involved dependencies in this way. We can now condition on specific values of d to produce a fully specified distribution, from which sampling is possible, e.g.

Download figure:
Standard image High-resolution imageproduces 10 samples from  for the two choices d = 0.1 and d = 0.3, respectively.
for the two choices d = 0.1 and d = 0.3, respectively.
A common use case for conditional distributions is to express the data distribution for an inverse problem, in our example the conditional distribution  . Assuming Gaussian noise (with a known noise level) on the measured data, this distribution is given by
. Assuming Gaussian noise (with a known noise level) on the measured data, this distribution is given by

We can express this in CUQIpy by

Download figure:
Standard image High-resolution imagewhere the use of @ emphasises the structural information that A is a linear operator. In general, lambda (anonymous) functions are used to define algebraic expressions on parameters, with some operations like A @ x being natively supported without lambda expressions. More native algebraic operations are planned in future versions of CUQIpy. In this scenario, the previously defined distribution x is employed to establish the dependency.
Calling print(y) shows that this is a conditional distribution on x:

Download figure:
Standard image High-resolution imageAs we shall see in the following section this general syntax is used for specifying a Bayesian Problem to be solved for given observed data in a simple and intuitive way. Here, we show how one can simulate new data realizations by conditioning on the true signal, sampling the resulting distribution and plotting the resulting samples:

Download figure:
Standard image High-resolution imageThese new example data realizations are shown in figure 5 top left.

Figure 5. Results for Sinc example. Top left: samples of data distribution given  . Top center: ML, MAP,
. Top center: ML, MAP,  and
and  . Top right: posterior mean and 95% credibility interval compared to
. Top right: posterior mean and 95% credibility interval compared to  . Bottom left: kernel density estimate from posterior samples of s. Bottom right: trace (chain) of posterior samples of s compared to
. Bottom left: kernel density estimate from posterior samples of s. Bottom right: trace (chain) of posterior samples of s compared to  .
.
Download figure:
Standard image High-resolution image3.4. Bayesian modelling: specifying inverse problems for UQ analysis
We now have all the tools we need to specify a complete Bayesian Problem in CUQIpy. We consider the 1D deblurring sinc case and choose a GMRF prior on the signal x and assume Gaussian data distribution:


which in CUQIpy is specified as

Download figure:
Standard image High-resolution imageThe most automated high-level approach is to form a BayesianProblem:

Download figure:
Standard image High-resolution imagePrinting demonstrates how this represents a joint distribution  :
:

Download figure:
Standard image High-resolution imageNext, we specify the observed data  to produce a posterior distribution
to produce a posterior distribution

Download figure:
Standard image High-resolution imageMaximum likelihood (ML) and maximum a posteriori (MAP) estimates are given:

Download figure:
Standard image High-resolution imagewhich are CUQIarrays containing the geometry so may be plotted directly, see figure 5.We can also generate a desired number of posterior samples using MCMC by

Download figure:
Standard image High-resolution imageThis will analyze the problem structure and try to determine a suitable sampler. In the present case of a linear forward model and Gaussian prior and data distribution (recall that GMRF is a Gaussian with special structure) the LinearRTO sampler is efficient and selected. This is possible for a range of problem types, with more being added. More details and how to manually specify a sampler will be described in section 3.6.
The MCMC samples are returned in a Samples object that as we have seen before offers various plotting options such as the posterior mean and credibility interval, with the option to compare with the exact:

Download figure:
Standard image High-resolution imageFinally, we mention the convenience 'UQ' method that carries out the above steps and generates selected solution plots:

Download figure:
Standard image High-resolution image3.5. Hierarchical modeling
Until now, we assumed a known noise level, i.e. the standard deviation on the noise in the data distribution. Often this is not known and we can then include this in the set of parameters to be estimated along with x , as mentioned in section 2.1. Such a hyperparameter is often modelled by a Gamma distribution on the precision (inverse variance), since it forms a conjugate pair with the Gaussian distribution, and this can be exploited for efficient sampling. The problem then takes the form



which we can specify in CUQIpy as (noting again the near-math syntax)

Download figure:
Standard image High-resolution imageNote for illustration purposes we use the prec keyword to define the Gaussian with a precision rather than the default covariance used earlier. The same result can be achieved by using the syntax cov = lambda s: 1/s.
As before we set up a Bayesian Problem, this time also including s, and provide the observed data  , leaving
x
and s to be estimated.
, leaving
x
and s to be estimated.

Download figure:
Standard image High-resolution imageWe can then sample the posterior distribution; this will detect that multiple parameters are to be estimated and employ a Gibbs sampler, while making use of any conjugacy, here between the Gaussian and Gamma distributions, to employ efficient samplers for each of the conditional distributions.

Download figure:
Standard image High-resolution imageThe sampling outputs the automatically determined sampling strategy selected for the posterior:

Download figure:
Standard image High-resolution imageFor a multi-parameter problem, the Samples object returned contains chains for each parameter that can be individually picked out and plotted, for example to plot the trace of s and the credibility interval for x compared to the ground truth s_true = 1/0.01**2 (recall s was the precision) and x_true respectively, we call

Download figure:
Standard image High-resolution imageThe figure in figure 5 shows that the posterior for s centers around the known true value  and the plot of individual samples has the 'fuzzy worm' appearance suggesting that samples are independent. It is also possible to compute the ESS, chain auto correlation and more via the Samples object.
and the plot of individual samples has the 'fuzzy worm' appearance suggesting that samples are independent. It is also possible to compute the ESS, chain auto correlation and more via the Samples object.
We note that the 2D deconvolution example in the introduction (section 1) is set up and solved in precisely the same way. This highlights the powerful abstraction layer in CUQIpy that allows problems of different types, dimensions etc to be modelled and solved using almost identical code.
3.6. Manually choosing the sampling method
The class BayesianProblem is aimed at automating the sampling process allowing the user to focus on just the modelling. For full control, it is possible to set up and sample the problem manually. CUQIpy provides a range of samplers (table 5) that can be employed in case the automated sampling is not available or unsatisfactory. We demonstrate this for the square 1D deconvolution test problem with three different choices of prior.
Table 5. Samplers in CUQIpy grouped as they are presented in section 2.
| Sampler name | Description |
|---|---|
| MH | Metropolis–Hastings |
| pCN | preconditioned Crank–Nicolson |
| ULA | Unadjusted Langevin algorithm |
| MALA | Metropolis-Adjusted Langevin algorithm |
| NUTS | No U-Turn Sampler |
| LinearRTO | Linear Randomize-Then-Optimize |
| UGLA | Unadjusted Laplace Approximation |
| Gibbs | Gibbs sampler for joint distributions |
| CWMH | Component-Wise Metropolis–Hastings |
| Conjugate | Conjugate sampler |
| ConjugateApprox | Approximate conjugate sampler |
For the smooth sinc signal, the GMRF produced accurate MAP and posterior mean solutions, but for non-smooth square signal we expect edge-preserving priors to be more suitable. We compare GMRF with LMRF and CMRF by letting

Download figure:
Standard image High-resolution imagein combination with

Download figure:
Standard image High-resolution imageAs was seen from the output of printing a Bayesian Problem earlier, it contains a target joint distribution over all the parameters of interest. To sample manually, instead of setting up the Bayesian Problem we set up this joint distribution over the
x
and
y
parameters, and—being a distribution—we condition it on the observed data  to obtain the posterior distribution:
to obtain the posterior distribution:

Download figure:
Standard image High-resolution imageEach of the three priors have a certain structure that can be exploited for efficient sampling by means of a choosing a suitable sampler

Download figure:
Standard image High-resolution imageAs already mentioned the LinearRTO sampler is a good choice for the GMRF case. For the LMRF case we use a dedicated sampler that uses a Gaussian approximation of the prior for efficiency known as the unadjusted Laplace approximation [58] and denoted as UGLA in CUQIpy. In case of CMRF, we exploit that the density function is differentiable and employ the gradient-based sampler NUTS. We note that these choices of samplers exactly match what is done by BayesianProblem for GMRF, LMRF, and CMRF priors, respectively.
Having specified the posterior and a sampler for each choice of prior, we proceed to generate a desired number of samples (1000), after a burn-in phase of 200 samples:

Download figure:
Standard image High-resolution imageafter which posterior information can be plotted:

Download figure:
Standard image High-resolution imageThe MAP and ML estimates can also be manually computed via the solver module of CUQIpy, but this is omitted for brevity.
The results of the UQ analysis are shown in figure 6. Clearly the GMRF prior (which imposes smoothness) is not suitable for the piecewise constant signal: it produces a smooth posterior mean solution with large variability. We also plot a single sample (the 500th) which confirms large variability. The LMRF prior and especially the CMRF prior produce solutions that much better resembles a piecewise constant signal, in particular the MAP solution, and much less variability.

Figure 6. UQ results for the square signal. Left: GMRF prior for this test problem. Center: LMRF prior. Right: CMRF prior. Top row: posterior mean and 95% credibility interval compared to exact solution. Bottom row: MAP estimate and a posterior sample compared to exact solution.
Download figure:
Standard image High-resolution imageThe samplers also return diagnostic information into the samples object, as demonstrated in section 4. A number of plotting methods are available in the samples objects; some are already demonstrated, and some will be illustrated in the following case studies.
Having demonstrated some of the key concepts of CUQIpy on a simple test problem, we now present three more complex case studies designed to highlight the capabilities and flexibility to model, solve and conduct UQ analysis for inverse problems. Further examples involving PDE-based inverse problems are given in the companion paper [1].
4. Case study: user-specified nonlinear model with a gravity anomaly
In this case study we demonstrate how CUQIpy can be applied to solve a non-linear inverse problem. We focus on an example from geophysics, where a subsurface density contrast gives rise to a gravity anomaly. This problem is not included in CUQIpy's suite of test problems, and hence it illustrates how a user-specified model can be handled in CUQIpy. We also demonstrate how different samplers can easily be applied to the same problem, and we will see that the NUTS sampler is much better suited for sampling correlated parameters than a simple MH sampler. Below, we specify the model and the Bayesian Problem using tools imported from CUQIpy:

Download figure:
Standard image High-resolution image4.1. User-specified forward model of gravity anomaly measurements
A subsurface body with a density contrast to its homogeneous surroundings causes a gravity anomaly. The gravity anomaly field depends on the body's depth, shape, size, and density contrast. We construct an example where a spherical body causes the gravity anomaly shown in figure 7. The sphere has radius  m, the density contrast is
m, the density contrast is  kg m−3, and the depth from surface to center of the sphere
kg m−3, and the depth from surface to center of the sphere  m. This could be interpreted as a crude model of iron ore (a mineral substance with high iron content) buried in sedimentary rock.
m. This could be interpreted as a crude model of iron ore (a mineral substance with high iron content) buried in sedimentary rock.

Figure 7. Top: simulated measured gravity anomaly with noise and true gravity anomaly. Bottom: buried spherical body causing the gravity anomaly at the surface.
Download figure:
Standard image High-resolution imageIn the inverse problem we are interested in inferring the spherical body's radius, density contrast and depth given measurements of the gravity anomaly at the surface. We measure the vertical component of the gravity anomaly, caused by the spherical body, at the surface along a ξ-axis whose origin intersects the point above the center of the sphere, see figure 7. The measured signal at the position ξ is modelled as arising from the parameters of interest  through the non-linear function
through the non-linear function

where G is the gravitational constant. We measure the signal at m points  to obtain the data vector
to obtain the data vector  with elements given by
with elements given by

and hence the complete nonlinear forward model  is expressed as
is expressed as

The forward model is implemented in forward_gravity(), cf  of the forward operator, with elements defined by
of the forward operator, with elements defined by

Computation of the Jacobian is implemented in jac_gravity(), cf
The user-specified CUQIpy model must contain a python function that evaluates the forward model as well as information about the problem's range and domain geometries. The measurements y are given by the continuous function f in (28) while the inferred parameters in x consist of three different physical quantities, making the CUQIpy geometries Continuous1D() and Discrete() appropriate for the range and domain, respectively. Derivative information is added via a python function that evaluates the Jacobian matrix. The CUQIpy model is specified as follows:

Download figure:
Standard image High-resolution image4.2. The Bayesian problem
We specify a simple Gaussian prior with means that are different from the true parameter values and with large standard deviations, such that the prior is not very informative. Furthermore, we assume a Gaussian data distribution with standard deviation 10−6 m s−2. This leads to the Bayesian Problem:


where ' ' denotes a diagonal matrix or in CUQIpy:
' denotes a diagonal matrix or in CUQIpy:

Download figure:
Standard image High-resolution imageTo solve the inverse problem, we simulate a gravity anomaly signal  by obtaining one realization from the data distribution (32b
) at m = 100 equidistantly distributed points between
by obtaining one realization from the data distribution (32b
) at m = 100 equidistantly distributed points between  m and ξ = 8000 m, and with
m and ξ = 8000 m, and with ![$\boldsymbol{x}^{\mathrm{true}} = \left[z^{\mathrm{true}}, \Delta \rho^{\mathrm{true}}, r^{\mathrm{true}}\right]^{\mathsf{T}}$](https://content.cld.iop.org/journals/0266-5611/40/4/045009/revision2/ipad22e7ieqn109.gif) . In CUQIpy this is conveniently done using the data distribution's sample() method:
. In CUQIpy this is conveniently done using the data distribution's sample() method:

Download figure:
Standard image High-resolution imageThe true and the noisy signals are plotted in figure 7.
4.3. Posterior sampling and analysis
In CUQIpy, we define the posterior distribution by forming the joint distribution of the prior and data distributions and conditioning on the observed data:

Download figure:
Standard image High-resolution imageExamining (28) we see that the signal is determined from z and the product  , which means that z can be inferred from the data while
, which means that z can be inferred from the data while  and r can not be resolved individually. Therefore, we expect that the
and r can not be resolved individually. Therefore, we expect that the  and r samples will be extremely correlated. We compare the performance of the MH sampler and the NUTS sampler. We use the same starting point
and r samples will be extremely correlated. We compare the performance of the MH sampler and the NUTS sampler. We use the same starting point ![$\boldsymbol{x}^\mathrm{init} = \left[1000,2000,1000\right]^{\mathsf{T}}$](https://content.cld.iop.org/journals/0266-5611/40/4/045009/revision2/ipad22e7ieqn113.gif) and run both samplers for approximately 10 min.
and run both samplers for approximately 10 min.
We run the MH sampler with adaptive choice of step size by:

Download figure:
Standard image High-resolution imageand the NUTS sampler with:

Download figure:
Standard image High-resolution imageWe analyse the samples by inspecting correlation coefficients between the inferred variables and trace plots of the samples using CUQIpy's plotting functionality, e.g. samplesMH.plot_trace(). As expected, table 6 reveals strong correlation between the radius r and density contrast  samples, whereas the depth z samples are not correlated with the other parameters. This is the case for both sampling methods.
samples, whereas the depth z samples are not correlated with the other parameters. This is the case for both sampling methods.
Table 6. Correlation coefficients between sampled parameters using (left) the Metropolis–Hastings sampler and (right) the NUTS sampler.
| z |

| |
|---|---|---|

| 0.004 | |
| r | 0.03 | −0.98 |
| z |

| |
|---|---|---|

| −0.01 | |
| r | 0.03 | −0.95 |
The trace plots in figure 8 show that for both sampling methods the depth parameter chains are well-mixed and that the posterior 1D marginals converge to the same distribution. More interestingly, the trace plots show that the MH chains of density contrast and radius are very poorly mixed, and the posterior 1D marginals have not converged to distributions of a simple form. The poor mixing is also confirmed by the ESS computed with CUQIpy's samplesMH.compute_ess(). On the other hand, the NUTS sampler, that utilizes gradient information, immensely improves the mixing of the chains [37]. This is indicated by the chain plots, the smoother 1D marginals, and that the much larger ESS for NUTS, even though the number of posterior samples is much smaller. This demonstrates that gradient-based samplers like NUTS are better suited for correlated parameters.

Figure 8. Trace plots of posterior samples using the uninformative prior (Pr1) in combination with the Metropolis–Hastings and NUTS samplers, and the strong  prior (Pr2) in combination with the NUTS sampler. The top row show the 1D marginals of the posterior distributions with the prior and true parameter values marked with black vertical lines. Rows 2–4 show the chains of the samples and respective ESS that are computed for each chain using samples.compute_ess().
prior (Pr2) in combination with the NUTS sampler. The top row show the 1D marginals of the posterior distributions with the prior and true parameter values marked with black vertical lines. Rows 2–4 show the chains of the samples and respective ESS that are computed for each chain using samples.compute_ess().
Download figure:
Standard image High-resolution imageFinally, we see that the depth posterior marginal seems to contract close to the true value with fairly high certainty, and is not very biased towards the prior mean. On the other hand, the posterior marginals of the density contrast and the radius contract around their respective prior means, but with high uncertainty. This reflects the fact that the data informs the depth posterior well, while the density contrast and radius are more controlled by the prior, as the data can not resolve these parameters individually.
To improve the posterior estimates we formulate a Gaussian prior that is more informative about the density contrast, but less informative about the radius or depth. This simulates a scenario where we seek iron ore in sedimentary rock with unknown size and depth. Hence, the depth and radius priors remain unchanged but the density contrast prior now has the true density contrast as mean, and a small standard deviation. The new, more informative prior is:

Since the density contrast and radius remain correlated, we use NUTS to sample the posterior as before. Using the new  prior, we see in figure 8 that both the
prior, we see in figure 8 that both the  posterior and the r posterior contract around the ground truth with high certainty.
posterior and the r posterior contract around the ground truth with high certainty.
5. Case study: x-ray CT with the CUQIpy-CIL plugin
In this case study we demonstrate how CUQIpy can be applied to a larger real-data 2D imaging problem in x-ray CT through the CUQIpy-CIL plugin that provides a simple interface to configure a model for CT. The only component needed to allow us to handle a CT problem in CUQIpy is the forward model which we load from the plugin, along with general CUQIpy tools:

Download figure:
Standard image High-resolution imageWe assume the data and prior distributions are known, but with unknown precision parameters, and we show how this is modelled with a simple hierarchical model. Finally, we sample from the posterior and display the results via CUQIpy plotting functionality.
We use dataset B from the Helsinki Tomography Challenge (HTC) 2022 [36] to demonstrate UQ for CT. This is a 2D dataset and it is measured using fan-beam geometry. The data comes with a set of parameters characterizing the measurement setup and we use them to construct the model in section 5.1. To make the data compatible with CUQIpy we load it into a CUQIarray and equip it with geometry.

Download figure:
Standard image High-resolution imageThis also allows easy data plotting by y_obs.plot(), see figure 9(a).

Figure 9. (a) Sinogram containing the noisy data  . (b)–(c) Visualization of some basic statistics of the
x
posterior samples.
. (b)–(c) Visualization of some basic statistics of the
x
posterior samples.
Download figure:
Standard image High-resolution image5.1. Model
In CT, an image of an object's interior is found from observed attenuation of x-rays passing through the object [23]; this is often formulated as a linear inverse problem  . Here,
x
represents an image of the object's spatially varying attenuation coefficient,
y
represents the measured attenuation (sometimes called the sinogram), and each matrix element Aij
represents the ith x-ray's intersection with pixel j.
. Here,
x
represents an image of the object's spatially varying attenuation coefficient,
y
represents the measured attenuation (sometimes called the sinogram), and each matrix element Aij
represents the ith x-ray's intersection with pixel j.
We use the CUQIpy-CIL plugin to specify the CT model. It is based on the Python package CIL [28, 39] from which the forward and adjoint operations (projection and backprojection) are wrapped as a CUQIpy model. Furthermore CUQIpy-CIL sets up the model with Image2D domain and range geometries. The CUQIpy-CIL model is straightforward to specify using parameters from the HTC dataset:

Download figure:
Standard image High-resolution image5.2. The Bayesian problem
To construct our Bayesian Problem we must specify the data and prior distributions. We want an edge-preserving prior because we expect a piecewise constant image. Therefore, we apply a 2D LMRF prior to the unknown image x , which is similar to total-variation regularization [22, section 8.6]. Since we do not know the prior precision, we let this be a random variable d that follows a Gamma distribution, and we include this in the prior. The data distribution is formulated assuming the data noise is Gaussian, which is a good approximation for high-intensity x-rays. However, we do not know the noise level of the dataset. Therefore we model the noise precision as a random variable s and let it follow a Gamma distribution.
With these prior and data distributions, we define the Bayesian Problem:




In CUQIpy we express this by:

Download figure:
Standard image High-resolution image5.3. Posterior sampling and analysis
We set up the posterior as a joint distribution and condition on the observed data:

Download figure:
Standard image High-resolution imageThis posterior has a hierarchical structure so we use a Gibbs sampler. We utilize that the hyperpriors for the precision parameters l and d are conjugate to the data and prior distributions respectively. In CUQIpy we construct the appropriate Gibbs sampler, and we obtain 500 samples from the posterior after a burn-in of 100 samples:

Download figure:
Standard image High-resolution imageThese match the automatic sampler selection done by BayesianProblem.
We analyze and visualize posterior samples and basic statistics for the CT reconstruction x and the hyperparameters s and d:

Download figure:
Standard image High-resolution imageThe posterior mean for x is a good reconstruction of the CT data, and its standard deviation image highlights most uncertainty near the edges (figure 9). The trace plots for s and d in figure 10 suggest that chains have converged and we see that the distributions of the samples s and d take their maxima around 9250 and 460. These parameters estimate the inferred noise and regularization levels and how certain the estimates are.

Figure 10. Trace plots of posterior samples of the hyperparameters. Left column: posterior distributions. Right column: sample chains.
Download figure:
Standard image High-resolution image6. Case study: AD benchmark by CUQIpy-PyTorch
In this case study, we demonstrate the capabilities of the CUQIpy-PyTorch plugin, which enables the use of PyTorch's AD framework within CUQIpy, allowing efficient gradient-based sampling of an arbitrary Bayesian Problem using the NUTS sampler. To showcase this, we use a benchmark problem that is commonly used to illustrate Bayesian sampling with NUTS, known as the Eight Schools problem.
The Eight Schools problem is a classic example in Bayesian statistics, first introduced in [49] and later adapted as a benchmark problem in STAN [10], Pyro [5], Edward [57], and Tensorflow probability [43]. The problem involves estimating the effects of coaching on exam scores at eight different schools. Specifically, we want to estimate the treatment effect, xi , at each school i, which represents the difference in exam scores between students who received coaching and those who did not. However, because the number of students in each school is small, the estimates of the treatment effects are noisy and may be biased. We therefore use a Bayesian hierarchical model to estimate the treatment effects, which accounts for both within-school variation and between-school variation. For more details see [16, 49] and the above-mentioned software packages.
Treatment effects and standard deviations are estimated in a study and assumed to be observed and known. We import the packages and define the observations by:

Download figure:
Standard image High-resolution imageThe centered hierarchical Bayesian Problem for Eight Schools is given by:





where ![$\boldsymbol x = [x_1, \dots, x_8]^\mathsf{T}$](https://content.cld.iop.org/journals/0266-5611/40/4/045009/revision2/ipad22e7ieqn124.gif) represents the treatment effects at each school,
represents the treatment effects at each school, ![$\boldsymbol x^{^{\prime}} = [x^{^{\prime}}_1, \dots, x^{^{\prime}}_8]^\mathsf{T}$](https://content.cld.iop.org/journals/0266-5611/40/4/045009/revision2/ipad22e7ieqn125.gif) represents the standardized effects, u represents the average treatment effect across all schools, t represents the standard deviation of the treatment effects, and
represents the standardized effects, u represents the average treatment effect across all schools, t represents the standard deviation of the treatment effects, and ![$\boldsymbol{y} = [y_1, \dots, y_8]^\mathsf{T}$](https://content.cld.iop.org/journals/0266-5611/40/4/045009/revision2/ipad22e7ieqn126.gif) represents the exam score differences. Note that due to parameter relations there are no relations between distributions that can be exploited, e.g. for conjugacy. The Bayesian Problem can be implemented with CUQIpy-PyTorch as follows
represents the exam score differences. Note that due to parameter relations there are no relations between distributions that can be exploited, e.g. for conjugacy. The Bayesian Problem can be implemented with CUQIpy-PyTorch as follows

Download figure:
Standard image High-resolution imageNote here the use of a lambda function to define a function representing the random variable
x
. Since
x
is entirely specified by the other random variables, the posterior of interest is  . We sample the problem by the optimized NUTS from Pyro [5], which is embedded in CUQIpy-PyTorch. We draw 1000 posterior samples and 500 warm-up samples with default target acceptance rate of 0.8:
. We sample the problem by the optimized NUTS from Pyro [5], which is embedded in CUQIpy-PyTorch. We draw 1000 posterior samples and 500 warm-up samples with default target acceptance rate of 0.8:

Download figure:
Standard image High-resolution imageBecause of the AD capabilities of CUQIpy-PyTorch the posterior is jointly sampled with NUTS. The analysis of the Eight Schools problem can be visualized, e.g. with a so-called violin plot, which is also available in CUQIpy, see figure 11. The sample means of the average treatment effect u is found to be 5.6 with standard deviation t of 12.7.

Download figure:
Standard image High-resolution image
Figure 11. Violin plots showing combined kernel density estimates and box plots of the estimated standardized effects  obtained via NUTS sampling of the joint posterior. The results match those obtained with other software packages for the same problem and show a difference in the effectiveness of the coaching for the eight schools studied.
obtained via NUTS sampling of the joint posterior. The results match those obtained with other software packages for the same problem and show a difference in the effectiveness of the coaching for the eight schools studied.
Download figure:
Standard image High-resolution imageThese results can be used to conclude on the effect of coaching for SAT scores [16]. The results obtained are in line with those obtained by the above-mentioned software packages.
7. Conclusion and future work
In this paper, we have presented CUQIpy, a Python package designed to serve as a versatile framework for UQ in inverse problems. This flexible framework enables users to focus on modeling aspects while still providing experts with access to the underlying 'machine room'.
We demonstrated the capabilities of CUQIpy by showcasing Bayesian inverse problems using both simple and advanced distributions, along with sampling strategies ranging from classical samplers to advanced techniques incorporating gradient information, forward model linearity, or distribution approximations.
As CUQIpy remains under active development, we anticipate further enhancement and expansion of its features beyond the current version 1.0.0. Future work for CUQIpy includes:
- Extending CUQIpy with new distributions and samplers.
- Extending support for automated sampler selection by BayesianProblem to accommodate a broader range of problems, including more hierarchical models.
- Enhancing the exploitation of structure through a wider range of algebraic operations on random variables and forward models, replacing lambda functions.
- Improving interoperability with other libraries and array types, inspired by NEP 47 (https://numpy.org/neps/nep-0047-array-api-standard.html).
- Incorporating support for UQ techniques beyond MCMC-based sampling, such as Variational Inference [6], to enable efficient sampling of posterior distribution approximations.
- Incorporate support for learned models and priors such as Plug & Play priors [31].
The flexibility and adaptability of CUQIpy encompass a wide array of inverse problems illustrating its potential as a powerful tool for UQ in the field. It is our hope that CUQIpy and similar computational tools will foster a more wide-spread adoption of UQ methods for large-scale inverse problems.
Acknowledgments
This work was supported by The Villum Foundation (Grant No. 25893). J S J would like to thank the Isaac Newton Institute for Mathematical Sciences for support and hospitality during the programme 'Rich and Nonlinear Tomography—a multidisciplinary approach' when work on this paper was undertaken. This work was supported by EPSRC Grant Number EP/R014604/1. This work was partially supported by a grant from the Simons Foundation (J S J). F U has been supported in part by Academy of Finland (Project Number 353095). The authors are grateful to members of the CUQI project for valuable input that helped shape the design of CUQIpy.
Data availability statement
CUQIpy and plugins are available from https://cuqi-dtu.github.io/CUQIpy. The code and data to reproduce the results and figures of the present paper are available from https://github.com/CUQI-DTU/paper-CUQIpy-1-Core.
The data that support the findings of this study are openly available at the following URL/DOI: https://zenodo.org/doi/10.5281/zenodo.10512533.
Appendix: Python implementations for case study 3: gravity anomaly
This Python function implements the gravity model (28) evaluated in a point wrt:

Download figure:
Standard image High-resolution imageThis Python function evaluates the Jacobian of the gravity model in a point wrt:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
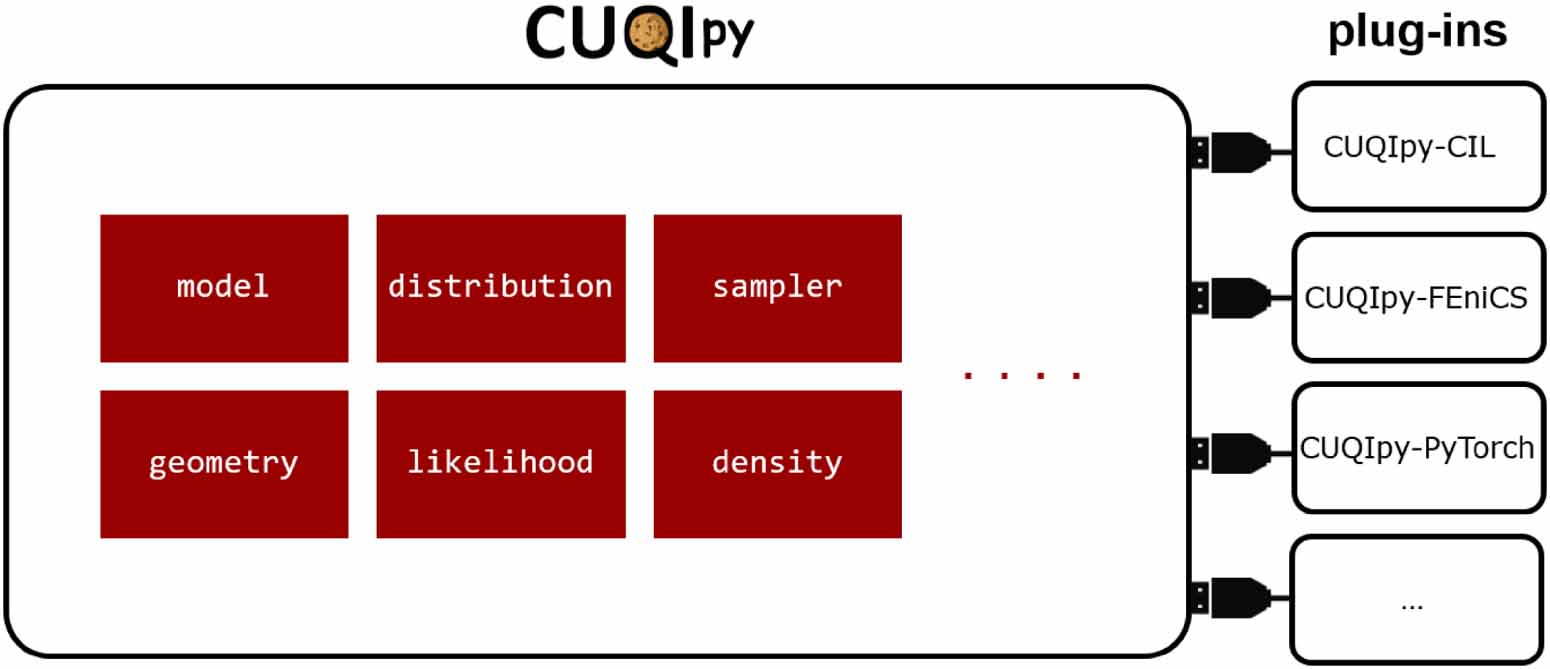{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
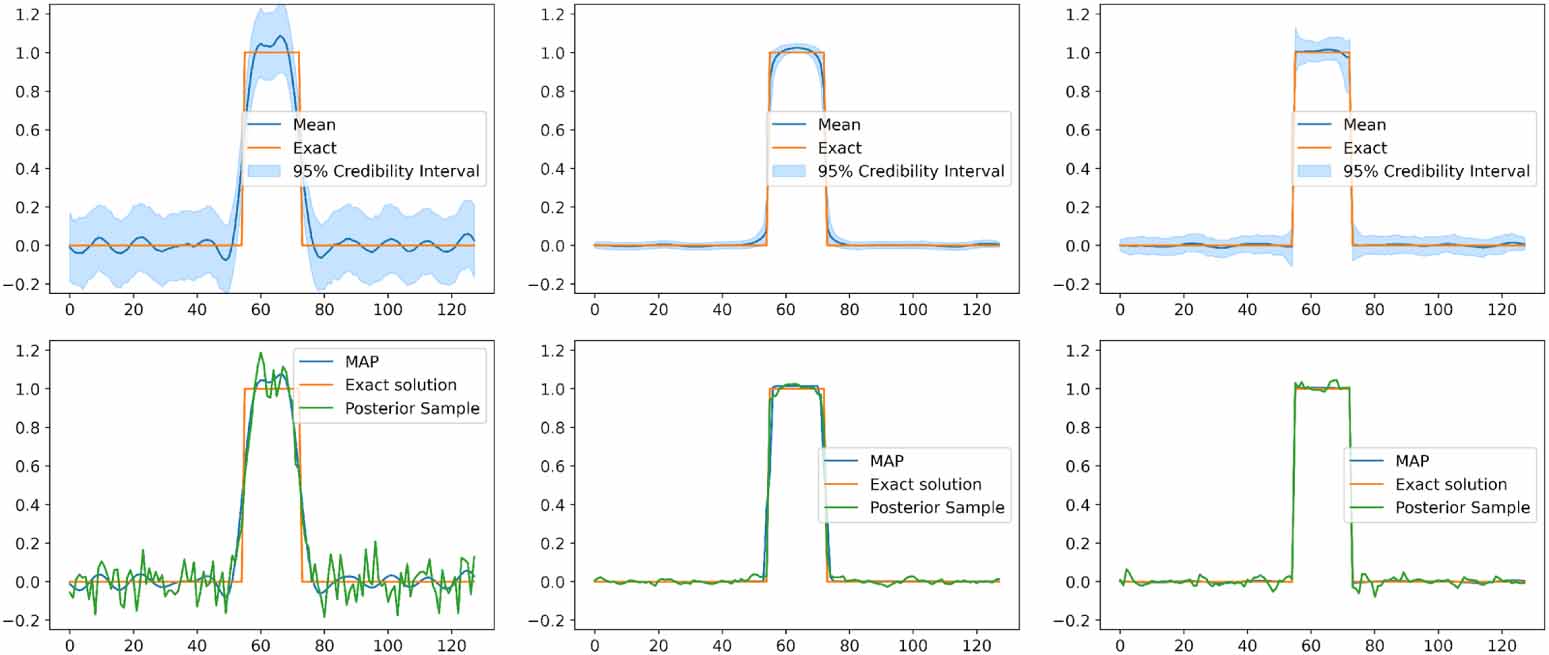{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
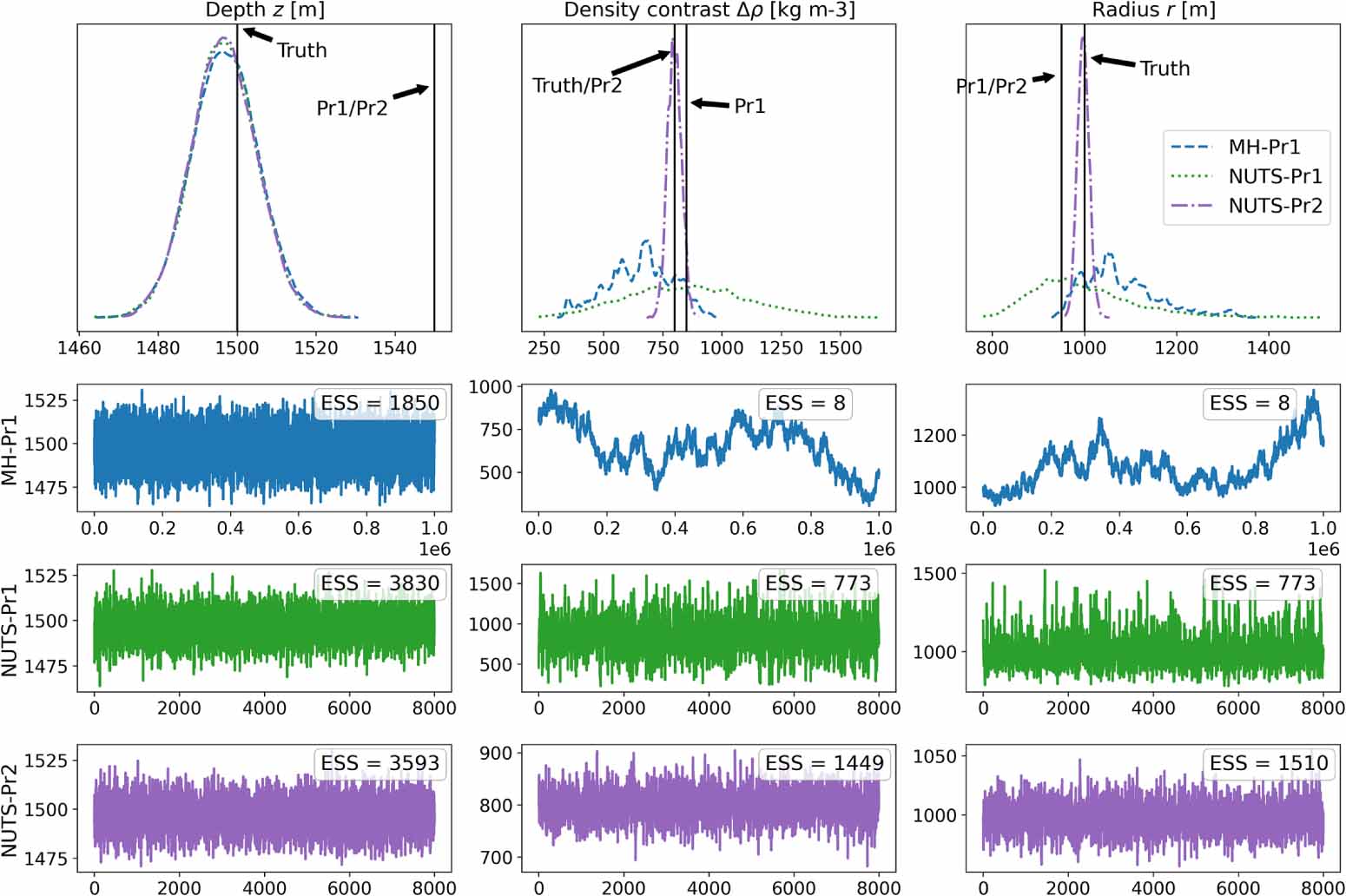{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download figure:
Standard image High-resolution image{kind=link}