
Evaluating the Gilbert–Varshamov Bound for Constrained Systems †



School of Physical and Mathematical Sciences, Nanyang Technological University, Singapore 637121, Singapore
*
Author to whom correspondence should be addressed.
†
The paper was presented in part at the 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 Jun–1 July 2022.
Entropy 2024, 26(4), 346; https://doi.org/10.3390/e26040346
Submission received: 28 February 2024
/
Revised: 11 April 2024
/
Accepted: 17 April 2024
/
Published: 19 April 2024
(This article belongs to the Special Issue Discrete Math in Coding Theory)
Abstract
:We revisit the well-known Gilbert–Varshamov (GV) bound for constrained systems. In 1991, Kolesnik and Krachkovsky showed that the GV bound can be determined via the solution of an optimization problem. Later, in 1992, Marcus and Roth modified the optimization problem and improved the GV bound in many instances. In this work, we provide explicit numerical procedures to solve these two optimization problems and, hence, compute the bounds. We then show that the procedures can be further simplified when we plot the respective curves. In the case where the graph presentation comprises a single state, we provide explicit formulas for both bounds.
1. Introduction
From early applications in magnetic recording systems to recent applications in DNA-based data storage [1,2,3,4] and energy-harvesting [5,6,7,8,9,10], constrained codes have played a central role in enhancing reliability in many data storage and communications systems (see also [11] for an overview). Specifically, for most data storage systems, certain substrings are more prone to errors than others. Thus, by forbidding the appearance of such strings, that is, by imposing constraints on the codewords, the user is able to reduce the likelihood of error. We refer to the collection of words that satisfy the constraints as the constrained space .
To further reduce the error probability, one can impose certain distance constraints on the codebook. In this work, we focus on the Hamming metric and consider the maximum size of a codebook whose words belong to the constrained space and whose pairwise distance is at least of a certain value d. Specifically, we study one of the most well-known and fundamental lower bounds of this quantity—the Gilbert–Varshamov (GV) bound.
To determine the GV bound, one requires two quantities: the size of the constrained space, , and, also, the ball volume, that is, the number of words with a distance of at most from a “center” word. In the case where the space is unconstrained, i.e., , the ball volume does not depend on the center. Then, the GV bound is simply , where V is the ball volume of a center. However, for most constrained systems, the ball volume varies with the center. Nevertheless, Kolesnik and Krachkovsky showed that the GV lower bound can be generalized to , where is the average ball volume [12]. This was further improved by Gu and Fuja to in [13] (see pp. 242–243 in [11] for additional details). In the same paper [12], they showed the asymptotic rate of average ball volume can be computed via an optimization problem. Later, Marcus and Roth modified the optimization problem by including an additional constraint and variable [14], and the resulting bound, which we refer to as GV-MR bound, improves the usual GV bound. Furthermore, in most cases, the improvement is strictly positive.
However, about three decades later, very few works have evaluated these bounds for specific constrained systems. To the best of our knowledge, in all works that numerically computed the GV bound and/or GV-MR bound, the constrained systems of interest have, at most, eight states [15]. In [15], the authors wrote that “evaluation of the bound required considerable computation”, referring to the GV-MR bound.
In this paper, we revisit the optimization problems defined by Kolesnik and Krachkovsky [12] and Marcus and Roth [14] and develop a suite of explicit numerical procedures that solve these problems. In particular, to demonstrate the feasibility of our methods, we evaluated and plotted the GV and GV-MR bounds for a constrained system involving 120 states in Figure 1b.
We provide a high-level description of our approach. For both optimization problems, we first characterized the optimal solutions as roots of certain equations. Then, using the celebrated Newton–Raphson iterative procedure, we proceeded to find the roots of these equations. However, as the latter equations involved the largest eigenvalues of certain matrices, each Newton–Raphson iteration required the (partial) derivatives of these eigenvalues (in some variables). To resolve this, we made modifications to another celebrated iterative procedure—the power iteration method—and the resulting procedures computed the GV and GV-MR bounds efficiently for a specific relative distance . Interestingly, if we plot the bounds for , the numerical procedure can be further simplified. Specifically, by exploiting certain properties of the optimal solutions, we provided procedures that use less Newton–Raphson iterations.
Parts of this paper were presented in the IEEE International Symposium on Information Theory (ISIT 2022) [16]. In the next section, we provide the formal definitions and state the optimization problems that compute the GV bound.
2. Preliminaries
Let be the binary alphabet and let denote the set of all words of length n over . A labeled graph is a finite directed graph with states , edges, and an edge labeling for some . Here, we use to mean that there is an edge from to with label . The labeled graph is deterministic if, for each state, the outgoing edges have distinct labels.
A constrained system is, then, the set of all words obtained by reading the labels of paths in a labeled graph . We say that is a graph presentation of . We further denote the set of all n-length words by . Alternatively, is the set of all words obtained by reading the labels of -length paths in . Then, the capacity of , denoted by , is given by . It is well-known that corresponds to the largest eigenvalue of the adjacency matrix (see, for example, [11]). Here, is a -matrix whose rows and columns are indexed by . For each entry , we set the corresponding entry to be one if is an edge, and zero otherwise.
Every constrained system can be presented by a deterministic graph . Furthermore, any deterministic graph can be transformed into a primitive deterministic graph such that the capacity of is same as the capacity of the constrained system presented by some irreducible component (maximal irreducible subgraph) of (see, for example, Marcus et al. [11]). It should be noted that a graph is primitive if there exists a positive integer ℓ such that is strictly positive. Therefore, we henceforth assume that our graphs are deterministic and primitive. When , we call this a single-state graph presentation and study these graphs in Section 5.
For , is the Hamming distance between x and y. We fix , and a fundamental problem in coding theory is finding the largest subset of such that for all distinct . Let denote the size of largest subset .
In terms of asymptotic rates, we fix , and our task is to find the highest attainable rate, denoted by , which is given by .
2.1. Review of Gilbert–Varshamov Bound
To define the GV bound, we need to determine the total ball size. Specifically, for and , we define . We further define . Then, the GV bound, as given by Gu and Fuja [13,17], states that there exists an code of size at least .
In terms of asymptotic rates, there exists a family of codes such that their rates approach
where .
In this paper, our main task is to determine efficiently. We observe that since , it suffices to find efficient ways of determining . It turns out that can be found via the solution of a convex optimization problem. Specifically, given a labeled graph , we define its product graph as follows:
- .
- For , and , we draw an edge if and only if both and belong to .
- Then, we label the edges in with the function , where .
A stationary Markov chain P on a graph is a probability distribution function such that and, for any state , the sum of the probabilities of the outgoing edges equals the sum of the probabilities of the incoming edges. We denote by the set of all stationary Markov chains on . For a state , let denote the set of outgoing edges from u in . The state vector of a stationary Markov chain P on is defined by . The entropy rate of a stationary Markov chain is defined by
To this end, we consider the dual problem of (2). Specifically, we define a -distance matrix whose rows and columns are indexed by . For each entry indexed by , we set the entry to be zero if and we set it to be if . Then, the dual problem can be stated in terms of the dominant eigenvalue of the matrix .
By applying the reduction techniques from [14], we can reduce the problem size by a factor of two. Formally, in the case of , we define a -reduced distance matrix whose rows and columns are indexed by using the following procedure.
Two states and in are said to be equivalent if and . The matrix is then obtained by merging all pairs of equivalent states and . That is, we add the column indexed by to the column indexed by and then remove the row and column which are indexed by . It should be noted that it may be possible to reduce the size of this matrix further. However, for the ease of exposition, we did not consider this case in this work.
Following this procedure, we observe that the entries in the matrix can be described by the rules in Table 1. Moreover, the dominant eigenvalue of is the same as that of . Then, by strong duality, computing (2) is equivalent to solving the following dual problem [18,19] (see also, [20]):
Here, we use to denote the dominant eigenvalue of matrix M. To simplify further, we write .
Since the objective function in (3) is convex, it follows from standard calculus that any local minimum solution in the interval is also a global minimum solution. Furthermore, is a zero of the first derivative of the objective function. If we consider the numerator of this derivative, then is a root of the function
In Corollary 1, we showed that there is only one such that and is strictly positive for all values of y. Therefore, to evaluate the GV bound for a fixed , it suffices to determine .
Later, Marcus and Roth [14] improved the GV bound (1) by considering certain subsets of the constrained space . This entails the inclusion of an additional constraint defined in the optimization problem (2), and, correspondingly, an additional variable in the dual problem (3). Specifically, they considered certain subsets where each symbol in the words of appears with a certain frequency dependent on the parameter p. We describe this in more detail in Section 4.
2.2. Our Contributions
- (A)
- In Section 3, we develop the numerical procedures to compute for a fixed and, hence, determine the GV bound (1). Our procedure modifies the well-known power iteration method to compute the derivatives of . After that, using these derivatives, we apply the classical Newton–Raphson method to determine the root of (4). In the same section, we also study procedures to plot the GV curve, that is, the set . Here, we demonstrate that the GV curve can be plotted without any Newton–Raphson iterations.
- (B)
- In Section 4, we then develop similar power iteration methods and numerical procedures to compute the GV-MR bound. Similar to the GV curve, we also provide a plotting procedure that uses significantly less Newton–Raphson iterations.
- (C)
- In Section 5, we provide explicit formulas for the computation of the GV bound and GV-MR bound for graph presentations that have exactly one state but multiple parallel edges.
- (D)
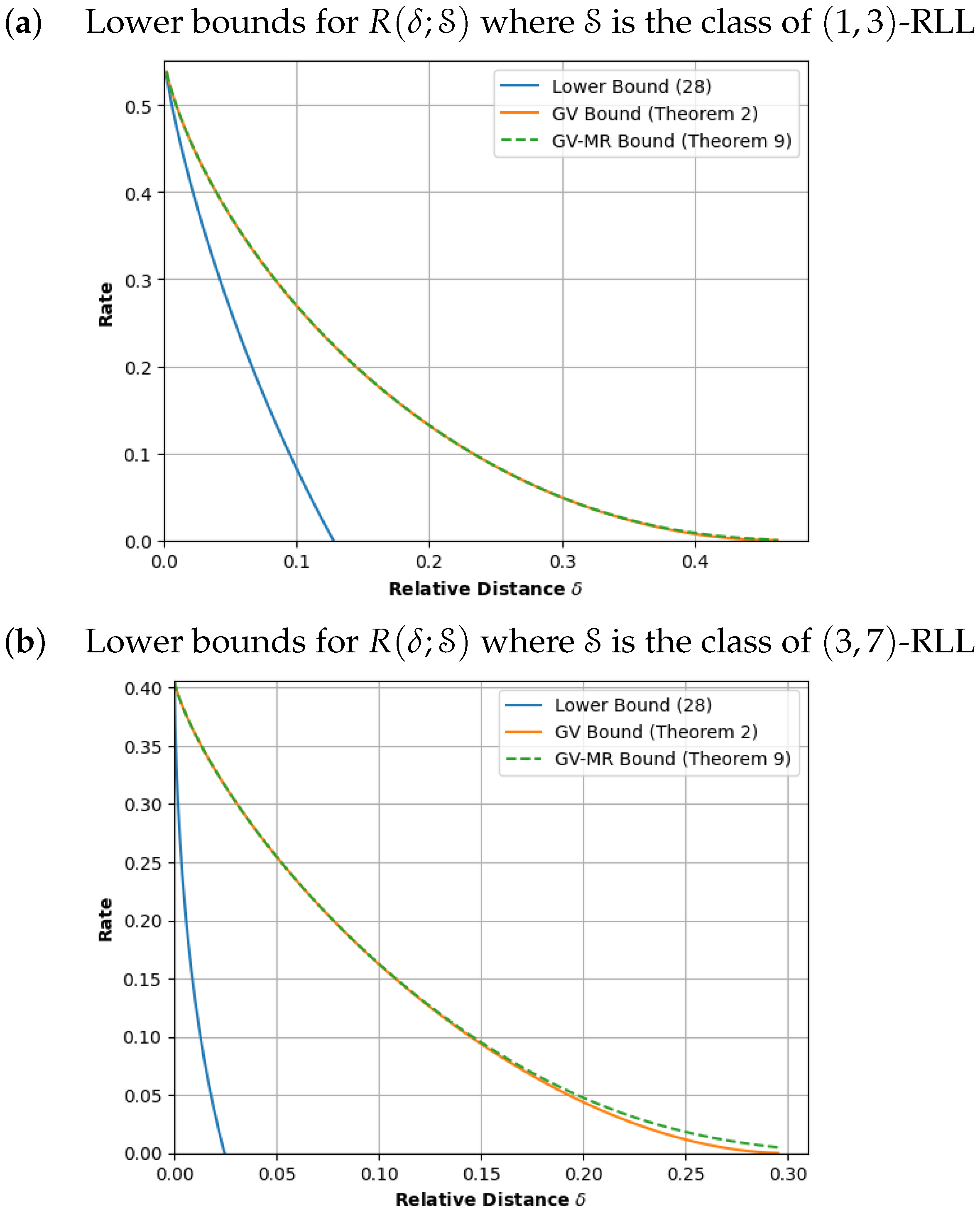
- In Section 6, we validate our methods by computing the GV and the GV-MR bounds for some specific constrained systems. For comparison purposes, we also plot a simple lower bound that is obtained by using an upper estimate of the ball size. From the plots in Figure 1, Figure 2 and Figure 3, it is also clear that the GV and GV-MR bounds are significantly better. We also observe that the GV bound and GV-MR bound for subblock energy-constrained codes (SECCs) obtained through our procedures improve the GV-type bound given by Tandon et al. (Proposition 12 in [21]).
3. Evaluating the Gilbert–Varshamov Bound
In this section, we first describe a numerical procedure that solves (3) and, hence, determine for fixed values of . Then, we show that the procedure can be simplified when we compute the GV curve, that is, the set of points . Here, we eschew notation and use to denote the interval , if , and the interval otherwise.
Below, we provide formal description of our procedure to obtain the GV bound for a fixed relative distance .
Procedure 1 (GV bound for fixed relative distance).
Input: Adjacency matrix , reduced distance matrix , and relative minimum distance
Output: GV bound, that is, as defined in (1)
- (1)
- Apply the Newton–Raphson method to obtain such that is approximately zero.
- Fix the tolerance value .
- Set and pick an initial guess .
- While ,
- –
- Compute the next guess as follows:
- –
- In this step, apply the power iteration method to compute , , and .
- –
- Increment t by one.
- Set .
- (2)
- Determine using . Specifically, compute , , and .
Throughout Section 3 and Section 4, we illustrate our numerical procedures via a running example using the class of sliding window-constrained codes (SWCCs). Formally, we fix a window length L and window weightw, and say that a binary word satisfies the -sliding window weight constraint if the number of ones in every consecutive L bits is at least w. We refer to the collection of words that meet this constraint as an -SWCC constrained system. The class of SWCCs was introduced by Tandon et al. for the application of simultaneous energy and information transfer [7,10]. Later, Immink and Cai [8,9] studied encoders for this constrained system and provided a simple graph presentation that uses only states.
In the next example, we illustrate how the numerical procedure can be used to compute the GV bound for the value when .
Example 1. ![Entropy 26 00346 i028]()
Let and , and we consider a -SWCC constrained system. From [8], we have the following graph presentation with states x11, 101, and 110

Then, the corresponding adjacency and reduced distance matrices are as follows:
To determine the GV bound at , we first approximate the optimal point for which is minimized.
We apply the Newton–Raphson method to find a zero of the function . Now, with the initial guess , we apply the power iteration method to determine
Then, we compute that . Repeating the computations, we have that . Since is less than the tolerance value , we set . Hence, we have that . Applying the power iteration method to either or , we compute the capacity of the -SWCC constrained system to be . Then, the GV bound is given by .
We discuss the convergence issues arising from Procedure 1. We observe that there are two different iterative processes in Step 1, namely, (a) the power iteration method to compute the values , , and , and (b) the Newton–Raphson method that determines the zero of .
- (a)
- We recall that is the largest eigenvalue of the reduced distance matrix . If we apply naive methods to compute this dominant eigenvalue, the computational complexity increases very rapidly with the matrix size. Specifically, if has M states, then the reduced distance matrix has dimensions and finding its characteristic equation takes time. Even then, determining the exact roots of characteristic equations with at least five degrees is generally impossible. Therefore, we turn to the numerical procedures like the ubiquitous power iteration method [22]. However, the standard power iteration method is only able to compute the dominant eigenvalue . Nevertheless, we can modify the power iteration method to compute and its higher order derivatives. In Appendix A, we demonstrate that under certain mild assumptions, the modified power iteration method always converges. Moreover, using the sparsity of the reduced distance matrix, we have that each iteration can be completed in time.
- (b)
- Next, we discuss whether we can guarantee that converges to as t approaches infinity. Even though the Newton–Raphson method converges in all our numerical experiments, we are unable to demonstrate that it always converges for . Nevertheless, we can circumvent this issue if we are interested in plotting the GV curve. Specifically, if our objective is to determine the curve , it turns out that we do not need to implement the Newton–Raphson iterations and we discuss this next.
We fix some constrained system . Let us define its corresponding GV curve to be the set of points . Here, we demonstrate that the GV curve can be plotted without any Newton–Raphson iterations.
To this end, we observe that when , we have that . Hence, we eschew notation and define the function
We further define . In this section, we prove the following theorem.
Theorem 1.
Let be the graph presentation for the constrained system . If we define the function
then the corresponding GV curve is given by
Before we prove Theorem 1, we discuss its implications. It should be noted that to compute and , it suffices to determine and using the modified power iteration methods described in Appendix A. In other words, no Newton–Raphson iterations are required. We also have additional computational savings, as we do not need to apply the power iteration method to compute the second derivative .
Example 2.
We continue our example and plot the GV curve for the -SWCC constrained system in Figure 1a. Before plotting, we observe that when , we have , as expected. When , we have . Indeed, both and are equal to zero and we have that for .
Next, we compute a set of 100 points on the GV curve. If we apply Procedure 1 to compute for 100 values of δ in the interval , we require 275 Newton–Raphson iterations and 6900 power iterations to find these points. In contrast, applying Theorem 1, we compute for 100 values of y in the interval . This does not require any Newton–Raphson iterations and involves only 2530 power iterations.
To prove Theorem 1, we demonstrate the following lemmas. Our first lemma is immediate from the definitions of , , and in (1), (5), and (6), respectively.
Lemma 1.
for all .
The next lemma studies the behaviour of both and as functions in y.
Lemma 2.
In terms of y, the functions and are monotone increasing and decreasing, respectively. Furthermore, we have that , and for .
Proof.
To simplify notation, we write , , and as , , and , respectively.
First, we show that is positive for . Differentiating the expression in (5), we have that is equivalent to
We recall that (3) is a convex minimization problem. Hence, the second order derivative of the objective function is always positive. In other words,
Substituting with and multiplying by , we obtain (8), as desired.
Next, we show that is monotone decreasing. We recall that . Since yields the asymptotic rate of the total ball size, we have that as y increases, increases and so, increases. Therefore, decreases, as desired.
Next, we show that . When , we have from (6) that . Now, we recall that shares the same dominant eigenvalue as the matrix [12]. Furthermore, it can be verified that when , is tensor product of and . That is, . It then follows from standard linear algebra that . Thus, and . In this instance, we also have that .
Finally, for , we have that and thus, , as required. □
Theorem 1 is then immediate from Lemmas 1 and 2.
We have the following corollary that immediately follows from Lemma 2. This corollary then implies that yields the global minimum for the optimization problem.
Corollary 1.
When , has a unique zero in . Furthermore, is strictly positive for all .
4. Evaluating Marcus and Roth’s Improvement of the Gilbert–Varshamov Bound
In [14], Marcus and Roth improved the GV lower bound for most constrained systems by considering subsets of where p is some parameter. Here, we focus on the case and set p to be the normalized frequency of edges whose labels correspond to one. Specifically, we set .
Next, let be the set of all words/paths of length n in and we define .
Similar to before, we define . Since is a subset of , it follows from the usual GV argument that there exists a family of codes whose rates approach for all . Therefore, we have the following lower bound on asymptotic achievable code rates:
Now, a key result from [14] is that both and can be obtained via two different convex optimization problems. For succinctness, we state the dual formulations of these optimization problems.
First, can be obtained from the following problem:
Here, is the following matrix whose rows and columns are indexed by . For each entry indexed by e, we set to be zero if , and if .
As before, we simplify notation by writing . Again, following the convexity of (10), we are interested in finding the zero of the following function:
Next, can be obtained via the following optimization:
Here, is a -reduced distance matrix indexed by . To define the entry of matrix indexed by , we look at the vertices , , , and and follow the rules given in Table 2.
Again, we write . Furthermore, following the convexity of (12), we have that if the optimal solution is obtained at x and y, then
To this end, we consider the function for and set . As with the previous section, we develop a numerical procedure to solve the optimization problem (9). To this end, we have the following critical observation.
Theorem 2.
For a given , consider the optimization problem
If is an optimal solution, then . Furthermore, if , then and .
Proof.
Let and be real-valued variables and we define . Using the Lagrangian multiplier theorem, we have that for any optimal solution. Solving these equations with the constraints , we have that and for any optimal solution.
Now, when , using , let us define . Then, proceeding as with the proof of Lemma 2, we see that is monotone increasing with . Therefore, is zero.
Similarly, given and , we use to define . Again, we can proceed as with the proof of Lemma 2 to show that is monotone increasing. Furthermore, since , we have that . □
Therefore, to determine for any fixed , it suffices to find x, y, z, and p such that and .
Now, the optimization in Theorem 2 does not constrain the values of p. Furthermore, for certain constrained systems, there are instances where p falls outside the interval . In this case, instead of solving the optimization problem (9), we set p to be either zero or one, and we solve the corresponding optimization problems (10) and (12). Specifically, if we have , then we set and , or if , then we set and . Hence, the resulting rates that we obtain are a lower bound for the GV-MR bound.
Procedure 2 ( for fixed ).
Input: Matrices ,
Output: or , where .
- (1)
- Apply the Newton–Raphson method to obtain and such that , , and are approximately zero. Specifically, do the following:
- Fix a tolerance value
- Set and pick an initial guess , , .
- While ,
- –
- Compute the next guess :
- –
- Here, apply the power iteration method to compute , , , , , , , , and .
- –
- Increment t by one.
- Set , , .
- (2A)
- If , set .
- (2B)
- Otherwise,
- If , set , , and .
- If , set , , and .
Finally, set .
Remark 1.
Let be the value computed at Step 1. When falls outside the interval , we set , and we argued earlier that the value returned (at Step 2B) is, at most, . Nevertheless, we conjecture that .
As before, we develop a plotting procedure that minimizes the use of Newton–Raphson iterations.
We note that we have three scenarios for . If is monotone decreasing, then and we set . If is monotone increasing, then and we set . Otherwise, is maximized for some positive value and we set to be this value. Next, to obtain the GV-MR curve (see Remark 2); we iterate over . It should be noted that if or, equivalently, , we obtain a lower bound on the GV-MR curve by iterating over . Similar to Theorem 1, we define
and
Finally, we state the following analogue of Theorem 1.
Theorem 3.
We define , as before. For , we set
Example 3.
We continue our example and evaluate the GV-MR bound for the -SWCC constrained system. In this case, the matrices of interest are
Here, we observe that is a monotone decreasing function and so, we set and . If we apply Procedure 2 to compute for 100 points in , we require 437 Newton–Raphson iterations and 85,500 power iterations. In contrast, we use Theorem 3 to compute for 100 values of x in the interval . This requires 323 Newton–Raphson iterations and involves 22,296 power iterations. The resulting GV-MR curve is given in Figure 1a.
Remark 2.
Strictly speaking, the GV-MR curve described by (17) may not be equal to the curve defined by the optimization problem (15). Nevertheless, the curve provides a lower bound for the optimal asymptotic code rates and we conjecture that the GV-MR curve described by (17) is a lower bound for the curve defined by the optimization problem (15).
5. Single-State Graph Presentation
In this section, we focus on graph presentations that have exactly one state. Here, we allow these single-state graph presentations to contain the parallel edges and their labels to be binary strings of length possibly greater than one. Now, for these constrained systems, the procedures to evaluate the GV bound and its MR improvements can be greatly simplified. This is because the matrices , , and are all of dimensions one by one. Therefore, determining their respective dominant eigenvalues is straightforward and does not require the power iteration method. The results in this section follow directly from previous sections and our objective is to provide explicit formulas whenever possible.
Formally, let be the constrained system with graph presentation such that and with (existing methods that determine the GV bound for constrained systems with assume that the edge-labels have single letters, i.e., . In other words, previous methods developed in [12,14] do not apply).
We further define for . Then. the corresponding adjacency and reduced distance matrices are as follows:
Then, we compute the capacity using its definition as .
To compute , we consider the following extension of the optimization problem (3) for the case :
As before, following the convexity of the objective function in (18), we have that the optimal y is the zero (in the interval ) of the function
So, for fixed values of , we can use the Newton–Raphson procedure to compute the root y of (19), and, hence, evaluate . It should be noted that the power iteration method is not required in this case.
On the other hand, to plot the GV curve, we have the following corollary of Theorem 1.
Corollary 2.
Let be the single-state graph presentation for a constrained system . Then, the corresponding GV curve is given by
where
We illustrate this evaluation procedure via an example of the class of subblock energy-constrained codes (SECCs). Formally, we fix a subblock length L and energy constraintw. A binary word x of length is said to satisfy the -subblock energy constraint if we partition x into m subblocks of length L, then the number of ones in every subblock is at least w. We refer to the collection of words that meet this constraint as an -SECC constrained system. The class of SECCs was introduced by Tandon et al. for the application of simultaneous energy and information transfer [7]. Later, in [21], a GV-type bound was introduced (see Proposition 12 in [21] and also, (28)) and we make comparisons with the GV bound (20) in the following example.
Example 4. ![Entropy 26 00346 i029]()
Let and and we consider a -SECC constrained system. It is straightforward to observe that the graph presentation is as follows with the single state x. Here, .

Then, the corresponding adjacency and reduced distance matrices are as follows:
First, we determine the GV bound at . We observe that and, so, the optimal point y for (18) is (the unique solution to in the interval ). Hence, we have that . On the other hand, the capacity of a -SECC constrained system is . Therefore, the GV bound is given by .
In contrast, the GV-type lower bound given by Proposition 12 in [21] is zero for . Hence, the evaluation of the GV bound yields a significantly better lower bound. In fact, we can show that for all .
To plot the GV curve, using the fact that , we have that
We plot the curve in Section 6.
From this example, we see that our methods yield better lower bounds in terms of asymptotic coding rates for a specific pair of . It is open to determine how much improvement can be achieved for general pairs of L and w.
Next, we evaluate the GV-MR bound. To this end, we consider some proper subset and define
Then, we consider the following matrices:
Setting p to be the normalized frequency of edges in , we obtain by solving the optimization problem (10).
Specifically, we have that
and this value is achieved when
To compute , we consider the following extension of the optimization problem (12) for the case .
As before, following the convexity of the objective function in (23), we have that the optimal x and y are the zeroes (in the interval ) of the functions
So, for fixed values of p and , we can use the Newton–Raphson procedure to compute the roots x and y of (24), and, hence, evaluate . It should be noted that the power iteration method is not required in this case. We find as defined in Section 4 and set
Furthermore, if , we set
Next, to plot the GV-MR curve, we have the following corollary of Theorem 3.
Corollary 3.
Let be the single-state graph presentation for a constrained system . For , we set
where is the smallest root of the equation
If , then for , we set
Example 5. ![Entropy 26 00346 i030]()
We continue our example and evaluate the GV-MR bound for the -SECC constrained system. We have the following single-state graph presentation:

Then, the matrices of interest are:
Since and are both singleton matrices, we have and . Then, , and . Now, we apply Theorem 2 and express and δ in terms of x where where .
Now, we observe that we have . Since we can still increase y to 1, we apply the GV bound with and once we reach the boundary that is . Hence, at the boundary, we solve the following problem:
By setting , we get where and we plot the respective curve.
6. Numerical Plots
In this section, we apply our numerical procedures to compute the GV and the GV-MR bounds for some specific constrained systems. In particular, we consider the -SWCC constrained systems defined in Section 3, the ubiquitous -runlength limited systems (see, for example, p. 3 in [11]) and the -subblock energy constrained codes recently introduced in [7]. In addition to the GV and GV-MR curves, we also plot a simple lower bound. For each , any ball size is at most . So, for any constrained system , we have that . Therefore, we have that
From the plots in Figure 1, Figure 2 and Figure 3, it is also clear that the computations of (7) and (17) yield a significantly better lower bound.
6.1. -Sliding Window Constrained Codes
We fix L and w. We recall from Section 3 that a binary word satisfies the -sliding window weight constraint if the number of ones in every consecutive L bits is at least w and the -SWCC constrained system refers to the collection of words that meet this constraint. From [8,9], we have a simple graph presentation that uses only states. To validate our methods, we choose and the corresponding graph presentations have 3 and 120 states, respectively. Applying the plotting procedures described in Theorems 1 and 3, we obtain Figure 1.
6.2. -Runlength Limited Codes
Next, we revisit the ubiquitous runlength constraint. We fix d and k. We say that a binary word satisfies the -RLL constraint if each run of zeroes in the word has a length of at least d and at most k. Here, we allow the first and last runs of zeroes to have a length of less than d. We refer to the collection of words that meet this constraint as a -RLL constrained system. It is well known that a -RLL constrained system has the graph presentation with states (see, for example, [11]). Here, we choose to validate our methods and apply Theorems 1 and 3 to obtain Figure 2. For , we corroborate our results with those derived in [15]. Specifically, Winick and Yang determined the GV bound (1) for the -RLL constraint and remarked that the “evaluation of the (GV-MR) bound required considerable computation” for “a small improvement”. In Table 3, we verify this statement.
6.3. -Subblock Energy-Constrained Codes
We fix L and w. We recall from Section 5 that a binary word satisfies the -subblock energy constraint if each subblock of length L has a weight of at least w and the -SECC constrained system refers to the collection of words that meet this constraint. Then, the corresponding graph presentation has a single state with edges, where each edge is labeled by a word of length L and weight at least w. We apply the methods in Section 5 to determine the GV and GV-MR bounds.
For the GV bound, we provide the explicit formula for and proceed as in Example 4.
Similarly, for GV-MR bound, we provide the explicit formula for , , and and proceed as in Example 5.
Author Contributions
Conceptualization, K.G. and H.M.K.; software, K.G.; writing—original draft preparation, K.G.; writing—review and editing, K.G. and H.M.K. All authors have read and agreed to the published version of the manuscript.
Funding
The work of Han Mao Kiah was supported by the Ministry of Education, Singapore, under its MOE AcRF Tier 2 Award under Grant MOE-T2EP20121-0007 and MOE AcRF Tier 1 Award under Grant RG19/23.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Acknowledgments
The authors would also like to thank the assistant editor for her skillful handling and the anonymous reviewers for their valuable suggestions.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. Power Iteration Method for Derivatives of Dominant Eigenvalues
Throughout this appendix, we assume that A is a diagonalizable matrix with dominant eigenvalue and whose corresponding eigenspace has dimension one. Let be the unit eigenvector whose entries are positive in this space. Then, the power iteration method is a well-known numerical procedure that finds the dominant eigenvalue and the corresponding eigenvector efficiently.
Now, in the preceding sections, the entries in the matrix A are given functions in either one or two variables and, thus, the dominant eigenvalue is a function in the same variables. Moreover, the numerical procedures in these sections require us to compute the higher order (partial) derivatives of this dominant eigenvalue function . To the best of our knowledge, we are unaware of any algorithms or numerical procedures that estimate the values of these derivatives. Hence, in this appendix, we modify the power iteration method to compute these estimates.
Formally, let A be an irreducible nonnegative diagonalizable square matrix with dominant eigenvalue and corresponding unit eigenvector . Since A is diagonalizable, A has n eigenvectors that form an orthonormal basis for . Let be the corresponding eigenvalues and, so, we have that
Since A is irreducible, the dominant eigenspace has dimension one and, also, the dominant eigenvalue is real and positive. Therefore, we can assume that .
We first assume that the entries of A are functions in the variable z. Hence, and the entries of are functions in z too. Then Power Iteration I then evaluates both and for some fixed value of z, while Power Iteration II additionally evaluates the second order derivative .
The case where the entries of A are functions in two variables x and y is discussed at the end of the appendix. Here, Power Iteration III evaluates higher order partial derivatives of for certain fixed values of x and y. For ease of exposition, we provide detailed proofs for the correctness of Power Iteration I and the proofs can be extended for Power Iteration II and Power Iteration III.
We continue our discussion where the entries of A are univariate functions in z. We differentiate each entry of A with respect to z to obtain the matrix . Furthermore, for all , we differentiate each entry of eigenvectors and the eigenvalue to obtain and , respectively. Specifically, it follows from (A1) that
Then, the following procedure computes both and .
Power Iteration I.
Input: Irreducible nonnegative diagonalizable matrix A
Output: Estimates of and
- (1)
- Initialize such that all its entries are strictly positive.Fix a tolerance value .While ,
- –
- Set
- –
- Increment k by one.
- (2)
Set and .
Theorem A1.
If A is an irreducible nonnegative diagonalizable matrix and has positive components with unit norm, then, as , we have
Here, means that as .
Before we present the proof of Theorem A1, we remark that the usual power iteration method computes only and . Then, it is well-known (see, for example, [22]) that and tend to and , respectively.
Now, since spans , we can write for any initial vector . The next technical lemma provides closed formulas for , , , and in terms of , and .
Lemma A1.
Let . Then,
Proof.
Since is defined recursively as , we have that
Then, it follows from Equation (A1) that
and, so, we obtain (A3). Similarly, from (A1), we have that
as required for (A4).
Next, we note that . Then, using the recursive definition of , we have
Then, from (A1), we have
and, from (A2),
Therefore, using (A1) again,
Therefore, we obtain (A5).
Finally, we recall that is defined as
Finally, we are ready to demonstrate the correctness of Power Iteration I.
Proof of Theorem A1.
Since A is an irreducible nonnegative diagonalizable matrix, is real positive and there exists such that (see, for example, [11]). For purposes of brevity, we write
and, so, we can rewrite (A3) as
Now, since for all , we have that
Then, using the triangle inequality, we have that as , and, thus, . Therefore, as required.
It should be noted that since tends to a finite limit, we have that is bounded above by some constant. In other words, we have that
Next, we show the following inequality:
Using (A4), we have that
Now, observe that for . Since , we have (A13) after applying the triangle inequality.
Again, to reduce clutter, we introduce the following abbreviations:
Thus, we can rewrite (A6) as
Next, we bound each of the summands on the right-hand side. Specifically, we show the following inequalities:
To demonstrate (A14), we consider
We use (A13) to bound the first summand by some constant multiple of . On the other hand, we have for . In other words, the second summand is also bounded by some constant multiple of . Next, we consider
and, so, is also bounded by a multiple of . Therefore, since , we have (A14). Using similar methods, we can establish (A15).
Next, we apply (A14) and then recursively apply (A15) until the right-hand side is free of s. Then, it follows that
Furthermore, since , , we can rewrite (A16) as
Next, it follows from standard calculus that . Furthermore, since , we have and . Putting everything together, we have
As , since , we have and . Therefore, . Using similar methods, we have that and, so, , as required. □
Next, we modify Power Iteration I so as to compute the higher order derivatives. We omit a detailed proof as it is similar to the proof of Theorem A1.
Power Iteration II.
Input: Irreducible nonnegative diagonalizable matrix A
Output: Estimates of , , and
- (1)
- Initialize such that all its entries are strictly positive.Fix a tolerance value .While ,
- –
- Set
- –
- Increment k by one.
- (2)
- Set , and .
Theorem A2.
If A is an irreducible nonnegative diagonalizable matrix and has positive components with unit norm, then, as , we have
Finally, we end this appendix with a power iteration method that computes the partial derivatives when the elements of the given matrix are bivariate functions.
Power Iteration III.
Input: Irreducible nonnegative diagonalizable matrix A
Output: Estimates of , , , , , and
- (1)
- Initialize such that all its entries are strictly positive.
- Fix a tolerance value .
- While ,
- –
- Set
- –
- Increment k by one.
- Set , , , , , .
Theorem A3.
If A is an irreducible nonnegative diagonalizable matrix and has positive components with unit norm, then, as , we have , , .
References
- Yazdi, S.M.H.T.; Kiah, H.M.; Garcia-Ruiz, E.; Ma, J.; Zhao, H.; Milenkovic, O. DNA-Based Storage: Trends and Methods. IEEE Trans. Mol. Biol. Multi-Scale Commun. 2015, 1, 230–248. [Google Scholar] [CrossRef]
- Immink, K.A.S.; Cai, K. Efficient balanced and maximum homopolymer-run restricted block codes for DNA-based data storage. IEEE Commun. Lett. 2019, 23, 1676–1679. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Cai, K.; Immink, K.A.S.; Kiah, H.M. Capacity-Approaching Constrained Codes with Error Correction for DNA-Based Data Storage. IEEE Trans. Inf. Theory 2021, 67, 5602–5613. [Google Scholar] [CrossRef]
- Kovačević, M.; Vukobratović, D. Asymptotic Behavior and Typicality Properties of Runlength-Limited Sequences. IEEE Trans. Inf. Theory 2022, 68, 1638–1650. [Google Scholar] [CrossRef]
- Popovski, P.; Fouladgar, A.M.; Simeone, O. Interactive joint transfer of energy and information. IEEE Trans. Commun. 2013, 61, 2086–2097. [Google Scholar] [CrossRef]
- Fouladgar, A.M.; Simeone, O.; Erkip, E. Constrained codes for joint energy and information transfer. IEEE Trans. Commun. 2014, 62, 2121–2131. [Google Scholar] [CrossRef]
- Tandon, A.; Motani, M.; Varshney, L.R. Subblock-constrained codes for real-time simultaneously energy and information transfer. IEEE Trans. Inf. Theory 2016, 62, 4212–4227. [Google Scholar] [CrossRef]
- Immink, K.A.S.; Cai, K. Block Codes for Energy-Harvesting Sliding- Window Constrained Channels. IEEE Commun. Lett. 2020, 24, 2383–2386. [Google Scholar] [CrossRef]
- Immink, K.A.S.; Cai, K. Properties and Constructions of Energy-Harvesting Sliding-Window Constrained Codes. IEEE Commun. Lett. 2020, 24, 1890–1893. [Google Scholar] [CrossRef]
- Wu, T.Y.; Tandon, A.; Varshney, L.R.; Motani, M. Skip-sliding window codes. IEEE Trans. Commun. 2021, 69, 2824–2836. [Google Scholar] [CrossRef]
- Marcus, B.H.; Roth, R.M.; Siegel, P.H. An Introduction to Coding for Constrained Systems. Lecture Notes. 2001. Available online: https://ronny.cswp.cs.technion.ac.il/wp-content/uploads/sites/54/2016/05/chapters1-9.pdf (accessed on 1 October 2020).
- Kolesnik, V.D.; Krachkovsky, V.Y. Generating functions and lower bounds on rates for limiting error-correcting codes. IEEE Trans. Inf. Theory 1991, 37, 778–788. [Google Scholar] [CrossRef]
- Gu, J.; Fuja, T. A generalized Gilbert-Varshamov bound derived via analysis of a code-search algorithm. IEEE Trans. Inf. Theory 1993, 39, 1089–1093. [Google Scholar] [CrossRef]
- Marcus, B.H.; Roth, R.M. Improved Gilbert-Varshamov bound for constrained systems. IEEE Trans. Inf. Theory 1992, 38, 1213–1221. [Google Scholar] [CrossRef]
- Winick, K.A.; Yang, S.H. Upper bounds on the size of error-correcting runlength-limited codes. Eur. Trans. Telecommun. 1996, 37, 273–283. [Google Scholar] [CrossRef]
- Goyal, K.; Kiah, H.M. Evaluating the Gilbert-Varshamov Bound for Constrained Systems. In Proceedings of the 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 Jun–1 July 2022; pp. 1348–1353. [Google Scholar]
- Tolhuizen, L.M.G.M. The generalized Gilbert-Varshamov bound is implied by Turan’s theorem. IEEE Trans. Inf. Theory 1997, 43, 1605–1606. [Google Scholar] [CrossRef]
- Luenberger, D.G. Introduction to Linear and Nonlinear Programming; Addison-Wesley: Reading, MA, USA, 1973. [Google Scholar]
- Rockafellar, T. Convex Analysis; Princeton University: Pressrinceton, NJ, USA, 1970. [Google Scholar]
- Kashyap, N.; Roth, R.M.; Siegel, P.H. The Capacity of Count-Constrained ICI-Free Systems. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1592–1596. [Google Scholar]
- Tandon, A.; Kiah, H.M.; Motani, M. Bounds on the size and asymptotic rate of subblock-constrained codes. IEEE Trans. Inf. Theory 2018, 64, 6604–6619. [Google Scholar] [CrossRef]
- Stewart, G.W. Introduction to Matrix Computations; Computer Science and Applied Mathematics; Academic Press: New York, NY, USA, 1973. [Google Scholar]
Figure 1.
Lower bounds for optimal asymptotic code rates for the class of sliding-window constrained codes.
Figure 1.
Lower bounds for optimal asymptotic code rates for the class of sliding-window constrained codes.

Figure 2.
Lower bounds for optimal asymptotic code rates for the class of runlength limited codes.

Figure 3.
Lower bounds for optimal asymptotic code rates where is the class of -SECCs (subblock energy-constrained codes).
Figure 3.
Lower bounds for optimal asymptotic code rates where is the class of -SECCs (subblock energy-constrained codes).


{kind=link}
{kind=link}
{kind=link}
Table 1.
We set the entry of the matrix according to subgraph induced by the states ,, Gilbert–Varshamov . Here, denotes the complement of .
Table 1.
We set the entry of the matrix according to subgraph induced by the states ,, Gilbert–Varshamov . Here, denotes the complement of .
| at Entry | Subgraph Induced by the States | ||||
|---|---|---|---|---|---|
| 0 |  |  |  |  |  |
| 1 |  |  |  | ||
| y |  |  |  | ||
 | |||||
Table 2.
We set the entry of the matrix according to the subgraph induced by the states ,,, and .
| at Entry | Subgraph Induced by the States | ||||
|---|---|---|---|---|---|
| 0 |  |  |  |  |  |
| 1 |  |  |  | ||
 |  |  | |||
 |  |  | |||
 | |||||
Table 3.
Comparison of the GV-MR bound with lower bound [15] for -RLL constrained systems.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Goyal, K.; Kiah, H.M. Evaluating the Gilbert–Varshamov Bound for Constrained Systems. Entropy 2024, 26, 346. https://doi.org/10.3390/e26040346
AMA Style
Goyal K, Kiah HM. Evaluating the Gilbert–Varshamov Bound for Constrained Systems. Entropy. 2024; 26(4):346. https://doi.org/10.3390/e26040346
Chicago/Turabian StyleGoyal, Keshav, and Han Mao Kiah. 2024. "Evaluating the Gilbert–Varshamov Bound for Constrained Systems" Entropy 26, no. 4: 346. https://doi.org/10.3390/e26040346
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.