
Abstract
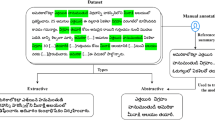
One of the most popular south Indian languages in India is the Telugu language which is currently spoken by 84 million native Telugu speakers in Andhra Pradesh and Telangana. With the rapid growth of the Telugu digital content, the need for the automatic text summarizer is arisen to provide short text from huge text documents. Extractive text summarization model generates only significant sentences. Abstractive text summarization method requires more training time. In this paper, a novel hybrid model is proposed for generating text summaries by combining extractive and abstractive approach to reduce the training time. For extractive method TextRank algorithm is utilized and for abstractive method attention-based sequence to sequence model with bidirectional long short-term memory (Bi-LSTM) is utilized. Moreover, coverage mechanism is included into the proposed hybrid approach to reduce the repetition in summaries and to improve the quality of summaries. The performance of the proposed hybrid model is evaluated by the ROUGE toolkit in terms of F-measure, recall and precision. The results of the proposed model are compared with other existing models which shows that the proposed hybrid model outperforms other existing text summarization models for Telugu Language.










Similar content being viewed by others


Availability of data and materials
Data will be shared on the reasonable request.
References
Alzuhair A and Al-Dhelaan M 2019 An approach for combining multiple weighting schemes and ranking methods in graph-based multi-document summarization. IEEE Access 7: 120375–120386
Hernandez-Castaneda A, Garcia-Hernandez R A, Ledeneva Y and Millan-Hernandez C E 2020 Extractive automatic text summarization based on lexical-semantic keywords. IEEE Access 8: 49896–49907
Elayeb B, Chouigui A, Bounhas M and Khiroun O B 2020 Automatic Arabic text summarization using analogical proportions. Cognit. Comput. 12(5): 1043–1069
Tomer M and Kumar M 2020 Improving text summarization using ensembled approach based on fuzzy with LSTM. Arab. J. Sci. Eng. 45(12): 10743–10754
Zhang P and Li C 2009 Automatic text summarization based on sentences clustering and extraction. In: 2nd IEEE International Conference on Computer Science and Information Technology, Beijing, China, pp. 167–170
Wong K F, Wu M and Li W 2008 Extractive summarization using supervised and semi-supervised learning. In: 22nd International Conference on Computational Linguistics, Manchester, pp. 985–992
Azadani M N, Ghadiri N and Davoodijam E 2018 Graph-based biomedical text summarization: an itemset mining and sentence clustering approach. J. Biomed. Inf. 84: 42–58
Erkan G and Radev D R 2004 LexRank: graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 22: 457–479
Mihalcea R and Tarau P 2004 TextRank: bringing order into texts. In: Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, pp. 404–411
Pan H X, Liu H and Tang Y 2019 A sequence-to-sequence text summarization model with topic based attention mechanism. In:16th International Conference on Web Information Systems and Applications. Springer, Cham, pp. 285–297
Zeng B, Xu R, Yang H, Gan Z and Zhou W 2020 Comprehensive document summarization with refined self-matching mechanism. Appl. Sci. 10(5): 1864
Sun M, Liu Y, Liu Z and Zhang M 2018 Chinese computational linguistics and natural language processing based on naturally annotated big data. In: 17th China National Conference and 6th International Symposium, Changsha, China
Tu Z, Lu Z, Liu Y, Liu X and Li H 2016 Modeling coverage for neural machine translation, pp. 76–85. arXiv:1601.04811v6
Lin C Y 2004 ROUGE: a package for automatic evaluation of summaries. In: Proceedings of the ACL Workshop: Text Summarization Braches Out 2004, Barcelona, Spain
Sutskever I, Vinyals O and Le Q V 2014 Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 27
Bahdanau D, Cho K, Bengio Y 2014 Neural machine translation by jointly learning to align and translate. arXiv:1409.0473
Rush A M, Chopra S, Weston J 2015 A neural attention model for abstractive sentence summarization. arXiv: 1509.00685
See A, Liu P J and Manning C D 2017 Get to the point: summarization with pointer-generator networks. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pp. 1073–1083
Khanam M H 2016 Text summarization for Telugu document. J. Comput. Eng. 25–28
Shashikanth S and Sanghavi S 2019 Text summarization techniques survey on Telugu and Foreign languages. Int. J. Res. Eng. Sci. Manag. 2(1): 211–213
Kallimani J S, Srinivasa K G and Eswara Reddy B 2011 Information extraction by an abstractive text summarization for an Indian regional language. In: 7th International Conference on Natural Language Processing and Knowledge Engineering, Tokushima, Japan, pp. 319–322
Sudha D N and Latha Y M 2020 Multi-document abstractive text summarization through semantic similarity matrix for Telugu language. Int. J. Adv. Sci. Technol. 29(1): 513–521
Vimal Kumar K and Yadav D 2015 An improvised extractive approach to Hindi text summarization. In: Information Systems Design and Intelligent Applications. Springer, New Delhi, pp. 291–300
Gupta V and Kaur N 2016 A novel hybrid text summarization system for Punjabi text. Cogn. Comput. 8(2): 261–77
Rathod Y V 2018 Extractive text summarization of Marathi news articles. Int. Res. J. Eng. Technol. 5(7): 1204–1210
Banu M, Karthika C, Sudarmani P and Geetha T V 2007 Tamil document summarization using semantic graph method. In: International Conference on Computational Intelligence and Multimedia Applications (ICCIMA 2007), Sivakasi, India, pp. 128–34
Kondath M, Suseelan D P and Idicula S M 2022 Extractive summarization of Malayalam documents using latent Dirichlet allocation: an experience. J. Intell. Syst. 31(1): 393–406
Acknowledgements
I confirm that all authors listed on the title page have contributed significantly to the work, have read the manuscript, attest to the validity and legitimacy of the data and its interpretation, and agree to its submission.
Funding
Funding information is not applicable because no funding was received
Author information
Authors and Affiliations
Contributions
Experimental, literature reviews, identification of novelty, analyzing the data, code work, figures and tables works have been done by G. L. Anand Babu. Manuscript drafting, revision, proof reading and guidance of all works are done by Srinivasu Badugu.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethics approval
Funding information is not applicable because no funding was received, so he name of the approving body and the approval number ID not applicable to this manuscript.
Consent to participate
This research did not contain any studies involving human animal participants.
Consent for publication
I, give my consent for the publication of above Article.I declare that I shall not submit the paper for publication in any other Journal or Magazine till the decision is made by journal editors.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Babu, G.L.A., Badugu, S. Multi-document hybrid text summarization with bi-LSTM RNN for Telugu language. Sādhanā 49, 155 (2024). https://doi.org/10.1007/s12046-024-02499-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12046-024-02499-8