
Abstract
Many existing Visual Question Answering (VQA) methods use traditional attention mechanisms to focus on each region of the input image and each word of the input question and achieve well performance. However, the most obvious limitation of traditional attention mechanisms is that the module always generates a weighted average based on a specific query. When all regions and words are unsatisfied with the query, the generated vectors, which are noisy information, may lead to incorrect predictions. In this paper, we propose an Improved Modular Co-attention Network (IMCN) by incorporating the Attention on Attention (AoA) module into the self-attention module and the co-attention module to solve this problem. AoA adds another attention process by using element-wise multiplication on the information vector and the attention gate, which are both generated from the attention result and the current context. With AoA, the attended information obtained by the model is more useful. We also introduce an Improved Multimodal Fusion Network (IMFN), which leverages various branches to achieve hierarchical fusion, to fuse visual features and textual features for further improvements. We conduct extensive experiments on the VQA-v2 dataset to verify the effectiveness of the proposed modules and experimental results demonstrate our model outperforms the existing methods.












Similar content being viewed by others

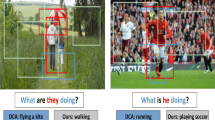
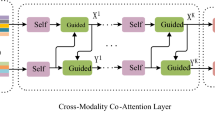
Data Availability
Data will be available upon request.
Code Availability
The code for reproducing the results provided in the manuscript will be made public upon acceptance.
References
Rahman T, Chou S-H, Sigal L, Carenini G (2021) An improved attention for visual question answering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1653–1662
Zhang H, Li R, Liu L (2022) Multi-head attention fusion network for visual question answering. 2022 IEEE International Conference on Multimedia and Expo (ICME), pp 1–6
Shen X, Han D, Guo Z, Chen C, Hua J, Luo G (2022) Local self-attention in transformer for visual question answering. Appl Intell 1–18
Khurana D, Koli A, Khatter K, Singh S (2023) Natural language processing: State of the art, current trends and challenges. Multimed Tools Appl 82(3):3713–3744
Antol S, Agrawal A, Lu J, Mitchell M, Batra D, Zitnick CL, Parikh D (2015) Vqa: Visual question answering. In: Proceedings of the IEEE international conference on computer vision, pp 2425–2433
Shih KJ, Singh S, Hoiem D (2016) Where to look: Focus regions for visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4613–4621
Lu J, Yang J, Batra D, Parikh D (2016) Hierarchical question-image co-attention for visual question answering. Adv Neural Inf Process Syst 29
Yu Z, Yu J, Xiang C, Fan J, Tao D (2018) Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering. IEEE Trans Neural Netw Learn Syst 29(12):5947–5959
Kim J-H, Jun J, Zhang B-T (2018) Bilinear attention networks. Adv Neural Inf Process Syst 31
Nguyen D-K, Okatani T (2018) Improved fusion of visual and language representations by dense symmetric co-attention for visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6087–6096
Yu Z, Yu J, Cui Y, Tao D, Tian Q (2019) Deep modular co-attention networks for visual question answering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 6281–6290
Huang L, Wang W, Chen J, Wei X-Y (2019) Attention on attention for image captioning. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 4634–4643
Lee K-H, Chen X, Hua G, Hu H, He X (2018) Stacked cross attention for image-text matching. In: Proceedings of the European conference on computer vision (ECCV), pp 201–216
Teney D, Anderson P, He X, Van Den Hengel A (2018) Tips and tricks for visual question answering: Learnings from the 2017 challenge. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4223–4232
Nam H, Ha J-W, Kim J (2017) Dual attention networks for multimodal reasoning and matching. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 299–307
Fan H, Zhou J (2018) Stacked latent attention for multimodal reasoning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1072–1080
Gurunlu B, Ozturk S (2022) Efficient approach for block-based copy-move forgery detection. In: Smart trends in computing and communications: proceedings of SmartCom 2021, pp 167–174. Springer
Le TM, Le V, Gupta S, Venkatesh S, Tran T (2023) Guiding visual question answering with attention priors. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 4381–4390
Marino K, Rastegari M, Farhadi A, Mottaghi R (2019) Ok-vqa: A visual question answering benchmark requiring external knowledge. In: Proceedings of the IEEE/cvf conference on computer vision and pattern recognition, pp 3195–3204
Schwenk D, Khandelwal A, Clark C, Marino K, Mottaghi R (2022) A-okvqa: A benchmark for visual question answering using world knowledge. In: European conference on computer vision, pp 146–162. Springer
Chang Y, Narang M, Suzuki H, Cao G, Gao J, Bisk Y (2022) Webqa: Multihop and multimodal qa. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 16495–16504
Ravi S, Chinchure A, Sigal L, Liao R, Shwartz V (2023) Vlc-bert: Visual question answering with contextualized commonsense knowledge. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 1155–1165
Garcia-Olano D, Onoe Y, Ghosh J (2022) Improving and diagnosing knowledge-based visual question answering via entity enhanced knowledge injection. Companion Proceedings of the Web Conference 2022:705–715
Ding Y, Yu J, Liu B, Hu Y, Cui M, Wu Q (2022) Mukea: Multimodal knowledge extraction and accumulation for knowledge-based visual question answering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 5089–5098
Gao F, Ping Q, Thattai G, Reganti A, Wu YN, Natarajan P (2022) Transform-retrieve-generate: Natural language-centric outside-knowledge visual question answering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 5067–5077
Yang Z, Gan Z, Wang J, Hu X, Lu Y, Liu Z, Wang L (2022) An empirical study of gpt-3 for few-shot knowledge-based vqa. Proceedings of the AAAI conference on artificial intelligence 36:3081–3089
Tiong AMH, Li J, Li B, Savarese S, Hoi SC (2022) Plug-and-play vqa: Zero-shot vqa by conjoining large pretrained models with zero training. Findings of the Association for Computational Linguistics: EMNLP 2022:951–967
Guo J, Li J, Li D, Tiong AMH, Li B, Tao D, Hoi S (2023) From images to textual prompts: Zero-shot visual question answering with frozen large language models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10867–10877
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. Adv Neural Inf Process Syst 30
Yang Z, He X, Gao J, Deng L, Smola A (2016) Stacked attention networks for image question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 21–29
Kim J-H, Lee S-W, Kwak D, Heo M-O, Kim J, Ha J-W, Zhang B-T (2016) Multimodal residual learning for visual qa. Adv Neural Inf Process Syst 29
Zhu C, Zhao Y, Huang S, Tu K, Ma Y (2017) Structured attentions for visual question answering. In: Proceedings of the IEEE international conference on computer vision, pp 1291–1300
Yu D, Fu J, Mei T, Rui Y (2017) Multi-level attention networks for visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4709–4717
Zhou L, Palangi H, Zhang L, Hu H, Corso J, Gao J (2020) Unified vision-language pre-training for image captioning and vqa. Proceedings of the AAAI conference on artificial intelligence 34:13041–13049
Zhou Y, Ren T, Zhu C, Sun X, Liu J, Ding X, Xu M, Ji R (2021) Trar: Routing the attention spans in transformer for visual question answering. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 2074–2084
Guo Z, Han D (2023) Sparse co-attention visual question answering networks based on thresholds. Appl Intell 53(1):586–600
Cheng B, Misra I, Schwing AG, Kirillov A, Girdhar R (2022) Masked-attention mask transformer for universal image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1290–1299
Liu S-A, Xie H, Xu H, Zhang Y, Tian Q (2022) Partial class activation attention for semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 16836–16845
Liang J, Fan Y, Xiang X, Ranjan R, Ilg E, Green S, Cao J, Zhang K, Timofte R, Gool LV (2022) Recurrent video restoration transformer with guided deformable attention. Adv Neural Inf Process Syst 35:378–393
Song CH, Han HJ, Avrithis Y (2022) All the attention you need: Global-local, spatial-channel attention for image retrieval. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 2754–2763
Xia Z, Pan X, Song S, Li LE, Huang G (2022) Vision transformer with deformable attention. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 4794–4803
Zhang C, Wan H, Shen X, Wu Z (2022) Patchformer: An efficient point transformer with patch attention. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 11799–11808
Park G, Han C, Yoon W, Kim D (2020) Mhsan: multi-head self-attention network for visual semantic embedding. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 1518–1526
Goyal Y, Khot T, Summers-Stay D, Batra D, Parikh D (2017) Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6904–6913
Hudson DA, Manning CD (2019) Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 6700–6709
Fukui A, Park DH, Yang D, Rohrbach A, Darrell T, Rohrbach M (2016) Multimodal compact bilinear pooling for visual question answering and visual grounding. In: Proceedings of the 2016 conference on empirical methods in natural language processing. Assoc Comput Linguist
Ma C, Shen C, Dick A, Wu Q, Wang P, van den Hengel A, Reid I (2018) Visual question answering with memory-augmented networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6975–6984
Qiao T, Dong J, Xu D (2018) Exploring human-like attention supervision in visual question answering. In: Proceedings of the AAAI conference on artificial intelligence, vol 32
Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L (2018) Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6077–6086
Lu P, Li H, Zhang W, Wang J, Wang X (2018) Co-attending free-form regions and detections with multi-modal multiplicative feature embedding for visual question answering. In: Proceedings of the AAAI conference on artificial intelligence, vol 32
Zhang Y, Hare J, Prügel-Bennett A (2018) Learning to count objects in natural images for visual question answering. In: International conference on learning representations
Hudson DA, Manning CD (2018) Compositional attention networks for machine reasoning. In: International conference on learning representations
Wu C, Liu J, Wang X, Dong X (2018) Chain of reasoning for visual question answering. Adv Neural Inf Process Syst 31
Acknowledgements
We thank the anonymous reviewers for their valuable comments. This work was supported by the Program of Natural Science Foundation of Shanghai (No. 23ZR1422800).
Author information
Authors and Affiliations
Contributions
Cheng Liu: Writing - Original Draft, Writing - Editing, Software, Data curation. Chao Wang: Writing - Editing, Investigation. Yan Peng: Writing - Review, Editing.
Corresponding author
Ethics declarations
Competing interests
The authors have no relevant financial or nonfinancial interests to disclose other than the aforementioned funding.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, C., Wang, C. & Peng, Y. IMCN: Improved modular co-attention networks for visual question answering. Appl Intell 54, 5167–5182 (2024). https://doi.org/10.1007/s10489-024-05456-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-024-05456-4