
Abstract
We extend the error bounds from Chen et al. (SIAM J. Matrix Anal. Appl 43(2):787–811, 2022) for the Lanczos method for matrix function approximation to the block algorithm. Numerical experiments suggest that our bounds are fairly robust to changing block size and have the potential for use as a practical stopping criterion. Further experiments work toward a better understanding of how certain hyperparameters should be chosen in order to maximize the quality of the error bounds, even in the previously studied block size one case.









Similar content being viewed by others


Availability of supporting data
All data generated or analyzed during this study are included in this published article and published on GitHub.
Notes
For simplicity of exposition, we assume the block-Krylov subspace does not become degenerate; i.e., that the dimension of the matrix block-Krylov subspace \(\varvec{\mathcal {K}}_{k+1}(\textbf{H},\textbf{V})\) is \((k+1)b\).
In fact, a somewhat more general statement in terms of matrix-polynomials is true [18, Theorem 2.7].
References
Ando, T., Chow, E., Saad, Y., Skolnick, J.: Krylov subspace methods for computing hydrodynamic interactions in brownian dynamics simulations. J. Chem. Phys. 137, 064106 (2012)
Bai, Z., Fahey, G., Golub, G.: Some large-scale matrix computation problems. J. Comput Appl. Math. 74, 71–89 (1996)
Barkouki, H., Bentbib, A.H., Jbilou, K.: An adaptive rational block Lanczos-type algorithm for model reduction of large scale dynamical systems. J Sci Comput 67, 221–236 (2015)
Birk, S.: Deflated Shifted Block Krylov Subspace Methods for Hermitian Positive Definite Matrices, PhD thesis, Universität Wuppertal, (2018)
Carson, E., Liesen, J., Strakoš, Z.: Towards understanding cg and gmres through examples. arXiv:2211.00953 (2022)
Chen, T., Cheng, Y.-C.: Numerical computation of the equilibrium-reduced density matrix for strongly coupled open quantum systems. J. Chem. Phys. 157, 064106 (2022)
Chen, T., Greenbaum, A., Musco, C., Musco, C.: Error bounds for Lanczos-based matrix function approximation. SIAM J. Matrix Anal. Appl. 43(2), 787–811 (2022)
Chen, T., Hallman, E.: Krylov-aware stochastic trace estimation. SIAM J. Matrix Anal. Appl. 44, 1218–1244 (2023)
Dieci, L., Vleck, E.S.V.: Computation of a few lyapunov exponents for continuous and discrete dynamical systems. Appl. Numer. Math. 17, 275–291 (1995)
Druskin, V., Knizhnerman, L.: Two polynomial methods of calculating functions of symmetric matrices. USSR Comput. Math. Math. Phys. 29, 112–121 (1989)
Druskin, V., Knizhnerman, L.: Error bounds in the simple Lanczos procedure for computing functions of symmetric matrices and eigenvalues. Comput. Math. Math. Phys. 31, 20–30 (1992)
Eshghi, N., Reichel, L.: Estimating the error in matrix function approximations. Adv. Comput. Math. 47 (2021)
Estrin, R., Orban, D., Saunders, M.: Euclidean-norm error bounds for SYMMLQ and CG. SIAM J. Matrix Anal. Appl. 40, 235–253 (2019)
Fika, P., Mitrouli, M., Roupa, P.: Estimating the diagonal of matrix functions. Math. Methods Appl. Sci. 41, 1083–1088 (2016)
Frommer, A., Güttel, S., Schweitzer, M.: Convergence of restarted Krylov subspace methods for Stieltjes functions of matrices. SIAM J. Matrix Anal. Appl. 35, 1602–1624 (2014)
Frommer, A., Kahl, K., Lippert, T., Rittich, H.: 2-norm error bounds and estimates for Lanczos approximations to linear systems and rational matrix functions. SIAM J. Matrix Anal. Appl. 34, 1046–1065 (2013)
Frommer, A., Lund, K., Szyld, D.B.: Block Krylov subspace methods for functions of matrices. Electron. Trans. Numer. Anal. 47, 100–126 (2017)
Frommer, A., Lund, K., Szyld, D.B.: Block Krylov subspace methods for functions of matrices II: Modified block FOM. SIAM J. Matrix Anal. Appl. 41, 804–837 (2020)
Frommer, A., Schweitzer, M.: Error bounds and estimates for Krylov subspace approximations of Stieltjes matrix functions. BIT Numer. Math. 56, 865–892 (2015)
Frommer, A., Simoncini, V.: Stopping criteria for rational matrix functions of Hermitian and symmetric matrices. SIAM J. Sci. Comput. 30, 1387–1412 (2008)
Frommer, A., Simoncini, V.: Error bounds for Lanczos approximations of rational functions of matrices. In: Numerical Validation in Current Hardware Architectures, Berlin, Heidelberg, pp. 203–216. Springer, Berlin Heidelberg (2009)
Golub, G.H., Meurant, G.: Matrices, moments and quadrature with applications, vol. 30, Princeton University Press, (2009)
Golub, G.H., Underwood, R.: The block Lanczos method for computing eigenvalues. In: Mathematical Software, pp. 361–377, Elsevier, (1977)
Greenbaum, A.: Iterative Methods for Solving Linear Systems. Society for Industrial and Applied Mathematics, Philadelphia, PA, USA (1997)
Halko, N., Martinsson, P.G., Tropp, J.A.: Finding structure with randomness: probabilistic algorithms for constructing approximate matrix decompositions. SIAM Rev. 53, 217–288 (2011)
Ilic, M.D., Turner, I.W., Simpson, D.P.: A restarted Lanczos approximation to functions of a symmetric matrix. IMA J. Numer. Anal. 30, 1044–1061 (2009)
Li, S.C.-X., Marlin, B.M.: A scalable end-to-end Gaussian process adapter for irregularly sampled time series classification. In: Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 29, Curran Associates, Inc., (2016)
Meurant, G., Papež, J., Tichý, P.: Accurate error estimation in cg. Numer. Algorithms 88, 1337–1359 (2021)
Meurant, G., Tichý, P.: The behaviour of the Gauss–Radau upper bound of the error norm in CG. arXiv:2209.14601 (2022)
Meurant, G., Tichý, P.: Approximating the extreme Ritz values and upper bounds for the \({A}\)-norm of the error in CG. Numer. Algorithms 82, 937–968 (2018)
Meyer, R.A., Musco, C., Musco, C., Woodruff, D.P.: Hutch++: optimal stochastic trace estimation. In: Symposium on Simplicity in Algorithms (SOSA), SIAM, pp. 142–155 (2021)
Musco, C., Musco, C., Sidford, A.: Stability of the Lanczos method for matrix function approximation. In: Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA ’18, USA, 2018, Society for Industrial and Applied Mathematics, pp. 1605–1624
O’Leary, D.P.: The block conjugate gradient algorithm and related methods. Linear Algebra Appl. 29, 293–322 (1980)
Paige, C.C.: The computation of eigenvalues and eigenvectors of very large sparse matrices., PhD thesis, University of London, (1971)
Paige, C.C.: Error analysis of the Lanczos algorithm for tridiagonalizing a symmetric matrix. IMA J. Appl. Math. 18, 341–349 (1976)
Paige, C.C.: Accuracy and effectiveness of the Lanczos algorithm for the symmetric eigenproblem. Linear Algebra Appl. 34, 235–258 (1980)
Saad, Y.: Analysis of some Krylov subspace approximations to the matrix exponential operator. SIAM J. Numer. Anal. 29, 209–228 (1992)
Schaerer, C.E., Szyld, D.B., Torres, P.J.: A posteriori superlinear convergence bounds for block conjugate gradient, (2021)
Schnack, J., Richter, J., Steinigeweg, R.: Accuracy of the finite-temperature Lanczos method compared to simple typicality-based estimates. Phys. Rev. Res. 2 (2020)
Seki, K., Yunoki, S.: Thermodynamic properties of an \(s=\frac{1}{2}\) ring-exchange model on the triangular lattice. Phys. Rev. B 101 (2020)
Simunec, I.: Error bounds for the approximation of matrix functions with rational Krylov methods. arXiv:2311.02701 (2023)
Strakos, Z.: On the real convergence rate of the conjugate gradient method. Linear Algebra Appl. 154–156, 535–549 (1991)
Strakos, Z., Greenbaum, A.: Open questions in the convergence analysis of the Lanczos process for the real symmetric eigenvalue problem, University of Minnesota, (1992)
Strakoš, Z., Tichỳ, P.: On error estimation in the conjugate gradient method and why it works in finite precision computations. ETNA. Electronic Transactions on Numerical Analysis [electronic only], 13, pp. 56–80 (2002)
Underwood, R.R.: An Iterative Block Lanczos Method for the Solution of Large Sparse Symmetric Eigenproblems., PhD thesis, Stanford, CA, USA, (1975). AAI7525622
van den Eshof, J., Frommer, A., Lippert, T., Schilling, K., van der Vorst, H.: Numerical methods for the QCDd overlap operator. I Sign-function and error bounds. Comput. Phys. Commun. 146, 203–224 (2002)
Author information
Authors and Affiliations
Contributions
Analysis and numerical experiments were primarily done by Q. X. Both authors contributed to writing and reviewing the manuscript.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1. Estimates for the block-CG error norm
In this section, we discuss how to obtain an error estimate for the \((\textbf{H}-w\textbf{I})\)-norm of the error of the block-Lanczos algorithm used to approximate \((\textbf{H}-w\textbf{I})^{-1}\textbf{V}\); i.e. with \(f(x)=(x-w)^{-1}\). For simplicity, without loss of generality, we will assume \(w=0\). Closely related approaches are widely studied for the block size one case [13, 28,29,30, 44]. Bounds for the block algorithm have also been studied [38].

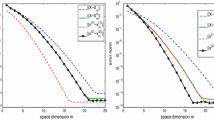
Illustration of the quality of Fig. 9 for varying d. The block-Lanczos-FA error is measured using \(\Vert \cdot \Vert _{\textbf{H}-w\textbf{I}}\) with \(w = 0\)
By a simple triangle inequality, we obtain a bound
If we assume that d is chosen sufficiently large so that
then we obtain an approximate error bound (error estimate)
It is natural to ask why we don’t simply apply this approach to the block-Lanczos-FA algorithm for any function f. Such an approach was suggested for the Lanczos-FA algorithm in [12], and in many cases can work well. However, if the convergence of the block-Lanczos-FA algorithm is not monotonic, then the critical assumption that \(\textsf {lan} _{k+d}(f)\) is a much better approximation to \(f(\textbf{H})\textbf{V}\) than \(\textsf {lan} _k(f)\) may not hold. Perhaps more importantly, the decomposition in Theorem 2.1 also allows intuition about how the distribution of eigenvalues of \(\textbf{H}\) impact the convergence of block-CG to be extended to the block-Lanczos-FA algorithm.
In Fig. 9 we show a numerical experiment illustrating the quality of (18) for several values of d. As expected, increasing d improves the quality of the estimate. However, even for small d, Fig. 9 appears suitable for use as a practical stopping criterion on this problem. Of course, on problems where the convergence of block-CG stagnates, such an error estimate will require d fairly large. Further study of this topic is outside the scope of the present paper.
Appendix 2. Proofs of known results
Proof of (3)
Owing to linearity, in order to show \(p(\textbf{H})\textbf{V} = \textsf {lan} _k(p)\) for any polynomial p with \(\deg (p)<k\), it suffices to consider the case \(p(x) = x^j\), for \(j=0, \ldots , k-1\). Left multiplying (2) by \(\textbf{H}^{j-1}\) and then repeatedly applying (2) we find
Thus, using that \(\textbf{V} = \textbf{Q}_k \textbf{E}_1\textbf{B}_0\),
Since \(\textbf{T}_k\) is banded with half bandwidths b, \(\textbf{T}_k^{i-1}\) is banded with half bandwidth \((i-1)b\). Thus, the bottom left \(b\times b\) block of \(\textbf{T}_k^{i-1}\) is all zero provided \(i-1 \le k-2\); i.e., \(\textbf{E}_k^* \textbf{T}_k^{i-1}\textbf{E}_1\textbf{B}_0 = \textbf{0}\) provided \(i<k\). We therefore find that for all \(j<k\),
from which we infer \(p(\textbf{H})\textbf{V} = \textsf {lan} _k(p)\) for any p with \(\deg (p)<k\). This is a well-known result; [10, 17, 18, 37].
Therefore, using the triangle inequality, for any polynomial p with \(\deg (p)<k\),
In the final inequality we have use that \(\Vert \textbf{Q}_k\Vert \le 1\) since \(\textbf{Q}_k\) has orthonormal columns and that \(\Vert \textbf{E}_1 \textbf{B}_0\Vert = \Vert \textbf{Q}_k^*\textbf{V}\Vert \le \Vert \textbf{V}\Vert \). Next, note that
so, since each of \(\Lambda (\textbf{H})\) and \(\Lambda (\textbf{T}_k)\) are contained in \([\lambda _{min }(\textbf{H}),\lambda _{max }(\textbf{H})]\), we find
Since p was arbitrary, we can optimize over all polynomials p with \(\deg (p)<k\).\(\square \)
Proof of Lemma 2.2
From Definition 1.2,
Using the fact that the Lanczos factorization (2) can be shifted,
Thus, by substitution, we have
Since \(\textbf{E}_1 = \left[ \textbf{I}_{b}, \textbf{0},..., \textbf{0 }\right] ^*\), where \(\textbf{I}_{b}\) is the \(b\times b\) identity matrix, we know that \(\textbf{Q}\textbf{E}_1\textbf{B}_0 = \textbf{Q}_1\textbf{B}_0 = \textbf{V}\). Therefore,
The result follows from the definition of \(\textbf{C}_k(z)\). \(\square \)
Proof of Corollary 2.1
We have shown in Lemma 2.2 that \(\textsf {res} _k(z) = \overline{\textbf{Q}}_{k+1}\textbf{B}_k \textbf{C}_k(z)\). Thus,
Next, notice that
The result is established.\(\square \)
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Xu, Q., Chen, T. A posteriori error bounds for the block-Lanczos method for matrix function approximation. Numer Algor (2024). https://doi.org/10.1007/s11075-024-01819-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11075-024-01819-7