
Structural Properties of the Wyner–Ziv Rate Distortion Function: Applications for Multivariate Gaussian Sources †

1
Department of Electrical and Computer Engineering, Texas A & M University, College Station, TX 77843, USA
2
Department of Electrical and Computer Engineering, University of Cyprus, P.O. Box 20537, CY-1678 Nicosia, Cyprus
*
Author to whom correspondence should be addressed.
†
Preliminary results of this paper are published in 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Victoria, Australia.
Entropy 2024, 26(4), 306; https://doi.org/10.3390/e26040306
Submission received: 4 January 2024
/
Revised: 7 March 2024
/
Accepted: 20 March 2024
/
Published: 29 March 2024
(This article belongs to the Special Issue Foundations of Goal-Oriented Semantic Communication in Intelligent Networks)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:The main focus of this paper is the derivation of the structural properties of the test channels of Wyner’s operational information rate distortion function (RDF), , for arbitrary abstract sources and, subsequently, the derivation of additional properties for a tuple of multivariate correlated, jointly independent, and identically distributed Gaussian random variables, , , , with average mean-square error at the decoder and the side information, , available only at the decoder. For the tuple of multivariate correlated Gaussian sources, we construct optimal test channel realizations which achieve the informational RDF, , where is the set of auxiliary RVs Z such that , , and . We show the following fundamental structural properties: (1) Optimal test channel realizations that achieve the RDF and satisfy conditional independence, (2) Similarly, for the conditional RDF, , when the side information is available to both the encoder and the decoder, we show the equality . (3) We derive the water-filling solution for .
1. Introduction, Problem Statement, and Main Results
1.1. The Wyner and Ziv Lossy Compression Problem and Generalizations
Wyner and Ziv [1] derived an operational information definition for the lossy compression problem in Figure 1 with respect to a single-letter fidelity of reconstruction. The joint sequence of random variables (RVs) takes values in sets of finite cardinality, , and it is generated independently according to the joint probability distribution function . Wyner [2] generalized [1] to RVs that take values in abstract alphabet spaces and hence include continuous-valued RVs.
(A) Switch “A” Closed: When the side information is available non-causally at both the encoder and the decoder, Wyner [2] (see also Berger [3]) characterized the infimum of all achievable operational rates (denoted by in [2]), subject to a single-letter fidelity with average distortion less than or equal to . The rate is given by the single-letter operational information theoretic conditional RDF:
where is the set specified by
and is the reproduction of X. is the conditional mutual information between X and conditioned on Y, and is the fidelity criterion between x and . The infimum in (1) is over all elements of with induced joint distributions of the RVs such that the marginal distribution is the fixed joint distribution of the source . This problem is equivalent to (2) [4].
(B) Switch “A” Open: When the side information is available non-causally only at the decoder, Wyner [2] characterized the infimum of all achievable operational rates (denoted by in [2]), subject to a single-letter fidelity with average distortion less than or equal to . The rate is given by the single-letter operational information theoretic RDF as a function of an auxiliary RV :
where is specified by the set of auxiliary RVs Z and defined as:
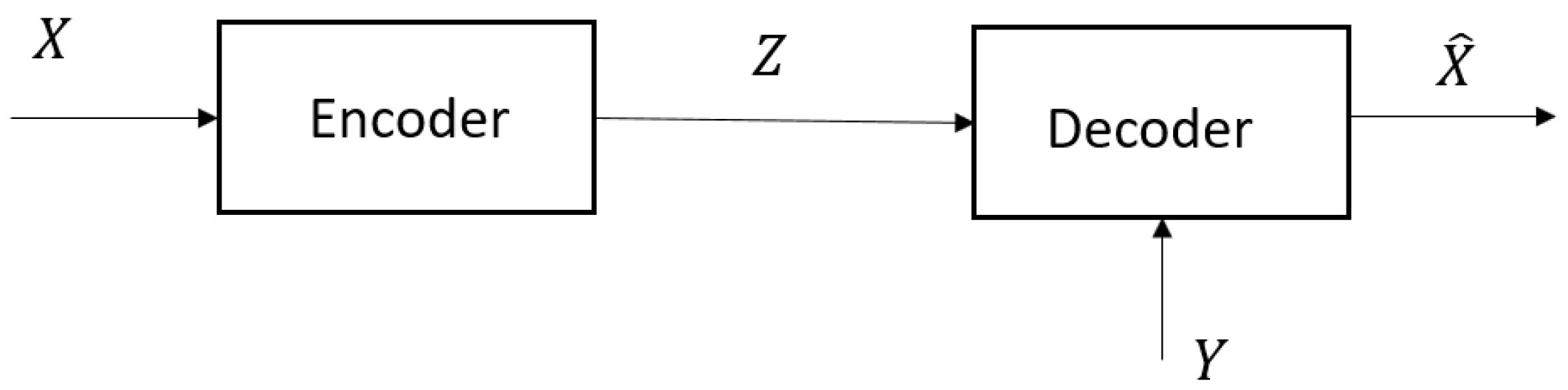
Wyner’s realization of the joint measure induced by the RVs is illustrated in Figure 2, where Z is the output of the “test channel”, . Clearly, involves two strategies, i.e., and . This makes it a much more complex problem compared to (which involves only ).
Throughout [2], the following assumption is imposed.
Assumption 1.
(see [2]).
Wyner [2] considered scalar-valued jointly Gaussian RVs with square-error distortion and constructed the optimal realizations and and the function from the sets and , respectively. Also, it is shown that these realizations achieve the characterizations of the RDFs and , respectively, and that the two rates are equal, i.e., .
(C) Marginal RDF: If there is no side information, , or the side information is independent of the source, , the RDFs and degenerate to the marginal RDF , defined by
(D) Gray’s Lower Bounds: A lower bound on is given by Gray in [4] [Theorem 3.1]. This bound connects with the marginal RDF and the mutual information between X and Y as follows:
Clearly, the lower bound is trivial for values of such that .
1.2. Main Contributions of the Paper
We first consider Wyner’s [2] RDFs and for arbitrary RVs defined on abstract alphabet spaces, and we derive structural properties of the realizations that achieve the two optimal test channels. Subsequently, we generalize Wyner’s [2] results to multivariate-valued jointly Gaussian RVs . In other words, we construct the optimal multivariate-valued realizations and and the function which achieve the RDFs and , respectively. In the literature, it is often called achievability of the converse coding theorem. In addition, we use the realizations to prove the equality and to derive the water-filling solution. Along the way, we verify that our results reproduce, for scalar-valued RVs , Wyner [2] RDFs and the optimal realizations. However, to our surprise, the existing results from the literature [[5], Theorem 4 and Abstract and [6], Theorem 3A], which deal with the more general multivariate-valued remote sensor problem (the RDF of the remote sensor problem is a generalization of Wyner’s RDF , with the encoder observing a noisy version of the RVs generated by the source), do not degenerate to Wyner’s [2] RDFs, when specilized to scalar-valued RVs (we verify this in Remark 5 by also checking the correction suggested in https://tiangroup.engr.tamu.edu/publications/) (accessed on 3 January 2024). In Section 1.3, we give a detailed account of the main results of this paper. We should emphasize that preliminary results of this paper appeared in [7], mostly without the details of the proofs. This paper is extended [7] and contains complete proofs of the preliminary results of [7], which in some cases are lengthy (see, for example, Section 4, proofs of Theorems 3–5, Corollaries 1 and 2, etc.).
1.3. Problem Statement and Main Results
(a) We consider a tuple of jointly independent and identically distributed (i.i.d.) arbitrary RVs defined on abstract alphabet spaces, and we derive the following results.
(a.1) Lemma 1: Achievable lower bound on the conditional mutual information , which strengthens Gray’s lower bound (8) [[4], Theorem 3.1].
(a.2) Theorem 2: Structural properties of the optimal reconstruction , which achieves a lower bound on for mean-square error distortion. Theorem 2 strengthens the conditions for the equality to hold, , given by Wyner [2] [Remarks, p. 65] (see Remark 1). However, for finite-alphabet-valued sources with Hamming distance distortion, it might be the case that , as pointed out by Wyner and Ziv [1] [Section 3] for the doubly symmetric binary source.
(b) We consider a tuple of jointly i.i.d. multivariate Gaussian RVs , with respect to the square-error fidelity, as defined below.
where are arbitrary positive integers, means X is a Gaussian RV, with zero mean and covariance matrix , and is the Euclidean distance on . To give additional insight we often consider the following realization of side information (the condition ensures , and hence, Assumption 1 is respected).
where denotes the identity matrix. For the above specification of the source and distortion criterion, we derive the following results.
(b.1) Theorems 3 and 4: Structural properties of optimal realization of , which achieves , its closed form expression.
(b.2) Theorem 5: Structural properties of optimal realization of and , which achieve and the closed form expression of .
(b.3) A proof that and coincide: Calculation of the distortion region such that Gray’s lower bound (8) holds with equality.
In Remark 4, we consider the tuple of scalar-valued, jointly Gaussian RVs with square error distortion function and verify that our optimal realizations of and the closed form expressions for and are identical to Wyner’s [2] realizations and RDFs.
We should emphasize that our methodology is different from past studies in the sense that we focus on the structural properties of the realizations of the test channels, that achieve the characterizations of the two RDFs (i.e., verification of the converse coding theorem). Our derivations are generic and bring new insight into the construction of realizations that induce the optimal test channels of other distributed source coding problems (i.e., establishing the achievability of the converse coding theorem).
1.4. Additional Generalizations of the Wyner-Ziv [1] and Wyner [2] RDFs
(A) Draper and Wornell [8] Distributed Remote Source Coding Problem: Draper and Wornell [8] generalized the RDF , when the source to be estimated at the decoder is , and it is not directly observed at the encoder. Rather, the encoder observes a RV (which is correlated with S), while the decoder observes another RV, as side information, , which provides information on . The aim is to reconstruct S at the decoder by , subject to an average distortion , by a function . The RDF for this problem, called the distributed remote source coding problem, is defined by [8]
where is specified by the set of auxiliary RVs Z, and defined as:
Clearly, if (almost surely), then degenerates (this implies the optimal test channel that achieves the characterization of the RDF should degenerate to the optimal test channel that achieves the characterization of the RDF ) to . For scalar-valued jointly Gaussian RVs with square-error distortion, Draper and Wornell [8] [Equation (3) and Appendix A.1] derived the characterization of the RDF and constructed the optimal realization , which achieves this characterization.
In [5,6], the authors investigated the RDF of [8] for the multivariate jointly Gaussian RVs , with square-error distortion, and derived a characterization for the RDF in [[5], Theorem 4] and [[6], Theorem 3A] (see [[6], Equation (26)]). However, it will become apparent in Remark 5 that, when almost surely (a.s.), and hence , the RDFs given in [[5], Theorem 4] and [[6], Theorem 3A], do not produce Wyner’s [2] value. We also show in Remark 5 that the same technical issues occur for the correction suggested in https://tiangroup.engr.tamu.edu/publications/ (accessed on 3 January 2024). Similarly, when and [[5], Theorem 4] and [[6], Theorem 3A], do not produce the classical RDF of the Gaussian source X.
(B) Additional Literature Review: The formulation of Figure 1 is generalized to other multiterminal or distributed lossy compression problems, such as relay networks, sensor networks, etc., under various code formulations and assumptions. Oohama [9] analyzed lossy compression problems for a tuple of scalar correlated Gaussian memoryless sources with square error distortion criterion. Also, he determined the rate-distortion region, in the special case when one source provides partial side information to the other source. Furthermore, Oohama in [10] analyzed separate lossy compression problems for scalar correlated Gaussian memoryless sources, when L of the sources provide partial side information at the decoder for the reconstruction of the remaining source and gave a partial answer to the rate distortion region. Additionally, ref. [10] proved that the problem of [10] includes, as a special case, the additive white Gaussian CEO problem analyzed by Viswanathan and Berger [11]. Extensions of [10] are derived by Ekrem and Ulukus [12] and Wang and Chen [13], where an outer bound on the rate region is derived for the vector Gaussian multiterminal source. Additional works are [14,15,16] and the references therein.
The vast literature on multiterminal or distributed lossy compression of jointly Gaussian sources with square-error distortion (including the references mentioned above), is often confined to scalar-valued correlated RVs. Moreover, as easily verified, not much emphasis is given in the literature on the structural properties of the realizations of RVs that induce the optimal test channels that achieve the characterizations of the RDFs.
The rest of the paper is organized as follows. In Section 2, we review Wyner’s [2] operational definition of lossy compression. We also state a fundamental theorem on mean-square estimation that we use throughout the paper regarding the analysis of (b). The main Theorems are presented in Section 3; some of the proofs, including the structural properties, are given in Section 4. Connections between our results and the past literature are provided in Section 5. A simulation to show the gap between the two rates is given in the same section.
2. Preliminaries
In this section, we review the Wyner [2] source coding problems with fidelity in Figure 1. We begin with the notation, which follows closely [2].
2.1. Notation
Let the set of all integers, the set of natural integers, . For , denote the following finite subset of the above defined set, . Denote the real numbers by and the set of positive and of strictly positive real numbers, by and , respectively.
For any matrix , we denote its kernel by its transpose by , and for , we denote its trace by , and by , the matrix with diagonal entries , and zero elsewhere. The determinant of a square matrix A is denoted by . The identity matrix with dimensions is designated as . Denote an arbitrary set or space by and the product space formed by n copies of it by . denotes the set of tuples , where are its coordinates. Denote a probability space by . For a sub-sigma-field , and , denote by the conditional probability of A given ; i.e., is a measurable function on .
On the above probability space, consider two-real valued random variables (RV) , where are arbitrary measurable spaces. The measure (or joint distribution if are Euclidean spaces) induced by on is denoted by or and their marginals on and by and , respectively. The conditional measure of RV X conditioned on Y is denoted by or , when is fixed. On the above probability space, consider three-real values RVs , . We say that RVs are conditional independent given RV X if (almost surely) or equivalently ; the specification a.s is often omitted. We often denote the above conditional independence by the Markov chain (MC) .
Finally, for RVs , etc., denotes differential entropy of X, conditional differential entropy of X given Y, and the mutual information between X and Y, as defined in standard books on information theory [17,18]. We use to denote the natural logarithm. The notation means X is a Gaussian distributed RV with zero mean and covariance , where (resp. ) means is positive semidefinite (respectively, positive definite). We denote the covariance of X and Y by
We denote the covariance of X conditioned on Y by
where the second equality is due to a property of jointly Gaussian RVs.
2.2. Mean-Square Estimation of Conditionally Gaussian RVs
Below, we state a well-known property of conditionally Gaussian RVs from [19], which we use in our derivations.
Proposition 1.
Conditionally Gaussian RVs [19]. Consider a pair of multivariate RVs and , , defined on some probability distribution . Let be a subalgebra. Assume the conditional distribution of conditioned on , i.e., is (almost surely) Gaussian, with conditional means
and conditional covariances
Then, the vectors of conditional expectations and matrices of conditional covariances are given, , by the following expressions (If then the inverse exists and the pseudoinverse is ):
If is the trivial information, i.e., , then is removed from the above expressions.
Note that, if , then (26) and (27) reduce to the well-known conditional mean and conditional covariance of X conditioned on Y.
For Gaussian RVs, we make use of the following properties.
Proposition 2.
Let , , , and denote by and the algebra generated by the RVs X and , respectively. The following hold.
(a) .
(b) if and only if .
Proof.
This is well-known in measure theory, see [20]. □
Proposition 3.
Let , , . Then, there exists a linear transformation such that, if , , then , .
Proof.
This is well-known in probability theory, see [20]. □
2.3. Wyner’s Coding Theorems with Side Information at the Decoder
For the sake of completeness, we introduce certain results from Wyner’s work in [2], which we use in this paper. On a probability space , consider a tuple of jointly i.i.d. RVs ,
with induced distribution . Consider also the measurable function , for a measurable space . Let
be a finite set.
A code , when switch “A” is open (see Figure 1), is defined by two measurable functions, the encoder and the decoder , with average distortion, as follows.
where is again a sequence of RVs, . A non-negative rate distortion pair is said to be achievable if for every , and n sufficiently large, there exists a code such that
Let denote the set of all achievable pairs , and define, for , the infimum of all achievable rates by
If for some there is no such that , then set For arbitrary abstract spaces Wyner [2] characterized the infimum of all achievable rates by the single-letter RDF, given by (5) and (6), in terms of an auxiliary RV . Wyner’s realization of the joint measure induced by the RVs is illustrated in Figure 2, where Z is the output of the “test channel”, . Wyner proved the following coding theorems.
Theorem 1.
Wyner [[2], Theorems, pp. 64–65]. Suppose Assumption 1 holds.
(a) Converse Theorem. For any , .
(b) Direct Theorem. If the conditions stated in ([2], pages 64-65, (i), (ii)) hold, then , .
In Figure 1, when switch A is closed and the tuple of jointly independent and identically distributed RVs is defined as in Section 2.3, Wyner [2] generalized Berger’s [3] characterization of all achievable pairs , from finite alphabet spaces to abstract alphabet spaces.
A code , when switch “A” is closed, (see Figure 1), is defined as in Section 2.3, with the encoder , replaced by
Let denote the set of all achievable pairs , again as defined in Section 2.3. For , define the infimum of all achievable rates by
Wyner [2] characterized the infimum of all achievable rates by the single-letter RDF given by (1) and (3). The coding Theorems are given by Theorem 1 with and replaced by and , respectively. That is, (using Wyner’s notation [[2], Appendix A.1]) These coding theorems generalized earlier work of Berger [3] for finite alphabet spaces. Wyner also derived a fundamental lower bound on in terms of , as stated in the next remark.
Remark 1.
Wyner [[2], Remarks, p. 65]
(A) For , , and thus . Then, by a property of conditional mutual information and the data processing inequality:
where the last equality is defined since (see [[2], Remarks, p. 65]. Moreover, minimizing (36) over gives
(B) Inequality (37) holds with equality, i.e., if , which achieves can be generated as in Figure 2 with . This occurs if and only if , and follows from the identity and lower bound
where the inequality holds with equality if and only if .
3. Main Theorems and Discussion
In this section, we state the main results of this paper. These are the achievable lower bounds of Lemma 1 and Theorem 2, which hold for RVs defined on general abstract alphabet spaces, and Theorems 4 and 5, which hold for multivariate Gaussian RVs.
3.1. Side Information at Encoder and Decoder for an Arbitrary Source
We start with the following achievable lower bound on the conditional mutual information , which appears in the definition of of (1); this strengthens Gray’s lower bound (8) [[4], Theorem 3.1].
Lemma 1.
Achievable lower bound on conditional mutual information. Let be a triple of arbitrary RVs taking values in the abstract spaces , with distribution and joint marginal the fixed distribution of . Then, the following hold.
(a) The inequality holds:
Moreover, the equality holds
if and only if
(b) If is a Markov chain then the equality holds
i.e., for all that belong to strictly positive set .
Proof.
See Appendix A.1. □
The next theorem which holds for arbitrary RVs is further used to derive the characterization of for multivariate Gaussian RVs.
Theorem 2.
Achievable lower bound on conditional mutual information and mean-square error estimation
(a) Let be a triple of arbitrary RVs on the abstract spaces , with distribution and joint marginal the fixed distribution of .
Define the conditional mean of X conditioned on by
for some measurable function .
(1) The inequality holds:
(2) The equality holds, if anyone of the conditions (i) or (ii) holds.
(b) In part (a) let be a triple of arbitrary RVs on , .
For all measurable functions , the mean-square error satisfies
Proof.
See Appendix A.2. □
3.2. Side Information at Encoder and Decoder for Multivariate Gaussian Source
The characterizations of the RDFs and for a multivariate Gaussian source are encapsulated in Theorems 3–5; these are proved in Section 4. These theorems include the structural properties of optimal test channels or realizations of , which induce joint distributions. Furthermore, they achieve the RDFs; the closed form expressions of the RDFs are based on a water-filling. The realization of the optimal test channel of is shown in Figure 3.
The following theorem gives a parametric realization of optimal test channel that achieves the characterization of the RDF .
Theorem 3.
Characterization of by test channel realization. Consider the RDF defined by (1), for the multivariate Gaussian source with mean-square error distortion defined by (9)–(18). The following hold.
(a) The optimal realization that achieves is parametrized by the matrices and represented by
where
Moreover, the optimal parametric realization of satisfies the following structural properties.
(b) The RDF is given by
Proof.
The proof is given in Section 4. □
The next theorem gives additional structural properties of the optimal test channel realization of Theorem 3 and uses these properties to characterize RDF via a water-filling solution.
Theorem 4.
Characterization of via water-filling solution. Consider the RDF defined by (1), for the multivariate Gaussian source with mean-square error distortion defined by (9)–(18), and its characterization in Theorem 3. The following hold.
(a) The matrices of the parametric realization of ,
where the realization coefficients are
and the eigenvalues and are given by
Moreover, if , then , and vice versa.
(b) The RDF is given by the water-filling solution:
where
and is a Lagrange multiplier (obtained from the Kuch–Tucker conditions).
(c) Figure 3 depicts the parallel channel scheme that realizes the optimal of parts (a), (b), which achieves .
(d) If X and Y are independent or Y is replaced by a RV that generates the trivial information, i.e., the algebra of Y is (or in (15)), then (a)–(c) hold with , and , i.e., reduces to the marginal RDF of X.
Proof.
The proof is given in Section 4. □
The proof of Theorem 4 (see Section 4) is based on the identification of structural properties of the test channel distribution. Some of the implications are briefly described below.
Conclusion 1: The construction and the structural properties of the optimal test channel that achieves the water-filling characterization of the RDF of Theorems 3 and 4 are not documented elsewhere in the literature.
(i) Structural properties (58) and (61) strengthen Gray’s inequality [[4], Theorem 3.1], (see proof of (8)) to the equality. That is, structural property (58) implies that Gray’s [[4], Theorem 3.1] lower bound (8) holds with equality for a strictly positive surface (See Gray [4] for definition) , i.e.,
The set excludes values of for which water-filling is active in (69) and (70).
By the realization of the optimal reproduction , it follows that the subtraction of equal quantities at the encoder and decoder does not affect the information measure, noting that .
Theorem 4 points (a) and (b) are obtained with the aid of Theorem 3 and Hadamard’s inequality, which shows and have the same eigenvectors.
(ii) Structural properties of realizations of Theorems 3 and 4: The matrices are nonnegative symmetric and have a spectral decomposition with respect to the same unitary matrix [21]. This implies that the test channel is equivalently represented by parallel additive Gaussian noise channels (subject to pre-processing and post-processing at the encoder and decoder).
3.3. Side Information Only at Decoder for Multivariate Gaussian Source
Theorem 5 gives the optimal test channel that achieves the characterization of the RDF and further states that there is no loss of compression rate if side information is only available at the decoder. That is, although in general, , an optimal reproduction of X, where is linear, is constructed such that the inequality holds with equality.
Theorem 5.
Characterization and water-filling solution of . Consider the RDF defined by (5) for the multivariate Gaussian source with mean-square error distortion, defined by (9)–(18). Then, the following hold.
(a) The characterization of the RDF, satisfies
where is given in Theorem 4b.
(b) The optimal realization , which achieves the lower bound in (72), i.e., , is represented by
Moreover, the following structural properties hold:
(1) The optimal test channel satisfies
(2) Structural property (2) of Theorem 4a holds.
Proof.
It is given in Section 4. □
The proof of Theorem 5 is based on the derivation of the structural properties and Theorem 4. Some implications are discussed below.
Conclusion 2: The optimal reproduction or test channel distribution , which achieves of Theorem 5, are not reported in the literature.
(i) From the structural property (1) of Theorem 5, i.e., (77), it follows that the lower bound is achieved by the realization of Theorem 5b; i.e., for a given , then uniquely defines Z.
(ii) If X is independent of Y or Y generates trivial information, then the RDFs degenerate to the classical RDF of the source X, i.e., , as expected. This is easily verified from (73) and (76), i.e., , which implies .
For scalar-valued RVs, , and X independent of Y, then the optimal realization reduces to
as expected.
(iii) In Remark 4, we show that the realization of optimal , which achieves the RDF of Theorem 5, degenerates to Wyner’s [2] realization that attains the RDF , of the tuple of scalar-valued, jointly Gaussian RVs , with the square error distortion function.
4. Proofs of Theorems 3–5
In this section, we derive the statements of Theorems 3–5 by making use of Theorem 2 (which holds for general abstract alphabet spaces) by restricting attention to multivariate jointly Gaussian .
4.1. Side Information at Encoder and Decoder
For jointly Gaussian RVs , in the next theorem we identify simple sufficient conditions for the lower bound of Theorem 2 to be achievable.
Theorem 6.
Sufficient conditions for the lower bounds of Theorem 2 to be achievable. Consider the statement of Theorem 2 for a triple of jointly Gaussian RVs on , , i.e., and joint marginal the fixed Gaussian distribution of
Then,
Moreover, the following hold.
Proof.
Note that identity (83) follows from Proposition 1, (26), by letting and be the information generated by Y. Consider Case (i); If (84) holds then . By (83), Conditions 1 and 2 are sufficient for (84) to hold. Consider Case (ii). Sufficient condition (87) follows from Theorem 2, and implies . The statement below (87) follows from Proposition 2. □
Now, we turn our attention to the optimization problem defined by (1) for the multivariate Gaussian source with mean-square error distortion defined by (9)–(18). In the next lemma, we derive a preliminary parametrization of the optimal reproduction distribution of the RDF .
Lemma 2.
Preliminary parametrization of optimal reproduction distribution of . Consider the RDF defined by (1) for the multivariate Gaussian source, i.e., , with mean-square error distortion defined by (9)–(18).
(a) For every joint distribution there exists a jointly Gaussian distribution denoted by , with marginal the fixed distribution , which minimizes and satisfies the average distortion constraint, i.e., with .
(b) The conditional reproduction distribution of the RDF is and induced by the parametric realization of (in terms of ),
and is a Gaussian RV.
Proof.
(a) This is omitted since it is similar to the classical unconditional RDF of a Gaussian message . (b) By (a), the conditional distribution is such that, its conditional mean is linear in , its conditional covariance is nonrandom, i.e., constant, and for fixed , is Gaussian. Such a distribution is induced by the parametric realization (88)–(91). (c) Follows from parts (a) and (b). (d) Follows from Theorem 6 and (48) due to the achievability of the lower bounds. □
In the next theorem, we identify the optimal triple such that (84) or (87) hold (i.e., establish its existence), characterize the RDF by , and construct a realization that achieves it.
Theorem 7.
Characterization of RDF . Consider the RDF , defined by (1), for the multivariate Gaussian source with mean-square error distortion, defined by (9)–(18). The characterization of the RDF is
where
The realization of the optimal reproduction , which achieves , is given in Theorem 3a, also satisfies the properties stated under Theorem 3a. (i)–(iv).
Proof.
See Appendix A.3. □
Remark 2.
Structural properties of the optimal realization of Theorem 4a. For the characterization of the RDF of Theorem 7, which is achieved by defined in Theorem 3a in terms of the matrices , we show in Corollary 2, the statements of Theorem 4a, i.e.,
To prove the structural property of Remark 2, we use the next corollary, which is a degenerate case of [[22], Lemma 2] (i.e., the structural properties of test channel of Gorbunov and Pinsker [23] nonanticipatory RDF of Markov sources).
Corollary 1.
Structural properties of realization of optimal of Theorem 4a. Consider the characterization of the RDF of Theorem 7. Suppose and commute, that is,
Then,
that is, the following hold.
Proof.
See Appendix A.4. □
In the next corollary, we re-express the realization of of Theorem 4a, which characterizes the RDF of Theorem 7 using a translation of X and by subtracting their conditional means with respect to Y, making use of property of (78). This is the the realization shown in Figure 3.
Corollary 2.
Equivalent characterization of . Consider the characterization of the RDF of Theorem 7 and the realization of of Theorem 3a and Theorem 4a. Define the translated RVs
Let
Then,
where are given in Theorem 3a.
Proof.
By Theorem 3a,
The last equation establishes (115). By properties of conditional mutual information and the properties of optimal realization , the following equalities hold.
Moreover, inequality (136) holds with equality if are jointly independent. The average distortion function is then given by
By Corollary 1, if (105) holds, that is, and satisfy (i.e., commute), then (106)–(108) hold, and by (122) we obtain
Hence, if (105) holds, then the lower bound in (136) holds with equality because are jointly independent. Moreover, if (105) holds, then from, say, (118), the expressions (122) and (123) are obtained. The above equations establish all claims. □
Proposition 4.
Theorem 4 is correct.
Proof.
By invoking Corollary 2, Theorem 7 and the convexity of given by (122), then we arrive at the statements of Theorem 4, which completely characterize the RDF and construct a realization of the optimal that achieves it. □
Next, we discuss the degenerate case, when the statements of Theorems 3, 4 and 7 reduce to the RDF of a Gaussian RV X with square-error distortion function. We illustrate that the identified structural property of the realization matrices leads to to the well-known water-filling solution.
Remark 3.
Degenerate case of Theorem 7 and realization of Theorem 4a. Consider the characterization of the RDF of Theorem 7, the realization of Theorem 3a, Theorem 3, and assume X and Y are independent or Y generates the trivial information; i.e., the algebra of Y is or in (15)–(18).
(a) By the definitions of then
Substituting (142) into the expressions of Theorem 7, the RDF reduces to
where
and the optimal reproduction reduces to
Thus, is the well-known RDF of a multivariate memoryless Gaussian RV X with square-error distortion.
(b) For the RDF of part (a), it is known [24] that and have a spectral decomposition with respect to the same unitary matrix, that is,
where the entries of are in decreasing order.
Define
Then, a parallel channel realization of the optimal reproduction is obtained as follows:
The RDF is then computed from the reverse water-filling equations as follows.
where
and is a Lagrange multiplier (obtained from the Kuch–Tucker conditions).
4.2. Side Information Only at Decoder
In general, when the side information is available only at the decoder, the achievable operational rate is greater than the achievable operational rate when the side information is available to the encoder and the decoder [2]. By Remark 1, , and equality holds if .
In view of the characterization of and the realization of the optimal reproduction of Theorem 3, which is presented in Figure 3, we observe that we can re-write (49) as follows.
Proposition 5.
Theorem 5 is correct.
Proof.
From the above realization of , we have the following. (a) By Wyner, see Remark 1, then the inequalities (36) and (37) hold, and equalities hold if . That is, for any , and by the properties of conditional mutual information, then
where is due to , is due to the chain rule of mutual information, and is due to . Hence, (72) is obtained (as in Wyner [2] for a tuple of scalar jointly Gaussian RVs). (b) Equality holds in (164) if there exists an such that , and the average distortion is satisfied. Taking , where is specified by (156)–(160), then and the average distortion is satisfied. Since the realization (156)–(160) is identical to the realization (73)–(76), then part (b) is also shown. (c) This follows directly from the optimal realization. □
5. Connection with Other Works and Simulations
In this section, we illustrate that for the special case of scalar-valued jointly Gaussian RVs , our results reproduce Wyner’s [2] results. In addition, we show that the characterizations of the RDFs of the more general problems considered in [5,6] (i.e., where a noisy version of source is available at the encoder) do not reproduce Wyner’s [2] results. Finally, we present simulations.
5.1. Connection with Other Works
Remark 4.
The degenerate case to Wyner’s [2] optimal test channel realizations. Now, we verify that for the tuple of scalar-valued, jointly Gaussian RVs , with square error distortion function specified below, our optimal realizations of and closed form expressions for and are identical to Wyner’s [2] realizations and RDFs (see Figure 4). Let us define:
(a) RDF : By Theorem 4a applied to (165)–(168), we obtain
Moreover, by Theorem 4b the optimal reproduction and are,
This shows our realization of Figure 3 degenerates to Wyner’s [2] realization of Figure 4a.
In the following Remark, we show that, when -a.s., the realization of the auxiliary RV Z, which is used in the proofs in [5,6] to show the converse coding theorem does not coincide with Wyner’s realization [2]. Also, their realizations do not reproduce Wyner’s RDF (this observation is verified for modified realization given in the correction note without proof in https://tiangroup.engr.tamu.edu/publications/ (accessed on 3 January 2024)). The deficiency of the realizations in [5,6] to show the converse was first pointed out in [7], using an alternative proof.
Remark 5.
(a) The derivation of [[5], Theorem 4], uses the following representation of RVs (see [[5], Equation (4)] adopted to our notation using (19)):
where and are independent Gaussian RVs with zero mean, is independent Y and is independent of .
To reduce [5,6] to the Wyner and Ziv RDF, we set , which then implies, and . According to the derivation of the converse [[5], Theorem 4] (see [[5], 3 lines above Equation (32)] using our notation), the optimal realization of the auxiliary RV used to achieve the RDF is
where and U is a unitary matrix, such that is a diagonal covariance matrix, with elements given by (for the value of , we considered the one given in the correction note in https://tiangroup.engr.tamu.edu/publications/ (accessed on 3 January 2024) (although no derivation is given), where it is stated that that appeared in the derivation [[5], proof of theorem 4] should be multiplied by ),
(b) It is easy to verify that the above realization of that uses the correction of footnote 6 is precisely the realization given in [[6], Theorem 3A].
(c) Special Case: For scalar-valued RVs the auxiliary RV reduces to
Now, we examine whether the realization (179) corresponds to Wyner’s realization and induces Wyner’s RDF. Recall that the Wyner’s [2] RDF, denoted by and corresponding to auxiliary RV Z, is
Clearly, the two realizations (179) and (180) are different. Let denote the RDF corresponding to the realization . Then can be computed using where denotes the conditional differential entropy. Then, by using
it is straightforward to show that
However, we note that (i) unlike Wyner’s RDF given in (181), which gives at , the corresponding at , and (ii) Wyner’s test channel realization is and , which is different from the test channel realization in (179). In particular, if , then and . On the other hand, for the test channel in (179), if , then , and thus the variance of in (179) is not zero.
Further, in Proposition 6, we prove that for the multi-dimensional source, the test channel realization in (179) does not achieve the RDF when water-filling is active, i.e., when at least one component of the source is not reproduced.
(d) Special Case Classical RDF: The classical RDF is obtained as a special case if we assume X and Y are independent or Y generates the trivial information ; i.e., Y is nonrandom. Clearly, in this case, the RDF should degenerate to the classical RDF of the source X, i.e., , and it should be that . However, for this case, (179) gives , which is fundamentally different from Wyner’s degenerate, and correct values .
Proposition 6.
Proof.
Recall that, if the two auxiliary RVs and Z are not related by an invertible function, i.e., , where is invertible and both f and its inverse are measurable, then . It was shown earlier in this paper (and also in [7]) that for the multivariate Wyner’s RDF, the auxiliary RV takes the form
where , , and , where U is a unitary matrix. The eigenvalues and are given by
where . Hence, Equations (186), (187), and (188), imply that if then , and vice versa. Such zero values correspond to compression with water-filling. On the other hand, from (177) and (178), if water-filling is active, then . Moreover, by comparing Equations (187) with (178) and (188) with (177), it is straightforward to show that . If is not an invertible matrix for all values of the distortion , then .
By (188) it is easy to show that if , is not invertible. This implies . □
5.2. Simulations
In this section, we provide an example to show the gap between the classical rate distortion defined in (154), the conditional distortion function (69), and to verify the validity of Gray’s lower bound (8). Note that in Theorem 5 it is shown that , and hence the plot for is omitted. For the evaluation, we pick a joint covariance matrix (11) given by
In order to compute the rates, we first have to find and . From the definition of given in (11), it is easy to see that the covariance of X, Y, and the joint covariance of X and Y are equal to
Then, the conditional covariance , which appears in , can be computed from (27). Using Singular Value Decomposition (SVD), we can calculate the eigenvalues of . For this case, the eigenvalues of the conditional covariance are . Similarly, the eigenvalues of can be determined. Finally, the eigenvalues of and are passed to the water-filling to compute the and , respectively.
The classical rate distortion, the conditional RDF, and the Gray’s lower bound for the joint covariance above are illustrated in Figure 5. It is clear that is smaller, and as the distortion increases, the gap between the classical and conditional RDF becomes larger. Gray’s lower bound is achievable for some positive distortion values, as provided in (71), i.e., for . Recall that the set of eigenvalues of is , and the lower bound is achievable for ; i.e., for these values .
6. Conclusions
We derived nontrivial structural properties of the optimal test channel realizations that achieve the optimal test channel distributions of the characterizations of RDFs for a tuple of multivariate jointly independent and identically distributed Gaussian random variables with mean-square error fidelity for two cases. Initially, the side information was available at the encoder and decoder, and then it was only available at the decoder. Using the realizations of the optimal test channels, we showed that when the side information is known to the encoder and the decoder, it does not achieve a better compression compared to when side information is only known to the decoder.
Author Contributions
M.G. and C.D.C. contributed to the conceptualization, methodology, and writing of the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
The work of M.G. and C.D. Charalambous was co-funded by the European Regional Development Fund and the Republic of Cyprus through the Research and Innovation Foundation (Project: EXCELLENCE/1216/0296).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Appendix A
Appendix A.1. Proof of Lemma 1
(a) By the chain rule of mutual information,
Since , then from the above it follows
The above shows (40). However, the inequality holds with equality if and only if , and this quantity is zero if and only if . Alternatively, we note the following:
This completes the statement of equality of (40); i.e., it establishes equality (41). (b) Consider a test channel such that , i.e., , and such that , for . By (41) taking the infimum of both sides over such that , then (43) is obtained on a nontrivial surface, i.e., , which exists due to continuity and convexity of for . This completes the proof.
Appendix A.2. Proof of Theorem 2
(a) (1) By properties of conditional mutual information [18],
where is due to being a function of , and a well-known property of the mutual information [18] is due to the chain rule of mutual information [18], and is due to . Hence, inequality (45) is shown. (2) If (i) holds, i.e., - a.s, then , and hence the inequality (45) becomes an equality. If (ii) holds, since for fixed the function , uniquely defines , then , and the inequality (45) becomes an equality.
(b) The inequality (48) is well known due to the orthogonal projection theorem.
Appendix A.3. Proof of Theorem 7
Consider the realization (88). We identify the triple such that (84) or (87) hold; i.e., we characterize the set .
Case (i). , that is, . By Theorem 6, Case (i), we seek the triple such that (84) holds, i.e., . Recall that Conditions 1 and 2 of Theorem 6 are sufficient for .
Condition 1, i.e., (85). The left-hand side part of (85) is given by (this follows from mean-square estimation theory, or an application of (26) with )
Similarly, the right hand side of (85) is given by
Equating (A9) and (A12), then
Hence, G is obtained, and the reproduction is represented by
Condition 2, i.e., (86). To apply (86), the following calculations are needed.
By Condition 2 and (A28) and (A31),
It remains to show . This will follow shortly by identifying the equation for H as follows. Conditions 1 and 2 imply
By (A39), it then follows from (A33) that . From the specification of G the equation of given by (A33) and (A34) and given by (A39), and (A40) then follows the realization of Theorem 4.(a) for the case . Properties (58)–(61) are easily verified.
Case (ii). but not , that is, . We can verify that the stated realization in Theorem 4.(a) is such that Condition (87) holds. By (83) and the above calculations, we have
Since , , and , where , then an application of Proposition 3, implies that Condition (87) holds. Thus, we have established Theorem 3.(a) and the properties stated under Theorem 4.(a). (i)–(iv). Finally, (96)–(101) are obtained from the realization, and hence Theorem 3.(b) is achievable.
Appendix A.4. Proof of Corollary 1
(a) This part is a special case of a related statement in [22]. However, we include it for completeness. By linear algebra [21], given two matrices , then the following statements are equivalent: (1) is normal and (2) , where normal means . Note that is normal if and only if ; i.e., they commute. Let ,; i.e., there exists a spectral representation of in terms of unitary matrices and diagonal matrices . Then, if and only if the matrices A and B commute; i.e., , and A and B commute if and only if .
References
- Wyner, A.; Ziv, J. The rate-distortion function for source coding with side information at the decoder. IEEE Trans. Inf. Theory 1976, 22, 1–10. [Google Scholar] [CrossRef]
- Wyner, A. The rate-distortion function for source coding with side information at the decoder-II: General sources. Inf. Control. 1978, 38, 60–80. [Google Scholar] [CrossRef]
- Berger, T. Rate Distortion Theory: A Mathematical Basis for Data Compression; Englewood Cliffs: Prentice-Hall, NJ, USA, 1971. [Google Scholar]
- Gray, R.M. A new class of lower bounds to information rates of stationary sources via conditional rate-distortion functions. IEEE Trans. Inf. Theory 1973, 19, 480–489. [Google Scholar] [CrossRef]
- Tian, C.; Chen, J. Remote Vector Gaussian Source Coding With Decoder Side Information Under Mutual Information and Distortion Constraints. IEEE Trans. Inf. Theory 2009, 55, 4676–4680. [Google Scholar] [CrossRef]
- Zahedi, A.; Ostergaard, J.; Jensen, S.H.; Naylor, P.; Bech, S. Distributed remote vector gaussian source coding with covariance distortion constraints. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 586–590. [Google Scholar]
- Gkagkos, M.; Charalambous, C.D. Structural Properties of Test Channels of the RDF for Gaussian Multivariate Distributed Sources. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 2631–2636. [Google Scholar] [CrossRef]
- Draper, S.C.; Wornell, G.W. Side information aware coding strategies for sensor networks. IEEE J. Sel. Areas Commun. 2004, 22, 966–976. [Google Scholar] [CrossRef]
- Oohama, Y. Gaussian multiterminal source coding. IEEE Trans. Inf. Theory 1997, 43, 1912–1923. [Google Scholar] [CrossRef]
- Oohama, Y. Rate-distortion theory for Gaussian multiterminal source coding systems with several side informations at the decoder. IEEE Trans. Inf. Theory 2005, 51, 2577–2593. [Google Scholar] [CrossRef]
- Viswanathan, H.; Berger, T. The quadratic Gaussian CEO problem. IEEE Trans. Inf. Theory 1997, 43, 1549–1559. [Google Scholar] [CrossRef]
- Ekrem, E.; Ulukus, S. An outer bound for the vector Gaussian CEO problem. In Proceedings of the 2012 IEEE International Symposium on Information Theory Proceedings, Cambridge, MA, USA, 1–6 July 2012; pp. 576–580. [Google Scholar]
- Wang, J.; Chen, J. Vector Gaussian Multiterminal Source Coding. IEEE Trans. Inf. Theory 2014, 60, 5533–5552. [Google Scholar] [CrossRef]
- Xu, Y.; Guang, X.; Lu, J.; Chen, J. Vector Gaussian Successive Refinement With Degraded Side Information. IEEE Trans. Inf. Theory 2021, 67, 6963–6982. [Google Scholar] [CrossRef]
- Renna, F.; Wang, L.; Yuan, X.; Yang, J.; Reeves, G.; Calderbank, R.; Carin, L.; Rodrigues, M.R.D. Classification and Reconstruction of High-Dimensional Signals From Low-Dimensional Features in the Presence of Side Information. IEEE Trans. Inf. Theory 2016, 62, 6459–6492. [Google Scholar] [CrossRef]
- Salehkalaibar, S.; Phan, B.; Khisti, A.; Yu, W. Rate-Distortion-Perception Tradeoff Based on the Conditional Perception Measure. In Proceedings of the 2023 Biennial Symposium on Communications (BSC), Montreal, QC, Canada, 4–7 July 2023; pp. 31–37. [Google Scholar]
- Gallager, R.G. Information Theory and Reliable Communication; John Wiley & Sons, Inc.: New York, NY, USA, 1968. [Google Scholar]
- Pinsker, M.S. The Information Stability of Gaussian Random Variables and Processes; Holden-Day, Inc.: San Francisco, CA, USA, 1964; Volume 133, pp. 28–30. [Google Scholar]
- Aries, A.; Liptser, R.; Shiryayev, A. Statistics of Random Processes II: Applications; Stochastic Modelling and Applied Probability; Springer: New York, NY, USA, 2013. [Google Scholar]
- van Schuppen, J. Control and System Theory of Discrete-Time Stochastic Systems; Number 923 in Communications and Control Engineering; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Horn, R.A.; Johnson, C.R. (Eds.) Matrix Analysis, 2nd ed.; Cambridge University Press: New York, NY, USA, 2013. [Google Scholar]
- Charalambous, C.; Charalambous, T.; Kourtellaris, C.; van Schuppen, J. Structural Properties of Nonanticipatory Epsilon Entropy of Multivariate Gaussian Sources. In Proceedings of the 2020 IEEE International Symposium on Information Theory, Los Angeles, CA, USA, 21–26 June 2020; pp. 586–590. [Google Scholar]
- Gorbunov, A.K.; Pinsker, M.S. Prognostic Epsilon Entropy of a Gaussian Message and a Gaussian Source. Probl. Inf. Transm. 1974, 10, 93–109. [Google Scholar]
- Ihara, S. Information Theory for Continuous Systems; World Scientific: Singapore, 1993. [Google Scholar]
Figure 1.
The Wyner and Ziv [1] block diagram of lossy compression. If switch A is closed, then the side information is available at both the encoder and the decoder; if switch A is open, the side information is only available at the decoder.
Figure 1.
The Wyner and Ziv [1] block diagram of lossy compression. If switch A is closed, then the side information is available at both the encoder and the decoder; if switch A is open, the side information is only available at the decoder.

Figure 2.
Test channel when side information is only available to the decoder.

Figure 3.
: A realization of optimal reproduction over parallel additive Gaussian noise channels of Theorem 4, where are the diagonal element of the spectral decomposition of the matrix , and , the additive noise introduced due to compression.
Figure 3.
: A realization of optimal reproduction over parallel additive Gaussian noise channels of Theorem 4, where are the diagonal element of the spectral decomposition of the matrix , and , the additive noise introduced due to compression.

Figure 4.
Wyner’s realizations of optimal reproductions for RDFs and . (a) RDF : Wyner’s [2] optimal realization of for RDF of (165)–(168). (b) RDF : Wyner’s [2] optimal realization for RDF of (165)–(168).

Figure 5.
Comparison of classical RDF, , conditional RDF , and Gray’s lower bound (solid green line).
Figure 5.
Comparison of classical RDF, , conditional RDF , and Gray’s lower bound (solid green line).

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gkagkos, M.; Charalambous, C.D. Structural Properties of the Wyner–Ziv Rate Distortion Function: Applications for Multivariate Gaussian Sources. Entropy 2024, 26, 306. https://doi.org/10.3390/e26040306
AMA Style
Gkagkos M, Charalambous CD. Structural Properties of the Wyner–Ziv Rate Distortion Function: Applications for Multivariate Gaussian Sources. Entropy. 2024; 26(4):306. https://doi.org/10.3390/e26040306
Chicago/Turabian StyleGkagkos, Michail, and Charalambos D. Charalambous. 2024. "Structural Properties of the Wyner–Ziv Rate Distortion Function: Applications for Multivariate Gaussian Sources" Entropy 26, no. 4: 306. https://doi.org/10.3390/e26040306
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.