
Abstract
Predicting and interpolating the permeability between wells to obtain the 3D distribution is a challenging mission in reservoir simulation. The high degree of heterogeneity and diagenesis in the Nullipore carbonate reservoir provide a significant obstacle to accurate prediction. Moreover, intricate relationships between core and well logging data exist in the reservoir. This study presents a novel approach based on Machine Learning (ML) to overcome such difficulties and build a robust permeability predictive model. The main objective of this study is to develop an ML-based permeability prediction approach to predict permeability logs and populate the predicted logs to obtain the 3D permeability distribution of the reservoir. The methodology involves grouping the reservoir cored intervals into flow units (FUs), each of which has distinct petrophysical characteristics. The probability density function is used to investigate the relationships between the well logs and FUs to select high-weighted input features for reliable model prediction. Five ML algorithms, including Linear Regression (LR), Polynomial Regression (PR), Support Vector Regression (SVR), Decision Trees (DeT), and Random Forests (RF), have been implemented to integrate the core permeability with the influential well logs to predict permeability. The dataset is randomly split into training and testing sets to evaluate the performance of the developed models. The models’ hyperparameters were tuned to improve the model’s prediction performance. To predict permeability logs, two key wells containing the whole reservoir FUs are used to train the most accurate ML model, and other wells to test the performance. Results indicate that the RF model outperforms all other ML models and offers the most accurate results, where the adjusted coefficient of determination (R2adj) between the predicted permeability and core permeability is 0.87 for the training set and 0.82 for the testing set, mean absolute error and mean squared error (MSE) are 0.32 and 0.19, respectively, for both sets. It was observed that the RF model exhibits high prediction performance when it is trained on wells containing the whole reservoir FUs. This approach aids in detecting patterns between the well logs and permeability along the profile of wells and capturing the wide permeability distribution of the reservoir. Ultimately, the predicted permeability logs were populated via the Gaussian Random Function Simulation geostatistical method to build a 3D permeability distribution for the reservoir. The study outcomes will aid users of ML to make informed choices on the appropriate ML algorithms to use in carbonate reservoir characterization for more accurate permeability predictions and better decision-making with limited available data.
Similar content being viewed by others

Introduction
Permeability is a crucial petrophysical parameter for reservoir simulation. It is essential for selecting the optimum development scenarios. It can be measured via core sampling or pressure testing methods. However, these methods are limited, costly, and time-consuming. Thus, several researchers tried integrating permeability with well logs to obtain a continuous permeability profile along the reservoir. Kozeny (1927) and Carman (1937) created the permeability correlation with formation porosity. This model assumes that pores are cylindrical. However, pore shape can vary from one unit to another within the reservoir. Moreover, the model ignores the lack of a basic relationship between porosity and permeability; as zones with equal porosity but different permeability exist in the same reservoir. Besides, some carbonate reservoirs constitute low porosity and high permeability due to fractures. Both depositional factors—such as pore geometry, grain size, tortuosity-, and diagenetic ones—as cementation, dissolution, and fracturing-affect permeability. Subsequently, a more reliable approach was needed to take into account the fundamentals of geology and flow physics in porous media.
Wendt et al. (1986), Balan et al. (1995), and Xue et al. (1997) reported that integrating permeability with logs other than porosity and using multiple linear regression analysis increases the correlation between measured and predicted permeability. This approach assumes a linear relationship between permeability and influential well logs. However, this is not the case in many reservoirs, especially in heterogeneous ones, where non-linear and complex relationships exist between well logs and permeability.
To overcome such challenges, Machine Learning (ML) has been extensively introduced and tested as a regression tool for the prediction of reservoir permeability from well logs (Akande et al. 2017; Zhu et al. 2017; Elkatatny et al. 2018; Okon et al. 2021; Male et al. 2020; Lv et al. 2021; Kamali et al. 2022; Abbas et al. 2023; Matinkia et al. 2023; Mahdy et al. 2024).
In some reservoirs, categorizing the reservoir into hydraulic flow units (HFUs), where each unit has geological and petrophysical characteristics different from the other, improves the permeability prediction. Amaefule et al. (1993) presented the Flow Zone Indicator (FZI) concept to group the reservoir into HFUs, where each unit has a similar FZI. Several researchers integrated the FZI with well logs via multiple regression analysis, artificial neural networks (ANN), and adaptive neuro-fuzzy inference system to estimate the FZI from logs, thereafter computed permeability from FZI (Aminian et al.; 2003; Kharrat et al. 2009; Khalid et al. 2020; Alizadeh et al. 2022; Djebbas et al. 2023).
Although ML-based models have been extensively used for permeability prediction, there are significant challenges and shortcomings in the application of these models to heterogeneous reservoirs. Most ML studies did not present a systematic approach to predict permeability in complex carbonate reservoirs along the wells profile to be further populated in 3D. In the present study, a systematic novel approach based on Machine Learning is presented to predict the permeability logs in the Nullipore heterogeneous carbonate reservoir in Ras Fanar field using core and well logs data. In this approach, the reservoir is divided into different HFUs. Five Machine Learning algorithms, namely Linear Regression (LR), Polynomial Regression (PR), Support Vector Regression (SVR), Decision Trees (DeT), and Random Forests (RF), were applied to integrate the core permeability data with well logging ones and their performance was evaluated. The most accurate algorithm was applied to predict permeability logs along the profile of wells. Contrary to the existing models in the literature, the new approach presented in this study is applied to two key wells containing all the reservoir HFUs to train the algorithm. Other wells are used as blind test wells for model validation. This approach enables the model to detect the patterns between the input and output data for the whole permeability variation range, hence capturing the permeability heterogeneity of the reservoir. The study aims to (a) identify the reservoir HFUs from core data, (b) analyze the quality of the reservoir in terms of storage and flow capacities, and (c) develop an ML-based permeability prediction approach to predict permeability logs along the wells profile and populate the predicted logs to obtain 3D permeability distribution of the reservoir. Furthermore, the study provides a reference for predicting permeability in complex carbonate reservoirs, which can be followed in other areas that have similar geological conditions.
Location and geology of the study area
The most prolific hydrocarbon province in Egypt is the Gulf of Suez rift basin. It has 80% of oil reserves and gives 75% of oil production in Egypt. Ras Fanar field is an oil field located on the offshore western side of the central province of the Gulf of Suez (G.O.S), Egypt (Fig. 1). The field lies 3.5 km east of Ras Gharib shoreline in the Belayim dip province of northeast direction; between latitudes 28° 13ʹ and 28° 18ʹ to the north, and longitudes 33° 11ʹ and 33° 17ʹ to the east. The Middle Miocene Nullipore reservoir is the main oil-producing unit in the field. It is equivalent to the Hammam Faraun Member of the Belayim Formation. Belayim formation represents a part of the Middle Miocene syn-rift succession in the Ras Fanar field (Moustafa 1976).

Location map of Ras Fanar field
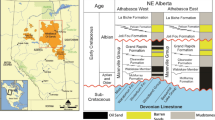
Three depositional sequences characterize the rift stratigraphy of G.O.S, as follows: Pre-rift sequence (Paleozoic to Late Eocene), syn-rift (Early to Late Miocene), and post-rift (Post-Miocene). The Ras Fanar field was produced from an NW–SE structural trap bounded by a major fault system to the SW and tilted to NE. The Ras Fanar area sedimentary succession ranges in age from Paleozoic to recent, as shown in Fig. 2. The syn-rift succession is represented by Belayim formation at the base, South Gharib formation in the middle, and Zeit formation at the top (Souaya 1965; Hosny et al. 1986; Rateb 1988).

Lithostratigraphic column of Ras Fanar field. Modified after (El Naggar 1988)
The Nullipore represents the main carbonate reservoir unit in the Ras Fanar field. It contributes to about half of the field production. Thiébaud and Robson (1979) introduced the Nullipore reservoir as bioclastic Limestone exposed at the G.O.S region, with frequent occurrence of reefs, corals, and algae.
As a result of the rifting of the Suez Gulf, several stratigraphic successions were developed on both sides of the Gulf. Moreover, many grabens, half-grabens, and horst blocks were created. Ras Fanar was a positive highland area during the Early Miocene and was subjected to severe erosion. In the adjacent lowland troughs, a thick organic-rich shale sequence was deposited. The area was submerged by a shallow sea during the Early Middle Miocene. This allows the accumulation of thick algal-reefal carbonate facies of the Nullipore reservoir. More arid conditions exist by the end of the Middle Miocene, resulting in vertical and lateral facies changes from carbonates to alternative cycles of evaporates, siliciclastics, and carbonates of South Gharib and Zeit formations (Moustafa 1977; Thiébaud and Robson 1979; Chowdhary and Taha 1986; El Naggar 1988; Ouda and Masoud 1993; Khalil and McClay 2001).
Materials and methodology
Four wells drilled in the Ras Fanar field have been assessed in this study. The wells targeted the Middle Miocene Nullipore reservoir. Routine core analysis (RCA) was performed on 794 core plug samples from the four wells. RCA involves porosity acquired by a helium porosimeter and horizontal permeability measured by a permeameter. Conventional well logs, comprising gamma-ray (GR), neutron (NPHI), density (RHOB), and compressional slowness data in every 0.5 ft. are available from the wells.
The following steps were followed to achieve the aim of the study: (1) reservoir litho-facies were determined at the four wells, (2) wells that have cored and logged reservoir intervals with similar litho-facies were selected, (3) Available cores from the selected wells were analyzed to identify the hydraulic flow units (HFUs) in the reservoir, relying on the concept of flow zone indicator (FZI), (4) Core-log depth match was performed, (5) well logs, including gamma-ray, resistivity, Neutron, bulk density, sonic, were analyzed at the selected wells, (6) Five logs were initially selected as input features to build the permeability model. The logs include sonic, density, neutron, effective porosity, and volume of minerals logs. The probability density function (PDF) was used to investigate the relationships between the selected logs and FUs, (7) the influential logs and the reservoir FUs were integrated with permeability via five Machine Learning algorithms to predict permeability from the logs.
The dataset was split into training and testing sets to evaluate the performance of each model via three evaluation metrics: mean absolute error (MAE), mean squared error (MSE), and adjusted coefficient of determination (R2adj). Hyperparameters of the models were tuned to choose the optimal values of parameters that improve the models' performance and achieve high accuracy. The most accurate model was selected to predict the permeability logs of the studied wells. The data of two wells containing the whole reservoir FUs were used to train the model. The model accuracy was checked by using other wells as blind test wells. The developed model was used to predict the permeability in logged un-cored intervals. The predicted permeability logs were populated via geostatistics to create the 3D distribution of reservoir permeability. Figure 3 indicates the workflow used in this study for predicting permeability logs via ML.

Flow chart of the proposed methodology to predict and distribute permeability logs
Hydraulic flow units
Petroleum geologists and engineers have recognized the need to define geological/engineering units to shape the description of reservoir zones as storage containers and conduits for fluid flow. Depositional and diagenetic processes result in the formation of different flow units in the reservoir. A flow unit (FU) was defined by Bear (1988) as a representative reservoir volume that has the same geological and petrophysical characteristics. Hearn et al. (1984) defined the FU as the reservoir portion that is continuous laterally and vertically and has similar bedding characteristics, porosity, and permeability.
To identify the trends between porosity and permeability, Amaefule et al. (1993) presented the concept of Flow Zone Indicator (FZI). The modified form of the Kozeny-Carman equation for estimating permeability is given by:
where K is the permeability, md, \({F}_{s}\) is the pore shape factor, T is the tortuosity of the path of flow, \({S}_{{\text{vgr}}}\) is the specific area per unit grain volume, and \(\Phi\) is the effective porosity, fraction (Kozeny 1927; Carman 1937).
Since it is difficult to determine \({F}_{s}, {S}_{{\text{vgr}}}\), and T, Amaefule et al. (1993) defined the FZI parameter as the square root of \((\frac{1}{{ {F}_{s}. T}^{2}. {S}_{{\text{vgr}}}^{2}}\)) and developed an equation to calculate FZI from core data, as follows:
where RQI is the reservoir quality index, µm, and \({\Phi }_{{\text{z}}}\) is the normalized porosity.
The calculated FZI is used to group the reservoir into different FUs, through the following formula:
The base of categorizing the reservoir into flow units is identifying clusters that achieve unit slope straight lines on the plot (log RQI vs. log \({\Phi }_{z}\)), where each cluster has unique geological and petrophysical characteristics (porosity and permeability) (Tiab and Donaldson 2015).
Machine learning
In this study, we aim to integrate the core permeability of each FU with the well logs via Machine Learning to predict permeability logs along the wells profile.
Machine Learning (ML) evolved as a subfield of artificial intelligence (AI), including self-learning algorithms that derive knowledge from data, instead of requiring humans to manually derive rules and build models, to improve the performance of predictive models, and make data-driven decisions. ML is considered the cornerstone in the new era of big data. It has been successfully applied in the Geoscience field to predict different reservoir properties (Raschka and Mirjalili 2019; Al Khalifah et al. 2020; Alizadeh et al. 2022).
This study focuses on a specific field of ML called predictive modeling of a continuous variable (permeability). Predictive modeling focuses on developing models that create accurate predictions at the expense of explaining why the predictions are made. Five Machine Learning (ML) algorithms were implemented via Python programming language. The algorithms involve Linear Regression (LR), Polynomial Regression (PR), Support Vector Regression (SVR), Decision Trees (DeT), and Random Forests (RF).
Linear regression
Linear regression is a statistical method used to predict the value of a response (dependent variable) from known values of one or more independent variables (regressors). Transformation of data may be required to achieve a better fit between variables. The general form of the equation is:
where Y is the dependent variable, Xn is the independent variable/s, bo is the intercept, and b’s are the regression coefficients.
In this study, core permeability is the dependent variable, while the FU and influential well logs are the independent variables.
Polynomial regression
If the data of the model is more complex than a linear straight line, the algorithm of Polynomial Regression (PR) can be effective to fit the non-linearity. The algorithm involves adding powers of each feature as new features and thereafter trains a linear model on the new features. Moreover, PR can find relationships between features by adding combinations of features up to the given degree. For example, if the model has two input features a and b, Polynomial features with degree 3 will not only add a2, a3, b2, and b3, but also the combination ab, a2b, and ab2 (Géron 2022).
Support vector regression
One of the versatile Machine Learning algorithms that are capable of performing linear or nonlinear classification and regression issues is the Support Vector Machine (SVM). SVM is particularly well suited for complex but small- to medium-sized datasets for classification issues (Géron 2022).
In this article, we are concerned with Support Vector Regression (SVR) to predict permeability. SVR differs from Linear Regression (LR) in searching for a hyperplane that best fits the data points in a continuous space, instead of fitting a line to the data points. Besides, in contradiction with LR which aims to minimize the sum of squared errors, the objective function of SVR is to minimize the coefficients of the variables and give the flexibility to define how much error is acceptable in the model. The error term is handled in the constraints, where the absolute error is set less than or equal to a specified margin, named the maximum error (epsilon, ɛ). The epsilon must be tuned to gain the desired accuracy of the model. The “C” hyperparameter controls the balance between samples in the decision boundary and margin violations (outliers).
To tackle non-linear problems, SVR maps the input features into a higher dimension space through a kernel trick. The kernel is a function that transforms the non-linear pattern to a linear one in a higher dimension space. Polynomial, sigmoid, and radial basis function (RBF) kernels can achieve this task. One can select the kernel function type according to the trends between the input features and the target variable. In this study, linear, polynomial, and RBF kernels were used sequentially, and the one that achieves the highest accuracy was selected to develop the SVR permeability model.
Since SVR relies on distances between data points, it is beneficial to scale the input features to ensure that they fit into the same range. In this study, the features are standardized by removing the mean and scaling to unit variance (features range from − 1 to 1) (Géron 2022).
Decision trees
Decision trees (DeT) is a ML algorithm that can fit complex datasets, and perform classification and regression tasks. DeT are the basic components of Random Forests. DeT aims to develop a model that predicts a target variable by learning simple decision rules inferred from data features. The algorithm splits the training set into two subsets using a single feature (k) and a threshold (tk). The pair (k, tk) that produces the least mean squared error (MSE) is considered the best split. The prediction is the average target value of the training instances associated with the leaf node. The cost function that the algorithm tries to minimize is given by:
where “mright/left” is the number of instances in the right/left subset.
The tree starts at the root node (depth 0 at the top): this node assumes certain condition. In other words, the node asks whether a feature is smaller than a certain value. If the data sample satisfies this condition, it will move down to the root’s left child node (depth 1, left) and so on till it reaches the leaf node (last node in the tree on the left side). On the other hand, if the sample is greater than the value of the root node, it will move to the root’s right child node (depth 1, right), and so on till it reaches the leaf node (Géron 2022).
Particularly, DeT does not require feature scaling or centering at all. Moreover, the trees do not assume the linearity of data. The tree adapts itself to the training data. To avoid overfitting, hyperparameters of the tree must be regularized, particularly its depth and the minimum number of samples that can be split at each node (Géron 2022).
Random forests
A Random Forest (RF) is an ensemble of decision trees. The concept of RF is to average multiple decision trees that individually suffer from high variance to build a more robust model that has a better generalization performance. The algorithm can be summarized in four steps: choose “n” samples from the training data randomly, grow a decision tree from the selected samples via selecting some features randomly and splitting the node using the feature that provides the best split, repeat steps 1 & 2 k-times, and finally, aggregate the prediction of each tree and take the average value (Raschka and Mirjalili 2019).
Cross-validation
The accuracy and prediction performance of ML models can be assessed using various techniques of cross-validation, such as random subsampling and K-fold cross-validation. Random subsampling is carried out by splitting the original dataset into two parts: training and testing sets. The ML algorithm is trained on the first part, makes predictions on the second part and evaluates the predictions against the expected results. This prevents the problem of overfitting, assures the external prediction and gives more trust for the prediction given different datasets with the same parameters. K-fold cross-validation is adopted by partitioning the training dataset into k-folds (e.g. k = 5, or k = 10). Each partition is called a fold. “k−1” folds are used for training the algorithm and one is held back for model validation. This procedure is repeated so that each fold is given a chance to be used for testing. The dataset size controls the number of folds. A small number of folds leads to large bias and small variance with reduced computation time. On the other hand, a large number of folds leads to large variance and small bias with large computation time. Using tenfold cross-validation is a common choice. The performance measure is then the average of the values computed in the loop (Al-Mudhafar 2016; Brownlee 2016).
Results and discussion
Core data
Nullipore reservoir penetrated by four wells in Ras Fanar field is mainly dolomitic Limestone with considerable amounts of Anhydrite and minor intercalations of Shale.
A plot of core porosity vs. logarithm of permeability (LK) of the cored intervals of the four wells is shown in Fig. 4. Descriptive statistics of core porosity and permeability are summarized in Table 1. The figure indicates a very poor correlation (R2 = 0.4286) with high a degree of scatter and samples of the same porosity but different permeability. This is a result of the existence of more than one FU in the reservoir, where each unit has rock and fluid flow properties different from the other. Hence, grouping the reservoir into different FUs is essential. The approach of FZI was applied. Figure 5 shows a plot of log phiz vs. log RQI of the core data. The figure indicates the existence of two FUs, where each unit has a unit slope and mean FZI (0.51 and 2.42, respectively). This reflects that each unit has fluid flow properties different from the other.

A plot of core porosity vs. logarithm of core permeability of the four wells

A plot of log normalized porosity vs. log RQI of the core data
A plot of porosity vs. log of permeability for each FU is shown in Fig. 6. It is evident from the figure that the porosity–permeability correlation is improved relative to Fig. 4, where R2 is 0.74 for the first FU and 0.58 for the second one.

A plot of porosity vs. log of permeability for each FU
The range of FZI, average value of FZI, porosity, and permeability of each unit are summarized in Table 2. The table indicates the notable difference in average permeability between the two FUs, hence the difference in their fluid flow capacity, where the average permeability of the first FU is 0.19, whereas that of the second FU is 1.96. This means that the second FU with a higher FZI (2.42) has better reservoir quality and percolation capacity than the first FU (FZI = 0.51).
Sensitivity analysis of well logs
Five well logs were initially selected to create the permeability model, as follows: sonic log, bulk density (RHOB), neutron porosity log (NPHI), effective porosity (phiE), and volume of minerals log (Vminerals). It must be highlighted that the effective porosity log was developed by combining the three porosity logs; neutron, density, and sonic. Besides, the volume of minerals log was created from the density log. Shale volume is not considered because its volume is very low in the reservoir, hence is discarded. On the other hand, sonic, neutron, and bulk density logs are raw logs. The statistical parameters of the logs of the two FUs are shown in Tables 3 and 4, respectively.
The probability density function (PDF) was used to investigate the relationships between the selected logs and reservoir FUs. PDF of each log is plotted and compared. If the two curves are distinctly separated, the log is considered a good regressor and can be used in the predictive model. On the other hand, if the curves are overlapping and forming one cluster with almost the same mean, the log is not considered a good regressor, hence discarded from the model.
The density functions of the sonic log are shown in Fig. 7a. The second curve (FU 2) has a wider range of interval transit time than the first curve. This is a result of the higher porosity and permeability of the second flow unit than the first one. Therefore, the sonic log is a good regressor and can be used in the model.

The probability density functions of the selected logs for the reservoir FUs a sonic log, b density log, c neutron porosity, d effective porosity log, and e volume of minerals log
Figure 7b shows the density functions of the density log. The two curves are clearly separated, with different means, where the second curve has a lower density (due to higher porosity and permeability) than the second curve. Consequently, the density log is good a regressor and can be used in the model.
The density functions of the neutron log of the two flow units are shown in Fig. 7c. The two curves of the two flow units are very similar with the same mean and are not distinctly separated, hence no relation exists between neutron porosity and permeability as the log gives different responses to the same permeability. So, the neutron log is discarded from the model.
The density functions of the effective porosity log are shown in Fig. 7d. The two curves are separated. The first curve has a lower mean value of porosity than the second curve. Subsequently, the effective porosity log is a good regressor and can be used in the model.
The volume of minerals log involves the volumes of calcite, dolomite, and anhydrite (the main minerals in the reservoir). The density functions of the minerals log are shown in Fig. 7e. The two curves are similar and not distinctly separated, hence the log is discarded from the model.
According to the PDF, only sonic, density, and effective porosity logs can determine the reservoir FUs and can be used for building the permeability model.
Core-logs data integration
Core permeability and the influential logs data were imported into Python. The dataset was grouped into input features and target variable. FU, Sonic, Density (D), and effective porosity (phiE) logs are the input features, whereas core permeability (LK) is the target variable. FU was imported as a feature to get one model for the whole reservoir, instead of getting a model for each flow unit. Figure 8 shows a heat map of the well logs and LK for the two FUs of the reservoir based on the Pearson correlation coefficient (R). The figure indicates that phiE and DT logs have high positive R with LK for the two flow units (R = 0.73, 0.74, 0.63, and 0.7, respectively) for the two flow units, while D has a high negative correlation (R = − 0.62, and − 0.63, respectively).

Heat map of well logs and permeability of the reservoir flow units a heat map of FU 1, and b heat map of FU 2
The dataset was randomly split into 80% training (583 data samples) and 20% testing sets (145 data samples). The random generator seed was set to “60” to better compare the models.
In the case of SVR, DeT, and RF models, a grid search (LaValle et al. 2004) was conducted to select the optimum hyperparameters that provide better performance. The grid search function searches for various values of the model hyperparameter/s. The range of hyperparameters that have been tuned and that achieved the highest accuracy are shown in Table 5.
Evaluation of prediction accuracy of ML models
One or more evaluation metrics must be used to evaluate the performance of any ML model. In this study, three evaluation metrics were used to monitor the permeability prediction accuracy: Mean absolute error, mean squared error (MSE), and adjusted coefficient of determination (R2adj). MAE is the arithmetic average of the absolute errors between true values and predicted ones, where:
where Y is the logarithm of core permeability (LK), ϔ is the predicted logarithm of permeability, and n is the number of samples.
MSE is the average squared difference between true and predicted values, where:
Adjusted R2 is a statistical metric used to evaluate the goodness of fit of a regression model. It takes into account only the significant predictors that explain the variability in the data and improve the model performance. It is be expressed by:
where SSE is the error sum of squares, n is the number of samples, p is the number of predictors, and SST is the total sum of squares.
Performance of ML models
In this section, the performance of the permeability prediction of LR, PR, SVR (with kernel trick that provides the best performance), DeT, and RF models are evaluated and compared to core permeability for both training and testing sets. Performance of the linear, polynomial, and radial basis function kernel tricks of SVR for both training and testing sets is shown in Fig. 9. It is observed that RBF kernel trick outperforms the linear and polynomial tricks, where R2adj is 0.77, MAE is 0.34, and MSE is 0.29 for both training and testing sets, while in case of linear trick, R2 is 0.66, MAE is 0.44, and MSE is 0.37 for both sets. Results of the polynomial trick show R2 = 0.67, MAE = 0.44, and MSE = 0.42 for both sets. Consequently, the RBF trick is used to build the SVR permeability model.

Comparison of performance of kernel tricks of SVR of training and testing sets
Figures 10 and 11 show the logarithm of predicted permeability vs. the measured core permeability of the training and testing sets of the five ML models, respectively. Figure 12 indicates the evaluation metrics (R2adj, MAE, and MSE) of the training and testing sets of the five models.

A plot of the logarithm of predicted permeability and measured core permeability of the five ML models for the training sets

A plot of the logarithm of predicted permeability and measured core permeability of the five ML models for the testing sets

Validation metrics of permeability prediction of the five ML models for the training and testing sets
It is observed that poor correlation and high error appear in the case of the LR model where R2adj is 0.69, MAE is 0.44, and MSE is 0.36 for both the training and testing sets. The data samples are away from the 45-degree line (the farther the data is away from the 45-degree line, the lower the prediction accuracy, and vice versa). This can be attributed to the complex non-linear relation between the well logs and the permeability that the LR cannot capture since it assumes a linear relation between variables. Better correlation and lower error than the LR are obvious in the case of the SVR model, where R2adj is 0.77, MAE is 0.34, and MSE is 0.29 for both the training and testing sets. This is attributed to the ability of SVR to track the non-linearity between variables via the radial basis function kernel trick. The performance of the PR model is slightly better, where R2adj is 0.81 for the training set and 0.79 for the testing set, MAE is 0.38, and MSE is 0.29 for both sets. PR tries to track the non-linearity by increasing the polynomial degree of the input features (degree 5) in this case offers better performance than other polynomial degrees), hence correlation increases. The performance of the DeT model is very close to that of PR, where R2adj is 0.81 for the training set, 0.78 for the testing set, MAE is 0.39, and MSE is 0.28 for both sets. RF model provides the highest correlation and the least error among other ML models, where R2adj reaches 0.87 for the training set and 0.82 for the testing set, MAE is 0.32 for both sets, and MSE is 0.19 for both sets. The RF cross plot indicates that the data samples are closer to the 45-degree line than other models. RF provides high tree diversity via searching for the best feature among a random subset of features (not the whole subset, as DeT does), hence increasing the chance of determining the complex relationships between the features (well logs) and target variable (permeability), hence providing the best accuracy among all other models.
Predicting permeability in the studied wells
Since the RF algorithm provides the most accurate prediction results, it is used to predict the permeability logs in the studied wells. A new approach is presented for prediction, where two wells involving the two FUs were considered as key wells to train and develop the RF model, and the other two wells as blind test wells to evaluate the model performance. The comparison between the logarithm of predicted permeability and core permeability for the train wells, and the test wells is shown in Figs. 13a, b, 14a, b, respectively. Overall, the two figures indicate a good match between the predicted permeability and core permeability for the four wells. The approach of selecting wells constituting the reservoir FUs to train the RF model enables the model to select input and output data for the whole reservoir FUs. This enables the model to detect the patterns between the input and output data for the whole permeability variation range, hence capturing the permeability heterogeneity of the reservoir.

Comparison of the logarithm of predicted permeability and core permeability of the train wells a train well 1, and b train well 2

Comparison of the logarithm of predicted permeability and core permeability of the test wells a test well 1, and b test well 2
It must be highlighted that some high permeability values are underestimated by the model since the model ignored the higher values while fitting the pattern in the data, and such performance occurs at the expense of the model’s ability to fit the test (unseen) data. If the model fits the whole dataset that has a wide range of values, the overfitting problem will occur. Cross-validation was adopted and the pertinent hyperparameters were tuned for their optimized values to prevent this problem. This helps to apprehend the permeability heterogeneity and develop the best performing predictive model.
The developed RF model was used to predict the permeability logs for the logged uncored intervals of the reservoir for the four wells. The permeability logs of the four wells are shown in Fig. 15.

The permeability logs of the whole logged reservoir intervals for the studied wells
The wells data was imported in petrel software. The predicted permeability logs were upscaled and populated in the geological model by setting the appropriate variogram model and applying the Gaussian Random Function Simulation geostatistical method (GRFS). GRFS is a stochastic method that can produce local variation and reproduce input histograms. It honors well data, distributions of inputs, variogram, and trends. Figure 16 indicates the histogram of the K-log and upscaled log. It is evident from the figure that the upscaled data honors the input data, where 2.4% of data is > 1 md, 22% is between 3 and 9 md, 39% is between 30 and 90 md, 31.7% is between 300 and 900 md and 4.9% is > 2000 md. The parameters of the developed permeability model are summarized in Table 6. Figure 17 shows the 3D permeability distribution of the reservoir.

Histogram of the K-log and upscaled log

3D distribution of permeability of Nullipore reservoir
Summary and conclusions
This study provides a systematic approach for predicting and distributing permeability logs from conventional well logs via Machine Learning in the Middle Miocene Nullipore carbonate reservoir. Nullipore reservoir is highly heterogeneous with wide permeability distribution. Categorizing the cored intervals into flow units improves the reservoir characterization and permeability prediction. In this study, five ML algorithms were applied to integrate the core permeability of each flow unit with the influential well logs, and their performance was evaluated. The models involve Linear Regression (LR), Polynomial Regression (PR), Support Vector Regression (SVR), Decision Trees (DeT), and Random Forests (RF). Cross-validation of the dataset and hyperparameters’ tuning of the models reveals that RF is the most powerful ML model in tackling the complex non-linear relationships between the influential well logs and permeability, based on three evaluation metrics (R2adj, MAE, and MSE). Splitting the data into train and test sets allows for producing exterior prediction given the test dataset rather than prediction on the same data (interior prediction). A new approach is presented to predict the permeability logs in each well. The approach involves training the RF model on the core and logging data of two wells containing all the reservoir flow units and using the other wells as blind test wells. This aids in capturing the heterogeneity of reservoir permeability. Gaussian Random Function Simulation geostatistical method was used to populate the predicted permeability logs to obtain 3D distribution for the reservoir permeability.
Data availability
The data is confidential.
Abbreviations
- AI:
-
Artificial intelligence
- ANN:
-
Artificial neural networks
- D:
-
Density
- DeT:
-
Decision trees
- DT:
-
Delay time recorded by sonic log
- FZI:
-
Flow zone indicator
- GRFS:
-
Gaussian Random Function Simulation
- HFUs:
-
Hydraulic flow units
- LR:
-
Linear regression
- MAE:
-
Mean absolute error
- ML:
-
Machine learning
- MSE:
-
Mean squared error
- Pdf:
-
Probability density function
- PR:
-
Polynomial regression
- phiE:
-
Effective porosity
- RF:
-
Random forests
- RQI:
-
Reservoir quality index
- SVR:
-
Support vector regression
- Vminerals :
-
Volume of minerals
- F s :
-
Pore shape factor
- LK:
-
Logarithm of permeability
- R :
-
Pearson coefficient of correlation
- R 2 adj :
-
Adjusted coefficient of determination
- m right/left :
-
Number of instances in the right/left subset of Decision Tree
- S vgr :
-
Specific area per unit grain volume
- T :
-
Tortuosity
- ∆t :
-
Interval transit time, µs/ft
- Φ :
-
Porosity, fraction
- Φ z :
-
Normalized porosity
References
Abbas MA, Al-Mudhafar WJ, Wood DA (2023) Improving permeability prediction in carbonate reservoirs through gradient boosting hyperparameter tuning. Earth Sci Inf 16:1–16
Akande KO, Owolabi TO, Olatunji SO, AbdulRaheem A (2017) A hybrid particle swarm optimization and support vector regression model for modelling permeability prediction of hydrocarbon reservoir. J Petrol Sci Eng 150:43–53
Al Khalifah H, Glover P, Lorinczi P (2020) Permeability prediction and diagenesis in tight carbonates using machine learning techniques. Mar Pet Geol 112:104096
Alizadeh N, Rahmati N, Najafi A, Leung E, Adabnezhad P (2022) A novel approach by integrating the core derived FZI and well logging data into artificial neural network model for improved permeability prediction in a heterogeneous gas reservoir. J Petrol Sci Eng 214:110573
Al-Mudhafar WJ (2016) Incorporation of bootstrapping and cross-validation for efficient multivariate facies and petrophysical modeling. In: SPE rocky mountain petroleum technology conference/low-permeability reservoirs symposium. SPE, pp. SPE-180277-MS
Amaefule JO, Altunbay M, Tiab D, Kersey DG, Keelan DK (1993) Enhanced reservoir description: using core and log data to identify hydraulic (flow) units and predict permeability in uncored intervals/wells. In: SPE annual technical conference and exhibition. OnePetro
Aminian K, Ameri S, Oyerokun A, Thomas B (2003) Prediction of flow units and permeability using artificial neural networks. In: SPE Western Regional/AAPG Pacific Section Joint Meeting. OnePetro
Balan B, Mohaghegh S, Ameri S (1995) State-of-the-art in permeability determination from well log data: Part 1-A comparative study, model development. In: SPE Eastern Regional Meeting. OnePetro
Bear J (1988) Dynamics of fluids in porous media. Courier Corporation
Brownlee J (2016) Machine learning mastery with Python: understand your data, create accurate models, and work projects end-to-end. Machine Learning Mastery, San Francisco
Carman PC (1937) Fluid flow through a granular bed. Trans Inst Chem Eng London 15:150–156
Chowdhary L, Taha S (1986) History of exploration and geology of Ras Budran, Ras Fanar and Zeit Bay oil fields, Egyptian General Petroleum Corporation. In: 8th exploration conference, pp 42
Djebbas F, Ameur-Zaimeche O, Kechiched R, Heddam S, Wood DA, Movahed Z (2023) Integrating hydraulic flow unit concept and adaptive neuro-fuzzy inference system to accurately estimate permeability in heterogeneous reservoirs: Case study Sif Fatima oilfield, southern Algeria. J Afr Earth Sc 206:105027
El Naggar A (1988) Geology of Ras Gharib, Shoab Gharib and Ras Fanar oil fields. SUCO International Report 88:522
Elkatatny S, Mahmoud M, Tariq Z, Abdulraheem A (2018) New insights into the prediction of heterogeneous carbonate reservoir permeability from well logs using artificial intelligence network. Neural Comput Appl 30:2673–2683
Géron A (2022) Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow. O’Reilly Media Inc
Hearn C, Ebanks W, Tye R, Ranganathan V (1984) Geological factors influencing reservoir performance of the Hartzog Draw Field, Wyoming. J Petrol Technol 36(08):1335–1344
Hosny W, Gaafar I, Sabour A (1986) Miocene stratigraphic nomenclature in the Gulf of Suez region. In: Proceedings of the 8th Exploration Conference: Cairo, Egyptian General Petroleum Corporation, pp 131–148
Kamali MZ, Davoodi S, Ghorbani H, Wood DA, Mohamadian N, Lajmorak S, Rukavishnikov VS, Taherizade F, Band SS (2022) Permeability prediction of heterogeneous carbonate gas condensate reservoirs applying group method of data handling. Mar Pet Geol 139:105597
Khalid M, Desouky SE-D, Rashed M, Shazly T, Sediek K (2020) Application of hydraulic flow units’ approach for improving reservoir characterization and predicting permeability. J Petrol Exploration Prod Technol 10(2):467–479
Khalil S, McClay K (2001) Tectonic evolution of the NW Red Sea-Gulf of Suez rift system. Geol Soc Lond Special Publ 187(1):453–473
Kharrat R, Mahdavi R, Bagherpour MH, Hejri S (2009) Rock typeand permeability prediction of a heterogeneous carbonate reservoir using artificial neural networks based on flow zone index approach. In: SPE middle east oil and gas show and conference. OnePetro
Kozeny J (1927) Úber kapillare leitung der wasser in boden. Royal Academy of Science
LaValle SM, Branicky MS, Lindemann SR (2004) On the relationship between classical grid search and probabilistic roadmaps. Int J Robot Res 23(7–8):673–692
Lv A, Cheng L, Aghighi MA, Masoumi H, Roshan H (2021) A novel workflow based on physics-informed machine learning to determine the permeability profile of fractured coal seams using downhole geophysical logs. Mar Pet Geol 131:105171
Mahdy A, Zakaria W, Helmi A, Helaly AS, Mahmoud AM (2024) Machine learning approach for core permeability prediction from well logs in Sandstone Reservoir, Mediterranean Sea, Egypt. J Appl Geophys 220:105249
Male F, Jensen JL, Lake LW (2020) Comparison of permeability predictions on cemented sandstones with physics-based and machine learning approaches. J Nat Gas Sci Eng 77:103244
Matinkia M, Hashami R, Mehrad M, Hajsaeedi MR, Velayati A (2023) Prediction of permeability from well logs using a new hybrid machine learning algorithm. Petroleum 9(1):108–123
Moustafa A (1976) Block faulting in the Gulf of Suez. In: Proceedings of the 5th Egyptian general petroleum corporation exploration seminar, Cairo, Egypt
Moustafa A (1977) The Nullipore of Ras Gharib field. Deminex, Egypt Branch. Report EP. 24(77): 107.
Okon AN, Adewole SE, Uguma EM (2021) Artificial neural network model for reservoir petrophysical properties: porosity, permeability and water saturation prediction. Model Earth Syst Environ 7(4):2373–2390
Ouda K, Masoud M (1993) Sedimentation history and geological evolution of the Gulf of Suez during the Late Oligocene-Miocene. Geodyn Sediment Red Sea-Gulf of Aden Rift Syst 1:47–88
Raschka S, Mirjalili V (2019) Python machine learning: machine learning and deep learning with Python, scikit-learn, and TensorFlow 2. Packt Publishing Ltd
Rateb R (1988) Miocene planktonic foraminiferal analysis and its stratigraphic application in the Gulf of Suez region. In: 9th EGPC exploration production conference, pp 1–21
Souaya FJ (1965) Miocene foraminifera of the Gulf of Suez region, UAR; part 1, systematics (Astrorhizoidea-Buliminoidea). Micropaleontology 11(3):301–334
Thiébaud CE, Robson DA (1979) The geology of the area between Wadi Wardan and Wadi Gharandal, east Clysmic rift, Sinai, Egypt. J Petrol Geol 1(4):63–75
Tiab D, Donaldson EC (2015) Petrophysics: theory and practice of measuring reservoir rock and fluid transport properties. Gulf professional publishing
Wendt W, Sakurai ST, Nelson P (1986) Permeability prediction from well logs using multiple regression, reservoir characterization. Elsevier, pp 181–221
Xue G, Datta-Gupta A, Valko P, Blasingame T (1997) Optimal transformations for multiple regression: application to permeability estimation from well logs. SPE Form Eval 12(02):85–93
Zhu L-Q, Zhang C, Wei Y, Zhang C-M (2017) Permeability prediction of the tight sandstone reservoirs using hybrid intelligent algorithm and nuclear magnetic resonance logging data. Arab J Sci Eng 42(4):1643–1654
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
Mostafa Khalid: conceptualization, methodology, writing, software, programming language. Ahmed Mansour: supervision, visualization, writing—review and editing, validation. Saad El-Din Desouky: review and editing. Walaa Afify: supervision, visualization, review, and editing. Sayed Ahmed: visualization, review, and editing. Osama Elnaggar: review and editing.
Corresponding author
Ethics declarations
Conflict of interests
The authors confirm that they have no competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Khalid, M.S., Mansour, A.S., Desouky, S.ED.M. et al. Improving permeability prediction via Machine Learning in a heterogeneous carbonate reservoir: application to Middle Miocene Nullipore, Ras Fanar field, Gulf of Suez, Egypt. Environ Earth Sci 83, 244 (2024). https://doi.org/10.1007/s12665-024-11534-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-024-11534-0