Soft Computing ( IF 4.1 ) Pub Date : 2024-02-06 , DOI: 10.1007/s00500-024-09668-1 P. Naga Bhushanam , S. Selva Kumar
|
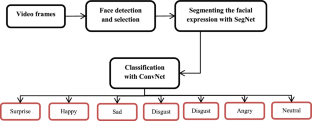
Facial Emotion detection (FER) is primarily used to assess human emotion to meet the demands of several real-time applications, including emotion detection, computer–human interfaces, biometrics, forensics, and human–robot collaboration. However, several current techniques fall short of providing accurate predictions with a low error rate. This study focuses on modeling an effective FER with unrestricted videos using a hybrid SegNet and ConvNet model. SegNet is used to segment the regions of facial expression, and ConvNet is used to analyze facial features and to make predictions about emotions like surprise, sadness, and happiness, among others. The suggested hybridized approach uses a neural network model to classify face characteristics depending on their location. The proposed model aims to recognize facial emotions with a quicker convergence rate and improved prediction accuracy. This work takes into account the internet-accessible datasets from the FER2013, Kaggle, and GitHub databases to execute execution. To accomplish generalization and improve the quality of prediction, the model acts as a multi-modal application. With the available datasets throughout the testing procedure, the suggested model provides 95% prediction accuracy. Additionally, the suggested hybridized model is used to calculate the system's importance. The experimental results show that, in comparison to previous techniques, the expected model provides superior prediction results and produces better trade-offs. Other related statistical measures are also assessed and contrasted while the simulation is being run in the MATLAB 2020a environment.
中文翻译:
使用无约束视频和深度学习方法对面部情绪识别的高效混合方法进行建模
面部情绪检测(FER)主要用于评估人类情绪,以满足多种实时应用的需求,包括情绪检测、计算机人机界面、生物识别、取证和人机协作。然而,当前的几种技术无法以低错误率提供准确的预测。本研究的重点是使用混合 SegNet 和 ConvNet 模型对不受限制的视频进行有效的 FER 建模。SegNet 用于分割面部表情区域,ConvNet 用于分析面部特征并预测惊讶、悲伤和快乐等情绪。建议的混合方法使用神经网络模型根据面部特征的位置对其进行分类。所提出的模型旨在以更快的收敛速度和更高的预测精度来识别面部情绪。这项工作考虑了来自 FER2013、Kaggle 和 GitHub 数据库的互联网可访问数据集来执行执行。为了实现泛化并提高预测质量,该模型充当多模态应用程序。利用整个测试过程中的可用数据集,建议的模型可提供 95% 的预测精度。此外,建议的混合模型用于计算系统的重要性。实验结果表明,与以前的技术相比,预期模型提供了更好的预测结果并产生了更好的权衡。在 MATLAB 2020a 环境中运行仿真时,还会评估和对比其他相关统计测量。


























 京公网安备 11010802027423号
京公网安备 11010802027423号