International Journal of Parallel Programming ( IF 1.5 ) Pub Date : 2024-02-16 , DOI: 10.1007/s10766-024-00762-3 Milad Kokhazadeh , Georgios Keramidas , Vasilios Kelefouras , Iakovos Stamoulis
|
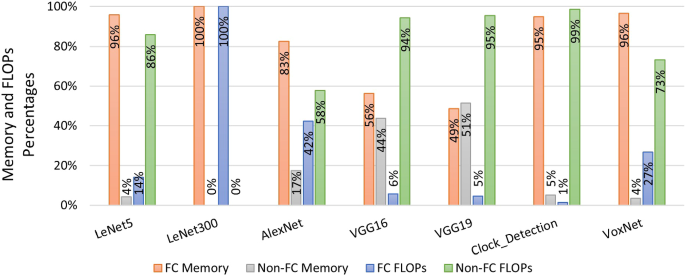
Deep Neural Networks (DNN) have made significant advances in various fields including speech recognition and image processing. Typically, modern DNNs are both compute and memory intensive, therefore their deployment in low-end devices is a challenging task. A well-known technique to address this problem is Low-Rank Factorization (LRF), where a weight tensor is approximated by one or more lower-rank tensors, reducing both the memory size and the number of executed tensor operations. However, the employment of LRF is a multi-parametric optimization process involving a huge design space where different design points represent different solutions trading-off the number of FLOPs, the memory size, and the prediction accuracy of the DNN models. As a result, extracting an efficient solution is a complex and time-consuming process. In this work, a new methodology is presented that formulates the LRF problem as a (FLOPs vs. memory vs. prediction accuracy) Design Space Exploration (DSE) problem. Then, the DSE space is drastically pruned by removing inefficient solutions. Our experimental results prove that the design space can be efficiently pruned, therefore extract only a limited set of solutions with improved accuracy, memory, and FLOPs compared to the original (non-factorized) model. Our methodology has been developed as a stand-alone, parameterized module integrated into T3F library of TensorFlow 2.X.
中文翻译:
在边缘设备中采用张量序列分解的实用方法
深度神经网络(DNN)在语音识别和图像处理等各个领域取得了重大进展。通常,现代 DNN 都是计算和内存密集型的,因此它们在低端设备中的部署是一项具有挑战性的任务。解决这一问题的一种众所周知的技术是低阶分解(LRF),其中权重张量由一个或多个低阶张量近似,从而减少内存大小和执行的张量运算的数量。然而,LRF 的使用是一个多参数优化过程,涉及巨大的设计空间,其中不同的设计点代表不同的解决方案,需要权衡 FLOP 数量、内存大小和 DNN 模型的预测精度。因此,提取有效的解决方案是一个复杂且耗时的过程。在这项工作中,提出了一种新方法,将 LRF 问题表述为(浮点运算与内存与预测精度)设计空间探索 (DSE) 问题。然后,通过删除低效的解决方案来大幅修剪 DSE 空间。我们的实验结果证明,可以有效地修剪设计空间,因此仅提取有限的一组解决方案,与原始(非因式分解)模型相比,其精度、内存和 FLOP 有所提高。我们的方法已开发为独立的参数化模块,集成到 TensorFlow 2.X 的 T3F 库中。


























 京公网安备 11010802027423号
京公网安备 11010802027423号